

En esta guía, vamos a caminar a través de la construcción de un servidor local de MCP en Python para raspar los datos de productos de Amazon en la demanda. Aprenderá los fundamentos de MCP, cómo escribir y ejecutar su propio servidor y cómo conectarlo a herramientas de desarrollo como Claude Desktop y Cursor IDE. Concluiremos con una integración real de Bright Data MCP para obtener datos web en tiempo real y listos para la IA.
Vamos a sumergirnos.
El cuello de botella: Por qué a los LLM les cuesta interactuar con el mundo real (y cómo lo soluciona MCP)
Los grandes modelos lingüísticos (LLM) son increíblemente potentes a la hora de procesar y generar texto a partir de enormes conjuntos de datos de entrenamiento. Pero tienen una limitación clave: no pueden interactuar de forma nativa con el mundo real. Esto significa que no pueden acceder a archivos locales, ejecutar secuencias de comandos personalizadas ni obtener datos en tiempo real de la Web.
Pongamos un ejemplo sencillo: pídele a Claude que extraiga los detalles de un producto de una página de Amazon en vivo, y no podrá hacerlo. ¿Por qué? Porque carece de la capacidad incorporada para navegar por la web o desencadenar acciones externas.

Sin herramientas externas, los LLM no pueden realizar tareas prácticas que dependan de datos en tiempo real o de la integración con sistemas externos.
Aquí es donde entra en juego el Protocolo de Contexto de Modelos (MCP) de Anthropic. Permite a los LLM comunicarse con herramientas externas, como scrapers, API o scripts, de forma segura y estandarizada.
He aquí la diferencia en acción. Tras integrar un servidor MCP personalizado, pudimos extraer datos estructurados de productos de Amazon directamente a través de Claude:

No te preocupes todavía por cómo funciona: lo explicaremos todo paso a paso más adelante en la guía.
¿Por qué es importante el MCP?
- Estandarización: MCP proporciona una interfaz estandarizada para que los sistemas basados en LLM se conecten con herramientas y datos externos, de forma similar a como las API estandarizan las integraciones web. Esto reduce drásticamente la necesidad de integraciones personalizadas, acelerando el desarrollo.
- Flexibilidad y escalabilidad: Los desarrolladores pueden cambiar los LLM o las plataformas de alojamiento sin tener que reescribir las integraciones de las herramientas. MCP admite múltiples transportes de comunicación (como
stdio), lo que lo hace adaptable a diferentes configuraciones. - Capacidades LLM mejoradas: Al conectar los LLM con datos en tiempo real y herramientas externas, MCP les permite ir más allá de las respuestas estáticas. Ahora pueden devolver información actual y relevante y desencadenar acciones en el mundo real basadas en el contexto.
Analogía: Piense en MCP como una interfaz USB para los LLM. Del mismo modo que USB permite conectar diferentes dispositivos (teclados, impresoras, unidades externas) a cualquier máquina compatible sin necesidad de controladores especiales, MCP permite a los LLM conectarse a una amplia gama de herramientas utilizando un protocolo estandarizado, sin necesidad de una integración personalizada cada vez.
¿Qué es el Protocolo de Contexto Modelo (MCP)?
Model Context Protocol (MCP) es un estándar abierto desarrollado por Anthropic que permite a los grandes modelos lingüísticos (LLM) interactuar con herramientas externas, API y fuentes de datos de forma coherente y segura. Actúa como un conector universal, permitiendo a los LLM realizar tareas del mundo real como el scraping de sitios web, la consulta de bases de datos o la activación de scripts.
Aunque Anthropic lo introdujo, MCP es abierto y extensible, lo que significa que cualquiera puede implementar o contribuir al estándar. Si ha trabajado con Retrieval-Augmented Generation (RAG), apreciará el concepto. MCP se basa en esa idea mediante la normalización de las interacciones a través de una interfaz JSON-RPC ligera para que los modelos puedan acceder a los datos en vivo y tomar medidas.
Arquitectura MCP: Cómo funciona
En esencia, MCP estandariza la comunicación entre un modelo de IA y las capacidades externas.
Idea central: Una interfaz estandarizada (normalmente JSON-RPC 2.0 sobre transportes como stdio) permite a un LLM (a través de un cliente) descubrir e invocar herramientas expuestas por servidores externos.
MCP funciona mediante una arquitectura cliente-servidor con tres componentes clave:
- Host MCP: El entorno o aplicación que inicia y gestiona las interacciones entre el LLM y las herramientas externas. Por ejemplo, asistentes de IA como Claude Desktop o IDEs como Cursor.
- Cliente MCP: Componente dentro del host que establece y mantiene las conexiones con los Servidores MCP, manejando los protocolos de comunicación y gestionando el intercambio de datos.
- Servidor MCP: Un programa (que creamos los desarrolladores) que implementa el protocolo MCP y expone un conjunto específico de capacidades. Un servidor MCP puede interactuar con una base de datos, un servicio web o, en nuestro caso, un sitio web (Amazon). Los servidores exponen su funcionalidad de formas estandarizadas
:Polylang placeholder do not modify
Aquí está el diagrama de la arquitectura MCP:

Fuente de la imagen: Modelo de Protocolo de Contexto
En esta configuración, el host (Claude Desktop o Cursor IDE) genera un cliente MCP, que se conecta a un servidor MCP externo. Ese servidor expone herramientas, recursos y avisos, permitiendo a la IA interactuar con ellos según sea necesario.
En resumen, el flujo de trabajo funciona del siguiente modo:
- El usuario envía un mensaje como “Obtener información del producto desde este enlace de Amazon”.
- El cliente MCP busca una herramienta registrada que pueda realizar esa tarea
- El cliente envía una solicitud estructurada al servidor MCP
- El servidor MCP ejecuta la acción apropiada (por ejemplo, lanzar un navegador headless)
- El servidor devuelve resultados estructurados al cliente MCP
- El cliente envía los resultados al LLM, que los presenta al usuario
Creación de un servidor MCP personalizado
Vamos a construir un servidor Python MCP para scrapear páginas de productos de Amazon.

Este servidor expondrá dos herramientas: una para descargar HTML y otra para extraer información estructurada. Interactuarás con el servidor a través de un cliente LLM en Cursor o Claude Desktop.
Paso 1: Configuración del entorno
En primer lugar, asegúrate de que tienes Python 3 instalado. A continuación, crea y activa un entorno virtual:
python -m venv mcp-amazon-scraper
# On macOS/Linux:
source mcp-amazon-scraper/bin/activate
# On Windows:
.mcp-amazon-scraperScriptsactivateInstale las bibliotecas necesarias: MCP Python SDK, Playwright y LXML.
pip install mcp playwright lxml
# Install browser binaries for Playwright
python -m playwright installEsto se instala:
- mcp: SDK de Python para servidores y clientes del Protocolo de Contexto de Modelo que maneja todos los detalles de la comunicación JSON-RPC.
- playwright: Biblioteca de automatización del navegador que proporciona capacidades de navegador sin cabeza para renderizar y raspar sitios web con mucho JavaScript.
- lxml: Rápida biblioteca de análisis XML/HTML que facilita la extracción de elementos de datos específicos de páginas web mediante consultas XPath.
En resumen, el MCP Python SDK(mcp) maneja todos los detalles del protocolo, permitiéndote exponer herramientas que Claude o Cursor pueden llamar a través de prompts en lenguaje natural. Playwright nos permite renderizar páginas web completamente (incluyendo contenido JavaScript), y lxml nos da potentes capacidades de análisis HTML.
Paso 2: Inicializar el servidor MCP
Crea un archivo Python llamado amazon_scraper_mcp.py. Empieza importando los módulos necesarios e inicializando el servidor FastMCP:
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")Esto crea una instancia del servidor MCP. Ahora le añadiremos herramientas.
Paso 3: Implementar la herramienta fetch_page
Esta herramienta tomará una URL como entrada, utilizará Playwright para navegar hasta la página, esperará a que se cargue el contenido, descargará el HTML y lo guardará en nuestro archivo temporal.
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_messageEsta función asíncrona utiliza Playwright para gestionar la posible renderización de JavaScript en las páginas de Amazon. El decorador @mcp.tool() registra esta función como una herramienta invocable dentro de nuestro servidor.
Paso 4: Implementar la herramienta extract_info
Esta herramienta lee el archivo HTML guardado por fetch_page, lo analiza utilizando selectores LXML y XPath, y devuelve un diccionario que contiene los detalles del producto extraídos.
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}Esta función utiliza fromstring de LXML para analizar el HTML y selectores XPath robustos para encontrar los elementos deseados
Paso 5: Ejecutar el servidor
Por último, añada las siguientes líneas al final de su script amazon_scraper_mcp.py para iniciar el servidor utilizando el mecanismo de transporte stdio, que es estándar para los servidores MCP locales que se comunican con clientes como Claude Desktop o Cursor.
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Código completo(amazon_scraper_mcp.py)
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Integración de su servidor MCP personalizado
Ahora que el script del servidor está listo, vamos a conectarlo a clientes MCP como Claude Desktop y Cursor.
Conexión a Claude Desktop
Paso 1: Abra Claude Desktop.
Paso 2: Vaya a Configuración -> Desarrollador -> Editar configuración. Esto abrirá el archivo claude_desktop_config.json en su editor de texto predeterminado.

