

En los proyectos de datos modernos, el mapeo de datos alinea campos y registros entre sistemas para que la información conserve su significado cuando se mueve entre bases de datos y aplicaciones. Antes manual y frágil, ahora se beneficia de la IA. En esta guía, exploraremos cómo la IA transforma el mapeo de datos, las técnicas clave que lo sustentan y cómo convertir datos web públicos en conjuntos de datos listos para el análisis.
¿Qué es el mapeo de datos y por qué supone un reto?
El mapeo de datos simplemente indica a los sistemas cómo se corresponden los campos de datos. Por ejemplo, el correo electrónico de un cliente en una base de datos se corresponde con la dirección de correo electrónico en otra. Sin un mapeo adecuado, los datos transferidos entre sistemas pueden perder contexto o provocar duplicados. El mapeo es esencial para la integración, la migración y el análisis: ayuda a garantizar que cuando se trasladan datos a una nueva herramienta o almacén, cada valor termina en el lugar correcto.
Sin embargo, el mapeo tradicional es lento y propenso a errores. En las grandes empresas, los datos viven en cientos de fuentes y formatos diferentes. A menudo, los equipos tienen que escribir secuencias de comandos personalizadas o utilizar complejas herramientas ETL, cotejando manualmente cada campo. Este método no es escalable: los proyectos pueden durar meses y los errores humanos son frecuentes.
El reto es aún mayor cuando se trabaja con datos web: las páginas HTML no estructuradas, los nombres incoherentes de los campos y el formato desordenado crean una complejidad adicional. Los datos de origen de mala calidad conducen a resultados de mapeo deficientes, independientemente de lo avanzadas que sean sus herramientas de IA.
Cómo la IA transforma el mapeo de datos
El mapeo de datos impulsado por IA utiliza el aprendizaje automático y el procesamiento del lenguaje natural para analizar los esquemas de origen y destino, interpretar los nombres de los campos y el contexto, y aprender de mapeos anteriores para proponer coincidencias precisas en lugar de requerir la codificación manual de los campos.
La IA reconoce que cust_ID, customerID y customer_id representan el mismo concepto. Las plataformas detectan indicios de tipos de datos y sugieren campos de destino en consecuencia, reduciendo las tareas de asignación de horas a minutos.
Estas son las principales ventajas de la asignación de datos mediante IA:
- Velocidad y eficiencia. La automatización se encarga de la configuración repetitiva del mapeo y la transformación, reduciendo el esfuerzo manual.
- Precisión y aprendizaje. Los sistemas aprenden de sus elecciones de aceptación/rechazo, mejorando las sugerencias con el tiempo.
- Escalabilidad. El mapeo de IA gestiona conjuntos de datos grandes y complejos. A medida que aumentan el volumen y la variedad de los datos, las herramientas modernas pueden analizar simultáneamente múltiples esquemas y fuentes.
- Adaptabilidad. A diferencia de las secuencias de comandos estáticas, la cartografía de IA se adapta a los cambios. Cuando aparecen nuevos campos o formatos, la IA infiere las relaciones a partir del contexto o de los comentarios de los usuarios. El sistema aprende los patrones de datos de su organización, por lo que requiere menos correcciones humanas a lo largo del tiempo.
- Mejor calidad y gobernanza de los datos. La asignación automatizada ayuda a reforzar la coherencia y la gobernanza. Al documentar cómo se alinean los campos, las herramientas de IA mantienen el linaje de los datos y apoyan el cumplimiento mediante el seguimiento del enrutamiento de datos confidenciales.
- Reducción de costes. Estas ventajas reducen los costes gracias a una menor mano de obra, menos errores que requieran repetición y una finalización más rápida del proyecto.
Tecnologías detrás del mapeo de datos con IA
Varias técnicas de IA impulsan el mapeo de datos moderno:
- Procesamiento del lenguaje natural (PLN). El PLN interpreta el significado de los nombres y etiquetas de los campos (por ejemplo, dirección de correo electrónico frente a correo electrónico) y puede procesar la documentación para extraer el contexto, lo que hace que el mapeo sea más sólido incluso cuando los nombres difieren mucho.
- Modelos de aprendizaje automático. Los modelos de aprendizaje automático clasifican y predicen las correspondencias basándose en patrones aprendidos. Cada correspondencia anterior alimenta el modelo: si muchos conjuntos de datos muestran que account_manager corresponde a sales_rep en un sistema de facturación, el modelo dará prioridad a esa sugerencia la próxima vez, mejorando las recomendaciones a lo largo del tiempo con un humano en el bucle.
