

TL;DR: Este tutorial mostrará cómo extraer datos de un sitio en Ruby y demostrará las razones por las que es uno de los lenguajes más eficaces para el raspado de datos.
Esta guía cubrirá:
- ¿Ruby es bueno para el raspado web?
- Las mejores gemas Ruby para el raspado web
- Construir un raspador web en Ruby
¿Ruby es bueno para el raspado web?
Ruby es un lenguaje de programación interpretado, de código abierto y de tipado dinámico que admite el desarrollo funcional, procedimental y orientado a objetos. Está diseñado para ser sencillo, con una sintaxis elegante que es fácil de escribir y natural de leer. Su enfoque en la productividad lo ha convertido en una opción popular en varias aplicaciones, incluido el raspado web.
En concreto, Ruby es una opción excelente para el raspado web debido a la amplia gama de bibliotecas de terceros disponibles. Se llaman “gemas” y hay una para casi cada tarea. Cuando se trata de recolectar información de la Web mediante programación, existen gemas para descargar páginas, analizar su contenido HTML y extraer datos de ellas.
En resumen, el raspado web en Ruby no sólo es posible, sino también fácil gracias a la diversidad de bibliotecas disponibles. Veamos cuáles son las más populares.
Las mejores joyas de raspado web en Ruby
Aquí están las tres mejores bibliotecas de raspado web para Ruby:
- Nokogiri(鋸): Una robusta y flexible biblioteca de análisis HTML y XML con una API completa para recorrer y manipular documentos HTML/XML, facilitando la extracción de datos relevantes de ellos.
- Mechanize: Una biblioteca con funcionalidad de navegador sin interfaz gráfica (headless) que proporciona una API de alto nivel para automatizar la interacción con sitios web. Puede almacenar y enviar cookies, gestionar redireccionamientos, seguir enlaces y enviar formularios. Además, proporciona un historial para realizar un seguimiento de los sitios visitados.
- Selenium: Una vinculación Ruby del framework más popular para ejecutar pruebas automatizadas en páginas web. Su función es hacer que un navegador interactúe con un sitio web como lo haría un usuario humano. Esta tecnología desempeña un papel clave a la hora de eludir las soluciones antibot y los sitios de raspado web que dependen de JavaScript para renderizar o recuperar datos.
Requisitos previos
Antes de escribir algo de código, es necesario instalar Ruby en su máquina. A continuación, se muestra la guía correspondiente a cada sistema operativo.
Instalar Ruby en MacOS
De manera predeterminada, Ruby está incluido en macOS desde la versión 10.11 (El Capitan), lanzada en 2015. Teniendo en cuenta que macOS depende nativamente de Ruby para proporcionar algunas funcionalidades, no debería tocarlo. No se recomienda actualizar la versión nativa de Ruby con brew install ruby o update ruby mac, ya que puede romper algunas funciones integradas.
Instalar Ruby en Windows
Se debe descargar el paquete RubyInstaller, ejecutarlo y seguir el asistente de instalación para configurar Ruby. Puede ser necesario reiniciar el sistema. A partir de Windows 10, también se puede utilizar el Subsistema de Windows para Linux para instalar Ruby siguiendo las instrucciones que se indican a continuación.
Instalar Ruby en Linux
La mejor forma de configurar un entorno Ruby en Linux es instalarlo a través de un gestor de paquetes.
En Debian y Ubuntu, inicie:
sudo apt-get install ruby-fullEn otras distribuciones, el comando de terminal a ejecutar es diferente. Consulta la guía en el sitio oficial para ver todos los sistemas de gestión de paquetes soportados.
Independientemente de cuál sea su sistema operativo, ahora puede verificar que Ruby está funcionando:
ruby -vSe debería imprimir algo como:
ruby 3.2.2 (2023-03-30 revision e51014f9c0)¡Genial! ¡Ahora está todo listo para comenzar con el raspado web en Ruby!
Construir un Raspador web en Ruby
En esta sección, se mostrará cómo crear un raspador web en Ruby. Este script automatizado recuperará datos de la página de inicio de Bright Data. A continuación, se presentanlas acciones a detalle:
- Se conectará al sitio de destino
- Se seleccionarán los elementos HTML de interés del DOM
- Se extraerá datos de ellos
- Se convertirá los datos extraídos a formatos fáciles de explorar, como CSV y JSON.
