

En esta guía, aprenderá a crear un raspador de noticias automatizado con n8n, OpenAI y Bright Data MCP Server. Al final de este tutorial, usted será capaz de realizar lo siguiente.
- Crear una instancia n8n autoalojada
- Instalar nodos comunitarios en n8n
- Cree sus propios flujos de trabajo con n8n
- Integrar agentes de IA mediante OpenAI y n8n
- Conecte su Agente AI a Web Unlocker utilizando el Servidor MCP de Bright Data
- Envíe correos electrónicos automatizados con n8n
Primeros pasos
Para empezar, necesitamos lanzar una instancia auto-alojada de n8n. Una vez en marcha, tenemos que instalar un nodo de la comunidad n8n. También necesitamos obtener claves API de OpenAI y Bright Data para ejecutar nuestro flujo de trabajo de scraping.
Lanzamiento del n8n
Cree un nuevo volumen de almacenamiento para n8n y láncelo en un contenedor Docker.
# Create persistent volume
sudo docker volume create n8n_data
# Start self-hosted n8n container with support for unsigned community nodes
sudo docker run -d
--name n8n
-p 5678:5678
-v n8n_data:/home/node/.n8n
-e N8N_BASIC_AUTH_ACTIVE=false
-e N8N_ENCRYPTION_KEY="this_is_my_secure_encryption_key_1234"
-e N8N_ALLOW_LOADING_UNSIGNED_NODES=true
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
-e N8N_HOST="0.0.0.0"
-e N8N_PORT=5678
-e WEBHOOK_URL="http://localhost:5678"
n8nio/n8nAhora, abre http://localhost:5678/ dentro de tu navegador. Probablemente se te pedirá que inicies sesión o crees un login.

Cuando hayas iniciado sesión, ve a tu configuración y selecciona “Nodos comunitarios”. A continuación, haz clic en el botón “Instalar un nodo comunitario”.

En “Nombre del paquete npm”, introduzca “n8n-nodes-mcp”.

Obtención de claves API
Necesitará una clave de API de OpenAI y una clave de API de Bright Data. Su clave OpenAI permite a su instancia n8n acceder a LLMs como GPT-4.1. Su clave API de Bright Data permite a su LLM acceder a datos web en tiempo real a través del servidor MCP de Bright Data.
Claves de la API de OpenAI
Dirígete a la plataforma para desarrolladores de OpenAI y crea una cuenta si aún no lo has hecho. Selecciona “Claves API” y haz clic en el botón “Crear nueva clave secreta”. Guarda la clave en un lugar seguro.

Claves API de Bright Data
Es posible que ya tenga una cuenta con Bright Data. Incluso si la tiene, debe crear una nueva zona de Web Unlocker. En el panel de Bright Data, seleccione “Proxies y Scraping” y haga clic en el botón “Añadir”.

Puede utilizar otros nombres de zona, pero le recomendamos encarecidamente que nombre esta zona “mcp_unlocker”. Este nombre le permite trabajar con nuestro Servidor MCP prácticamente desde el principio.
En la configuración de su cuenta, copie su clave API y guárdela en un lugar seguro. Esta clave proporciona acceso a todos sus servicios de Bright Data.

Ahora que tenemos una instancia n8n autoalojada y las credenciales adecuadas, es hora de construir nuestro flujo de trabajo.
Construir el flujo de trabajo

Ahora, vamos a construir nuestro flujo de trabajo real. Haga clic en el botón “Crear un nuevo flujo de trabajo”. Esto le da un lienzo en blanco para trabajar.
1. Crear nuestro disparador
Empezaremos creando un nuevo nodo. En la barra de búsqueda, escribe “chat” y selecciona el nodo “Chat Trigger”.

Chat Trigger no será nuestro disparador permanente, pero hace la depuración mucho más fácil. Nuestro agente de IA va a recibir un aviso. Con el nodo Chat Trigger, puedes probar diferentes avisos fácilmente sin tener que editar tus nodos.
2. Añadir nuestro agente

A continuación, tenemos que conectar nuestro nodo de activación a un Agente AI. Añade otro nodo y escribe “ai agent” en la barra de búsqueda. Selecciona el nodo AI Agent.