- Gráficos de conocimiento. Algunas plataformas mantienen gráficos de conocimiento internos que vinculan entidades y relaciones entre sistemas. Un gráfico puede representar que un ID de cliente en un sistema es el mismo que un número de cuenta en otro, y que ambos se relacionan con una referencia de facturación, lo que ayuda a inferir asignaciones indirectas y mantener la coherencia de los esquemas.
- Aprendizaje profundo y visión por ordenador. Para documentos no estructurados o semiestructurados (por ejemplo, PDF, formularios escaneados), el aprendizaje profundo puede extraer texto, tablas y pares clave-valor para que pueda asignarlos a objetivos estructurados.
- Correspondencia semántica y alineación de esquemas. Las herramientas modernas integran algoritmos de correspondencia de esquemas (incluida la alineación de gráficos/ontología) que combinan pruebas léxicas, estructurales y basadas en instancias, además de diccionarios de dominio cuando están disponibles, para encontrar correspondencias.
Cómo funciona el mapeo de datos de IA (paso a paso)
Las herramientas de mapeo de datos de IA siguen el siguiente flujo de trabajo:
- Conectar las fuentes de datos. La herramienta se conecta a los sistemas de origen y destino (bases de datos, archivos, API), inspecciona los nombres de los campos, los tipos de datos, los valores de muestra y los metadatos, y utiliza la PNL para leer las etiquetas/descripciones de modo que comprenda el contexto antes de proponer correspondencias.
- Analiza y propone coincidencias. Aplica el mapeo automático por nombre/posición y similitud semántica para generar pares candidatos, a menudo con puntuaciones de confianza. Por ejemplo, puede relacionar código_país con CountryID. Si detecta una discrepancia de tipo (texto como “Ctd.: 12” frente a un objetivo numérico), propondrá una transformación parse/cast antes del mapeo final.
- Revisar y refinar. Las coincidencias de alta confianza pueden aceptarse automáticamente, mientras que las ambiguas se marcan para que las revise el administrador. Las acciones de aceptación/rechazo se registran para su auditoría y se utilizan para mejorar futuras sugerencias.
- La IA aprende de los comentarios. El sistema interioriza sus elecciones (su memoria institucional), de modo que los conjuntos de datos similares se asignan más rápidamente la próxima vez y las recomendaciones se alinean con sus convenciones y políticas de nomenclatura.
- Despliegue de transformaciones. Una vez aprobadas las correspondencias, la plataforma genera y pone en funcionamiento las transformaciones necesarias (transformaciones, concatenaciones, estandarizaciones) y las ejecuta dentro de procesos ETL/ELT gestionados con programación, supervisión y captura de linaje.
Obtención de datos de la Web listos para la asignación
Antes de que la IA pueda mapear eficazmente sus datos, necesita entradas limpias y estructuradas. Los datos de la Web suelen venir desordenados: formato incoherente, HTML anidado, estructuras de página cambiantes. Aquí es donde la recopilación adecuada de datos web es crucial para el éxito de los proyectos de mapeo.
Bright Data proporciona una plataforma para extraer y preparar datos web para la IA, de modo que el mapeo comience a partir de entradas más limpias:
- AI Web Scraper. Identifica la estructura de la página y extrae datos estructurados de sitios modernos; entrega JSON/CSV a través de API o webhooks.
- Conjuntos de datos (preconstruidos). Conjuntos de datos listos y actualizados con esquemas documentados (por ejemplo, productos de Amazon), para que los nombres y tipos de campo sean coherentes desde el principio.
- Proxy y Web Unlocker. Acceso fiable a sitios web públicos mediante la gestión de bloqueos y CAPTCHA, para que pueda recopilar los datos antes de asignarlos, incluso en sitios difíciles.
- API del navegador y funciones sin servidor. Ejecute flujos de trabajo de scraping programables y alojados para la recopilación en varios pasos antes del mapeo.
- Integraciones. Conecte los resultados del scraping o del conjunto de datos a marcos de aplicaciones de IA (por ejemplo, LangChain, LlamaIndex) o a sus objetivos de almacenamiento.
Al encargarse de la recopilación y la estructuración inicial, Bright Data le permite centrarse en el mapeo y la transformación.
Ejemplo sencillo: asignación de un conjunto de datos de productos de Amazon
Veamos un ejemplo práctico con datos de productos de Amazon. En lugar de raspar manualmente páginas de productos desordenadas, utilizaremos el conjunto de datos de productos de Amazon de Bright Data, que proporciona registros limpios y estructurados perfectos para el mapeo de IA.
El conjunto de datos incluye campos como title, brand, initial_price, currency y availability. Un registro de muestra tiene el siguiente aspecto:
{
"title": "Hanes Girls' Cami Tops, Camisolas 100% algodón...",
"brand": "Hanes Girls 7-16 Underwear",
"initial_price": 10.00,
"currency": "USD",
"availability": true
}Supongamos que nuestro esquema de análisis de destino necesita ProductName, Brand, PriceUSD y InStock. La herramienta de mapeo de IA propondría estas transformaciones:
- title → ProductName (coincidencia semántica de alta confianza)
- brand → Marca (coincidencia exacta del nombre)
- precio_inicial + divisa → PrecioUSD (combinar campos, normalizar a USD)
- disponibilidad → InStock (conversión booleana).
Tras el mapeo y la transformación:
{
"ProductName": "Hanes Girls' Cami Tops, ...",
"Brand": "Hanes Girls 7-16 Underwear",
"PriceUSD": 10.00,
"InStock": true
}La herramienta de mapeo de IA propuso automáticamente la mayoría de las alineaciones porque los datos de origen estaban limpios y tenían un formato coherente.
Para requisitos personalizados, puede utilizar AI Web Scraper para extraer campos específicos de Amazon en su formato preferido y, a continuación, asignarlos a su esquema de destino.
Nota – Mantenga a los humanos en el bucle. El mapeo de IA funciona mejor como asistente inteligente, no como sustituto de la experiencia en datos. Valide siempre las asignaciones críticas, especialmente para los campos sensibles o el cumplimiento normativo.
Mapeo avanzado con consultas en lenguaje natural
A veces es necesario investigar y mapear datos que no existen en formatos predefinidos. Deep Lookup de Bright Data le permite generar conjuntos de datos personalizados mediante consultas en lenguaje natural y, a continuación, asignar los resultados a su esquema de destino. Por ejemplo:
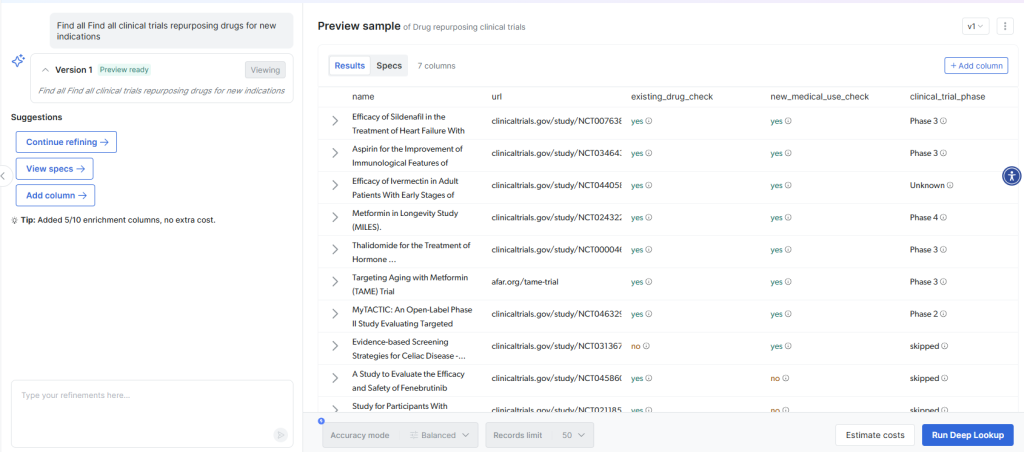
Deep Lookup explora los datos de la web para encontrar empresas coincidentes y devuelve resultados estructurados listos para la asignación:

Esto elimina el flujo de trabajo tradicional de investigar, estructurar y luego mapear, ya que proporciona datos listos para mapear directamente a partir de consultas en lenguaje natural.
Conclusión
El mapeo de datos de IA está transformando la forma en que las organizaciones integran los datos web públicos en los flujos de trabajo de análisis e IA. El éxito comienza antes del mapeo: los datos de origen de alta calidad y bien estructurados mejoran la precisión del mapeo y reducen la intervención manual.
Las soluciones de Bright Data se encargan de la recopilación y la estructuración, para que usted pueda centrarse en la asignación de datos web a sus necesidades empresariales y marcos analíticos específicos.
¿Está listo para ver el impacto de los datos web limpios en sus proyectos de mapeo? Póngase en contacto con nosotros para obtener rápidamente conjuntos de datos estructurados y listos para la cartografía.