En el momento de escribir estas líneas, esto es lo que ven los usuarios cuando visitan la página web de destino:
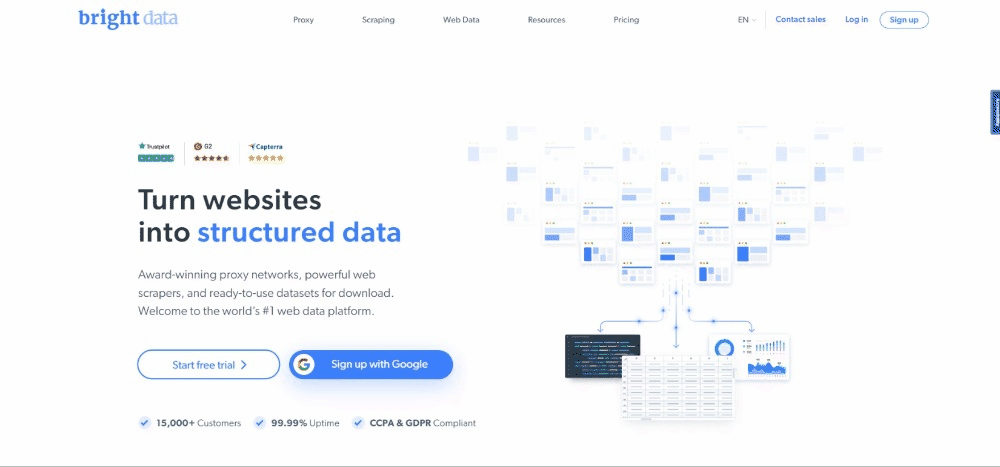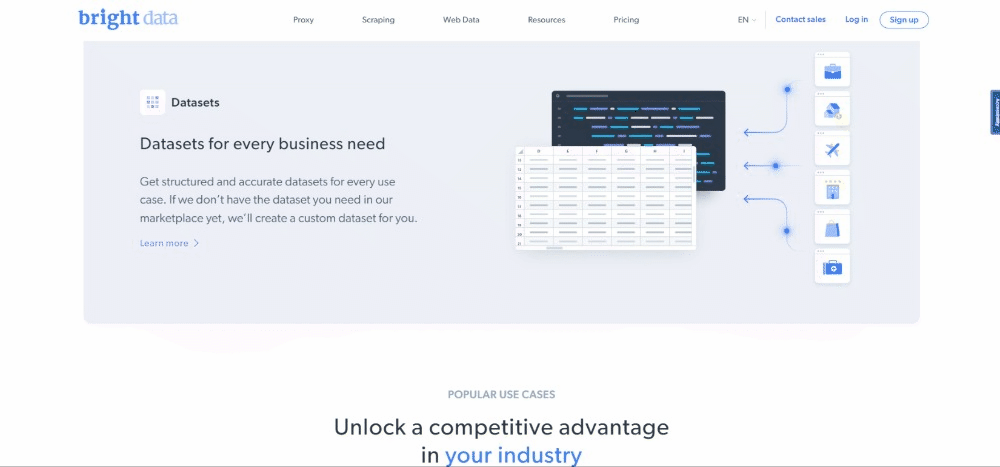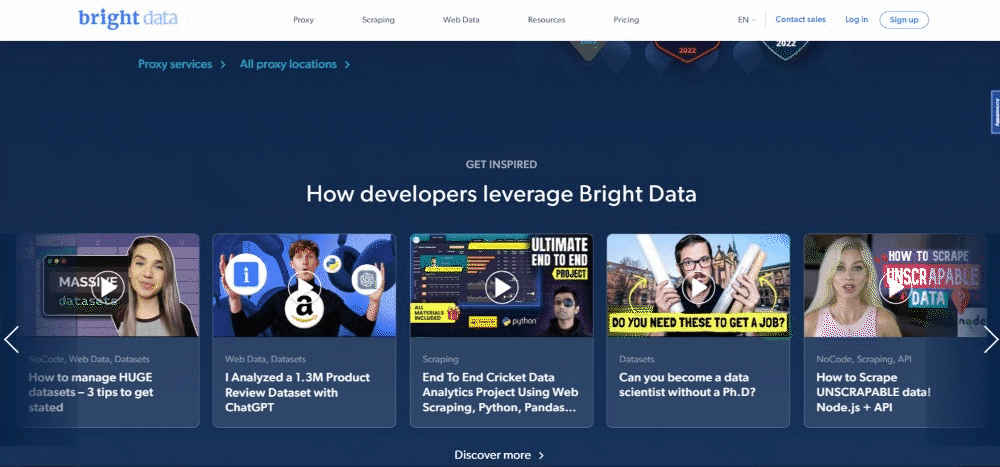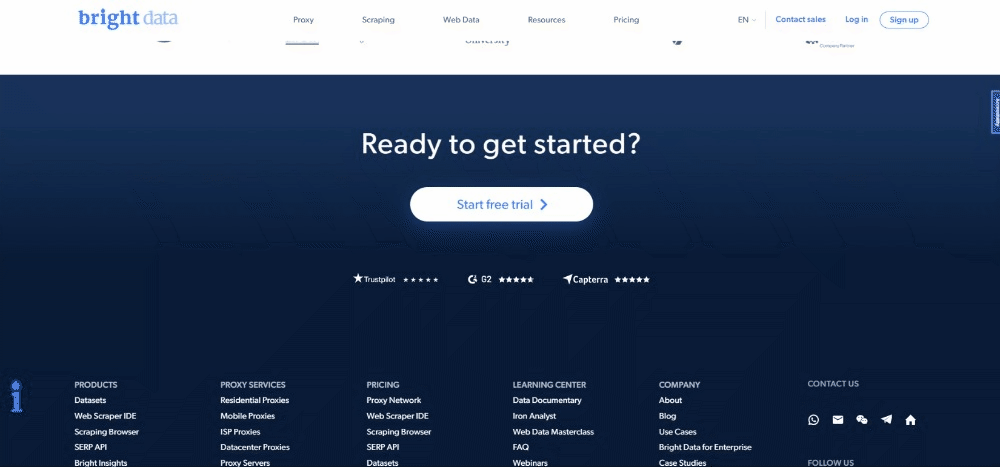
Es importante tener en cuenta que la página de inicio de BrightData cambia con frecuencia y puede que no sea la misma cuando usted lea este artículo.