Paso 3: Añada una entrada para su servidor bajo la clave mcpServers. Asegúrese de sustituir la ruta en args por la ruta absoluta a su archivo amazon_scraper_mcp.py.
{
"mcpServers": {
"amazon_product_scraper": {
"command": "python", // Or python3 if needed
"args": ["/full/path/to/your/amazon_scraper_mcp.py"], // <-- IMPORTANT: Use the correct absolute path
}
}
}Paso 4: Guarde el archivo claude_desktop_config.json y cierre completamente y vuelva a abrir Claude Desktop para que los cambios surtan efecto.
Paso 5: En Claude Desktop, ahora deberías ver un pequeño icono de herramientas (como un martillo 🔨) en el área de entrada del chat.
Paso 6: Al hacer clic en él debería listar su “Amazon Product Scraper” con sus herramientas fetch_page y extract_info.

Paso 7: Enviar un Prompt, por ejemplo: “Obtenga el precio actual, el precio original y la valoración de este producto de Amazon: https://www.amazon.com/dp/B09C13PZX7″.
Paso 8: Claude detectará que esto requiere herramientas externas y le pedirá permiso para ejecutar primero fetch_page y luego extract_info. Haga clic en “Permitir para este chat” para cada herramienta.

Paso 9: Tras conceder los permisos, el servidor MCP ejecutará las herramientas. A continuación, Claude recibirá los datos estructurados y los presentará en el chat.

🔥 ¡Genial, has construido e integrado con éxito tu primer servidor MCP!
Conexión a Cursor
El proceso para Cursor (un IDE que prioriza la inteligencia artificial) es similar.
Paso 1: Abrir Cursor.
Paso 2: Vaya a Ajustes ⚙️ y navegue hasta la sección MCP.

