

En esta publicación del blog, aprenderás:
- Qué es Amazon SageMaker y el valor que aporta al aprendizaje automático.
- Por qué los datos web son esenciales para una ingeniería de características exitosa.
- Dónde obtener datos web de alta calidad para la ingeniería de características y otros escenarios de aprendizaje automático.
- Cómo realizar ingeniería de características en Amazon SageMaker usando conjuntos de datos con datos web.
¡Comencemos!
¿Qué Es Amazon SageMaker?
Amazon SageMaker es un servicio completamente administrado diseñado para ayudarte a construir, entrenar e implementar modelos de aprendizaje automático y aplicaciones de IA a escala. Proporciona un entorno unificado de extremo a extremo para análisis e IA.
Te permite acceder a datos de múltiples fuentes, ya sea almacenados en lagos de datos de Amazon S3, almacenes de datos Redshift, o sistemas de terceros y federados. Todo ello garantizando seguridad y gobernanza de nivel empresarial.
En resumen, SageMaker simplifica los flujos de trabajo de ML y acelera el desarrollo de modelos, desde la ingeniería de características hasta la implementación del modelo. Estas son las principales características y capacidades que ofrece:
- SageMaker Unified Studio: Un entorno de desarrollo único para construir, entrenar e implementar modelos de ML e IA generativa usando infraestructura completamente administrada y herramientas integradas.
- Desarrollo de modelos y MLOps: Incluye plantillas predefinidas, HyperPod y JumpStart para prototipado rápido, entrenamiento y operacionalización de modelos.
- Soporte de IA generativa: Construye y escala aplicaciones con Amazon Bedrock y aprovecha asistentes de IA integrados como Amazon Q Developer.
- Procesamiento de datos y análisis SQL: Prepara, analiza e integra datos usando frameworks de código abierto en Amazon Athena, EMR, Glue y Redshift.
- Arquitectura Lakehouse: Unifica el acceso a datos aislados en distintos sistemas de almacenamiento para respaldar análisis e IA integrales.
Una Introducción a la Ingeniería de Características con Datos Web
La ingeniería de características es el proceso de transformar datos brutos en variables significativas, llamadas “características”, que los modelos de aprendizaje automático pueden utilizar de manera más efectiva. En lugar de alimentar un modelo con datos sin procesar, la idea es crear métricas derivadas que capturen mejor los patrones en el conjunto de datos fuente.
Los ejemplos incluyen agregar valores, normalizar puntuaciones, combinar variables relacionadas o crear ratios que resalten relaciones entre distintos campos. Una buena ingeniería de características puede incluso tener un impacto mayor en el rendimiento del modelo que la elección del algoritmo en sí. Esto se debe a que las características bien diseñadas ayudan a los modelos a identificar señales que de otro modo permanecerían ocultas.
Los datos web son particularmente valiosos para la ingeniería de características porque reflejan la actividad del mundo real a escala. Los sitios web públicos contienen grandes cantidades de información sobre empresas, productos, empleos, reseñas, precios y comportamiento de los usuarios. Estas señales pueden transformarse en características como indicadores de popularidad, métricas de demanda del mercado, puntuaciones de sentimiento o tendencias de contratación. Tales características pueden mejorar significativamente el rendimiento de tus pipelines de aprendizaje automático.
Sin embargo, trabajar con datos web también presenta varios desafíos. Los datos pueden ser ruidosos, incompletos o inconsistentes. Esto puede afectar enormemente la calidad de los datos de entrada. Además, muchos sitios web adoptan medidas anti-bot.
Por ello, usar el scraping web para potenciar el aprendizaje automático es complicado. Requiere que los datos recopilados sean limpiados, validados y preparados antes de poder usarse en un pipeline de ML.
Dónde Obtener Datos Web de Alta Calidad en Grandes Volúmenes
Como habrás comprendido, los datos web juegan un papel fundamental en la ingeniería de características. Al mismo tiempo, obtenerlos de manera confiable y para uso empresarial es difícil. Recopilar datos de unas pocas páginas puede parecer sencillo si sigues una hoja de ruta de scraping web, pero hacerlo de forma consistente en muchos dominios o en un sitio grande es mucho más complejo.
Los sitios web cambian frecuentemente su estructura, aplican límites de velocidad y despliegan protecciones anti-bot que bloquean solicitudes automatizadas. Además, incluso cuando logras recopilar los datos, garantizar que sean de alta calidad, completos y actualizados puede ser un desafío.
Por esta razón, muchas organizaciones recurren a empresas de conjuntos de datos web y proveedores de datos web como Bright Data. Estas plataformas te dan acceso a grandes cantidades de datos web para que no tengas que construir y mantener una infraestructura de scraping.
Bright Data ofrece cientos de conjuntos de datos de más de 215 dominios web populares, con más de 17 mil millones de registros en total. Estos conjuntos de datos contienen datos web continuamente actualizados, estructurados, listos para usar y optimizados para aplicaciones de ML e IA. ¡Explora el mercado de conjuntos de datos!
Si los conjuntos de datos prerecopilados no satisfacen tus necesidades, Bright Data también ofrece APIs de Scraping Web y otras herramientas de recopilación de datos. Estas te ayudan a obtener datos frescos de sitios web bajo demanda sin tener que gestionar los desafíos del scraping tú mismo.
Lo que distingue a Bright Data es su infraestructura de recopilación de datos. Está construida sobre una red de proxies global con más de 150 millones de IPs en más de 195 países, logrando un tiempo de actividad del 99,99% y tasas de éxito del 99,95%. Esta base facilita la construcción de aplicaciones basadas en datos y pipelines de ML impulsados por datos web confiables.
Cómo Realizar Ingeniería de Características con Datos Web en Amazon SageMaker
En esta sección paso a paso, serás guiado a través del proceso de realizar ingeniería de características en Amazon SageMaker.
Comenzarás con un conjunto de datos de Glassdoor de Bright Data, lo subirás a Amazon S3, lo cargarás en un notebook de SageMaker y aplicarás ingeniería de características para crear métricas significativas. Una vez preparadas las características, las usarás para entrenar un modelo de aprendizaje automático predictivo para alta satisfacción de los empleados.
Ten en cuenta que esto es solo un ejemplo, y muchos otros casos de uso son posibles.
¡Sigue las instrucciones!
Requisitos Previos
Para seguir esta guía, asegúrate de tener:
- Una cuenta de AWS (incluso en prueba gratuita).
- Una cuenta de Bright Data.
- Un bucket de S3 definido en tu cuenta de AWS.
- Conocimientos básicos de Python, especialmente en desarrollo de aprendizaje automático y ciencia de datos.
A partir de ahora, asumiremos que tu bucket de S3 se llama bright-data-sagemaker:
Paso #1: Obtener el Conjunto de Datos de Entrada desde Bright Data
El primer paso es obtener los datos web de entrada. Para la ingeniería de características, es mejor comenzar con un conjunto de datos grande y de alta calidad. En este ejemplo, aprovecharemos las extensas colecciones de conjuntos de datos de Bright Data, centrándonos en un conjunto de datos de Glassdoor como se planificó anteriormente.
Alternativa: Si prefieres recopilar datos nuevos, puedes usar una de las APIs de Scraping Web de Bright Data para obtener conjuntos de datos frescos, estructurados y listos para ML. Estas APIs ofrecen una opción de entrega que puede enviar datos directamente a tu cuenta de Amazon S3, haciendo que la integración con SageMaker sea perfecta.
Ahora, si aún no tienes una cuenta de Bright Data, comienza creando una. De lo contrario, simplemente inicia sesión.
En el panel de control de Bright Data, selecciona la opción de menú “Web Datasets”. Navega a la pestaña “Mercado de conjuntos de datos” para explorar los conjuntos de datos disponibles:
Aquí puedes explorar más de 200 conjuntos de datos scrapeados de más de 155 dominios, que contienen miles de millones de registros.
