

Exa es un motor de búsqueda semántico. Bright Data es una infraestructura de datos web. Son productos fundamentalmente diferentes, y la elección de cuál utilizar depende totalmente de lo que su agente de IA realmente necesite hacer.
Esta comparación analiza ambos productos en todas las dimensiones que importan para los equipos de IA de producción: coste, límites de velocidad, cobertura, acceso y datos históricos. Sin valoraciones vagas, solo cifras y hechos.
TL;DR – Bright Data vs. Exa de un vistazo
- Exa es un motor de búsqueda semántico; Bright Data es una infraestructura de datos web.
- La API SERP de Bright Data cuesta 1,50 $ por cada 1000 solicitudes; Exa cobra 7 $ por cada 1000.
- El límite de velocidad predeterminado
de /searchde Exa es de 10 QPS. Bright Data no tiene límite de solicitudes simultáneas. - Bright Data Web Unlocker puede rastrear páginas protegidas contra bots. Exa no puede.
- Bright Data cuenta con más de 50 PB de datos web históricos. Exa solo ofrece datos en tiempo real.
- La función «Find Similar» de Exa es única y no tiene un equivalente directo en Bright Data.
- Utiliza Exa para el descubrimiento semántico. Utiliza Bright Data para la extracción de datos de referencia a gran escala.
Bright Data frente a Exa: comparación directa
| Dimensión | Bright Data | Exa |
|---|---|---|
| Categoría de producto | Infraestructura de datos web (red de proxies + scraping + Conjuntos de datos) | API de motor de búsqueda semántica |
| Enfoque de búsqueda | Scraping de motores de búsqueda reales (Google, Bing, Yandex, etc.) a través de la API SERP + descubrimiento en tiempo real a través de la API Discover | Índice neuronal basado en incrustaciones personalizadas (índice propio) |
| Resultados por consulta | Hasta 1000 (API Discover) | Hasta 100 (estándar); hasta 1.000 en Enterprise |
| Contenido de página completa | Sí, extracción en tiempo real a través de Web Unlocker, devuelta como Markdown | Sí, a través del punto final /contents (1 $ por cada 1 000 páginas adicionales) |
| Antibots y omisión de CAPTCHA | Sí, integrado en Web Unlocker; más de 150 millones de direcciones IP Proxy | No, no puede rastrear detrás de muros de inicio de sesión ni de protección anti-bot |
| Datos históricos | Sí, más de 50 PB de archivo web; Conjuntos de datos predefinidos | No, solo índice en tiempo real |
| Límites de velocidad | Sin límite de solicitudes simultáneas (API SERP) | 10 QPS por defecto en /search; personalizable en Enterprise |
| Precios (PAYG) | Desde 1,50 $ por cada 1000 solicitudes (API SERP) | 7 $ por cada 1000 solicitudes (búsqueda estándar, 1-10 resultados) |
| Motores de búsqueda compatibles | Google, Bing, DuckDuckGo, Yandex, Baidu, Naver, Yahoo | Índice neuronal propio de Exa |
| Cumplimiento normativo | RGPD, CCPA, SOC 2, SOC 3, ISO 27701 | SOC 2 Tipo II, opción ZDR |
| Integración con MCP | Sí, servidor MCP de Bright Data (gratuito, 5000 solicitudes gratuitas al mes) | Sí, servidor MCP de Exa |
| Integraciones de marcos | LangChain, LlamaIndex, CrewAI, Agno, Dify, n8n, Zapier, más de 70 | LangChain, LlamaIndex, CrewAI, Vercel IA SDK, más de 20 |
| Nivel gratuito | Sí, prueba gratuita | Sí, 1000 solicitudes al mes |
| SLA empresarial | Sí, SLA del 99,9 %, Gerente de cuenta dedicado | Sí, SLA personalizado, incorporación 1:1 |
¿Qué es Exa?