El objetivo específico del raspado web es obtener la información del caso de uso contenida en las siguientes tarjetas:
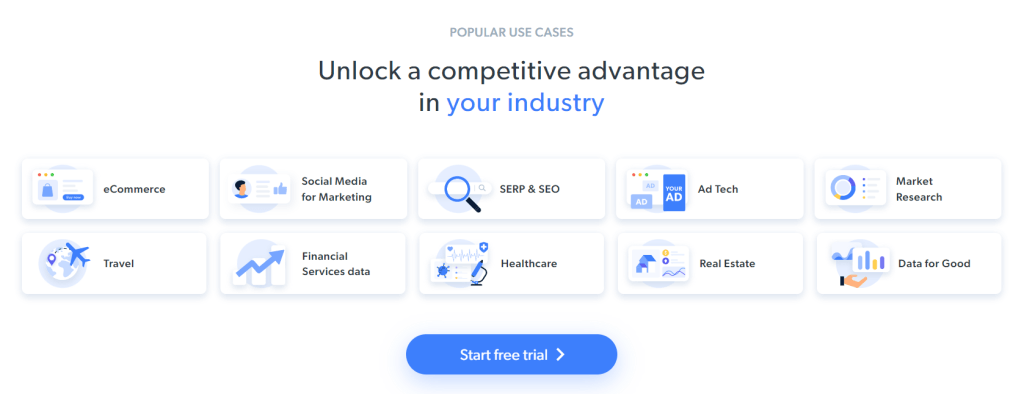
A continuación, ofrecemos un tutorial paso a paso para aprender a hacer raspado web con Ruby.
Paso 1: Inicializar un proyecto Ruby
Antes de empezar, es necesario que se configure el proyecto Ruby. Inicie la terminal, cree la carpeta del proyecto e ingrese:
mkdir ruby-web-scraper
cd ruby-web-scraperEl directorio ruby-web-scraper contendrá su raspador.