Este agente AI contiene básicamente todo nuestro tiempo de ejecución. El agente recibe un prompt y ejecuta nuestra lógica de scraping. Puedes leer nuestro prompt más abajo. Siéntase libre de ajustarlo como mejor le parezca – es por eso que hemos añadido el Chat Trigger. El siguiente fragmento contiene el prompt que usaremos para este flujo de trabajo.
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.3. Conexión de un modelo

Haz clic en el signo “+” bajo “Modelo de chat” y escribe “openai” en la barra de búsqueda. Selecciona el modelo de chat OpenAI.

Cuando se le pida que añada credenciales, añada su clave de API de OpenAI y guarde las credenciales.

A continuación, tenemos que elegir un modelo. Puede elegir entre cualquier variedad de modelos, pero recuerde que se trata de un flujo de trabajo complejo para un solo agente. Con GPT-4o, obtuvimos un éxito limitado. GPT-4.1-Nano y GPT-4.1-Mini resultaron insuficientes. El modelo GPT-4.1 completo es más caro, pero resultó increíblemente competente, así que nos quedamos con él.

4. Añadir memoria

Para gestionar las ventanas contextuales, necesitamos añadir memoria. No necesitamos nada complejo. Sólo necesitamos una configuración de Memoria Simple para que nuestro modelo pueda recordar lo que está haciendo a través de los pasos.
Elige la “Memoria simple” para dotar a tu modelo de memoria.
5. Conexión al MCP de Bright Data

Para buscar en la web, nuestro modelo necesita conectarse al servidor MCP de Bright Data. Haga clic en el signo “+” bajo “Herramienta” y seleccione el Cliente MCP que aparece en la parte superior de la sección “Otras herramientas”.

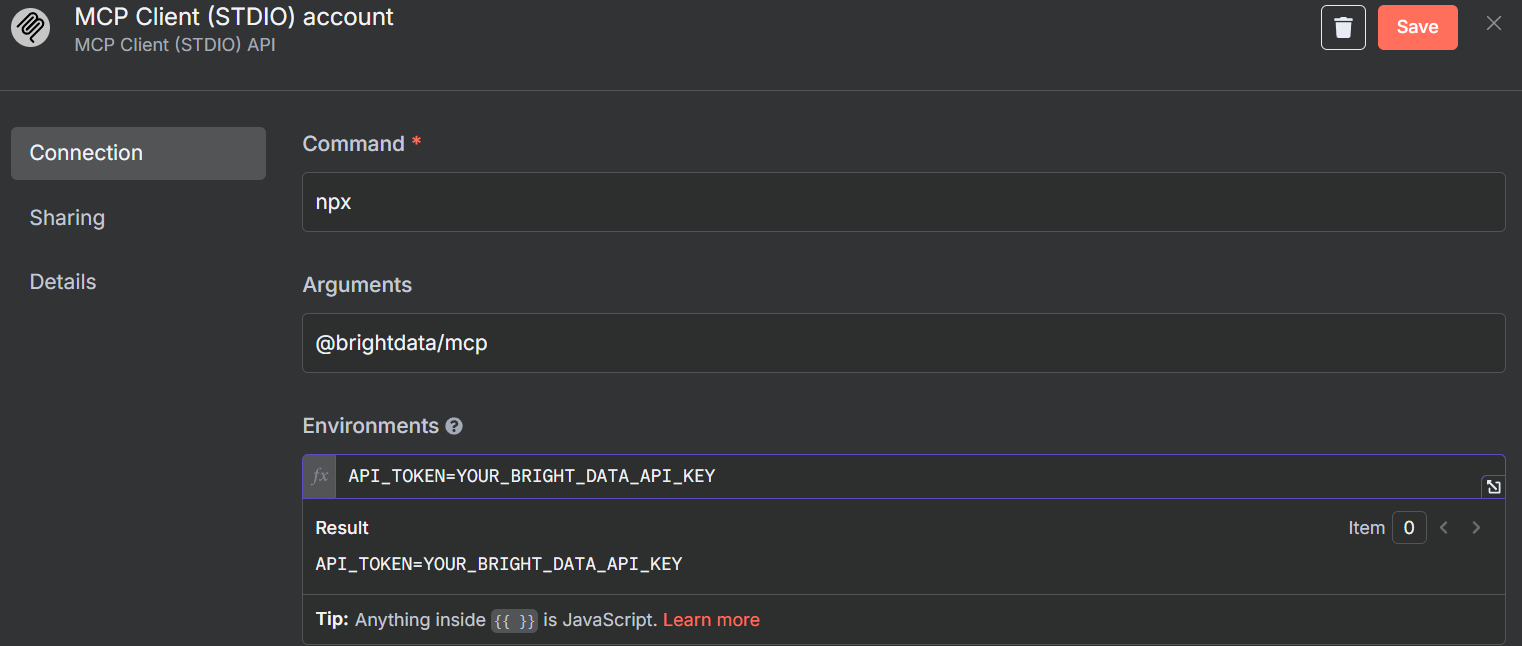
Cuando se le solicite, introduzca sus credenciales para el servidor MCP de Bright Data. En el cuadro “Comando”, introduzca npx – esto permite a NodeJS crear y ejecutar automáticamente nuestro servidor MCP. En “Argumentos”, añada @brightdata/mcp. En “Entornos”, introduzca API_TOKEN=YOUR_BRIGHT_DATA_API_KEY (sustitúyalo por su clave real).
El método por defecto para esta herramienta es “Listar Herramientas”. Eso es exactamente lo que tenemos que hacer. Si tu modelo es capaz de conectarse, hará ping al servidor MCP y listará las herramientas de las que dispone.