Exa es un motor de búsqueda creado específicamente para aplicaciones de IA. En lugar de utilizar la indexación tradicional por palabras clave, Exa ha creado su propio índice neuronal, un modelo de incrustaciones a gran escala entrenado en la web. Cuando se realiza una consulta en Exa, este lleva a cabo una búsqueda vectorial semántica en ese índice y devuelve resultados ordenados por relevancia conceptual, no por coincidencia de palabras clave.
Esta elección arquitectónica es el principal diferenciador de Exa. Responde a preguntas como «encuentra artículos similares a esta URL de arXiv» o «empresas que hacen lo que hace Nvidia en el ámbito de los semiconductores» de formas que un Scraper de SERP basado en palabras clave no puede. A fecha de marzo de 2026, el índice de Exa incluye más de 1000 millones de perfiles de personas y 70 millones de entradas de empresas, y ofrece modos de búsqueda específicos para noticias, código y informes financieros. Si estás evaluando alternativas a Exa, el artículo «Las mejores alternativas a Exa para la búsqueda web con IA» ofrece una comparación detallada de herramientas de la competencia, como Bright Data, Tavily y Firecrawl.
Lo que Exa hace bien
Búsqueda semántica «Encontrar similares». Ninguna otra API de búsqueda ofrece la función «encuéntrame páginas conceptualmente similares a esta URL». Se trata de una auténtica brecha de capacidades que Bright Data no cubre.
Recuperación de baja latencia. Exa Instant ofrece respuestas en menos de 200 ms. La búsqueda estándar tarda entre 100 y 1200 ms. Para interfaces de chat interactivas y agentes en tiempo real, esta velocidad supone una ventaja real.
Experiencia para desarrolladores. SDK en Python y TypeScript, integraciones nativas con LangChain, LlamaIndex y CrewAI, compatibilidad con MCP Server y unas generosas 1000 solicitudes gratuitas al mes. Pasar de cero a una integración de agente operativa lleva unos minutos.
Índices de dominios especializados. El índice de personas de Exa (más de 1000 millones de perfiles, más de 50 millones de actualizaciones semanales) y el índice de empresas (más de 70 millones de empresas) están diseñados específicamente para agentes de reclutamiento, procesos de inteligencia de ventas y flujos de trabajo de enriquecimiento de datos de empresas.
Gran precisión en las pruebas de rendimiento. En la recuperación de múltiples saltos de WebWalker, Exa obtuvo una puntuación del 81 % frente al 71 % de Tavily en una evaluación de una empresa de la lista Fortune 100 (enero de 2025). En la prueba de rendimiento de AIMultiple con 100 consultas en 8 API, Exa ocupó el tercer puesto con una puntuación de agente de 14,39.
Limitaciones fundamentales de Exa a gran escala
Los límites de velocidad de Exa restringen las cargas de trabajo de producción. El límite predeterminado de /search es de 10 QPS (600 solicitudes por minuto). Confirmado directamente en la documentación oficial de límites de velocidad de Exa. Para los flujos de trabajo con múltiples agentes que ejecutan miles de tareas de investigación en paralelo, este límite obliga a los equipos a implementar lógicas de reintento y colas de solicitudes desde el primer día. Los clientes empresariales pueden negociar límites más altos, pero eso requiere una negociación comercial por separado.
Exa no puede penetrar la protección antibots. Exa rastrea la web abierta según su propio calendario. No puede recuperar páginas protegidas por Cloudflare, pantallas de inicio de sesión, sistemas CAPTCHA o detección de bots basada en JavaScript. Para la Inteligencia competitiva, el Monitoreo de precios o cualquier caso de uso en el que las páginas más valiosas sean también las más protegidas, esto supone una limitación importante.
No hay capa de datos históricos. Exa solo ofrece datos en tiempo real. No hay producto de archivo, ni Conjuntos de datos históricos, ni forma de comparar los resultados de hoy con los del último trimestre. Para la detección de anomalías, el análisis de tendencias o los resultados de agentes basados en una línea de referencia, esto supone una carencia estructural.