A continuación, se debe inicializar un archivo scraper.rb dentro de la carpeta del proyecto con el siguiente contenido:
puts "Hello, World!"El fragmento anterior es el script Ruby más sencillo posible.
Compruebe que funciona ejecutándolo en su terminal:
ruby scraper.rbEsto debería imprimir este mensaje:
Hello, World!Es hora de importar el proyecto a su IDE y empezar a definir la lógica avanzada del raspado web en Ruby. Esta guía explica cómo configurar Visual Studio Code (VS Code) para el desarrollo de Ruby. Al mismo tiempo, cualquier otro IDE de Ruby servirá.
Dado que VS Code no soporta Ruby de forma nativa, primero es necesario añadir la extensión Ruby. Inicie Visual Studio Code, haga clic en el icono “Extensiones” en la barra de la izquierda, y escriba “Ruby” en la entrada de búsqueda en la parte superior.
Haga clic en el botón “Instalar” del primer elemento para añadir las funciones de resaltado de Ruby a VS Code. Espere a que el plugin se añada al IDE. A continuación, abra la carpeta ruby-web-scraper con “Archivo“, “Abrir carpeta…”.
Haga clic en el archivo scraper.rb bajo la barra “EXPLORER” para comenzar a editar el archivo:
Paso 2: Elegir la biblioteca de raspado web
Construir un raspador web en Ruby se hace más fácil con la biblioteca adecuada. Por esta razón, se debe adoptar una de las gemas presentadas anteriormente. Para averiguar qué biblioteca Ruby de raspado web se adapta mejor a sus objetivos, debe dedicar algún tiempo a analizar el sitio de destino.
Para ello, visite la página de destino en su navegador, haga clic con el botón derecho del ratón en un lugar en blanco del fondo y haga clic en la opción “Inspeccionar“. Esto iniciará las herramientas de desarrollo de su navegador. En Chrome, vaya a la pestaña “Red” y explore la sección “Fetch/XHR“.
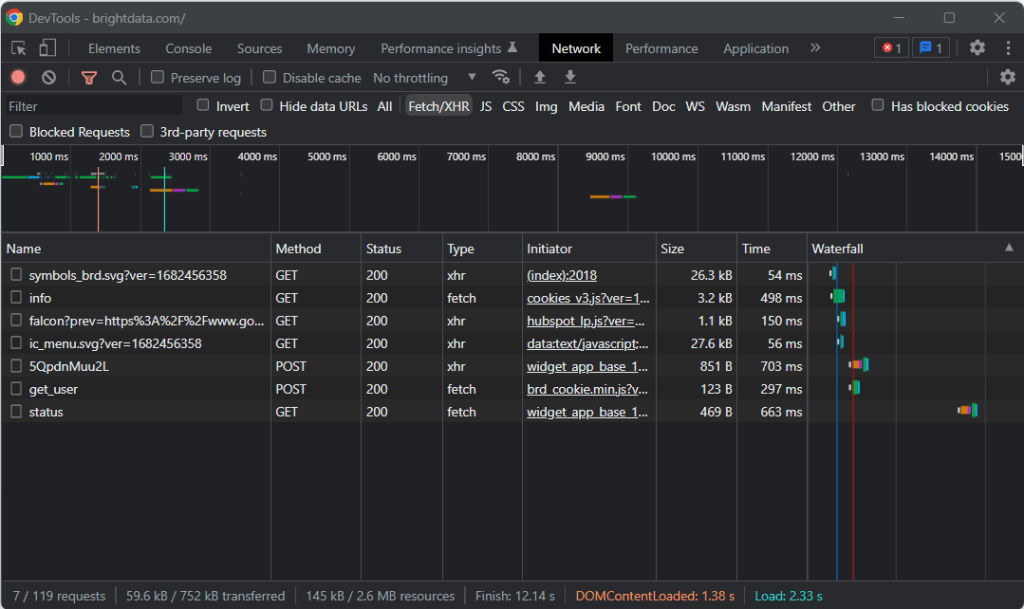
Como se puede observar en la captura de pantalla anterior, sólo hay siete peticiones AJAX. Analice cada una de las llamadas XHR y observará que no implican ningún dato significativo. Esto significa que la página de destino no recupera contenido en el momento de la renderización. Así, el documento HTML devuelto por el servidor ya contiene todos los datos que mostrar a los usuarios.
