

Google eliminó el parámetro num en septiembre de 2025 sin previo aviso. La representación de JavaScript pasó a ser obligatoria y las descripciones generales de IA se implementaron en 200 países y territorios. Si estás rastreando Google, tus solicitudes HTTP sin procesar ahora devuelven respuestas vacías o degradadas, la paginación basada en num no funciona y el contenido generado por IA empuja los resultados orgánicos por debajo del pliegue.
Todas las URL de búsqueda de Google contienen parámetros después del signo ? (como q para la consulta, gl para el país, hl para el idioma, tbs para los filtros de tiempo y muchos más). Si se comete un error al introducirlos, el Scraper devolverá datos del país equivocado o resultados vacíos que serán difíciles de depurar.
A continuación se muestran todos los parámetros importantes, con código probado y ejemplos prácticos. Todo el código se ejecutó con la API SERP de Bright Data en tiempo real.
TL;DR: Lo que necesitas saber para 2026:
- Seguimiento de posiciones:
q=...&gl=us&hl=en&pws=0&udm=14&brd_json=1(no personalizado, sin resúmenes de IA)- Paginación:
start=10,start=20, etc. (10 resultados por página).numya no funciona- Filtros de tiempo:
tbs=qdr:d(último día),tbs=sbd:1(ordenar por fecha),tbs=li:1(textual)- Nuevo:
udmamplíatbmcon modos comoudm=14(solo web, sin IA). Ambos funcionan actualmente. Admite ambos.- Requisito: renderización JavaScript. Las llamadas raw
requests.get()devuelven resultados vacíos desde enero de 2025
Ejemplo mínimo funcional:
curl -X POST "https://api.brightdata.com/request"
-H "Content-Type: application/json"
-H "Authorization: Bearer <API_TOKEN>"
-d '{"zone":"<ZONE_NAME>","url":"https://www.google.com/search?q=tools+for+scraping+web+content&gl=us&hl=en&brd_json=1","format":"raw"}'(brd_json=1 en la URL le indica a Bright Data que realice el parseo del HTML de Google en JSON estructurado. El formato: raw en el cuerpo de la solicitud devuelve la respuesta tal cual desde la infraestructura de Bright Data, que en este caso es el JSON analizado producido por brd_json=1).
Referencia rápida: hoja de referencia de parámetros de búsqueda de Google
| Parámetro | Qué hace | Estado |
|---|---|---|
q |
Consulta de búsqueda | Activo |
hl |
Idioma de la interfaz (en, fr, de) |
Activo |
gl |
Geolocalización/país (us, gb, in) |
Activo |
lr |
Restringir los resultados a idiomas específicos | Activo |
cr |
Restringir los resultados a páginas alojadas en países específicos | Activo |
num |
Resultados por página | Inactivo (septiembre de 2025) |
Inicio |
Desplazamiento de paginación | Activo |
tbm |
Tipo de búsqueda (isch, nws, shop, vid) |
Activo |
udm |
Filtro de modo de contenido (14, 2, 39, 50) |
Activo (Nuevo) |
tbs |
Filtros de tiempo y avanzados (qdr:d, qdr:w) |
Activo |
seguro |
Filtrado SafeSearch | Activo |
Filtro |
Filtrado de resultados duplicados | Activo |
nfpr |
Desactivar autocorrección | Activo |
pws |
Desactivar resultados personalizados (pws=0) |
Activo |
uule |
Ubicación codificada (segmentación a nivel de ciudad) | Activo |
sclient |
Identificador de cliente de búsqueda | Activo (interno) |
kgmid |
ID de entidad del gráfico de conocimiento | Activo |
si |
Pestañas del gráfico de conocimiento (cadena codificada opaca; no construible por el usuario) | Activo (interno) |
ibp |
Control de representación (trabajos, listados de empresas) | Activo |
ei, ved, sxsrf |
Seguimiento interno / tokens de sesión | Activo (interno) |
Los operadores de búsqueda de Google (site:, filetype:, intitle:, etc.) se tratan en la sección de operadores más adelante.
Prueba búsquedas básicas en el API SERP, sin necesidad de iniciar sesión. Para obtener el conjunto completo de parámetros, utiliza directamente la API.
¿Qué son los parámetros de búsqueda de Google?
Los parámetros de búsqueda de Google controlan la consulta, la ubicación, el idioma y el filtrado de los resultados. Son importantes para el seguimiento del posicionamiento SEO, el análisis de la competencia, la supervisión de anuncios y la introducción de resultados de búsqueda en aplicaciones LLM.
Un cambio que se produjo en 2025: Google anunció en abril de 2025 que los ccTLD (dominios de nivel superior con código de país, como google.co.uk, google.de o google.ca) redirigirán a google.com. La implementación es gradual y algunos ccTLD siguen mostrando los resultados directamente. En cualquier caso, utilice gl y hl para la localización, no el dominio.
Parámetros de búsqueda básicos
Estos son los que se establecen en casi todas las solicitudes: consulta, idioma, país y paginación.
q: consulta de búsqueda
Tu consulta de búsqueda va en q.
https://www.google.com/search?q=bright+data+Scraping webLos espacios en la consulta se codifican como + o %20. El parámetro q también admite los operadores de búsqueda de Google, por ejemplo:
https://www.google.com/search?q=filetype:pdf+web+scraping+guide
https://www.google.com/search?q=site:github.com+API SERP
https://www.google.com/search?q=intitle:proxy+rotation+tutorialCodifique correctamente la cadena de consulta en la URL, especialmente los caracteres no latinos (chino, árabe, japonés, coreano, etc.). Si no se codifican, es habitual que se obtengan resultados inesperados o vacíos. Si utiliza la API SERP de Bright Data, coloque siempre el parámetro q en primer lugar en la URL. La documentación de Bright Data así lo exige. Colocar otros parámetros antes de q puede ralentizar las respuestas y reducir las tasas de éxito.
A través del método Proxy de la API SERP de Bright Data:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Scraping web tools&brd_json=1"Si necesita conservar el HTML sin procesar dentro del JSON, utilice brd_json=html en lugar de brd_json=1. La API directa admite formatos de salida adicionales, como Markdown, capturas de pantalla y salida analizada ligera.
La respuesta JSON tiene este aspecto (recortada):
{
"general": {
"search_engine": "google",
"results_cnt": 33500000,
"search_time": 0.21,
"language": "en",
"mobile": false,
"search_type": "text"
},
"input": {
"original_url": "https://www.google.com/search?q=Scraping web tools&brd_json=1"
},
"organic": [
{
"link": "https://www.reddit.com/r/automation/comments/1ncuv8k/best_web_scraping_tools_ive_tried_and_what_i/",
"title": "Las mejores herramientas de Scraping web que he probado (y lo que he aprendido de ...",
"description": "Playwright: ideal para la automatización estructurada y las pruebas, aunque un poco pesado en código para un scraping ligero.",
"rank": 1,
"global_rank": 5
}
]
}El JSON agrupa todo por sección SERP. Los resultados orgánicos están separados de top_ads y bottom_ads, los paneles de conocimiento están separados de people_also_ask, los resultados locales están en snack_pack y las funciones más recientes, como ai_overview, están en sus propios campos. Hay más de una docena de secciones en total, dependiendo de la consulta.
hl – idioma del host
Abreviatura de «host language» (idioma del host), hl controla el idioma de la interfaz de Google y cómo Google interpreta tu consulta.
https://www.google.com/search?q=coffee&hl=en
https://www.google.com/search?q=coffee&hl=es
https://www.google.com/search?q=coffee&hl=jaLos valores son códigos ISO 639-1 como hl=en (inglés), hl=fr (francés), hl=de (alemán) o etiquetas de idioma BCP 47 como hl=en-gb (inglés británico), hl=pt-br (portugués brasileño), hl=es-419 (español latinoamericano).
A través de la API SERP, la misma búsqueda se ve así:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=meilleurs+outils+de+scraping&hl=fr&gl=fr&brd_json=1"Esto obtiene resultados en francés para una consulta en francés, como si estuvieras buscando desde Francia.
gl – geolocalización
La ubicación de la búsqueda afecta a los resultados. El parámetro gl simula su geolocalización (el país desde el que parece originarse la búsqueda). Utiliza códigos de país de dos letras ISO 3166-1 alfa-2.
https://www.google.com/search?q=pizza+delivery&gl=us
https://www.google.com/search?q=pizza+delivery&gl=gb
https://www.google.com/search?q=pizza+delivery&gl=inCompare la misma consulta en dos países:
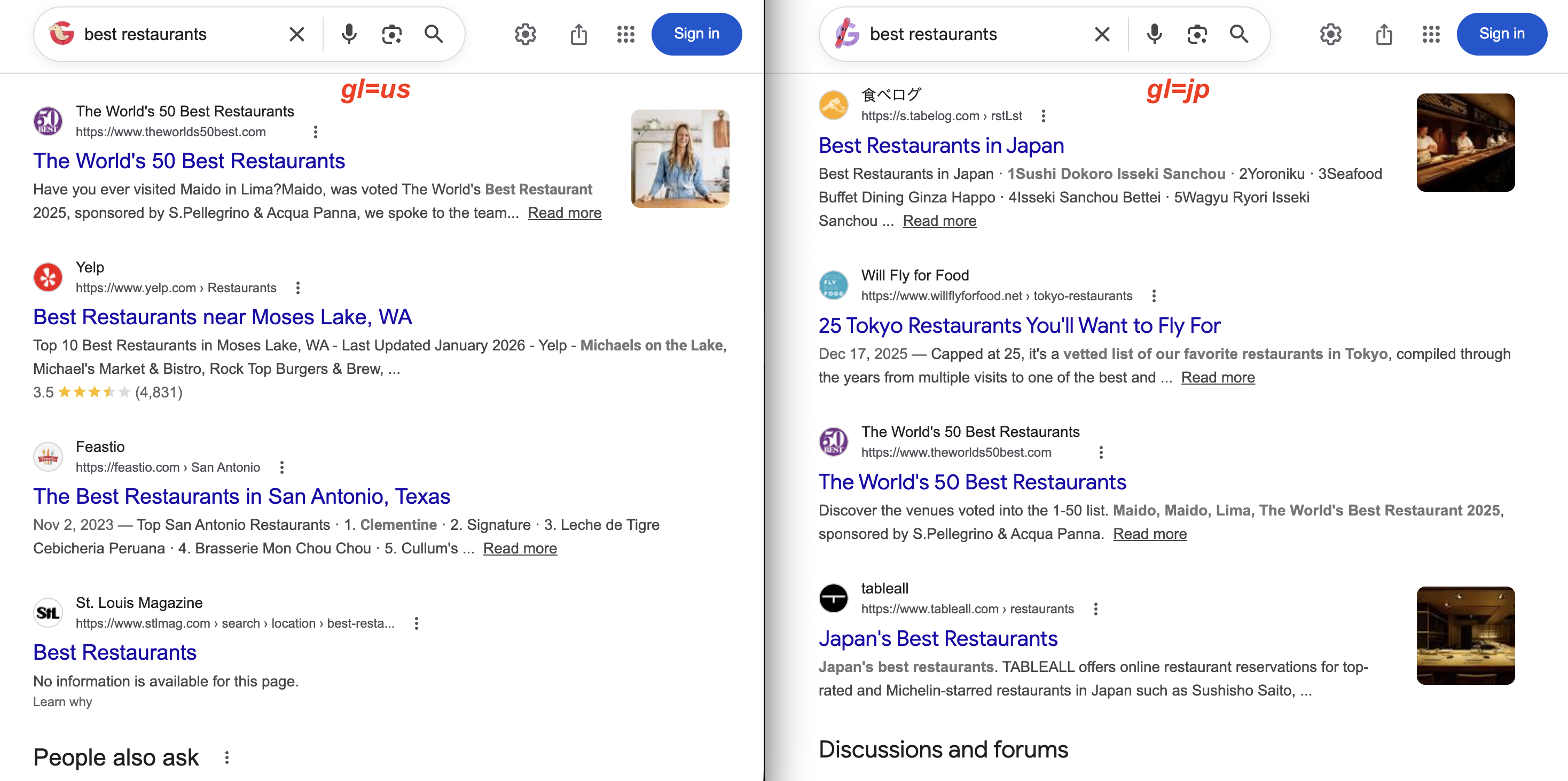
gl=us devuelve Yelp y revistas locales estadounidenses. Con gl=jp, los resultados muestran 食べログ (Tabelog) y guías de restaurantes de Tokio. La misma consulta, resultados muy diferentes.
lr: restricción de idioma
Si se busca «machine learning» con hl=en, siguen apareciendo artículos en chino, japonés o alemán si Google los considera relevantes. El parámetro lr resuelve este problema. Restringe los resultados a páginas escritas realmente en idiomas específicos, no solo en la interfaz.
https://www.google.com/search?q=machine+learning&lr=lang_en
https://www.google.com/search?q=machine+learning&lr=lang_en|lang_frAnteponga el código del idioma con lang_ (por lo tanto, inglés es lang_en, francés es lang_fr). Utilice la barra vertical | para combinar varios idiomas.
cr – restricción por país
Similar a lr, pero filtra por país de alojamiento en lugar de por idioma del contenido. Utilice cr=countryUS para un solo país, cr=countryUS|countryGB para varios. La diferencia clave con respecto a gl: gl geolocaliza su búsqueda como si estuviera en ese país, cr filtra las páginas que realmente están alojadas allí. Utilice ambos juntos si necesita un filtrado exacto.
num: número de resultados
El parámetro num se utiliza para controlar cuántos resultados de búsqueda aparecen por página (por ejemplo, num=20, num=50, num=100).