Ahora, busca el conjunto de datos “Glassdoor companies overview information” y abre su página:
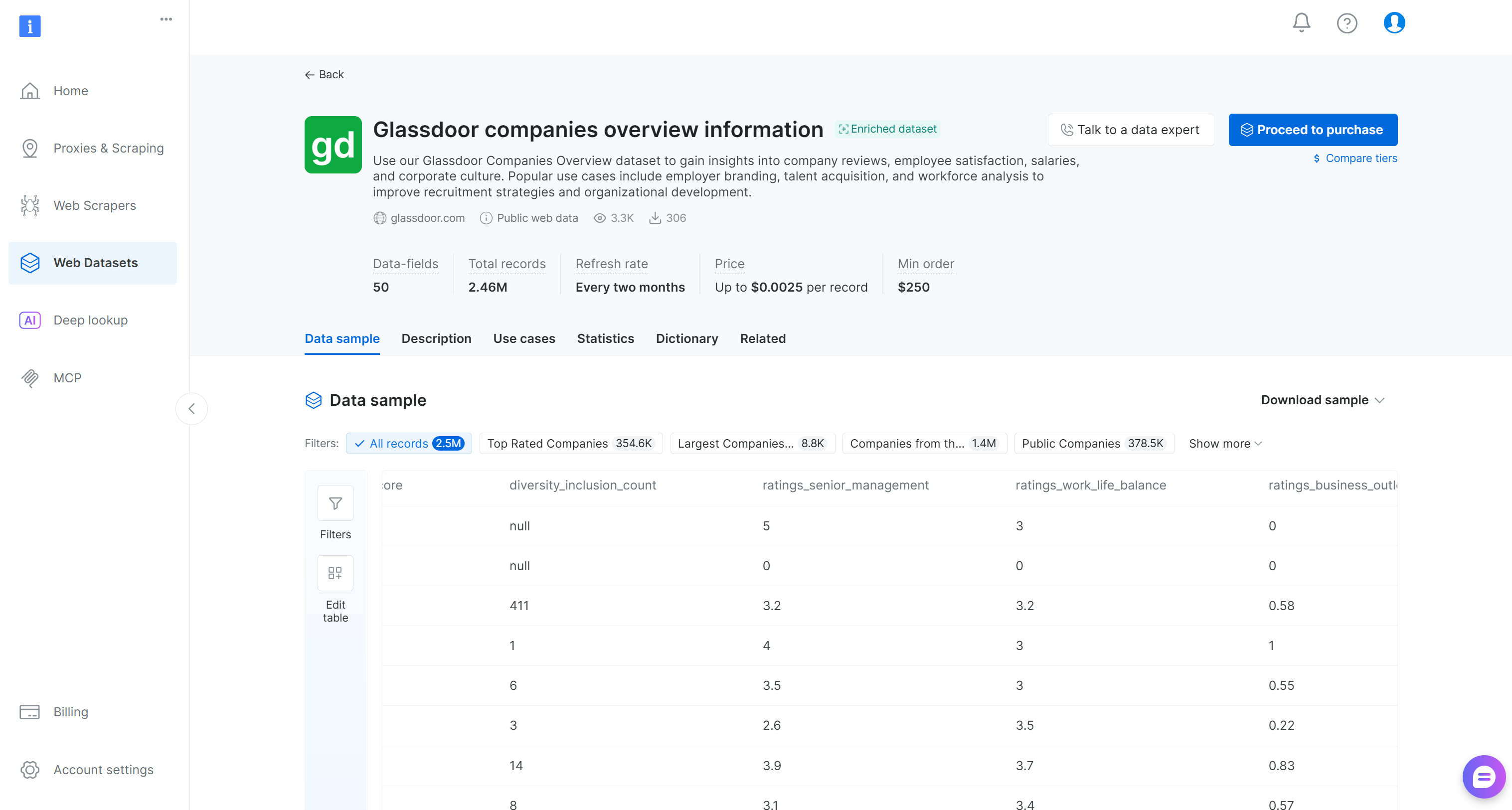
Este conjunto de datos incluye reseñas de empresas, puntuaciones de satisfacción de empleados, salarios e información sobre cultura corporativa. Los casos de uso populares incluyen branding del empleador, adquisición de talento y análisis de la fuerza laboral. Contiene más de 2,46 millones de entradas con 50 campos de datos.
Puedes elegir entre comprar un subconjunto filtrado o descargar una muestra gratuita. En un escenario de producción, cuanto mayor sea el conjunto de datos de entrada, más confiables serán tus resultados de ingeniería de características.
Para este tutorial, al ser solo un ejemplo, utilizaremos la muestra gratuita. Para obtenerla, haz clic en el desplegable “Download sample” y selecciona la opción “Download as JSON”:
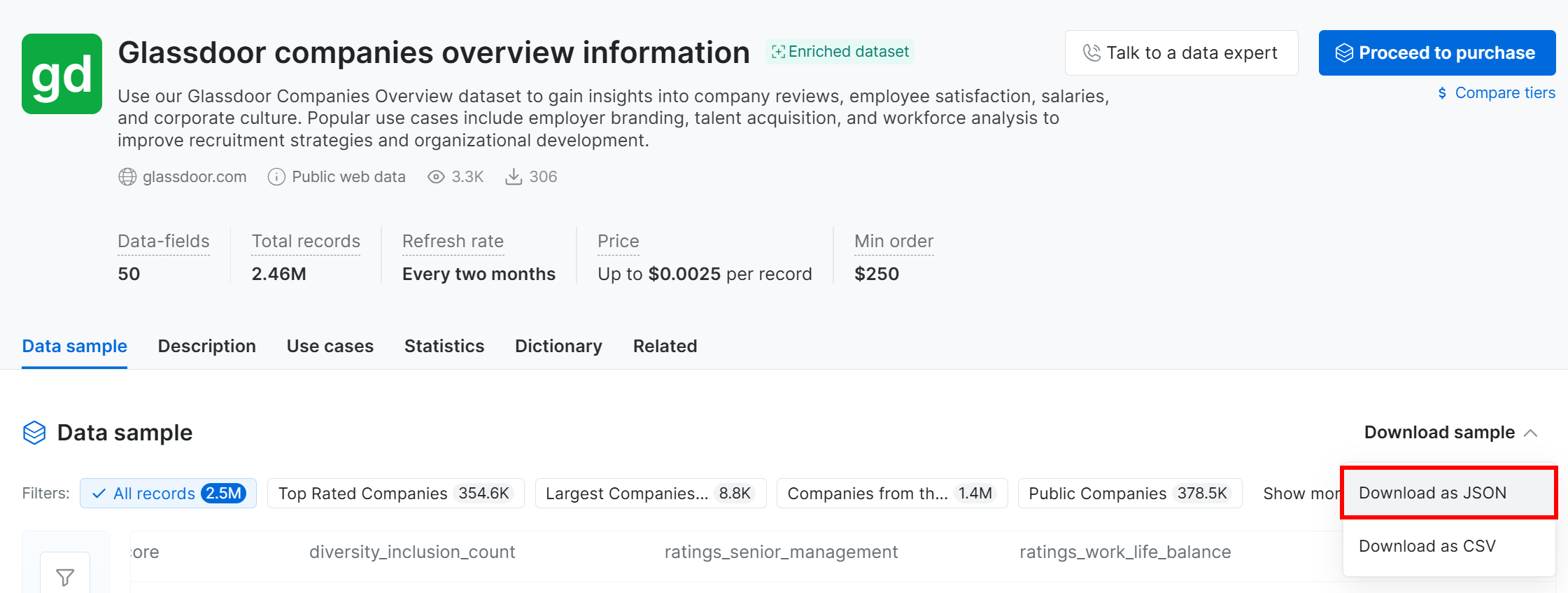
Recibirás un archivo de muestra llamado Glassdoor companies overview information.json. Este archivo contiene 1.000 registros de empresas, cada uno con 50 campos.
Renombra el archivo a glassdoor-companies.json y prepárate para subirlo a tu bucket de S3. Será usado como entrada para tu notebook de ingeniería de características en SageMaker. ¡Bien hecho!
Paso #2: Subir los Datos Web a tu Bucket de S3
Ve a la página de tu bucket de Amazon S3 y haz clic en el botón “Upload” para agregar el archivo glassdoor-companies.json. Una vez subido, aparecerá en tu bucket de esta manera:
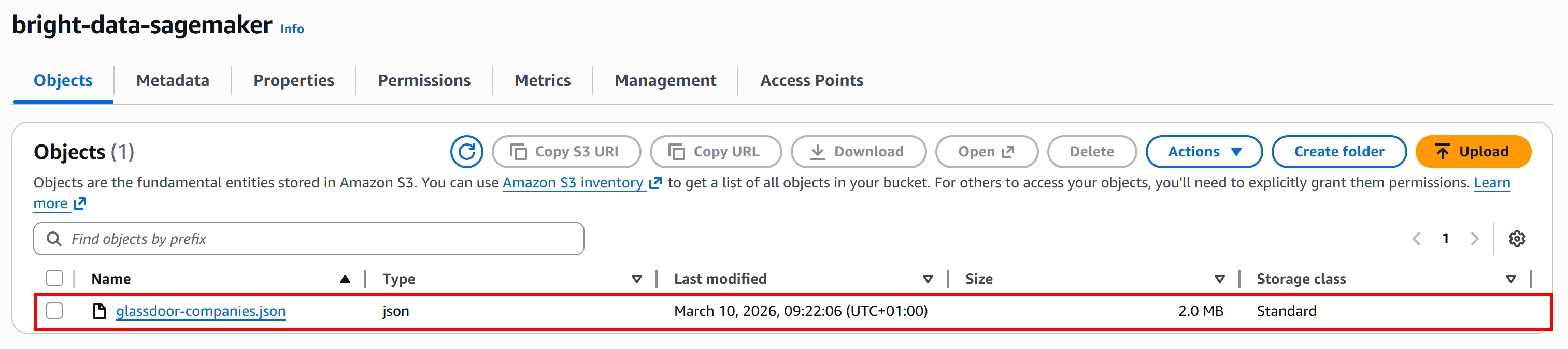
Alternativamente, puedes usar uno de los muchos clientes de Amazon S3 para subir el archivo.