Cuando estés listo, introduce una pregunta en el chat. Utiliza una sencilla que pida una lista de las herramientas disponibles.
List the tools available to youDebería recibir una respuesta con una lista de las herramientas disponibles para el modelo. Si esto ocurre, está conectado al servidor MCP. El siguiente fragmento sólo contiene una parte de la respuesta. En total, hay 21 herramientas disponibles para el modelo.
Here are the tools available to me:
1. search_engine – Search Google, Bing, or Yandex and return results in markdown (URL, title, description).
2. scrape_as_markdown – Scrape any webpage and return results as Markdown.
3. scrape_as_html – Scrape any webpage and return results as HTML.
4. session_stats – Show the usage statistics for tools in this session.
5. web_data_amazon_product – Retrieve structured Amazon product data (using a product URL).6. Añadir las herramientas de raspado
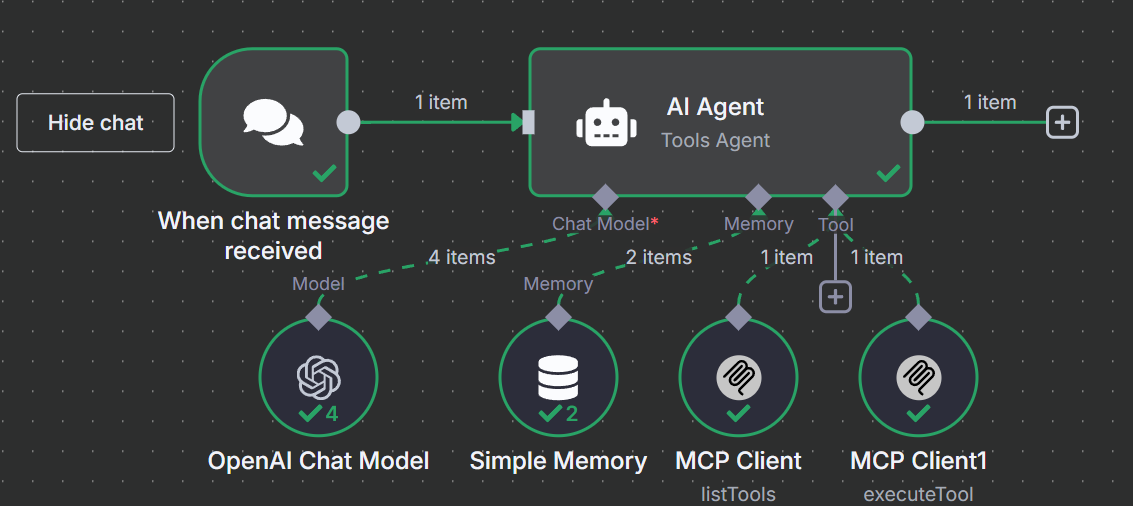
Vuelva a hacer clic en el signo “+” situado debajo de “Herramienta”. Una vez más, seleccione la misma “Herramienta de cliente MCP” de la sección “Otras herramientas”.