El índice de Exa no es Google. Exa devuelve resultados de su propio índice neuronal patentado, no de Google, Bing o Yandex. Para cualquier caso de uso que requiera saber exactamente lo que un usuario real ve en Google en este momento (monitorización SEO, inteligencia publicitaria, seguimiento de posicionamiento, Protección de marca), el índice de Exa es una fuente de datos inadecuada.
Los precios no se adaptan bien a los grandes volúmenes. Con 1 millón de solicitudes al mes, la búsqueda estándar de Exa cuesta más de 7000 $. Con contenido de página completa, esa cifra asciende a más de 8000 $. Exa actualizó sus precios en marzo de 2026, aumentando la búsqueda estándar de 5 $/1000 a 7 $/1000 e introduciendo un nivel «Agentic» a 12 $/1000.
¿Qué es Bright Data?
Bright Data es una infraestructura de datos web. No tiene su propio índice de búsqueda, sino que accede a la web real en tiempo real a gran escala, a través de un conjunto de productos diseñados para diferentes patrones de adquisición de datos.
La API SERP extrae resultados reales de Google, Bing, Yandex, Baidu, DuckDuckGo, Yahoo y Naver en tiempo real, desde cualquiera de los 195 países, con segmentación geográfica a nivel de ciudad. Devuelve lo que vería un usuario real en esa ubicación, en ese momento, no lo que cualquier índice cree que debería ver.
La API Discover está diseñada específicamente para cargas de trabajo de agentes que necesitan pruebas más amplias y profundas de la web en tiempo real, en lugar de una lista superficial de enlaces clasificados por SEO. Encuentra URL en tiempo real con hasta 1000 resultados por solicitud, clasificados según la intención específica del agente en lugar de la posición SEO, con contenido Markdown depurado opcional para la verificación y el fundamentado RAG. A diferencia de los motores de búsqueda o los índices en caché, cada solicitud de Discover se ejecuta en el momento de la consulta en la web en tiempo real, lo que la hace especialmente adecuada para la Inteligencia competitiva, la supervisión de riesgos y los flujos de trabajo de diligencia debida.
Web Unlocker recupera cualquier página web, incluidas aquellas protegidas por Cloudflare, CAPTCHAs, pantallas de inicio de sesión o renderización de JavaScript, y devuelve contenido Markdown limpio. Enruta las solicitudes a través de una red de más de 150 millones de IPs residenciales en 195 países, gestionando automáticamente el bypass de detección.
La capa de Conjuntos de datos proporciona datos estructurados predefinidos en más de 100 dominios. La API de Web Archive ofrece más de 50 PB de datos web históricos que se remontan a años atrás, lo que la convierte en la solución perfecta para el contexto histórico.
Cómo aborda Bright Data los datos web para IA
La arquitectura de Bright Data se basa en una premisa fundamental: la realidad de referencia es la web real en tiempo real, no la aproximación que ofrece ningún índice. Para los equipos de IA empresariales que desarrollan sistemas de producción, esto es importante cuando:
- Tu agente necesita recuperar la página de precios de un competidor, y esa página bloquea a los Scrapers
- Tu agente necesita saber lo que Google muestra realmente para una palabra clave, no lo que estima un índice neuronal
- Tu agente necesita ejecutar 10 000 consultas en paralelo sin alcanzar el límite de rate
- Tu agente necesita comprender si los resultados de hoy son anómalos en comparación con los de hace seis meses
Bright Data cuenta con la confianza de más de 20 000 clientes, incluidas empresas de la lista Fortune 500, y aparece citada en el informe «Competitive Landscape for Web Data Collection Solutions» de Gartner. Cuenta con las certificaciones GDPR, CCPA, SOC 2, SOC 3 e ISO 27701.
Productos clave: API SERP, Discover API, Web Unlocker, Conjuntos de datos
| Producto | Qué hace | Precio |
|---|---|---|
| API SERP | Extracción en tiempo real de 7 motores de búsqueda, 195 países, salida estructurada en JSON/Markdown | Desde 1,50 $/1000 resultados (pago por uso); hasta 1,00 $/1000 a partir de 2 millones al mes |
| API Discover | Detección de URL en tiempo real de hasta 1000 resultados por solicitud, ordenados por intención, contenido Markdown opcional | Gratis (beta) |
| Web Unlocker | Recupera cualquier página protegida contra bots y devuelve Markdown limpio | Desde 1 $ por cada 1000 solicitudes |
| Conjuntos de datos | Datos estructurados predefinidos de más de 100 dominios | Desde 250 $ por cada 100 000 registros |
| API de archivo web | Más de 50 PB de datos web históricos | Desde 0,20 $ por cada 1000 páginas HTML |
| Servidor MCP | Conecta agentes de IA directamente a la suite completa de productos de Bright Data | Gratis, 5000 solicitudes al mes |
Comparación de precios: Bright Data frente a Exa
Precios de Exa (marzo de 2026)
| Producto | Precio |
|---|---|
| Búsqueda estándar (1-10 resultados) | 7 $ / 1000 solicitudes |
| Resultados adicionales más allá de 10 | +1 $ / 1.000 resultados |
| Búsqueda avanzada / profunda | 12 $ / 1.000 solicitudes |
| Búsqueda profunda con razonamiento | 15 $ / 1.000 solicitudes |
| Contenidos (texto de página completa) | 1 $ / 1000 páginas |
| API de respuestas | 5 $ / 1000 respuestas |
| Nivel gratuito | 1.000 solicitudes al mes |
| Empresa | Personalizado |
Matiz importante: los precios de Exa son acumulativos. Si tu agente necesita 10 resultados más el contenido completo de la página, pagas por la búsqueda (7 $) más el contenido (1 $) por cada 1.000 solicitudes. El coste efectivo mínimo para los agentes que necesitan el texto completo en línea es de 8 $ por cada 1.000.
Precios de Bright Data
| Producto | Precio |
|---|---|
| API SERP (PAYG) | 1,50 $ / 1 000 resultados |
| API SERP (380 000 resultados al mes) | 1,30 $ / 1.000 resultados |
| API SERP (900 000 resultados al mes) | 1,10 $ / 1.000 resultados |
| API SERP (2 millones de resultados al mes) | 1,00 $ / 1 000 resultados |
| Web Unlocker | Desde 1 $ / 1 000 solicitudes |
| Conjuntos de datos | Desde 250 $ / 100 000 registros |
| Archivo web | Desde 0,20 $ / 1.000 páginas HTML |
| API Discover | Gratis (beta) |
| Servidor MCP | Gratis (5.000 solicitudes al mes) |
Coste a gran escala: las cifras son contundentes
| Volumen | Exa (solo búsqueda estándar) | Exa (búsqueda + contenido) | API SERP de Bright Data |
|---|---|---|---|
| 10 000 solicitudes | 70 $ | 80 | 15 $ |
| 100 000 solicitudes | 700 $ | 800 $ | 130-150 $ |
| 1 000 000 de solicitudes | Más de 7.000 $ | Más de 8 000 | 1000-1500 |
Con 1 millón de solicitudes al mes, Bright Data es entre 5 y 7 veces más barato que Exa solo en lo que respecta a la búsqueda. Para una comparación completa de los proveedores de API SERP y de búsqueda web a gran escala, consulta las mejores API SERP y de búsqueda web de 2026. Para los agentes que necesitan contenido de página completa, la diferencia se amplía aún más: Exa añade 1 $ por cada 1000; Bright Data Web Unlocker empieza en 1 $ por cada 1000, todo incluido.
Bright Data no tiene límite de solicitudes simultáneas
No se trata de una diferencia sutil. El límite de velocidad predeterminado de Exa para /search es de 10 QPS, 10 consultas por segundo, 600 por minuto. Esto se confirma en la documentación oficial de límites de velocidad de Exa.
La API SERP de Bright Data no tiene límite de solicitudes simultáneas. Según sus propias preguntas frecuentes: «No hay límite en el número de solicitudes simultáneas. La API SERP está diseñada para escalar».
Para cargas de trabajo de un solo agente y una consulta a la vez, esto no importa. Para pipelines de IA en producción que ejecutan docenas o cientos de tareas de investigación en paralelo, sistemas de Inteligencia competitiva, marcos de investigación multiagente y pilas de monitorización en tiempo real, la diferencia es fundamental. Con Exa, estás diseñando tu sistema con un límite máximo desde el primer día.
Bright Data puede acceder a páginas a las que Exa no puede
Exa rastrea la web abierta. No puede acceder a:
- Páginas protegidas por Cloudflare
- Sitios con barreras de inicio de sesión o requisitos de autenticación
- Páginas con CAPTCHA
- Sitios con mucho JavaScript que no sirven contenido a solicitudes HTTP sin procesar
- Contenido con restricciones geográficas que requiere direcciones IP locales
Esto no es una crítica, simplemente queda fuera del alcance del producto de Exa.
Web Unlocker de Bright Data se creó específicamente para este problema. Dirige las solicitudes a través de más de 150 millones de IPs residenciales, gestiona las huellas digitales del navegador, realiza la Resolución de CAPTCHA y devuelve el contenido completo de la página renderizada como Markdown limpio. Para los equipos que necesiten comprender todo lo que implica eludir los sistemas anti-bot, la guía para eludir Cloudflare para el Scraping web cubre en profundidad las técnicas relevantes. Para la inteligencia competitiva de precios, donde los datos más valiosos suelen encontrarse en las páginas más protegidas, esta es una capacidad fundamental.
A continuación se muestra un ejemplo básico de cómo un agente de producción utilizaría la API SERP de Bright Data frente a Exa para la misma tarea:
# API SERP de Bright Data: resultados reales de Google, sin límite de solicitudes
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer YOUR_API_KEY"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # Salida preparada para LLM
}
)
results = response.json()
# Exa - búsqueda semántica, límite de 10 QPS
from exa_py import Exa
exa = Exa(api_key="TU_CLAVE_EXA")
results = exa.search_and_contents(
"precios de la competencia para empresas 2026",
num_results=10,
text=True
)
# 7 $/1000 (búsqueda) + 1 $/1000 (contenidos) = 8 $/1000 de coste efectivoEl resultado funcional es similar para consultas básicas. Las diferencias surgen cuando necesitas ejecutar esto en paralelo para 1000 competidores, o cuando la página de destino bloquea los rastreadores de Exa. Mira este ejemplo:
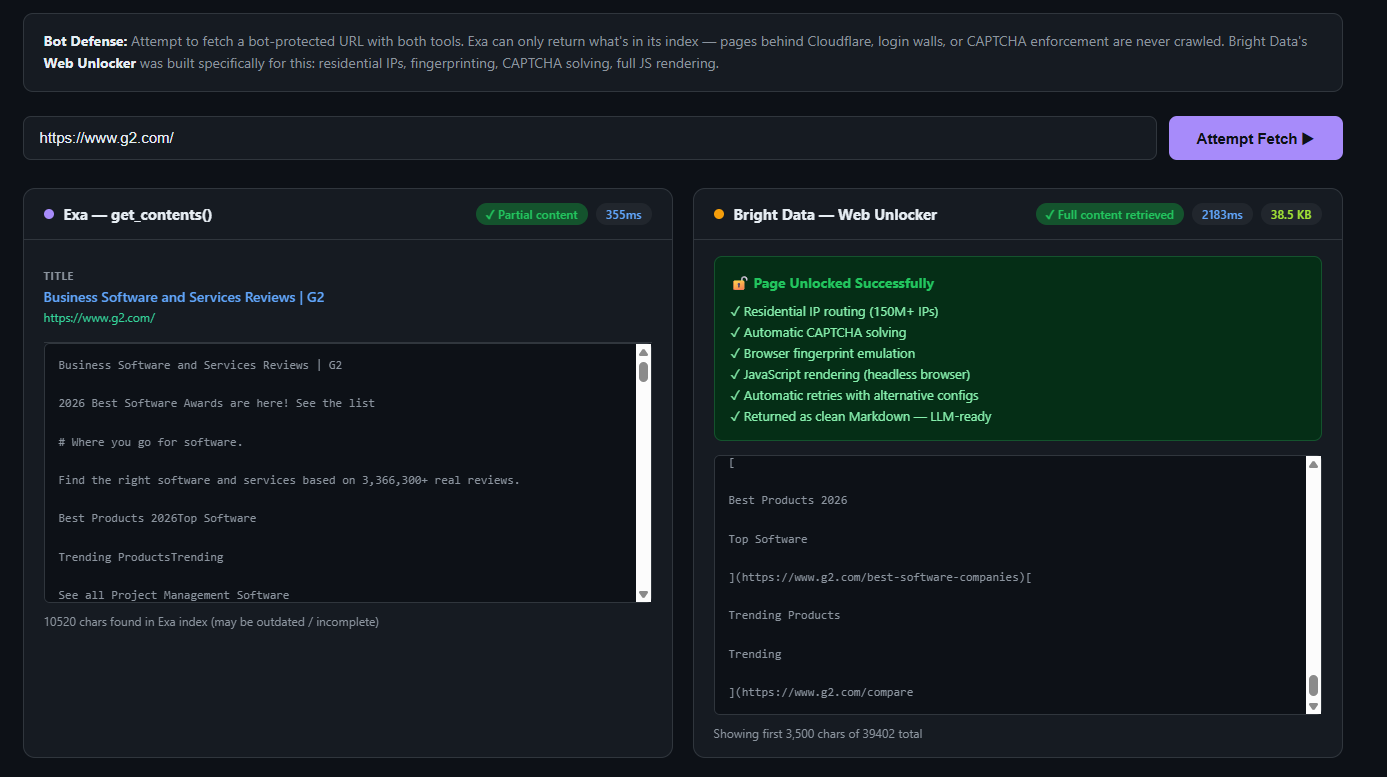
Si quieres probarlo tú mismo, echa un vistazo a esta demo en GitHub.
Exa no tiene una capa de datos históricos
Los agentes de IA que detectan cambios en los precios, cambios en las políticas o movimientos del mercado necesitan una referencia desde la que partir. No se puede etiquetar algo como una anomalía sin saber cómo es lo normal.
Exa solo funciona en tiempo real. No hay ningún producto de archivo, ni Conjuntos de datos históricos, ni capacidad de series temporales.
La API de archivo web de Bright Data contiene más de 50 PB de datos web históricos, y crece a diario. Los conjuntos de datos estructurados predefinidos abarcan más de 100 dominios y proporcionan bases de referencia históricas para el comercio electrónico, las redes sociales, el sector inmobiliario y mucho más. Para el trabajo de inteligencia longitudinal, como supervisar cómo ha cambiado la página de precios de un competidor a lo largo de 12 meses, realizar un seguimiento de los registros normativos a lo largo del tiempo o detectar cambios en la opinión pública, Bright Data cuenta con la infraestructura necesaria y Exa no.