Recuerda: Con las APIs de Scraping Web de Bright Data, puedes enviar datos scrapeados directamente a Amazon S3.
¡Excelente! Ahora tienes algunos datos web de entrada para la ingeniería de características en Amazon SageMaker.
Paso #3: Comenzar con Amazon SageMaker
Inicia sesión en la consola de AWS y busca “SageMaker”. Selecciona el servicio para abrir su página principal:
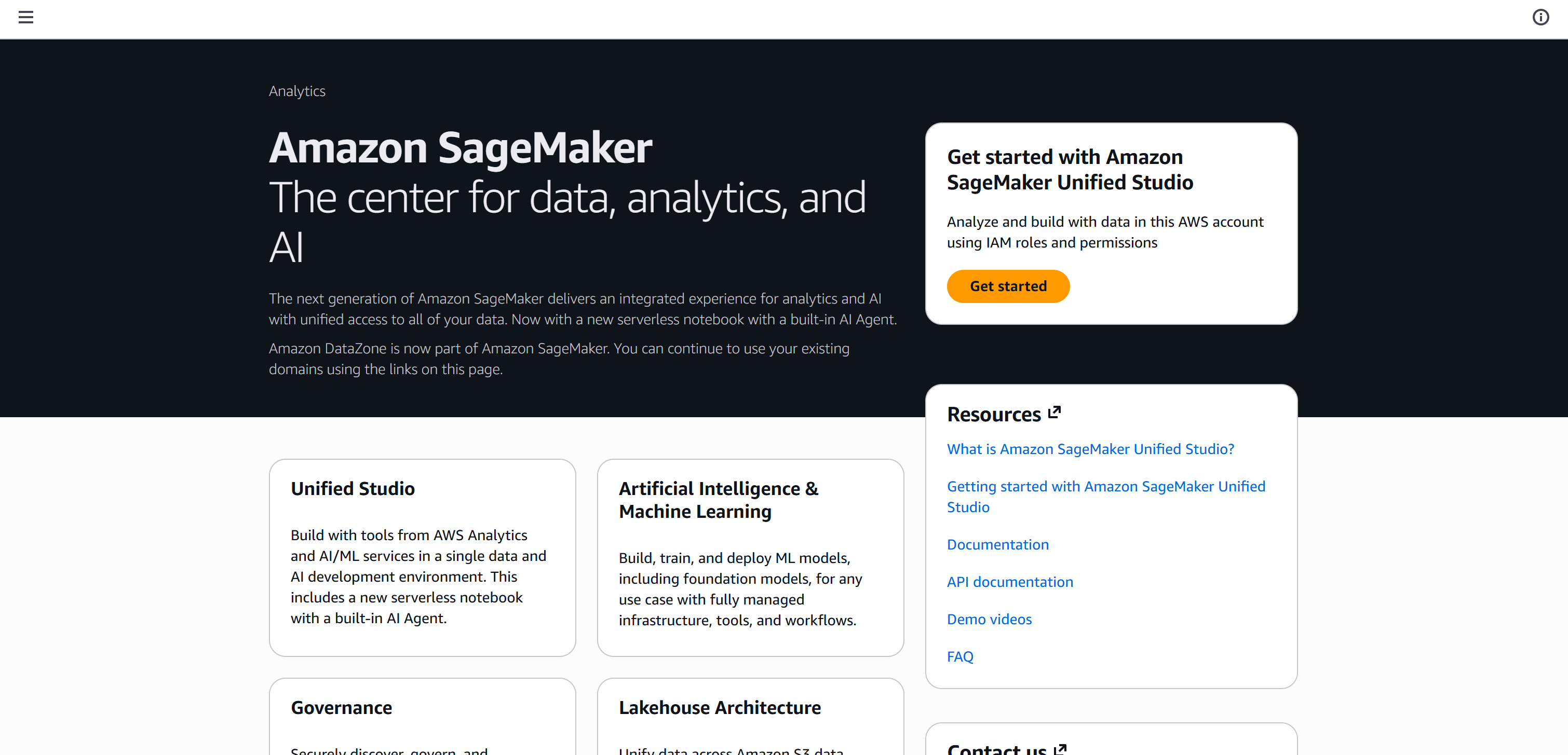
Haz clic en el botón “Get started” para iniciar tu experiencia con Amazon SageMaker.
En la página de configuración, para una configuración automática de IAM, verifica que esté seleccionada la opción “Auto-create a new role with admin permissions”. Continúa presionando el botón “Set up”:
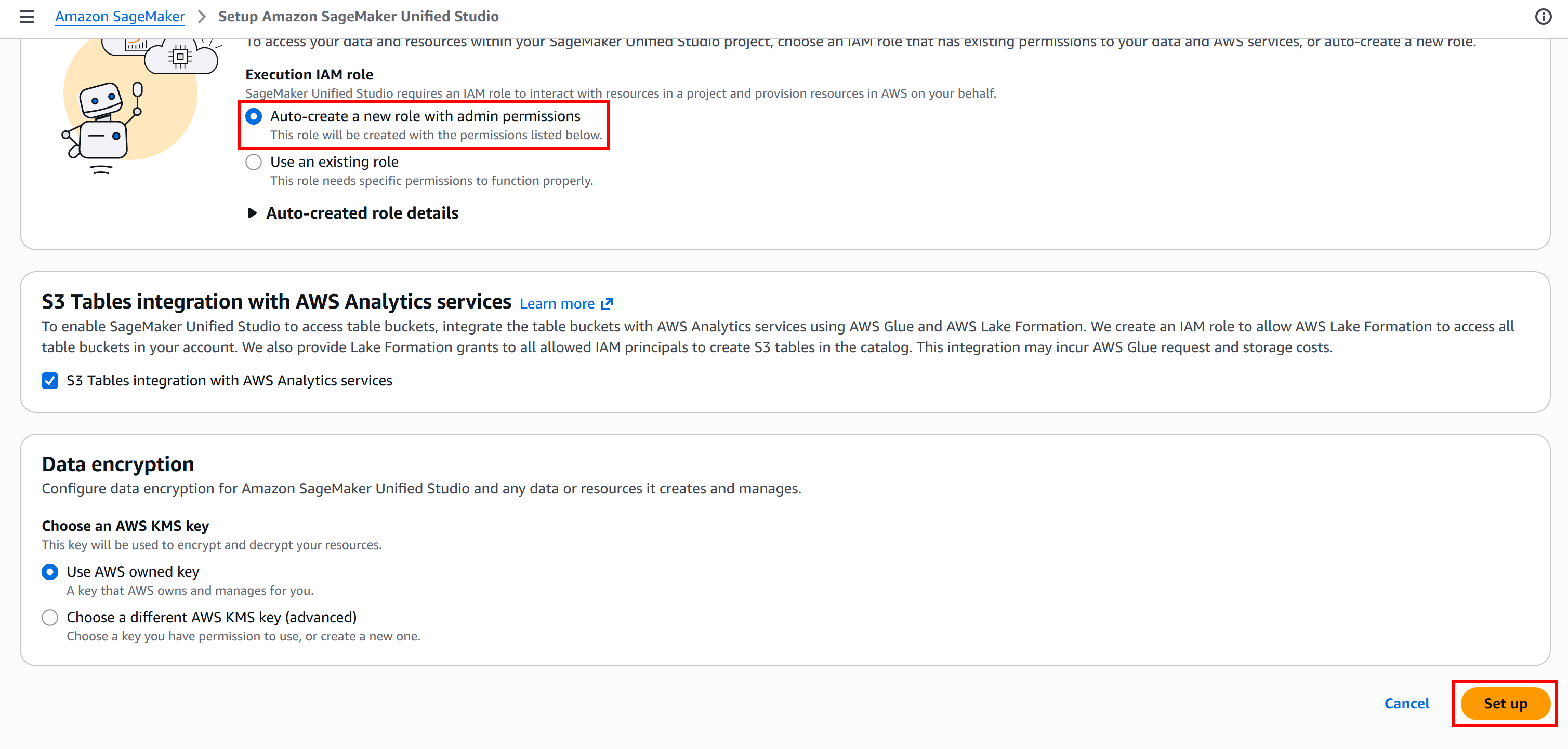
El proceso de inicialización puede tardar unos minutos, así que ten paciencia. Mientras se ejecuta, verás el mensaje “Setting up Amazon SageMaker Unified Studio…”.