Esta vez, configure la herramienta para usar “Ejecutar herramienta”.

En “Nombre de la herramienta”, pegue la siguiente expresión JavaScript. Llamamos a la función “fromAI” e introducimos el nombre de la herramienta, la descripción y el tipo de datos.
{{ $fromAI("toolname", "the most applicable tool required to be executed as specified by the users request and list of tools available", "string") }}Bajo los parámetros, añade el siguiente bloque. Proporciona una consulta al modelo junto a tu motor de búsqueda preferido.
{
"query": "Return the top 5 world news headlines and their links."
,
"engine": "google"
}Ahora, ajuste los parámetros para el propio agente de IA. Añade el siguiente mensaje de sistema.
You are an expert web scraping assistant with access to Bright Data's Web Unlocker API. This gives you the ability to execute a specific set of actions. When using tools, you must share across the exact name of the tool for it to be executed.
For example, "Search Engine Scraping" should be "search_engine"
Antes de ejecutar el scraper, debemos activar los reintentos. Los agentes de IA son inteligentes, pero no son perfectos. Los trabajos a veces fallan y necesitan ser manejados. Al igual que los scraper codificados manualmente, la lógica de reintentos no es opcional si quieres un producto que funcione de forma consistente.

Siga adelante y ejecute el siguiente mensaje.
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.Si todo funciona correctamente, debería obtener una respuesta similar a la que se muestra a continuación.
Here are real global news headlines for today, each with a direct source link:
1. Reuters
Headline: Houthi ceasefire followed US intel showing militants sought off-ramp
Source: https://www.reuters.com/world/
2. CNN
Headline: UK police arrest man for arson after fire at PM Starmer's house
Source: https://www.cnn.com/world
3. BBC
Headline: Uruguay's José Mujica, world's 'poorest president', dies
Source: https://www.bbc.com/news/world
4. AP News
Headline: Israel-Hamas war, Russia-Ukraine War, China, Asia Pacific, Latin America, Europe, Africa (multiple global crises)
Source: https://apnews.com/world-news
5. The Guardian
Headline: Fowl play: flying duck caught in Swiss speed trap believed to be repeat offender
Source: https://www.theguardian.com/world
These headlines were selected from the main headlines of each trusted global news outlet’s world section as of today.7. El principio y el fin

Ahora que nuestro Agente AI hace su trabajo, necesitamos añadir el principio y el final del flujo de trabajo. Nuestro raspador de noticias debe trabajar desde un programador, no desde un prompt individual. Finalmente, nuestra salida debería enviar un email usando SMTP.
Añadir el disparador adecuado
Busque el nodo “Schedule Trigger” y añádalo a su flujo de trabajo.

Configúralo para que se active a la hora que desees. Nosotros elegimos las 9:00 de la mañana.

Ahora, necesitamos agregar un nodo más a nuestra lógica de activación. Este nodo inyectará un aviso ficticio en nuestro Modelo de Chat.
Agregue el nodo “Editar Campos” a su Activador de Programación.

Añada lo siguiente a su nodo Editar Campos como JSON. “sessionId” es sólo un valor ficticio – no se puede iniciar un chat sin un sessionId. “chatInput” contiene el mensaje que estamos inyectando en el LLM.
{
"sessionId": "google",
"chatInput": "Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite."
}Por último, conecte estos nuevos pasos a su Agente AI. Su agente puede ahora ser activado por el programador.