Si su Scraper comenzó a devolver solo 10 resultados después de septiembre de 2025, este cambio de parámetro es la razón. A partir de septiembre de 2025, Google desactivó silenciosamente el parámetro num. Ahora se ignora por completo. Google devuelve 10 resultados por página independientemente del valor num que se pase, sin errores ni redireccionamientos. Esto rompió las herramientas de SEO y los flujos de trabajo de rastreo de SERP que dependían de él. Un portavoz de Google lo ha confirmado: «El uso de este parámetro URL no es algo que admitamos oficialmente». La sección de cambios de 2025-2026 cubre la solución alternativa utilizando el punto final Top 100 Results de Bright Data.
Puede verificarlo. num=100 está en la URL, pero solo se obtienen 10 resultados:
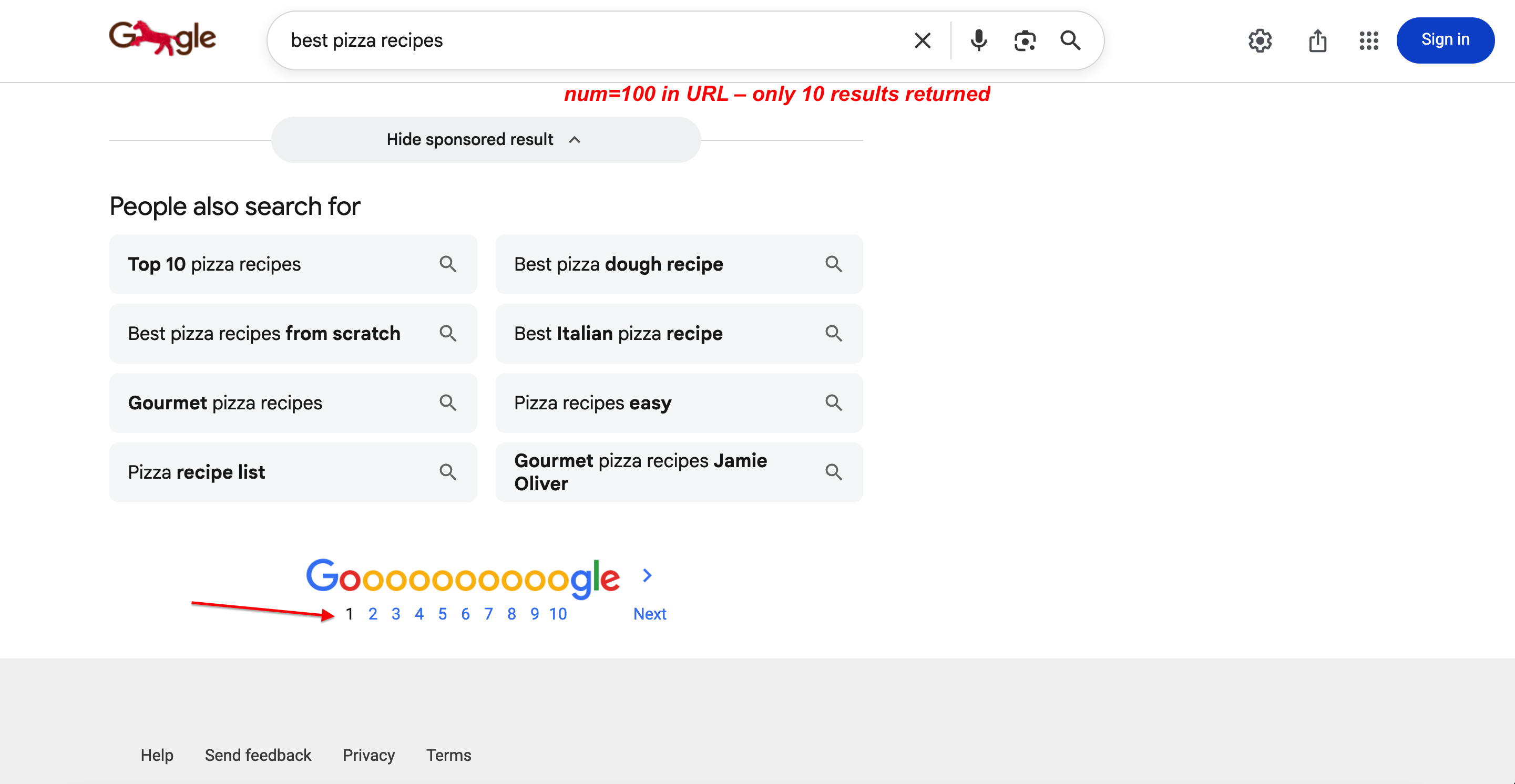
Búsqueda con num=100 en la URL. Google sigue devolviendo solo 10 resultados por página con paginación completa. El parámetro se ignora por completo.
start: desplazamiento del resultado (paginación)
Dado que Google ha eliminado num, start es su única opción de paginación nativa. Establece el desplazamiento de resultados, controlando desde qué posición de resultados comenzar.
https://www.google.com/search?q=Scraping web&start=0
https://www.google.com/search?q=Scraping web&start=10
https://www.google.com/search?q=Scraping web&start=20start=0 es la página 1 (la predeterminada), start=10 es la página 2 y start=20 es la página 3.
Dado que Google devuelve 10 resultados por página, start=20 te da los resultados 21-30, start=30 te da los 31-40, y así sucesivamente. Al paginar en varias páginas, Google puede devolver resultados superpuestos o ligeramente reordenados entre páginas. Desduplica por URL antes de procesar.
Paginación a través de la API SERP:
# Obtener la página 3 de los resultados
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=serp+scraping&start=20&brd_json=1"Parámetros de tipo de búsqueda
Google tiene dos parámetros para cambiar entre verticales de búsqueda (imágenes, noticias, compras, vídeos): tbm y udm.
tbm: tipo de contenido de búsqueda
El parámetro tbm (que suele interpretarse como «to be matched», aunque Google nunca ha confirmado el acrónimo) le indica a Google qué tipo de resultados de búsqueda desea. Sin él, Google utiliza por defecto la búsqueda web normal.
| Valor | Tipo de búsqueda | Ejemplo |
|---|---|---|
| (vacío) | Búsqueda web | q=café |
isch |
Búsqueda de imágenes | tbm=isch&q=café |
vid |
Búsqueda de vídeos | tbm=vid&q=café |
nws |
Búsqueda de noticias | tbm=nws&q=café |
tienda |
Búsqueda de tiendas | tbm=shop&q=café |
bks |
Búsqueda de libros | tbm=bks&q=café |
La misma consulta en tres tipos de búsqueda:
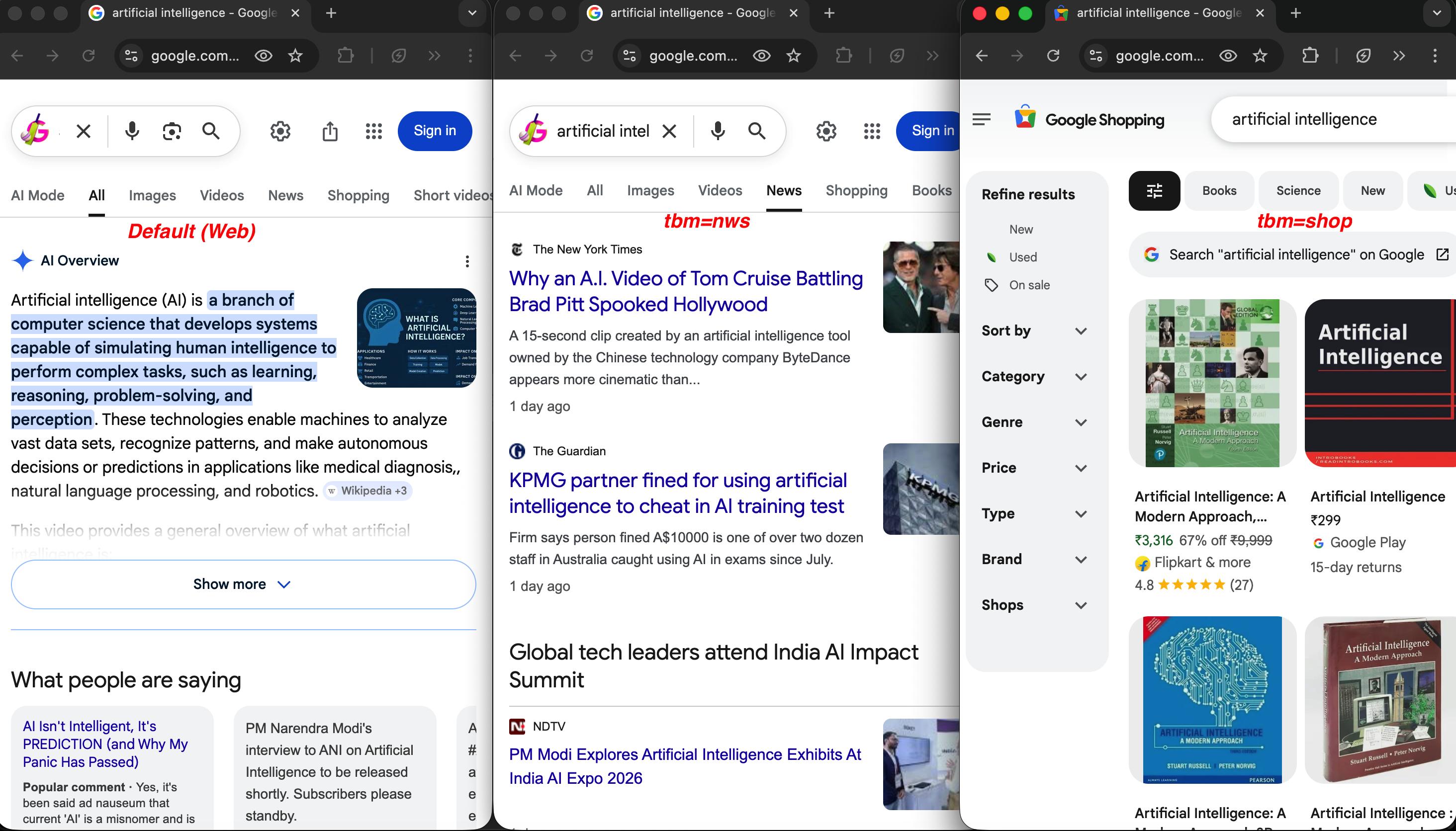
Misma consulta, diferentes valores tbm: la búsqueda web predeterminada (izquierda) muestra una descripción general de la IA, tbm=nws (centro) devuelve artículos de noticias del NYT y The Guardian, y tbm=shop (derecha) muestra listados de productos con precios y valoraciones.