Una vez completada la configuración, llegarás a la siguiente página:
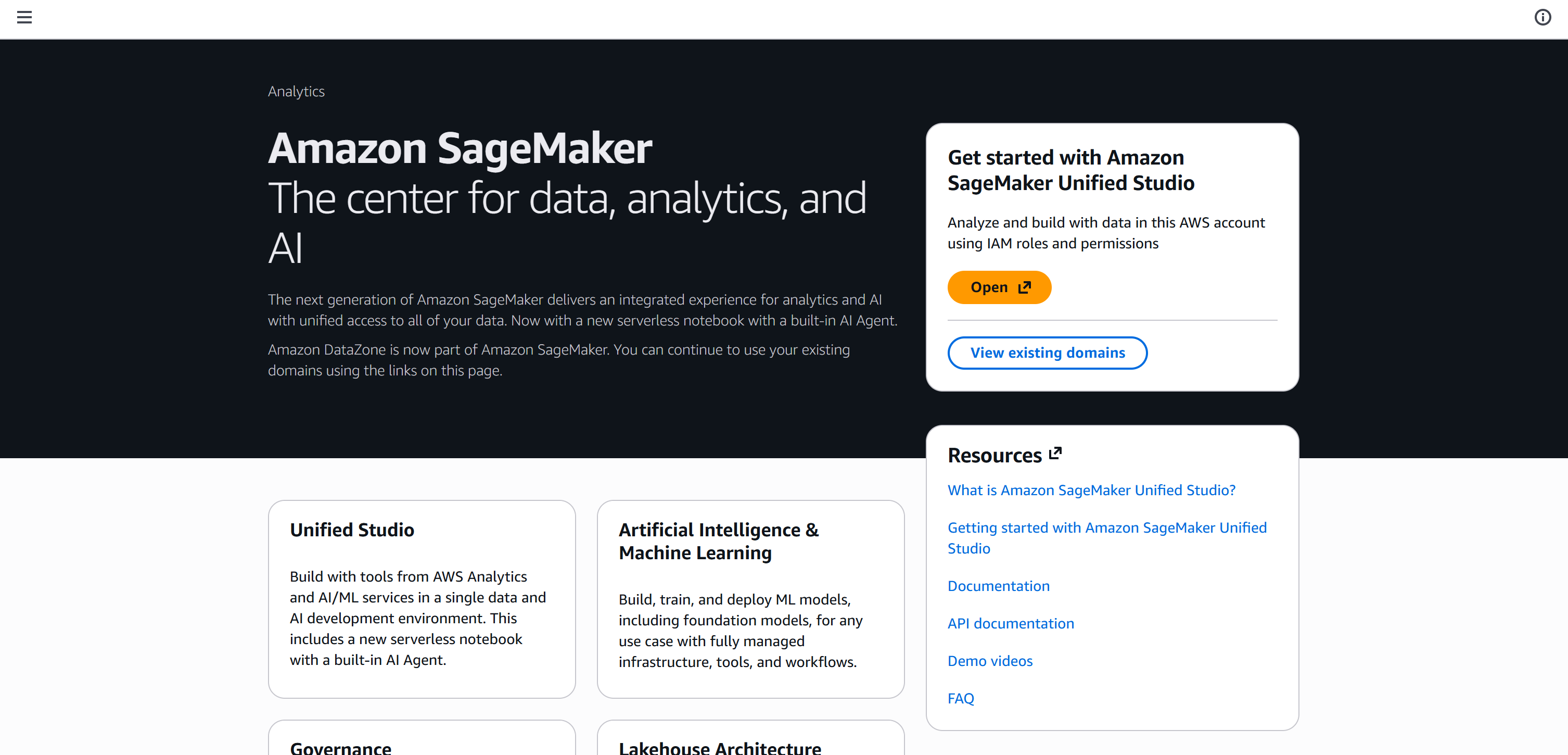
Haz clic en “Open” para lanzar Amazon SageMaker Unified Studio:
Desde aquí, puedes explorar y gestionar tu entorno de SageMaker, incluyendo el desarrollo y ejecución de notebooks. ¡Genial!
Paso #4: Crear un Nuevo Notebook
En Amazon SageMaker Unified Studio, haz clic en el botón “Build in the notebook” para crear un nuevo notebook:

Así es como debería verse tu nuevo notebook de SageMaker:
Considera darle a tu notebook un nombre descriptivo, como “Company Data Feature Engineering”.
Un notebook de Amazon SageMaker es una instancia de cómputo de aprendizaje automático administrada que ejecuta Jupyter Notebook. Proporciona todo lo que necesitas para preparar y procesar datos, escribir y probar código de entrenamiento, implementar modelos en el hosting de SageMaker y validar tus modelos.
¡Excelente! Ahora tienes todos los componentes necesarios para implementar la lógica de ingeniería de características en SageMaker.
Paso #5: Cargar los Datos Web de Entrada
El primer paso es cargar los datos web de entrada de Glassdoor de Bright Data en tu notebook de SageMaker.
En el panel “Data Explorer” de la izquierda, expande el desplegable “Buckets”. Localiza tu bucket de S3 y encuentra el archivo glassdoor-companies.json. Haz clic en el menú de hamburguesa junto al archivo y selecciona la opción “Read as dataframe”:
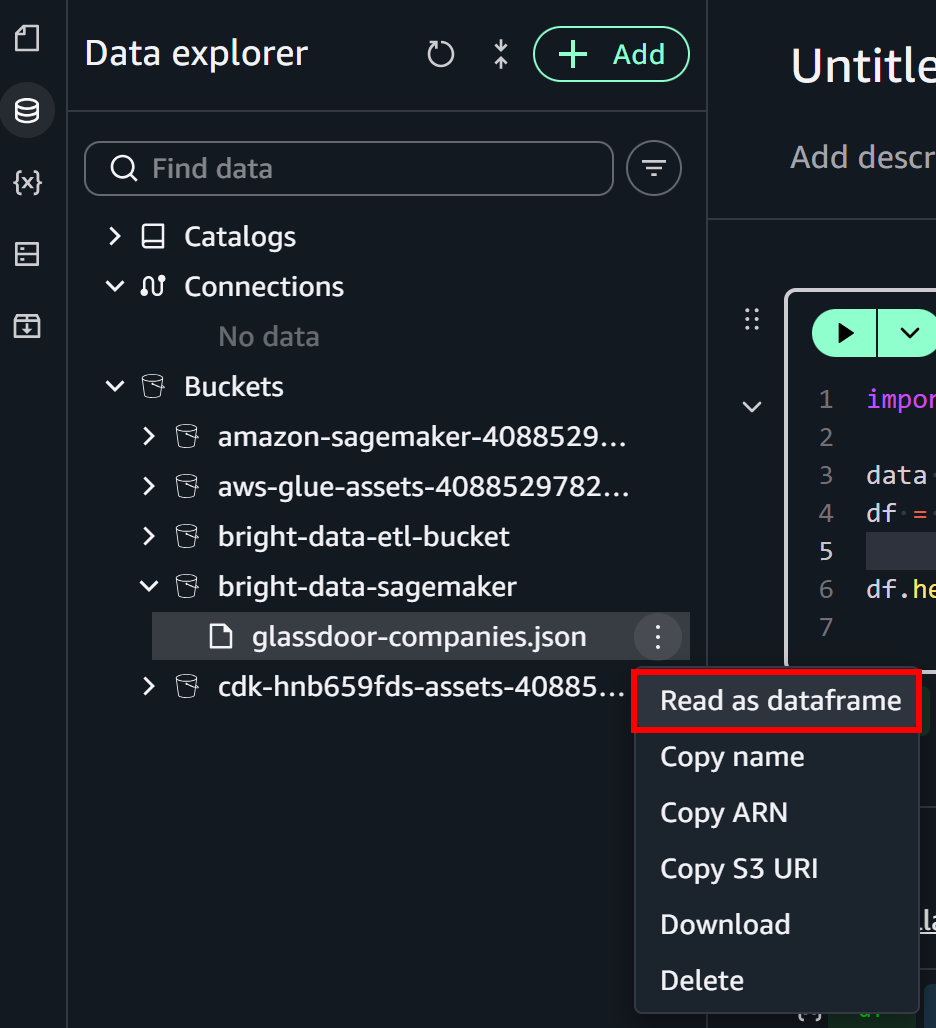
Esto llenará la celda inicial del notebook con la lógica para cargar el archivo desde S3:
import pandas as pd
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")Nota: Reemplaza bright-data-sagemaker con el nombre de tu bucket de S3.