Envío de los resultados por correo electrónico
Haga clic en el signo “+” a la derecha de su nodo de Agente AI. Añada el nodo “Enviar Email” al final de su flujo de trabajo. Añada sus credenciales SMTP y luego utilice los parámetros para personalizar el correo electrónico.

El correo electrónico
Ahora puede hacer clic en el botón “Probar flujo de trabajo”. Cuando el flujo de trabajo se ejecute correctamente, recibirá un correo electrónico con todos los titulares actuales. GPT-4.1

Más allá: Rastreo de sitios web reales
En su estado actual, nuestro Agente de IA encuentra titulares de Google News utilizando la herramienta de motor de búsqueda del Servidor MCP. Utilizando sólo un motor de búsqueda, los resultados pueden ser inconsistentes. A veces, el agente de IA encuentra titulares reales. Otras veces, sólo ve los metadatos del sitio: “¡Obtén los últimos titulares de CNN!”.
En lugar de limitar nuestra extracción a la herramienta del motor de búsqueda, vamos a añadir una herramienta de raspado. Comience añadiendo otra herramienta a su flujo de trabajo. Ahora debería tener tres Clientes MCP adjuntos a su Agente AI como ve en la imagen de abajo.
Añadir herramientas de scraping

Ahora, necesitamos abrir los ajustes y parámetros para esta nueva herramienta. Fíjese en que esta vez configuramos la Descripción de la Herramienta manualmente. Hacemos esto para que el agente no se confunda.
En nuestra descripción, le decimos al Agente de IA que utilice esta herramienta para raspar URLs. Nuestro Nombre de Herramienta es similar al que creamos anteriormente.
{{ $fromAI("toolname", "the most applicable scraping tool required to be executed as specified by the users request and list of tools available", "string") }}En nuestros parámetros, especificamos una url en lugar de una consulta o motor de búsqueda.
{
"url": "{{$fromAI('URL', 'url that the user would like to scrape', 'string')}}"
}Ajustar los demás nodos y herramientas
La herramienta de búsqueda
Con nuestra herramienta de raspado, ajustamos la descripción manualmente para evitar que el Agente AI se confunda. También vamos a ajustar la herramienta de motor de búsqueda. Los cambios no son extensos, simplemente le decimos manualmente que utilice la herramienta de motor de búsqueda cuando ejecute este Cliente MCP.

Editar campos: La pregunta ficticia
Abra el nodo Editar campos y ajuste nuestro aviso ficticio.
{
"sessionId": "google",
"chatInput": "get the latest news from https://www.brightdata.com/blog and https://www.theguardian.com/us with your scrape_as_markdown and Google News with your search engine tool to find the latest global headlines--pull actual headlines, not just the site description."
}Sus parámetros deben parecerse a la imagen siguiente.

En un principio utilizamos Reddit en lugar de The Guardian. Sin embargo, los LLM de OpenAI obedecen el archivo robots.txt. Aunque Reddit es fácil de scrapear, el Agente de IA se niega a hacerlo.

El nuevo feed curado
Al añadir otra herramienta, hemos dotado a nuestro agente de inteligencia artificial de la capacidad de rastrear sitios web, no sólo los resultados de los motores de búsqueda. Echa un vistazo al siguiente correo electrónico. Tiene un formato mucho más limpio con un desglose muy detallado de las noticias de cada fuente.

Conclusión
Al combinar n8n, OpenAI y el servidor de protocolo de contexto de modelo (MCP) de Bright Data, puede automatizar el raspado y la entrega de noticias con potentes flujos de trabajo impulsados por IA. MCP facilita el acceso a datos web actualizados y estructurados en tiempo real, lo que permite a sus agentes de IA extraer contenidos precisos de cualquier fuente. A medida que evoluciona la automatización de la IA, herramientas como MCP de Bright Data serán esenciales para una recopilación de datos eficiente, escalable y fiable.
Bright Data le anima a leer nuestro artículo sobre el web scraping con servidores MCP. Regístrese ahora para obtener sus créditos gratuitos para probar nuestros productos.






