
En este artículo aprenderás:
- Cómo crear un sistema RAG listo para la producción utilizando Google ADK y Vertex AI RAG Engine
- Cómo implementar la búsqueda híbrida con recuperación semántica y por palabras clave
- Cómo evitar alucinaciones mediante una base y citas adecuadas
- Cómo procesar contenido multimodal, incluyendo texto, imágenes y tablas
- Cómo mejorar su RAG con datos web en tiempo real utilizando la integración de Bright Data (opcional)
¡Empecemos!
El reto de la gestión moderna del conocimiento
La documentación técnica se almacena en wikis, las especificaciones de los productos se encuentran en archivos PDF, los datos de los clientes están en bases de datos y el conocimiento institucional reside en correos electrónicos. Los empleados pasan horas buscando información y, a menudo, encuentran respuestas obsoletas o incompletas. Los grandes modelos de lenguaje entrenados con datos generales no pueden acceder a su conocimiento propietario. A menudo cometen errores cuando se les pregunta sobre información específica de la empresa.
Los agentes RAG resuelven este problema recuperando el contexto relevante de su base de conocimientos antes de generar respuestas. Esto fundamenta la IA en información factual, reduce las alucinaciones y proporciona citas transparentes para su verificación.
Lo que estamos construyendo: sistema inteligente de agentes RAG