Búsqueda de noticias sobre inteligencia artificial:
https://www.google.com/search?q=artificial+intelligence&tbm=nws&hl=en&gl=usBúsqueda de teclados mecánicos:
https://www.google.com/search?q=mechanical+keyboard&tbm=shop&gl=usTodos estos tipos de búsqueda funcionan de forma nativa. Al realizar el parseo de la respuesta JSON, los anuncios se separan en los campos top_ads y bottom_ads, y los listados de productos aparecen en popular_products, todos ellos distintos de los resultados orgánicos. Para la supervisión dedicada de anuncios, consulte el Scraper de Google Ads. Los parámetros de viajes y hoteles (hotel_occupancy, hotel_dates, brd_dates, brd_occupancy, brd_currency, etc.) son específicos de Bright Data y están documentados en la referencia de parámetros de la API SERP.
udm: modo de visualización del usuario
El nuevo filtro de modo de contenido de Google es udm, que amplía tbm con tipos de resultados adicionales. Controla el «modo» de los resultados de búsqueda que se ven. Ninguno de los valores udm aparece en la documentación oficial de Google. Todos ellos han sido diseñados por la comunidad de desarrolladores mediante pruebas. Los valores que se indican a continuación son estables y se utilizan ampliamente, pero Google podría cambiarlos sin previo aviso.
| Valor | Modo de resultado | Descripción |
|---|---|---|
udm=2 |
Imágenes | Resultados de la búsqueda de imágenes |
udm=7 |
Vídeos | Resultados de vídeo; equivalente más reciente de tbm=vid |
udm=12 |
Noticias | Resultados de noticias; equivalente más reciente de tbm=nws |
udm=14 |
Web | Resultados web clásicos sin funciones de IA |
udm=18 |
Foros | Resultados de debates y foros |
udm=28 |
Compras | Resultados de compras/productos |
udm=36 |
Libros | Resultados de libros; equivalente más reciente de tbm=bks |
udm=39 |
Vídeos cortos | Contenido de vídeo de formato corto |
udm=50 |
Modo IA | Búsqueda conversacional con tecnología de IA de Google |
El valor más notable es udm=14. Obliga a Google a mostrar resultados web tradicionales sin resúmenes de IA ni otro contenido generado por IA:
https://www.google.com/search?q=Scraping web tools&udm=14La diferencia entre el valor predeterminado y udm=14 es visible de inmediato:
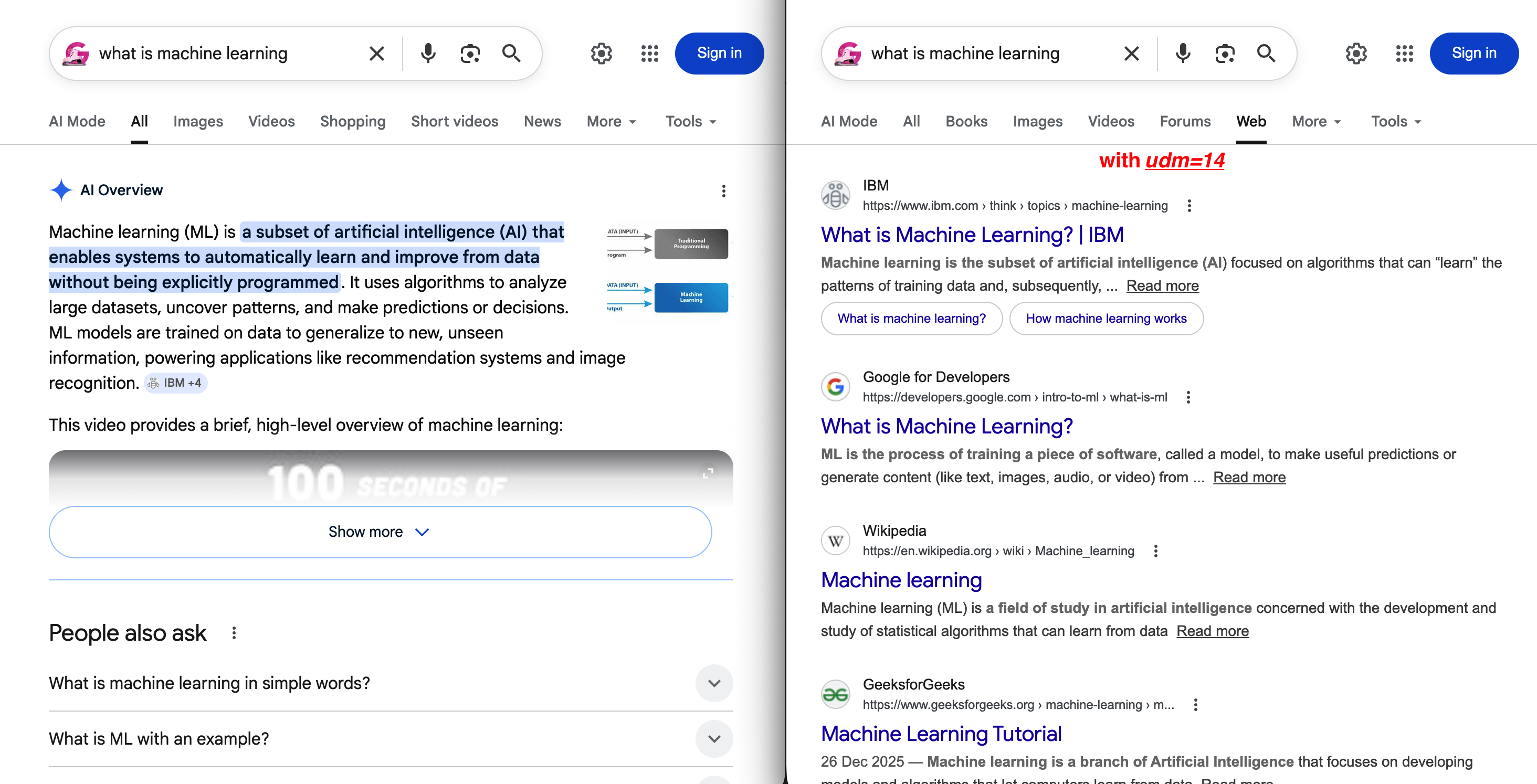
Izquierda: el SERP predeterminado con una descripción general de IA que empuja los resultados orgánicos por debajo del pliegue. Derecha: udm=14 elimina todo eso y muestra una pestaña «Web» limpia con enlaces azules tradicionales.
Para resultados de vídeos cortos, utilice udm=39 (no documentado por Google; el comportamiento puede variar según la región):
https://www.google.com/search?q=coffee+recipes&udm=39El modo IA (udm=50) es un tipo de búsqueda muy diferente:
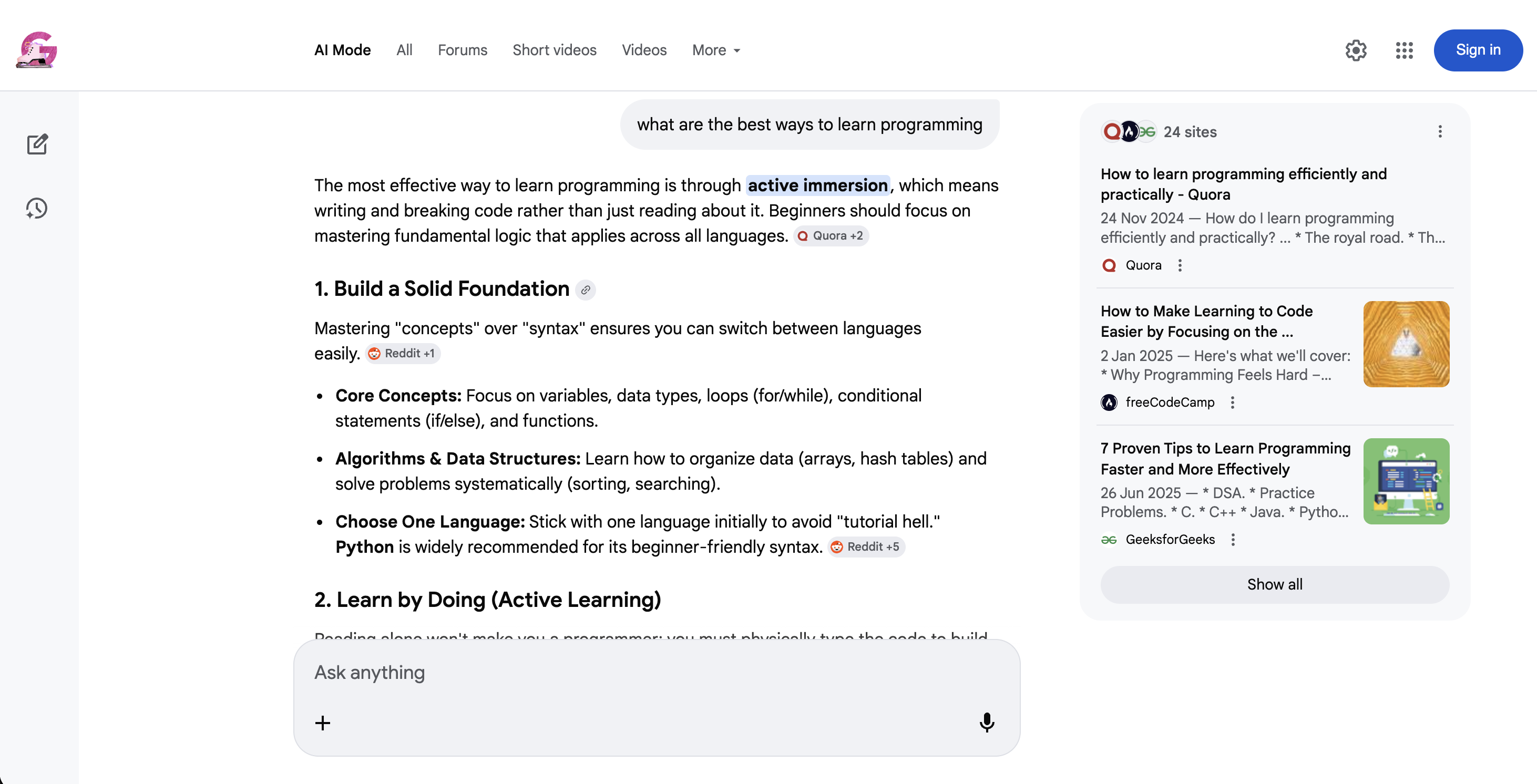
Modo IA de Google (udm=50): en lugar de los resultados tradicionales, Google devuelve una respuesta conversacional de IA con citas de fuentes en línea y preguntas de seguimiento sugeridas.
tbm y udm se superponen para imágenes, noticias y compras, pero udm también cubre modos que tbm no cubre (foros, vídeos cortos, modo IA, solo web). Ambos funcionan actualmente. Si está creando nuevos flujos de trabajo de scraping, admita ambos parámetros para obtener la máxima compatibilidad.
Parámetros de filtrado y clasificación
tbs: filtros basados en el tiempo y avanzados
El parámetro tbs (que se interpreta comúnmente como «para buscar», aunque ninguna fuente oficial lo confirma) controla el filtrado por tiempo, la clasificación por fecha y la coincidencia literal.
El uso más común es el filtrado por tiempo con qdr (rango de fechas de consulta):
| Valor | Intervalo de tiempo |
|---|---|
tbs=qdr:h |
Última hora |
tbs=qdr:d |
Últimas 24 horas |
tbs=qdr:w |
Última semana |
tbs=qdr:m |
Último mes |
tbs=qdr:y |
Último año |
También puede establecer un intervalo de fechas personalizado con tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025. Esto resulta útil para realizar un seguimiento de cómo cambian los resultados de búsqueda durante un período específico.
Además del filtrado por tiempo, tbs tiene otros dos modos útiles. tbs=sbd:1 obliga a Google a ordenar los resultados por fecha (los más recientes primero) en lugar de por relevancia, lo que resulta útil para supervisar las menciones recientes. Y tbs=li:1 habilita la búsqueda literal. Google busca exactamente lo que has escrito sin autocorrecciones, sinónimos ni términos relacionados.