Paso 3: Haga clic en “+Añadir un nuevo servidor MCP global”. Esto abrirá el archivo de configuración mcp.json. Añada una entrada para su servidor, de nuevo utilizando la ruta absoluta a su script.
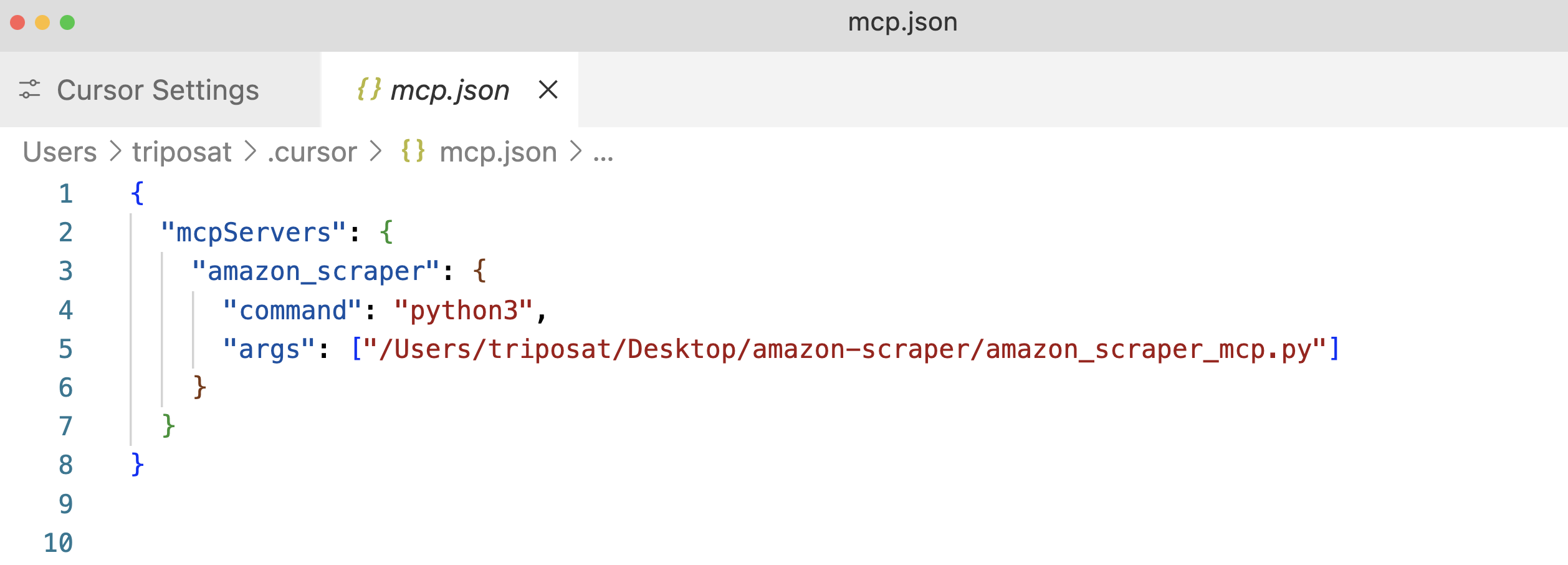
Paso 4: Guarde el archivo mcp.json y debería ver su “amazon_product_scraper” en la lista, con suerte con un punto verde que indica que se está ejecutando y conectado.

Paso 5: Utiliza la función de chat de Cursor(Cmd+l o Ctrl+l).
Paso 6: Enviar un Prompt, por ejemplo: “Extraer todos los datos de producto disponibles de esta URL de Amazon: https://www.amazon.com/dp/B09C13PZX7. Formatea la salida como un objeto JSON estructurado”.
Paso 7: De forma similar a Claude Desktop, el Cursor pedirá permiso para ejecutar las herramientas fetch_page y extract_info. Apruebe estas solicitudes (“Ejecutar herramienta”).
Paso 8: El Cursor mostrará el flujo de interacción, mostrando las llamadas a sus herramientas MCP y finalmente presentando los datos JSON estructurados devueltos por su herramienta extract_info.

