

En este artículo aprenderás:
- Qué es Microsoft TaskWeaver y qué lo hace único.
- Por qué ampliar TaskWeaver con los servicios de Bright Data le permite superar las limitaciones de LLM.
- Cómo integrar Bright Data en TaskWeaver a través de un complemento personalizado.
¡Empecemos!
¿Qué es Microsoft TaskWeaver?
Microsoft TaskWeaver es un marco de trabajo de código abierto y centrado en el código que transforma las solicitudes en lenguaje natural en código Python ejecutable. Su objetivo final es impulsar agentes de IA que planifiquen y ejecuten tareas complejas de forma independiente.
Esta tecnología funciona tomando su indicación y desglosándola en pasos ejecutables. A continuación, selecciona los complementos adecuados para lograr el objetivo, genera código Python para ejecutar el plan, ejecuta el código en un entorno seguro y devuelve los resultados.
TaskWeaver es de código abierto y ha obtenido más de 6000 estrellas en GitHub. Algunas de las características principales que lo diferencian son:
- Enfoque basado en el código: convierte las solicitudes de los usuarios en código Python, lo que permite a los agentes generar y ejecutar soluciones directamente.
- Ecosistema de complementos: admite tareas especializadas a través de complementos, lo que hace que el marco sea altamente extensible.
- Gestión de datos enriquecida: funciona de forma nativa con estructuras de datos de Python como DataFrames, lo que abre la puerta al análisis avanzado de datos.
- Adaptación de dominio: integra conocimientos específicos del dominio para obtener resultados más precisos.
- Ejecución con estado y reflexiva: mantiene el contexto y puede reflexionar sobre su propia ejecución de código para autocorregirse.
- Seguro y abierto: ejecuta el código en un entorno seguro y ofrece una experiencia de código abierto lista para usar.
Más información en la documentación oficial.
Por qué añadir capacidades de recuperación de datos web a TaskWeaver
Los LLM están intrínsecamente limitados por los datos con los que se han entrenado. Aunque pueden generar texto, código o multimedia, el resultado siempre se basa en sus conocimientos obsoletos. Además, no pueden interactuar con páginas web en tiempo real como lo haría un usuario humano. Estas dos son las principales limitaciones de los modelos actuales de IA.
TaskWeaver supera esas limitaciones al permitir que los agentes se integren con complementos personalizados. Puede pensar en los complementos como herramientas especializadas que el LLM puede utilizar para realizar tareas más allá de sus capacidades integradas, ampliando eficazmente su alcance y utilidad práctica.
Al llamar a estos complementos, el código generado por un agente de TaskWeaver puede interactuar con entornos externos y realizar operaciones complejas. Por ejemplo, Bright Data ofrece una gama de potentes herramientas:
- API Web Unlocker: raspa cualquier sitio web en una sola solicitud y recibe HTML o Markdown limpios, con gestión automatizada de Proxies, desbloqueo, encabezados y CAPTCHAs.
- API SERP: recopile resultados de motores de búsqueda de Google, Bing y otros a gran escala, sin preocuparse por los bloqueos.
- API de Scraping web: recopile datos estructurados y analizados de sitios conocidos como Amazon, Instagram, LinkedIn, Yahoo Finance y muchos más.
- Y otras soluciones de Bright Data…
Con acceso a complementos que se conectan a dichos servicios, un agente de TaskWeaver podría buscar en la web, extraer contenido y recuperar datos estructurados en tiempo real de dominios populares. Eso permite a la IA manejar flujos de trabajo complejos y listos para la empresa que van mucho más allá de lo que un LLM estándar podría lograr por sí solo.
Cómo integrar Bright Data en TaskWeaver a través de un complemento personalizado
En esta sección del tutorial, aprenderá a integrar un agente TaskWeaver con Bright Data para la recuperación de datos web.
En concreto, verá cómo ampliar una aplicación TaskWeaver con una herramienta personalizada que se conecta a la API Bright Data Web Unlocker. Esto permite a su agente «code-first» obtener datos de cualquier página web en Internet y procesarlos según sus necesidades.
Nota: Para un enfoque similar, consulta nuestra guía de integración con smoleagents, otro agente de IA basado en código.
¡Siga atentamente las instrucciones que se indican a continuación!
Requisitos
Para seguir este tutorial, necesita:
- Python 3.10 o superior instalado localmente: necesario para ejecutar TaskWeaver y sus complementos.
- Git instalado localmente: necesario para clonar el repositorio de TaskWeaver desde GitHub.
- El demonio Docker en ejecución: debe estar en ejecución para evitar errores con la función de verificación de código (que es opcional).
- Una clave API de OpenAI (o la clave API de cualquier otro LLM compatible).
Para trabajar con Bright Data, también necesitará:
- Una cuenta de Bright Data con una clave API.
- Una zona Web Unlocker configurada en su cuenta.
No te preocupes por configurar Bright Data todavía, ya que eso se tratará en un paso específico.
Paso n.º 1: Crear un proyecto Microsoft TaskWeaver
Comience creando una carpeta de proyecto para su proyecto TaskWeaver y navegue hasta ella en la terminal:
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-exampleDentro de la carpeta del proyecto, cree un entorno virtual:
python -m venv .venvA continuación, actívelo. En Linux/macOS, ejecute este comando:
source .venv/bin/activateO, alternativamente, en Windows, ejecute:
.venvScriptsactivateAhora, instala TaskWeaver mediante los siguientes comandos:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txtEsto clonará TaskWeaver/ en la carpeta de su proyecto e instalará todas las dependencias en el entorno virtual que acaba de crear a través de pip.