Para supervisar las noticias recientes sobre un tema:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Scraping web regulations&tbs=qdr:w&brd_json=1"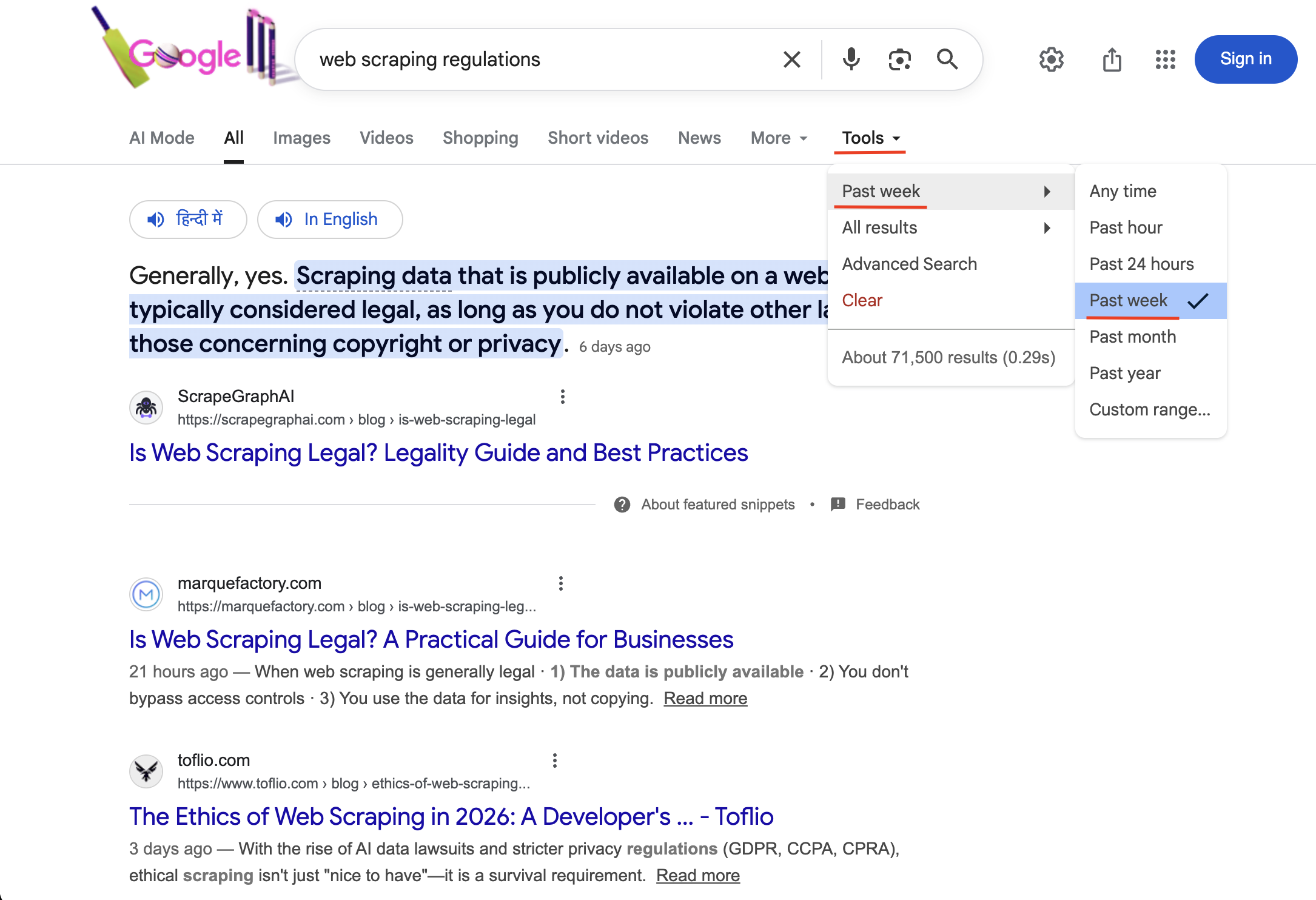
La búsqueda con tbs=qdr:w activa el filtro temporal «Última semana» (visible en Herramientas con una marca de verificación). Solo se muestran los resultados publicados en los últimos 7 días.
Consejo: combina filter=0 con cualquier filtro de tiempo tbs para obtener todos los resultados. Sin él, Google agrupa páginas similares y es posible que te pierdas información relevante.
safe: filtrado SafeSearch
safe=active filtra el contenido explícito, safe=off desactiva el filtrado.
https://www.google.com/search?q=photography&safe=active
https://www.google.com/search?q=photography&safe=offfilter: filtrado de duplicados
El parámetro filter controla cómo Google agrupa resultados similares o duplicados.
https://www.google.com/search?q=Scraping web&filter=0
https://www.google.com/search?q=Scraping web&filter=1filter=0 muestra todos los resultados, incluidos los duplicados. filter=1 (el valor predeterminado) agrupa las páginas similares. Es más útil cuando se combina con filtros de tiempo (consulte el consejo tbs anterior).
nfpr: sin autocorrección
Establezca nfpr=1 para evitar que Google corrija automáticamente su consulta.
https://www.google.com/search?q=scraping+brwser&nfpr=1Cuando se establece en 1, Google buscará exactamente lo que ha escrito sin sugerir «¿quiere decir: Navegador de scraping?». Es útil cuando busca intencionadamente términos mal escritos, nombres de marcas que Google considera errores ortográficos o términos técnicos que Google podría intentar corregir. Nota: nfpr=1 solo suprime la autocorrección. tbs=li:1 (modo literal) va más allá y también desactiva los sinónimos, la derivación y los términos relacionados. Utiliza ambos juntos para obtener la coincidencia más estricta.
pws: búsqueda web personalizada
Google personaliza los resultados de búsqueda de forma predeterminada. pws controla si esa personalización está activa.
https://www.google.com/search?q=Scraping web tools&pws=0Desactivar la personalización (pws=0) es importante porque los resultados personalizados varían según el usuario, lo que hace que los datos masivos sean inconsistentes. Para cualquier recopilación seria de datos SERP, incluya siempre pws=0 para obtener las clasificaciones básicas, no personalizadas.
Parámetros de ubicación
La mayoría de los seguimientos de clasificaciones solo necesitan una segmentación a nivel de país con gl. Sin embargo, para el SEO local, se necesita una segmentación más precisa.
uule: ubicación codificada
uule le ofrece precisión a nivel de ciudad cuando gl no es lo suficientemente granular.
El valor uule es una cadena codificada basada en los objetivos geográficos de la API de Google Ads. Utiliza una codificación de nombre canónico (de la base de datos de geolocalización de Google) o una codificación de coordenadas GPS (latitud/longitud).
https://www.google.com/search?q=best+restaurants&uule=w+CAIQICIGUGFyaXMGenerar valores uule manualmente es complicado. Debes buscar el nombre canónico de la ubicación en la documentación de Geo Targets de Google y, a continuación, codificarlo en el formato específico que espera Google.
Con la API SERP de Bright Data, puede omitir por completo la codificación y simplemente pasar el nombre del lugar como una cadena legible:
https://www.google.com/search?q=best+restaurants&uule=New+York,New+York,United+StatesLa API se encarga de la búsqueda y la codificación automáticamente.
Utilice gl para la segmentación a nivel de país y uule cuando necesite precisión a nivel de ciudad. Para la mayoría de los seguimientos de posicionamiento, gl es suficiente. Reserve uule para auditorías de SEO locales en las que los resultados difieren entre ciudades del mismo país.
Parámetros de dispositivo y cliente
Google devuelve resultados diferentes para móviles y ordenadores de sobremesa. Estos parámetros controlan la emulación del dispositivo y la identificación del navegador.
sclient: cliente de búsqueda
Verá sclient en casi todas las URL de búsqueda de Google. Identifica el cliente de búsqueda que inició la búsqueda. Valores comunes: gws-wiz (búsqueda web), gws-wiz-serp (iniciada por SERP), img (búsqueda de imágenes), psy-ab (asociada con la búsqueda instantánea/predictiva de Google). Se utiliza para el análisis interno de Google y no afecta a sus resultados.
brd_mobile / brd_browser: emulación de dispositivos y navegadores
La API SERP ofrece brd_mobile para simular búsquedas desde dispositivos específicos:
| Valor | Dispositivo | Tipo de agente de usuario |
|---|---|---|
0 u omitir |
Ordenador | Escritorio |
1 |
Móvil | Móvil |
iOS o iPhone |
iPhone | iOS |
iPad o tableta iOS |
iPad | Tableta iOS |
Android |
Android | Android |
Tableta Android |
Tableta Android | Tableta Android |
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+apps&brd_mobile=ios&brd_json=1"Si encuentra errores
expect_bodyal utilizarbrd_mobilecon el método Proxy, pruebe con el método Direct API. Suele ser más fiable para la emulación de dispositivos. La integración LangChain también funciona bien aquí, ya que pasadevice_typea través de Direct API automáticamente.
También puede controlar el tipo de navegador con brd_browser:
brd_browser=chrome(Google Chrome)brd_browser=safari(Safari)brd_browser=firefox(Mozilla Firefox, no compatible conbrd_mobile=1)
Si no se especifica, la API elige un navegador aleatorio. Combine ambos parámetros para establecer la combinación exacta de dispositivo + navegador:
curl --proxy brd.superproxy.io:33335
--Proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+smartphones&brd_browser=safari&brd_mobile=ios&brd_json=1"Parámetros avanzados e internos
No es necesario configurar ninguno de estos parámetros. Son parámetros internos de Google. Sin embargo, si desea saber qué significan ei, ved y sxsrf cuando los vea en una URL de Google, en esta sección se explican.
kgmid: ID de máquina del Gráfico de conocimiento
El parámetro kgmid proporciona resultados del Knowledge Graph de Google y puede anular por completo el parámetro q.
https://www.google.com/search?kgmid=/m/07gyp7Esto carga directamente el panel del Knowledge Graph de McDonald’s. Cada entidad tiene un ID de máquina único, y al pasarlo a través de kgmid se obtiene el panel de esa entidad.
El panel que Google devuelve para ese ID:
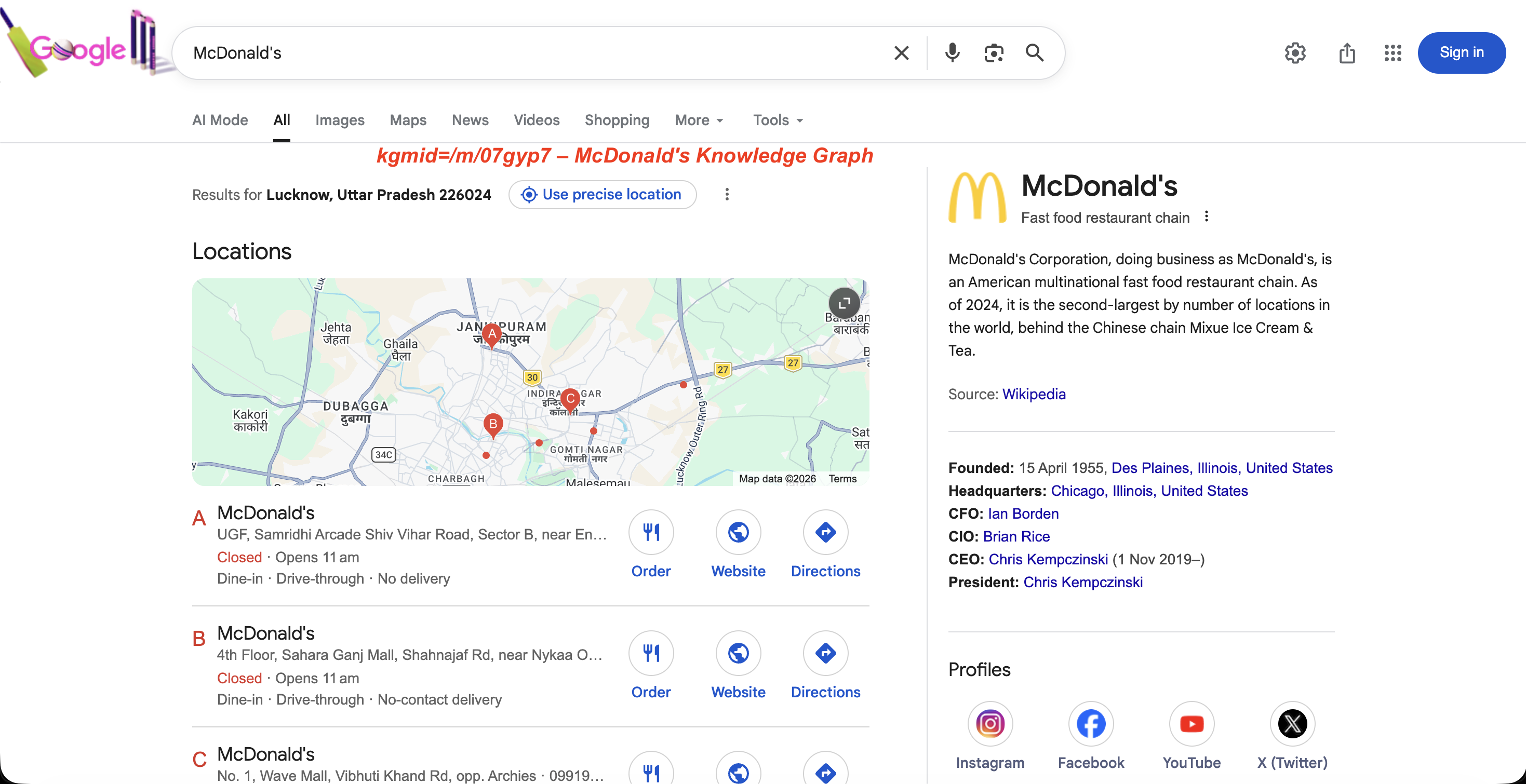
El panel del Gráfico de conocimiento para kgmid=/m/07gyp7: descripción de la entidad, fecha de fundación, liderazgo y perfiles sociales.
Los equipos de supervisión de marcas utilizan esto para realizar un seguimiento de cómo cambia el panel del Gráfico de conocimiento de Google a lo largo del tiempo para su empresa o sus competidores.
ibp: control de renderización
Google no utiliza ibp para los resultados de búsqueda habituales. Controla cómo se representan ciertos elementos en la SERP, en particular los listados de Google Business y Google Jobs.
https://www.google.com/search?ibp=gwp%3B0,7&ludocid=1663467585083384531Cuando se utiliza con el parámetro ludocid (que es el ID único de una ficha de Google Business), ibp puede activar la visualización de la ficha de la empresa a pantalla completa.