He aquí un ejemplo de salida JSON de Cursor:
{
"title": "Razer Basilisk V3 Customizable Ergonomic Gaming Mouse: Fastest Gaming Mouse Switch - Chroma RGB Lighting - 26K DPI Optical Sensor - 11 Programmable Buttons - HyperScroll Tilt Wheel - Classic Black",
"price": 39.99,
"original_price": 69.99,
"discount_percent": 43,
"rating_stars": 4.6,
"review_count": 7782,
"features": [
"ICONIC ERGONOMIC DESIGN WITH THUMB REST — PC gaming mouse favored by millions worldwide with a form factor that perfectly supports the hand while its buttons are optimally positioned for quick and easy access",
"11 PROGRAMMABLE BUTTONS — Assign macros and secondary functions across 11 programmable buttons to execute essential actions like push-to-talk, ping, and more",
"HYPERSCROLL TILT WHEEL — Speed through content with a scroll wheel that free-spins until its stopped or switch to tactile mode for more precision and satisfying feedback that's ideal for cycling through weapons or skills",
"11 RAZER CHROMA RGB LIGHTING ZONES — Customize each zone from over 16.8 million colors and countless lighting effects, all while it reacts dynamically with over 150 Chroma integrated games",
"OPTICAL MOUSE SWITCHES GEN 2 — With zero unintended misclicks these switches provide crisp, responsive execution at a blistering 0.2ms actuation speed for up to 70 million clicks",
"FOCUS+ 26K DPI OPTICAL SENSOR — Best-in-class mouse sensor with intelligent functions flawlessly tracks movement with zero smoothing, allowing for crisp response and pixel-precise accuracy",
// ... (other features)
],
"availability": "In Stock"
}Esto demuestra la flexibilidad de MCP: el mismo servidor funciona a la perfección con distintas aplicaciones cliente.
Integración de MCP de Bright Data para la extracción de datos web basada en IA
Los servidores MCP personalizados ofrecen un control total, pero conllevan desafíos, como la gestión de la infraestructura de proxy, el manejo de sofisticados mecanismos anti-bot y la garantía de escalabilidad. Bright Data aborda estos problemas con su solución MCP preconstruida y de nivel de producción, diseñada para una integración perfecta con agentes de IA y LLM.
La integración del Protocolo de Contexto de Modelos (MCP) con Bright Data proporciona a los LLM y a los agentes de IA un acceso fluido y en tiempo real a datos web públicos adaptados a los flujos de trabajo de IA. Al conectarse al MCP de Bright Data, sus aplicaciones y modelos pueden recuperar resultados de SERP de los principales motores de búsqueda y desbloquear sin problemas el acceso a sitios web de difícil acceso.
La solución Model Context Protocol (MCP) de Bright Data conecta su aplicación a un conjunto de potentes herramientas de extracción de datos web, entre las que se incluyen Web Unlocker, SERP API, Web Scraper API y Scraping Browser, proporcionandouna completa infraestructura que:
- Proporciona datos listos para la IA: Obtiene y formatea automáticamente el contenido web, reduciendo los pasos adicionales de preprocesamiento.
- Garantiza la escalabilidad y la fiabilidad: Aprovecha una infraestructura robusta para gestionar grandes volúmenes de solicitudes sin comprometer el rendimiento.
- Elude bloqueos y CAPTCHAs: Utiliza estrategias anti-bot avanzadas para navegar y recuperar contenidos incluso de los sitios web más protegidos.
- Ofrece cobertura global de IP: Utiliza una amplia red proxy que abarca 195 países para acceder a contenidos con restricciones geográficas.
- Simplifica la integración: Minimiza el esfuerzo de configuración trabajando sin problemas con cualquier cliente MCP.
Requisitos previos para el MCP de Bright Data
Antes de empezar a integrar Bright Data MCP, asegúrese de que dispone de lo siguiente:
- Cuenta de Bright Data: Regístrese en brightdata.com. Los nuevos usuarios reciben créditos gratuitos para realizar pruebas.
- Token de API: Obtenga su token de API en la configuración de su cuenta de Bright Data(Página de configuración de usuario).
- Zona Web Unlocker: Cree una zona proxy Web Unlocker en su panel de control de Bright Data. Póngale un nombre fácil de recordar, como
mcp_unlocker(puede modificarlo más adelante mediante variables de entorno si es necesario). - (Opcional) Scraping Brows er Zone: Si necesita capacidades avanzadas de automatización del navegador (por ejemplo, para interacciones complejas de JavaScript o capturas de pantalla), cree una Scraping Browser zone. Tenga en cuenta los detalles de autenticación (nombre de usuario y contraseña) proporcionados para esta zona (dentro de la pestaña Descripción general ), normalmente en el formato
brd-customer-ACCOUNT_ID-zone-ZONE_NAME:PASSWORD.
Inicio rápido: Configuración de Bright Data MCP para Claude Desktop
Paso 1: El servidor MCP de Bright Data se ejecuta normalmente utilizando npx, que viene con Node.js. Instale Node.js si aún no lo ha hecho desde el sitio web oficial.
Paso 2: Abra Claude Desktop -> Configuración -> Desarrollador -> Editar Config(claude_desktop_config.json).
Paso 3: Añada la configuración del servidor de Bright Data en mcpServers. Sustituya los marcadores de posición por sus credenciales reales.
{
"mcpServers": {
"Bright Data": { // Choose a name for the server
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_TOKEN", // Paste your API token here
"WEB_UNLOCKER_ZONE": "mcp_unlocker", // Your Web Unlocker zone name
// Optional: Add if using Scraping Browser tools
"BROWSER_AUTH": "brd-customer-ACCOUNTID-zone-YOURZONE:PASSWORD"
}
}
}
}Paso 4: Guarde el archivo de configuración y reinicie Claude Desktop.
Paso 5: Pase el ratón sobre el icono del martillo (🔨) en Claude Desktop. Ahora debería ver varias herramientas MCP.