Completa la lógica de importación de datos en la primera celda de la siguiente manera:
import pandas as pd
# Load the input data from the S3 bucket
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")
# Normalize the structured JSON fields
df = pd.json_normalize(data.to_dict(orient="records"))
# Print the first 10 lines
df.head(10)Este fragmento de código carga y preprocesa un conjunto de datos JSON desde un bucket de S3 para su análisis en Python. Usa pd.read_json() para leer el archivo, luego pd.json_normalize() para aplanar los campos JSON anidados en un DataFrame tabular. Finalmente, df.head(10) muestra las primeras 10 filas, dando una vista previa rápida de los datos estructurados.
Ejecuta la celda presionando el botón “▶”. Deberías ver una vista previa como esta:
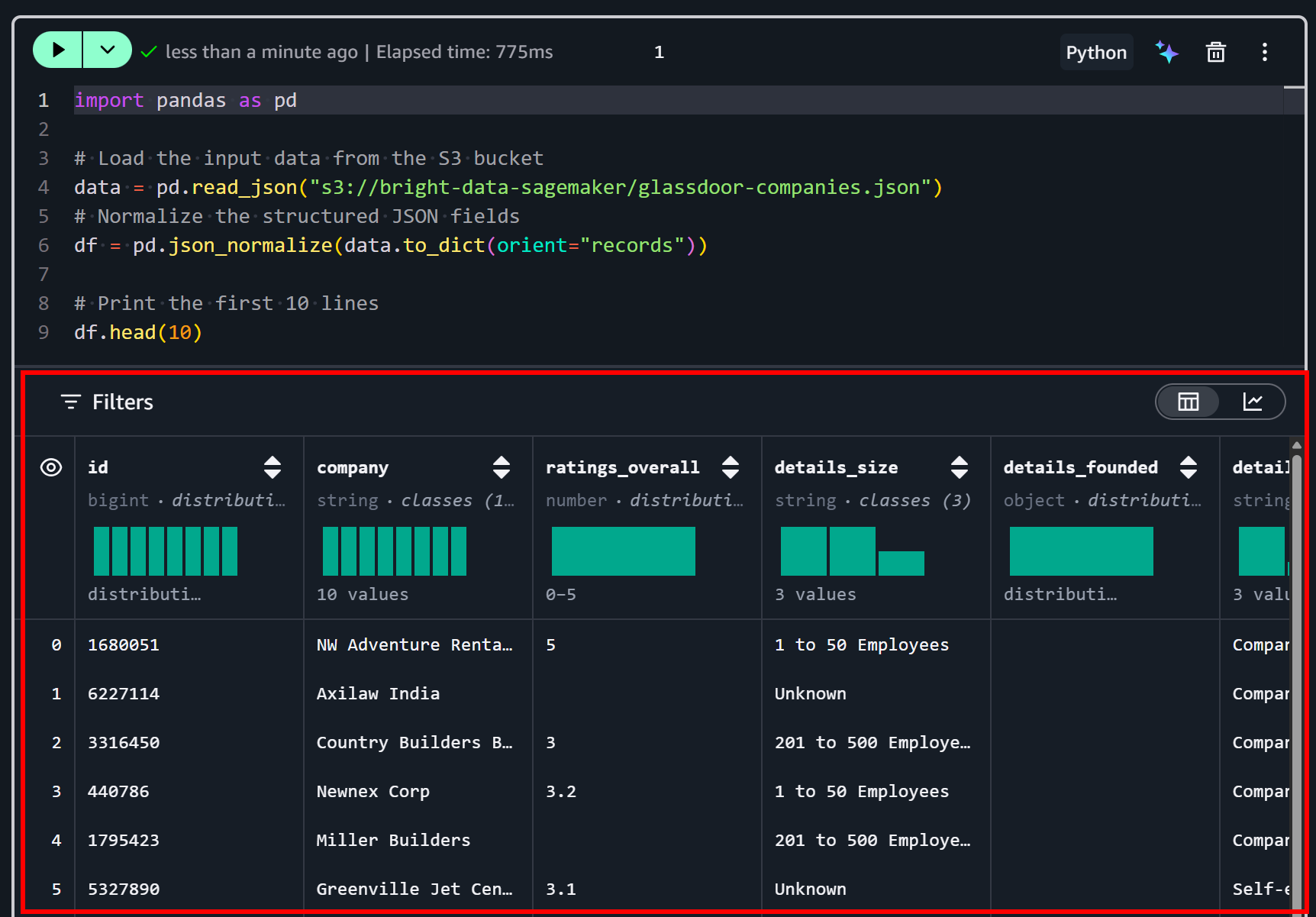
Como puedes ver, el conjunto de datos se ha cargado correctamente. Contiene 50 campos de datos, tal como se lista en la pestaña “Dictionary” de la página del conjunto de datos de Bright Data:
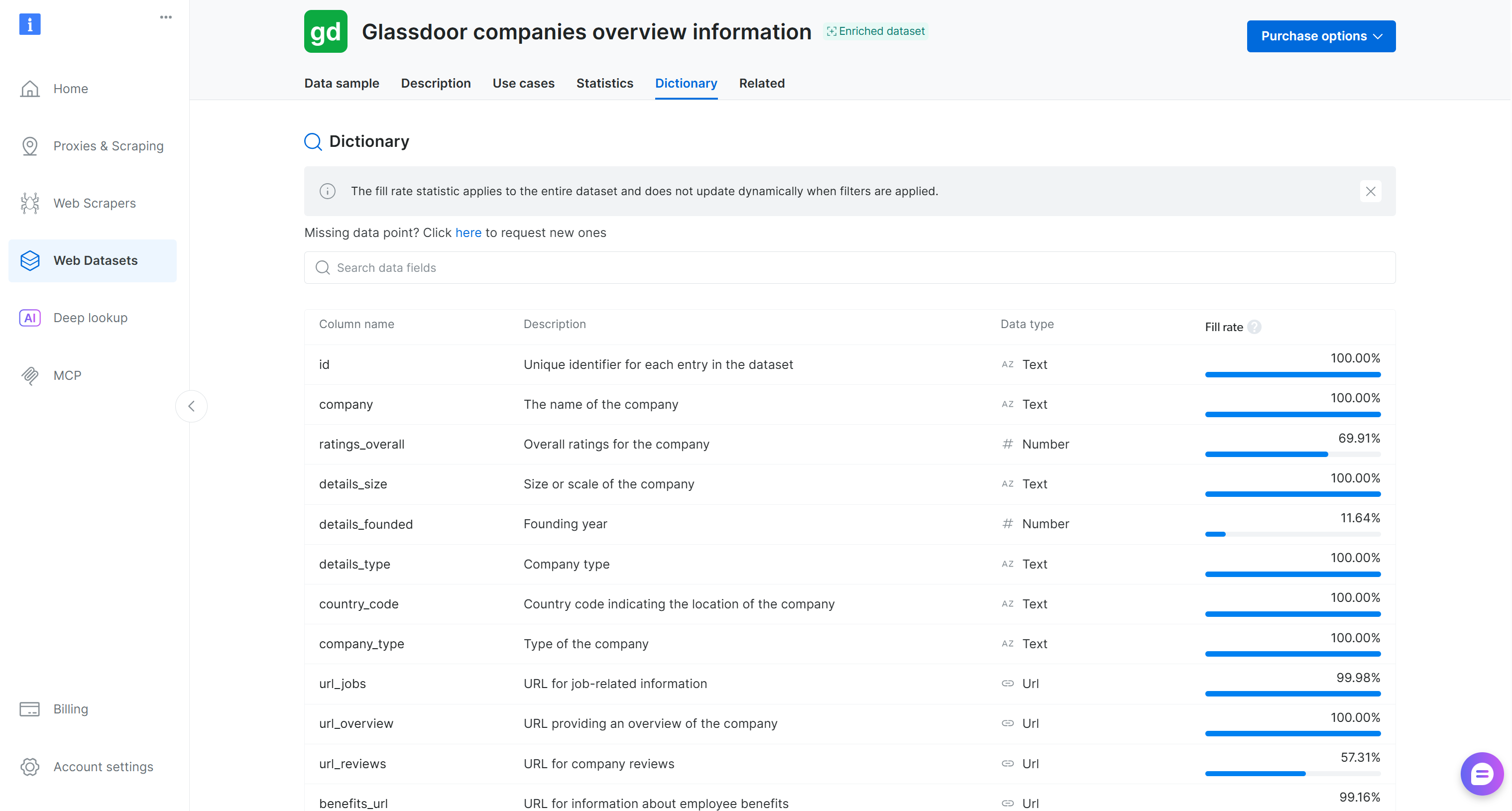
Tienes datos web de entrada listos para la ingeniería de características. ¡Fantástico!
Paso #6: Pre-Procesar los Datos de Entrada
Ahora que has importado tu conjunto de datos al notebook, el siguiente paso es limpiarlo y prepararlo para la ingeniería de características.