Para búsquedas de empleo, ibp=htl;jobs (codificado en URL como ibp=htl%3Bjobs) activa el panel de Google Jobs con listados completos de empleos:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=technical+copywriter&ibp=htl%3Bjobs&brd_json=1"El panel de empleo que activa ibp=htl%3Bjobs:
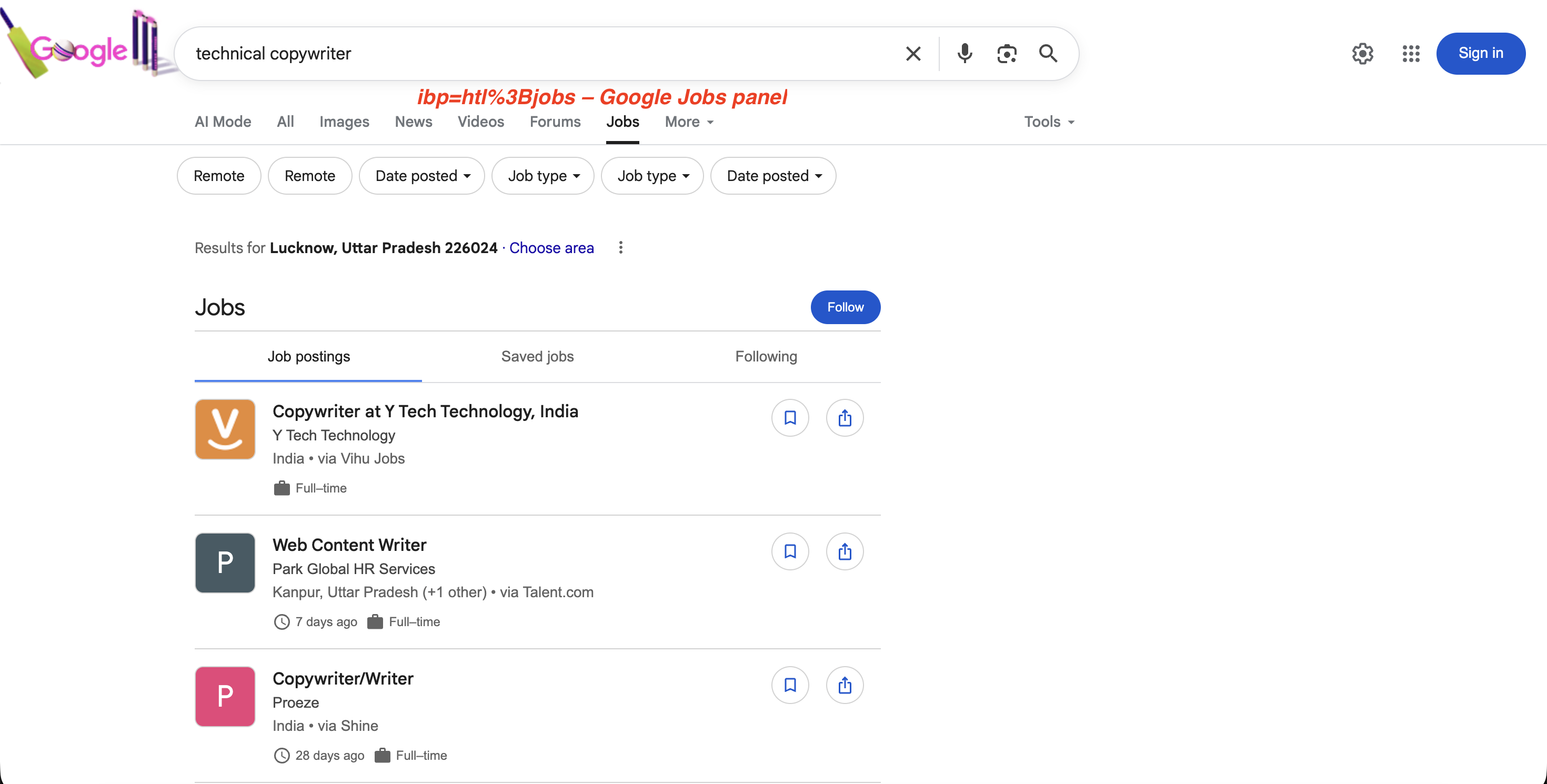
El parámetro ibp=htl%3Bjobs activa el panel de empleos dedicado de Google con ofertas de empleo, filtros y una opción «Seguir», todo ello extraíble a través de la API SERP.
El punto y coma en
htl;jobsdebe codificarse en la URL como%3B(es decir,ibp=htl%3Bjobs) cuando se utiliza en curl o en cualquier cliente HTTP. Sin la codificación adecuada, la solicitud puede devolver resultados vacíos.
ei, ved, sxsrf, oq, gs_lp: parámetros de seguimiento internos
Ninguno de ellos afecta a los resultados que se devuelven. Se pueden eliminar de las URL sin problema. A continuación se explica la función de cada uno:
| Parámetro | Propósito |
|---|---|
ei |
Identificador de sesión que contiene una marca de tiempo Unix y valores opacos |
ved |
Seguimiento de clics: codifica qué elemento SERP se ha pulsado, su índice y tipo |
sxsrf |
Token CSRF con una marca de tiempo Unix codificada |
oq |
Consulta original tal y como se escribió antes de que el autocompletado la modificara (por ejemplo, oq=web+scrap cuando q=web+Scraping web+API). |
gs_lp |
Datos internos de sesión relacionados con el estado del cliente de búsqueda |
ie / oe |
Codificación de caracteres de entrada/salida (casi siempre UTF-8; se puede ignorar) |
client |
Tipo de cliente de búsqueda (por ejemplo, firefox-b-d, safari); identifica el navegador o la aplicación |
fuente |
Identificador de la fuente de búsqueda (por ejemplo, hp para página de inicio, lnms para cambio de modo) |
biw / bih |
Ancho/alto interno del navegador en píxeles; puede influir en la variante de diseño SERP que ofrece Google |
Operadores de búsqueda de Google
Los operadores de búsqueda son comandos especiales dentro del parámetro q que filtran los resultados por dominio, tipo de archivo, título, URL o frase exacta. Google documenta algunos de ellos en su página de ayuda sobre el refinamiento de la búsqueda.
Son distintos de los parámetros URL: los operadores van dentro del valor q, mientras que los parámetros son pares clave-valor separados en la URL. Estos son los más útiles para el scraping y la recopilación de datos:
| Operador | Función | Ejemplo |
|---|---|---|
site: |
Restringe a un dominio específico | site:github.com python Scraper |
tipo de archivo: |
Restringir a un tipo de archivo | filetype:pdf guía de Scraping web |
intitle: |
Buscar en los títulos de las páginas | intitle:comparación de API SERP |
inurl: |
Buscar dentro de las URL | inurl:documentación de la API |
intext: |
Buscar dentro del cuerpo de la página | intext:rotación de Proxy |
allintitle: |
Todas las palabras en el título | allintitle:Scraping web python |
allinurl: |
Todas las palabras en la URL | allinurl:API docs scraping |
related: |
Buscar sitios similares | related:brightdata.com |
O |
Coincidir con cualquiera de los términos | Scraping web O web crawling |
«frase exacta» |
Coincidencia exacta | «API SERP para python» |
- |
Excluir término | Scraping web -selenium |
antes de: / después de: |
Intervalo | Descripción general de IA después: 2025-01-01 |
AROUND(n) |
Búsqueda por proximidad | scraping AROUND(3) python |
definir: |
Definición del diccionario | definir:Scraping web |
* |
Comodín | «lo mejor * para Scraping web» |
Todos estos también funcionan en solicitudes API. Por ejemplo:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=site:reddit.com+Scraping web+tools+2026&brd_json=1"Busca específicamente en Reddit debates sobre herramientas de Scraping web en 2026, con salida JSON estructurada.
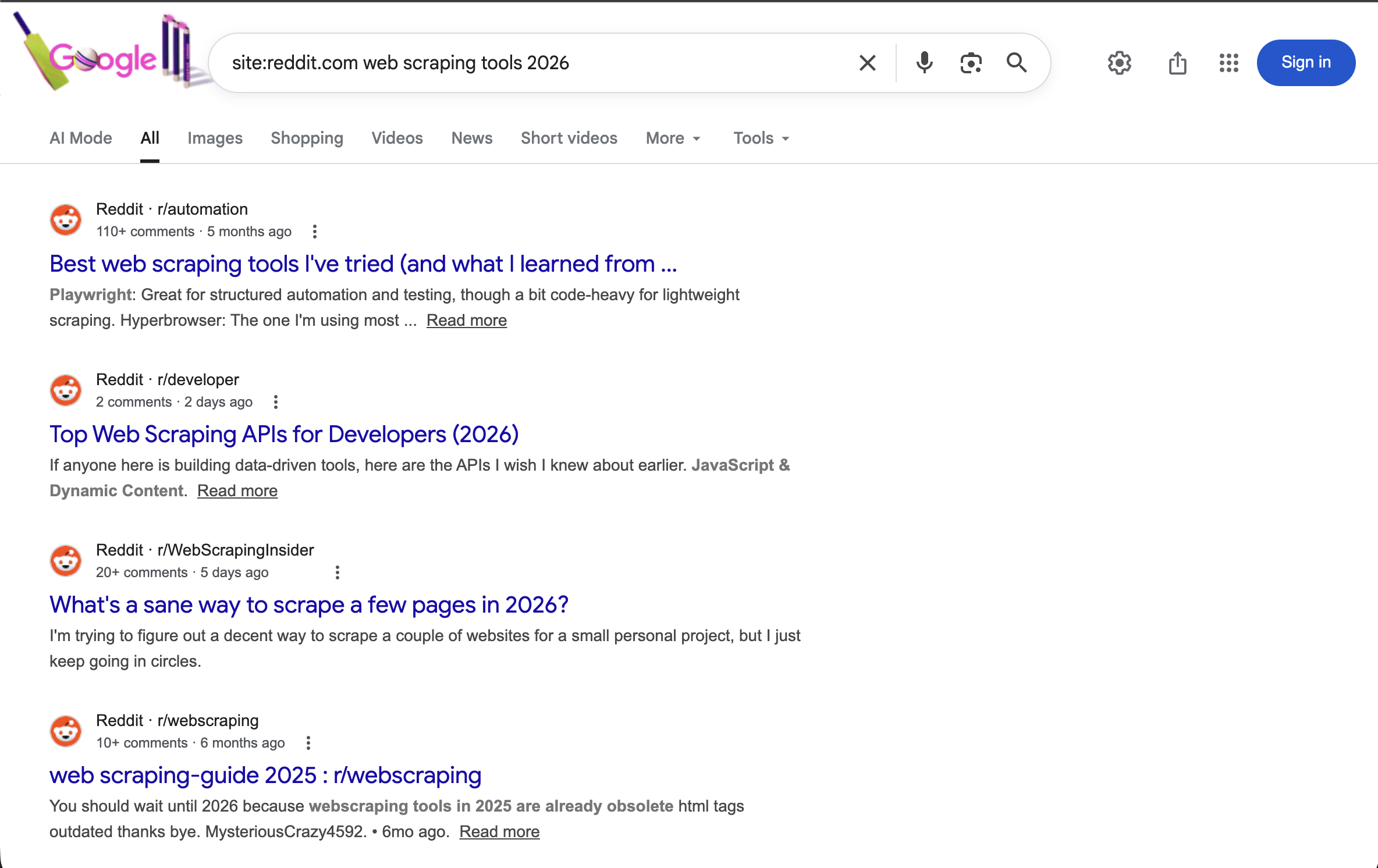
El operador site:reddit.com restringe todos los resultados a Reddit. En combinación con un término de año, muestra debates recientes de la comunidad sobre herramientas de Scraping web.
Los operadores se pueden combinar:
site:github.com filetype:pdf machine learningdevuelve solo archivos PDF alojados en GitHub que coinciden con «machine learning».
as_*: parámetros de búsqueda avanzada
El formulario de búsqueda avanzada de Google genera parámetros con el prefijo as_ (as_q, as_epq, as_sitesearch, as_filetype, etc.) que se corresponden con los operadores anteriores. La mayoría de los ingenieros utilizan los operadores directamente en q. Estos son útiles principalmente si estás creando una interfaz de usuario para un formulario de búsqueda y quieres asignar campos del formulario a parámetros URL sin concatenar cadenas de operadores.