Crearemos un agente RAG listo para su producción que toma documentos de diversas fuentes, los procesa en fragmentos buscables, los convierte en representaciones vectoriales, recupera el contexto relevante mediante una búsqueda híbrida y genera respuestas correctas con citas adecuadas, evitando imprecisiones.
El sistema gestionará:
- La recepción de documentos desde Cloud Storage, Drive y archivos locales
- Fragmentación inteligente con superposición y conservación de metadatos
- Recuperación híbrida que combina similitud semántica y coincidencia de palabras clave
- Contenido multimodal que incluye imágenes y tablas
- Generación de citas para verificar las respuestas
- Detección y prevención de errores
Requisitos previos
Configure su entorno de desarrollo con:
- Python 3.10 o superior: necesario para la compatibilidad con Google ADK.
- Proyecto de Google Cloud: cree un proyecto en Google Cloud Console con la facturación habilitada.
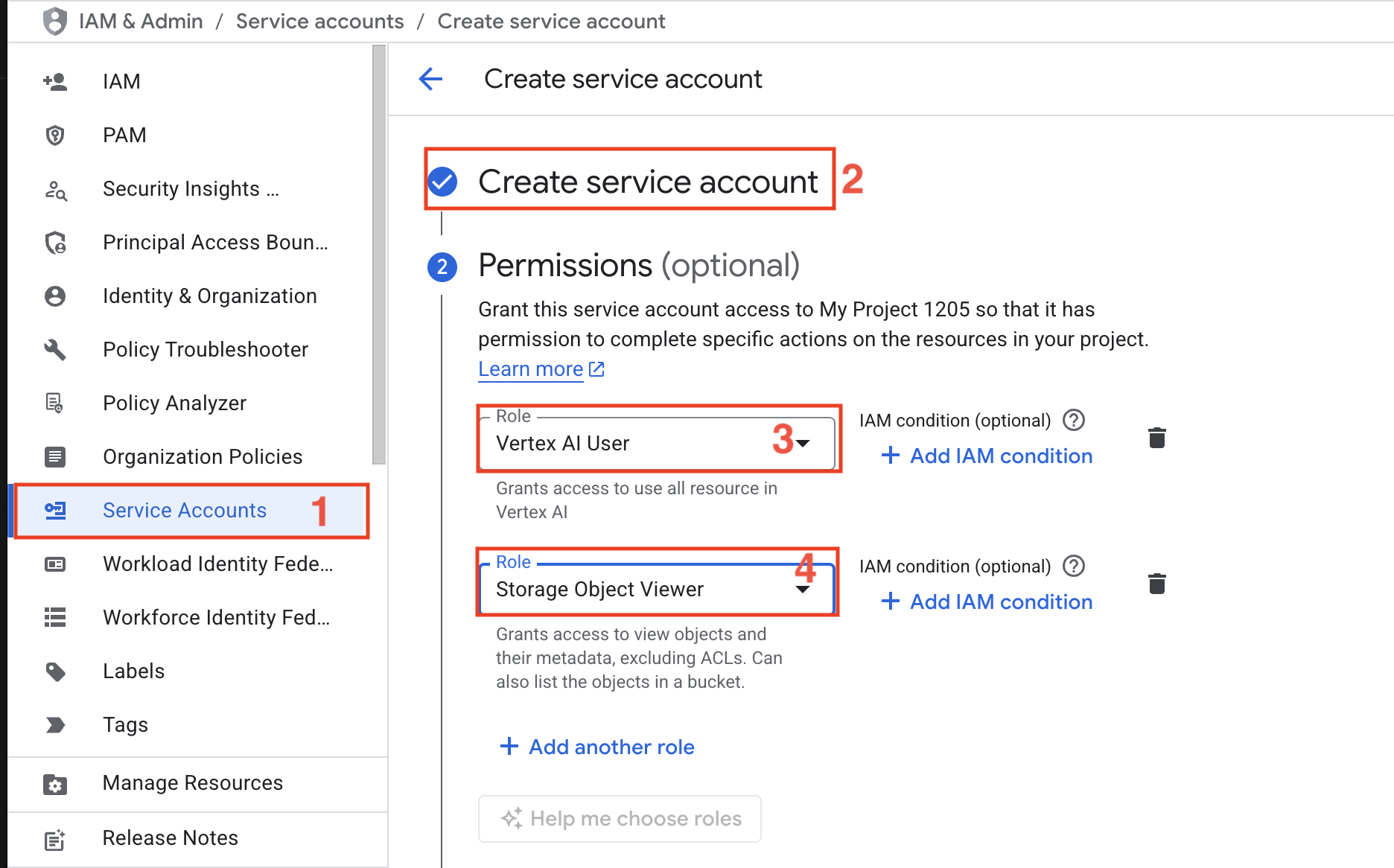
- Cuenta de servicio: cree una cuenta de servicio con las funciones de usuario de IA y visor de objetos de almacenamiento.
- Google ADK: kit de desarrollo de agentes para crear agentes de IA; consulte la documentación.
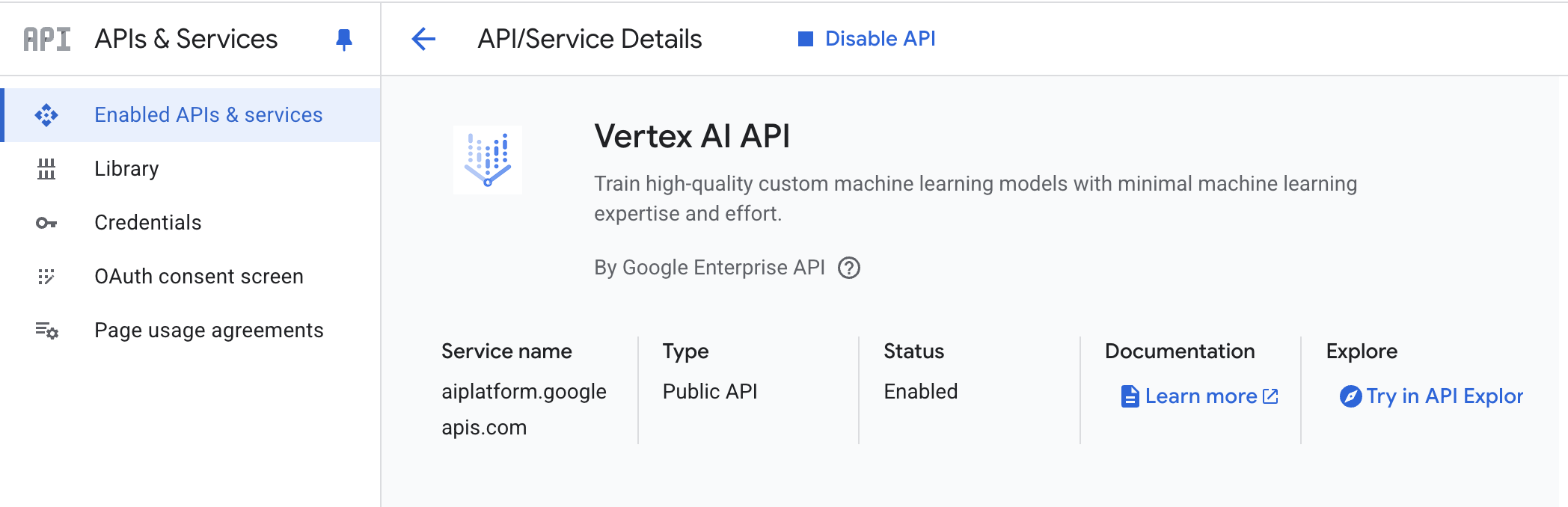
- API de IA de Vertex AI: habilite la API de IA de Vertex AI en su proyecto de Google Cloud.