TaskWeaver se ejecuta como un proceso y requiere un directorio de proyecto para almacenar complementos, archivos de configuración y datos de sesión. El repositorio que acaba de clonar proporciona un proyecto de muestra en el directorio TaskWeaver/project/: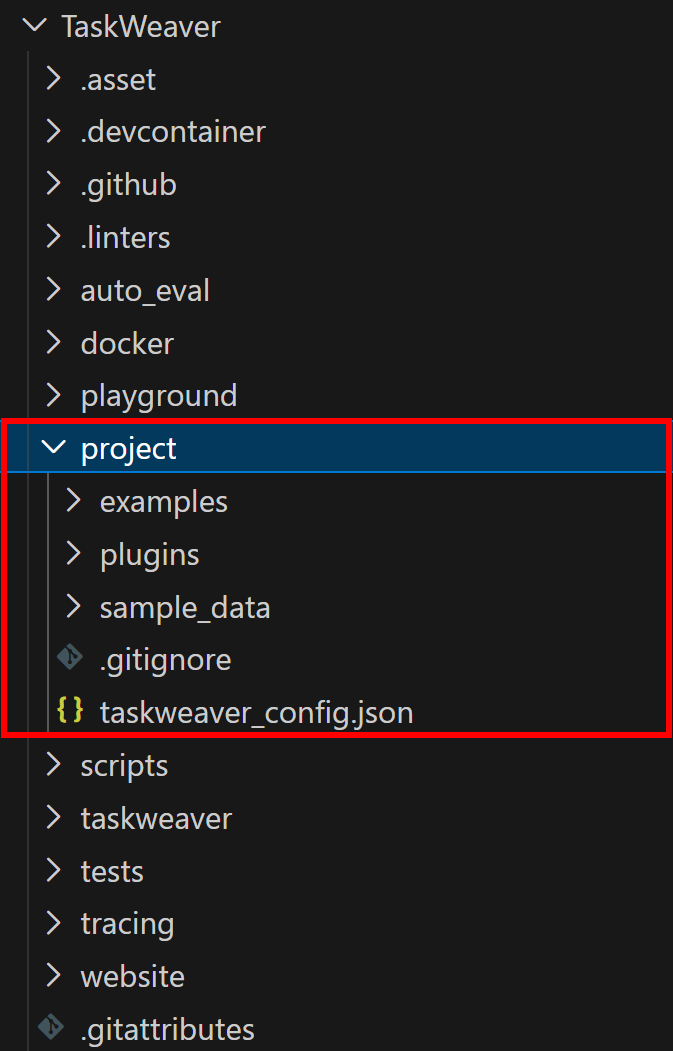
Copie el contenido de la carpeta del proyecto en su espacio de trabajo. Después de esto, su carpeta taskweaver-bright-data-example/ debería tener este aspecto:
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # Carpeta para almacenar sus complementos
├─ examples/
│ ├─ planner_examples/ # Scripts de ejemplo del planificador
│ └─ code_generator_examples/ # Scripts de ejemplo del generador de código
├─ sample_data/ # Conjuntos de datos de ejemplo opcionales
├─ .gitignore
└─ taskweaver_config.json # Archivo de configuración del proyectoEn concreto, un directorio típico de proyecto de Microsoft TaskWeaver contiene carpetas y archivos específicos, tal y como se describe en la documentación oficial.
Cargue taskweaver-bright-data-example/ en su IDE de Python favorito, como Visual Studio Code o PyCharm.
Con su entorno virtual activo, inicie la aplicación mientras se encuentra dentro de la carpeta /TaskWeaver con:
python -m taskweaverEsto iniciará el proceso TaskWeaver desde la carpeta /TaskWeaver, que cargará los archivos y el directorio del proyecto desde la carpeta taskweaver-bright-data-example/.
Si todo funciona correctamente, debería ver esto en su terminal:
¡Éxito! Microsoft TaskWeaver funciona. Después de ejecutar la aplicación por primera vez, se crearán las siguientes carpetas:
workspace/: Almacena los datos de sesión de su proyecto.logs/: Almacena los archivos de registro generados por el programa.
Nota: Si intenta introducir un comando ahora, fallará porque aún necesita configurar una conexión a un LLM. Eso se tratará en el siguiente paso.
Paso n.º 2: Configurar el LLM en TaskWeaver
TaskWeaver es compatible con una amplia gama de LLM. En este tutorial, integraremos un modelo OpenAI, pero puede adaptar fácilmente las instrucciones a cualquier otro proveedor de LLM compatible.
Para configurar el modelo GPT-4.1 mini en TaskWeaver, asegúrese de que su archivo taskweaver_config.json dentro de taskweaver-bright-data-example/ contiene lo siguiente:
{
"llm.api_key": "<YOUR_OPENAI_API_KEY>",
"llm.model": "gpt-4.1-mini"
}Reemplace <YOUR_OPENAI_API_KEY> con su clave API de OpenAI real.
Nota: En el momento de escribir este artículo, TaskWeaver no es compatible con los modelos GPT-5. Si intenta configurar un modelo GPT-5, aparecerá el siguiente error:
{'error': {'message': "Parámetro no compatible: 'max_tokens' no es compatible con este modelo. Utilice 'max_completion_tokens' en su lugar.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}¡Fantástico! Su proyecto TaskWeaver ahora funciona con el modelo mini GPT-4.1 de OpenAI y está listo para procesar indicaciones.
Paso n.º 3: Configurar una zona API de Bright Data Web Unlocker
Para conectar su agente TaskWeaver a Bright Data y poder utilizar las funciones de Scraping web, primero debe completar algunos pasos preliminares. En concreto, debe preparar su cuenta de Bright Data configurando una zona Web Unlocker.