Cambios de 2025-2026 que debes conocer
Google realizó tres cambios en 2025-2026 que rompieron las configuraciones de scraping existentes: renderización obligatoria de JavaScript (enero de 2025), eliminación del parámetro num (septiembre de 2025) y ampliación de las descripciones generales de IA a más de 200 países.
Google ahora requiere la representación de JavaScript
A partir de enero de 2025, Google no mostrará resultados de búsqueda sin renderización de JavaScript. Si ha estado ejecutando un Scraper de requests + BeautifulSoup, este cambio es la razón. Cada requests.get('https://google.com/search?q=...') ahora devuelve una respuesta vacía o degradada. Necesita una renderización completa del navegador o una API SERP que lo gestione por usted.
La renderización de JavaScript es automática con la API SERP, por lo que tus llamadas a la API siguen siendo las mismas.
El parámetro num ya no funciona
Entre el 12 y el 14 de septiembre de 2025, Google desactivó num de forma silenciosa. El impacto fue amplio: el 87,7 % de los sitios rastreados experimentaron caídas en las impresiones en Google Search Console, según un estudio que abarcó 319 propiedades.
Para obtener más de 10 resultados, la API SERP de Bright Data tiene un punto final de los 100 resultados principales que devuelve las posiciones 1-100 en una sola solicitud. Utiliza una superficie API diferente (/datasets/v3/trigger con el ID de Conjuntos de datos gd_mfz5x93lmsjjjylob) y le proporciona los parámetros start_page y end_page para controlar la profundidad de la paginación:
curl -X POST "https://api.brightdata.com/conjuntos_de_datos/v3/trigger?dataset_id=gd_mfz5x93lmsjjjylob&include_errors=true"
-H "Authorization: Bearer <API_TOKEN>"
-H "Content-Type: application/json"
-d '[{
"url": "https://www.google.com/",
"keyword": "Scraping web tools",
"language": "en",
"country": "US",
"start_page": 1,
"end_page": 10
}]'Rangos de páginas: 1..2 = 20 primeros, 1..5 = 50 primeros, 1..10 = 100 primeros (10 resultados por página). La respuesta incluye el texto de descripción general de IA (en el campo aio_text ) cuando Google muestra uno, y puede añadir «include_paginated_html»: true para capturar el HTML sin procesar junto con los datos analizados. También se admite el procesamiento por lotes. Pase una matriz de objetos de consulta para buscar varias palabras clave en una sola solicitud.
Resúmenes de IA en los resultados de búsqueda
Los resúmenes de IA de Google (los resúmenes generados por IA en la parte superior de los resultados de búsqueda) ahora están disponibles en más de 200 países y más de 40 idiomas. En enero de 2026, Google actualizó los resúmenes de IA a Gemini 3. Google también añadió transiciones de los resúmenes de IA a conversaciones en modo IA (udm=50). Para capturar este contenido se requiere renderización JavaScript y una lógica de extracción específica. Un resumen de IA en una SERP en vivo:
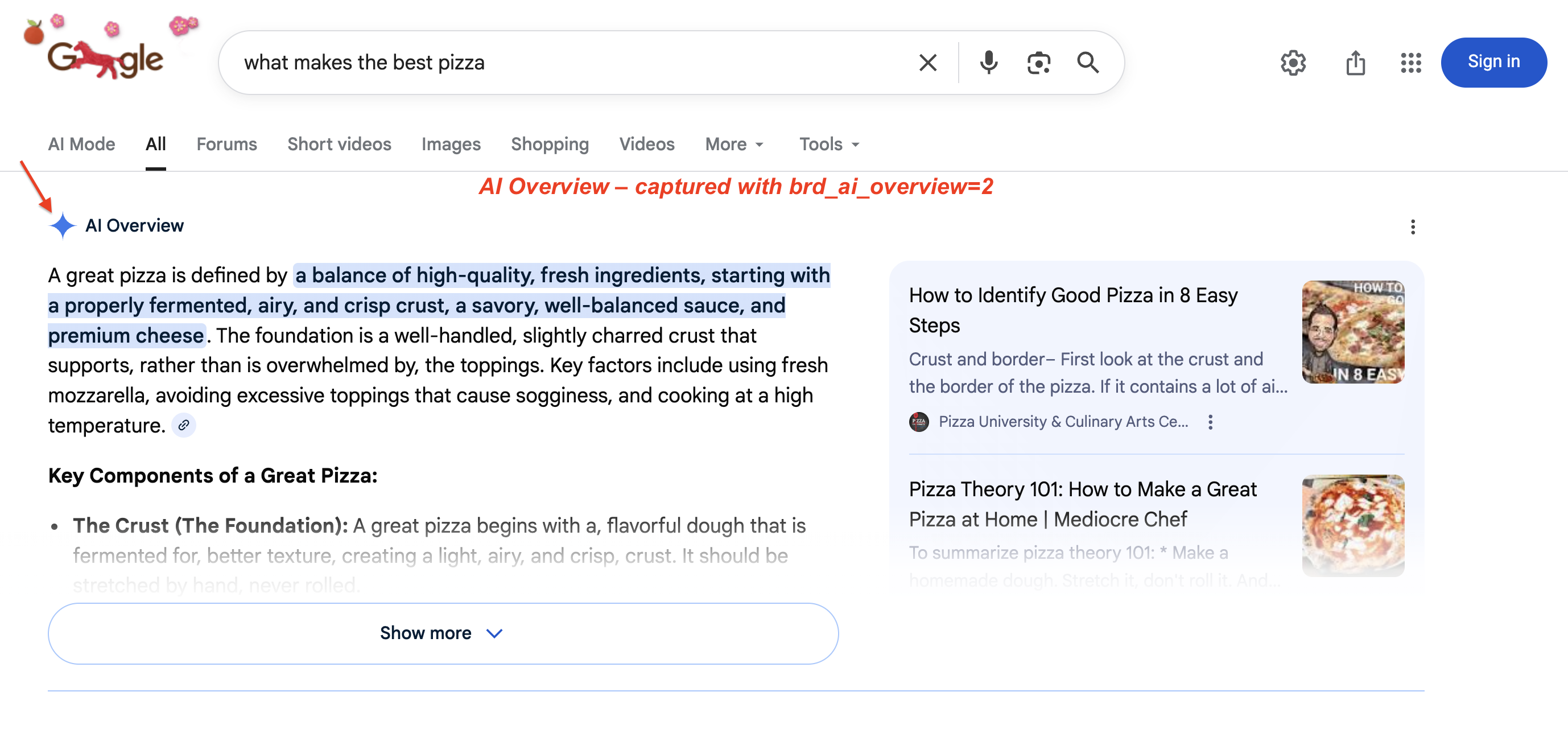
Un resumen de IA típico: Google genera un resumen de varios párrafos con frases clave resaltadas y tarjetas de origen a la derecha. Este bloque empuja los resultados orgánicos por debajo del pliegue. Utilice brd_ai_overview=2 para capturarlo a través de la API SERP.
El Scraper de resúmenes de IA funciona a través del parámetro brd_ai_overview. Establezca brd_ai_overview=2 para aumentar la probabilidad de recibir resúmenes generados por IA en sus resultados:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zona-<ZONA_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=what+makes+the+best+pizza&brd_ai_overview=2&brd_json=1"En nuestras pruebas (consultas en EE. UU.), al habilitar la captura de la descripción general de IA, el tiempo de respuesta aumentó entre 5 y 10 segundos. La latencia adicional se debe a la espera de que el contenido de IA cargado dinámicamente por Google termine de renderizarse en un navegador sin interfaz gráfica.
Cómo utilizar los parámetros de búsqueda de Google con una API SERP
Si estás realizando un rastreo con un volumen real, te encontrarás con CAPTCHAs, bloqueos de IP, renderización obligatoria de JavaScript y cambios en la infraestructura de Google que rompen silenciosamente los analizadores sintácticos. Hemos probado todos los métodos que se indican a continuación con la API en vivo para confirmar que funcionan tal y como se documenta.
Cuatro formas de utilizar estos parámetros con la API SERP de Bright Data, de la más sencilla a la más avanzada. Si solo estás explorando, empieza por el método 1 (API directa). Si estás integrando en un código base existente con encabezados personalizados, opta por el método 2 (Proxy). Para flujos de trabajo de agentes de IA, pasa al método 4 (LangChain). La guía de inicio te guía a través de la configuración.
| Método | Ideal para | Respuesta | Complejidad |
|---|---|---|---|
| API directa | Introducción, consultas únicas | Sincrónico | Bajo |
| Enrutamiento de Proxy | Flujos de trabajo HTTP existentes, encabezados de solicitud personalizados | Sincrónico | Bajo |
| Asíncrono por lotes | Gran volumen (más de 1000 consultas), barridos de paginación | En cola | Medio |
| LangChain | IA agents, RAG pipelines, multiple tool workflows | Sincrónico | Bajo |
Método 1: solicitud directa a la API
El método más sencillo. Realiza una solicitud POST con tu URL de búsqueda y obtén datos estructurados:
import requests
import json
from urllib.parse import urlencode
# Crea la URL de búsqueda de Google con la codificación adecuada (admite caracteres no latinos y caracteres especiales)
params = urlencode({"q": "API de Scraping web", "gl": "us", "hl": "en", "brd_json": "1"})
search_url = f"https://www.google.com/search?{params}"
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"zone": "<ZONE_NAME>",
"url": search_url,
"format": "raw"
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Validar la respuesta antes de procesarla
if "organic" not in data or len(data.get("organic", [])) == 0:
print("Advertencia: no se han devuelto resultados orgánicos (posible bloqueo suave o SERP vacío)")
print(json.dumps(data, indent=2))El nombre predeterminado de la zona suele ser «serp». La respuesta analizada se devuelve así:
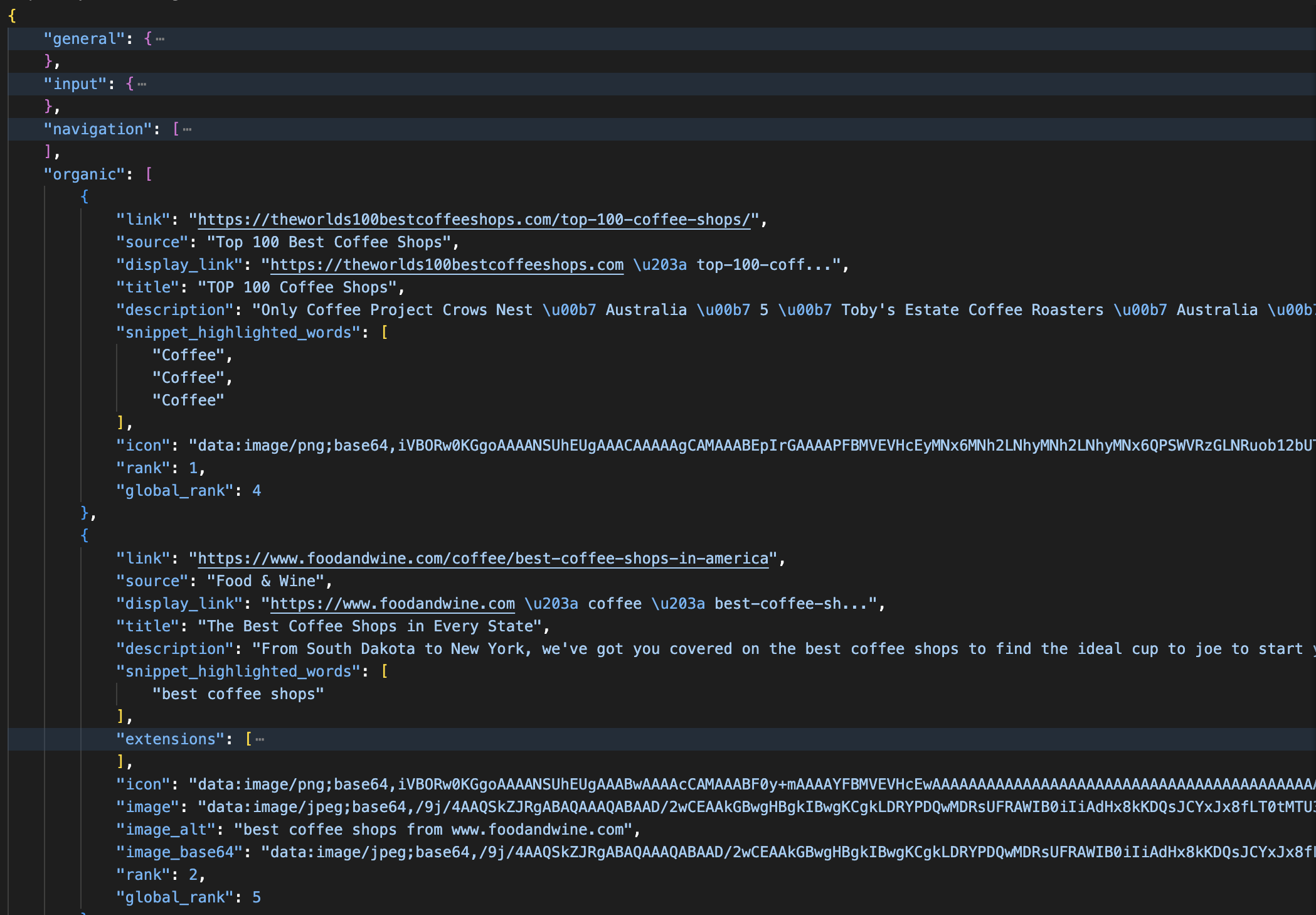
Una respuesta JSON analizada de la API SERP: cada resultado orgánico incluye los campos título, enlace, descripción, rango y rango global. La respuesta también separa los anuncios, los paneles de conocimiento y las descripciones generales de IA en secciones con nombre.