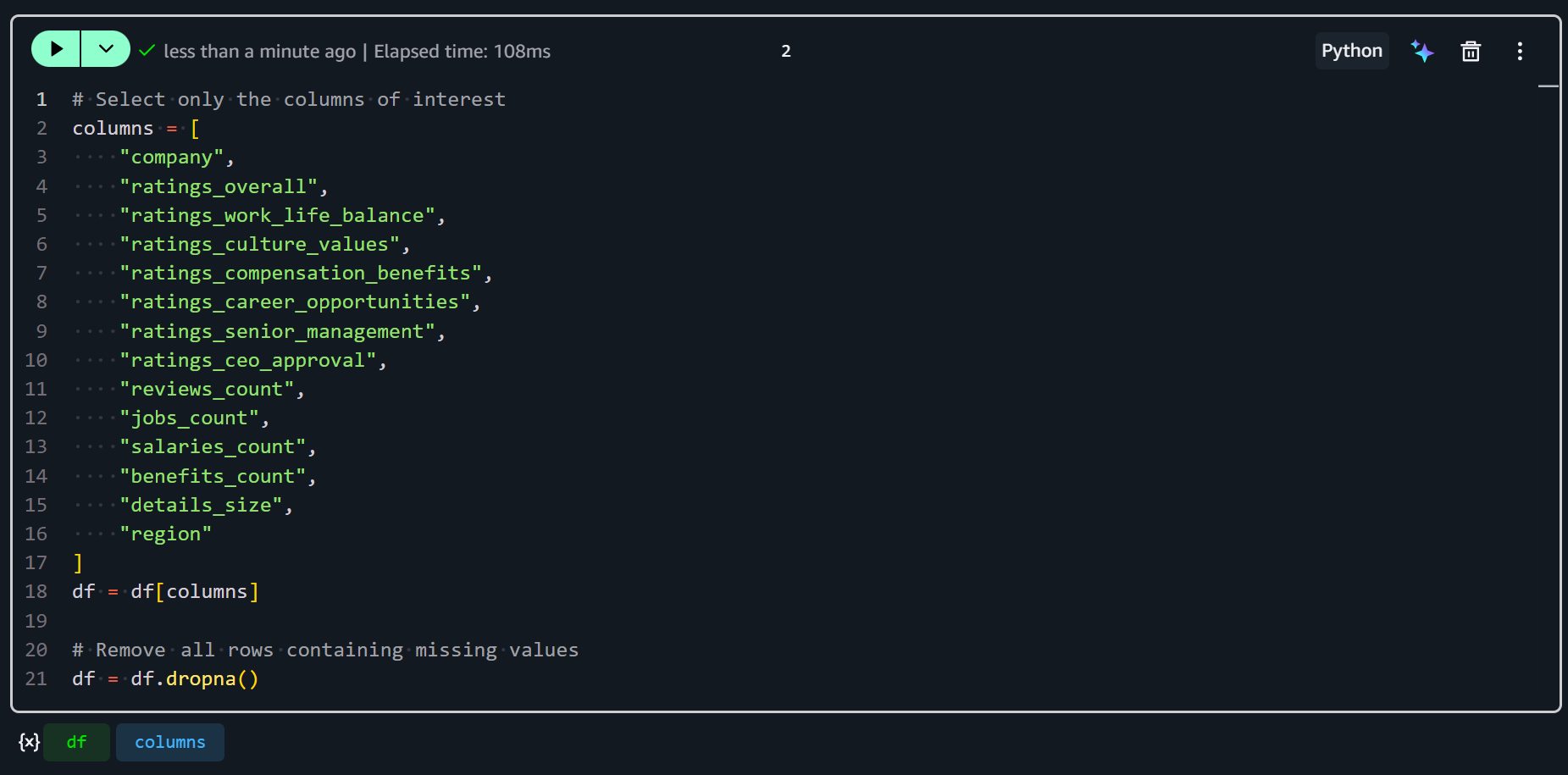
Agrega una nueva celda en tu notebook de SageMaker e ingresa el siguiente código:
# Select only the columns of interest
columns = [
"company",
"ratings_overall",
"ratings_work_life_balance",
"ratings_culture_values",
"ratings_compensation_benefits",
"ratings_career_opportunities",
"ratings_senior_management",
"ratings_ceo_approval",
"reviews_count",
"jobs_count",
"salaries_count",
"benefits_count",
"details_size",
"region"
]
df = df[columns]
# Remove all rows containing missing values
df = df.dropna()Este fragmento selecciona solo las columnas de interés, manteniendo tu conjunto de datos enfocado en métricas e identificadores relevantes. Luego, utiliza df.dropna() para eliminar cualquier fila que contenga valores faltantes en las columnas seleccionadas. Esto garantiza que tus datos estén limpios y consistentes para la ingeniería de características.
Tu nueva celda se verá así:
¡Excelente! Tu conjunto de datos de entrada está ahora listo para la ingeniería de características en SageMaker.
Paso #7: Definir las Características
Es hora de definir las características que usarás para el aprendizaje automático. Recuerda que las características son columnas derivadas que resumen o transforman datos brutos en métricas significativas que representan mejor los patrones subyacentes.
En este ejemplo, agregarás características que capturan la cultura empresarial, la compensación, la popularidad y la actividad de crecimiento.
Primero, la característica culture_score combina múltiples calificaciones relacionadas en una única métrica que representa el entorno cultural general de una empresa:
df["culture_score"] = (
df["ratings_culture_values"] +
df["ratings_work_life_balance"] +
df["ratings_senior_management"]
) / 3Promedia tres columnas de calificaciones:
ratings_culture_values: Describe qué tan bien la empresa encarna sus valores declarados.ratings_work_life_balance: Califica la percepción de los empleados sobre el equilibrio entre trabajo y vida personal.ratings_senior_management: Rastrea la percepción del liderazgo y la gestión.
Sumar las tres calificaciones y dividir entre 3 produce una puntuación normalizada. La puntuación resultante mantiene la misma escala que las calificaciones originales y otorga igual peso a cada aspecto de la cultura.
Segundo, la característica compensation_score representa una visión combinada de la satisfacción de los empleados con el salario y el crecimiento profesional:
df["compensation_score"] = (
df["ratings_compensation_benefits"] +
df["ratings_career_opportunities"]
) / 2Involucra:
ratings_compensation_benefits: Marca la satisfacción de los empleados con el salario y los beneficios.ratings_career_opportunities: Rastrea la satisfacción de los empleados con las oportunidades de avance profesional.
Al promediar, la característica se escala de manera consistente con otras puntuaciones para equilibrar ambos aspectos por igual.
Tercero, la característica review_popularity mide con qué frecuencia una empresa es reseñada en Glassdoor:
df["review_popularity"] = df["reviews_count"].apply(lambda x: x ** 0.5)Se obtiene aplicando una transformación de raíz cuadrada al número de reseñas. ¿Por qué la raíz cuadrada? Porque los recuentos de reseñas suelen estar muy sesgados (algunas empresas tienen miles de reseñas, muchas tienen muy pocas). Tomar la raíz cuadrada reduce el impacto de los valores extremadamente altos y estabiliza la varianza, facilitando el procesamiento y análisis.
Cuarto, la característica hiring_intensity estima qué tan activamente está contratando una empresa en relación con su actividad de reseñas:
df["hiring_intensity"] = df["jobs_count"] / (df["reviews_count"] + 1)Se calcula dividiendo el número de ofertas de trabajo abiertas (jobs_count) entre el número de reseñas más 1 (para evitar la división por cero para empresas sin reseñas).
Los valores más altos indican empresas que están contratando activamente en comparación con cuántos empleados están dejando reseñas. Esto puede ser un indicador de actividad de crecimiento o expansión.