Si aún no tiene una cuenta, cree una cuenta de Bright Data. De lo contrario, simplemente inicie sesión. Una vez en su cuenta, navegue hasta la página «Proxies y scraping». En la sección «Mis zonas», busque una fila con la etiqueta «API de Web Unlocker» en la tabla: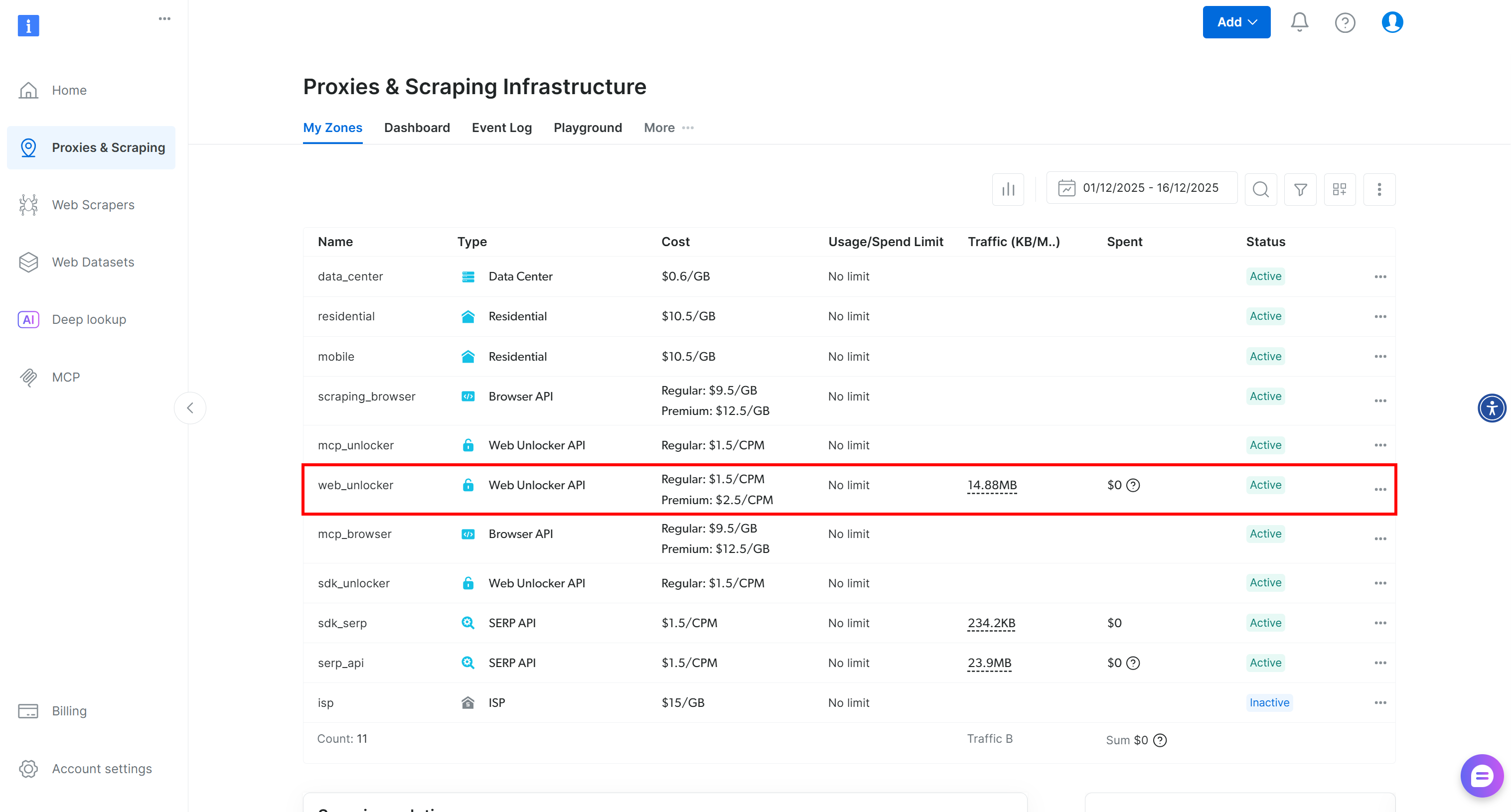
Si no ve una fila con la etiqueta «Web Unlocker API», significa que aún no se ha configurado dicha zona en su cuenta de Bright Data. Para crear una, desplácese hacia abajo hasta la sección «Unlocker API» y haga clic en «Crear zona» para añadir una: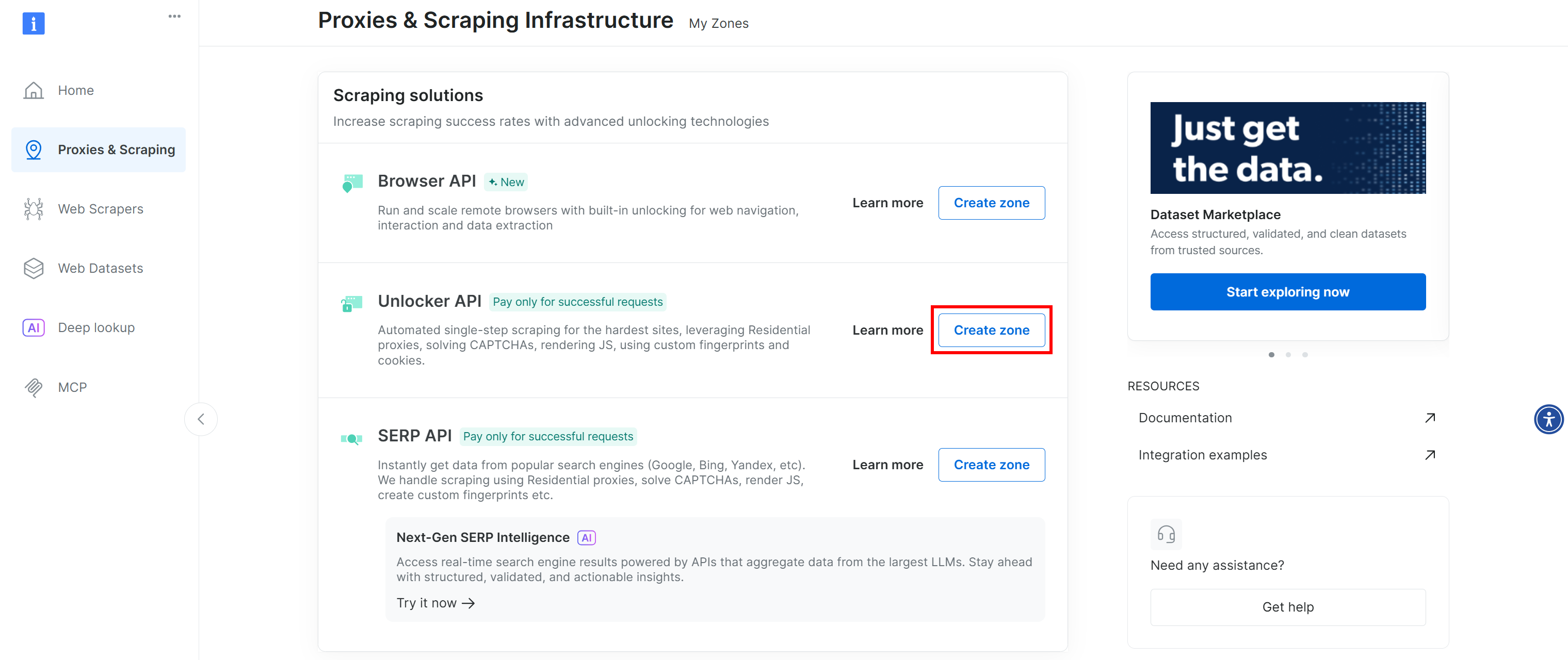
Cree una zona Web Unlocker API y asígnele un nombre, como web_unlocker (o cualquier otro nombre que prefiera). Recuerde el nombre de la zona, ya que lo necesitará para acceder al servicio a través de la API en un complemento personalizado.
En la página de la zona Web Unlocker, asegúrese de que el interruptor esté en «Activo» para confirmar que la zona está habilitada.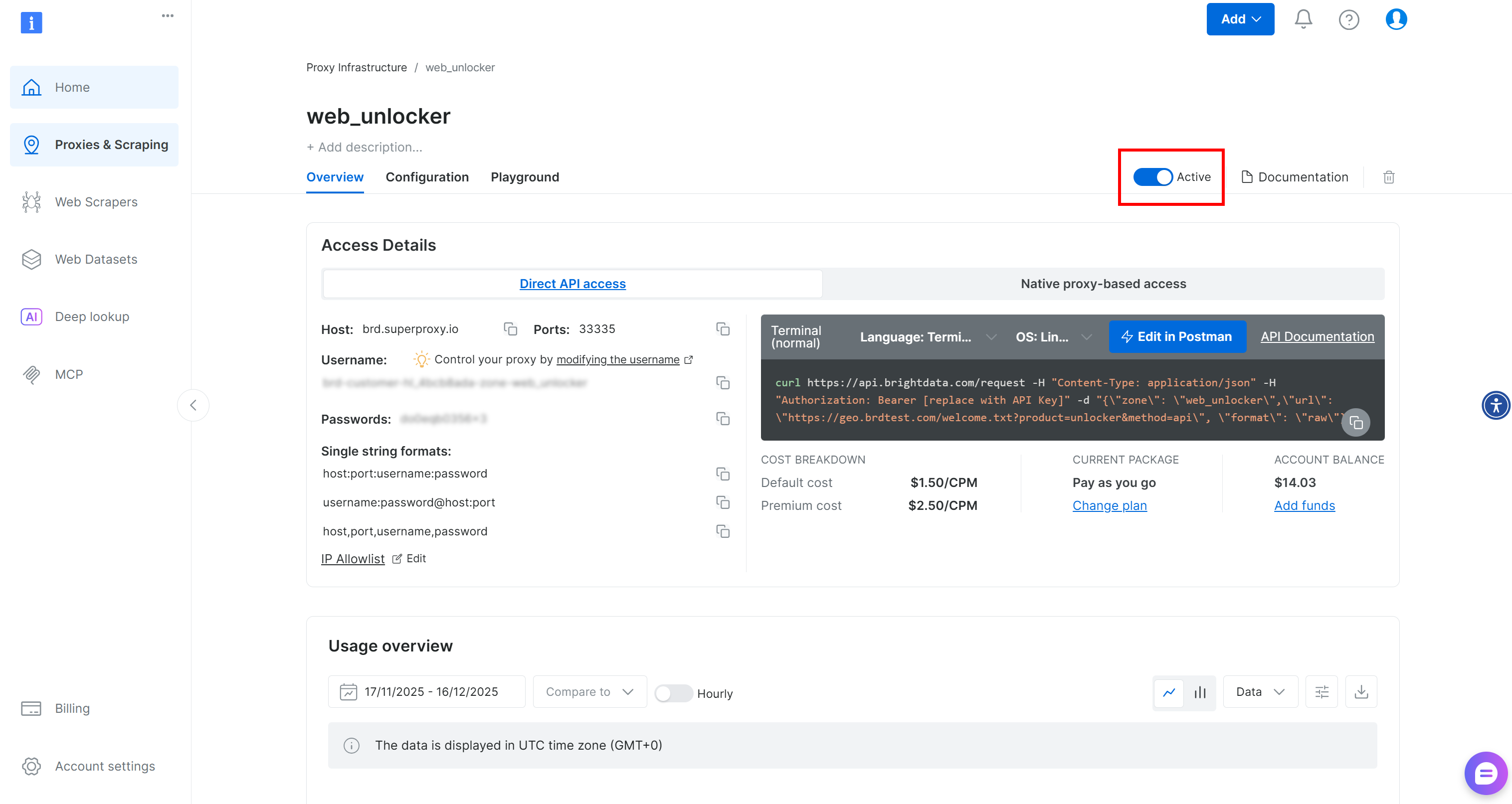
Por último, siga la guía oficial para generar su clave API de Bright Data. Guárdela en un lugar seguro, ya que la necesitará en breve.
¡Genial! Ahora ya tiene todo configurado para utilizar el complemento API Web Unlocker de Bright Data en su aplicación TaskWeaver.
Paso n.º 4: definir el complemento TaskWeaver Web Unlocker para la integración de Bright Data
Los complementos son unidades que pueden ser orquestadas por el intérprete de código de TaskWeaver. Más concretamente, cada complemento es una función de Python que puede ser llamada dentro del código generado.
En TaskWeaver, un complemento consta de dos archivos:
- Implementación del complemento: un archivo Python que define el complemento.
- Esquema del complemento: un archivo YAML que define las entradas, salidas y metadatos del complemento.
Ambos archivos deben colocarse en la subcarpeta plugins/ dentro de su proyecto.
En este caso, debe añadir un complemento que llame a la API Bright Data Web Unlocker. Para obtener más información sobre cómo llamar a ese punto final de la API, consulte la documentación oficial.
En su entorno virtual activo, primero instale un cliente HTTP de Python como Requests:
pip install requestsA continuación, añada un archivo de complemento web_unlocker.py dentro de la carpeta plugins/. Defínalo de la siguiente manera:
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# Leer los valores de configuración para la llamada a la API
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# Encabezados HTTP requeridos por la API de Bright Data para la autenticación
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# Carga útil de la solicitud enviada a Bright Data Web Unlocker
payload = {
"zone": zona,
"url": url,
"format": "raw", # Para obtener la respuesta directamente en el cuerpo
"data_format": data_format o default_format
}
# Enviar la solicitud a la API de Bright Data Web Unlocker
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
# Generar una excepción para respuestas HTTP que no sean 2xx
response.raise_for_status()
# Extrae el contenido de la respuesta y el código de estado HTTP.
content = response.text
status = response.status_code
# Resumen en lenguaje natural devuelto al LLM.
description = (
f"Página obtenida correctamente utilizando Bright Data Web Unlocker "
f"(HTTP {status}, {len(content)} caracteres)."
)
# Persistir la página obtenida como un artefacto en el espacio de trabajo de la sesión.
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content
)
# Devolver tanto el contenido sin procesar como una descripción legible para los humanos.
return content, descriptionEste complemento recupera una página web a través de la API Bright Data Web Unlocker. En primer lugar, lee los valores de configuración de la sección de configuraciones YAML del complemento (que se definirá en breve) utilizando self.config.get().
A continuación, envía una solicitud HTTP, comprueba si hay errores y guarda la página obtenida como un artefacto en el espacio de trabajo mediante self.ctx.add_artifact(), lo que le permite revisar el resultado durante y después de la ejecución. Por último, devuelve tanto el contenido sin procesar de la página como un resumen legible para su uso por parte del LLM.
Nota: De forma predeterminada, la llamada a la API de Bright Data Web Unlocker se ha configurado para devolver el contenido de la página web en formato Markdown, que es ideal para la ingestión de LLM. Esta es una característica útil que proporciona la API de Web Unlocker para admitir integraciones de IA y simplificar el procesamiento de contenido.
¡Increíble! Antes de que el agente TaskWeaver pueda utilizar este complemento, también debe especificar el archivo de esquema YAML del complemento.
Paso n.º 5: continuar con la definición del esquema del complemento
El esquema del complemento especifica cómo el LLM de TaskWeaver entiende y llama al complemento. Debe estar escrito en formato YAML, así que cree un archivo llamado web_unlocker.yaml dentro de la carpeta plugins/ de la siguiente manera:
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Obtiene y desbloquea páginas web utilizando la API Bright Data Web Unlocker,
evitando las protecciones antibots y devolviendo el contenido limpio de la página.
parameters:
- name: url
tipo: str
obligatorio: true
descripción: La URL completa de la página web que se va a recuperar.
- nombre: data_format
tipo: str
obligatorio: false
descripción: Formato de salida del contenido de la página («markdown» o HTML sin formato, si se omite).
devuelve:
- nombre: content
tipo: str
descripción: El contenido desbloqueado de la página.
- nombre: descripción
tipo: str
descripción: Un resumen en lenguaje natural de la operación de obtención.
configuraciones:
api_key: <YOUR_BRIGHT_DATA_API_KEY> # Reemplazar con su clave API de Bright Data.
zona: web_unlocker # Reemplazar con el nombre de su zona de Web Unlocker.
formato_de_datos: markdownEl archivo YAML anterior describe las entradas y salidas de la función __call__() en la clase WebUnlockerPlugin definida anteriormente. Gracias a este esquema, el LLM de TaskWeaver comprenderá cómo funciona el complemento web_unlocker.py y cómo llamarlo en el código Python generado.
En la sección de configuraciones, especifique su clave API de Bright Data, el nombre de la zona de Web Unlocker y el formato de salida deseado. Reemplace los campos api_key y zone con los valores que configuró en el paso n.º 3.
¡Ya está! La integración de TaskWeaver + Bright Data ha finalizado.
Nota: Puede utilizar el mismo enfoque para integrar otros servicios de Bright Data a través de la API, como la API SERP o las API de Scraping web.
Paso n.º 6: Prueba el agente TaskWeaver
Es el momento de verificar que el agente «code-first» de TaskWeaver ahora puede llamar al complemento impulsado por Bright Data. La idea es que el código generado invoque la función del complemento y acceda a las capacidades de desbloqueo web proporcionadas por la API de Web Unlocker.
Para probarlo, prueba con un comando como este:
Obtenga el último registro de cambios de MCP de «https://modelcontextprotocol.io/specification/2025-11-25/changelog» y enumere los cambios.Esta tarea normalmente sería imposible para un LLM estándar, ya que requiere una herramienta personalizada para navegar a una URL y extraer información de ella. Sin embargo, con TaskWeaver + Bright Data, ¡el agente puede manejarlo!
Inicie la aplicación TaskWeaver con:
python -m taskweaverPegue el mensaje y pulse Intro. Debería ver algo como esto: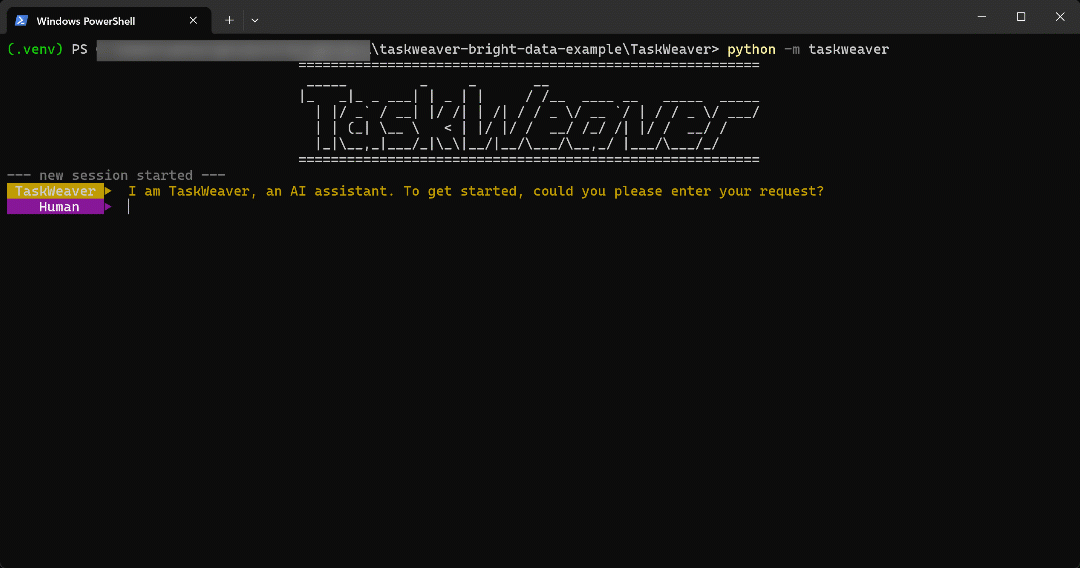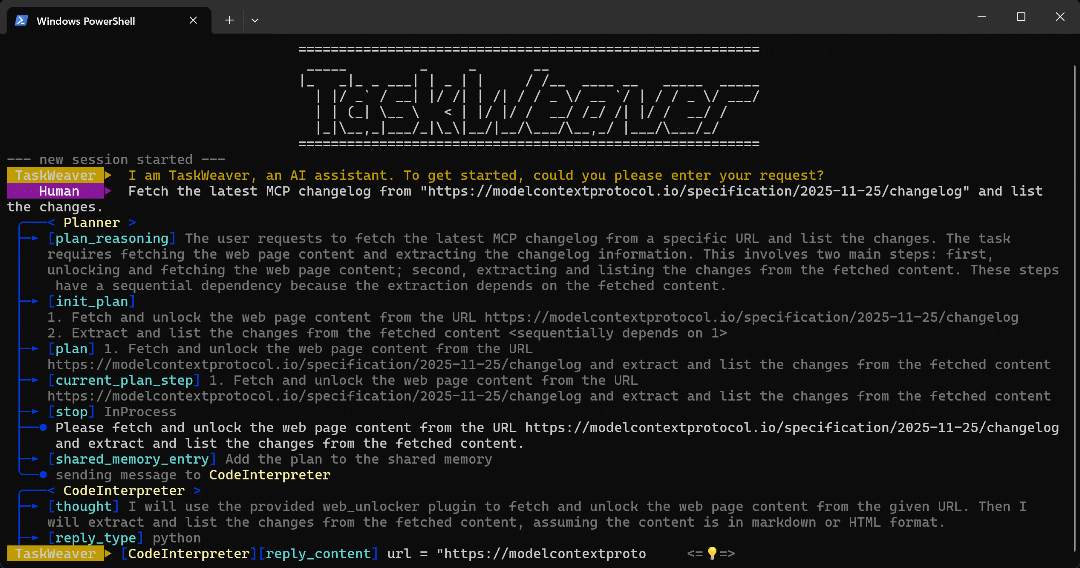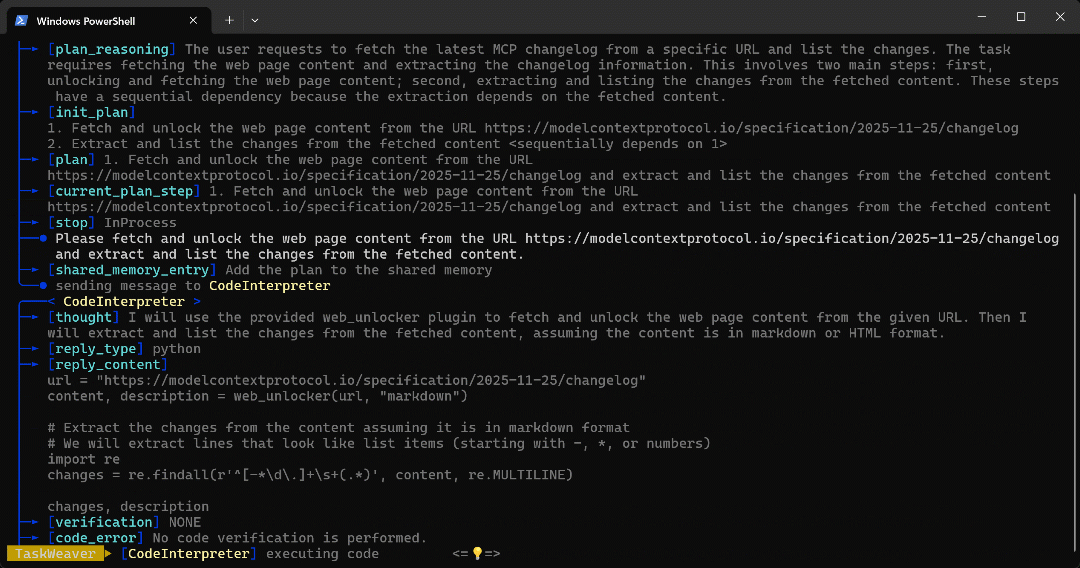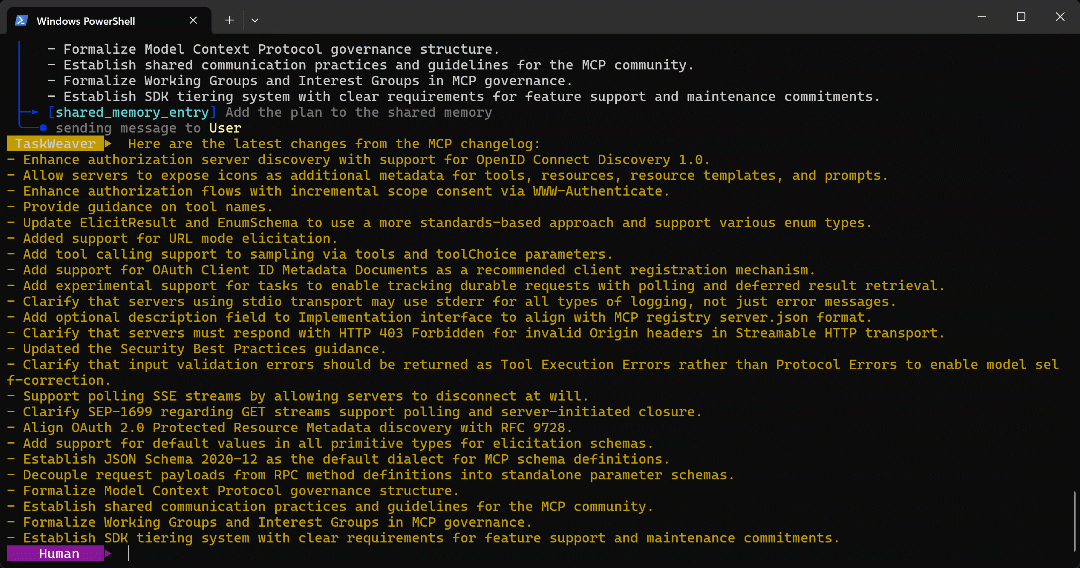
Como puede ver, el agente:
- El TaskWeaver
Plannercomienza elaborando un plan para llevar a cabo la tarea. - A continuación, el plan se envía al agente interno
CodeInterpreter, que genera código Python para alcanzar el objetivo. - El código Python llama al complemento Web Unlocker API y, a continuación, extrae todos los puntos clave del artículo utilizando una expresión regular.