La API Direct también acepta un campo de cuerpo «data_format» (separado de «format»): «markdown» para canalizaciones LLM/RAG (Retrieval-Augmented Generation), «screenshot» para una captura PNG o «parsed_light» solo para los 10 resultados orgánicos principales. Utilice brd_json=html en la URL si desea conservar el HTML sin procesar dentro del JSON.
El campo «country»del cuerpo no es lo mismo que«gl»de la URL.«country»: «us»controla el nodo de salida del Proxy (la ubicación IP de la solicitud).gl=usindica a Google qué resultados de qué país mostrar. Para obtener resultados geolocalizados precisos, configure ambos.
Método 2: enrutamiento de Proxy
Enrute sus solicitudes a través de la infraestructura de Proxy de Bright Data. El Proxy se encarga de la representación de JavaScript por su parte, por lo que, aunque su código realice una solicitud HTTP estándar, obtendrá resultados completamente representados. Esto funciona con cualquier cliente HTTP y le permite establecer encabezados personalizados, cookies y opciones a nivel de solicitud que la API directa no expone. Con el enfoque del Proxy, usted controla el formato de salida a través de los parámetros de la URL: añada brd_json=1 para obtener JSON analizado en lugar de HTML sin procesar:
import requests
# Utiliza una sesión para el agrupamiento de conexiones (reutiliza las conexiones TCP entre solicitudes)
session = requests.Session()
session.proxies = {
"http": "http://brd-customer-<CUSTOMER_ID>-zona-<ZONA_NAME>:<PASSWORD>@brd.superproxy.io:33335",
"https": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335"
}
session.verify = False # para pruebas; cargue el certificado TLS/SSL de Bright Data en producción
url = "https://www.google.com/search?q=API SERP+comparison&gl=us&hl=en&tbs=qdr:m&brd_json=1"
response = session.get(url, timeout=30)
response.raise_for_status()
print(response.json())Las credenciales se encuentran en la pestaña «Detalles de acceso» de la Zona API SERP de su panel de control. Valide siempre la respuesta antes de procesarla. Un bloqueo suave de Google puede devolver un JSON válido con conjuntos de resultados vacíos o reducidos. Si general.results_cnt muestra millones de resultados estimados, pero la matriz orgánica está vacía o solo tiene 1-2 entradas, eso suele indicar un bloqueo suave en lugar de un SERP realmente vacío.
El indicador
verify=False(o-ken curl) omite la verificación TLS/SSL, lo cual está bien para las pruebas. Para la producción, carga el certificado SSL de Bright Data en su lugar.
Método 3: procesamiento por lotes asíncrono
Para operaciones de gran volumen (más de 1000 consultas), utilice el modo asíncrono. El modo asíncrono tiene sentido cuando se paginan cientos de combinaciones de palabras clave + ubicación utilizando los parámetros start, gl y hl (por ejemplo, el seguimiento de 500 palabras clave en 10 países). Solo se le cobrará cuando envíe la solicitud; la recopilación de la respuesta es gratuita. Los tiempos de respuesta varían en función del volumen y la carga máxima.
En primer lugar, active la opción Solicitudes asíncronas en la configuración avanzada de su zona. A continuación, utilice el punto final /unblocker/req:
import requests
import json
import time
url = "https://api.brightdata.com/unblocker/req"
params = {"customer": "<CUSTOMER_ID>", "zone": "<ZONE_NAME>"}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"url": "https://www.google.com/search?q=Scraping web tools&gl=us&hl=en&brd_json=1",
"country": "us"
}
response = requests.post(url, params=params, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_id = response.headers.get("x-response-id")
print(f"En cola. ID de respuesta: {response_id}")
# Sondeo de resultados (para producción, configure una URL de webhook en la configuración de su zona)
# Ventana total de sondeo: 30 intentos × 10 s = 300 s. Aumente range() para lotes grandes.
for attempt in range(30):
time.sleep(10) # espere antes de comprobar: los resultados nunca están listos inmediatamente
resultado = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"customer": "<CUSTOMER_ID>", "zona": "<ZONA_NAME>", "response_id": response_id},
headers={"Authorization": "Bearer <API_TOKEN>"},
timeout=30
)
if result.status_code == 200:
data = result.json()
if "organic" in data and len(data["organic"]) > 0:
print(json.dumps(data, indent=2))
else:
print("Advertencia: se ha devuelto una respuesta, pero no contiene resultados orgánicos")
break
elif result.status_code == 202:
continue # los resultados aún no están listos
else:
print(f"Se ha agotado el tiempo de espera tras 300 segundos esperando response_id={response_id}")En lugar de realizar sondeos, puede configurar una URL de webhook (ya sea como valor predeterminado en la configuración de zona o por solicitud utilizando el parámetro webhook_url ). Bright Data envía una notificación a su punto final cuando los resultados están listos (con el response_id y el estado), por lo que no es necesario sondear manualmente el punto final /get_result. Las respuestas se almacenan durante un máximo de 48 horas.
Incluso con una API gestionada, respete los límites de velocidad de su zona. La configuración predeterminada gestiona un alto rendimiento, pero enviar miles de solicitudes de sincronización simultáneas sin control puede provocar respuestas HTTP 429. El modo asíncrono evita esto, ya que la API pone en cola y controla las solicitudes internamente.
Método 4: Integración de LangChain para flujos de trabajo de IA
Si está creando agentes de IA que necesitan datos de búsqueda en tiempo real, existe una integración oficial de LangChain (langchain-brightdata) para que pueda utilizar la búsqueda en tiempo real como herramienta en los flujos de trabajo de los agentes:
pip install langchain-brightdatafrom langchain_brightdata import BrightDataSERP
serp_tool = BrightDataSERP(
bright_data_api_key="<API_TOKEN>",
zone="<ZONE_NAME>", # debe coincidir con el nombre de la zona en su panel de control de Bright Data
search_engine="google",
country="us",
language="en",
results_count=10,
parse_results=True)
# Anular los valores predeterminados del constructor para esta solicitud específica:
results = serp_tool.invoke({
"query": "best web scraping tools 2026",
"country": "de",
"language": "de",
"search_type": "shop",
"device_type": "mobile",
})Algunas cosas a tener en cuenta en esta integración:
results_countse asigna internamente anumde Google. Dado quenumya no funciona (véase la sección num), los valores superiores a 10 no tienen ningún efecto.countryylanguagese asignan aglyhl(resultados de qué país y en qué idioma). A diferencia de la API directa, donde«country»controla el nodo de salida del Proxy, LangChain gestiona el enrutamiento del Proxy automáticamente.Zonase establece de forma predeterminada en«serp». Si el nombre de su zona es diferente (por ejemplo,«serp_api1»), configúrelo explícitamente o obtendrá un error de «zona no encontrada».
Más allá de LangChain, consulta las guías de integración para CrewAI, AWS Bedrock y Google Vertex AI. Para la recopilación de datos que no sean de búsqueda, consulta las herramientas de acceso web de IA de Bright Data.
Para ver la lista completa de parámetros: Documentación de la API SERP
¿Por qué utilizar una API SERP gestionada?
La API SERP se encarga de la representación de JavaScript, la rotación de proxies, la Resolución de CAPTCHA y la geolocalización:
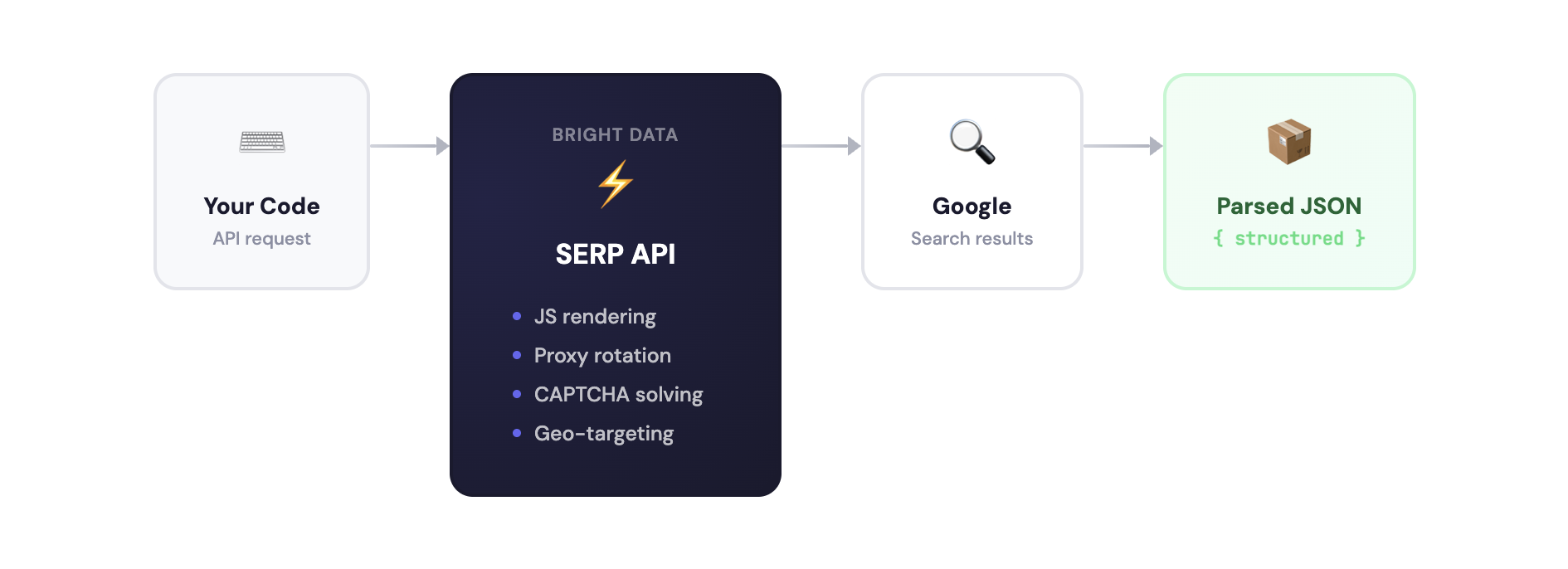
Podría crear esto usted mismo con Playwright, Selenium o la propia API del navegador de Bright Data. Pero mantener un Scraper de Google significa gestionar CAPTCHAs, bloqueos de IP, Proxies residenciales, renderización de JavaScript y Parseo de HTML que se rompe cada vez que Google actualiza su marcado. Consulte rastreo gestionado frente a rastreo basado en API para ver una comparación de ambos enfoques.
Con la API SERP, envías una URL de búsqueda y obtienes un JSON estructurado. Funciona en Google, Bing, DuckDuckGo, Yandex y otros. Consulta la página de precios para conocer las tarifas actuales.