Esto demuestra que la página de destino no utiliza JavaScript para recuperar datos ni para la renderización. En otras palabras, no se necesita una gema con capacidades de navegador sin interfaz gráfica para realizar raspado web. Todavía se puede utilizar Mechanize o Selenium, pero sólo añadirían algunos gastos generales de rendimiento. Después de todo, ejecutan una instancia del navegador detrás del telón, lo que consume recursos.
En resumen, conviene optar por un analizador HTML/XML sencillo como Nokogiri. Instálelo a través de la gema nokogiri con:
gem install nokogiriA continuación, se puede importar la biblioteca mediante la adición de la siguiente línea en la parte superior de su archivo scraper.rb:
require "nokogiri"Confirmar que el IDE de Ruby no informa de ningún error, ¡y ya puede hacer raspado web de datos en Ruby!
Paso 3: Utilizar HTTParty para obtener la página de destino
Para analizar el documento HTML de la página de destino, primero es necesario descargarlo a través de una petición HTTP GET. Ruby viene con un cliente HTTP integrado llamado Net::HTTP, pero su sintaxis es un poco engorrosa y poco intuitiva. En cambio, conviene utilizar HTTParty, que es la biblioteca más popular de Ruby para realizar peticiones HTTP.
Instálela a través de la gema httparty con:
gem install httparty
Then, import it in the scraper.rb file:
require "httparty"
Use HTTParty to connect to the target page with:
response = HTTParty.get("https://brightdata.com/")El método get() permite realizar una petición GET a la URL pasada como parámetro. El campo response.body contendrá el documento HTML devuelto por el servidor.
Tenga en cuenta que la petición HTTP realizada mediante get() puede fallar. Cuando esto ocurra, HTTParty lanzará una excepción y detendrá la ejecución del script con un error. Puede haber numerosas razones detrás de un fallo, pero lo que suele ocurrir es que una tecnología antibot adoptada por el sitio objetivo interceptó y bloqueó las peticiones automatizadas. Los sistemas antiraspado web más básicos tienden a filtrar las peticiones sin una cabecera HTTP User-Agent válida. Consulte nuestro artículo sobre User-Agents para el raspado web.
Como cualquier otro cliente HTTP, HTTParty utiliza un User-Agent marcador de posición. Este es generalmente muy diferente de los agentes utilizados por los navegadores populares, haciendo sus peticiones fácilmente detectables por las soluciones antibot. Para evitar que le bloqueen por ello, es posible especificar un User-Agent válido en HTTParty de la siguiente manera:
response = HTTParty.get("https://brightdata.com/", {
headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"},
})La petición realizada a través de ese get() aparecerá ahora ante el servidor como procedente de Google Chrome 112.
Esto es lo que contiene actualmente scraper.rb:
require "nokogiri"
require "httparty"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# scraping logic...Paso 4: Analizar el documento HTML con Nokogiri
Para analizar el documento HTML asociado a la página web de destino, pasa su contenido a la función HTML() de Nokogiri:
doc = Nokogiri::HTML(response.body)Ahora se puede utilizar la API de manipulación y exploración del DOM que se ofrece a través de la variable doc. En concreto, los dos métodos más importantes para seleccionar elementos HTML son:
- xpath(): Devuelve la lista de nodos HTML que coinciden con la consulta XPath
- css(): Devuelve la lista de nodos HTML que coinciden con el selector CSS pasado como parámetro.
Ambos métodos funcionan, pero las consultas CSS suelen ser la forma más sencilla de expresar lo que se busca.
