En esta guía descubrirá
- Qué es un agente de investigación y por qué fallan los métodos tradicionales
- Cómo configurar Bright Data para una recopilación de datos fiable
- Cómo construir un agente de investigación local impulsado por IA con Streamlit UI
- Cómo integrar las API de Bright Data con modelos locales para obtener información estructurada
Sumerjámonos en la construcción de su asistente de investigación inteligente. También le sugerimos que eche un vistazo a Deep Lookup, el motor de búsqueda impulsado por IA de Bright Data que le permite buscar en la web como en una base de datos.
El problema del sector
- Los investigadores se enfrentan a demasiada información procedente de muchas fuentes, lo que hace que la revisión manual sea poco práctica.
- La investigación tradicional implica búsquedas, extracciones y síntesis lentas y manuales.
- Los resultados suelen estar incompletos, desconectados y mal organizados.
- Las simples herramientas de scraping proporcionan datos en bruto sin credibilidad ni contexto.
Solución: Agente de investigación
Un agente de investigación profunda es un sistema de IA que automatiza la investigación desde la recopilación hasta la elaboración de informes. Maneja el contexto, gestiona las tareas y proporciona información bien estructurada.
Componentes clave:
- Agente planificador: divide la investigación en tareas
- Subagentes de investigación: realizan búsquedas y extraen datos.
- Agente redactor: elabora informes estructurados
- Agente de condiciones: comprueba la calidad y activa investigaciones más profundas si es necesario.
Esta guía muestra cómo crear un sistema de investigación local utilizando las API de Bright Data, una interfaz de usuario Streamlit y LLM locales para la privacidad y el control.
Requisitos previos
- Cuenta de Bright Data con clave API.
- Python 3.10+
- Dependencias:
solicitudesfaissochromadbpython-dotenvstreamlitollama(para modelos locales)
Configuración de Bright Data
Crear cuenta de Bright Data
- Regístrese en Bright Data
- Navegue hasta la sección de credenciales API
- Genere su token API
Almacene sus credenciales de API de forma segura utilizando variables de entorno. Cree un archivo .env para almacenar sus credenciales, manteniendo la información sensible separada de su código.
BRIGHT_DATA_API_KEY="su_bright_data_api_token_aquí"Configuración del entorno
# Crear venv
python -m venv venv
source venv/bin/activate
# Instalar dependencias
pip install peticiones openai chromadb python-dotenv streamlitImplementación
Paso 1: Investigación
Esta será nuestra tarea de investigación.
query = "Casos de uso de IA en sanidad"Paso 2: Obtención de datos
Este paso muestra cómo obtener datos de la web mediante programación utilizando la API de recopilación de datos de Bright Data. El código envía una consulta de investigación y recupera los datos relevantes mientras gestiona de forma segura las credenciales de la API.
import requests, os
from dotenv import cargar_dotenv
cargar_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": consulta, "limit": 20}
headers = {"Authorization": f "Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())Paso 3: Procesar e incrustar
Este paso procesa los datos de investigación obtenidos y los almacena en ChromaDB, una base de datos vectorial que permite la búsqueda semántica y la comparación de similitudes. De este modo, se crea una base de conocimientos con capacidad de búsqueda a partir de los resultados de la investigación, que puede consultarse para casos de uso de IA en sanidad o cualquier otro tema de investigación.
importar chromadb
from chromadb.config import Configuración
# Inicializar ChromaDB
client = chromadb.PersistentClient(path="./research_db")
colección = client.get_or_create_collection("datos_investigación")
# Almacenar los resultados de la investigación
def almacenar_datos_investigacion(resultados):
documentos = []
metadatos = []
ids = []
for i, item in enumerate(resultados):
documents.append(item.get('content', ''))
metadatos.append({
'fuente': item.get('fuente', ''),
'query': query,
'timestamp': item.get('timestamp', '')
})
ids.append(f "doc_{i}")
collection.add(
documentos=documentos,
metadatos=metadatos,
ids=ids
)Paso 4: Resumir el modelo local
Este paso demuestra cómo aprovechar los modelos de lenguaje de gran tamaño (LLM) ejecutados localmente a través de Ollama para generar resúmenes concisos del contenido de la investigación. Este enfoque mantiene la privacidad del procesamiento de datos y permite capacidades de resumen fuera de línea.
importar subproceso
importar json
def resumir_con_ollama(contenido, modelo="llama2"):
"""Resumir el contenido de la investigación utilizando el modelo local de Ollama"""
try:
result = subprocess.run(
['ollama', 'run', model, f "Resumir el contenido de esta investigación: {content[:2000]}"],
capture_output=True,
text=Verdadero,
timeout=120
)
return resultado.stdout.strip()
except Exception as e:
return f "Error de resumen: {str(e)}"
# Ejemplo de uso
datos_investigación = res.json().get('resultados', [])
for item in datos_investigación:
summary = resumir_con_ollama(item.get('contenido', ''))
print(f "Resumen: {resumen}")ollama run llama2 "Resumir casos de uso de IA en sanidad"Streamlit UI
Por último, cree una interfaz de usuario web completa que combine la recopilación de datos de Bright Data con el resumen local de IA a través de Ollama. La interfaz permite a los usuarios configurar los parámetros de investigación, ejecutar la recopilación de datos y generar resúmenes de IA a través de un panel intuitivo.