Juntándolo todo, obtendrás:
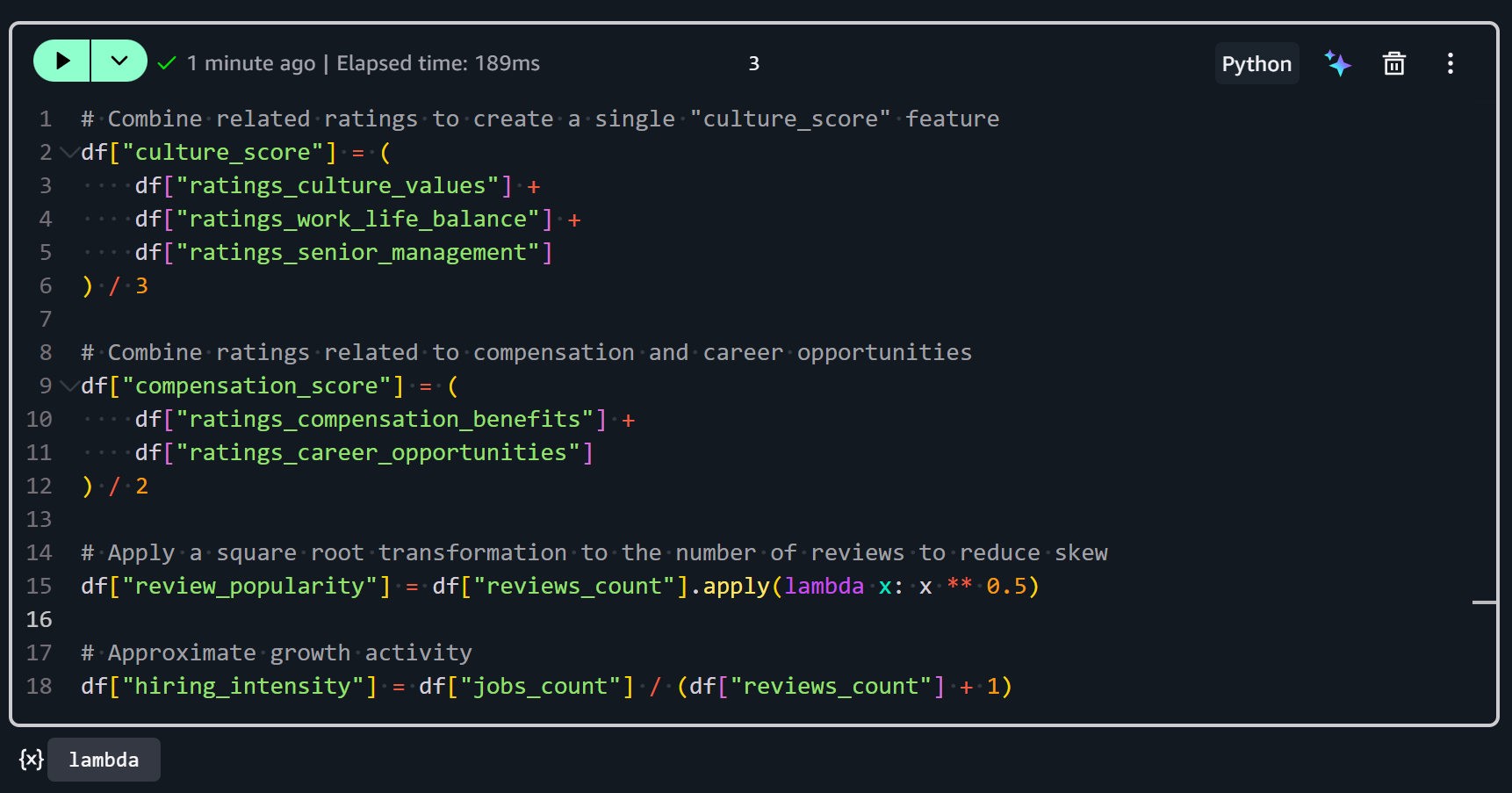
Después de ejecutar estas transformaciones, tu conjunto de datos ahora contiene características derivadas que combinan calificaciones y recuentos brutos en métricas más informativas. ¡Genial!
Paso #8: Establecer la Variable Objetivo
Ahora que tus características están definidas, el siguiente paso es establecer la variable objetivo para tu tarea de aprendizaje automático. La variable objetivo representa el resultado que quieres que tu modelo prediga. En este caso, predecirás si una empresa tiene alta satisfacción de los empleados.
Para establecer el objetivo, agrega una nueva celda en tu notebook y añade este código:
# Define the target variable
df["high_satisfaction"] = (df["ratings_overall"] >= 4).astype(int)Esto crea un campo booleano donde las empresas con una calificación general de 4 o superior se marcan como True (alta satisfacción), y las demás como False (baja satisfacción).

Muchos algoritmos de aprendizaje automático requieren una variable objetivo numérica. Al convertir las calificaciones de satisfacción en una etiqueta booleana binaria 0/1, puedes entrenar modelos para tareas de clasificación. Esto te ayuda a predecir si una empresa probablemente tendrá empleados altamente satisfechos basándose en las características que creaste. ¡Logra eso en el siguiente paso!
Paso #9: Entrenar el Modelo de ML para la Predicción de Satisfacción
Con tus características y variable objetivo definidas, ahora puedes entrenar un modelo de aprendizaje automático para predecir la alta satisfacción de los empleados.
El modelo de ML elegido es XGBoost, un algoritmo de gradient boosting que funciona excepcionalmente bien con datos tabulares y tareas de clasificación. Es adecuado para predecir la variable high_satisfaction basándose en una mezcla de características numéricas y derivadas.
Agrega una nueva celda en tu notebook y añade la lógica para entrenar tu modelo con:
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
# Define the features to use for prediction
features = [
"culture_score",
"compensation_score",
"ratings_ceo_approval",
"review_popularity",
"hiring_intensity"
]
# Separate input features (X) and target variable (y)
X = df[features]
y = df["high_satisfaction"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Initialize the XGBoost classifier with some reasonable hyperparameters
model = XGBClassifier(
n_estimators=500,
max_depth=5,
learning_rate=0.05,
eval_metric="logloss"
)
# Train the model on the training data
model.fit(X_train, y_train)El fragmento anterior prepara y entrena un modelo de aprendizaje automático para predecir la alta satisfacción de los empleados. Selecciona las características diseñadas y divide los datos en conjuntos de entrenamiento y prueba. Luego, inicializa un clasificador XGBoost con hiperparámetros ajustados. Finalmente, ajusta el modelo a los datos de entrenamiento.
Ejecuta la celda para entrenar efectivamente el modelo predictivo:
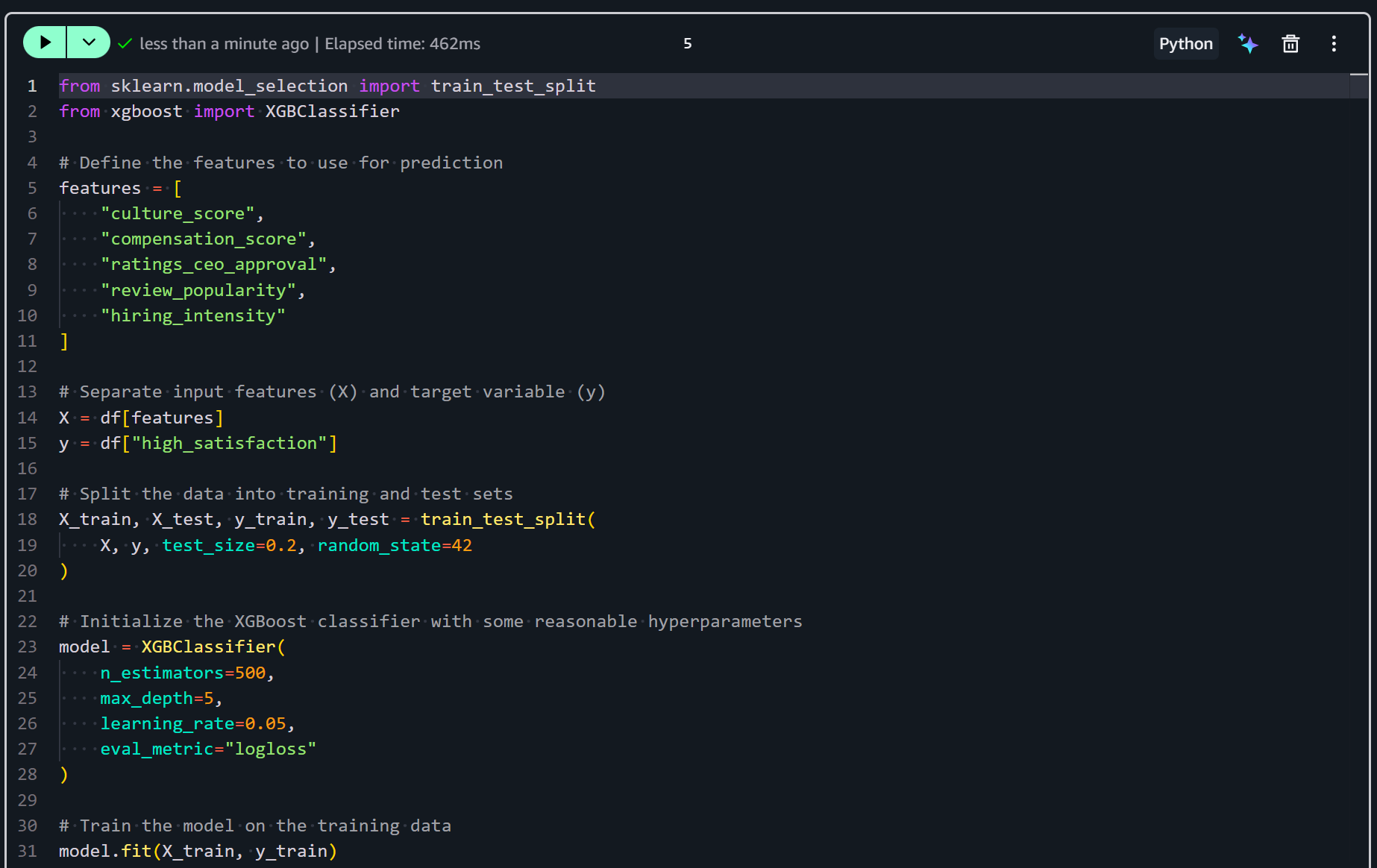
Después de este paso, tu clasificador XGBoost está entrenado y listo para evaluación y predicción. ¡El siguiente paso es evaluar su rendimiento!
Paso #10: Evaluar el Rendimiento del Modelo
El paso final es evaluar qué tan bien funciona tu modelo con datos no vistos. Agrega una nueva celda en tu notebook con este código:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, roc_auc_score, accuracy_score
# Use the trained model to predict labels on the test set
pred = model.predict(X_test)
print(classification_report(y_test, pred))
# Confusion matrix
cm = confusion_matrix(y_test, pred)
print("\nConfusion Matrix:\n", cm)
# ROC-AUC score
roc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
print("\nROC-AUC:", roc)Presiona el botón “Run All” para ejecutar todos los pasos y calcular las métricas:

Después de que se ejecute la última celda, deberías ver una salida similar a esta:
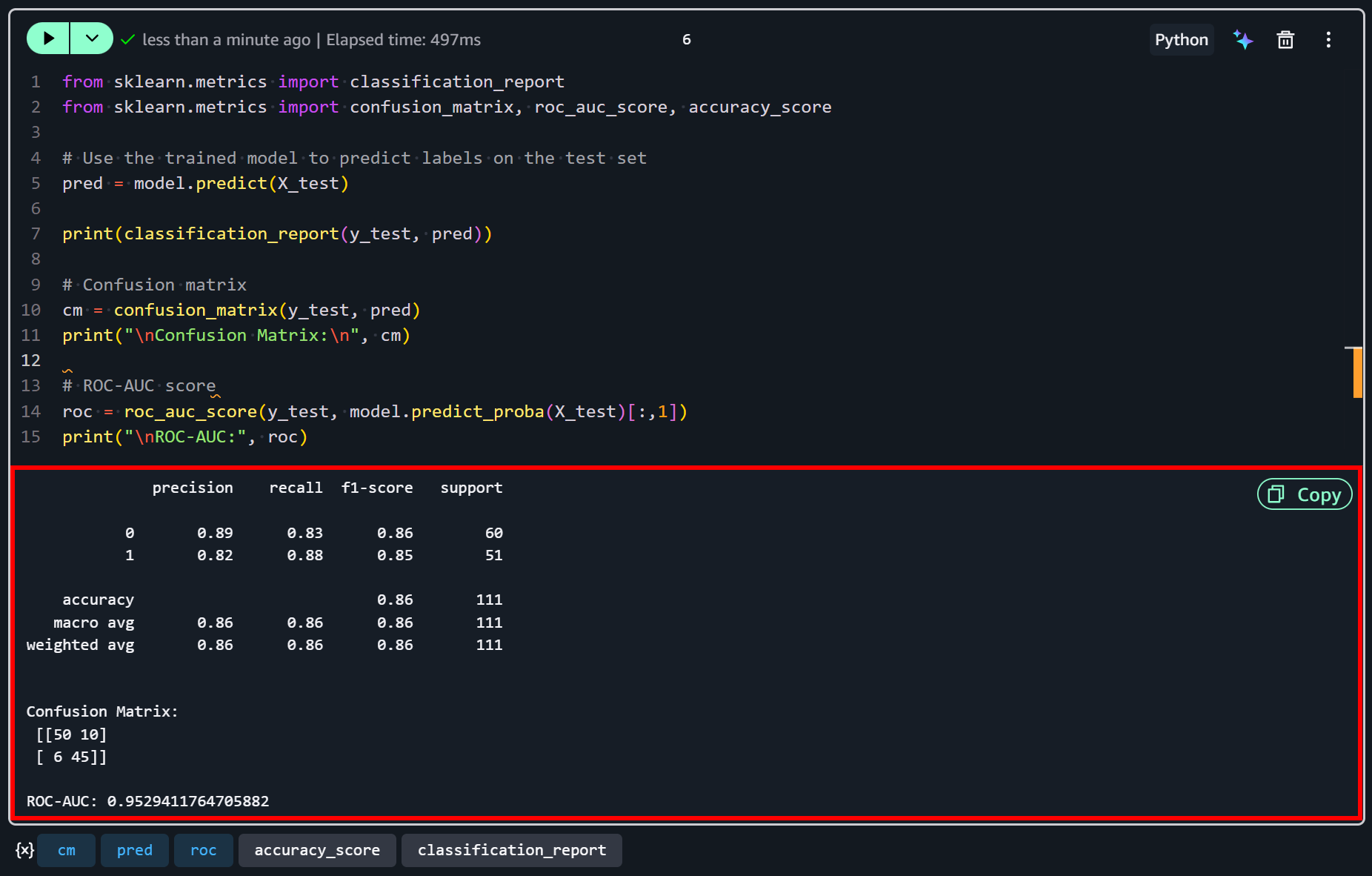
Estos resultados sugieren que el modelo funciona razonablemente bien para este conjunto de datos de ejemplo. Con una precisión del 86% y un ROC-AUC de 0,95, demuestra una fuerte capacidad para discriminar entre empresas con alta y baja satisfacción.
Ambas clases muestran precisión y recall equilibrados, lo que significa que el modelo es igualmente efectivo para identificar correctamente empresas con alta satisfacción (1) y aquellas con menor satisfacción (0).
Sin embargo, aún persisten algunas clasificaciones incorrectas… Como se refleja en la matriz de confusión, 10 empresas de baja satisfacción fueron incorrectamente predichas como de alta satisfacción, y 6 empresas de alta satisfacción fueron incorrectamente predichas como de baja satisfacción.
Esto indica que, si bien el modelo captura los patrones principales en los datos, no es perfecto y podría mejorarse con características adicionales (o más datos).
¡Et voilà! Gracias al conjunto de datos web de entrada de Bright Data, pudiste realizar ingeniería de características y entrenar un modelo predictivo en Amazon SageMaker. Este es solo uno de los muchos casos de uso que podrías explorar, gracias a la amplia variedad de conjuntos de datos web estructurados que ofrece Bright Data.
Próximos Pasos
El modelo actual, que predice la alta satisfacción de los empleados usando campos derivados mediante ingeniería de características, logra resultados decentes. Aun así, hay margen de mejora. Hay varias formas de mejorar su rendimiento, incluyendo:
- Crear más características derivadas: Combina las calificaciones existentes de nuevas maneras. Por ejemplo, podrías calcular un
leadership_scorea partir deratings_senior_managementyratings_ceo_approval, o unwork_life_compensation_ratiopara capturar las compensaciones entre salario y equilibrio trabajo-vida. Explora ratios, diferencias o interacciones entre características, que pueden revelar patrones ocultos. - Transformar distribuciones sesgadas: Características como
reviews_countojobs_countsuelen estar sesgadas. Ya aplicamos una transformación de raíz cuadrada, pero considera transformaciones logarítmicas o de Box-Cox para estabilizar aún más la varianza. - Incorporar características categóricas: Actualmente,
regionydetails_sizeno son numéricas. Codificarlas con one-hot encoding o target encoding podría proporcionar señal predictiva adicional. - Agregar múltiples puntos de datos: Si puedes obtener tendencias históricas de reseñas o contratación, crear características como el crecimiento promedio en
jobs_counta lo largo del tiempo o el cambio enculture_scorepodría capturar el comportamiento dinámico de las empresas. - Selección de características y análisis de importancia: Después del entrenamiento, inspecciona la importancia de características de XGBoost para identificar cuáles contribuyen más a las predicciones. Puedes diseñar nuevas características inspiradas en las más predictivas.
- Enriquecimiento con datos externos: Considera fusionar otros conjuntos de datos de Bright Data para crear características más ricas y contextuales.
Conclusión
En este tutorial, viste lo que Amazon SageMaker aporta para escenarios de aprendizaje automático. Específicamente, aprendiste por qué los conjuntos de datos scrapeados son excelentes fuentes para la ingeniería de características y cómo pueden aplicarse para entrenar modelos de ML predictivos.
Como se demostró, Bright Data proporciona un rico mercado de conjuntos de datos que cubre cientos de dominios y miles de millones de registros de datos web. Estos conjuntos de datos se actualizan continuamente mediante scraping web, lo que los hace ideales para respaldar flujos de trabajo de aprendizaje automático e IA. Además, se integran perfectamente con Amazon SageMaker, como se ilustra en esta guía.
¡Crea una cuenta gratuita de Bright Data hoy y comienza a explorar nuestras soluciones de datos web!