Paso 5: Definir los selectores CSS para los elementos HTML de interés
Para saber cómo seleccionar los elementos HTML deseados en la página de destino, es necesario analizar el DOM. Visite la página principal de Bright Data en su navegador, haga clic con el botón derecho en una de las fichas de interés y seleccione “Inspeccionar“:
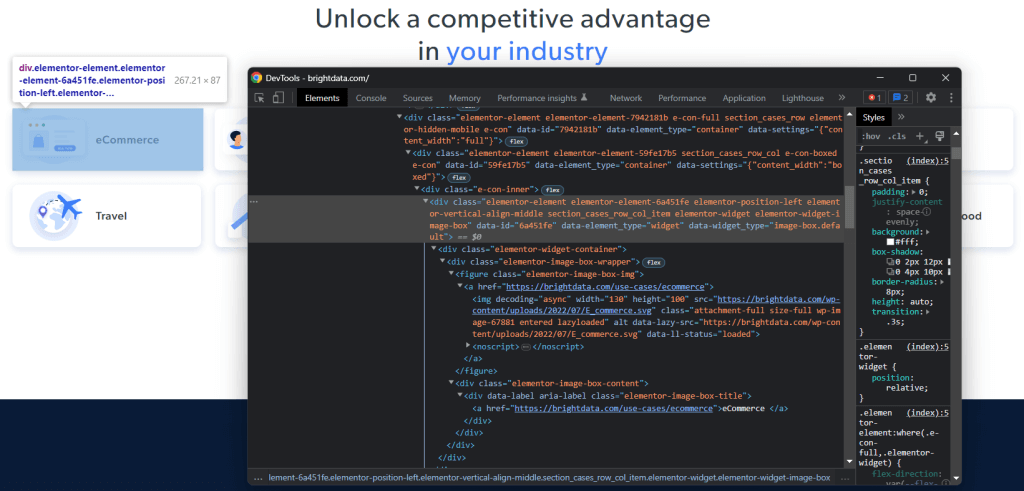
Tómese su tiempo para explorar el código HTML en la sección DevTools. Cada tarjeta de caso de uso es un
- Un <figure> que tiene un elemento <img> HTML que muestra la imagen asociada a la industria y un elemento que contiene el URL a la página de la industria.
- Un elemento HTML <div> que almacena el nombre de la industria en una etiqueta <a>.
El objetivo de extracción de datos del raspador Ruby es obtener la imagen URL, la URL de la página y el nombre del sector de cada tarjeta.
Para definir buenos selectores CSS, dirija su atención a las clases CSS asignadas a los nodos DOM de interés. Notará que puede obtener todas las tarjetas de casos de uso con el selector CSS que sigue:
.section_cases_row_col_itemTeniendo una tarjeta, se pueden seleccionar los nodos que almacenan los datos relevantes de sus hijos <figure> y <div> con:
- figure img
- figure a
- .elementor-image-box-content a
Paso 6: Extraer datos de una página web con Nokogiri
A continuación, hay que utilizar Nokogiri para recuperar los datos deseados de la página web HTML de destino.
Antes de entrar en la lógica de raspado de datos, no hay que olvidar que se necesitan algunas estructuras de datos donde almacenar los datos recopilados. Para ello, puedes definir una clase UseCase en una sola línea con un Struct:
UseCase = Struct.new(:image, :url, :name)En Ruby, un struct hace posible agrupar uno o más atributos en la misma clase de datos. La anterior tiene los tres atributos correspondientes a la información a recuperar de cada tarjeta de caso de uso.
Inicializa un array vacío de UseCase e implementa la lógica de raspado para rellenarlo:
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
endEl fragmento anterior selecciona todas las tarjetas de casos de uso e itera sobre ellas. A continuación, extrae de cada tarjeta la URL de la imagen, la URL de la página del sector y el nombre con at_css(). Se trata de una función Nokogiri que devuelve el primer elemento que se ajusta a la consulta CSS y representa un acceso directo para:
image = use_case_card.css("figure img").first.attribute("data-lazy-src").valuePor último, utiliza los datos recuperados para instanciar un nuevo objeto UseCase y lo añade a la lista.
El raspado web utilizando Ruby con Nokogiri es bastante sencillo. Con attribute(), puede seleccionar un atributo del elemento HTML actual. A continuación, el campo value permite obtener su valor. Del mismo modo, el campo text devuelve directamente todo el texto contenido en el nodo HTML actual como una cadena sin formato.
Ahora, se podría ir más lejos y raspar las páginas de la industria de casos de uso también. Se podrían seguir los enlaces descubiertos aquí e implementar una nueva lógica de raspado adaptada a ellos. Le damos la bienvenida al mundo del rastreo y raspado web.
¡Fantástico! Ahora sabe cómo alcanzar sus objetivos de raspado web con Ruby. Aunque todavía quedan algunas lecciones por aprender.
Paso 7: Exportar los datos obtenidos
Después del bucle each() loop, use_cases contendrá los datos raspados en objetos Ruby. Este no es el mejor formato para proporcionar datos a otros equipos. Afortunadamente, Ruby incorpora funciones de conversión a CSV y JSON. A continuación se explica cómo exportar los datos recuperados a CSV y JSON.
Para exportar a CSV, importa la siguiente gema:
import "csv"Forma parte de la API estándar de Ruby y proporciona una interfaz completa para tratar con archivos y datos CSV.
Se puede aprovechar para exportar la matriz use_cases a un archivo output.csv como se indica a continuación:
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
endEl fragmento anterior crea el archivo output.csv. A continuación, lo abre y lo inicializa con el registro de cabecera. Después, itera sobre la matriz use_cases y la añade al archivo CSV. Al utilizar el operador << , Ruby convertirá automáticamente cada instancia use_case en una matriz de cadenas, tal y como requiere la clase CSV incorporada.
Intente ejecutar el script con:
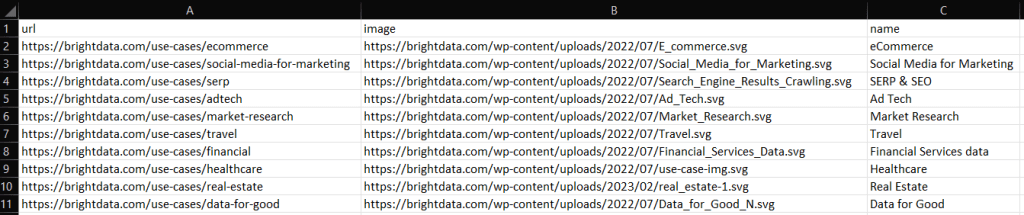
ruby scraper.rbSe producirá un archivo output.csv conteniendo los datos de abajo en el directorio raíz del proyecto:
Del mismo modo, es posible exportar use_cases a output.json:
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endEsto generará el siguiente archivo JSON:
[
{
"image": "https://brightdata.com/use-cases/ecommerce",
"url": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "eCommerce "
},
// ...
{
"image": "https://brightdata.com/use-cases/data-for-good",
"url": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
]¡Et voilà! Así es como se puede convertir un array de structs a CSV y JSON en Ruby.
Paso 8: Ponerlo todo junto
Aquí está el código completo del raspador Ruby:
# scraper.rb
require "nokogiri"
require "httparty"
require "csv"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# parse the HTML document retrieved with the GET request
doc = Nokogiri::HTML(response.body)
# define a class where to keep the scraped data
UseCase = Struct.new(:image, :url, :name)
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endEn unas 50 líneas de código, puede crear un script de raspado de datos en Ruby.
Conclusión
En este tutorial, ha descubierto por qué Ruby es un gran lenguaje para el raspado de datos en Internet. También tuvo la oportunidad de ver cuáles son las mejores bibliotecas de gemas Ruby para el raspado web, por qué y qué características ofrecen. Se ha empapado ya de información sobre cómo utilizar Nokogiri y la API estándar de Ruby para construir un raspador Ruby que puede raspar un objetivo del mundo real. Como hemos visto, el raspado de datos con Ruby requiere muy pocas líneas de código.
Sin embargo, no debemos subestimar los desafíos existentes cuando se trata de extraer datos de páginas web. Por eso, cada vez más sitios han implementado sistemas antibot y antiraspado para proteger sus datos. Estas tecnologías son capaces de detectar las peticiones realizadas por el script de raspado Ruby e impedir el acceso al sitio. Afortunadamente, es posible construir un raspador web que pueda eludir esos bloqueos con el IDE para raspado web de próxima generación de Bright Data.
¿No quiere ocuparse del raspado web en absoluto pero le interesan los datos web? Explore nuestros conjuntos de datos listos para usar.