Intentemos extraer datos de Zillow, un sitio conocido por bloquear potencialmente los scrapers. Pregunte a claude con “Extraer datos clave de propiedades en formato JSON de esta URL de Zillow: https://www.zillow.com/apartments/arverne-ny/the-tides-at-arverne-by-the-sea/ChWHPZ/”.

Permita que Claude utilice las herramientas MCP de Bright Data necesarias. El servidor MCP de Bright Data se encargará de las complejidades subyacentes (rotación de proxy, renderización de JavaScript a través de Scraping Browser si es necesario).
El servidor de Bright Data realiza la extracción y devuelve datos estructurados, que Claude presenta.

Aquí tienes un fragmento del resultado potencial:
{
"propertyInfo": {
"name": "The Tides At Arverne By The Sea",
"address": "190 Beach 69th St, Arverne, NY 11692",
"propertyType": "Apartment building",
// ... more info
},
"rentPrices": {
"studio": { "startingPrice": "$2,750", /* ... */ },
"oneBed": { "startingPrice": "$2,900", /* ... */ },
"twoBed": { "startingPrice": "$3,350", /* ... */ }
},
// ... amenities, policies, etc.
}🔥 ¡Esto es impresionante!
Otro ejemplo: Titulares de Hacker News
Una pregunta más simple:“Dame los títulos de los últimos 5 artículos de Hacker News“.

Esto muestra cómo el servidor MCP de Bright Data simplifica el acceso incluso a contenidos web dinámicos o fuertemente protegidos directamente dentro de su flujo de trabajo de IA.
Conclusión
Como hemos explorado a lo largo de esta guía, el Protocolo de Contexto de Modelo de Anthropic representa un cambio fundamental en la forma en que los sistemas de IA interactúan con el mundo exterior. Como hemos visto, se pueden crear servidores MCP personalizados para tareas específicas, como nuestro scraper de Amazon. La integración MCP de Bright Data mejora esto aún más al ofrecer capacidades de raspado web de nivel empresarial que eluden las protecciones anti-bot y proporcionan datos estructurados listos para la IA.
También hemos seleccionado algunos de los mejores recursos sobre IA y grandes modelos lingüísticos (LLM). No deje de consultarlos para obtener más información:






