

Ampliar la operación de scraping local de 1000 a 100 000 páginas suele implicar más servidores, Proxies y trabajo operativo. Los sitios de destino se vuelven más difíciles de rastrear. Los costes de infraestructura aumentan. Los equipos dedican más tiempo a reparar los Scrapers que a enviar funciones. A gran escala, el scraping deja de ser un script y se convierte en infraestructura.
La elección entre el rastreo local y el rastreo en la nube afecta a tres cosas: el coste, la fiabilidad y la velocidad de entrega.
TL;DR
- El rastreo local se ejecuta en sus máquinas. Usted tiene el control total, pero debe realizar el mantenimiento manual.
- El rastreo en la nube se ejecuta en una infraestructura remota con autoescalado y rotación de IP integrada.
- Elija el rastreo local para menos de 1000 páginas o datos regulados y solo internos.
- Elija el scraping en la nube para más de 10 000 páginas, sitios bloqueados o supervisión 24/7.
- El bloqueo de IP es el principal cuello de botella: el 68 % de los equipos lo citan como su principal reto.
- A gran escala, el scraping en la nube puede reducir los costes totales hasta en un 70 % al eliminar los gastos generales de DevOps.
- Bright Data ofrece más de 150 millones de IPs residenciales, un tiempo de actividad del 99,9 % y una ejecución sin mantenimiento.
¿Qué es el scraping local?
El scraping local significa que usted es propietario de toda la pila: código, IP, navegadores, pero también fallos y tiempo de inactividad. Usted ejecuta sus scripts de scraping en su infraestructura y gestiona todo el proceso usted mismo.
No hay una capa de infraestructura gestionada, por lo que, cuando algo falla, usted lo arregla.
Cómo funciona el scraping local
El scraping local sigue un sencillo bucle de ejecución. Su script envía solicitudes, recibe respuestas y extrae datos de páginas HTML o renderizadas.
Las solicitudes se originan desde su propia dirección IP o desde los Proxies que usted configura. Cuando los sitios bloquean el tráfico, es necesario rotar las IP y reintentar las solicitudes manualmente.
Un simple cliente HTTP es suficiente para las páginas estáticas, pero para los sitios con mucho JavaScript, es necesario ejecutar navegadores sin interfaz gráfica localmente para renderizar el contenido antes de extraerlo.
Además de todo esto, con el scraping local, normalmente tienes que gestionar manualmente los CAPTCHA y otras medidas antibots.
Esto funciona a pequeña escala, pero a medida que el volumen crece, el sencillo script con el que empezaste se convierte rápidamente en un complejo sistema de infraestructura que debes operar y mantener.
Ventajas del scraping local
Dado que el scraping local mantiene la ejecución íntegramente dentro de su entorno, es ideal si necesita:
- Control total de la ejecución: usted gestiona el tiempo de las solicitudes, los encabezados, la lógica de parseo y el almacenamiento.
- Sin dependencia de terceros: el scraping se ejecuta sin infraestructura ni proveedores externos.
- Protección de datos confidenciales: los datos permanecen dentro de su red.
- Gran valor de aprendizaje: trabajas directamente con encabezados, cookies, límites de velocidad y fallos.
- Bajo coste de configuración para trabajos pequeños: un script y un ordenador portátil son suficientes para el scraping de bajo volumen de sitios sin protección.
Limitaciones del scraping local
El scraping local se vuelve más difícil de mantener a medida que aumentan los requisitos de volumen y fiabilidad:
- Escasa escalabilidad: un mayor volumen requiere la compra de servidores y Ancho de banda adicionales.
- Bloqueo de IP: Debes buscar, rotar y reemplazar proxies a medida que los sitios bloquean el tráfico.
- Interrupciones CAPTCHA: la resolución manual interrumpe la automatización; los solucionadores automáticos añaden coste y latencia.
- Ejecución del navegador con mucho JavaScript: los sitios con mucho JavaScript requieren navegadores locales que consumen una cantidad significativa de CPU y memoria.
- Mantenimiento continuo: los cambios en los sitios y las actualizaciones de detección requieren frecuentes correcciones de código y reimplementaciones.
- Fiabilidad frágil: los fallos detienen la recopilación de datos hasta que se interviene.
Ejemplo: scraping local en Python
Así es como se ve el scraping local con Python a pequeña escala:
import requests
from bs4 import BeautifulSoup
def scrape_products(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
return [
{
"name": item.find("h3").text.strip(),
"price": item.find("span", class_="price").text.strip(),
}
for item in soup.select(".product-card")
]
products = scrape_products("https://example.com/products")Este script se ejecuta localmente y utiliza tu dirección IP real. Gestiona varios cientos de páginas sin problemas en sitios web desprotegidos.
Pero fíjate en lo que falta: no hay rotación de proxies, gestión de CAPTCHA, lógica de reintento ni supervisión. Añadir esas funciones puede sobrecargar fácilmente el script y dificultar su ejecución y mantenimiento.
¿Qué es el rastreo en la nube?
El cloud scraping traslada la ejecución fuera de su aplicación. Usted envía solicitudes a la API de un proveedor y recibe los datos extraídos como respuesta. El proveedor se encarga del funcionamiento de la red de Proxies y de toda la infraestructura de scraping necesaria.
Plataformas como Bright Data operan esta infraestructura a escala de producción.
Cómo funciona el cloud scraping
El cloud scraping sigue un modelo de solicitud-ejecución-respuesta:
- Usted envía una solicitud de scraping a través de la API de un proveedor.
- El proveedor enruta la solicitud a través de su red Proxy, en una infraestructura remota, no en sus máquinas.
- Cuando un sitio requiere JavaScript, la solicitud se ejecuta en un navegador gestionado. La página renderizada se procesa antes de la extracción de datos.
- Las solicitudes fallidas desencadenan reintentos basados en la lógica definida por el proveedor.
- Los retos CAPTCHA se detectan y resuelven dentro de la capa de ejecución.
- Usted recibe los datos extraídos como respuesta.
A continuación se ofrece una descripción simplificada del funcionamiento del cloud scraping: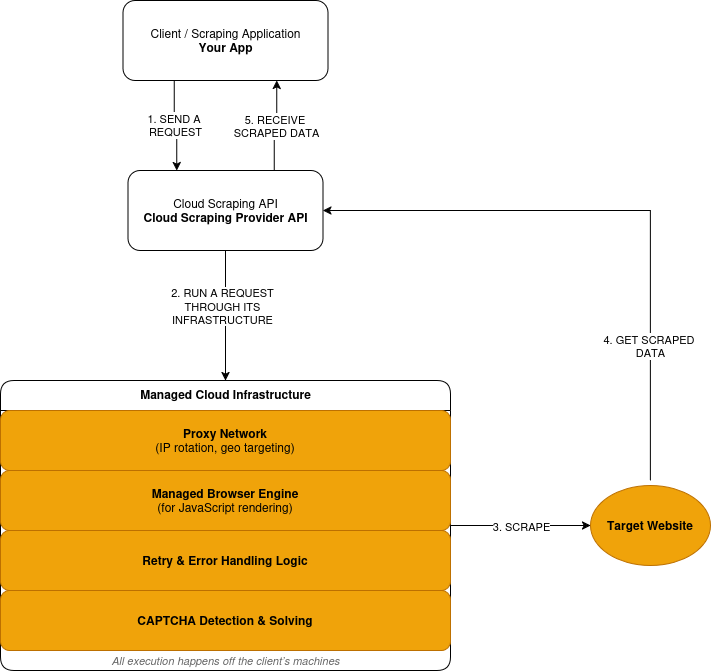
Ventajas del scraping en la nube
El scraping en la nube favorece la escalabilidad, la fiabilidad y la reducción de la propiedad operativa:
- Ejecución gestionada: las solicitudes se ejecutan en la infraestructura operada por el proveedor.