- El código se ejecuta y los datos deseados se recuperan a través de la API Web Unlocker y se almacenan en la carpeta del espacio de trabajo tal y como se ha configurado con
self.ctx.add_artifact(). - Los datos Markdown devueltos, que contienen el contenido de la página especificada por la URL, se envían de vuelta al
planificador, que continúa con el siguiente paso. - La lista de viñetas extraídas de la página de destino se devuelve al usuario según lo previsto.
¡Genial! El agente TaskWeaver funciona a la perfección. Dediquemos un momento a inspeccionar el resultado obtenido.
Paso n.º 7: Explorar el resultado
El resultado final de la ejecución del agente es:
Como se puede comprobar en la página de destino, esa lista se corresponde exactamente con la información que se encuentra en el registro de cambios de MCP: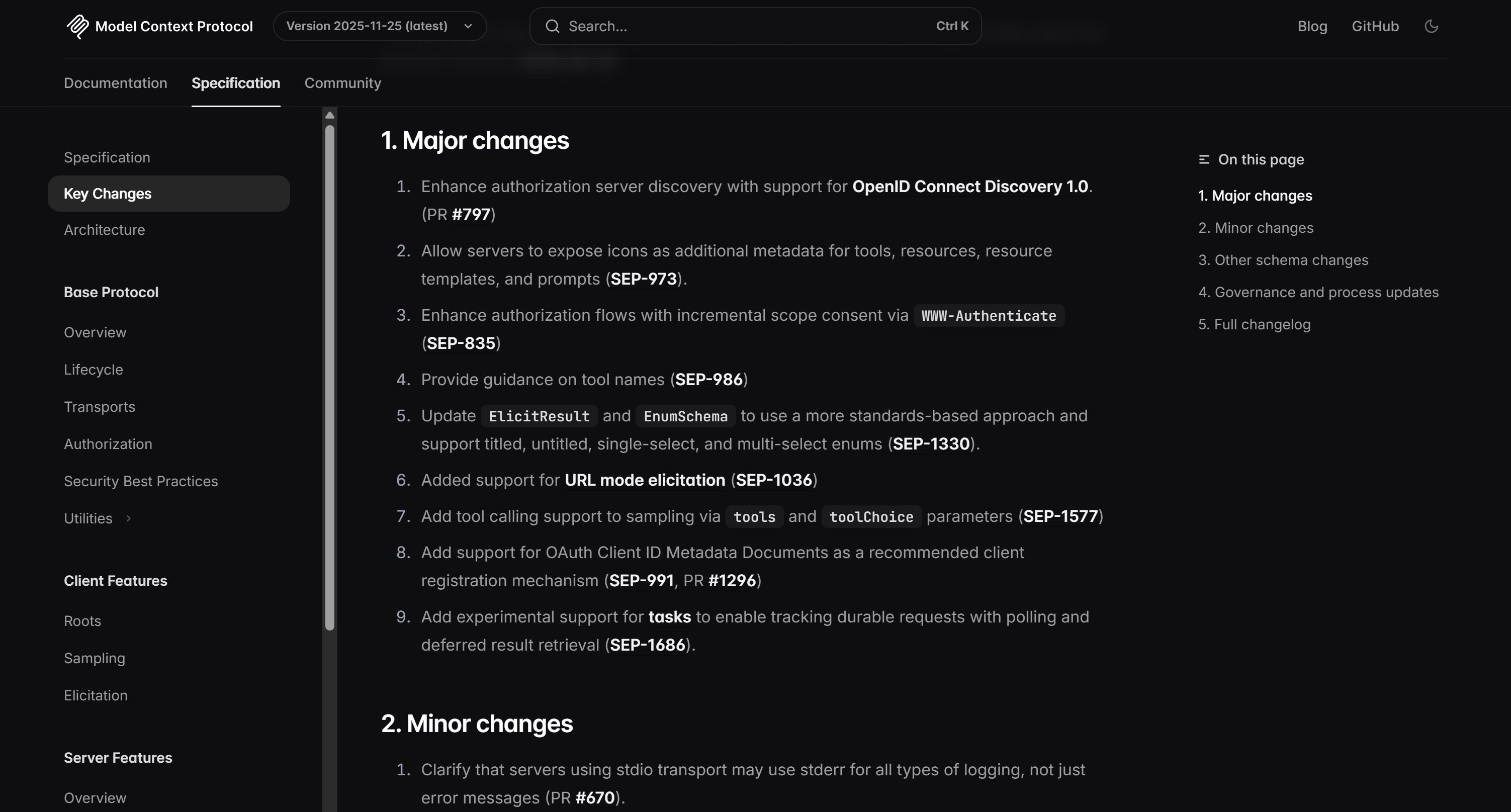
En concreto, el agente generó el resultado mediante el siguiente código Python:
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# Extraer los cambios del contenido suponiendo que está en formato Markdown.
# Extraeremos las líneas que parezcan elementos de una lista (que comiencen con -, * o números).
import re
changes = re.findall(r'^[-*d.]+s+(.*)', content, re.MULTILINE)
changes, descriptionObserve cómo el fragmento generado llama a la función plugin web_unlocker() para recuperar la página de entrada en formato Markdown. A continuación, la procesa utilizando una expresión regular simple para extraer la información relevante.