Crear app.py
importar streamlit como st
import requests, os
from dotenv import cargar_dotenv
import subproceso
import json
cargar_dotenv()
st.set_page_config(page_title="Agente de investigación profunda", page_icon="🔎")
st.title("🔎 Agente local de investigación profunda con datos brillantes")
# Configuración de la barra lateral
con st.sidebar:
st.header("Configuración")
api_key = st.text_input(
"Clave API de Bright Data",
type="contraseña",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Modelo Ollama",
["llama2", "mistral", "codellama"]
)
profundidad_investigación = st.slider("Profundidad_investigación", 5, 50, 20)
# Interfaz principal de investigación
query = st.text_input("Introducir tema de investigación:", "Casos de uso de IA en sanidad")
col1, col2 = st.columns(2)
con col1:
if st.button("🚀 Ejecutar investigación", type="primary"):
if not api_key:
st.error("Por favor, introduzca su clave API de Bright Data")
elif not query:
st.error("Por favor, introduzca un tema de investigación")
else
with st.spinner("Recopilando datos de investigación..."):
# Obtener datos de Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"consulta": consulta, "límite": profundidad_investigación}
headers = {"Authorization": f "Bearer {api_key}"}
res = requests.post(url, json=carga, cabeceras=cabeceras)
si res.status_code == 200:
st.success(f "¡Recogidas con éxito {len(res.json().get('results', []))} fuentes!")
st.session_state.research_data = res.json()
# Mostrar resultados
for i, item in enumerate(res.json().get('resultados', [])):
with st.expander(f "Fuente {i+1}: {item.get('title', 'Sin título')}"):
st.write(item.get('content', 'No content available'))
si no:
st.error(f "Failed to fetch data: {res.status_code}")
con col2:
if st.button("🤖 Resumir con Ollama"):
if 'research_data' in st.session_state:
with st.spinner("Generando resúmenes de IA..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('content', '')[:1500] # Limitar la longitud del contenido
probar:
result = subprocess.run(
['ollama', 'run', model_choice, f "Resumir este contenido: {contenido}"],
capture_output=True,
text=Verdadero,
timeout=60
)
resumen = resultado.stdout.strip()
con st.expander(f "Resumen IA {i+1}"):
st.write(resumen)
except Exception as e:
st.error(f "Error de resumen para la fuente {i+1}: {str(e)}")
else:
st.warning("Por favor, ejecute primero la investigación para recopilar datos")
# Mostrar los datos en bruto si están disponibles
if 'datos_investigación' in st.session_state:
with st.expander("Ver datos brutos de investigación"):
st.json(st.session_state.research_data)Ejecutar la aplicación:
streamlit run app.pyCuando ejecutes la aplicación y visites el puerto 8501, esta debería ser la interfaz de usuario:
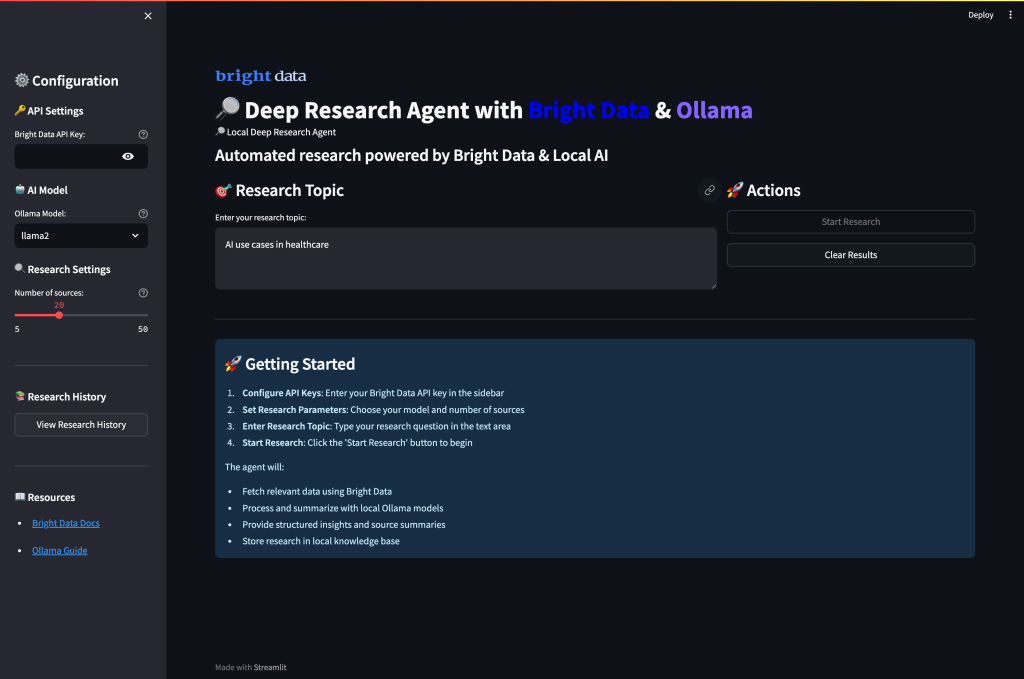
Ejecutando su Agente de Investigación Profunda
Ejecute la aplicación para empezar a realizar una investigación exhaustiva con análisis potenciados por IA. Abra su terminal y navegue hasta el directorio de su proyecto.