El API SERP Playground le permite realizar búsquedas básicas sin código, y el espacio de trabajo de Postman tiene solicitudes preconstruidas. Aquí está el Playground:
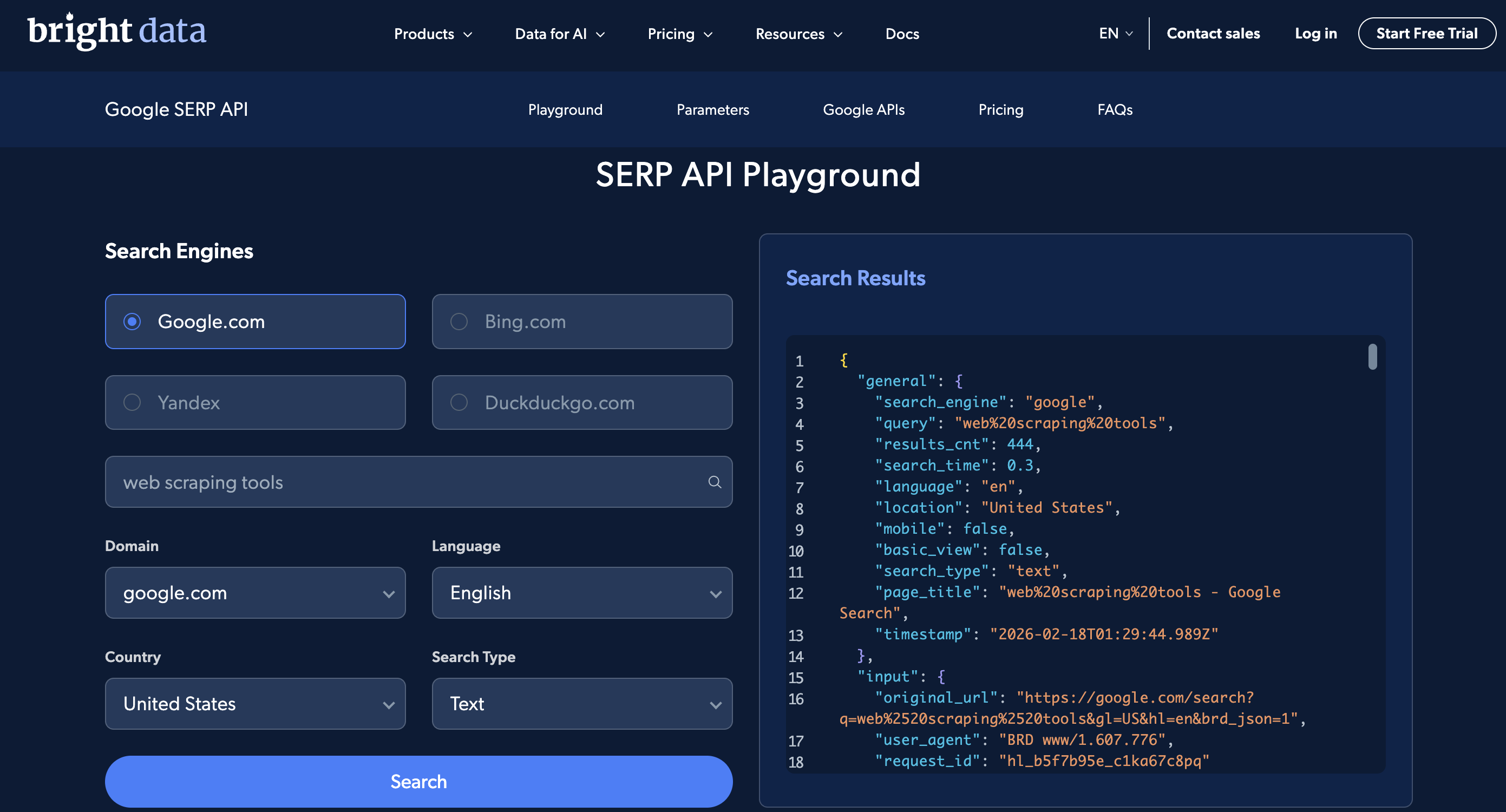
La interfaz de usuario del Playground: elige un motor de búsqueda, un país y un idioma, introduce una consulta y verás la respuesta JSON analizada a la derecha.
Cree una cuenta para ejecutar los ejemplos anteriores (las cuentas nuevas obtienen crédito gratuito para realizar pruebas).
Casos de uso en el mundo real
Estas combinaciones de parámetros aparecen repetidamente en los flujos de trabajo de scraping de producción.
Seguimiento del posicionamiento SEO
Realice un seguimiento de las clasificaciones de palabras clave en diferentes ubicaciones combinando q, gl, hl, pws=0, udm=14 y start:
# Compruebe la clasificación de «herramientas de Scraping web» en EE. UU., Reino Unido y Alemania.
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
«https://www.google.com/search?q=Scraping web tools&gl=us&hl=en&pws=0&udm=14&brd_json=1»
# A continuación, repita con gl=gb y gl=de.
# Utilice start=10, start=20 para comprobar las posiciones más allá de la página 1.Consulte cómo crear un rastreador de posicionamiento SEO con v0 y API SERP para obtener una guía completa.
Supervisión de anuncios de la competencia
La ubicación de los anuncios de sus competidores cambia a diario. Combine términos de marca con tbs=qdr:d para encontrar cambios recientes:
https://www.google.com/search?q=competitor+brand+name&gl=us&hl=en&tbs=qdr:d&brd_json=1La respuesta JSON separa top_ads, bottom_ads y popular_products (anuncios de ficha de producto) de los resultados orgánicos.
Comparación de precios e inteligencia de comercio electrónico
Para comparar precios entre mercados, cambia el valor gl manteniendo tbm=shop:
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=us&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=gb&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=de&brd_json=1Seguimiento de noticias y análisis de opiniones
https://www.google.com/search?q=openai&tbm=nws&tbs=qdr:h&filter=0&brd_json=1. Utilice tbm=nws para noticias, tbs=qdr:h para la última hora y filter=0 para evitar que Google agrupe artículos similares. Ejecute esto en una tarea cron para supervisar la cobertura cada hora.
Búsqueda basada en IA y aplicaciones RAG
Aplicaciones LLM basadas en datos de búsqueda en tiempo real utilizando la API SERP como capa de recuperación. La integración de LangChain (método 4 anterior), el servidor MCP y las llamadas directas a la API funcionan. Vea cómo crear un chatbot RAG con la API SERP para ver un ejemplo práctico.
SEO local y supervisión de múltiples ubicaciones
Las clasificaciones locales pueden variar significativamente entre ciudades. Utilice uule con gl y pws=0 para comparar:
# Compruebe las clasificaciones de «fontanero cerca de mí» en 3 ciudades.
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
«https://www.google.com/search?q=plumber+near+me&uule=Chicago,Illinois,United+States&gl=us&pws=0&brd_json=1»
# Repita con uule=Miami,Florida,United+States y uule=Seattle,Washington,United+StatesCompare los resultados de snack_pack (paquete local de 3) y orgánicos en todas las ubicaciones para identificar dónde deben mejorarse sus anuncios.
Investigación académica y de mercado
https://www.google.com/search?q=site:arxiv.org+large+language+models&lr=lang_en&tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025&brd_json=1Combine site: con filtros lr y tbs de rango de fechas para crear conjuntos de datos de investigación específicos. Reemplace arxiv.org por scholar.google.com, pubmed.ncbi.nlm.nih.gov o cualquier otro dominio.
Conclusión
Lo que realmente importa de todo lo anterior:
- Utilice
gl+hl+pws=0+udm=14para un seguimiento de clasificación coherente y no personalizado en todos los mercados. numha dejado de funcionar. Utilicestartpara la paginación o el punto final Top 100 de Bright Data para obtener resultados masivos.udm=14elimina las descripciones generales de IA y devuelve resultados orgánicos clásicos.udmamplíatbmcon modos adicionalestbsse encarga del filtrado por tiempo, la clasificación por fecha (sbd:1) y la búsqueda literal (li:1).- Los caracteres especiales necesitan codificación URL. El punto y coma en
ibp=htl%3Bjobses el error de codificación más común, junto con las consultas no latinas.
Google sigue cambiando estos parámetros. Eliminaron num sin previo aviso y podrían hacer lo mismo con start o dejar de usar tbm en favor de udm. Si estás recopilando datos en un volumen significativo, la API SERP de Bright Data se encarga de la representación, la rotación y el Parseo. Pruébala con los ejemplos anteriores.
Próximos pasos
Lecturas recomendadas, según su caso de uso:
Si quieres empezar a extraer datos de Google ahora mismo:
- Cómo extraer resultados de búsqueda de Google con Python: tutorial completo de Python con código funcional
- Cómo extraer datos de Google AI Overview: extrae resúmenes generados por IA
- Cómo extraer datos del modo IA de Google: extraiga datos de la búsqueda conversacional con IA de Google
Si está creando aplicaciones de IA:
- Cree un chatbot RAG con la API SERP: base las respuestas LLM en datos de búsqueda en tiempo real
- Cree un rastreador de posicionamiento SEO con v0 y API SERP: guía paso a paso
- Agente GEO y SEO IA: optimice el contenido para motores de búsqueda basados en IA
- CrewAI con API SERP: flujos de trabajo de IA con múltiples agentes
Si está evaluando proveedores de API SERP:
- Las mejores API SERP y búsqueda web de 2026: comparación entre los principales proveedores
- Rastreo gestionado frente a rastreo basado en API: comparación de servicios gestionados y enfoques basados en API
Otras fuentes de datos de Google:
- Cómo extraer datos de Google Trends
- Los mejores proveedores de datos hoteleros: comparación de servicios de recopilación de datos hoteleros
- Los mejores proveedores de datos de vuelos: comparación de servicios de recopilación de datos de vuelos
Referencias externas:
- Refinar las búsquedas en Google: guía oficial de Google para refinar las consultas de búsqueda
Referencias:
- API de búsqueda de Google de Bright Data (GitHub)
- API SERP de Bright Data (GitHub)
- Documentación de la API SERP de Bright Data
Preguntas frecuentes
¿Qué son los parámetros de búsqueda de Google?
Los parámetros de búsqueda de Google son pares clave-valor añadidos a la URL https://www.google.com/search? que controlan cómo se generan y muestran los resultados de búsqueda. Por ejemplo, q=pizza establece la consulta de búsqueda, gl=us se dirige a Estados Unidos y hl=en establece el idioma de la interfaz en inglés. Están separados por & y siguen al ? en la URL.
¿Cuál es la diferencia entre gl y hl en la búsqueda de Google?
El parámetro gl controla la geolocalización (el país desde el que parece originarse la búsqueda), lo que afecta a los resultados que se muestran. El parámetro hl controla el idioma del host (el idioma de la interfaz de Google). Por ejemplo, gl=de&hl=en ofrece resultados relevantes para Alemania, pero con la interfaz mostrada en inglés.
¿El parámetro num de Google está obsoleto?
No solo está en desuso. No funciona en absoluto. Google lo desactivó silenciosamente entre el 12 y el 14 de septiembre de 2025. Pasar num=100 no hace nada, y Google devuelve 10 resultados sin importar qué. Utilice start para la paginación o el punto final Top 100 de la API Web Scraper de Bright Data para obtener las posiciones 1-100 en una sola solicitud.
¿Qué es el parámetro udm de Google?
Es probable queudm signifique «modo de visualización del usuario» (según la ingeniería inversa de la comunidad; Google no ha confirmado el acrónimo). Lo más habitual es utilizar udm=14, que elimina las descripciones generales de IA y devuelve resultados orgánicos clásicos. Otros valores son udm=2 (imágenes), udm=39 (vídeos cortos) y udm=50 (modo IA). udm amplía tbm con modos adicionales, y ambos siguen funcionando. Todos los valores se enumeran en la sección udm.
¿Cuál es la diferencia entre tbm y udm?
tbm es el parámetro más antiguo, udm es la extensión más reciente. Se superponen en imágenes, noticias y compras (tbm=isch ≈ udm=2), pero udm también incluye características que tbm no admite: modo IA (udm=50), foros (udm=18), vídeos cortos (udm=39). Ambos funcionan actualmente. Cree un nuevo código basado en udm y mantenga tbm como alternativa.
¿Cómo puedo paginar los resultados de Google ahora que num ya no existe?
Utiliza el parámetro start. start=0 (u omitido) te da los resultados 1-10, start=10 te da los resultados 11-20, y así sucesivamente. Cada página devuelve 10 resultados. Para las posiciones 1-100 en una sola solicitud, utiliza el punto final Top 100 de Bright Data con los parámetros start_page y end_page.
¿Cómo puedo filtrar los resultados de Google por fecha?
Utilice el parámetro tbs. tbs=qdr:h = última hora, tbs=qdr:d = último día, tbs=qdr:w = última semana, tbs=qdr:m = último mes, tbs=qdr:y = último año. Para un intervalo de fechas personalizado: tbs=cdr:1,cd_min:MM/DD/AAAA,cd_max:MM/DD/AAAA. Añada tbs=sbd:1 para ordenar por fecha en lugar de por relevancia.
¿Cómo puedo extraer resultados de búsqueda de Google sin que me bloqueen?
Mantener un Scraper de Google a gran escala requiere actualizar los analizadores HTML cada vez que Google cambia su marcado, la resolución de CAPTCHA, la rotación de IPs y el renderizado de JavaScript para cada solicitud desde enero de 2025. Una API SERP gestionada se encarga de esta infraestructura. Usted envía una URL, obtiene un JSON estructurado y no tiene que mantener el analizador.