- Escalabilidad integrada: el volumen aumenta sin necesidad de adquirir nuevos servidores.
- Gestión integrada contra bots: la rotación de IP y los reintentos se producen automáticamente.
- Infraestructura del navegador incluida: el proveedor de scraping se encarga de la representación de JavaScript.
- Reducción del alcance del mantenimiento: los cambios en el sitio ya no requieren una reimplementación constante.
- Costes basados en el uso: precios basados en el volumen de solicitudes.
Ventajas e inconvenientes del scraping en la nube
El scraping en la nube reduce la propiedad operativa, pero introduce dependencias externas. Parte del control se traslada fuera de los límites de su aplicación.
- Control de bajo nivel reducido: la sincronización, la elección de IP y los reintentos siguen la lógica del proveedor.
- Dependencia de terceros: la disponibilidad y la ejecución se encuentran fuera de su sistema.
- Los costes varían en función del uso: un volumen elevado aumenta el gasto.
- Depuración externa: los fallos requieren la visibilidad y el soporte del proveedor.
- Restricciones de cumplimiento: algunos datos no pueden salir de entornos controlados.
Ejemplo: scraping web de gran volumen con Bright Data Web Unlocker
Esta es la misma tarea de scraping ejecutada a través de una capa de ejecución basada en la nube.
import requests
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer API_KEY',
}
payload = {
'zone': 'web_unlocker1',
'url': 'https://example.com/products',
'format': 'json'
}
response = requests.post('https://api.brightdata.com/request', json=payload, headers=headers)
print(response.json())A simple vista, esto parece similar al ejemplo de scraping local. Sigue siendo una única solicitud HTTP. La diferencia está en dónde se ejecuta la solicitud.
Con la API Web Unlocker de Bright Data, la solicitud se ejecuta en una infraestructura gestionada. La rotación de IP, la detección de bloqueos y los reintentos se producen fuera de su aplicación.
Rastreo en la nube frente a rastreo local: comparación directa
A continuación se muestra una comparación entre el scraping local y el scraping en la nube en función de los factores que realmente afectan a su proyecto.
| Factor | Raspado local | Raspado en la nube | Ventaja de Bright Data |
|---|---|---|---|
| Infraestructura | Configuración DIY | Totalmente gestionado | Red global en 195 países |
| Escalabilidad | Limitada | Escalabilidad automática a miles de millones al mes | Miles de millones de solicitudes al mes |
| Bloqueo de IP | Alto riesgo | Rotación automática | Más de 150 millones de IPs residenciales |
| Mantenimiento | Manual | Gestionado por el proveedor | Supervisión 24/7 |
| Modelo de costes | Fijo + oculto | Pago por uso | Reducción de costes de hasta el 70 % |
| Antibots | Bricolaje | Integrado | 99,9 % de éxito en CAPTCHA |
| Cumplimiento | Bricolaje | Varía | SOC2, RGPD, CCPA |
Desglose de costes: scraping local frente a scraping en la nube
El scraping local parece barato hasta que se tiene en cuenta todo lo que se necesita para mantenerlo en funcionamiento. El mayor coste aquí no son los servidores, sino los ingenieros que se encargan del mantenimiento del scraping en lugar de desarrollar funciones.
El scraping en la nube traslada esos costes a un precio por solicitud.
Componentes del coste del scraping local
El scraping local tiene costes fijos que se acumulan con el tiempo.
- Servidores: máquinas virtuales, Ancho de banda, almacenamiento.
- Proxies: suscripciones IP residenciales o móviles.
- Resolución de CAPTCHA: servicios de resolución de terceros.
- Mantenimiento: tiempo de ingeniería para correcciones y actualizaciones.
- Tiempo de inactividad: datos perdidos durante los fallos.
Estos costes existen independientemente de si se realiza scraping o no.
Componentes del coste del scraping en la nube
El scraping en la nube utiliza precios variables vinculados al uso.
- Solicitudes: precios por solicitud o por página.