Para verificar que la API de Web Unlocker devolvió el contenido de la página en Markdown, compruebe los archivos dentro de la carpeta workspace/. Cada ejecución del agente produce una subcarpeta de sesión en workspace/sessions/, que contiene una subcarpeta para esa ejecución específica.
En la carpeta cwd/, encontrará el archivo .md creado mediante la llamada self.ctx.add_artifact(). Ábralo para ver el contenido devuelto por la API de Web Unlocker: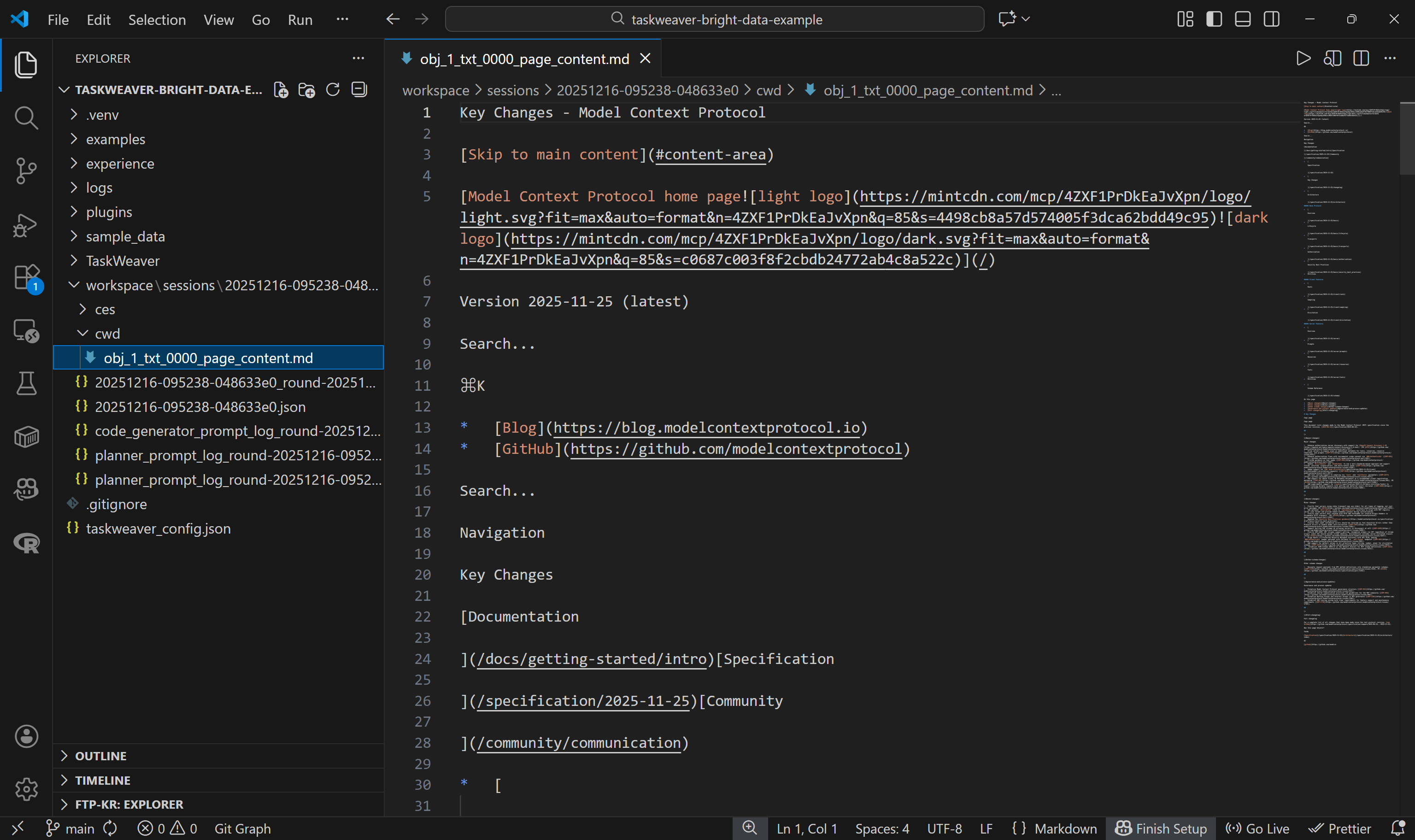
Esto coincide exactamente con la versión Markdown de la página de destino, lo que significa que la función de la API de Web Unlocker en el código Python generado funcionó perfectamente. ¡Vaya!
Ahora, lleve a su agente más allá. Experimente con diferentes indicaciones para manejar escenarios más realistas y preparados para la empresa.
¡Et voilà! Ha creado con éxito un agente de IA basado en código integrado con Bright Data utilizando TaskWeaver. Este agente puede recuperar de forma fiable datos preparados para IA desde cualquier página web.
Próximos pasos
La integración que se muestra aquí es un ejemplo básico. Para llevar su agente TaskWeaver al siguiente nivel y prepararlo para la producción, considere las siguientes mejoras:
- Integre soluciones adicionales de Bright Data, como la API SERP, para dotar al agente de la capacidad de buscar en la web y recopilar datos en tiempo real.
- Configure la interfaz de usuario web como un entorno de pruebas para simplificar el desarrollo, las pruebas y la supervisión de su agente.
- Habilite funciones avanzadas como la compresión de comandos, la selección automática de complementos yla telemetría/observabilidad para mejorar el rendimiento, la escalabilidad y la facilidad de mantenimiento.
Conclusión
En este tutorial, ha visto cómo integrar Bright Data con TaskWeaver a través de complementos personalizados que se conectan a API externas.
Esta configuración permite realizar búsquedas web en tiempo real, extraer datos estructurados, acceder a fuentes web en tiempo real y automatizar las interacciones web. Al aprovechar el conjunto completo de servicios de Bright Data para IA, podrá liberar todo el potencial de sus agentes de IA basados en código.
Crea hoy mismo una cuenta gratuita en Bright Data y hazte con nuestras soluciones de datos web preparadas para la IA.