streamlit ejecutar app.pyVerá el flujo de trabajo inteligente multiagente del sistema a medida que procesa sus solicitudes de investigación:
- Fase de recogida de datos: El agente obtiene datos de investigación exhaustivos de diversas fuentes web utilizando las API fiables de Bright Data, filtrando automáticamente la relevancia y la credibilidad.
- Procesamiento del contenido: Cada fuente se somete a un análisis inteligente en el que el sistema extrae la información clave, identifica los temas principales y evalúa la calidad del contenido mediante la comprensión semántica.
- Resumido IA: Los modelos locales de Ollama procesan los datos recopilados, generando resúmenes concisos al tiempo que preservan los conocimientos críticos y mantienen la precisión contextual en todas las fuentes.
- Síntesis del conocimiento: El sistema identifica patrones recurrentes, conecta conceptos relacionados y detecta tendencias emergentes mediante el análisis simultáneo de información de múltiples fuentes.
- Informes estructurados: Por último, el agente recopila todos los hallazgos en un informe de investigación exhaustivo con una organización adecuada, citas claras y un formato profesional que destaca los descubrimientos y conocimientos clave.
Investigación mejorada
Para obtener funciones de investigación más avanzadas, amplíe la aplicación.
Esta canalización mejorada crea un flujo de trabajo de investigación completo que va más allá de un simple resumen para proporcionar análisis estructurados, perspectivas clave y hallazgos procesables a partir de los datos de investigación recopilados. El proceso integra Bright Data para la recopilación de información y modelos locales de Ollama para el análisis inteligente.
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""Tubería de investigación completa con recopilación de datos y análisis de IA""".
# Paso 1: Obtener datos de Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": consulta, "limit": 20}
headers = {"Authorization": f "Bearer {api_key}"}
response = requests.post(url, json=carga, cabeceras=cabeceras)
si response.status_code != 200
return {"error": "Data collection failed"}
datos_investigación = response.json()
# Paso 2: Procesar y analizar con Ollama
información = []
for item in datos_de_investigación.get('resultados', []):
content = item.get('content', '')
# Generar insights para cada fuente
analysis_prompt = f""
Analiza este contenido y proporciona información clave:
{content[:2000]}
Concéntrese en:
- Puntos principales y conclusiones
- Datos y estadísticas clave
- Posibles aplicaciones
- Limitaciones mencionadas
"""
try:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=Verdadero,
timeout=90
)
insights.append({
'fuente': item.get('fuente', ''),
'análisis': result.stdout.strip(),
'title': item.get('title', '')
})
excepto Exception como e:
insights.append({
'fuente': item.get('fuente', ''),
'analysis': f "Análisis fallido: {str(e)}",
'title': item.get('title', '')
})
return {
'datos_investigación': datos_investigación,
'ai_insights': insights,
'query': query
}Conclusión
Este Agente de Investigación Profunda Local demuestra cómo construir un sistema de investigación automatizado que combina la recopilación fiable de datos web de Bright Data con el procesamiento local de IA utilizando Ollama. La implementación proporciona:
- Enfoque de Privacidad Primero: Todo el procesamiento de IA se realiza localmente con Ollama.
- Recopilación de datos fiable: Bright Data garantiza datos web estructurados de alta calidad
- Interfaz fácil de usar: Streamlit UI hace accesible la investigación compleja
- Flujo de trabajo personalizable: Adaptable a diversos dominios y requisitos de investigación
El sistema aborda los retos clave de la industria mediante la automatización de la recopilación, el procesamiento y el análisis de datos, transformando horas de investigación manual en minutos de generación automatizada de información.
Para mejorar aún más sus capacidades de investigación, explore las soluciones de conjuntos de datos de Bright Data para datos específicos del sector y considere la posibilidad de utilizar Deep Lookup para consultar y buscar en la mayor base de datos de datos web del mundo.
¿Listo para crear su propio agente de investigación? Cree una cuenta gratuita de Bright Data para empezar a recopilar datos web fiables y empezar a transformar sus flujos de trabajo de investigación hoy mismo.