Guía de decisión de casos de uso
| Caso de uso | Mejor opción | Motivo |
|---|---|---|
| Prototipado RAG / hackatón | Exa | Rápido, nivel gratuito, LangChain nativo, configuración mínima |
| Búsqueda de similitud semántica («encontrar páginas como esta URL») | Exa | El punto final «Find Similar» no tiene equivalente en Bright Data |
| Enriquecimiento de personas/empresas (agentes de reclutamiento, inteligencia de ventas) | Exa | Más de 1000 millones de perfiles indexados, índice estructurado de empresas |
| Inteligencia competitiva de precios (contenido de páginas en tiempo real) | Bright Data | Web Unlocker elude los sistemas anti-bot; Exa no puede acceder a páginas protegidas |
| Agente de producción con más de 1000 consultas simultáneas | Bright Data | Sin límite máximo de frecuencia; API SERP diseñada para cargas de trabajo paralelas |
| Datos reales de SERP de Google (SEO, monitorización de anuncios, seguimiento de posicionamiento) | Bright Data | La API SERP extrae datos reales de Google; Exa utiliza su propio índice |
| Detección de anomalías y referencia histórica | Bright Data | Archivo web de más de 50 PB, Conjuntos de datos, capacidad de series temporales |
| Páginas detrás de Cloudflare / muros de inicio de sesión | Bright Data | Web Unlocker; Exa no puede acceder a contenido protegido |
| Búsqueda multimotor (Google + Bing + Yandex) | Bright Data | La API SERP cubre los 7 principales motores de búsqueda en 195 países |
| Experiencia de usuario de chat interactivo de baja latencia | Exa | Exa Instant ofrece tiempos de respuesta inferiores a 200 ms |
| Económico para grandes volúmenes (más de 100 000 consultas al mes) | Bright Data | 1-1,50 $/1000 frente a los 7-15 $/1000 de Exa |
Cuándo elegir Exa
Exa es la herramienta adecuada si:
- Estás creando un prototipo o realizando una investigación en fase inicial. Las 1000 solicitudes mensuales gratuitas, la compatibilidad nativa con LangChain/LlamaIndex y la sencilla integración del SDK hacen de Exa la forma más sencilla de añadir búsqueda web a un agente de IA.
- Tu caso de uso principal es la similitud semántica. «Búscame páginas como esta URL» es una función exclusiva de Exa. Si ese es tu patrón de búsqueda principal, elige Exa.
- Necesitas datos estructurados sobre personas o empresas. El índice de más de 1 000 millones de perfiles y el índice de más de 70 millones de empresas de Exa están diseñados específicamente para agentes de inteligencia de ventas y reclutamiento.
- La latencia es la principal limitación. Los menos de 200 ms de Exa Instant superan a cualquier solución de scraping en tiempo real para aplicaciones interactivas.
- Tu volumen de consultas es inferior a 50 000-100 000 solicitudes al mes y no necesitas datos reales de Google ni acceso a páginas protegidas.
Cuándo elegir Bright Data
Bright Data es la herramienta adecuada si:
- Opera a escala de producción. Las solicitudes simultáneas ilimitadas y un SLA con un tiempo de actividad del 99,9 % eliminan la necesidad de soluciones de ingeniería para los límites de velocidad.
- Necesitas resultados reales de Google. La API SERP extrae datos de Google real (y Bing, Yandex, Baidu, Yahoo, Naver, DuckDuckGo) en tiempo real, en cualquier país, mostrando lo que ven los usuarios reales, no lo que estima un índice neuronal.
- Tu agente necesita acceder a páginas protegidas. Web Unlocker gestiona Cloudflare, barreras CAPTCHA, páginas de inicio de sesión y renderización de JavaScript. Exa no puede.
- Necesitas datos históricos. La API de Web Archive proporciona más de 50 PB de datos históricos para establecer una base de referencia y realizar análisis longitudinales.
- El coste a gran escala es un factor importante. Con más de 100 000 solicitudes al mes, Bright Data es entre 5 y 7 veces más barato que Exa.
- Estás creando sistemas de nivel empresarial. Más de 20 000 clientes, la adopción por parte de empresas de la lista Fortune 500, el reconocimiento de Gartner y más de 70 integraciones con marcos de IA significan que Bright Data encaja en las pilas de datos empresariales existentes.
Conclusión: dos herramientas diferentes para dos trabajos diferentes
Exa y Bright Data no compiten por el mismo trabajo.