- Renderización: mayor coste por la ejecución de JavaScript.
- Transferencia de datos: cargos basados en el ancho de banda.
Se incluyen la infraestructura, los Proxies y el mantenimiento.
Comparación de costes
| Factor de coste | Rastreo local | Rastreo en la nube | Bright Data |
|---|---|---|---|
| Capacidad del servidor | Coste mensual fijo | Incluido | Incluido |
| Infraestructura de Proxy | Suscripción independiente | Incluido | Más de 150 millones de direcciones IP |
| Resolución de CAPTCHA | Servicio independiente | Incluido | Incluido |
| Esfuerzo de mantenimiento | Tiempo de ingeniería continuo | Gestionado por el proveedor | Sin mantenimiento |
| Impacto del tiempo de inactividad | Absorbido por su equipo | Reducido por el proveedor | 99,9 % de tiempo de actividad SLA |
Ejemplo de coste real
Considere una carga de trabajo que recopila 500 000 páginas al mes de sitios protegidos.
Configuración local:
- Servidores y ancho de banda: 300 $ al mes
- Proxies residenciales: 1250 $ al mes
- Resolución de CAPTCHA: 150 $ al mes
- Mantenimiento técnico: 3000 $ al mes
- Total: 4700 $ al mes
Configuración en la nube:
- Solicitudes con renderización: 1500 $ al mes
- Transferencia de datos: 50 $ al mes
- Total: 1550 $ al mes
El enfoque de la nube reduce el coste mensual en aproximadamente un 70 % a esta escala.
El punto de equilibrio
- Por debajo de 5000 páginas al mes: a menudo gana la opción local
- Entre 5000 y 10 000 páginas: los costes convergen
- Por encima de 10 000 páginas: la nube suele ser más económica
Más allá de este punto, los costes locales crecen de forma lineal. Los costes de la nube escalan de forma predecible con el uso.
Cuándo utilizar el scraping local
El scraping local es la opción adecuada cuando se dan todas las siguientes condiciones:
- Se extraen menos de 1000 páginas por ejecución
- Los sitios de destino tienen una protección mínima contra los bots
- Los datos no pueden salir de su entorno
- Acepta el mantenimiento manual
- El scraping no es crítico para el negocio
Fuera de estas condiciones, los costes y los riesgos aumentan rápidamente.
Cuándo utilizar el scraping en la nube
El scraping en la nube es adecuado cuando se da alguna de las siguientes circunstancias:
- El volumen supera las 10 000 páginas al mes
- Los sitios implementan una protección agresiva contra los bots
- Se requiere renderización JavaScript
- Los datos deben actualizarse continuamente
- La fiabilidad es más importante que el control de la ejecución
En este punto, la propiedad de la infraestructura se convierte en una responsabilidad.
Cómo Bright Data simplifica el scraping en la nube
Bright Data define dónde se ejecuta el scraping y qué capas ya no se utilizan. Se encarga de la infraestructura de scraping que hace que el scraping sea costoso de ejecutar y mantener:
- Acceso a la red: enrutamiento de solicitudes a través de una infraestructura de Proxy gestionada
- Ejecución del navegador: navegadores remotos para sitios con mucho JavaScript.
- Mitigación antibots: rotación de IP, detección de bloqueos y reintentos.
- Gestión de fallos: control de ejecución y lógica de reintentos.
- Mantenimiento: actualizaciones continuas a medida que cambian los sitios y las defensas.
- Control de sesión: mantenimiento de sesiones persistentes entre solicitudes.
- Precisión geográfica: país, ciudad, operador o ASN de destino.
- Gestión de huellas digitales: reducción de la detección mediante huellas digitales a nivel del navegador.
- Control del tráfico: limitar, aumentar o distribuir la carga de forma segura.
Rutas de ejecución y herramientas
Bright Data expone esta infraestructura a través de distintas herramientas en función de sus necesidades.
API del navegador de scraping
Utilice el Navegador de scraping cuando los sitios requieran renderización JavaScript o interacción similar a la del usuario. Su lógica Selenium o Playwright existente se ejecuta en navegadores alojados en Bright Data en lugar de en instancias locales.
Bright Data sustituye los clústeres de navegadores locales, la gestión del ciclo de vida y el ajuste de recursos.
API Web Unlocker
Utilice Web Unlocker para el scraping basado en HTTP en sitios protegidos. Bright Data enruta las solicitudes a través de una infraestructura de Proxy adaptativa y aplica el manejo de bloqueos integrado.
Esto elimina la necesidad de obtener proxies, rotar IP o escribir lógica de reintento en su código.
API de Scraper (Conjuntos de datos preconstruidos)
Utilice las API de Web Scraper para plataformas estandarizadas como Amazon, Google, LinkedIn y muchas más. Ofrece más de 150 Scrapers preconstruidos para todas las principales plataformas de comercio electrónico y redes sociales.
Bright Data devuelve datos estructurados sin automatización del navegador ni analizadores personalizados. Esto elimina el mantenimiento de Scrapers específicos del sitio para fuentes de datos comunes.
Lo que desaparece de su pila
Cuando utiliza Bright Data, ya no opera con:
- Grupos de proxies o lógica de rotación de IP
- Clústeres de navegadores locales o autogestionados
- Servicios de resolución de CAPTCHA
- Código personalizado de reintento y detección de bloqueos
- Soluciones continuas para cambios en el sitio y la detección
Estos costes operativos se acumulan rápidamente en las configuraciones locales y en la nube DIY.
Bright Data frente a otras herramientas de scraping en la nube
Las plataformas de scraping en la nube no son intercambiables. La elección correcta depende de la cantidad de scraping que realice, del nivel de protección de los objetivos y de la infraestructura que esté dispuesto a operar.
Comparación directa
| Proveedor | Escala | Pool de IP | Cumplimiento | Ideal para |
|---|---|---|---|---|
| Bright Data | Empresa (miles de millones) | Más de 150 millones | SOC2, RGPD, CCPA | Producción a gran escala |
| ScrapingBee | Pequeña-mediana | Limitada | Parcial | Proyectos sencillos |
| Octoparse | Basado en GUI | Grupo pequeño | Limitado | Usuarios sin conocimientos técnicos |
Dónde encaja Bright Data
Bright Data es ideal para cargas de trabajo en las que el scraping es continuo y operativamente importante.
Esto incluye casos en los que:
- El volumen supera las 10 000 páginas al mes
- Los objetivos implementan defensas modernas contra los bots
- Se requiere renderización JavaScript
- Los datos alimentan sistemas o análisis posteriores
- Los fallos de scraping tienen un impacto en el negocio
En estos casos, la propiedad de la infraestructura influye más en los costes y los riesgos que la simplicidad de la API.
Cuando otras herramientas son suficientes
Las herramientas en la nube más ligeras funcionan cuando las restricciones son menores.
Los servicios basados en API son adecuados para:
- Tareas de scraping pequeñas o periódicas
- Sitios con protección limitada
- Cargas de trabajo en las que se aceptan fallos ocasionales
Las herramientas basadas en GUI son adecuadas para:
- Usuarios sin conocimientos técnicos
- Recopilación de datos puntual o manual
- Tareas exploratorias o ad hoc
Estas herramientas reducen el esfuerzo de configuración, pero no eliminan las limitaciones operativas a gran escala.
Cómo elegir
La decisión refleja los umbrales de coste y uso anteriores:
- Si el scraping es pequeño, poco frecuente o no crítico, a menudo bastan herramientas más sencillas
- Si el rastreo es continuo, protegido o crítico para el negocio, la infraestructura gestionada es importante.
Conclusión
Empiece con el scraping local para aprender. Ejecutar un Scraper en su propia máquina le enseña cómo funcionan las solicitudes, el parseo y los fallos. Para trabajos pequeños de menos de 1000 páginas, este enfoque suele ser suficiente.
Pase al scraping en la nube cuando la escala o la protección cambien la ecuación de costes. Una vez que el volumen supera las 10 000 páginas al mes, los objetivos implementan defensas modernas contra los bots o los datos deben actualizarse continuamente, la propiedad de la infraestructura se convierte en una limitación.
El scraping local le da control y responsabilidad. El scraping en la nube cambia algo de control por una ejecución predecible, un menor riesgo operativo y costes escalables.
Para las cargas de trabajo de producción, la infraestructura de scraping en la nube es infraestructura. No ejecutaría su propio CDN o servidores de correo electrónico a gran escala. La infraestructura de scraping sigue la misma lógica.
Si su caso de uso se ajusta a ese perfil, plataformas como Bright Data le permiten mantener la lógica de extracción mientras traslada la ejecución y el mantenimiento fuera de su pila.
Preguntas frecuentes: Rastreo en la nube frente a rastreo local
¿Qué es el scraping local?
El scraping local se ejecuta en máquinas que usted controla. Usted mismo gestiona las solicitudes, los Proxies, los navegadores, los reintentos y los fallos. Funciona mejor para trabajos pequeños y poco frecuentes en sitios con poca protección.
¿Qué es el scraping en la nube?
El scraping en la nube se ejecuta en una infraestructura operada por un tercero. Usted envía solicitudes a una API y recibe los datos extraídos como respuesta. El proveedor de scraping se encarga de la ejecución, el escalado, la rotación de IP, la Resolución de CAPTCHA, la superación de medidas antibots y mucho más.
¿Cuándo debo cambiar del scraping local al scraping en la nube?
Cambie cuando se dé cualquiera de las siguientes circunstancias:
- Aparecen bloqueos de IP tras un volumen limitado de solicitudes
- Los CAPTCHA interrumpen la automatización
- El volumen supera las 10 000 páginas al mes
- Es necesario el renderizado de JavaScript
- Los fallos de scraping afectan a los sistemas posteriores
En ese momento, la propiedad de la infraestructura se convierte en una responsabilidad.
¿El scraping en la nube es más caro que el scraping local?
Las configuraciones locales acumulan costes de servidor, Proxy, mantenimiento y tiempo de inactividad. El precio de la nube se adapta al uso y elimina los gastos generales fijos de infraestructura.
- A pequeña escala, el scraping local suele ser más barato
- A gran escala, el scraping en la nube suele ser más barato
¿El scraping en la nube puede manejar sitios con mucho JavaScript?
Sí. Las plataformas en la nube operan navegadores gestionados que ejecutan JavaScript de forma remota.
El scraping local requiere ejecutar navegadores sin interfaz gráfica, lo que limita la concurrencia y aumenta el mantenimiento.
¿Cómo reduce el scraping en la nube el bloqueo de IP?
Los proveedores de nube operan grandes redes de Proxy y gestionan el enrutamiento de solicitudes. La rotación de IP y la lógica de reintento se producen a nivel de infraestructura.
¿El scraping en la nube es adecuado para datos confidenciales o regulados?
No siempre. Algunas cargas de trabajo no pueden salir de entornos controlados debido a políticas o regulaciones. Pero Bright Data ofrece soluciones de scraping que cumplen totalmente con SOC2, GDPR y CCPA.
¿Puedo combinar el scraping local y en la nube?
Sí, pero la complejidad aumenta.
Algunos equipos desarrollan y prueban los Scrapers localmente y luego ejecutan las cargas de trabajo de producción en la nube. Esto requiere mantener dos entornos de ejecución y gestionar las diferencias entre ellos.
La mayoría de los equipos eligen un enfoque en función de sus principales limitaciones.
¿Qué tipo de equipos se benefician más de las plataformas de scraping en la nube como Bright Data?
Los equipos que ejecutan el scraping como un sistema continuo o crítico para el negocio. Esto incluye cargas de trabajo con un gran volumen, objetivos protegidos, renderización de JavaScript o un Ancho de banda de ingeniería limitado.