Exa es excelente en aquello para lo que fue diseñada: búsqueda neuronal semántica, rápida incorporación de desarrolladores e índices especializados para personas y empresas. Si necesitas encontrar páginas conceptualmente similares, explorar un entorno semántico o buscar entre mil millones de perfiles de LinkedIn, la arquitectura de Exa es ideal para esas tareas.
Bright Data está diseñada para un conjunto de problemas diferente: acceder a la realidad de la web en tiempo real a escala de producción, incluidas aquellas partes de la web que bloquean a los rastreadores. La API SERP ofrece resultados reales de Google a 1,50 $ por cada 1000, sin límite de solicitudes simultáneas. El Web Unlocker llega a páginas a las que los rastreadores de Exa no pueden acceder. El Web Archive proporciona la referencia histórica que las API de solo tiempo real no pueden ofrecer.
Este es el marco de decisión:
- Si su agente necesita encontrar páginas semánticamente similares, buscar entre más de 1000 millones de perfiles o devolver respuestas en menos de 200 ms, Exa está diseñado para eso.
- Si tu agente necesita escala de producción, datos reales de Google, acceso anti-bot, referencias históricas o rentabilidad por encima de las 100 000 consultas al mes, Bright Data es la infraestructura adecuada.
Muchos equipos de IA en producción utilizan ambos: Exa para el descubrimiento semántico en las primeras etapas de un proceso, y Bright Data para la verificación en tiempo real, la extracción de páginas completas y la inteligencia SERP a gran escala. No son mutuamente excluyentes. Simplemente tienen límites máximos diferentes, y a escala empresarial, el límite de Exa se alcanza rápidamente. Para los equipos que evalúan toda la gama de los mejores servidores MCP para flujos de trabajo de IA, el servidor MCP de Bright Data se sitúa sistemáticamente como la opción líder para basar los agentes en datos web en tiempo real.
Preguntas frecuentes
¿Cuál es la diferencia entre Bright Data y Exa?
Exa es una API de motor de búsqueda semántica que devuelve resultados de su propio índice neuronal. Bright Data es una infraestructura de datos web que rastrea motores de búsqueda reales, extrae páginas protegidas contra bots y proporciona Conjuntos de datos históricos. Resuelven problemas diferentes a escalas diferentes.
¿Es Bright Data más barato que Exa?
Sí. La API SERP de Bright Data tiene un precio inicial de 1,50 $ por cada 1000 solicitudes, con un modelo de pago por uso. La búsqueda estándar de Exa cuesta 7 $ por cada 1000 solicitudes. Con un millón de solicitudes al mes, Bright Data es aproximadamente entre 5 y 7 veces más barato.
¿Puede Exa rastrear sitios web protegidos por Cloudflare?
No. Exa no puede rastrear páginas protegidas por Cloudflare, pantallas de inicio de sesión o sistemas CAPTCHA. El Web Unlocker de Bright Data está diseñado específicamente para eludir la protección antibots, utilizando una red de más de 150 millones de IPs residenciales.
¿Tiene Exa un límite de velocidad?
Sí. El límite de velocidad predeterminado de /search de Exa es de 10 QPS (600 solicitudes por minuto). Los clientes empresariales pueden negociar límites más altos. La API SERP de Bright Data no tiene límite de solicitudes simultáneas.
¿Cuál es la mejor alternativa a Exa para los agentes de IA empresariales?
Bright Data es la principal alternativa empresarial a Exa. Ofrece solicitudes simultáneas ilimitadas, scraping web en tiempo real de Google/Bing/Yandex, elusión de la protección antibot a través de Web Unlocker, archivos de datos históricos y compatibilidad con flujos de trabajo de agentes de IA basados en MCP, todo ello con un modelo de pago por éxito.
¿Dispone Exa de datos históricos?
No. Exa solo ofrece datos en tiempo real, sin productos de archivo ni Conjuntos de datos. La API Web Archive de Bright Data contiene más de 50 PB de datos web históricos, y crece a diario.