- Entorno virtual Python: mantiene las dependencias aisladas; consulte la documentación
de venv.
Configuración del entorno
Cree el directorio de su proyecto e instale las dependencias:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install google-genai google-cloud-aiplatform google-cloud-storage langchain-google-vertexai pypdf python-dotenv pandas pillowCrea un nuevo archivo llamado rag_agent.py y añade las siguientes importaciones:
import os
import json
import PyPDF2
import fitz
import time
import vertexai
from google import genai
from vertexai.preview import rag
from pathlib import Path
from vertexai.preview.generative_models import GenerativeModel, Tool
from google.cloud import storage
from typing import List, Dict, Any, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.api_core.exceptions import ResourceExhausted
from google.genai import types
load_dotenv()Cree un archivo .env con sus credenciales:
GOOGLE_CLOUD_PROJECT="tu-id-de-proyecto"
GOOGLE_CLOUD_LOCATION="us-central1"
GOOGLE_APPLICATION_CREDENTIALS="ruta/a/clave-de-cuenta-de-servicio.json"
GENAI_API_KEY="tu-clave-API-genai"
GCS_BUCKET_NAME="tu-nombre-de-depósito"Necesitas:
- ID del proyecto: su identificador de proyecto de Google Cloud desde la consola
- Ubicación: región para los recursos de IA (se recomienda us-east1)
- Clave de cuenta de servicio: archivo de clave JSON descargado de IAM y Admin
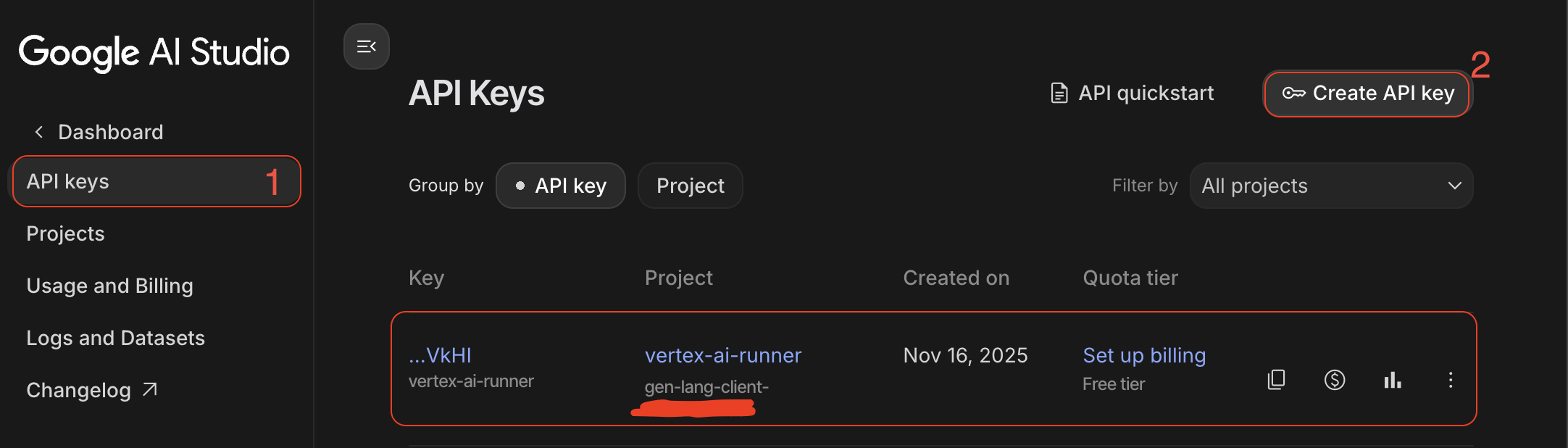
- Clave API IA: Crearla desde Google AI Studio
- Depósito GCS: depósito de Cloud Storage para el almacenamiento de documentos
Creación del sistema de agente RAG
Paso 1: Configuración de Google ADK
Configure el cliente Google ADK e inicialice Vertex AI con la autenticación adecuada. El cliente gestiona todas las interacciones con los servicios de IA generativa de Google.
def initialize_adk():
"""Inicializar Vertex IA con la autenticación adecuada."""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
vertexai.init(
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
print(f"✓ Vertex IA inicializado")
# Inicializar el sistema
initialize_adk()La inicialización establece conexiones tanto con el cliente IA para las operaciones del agente como con Vertex AI para las capacidades RAG. Valida las credenciales y confirma la configuración del proyecto antes de continuar.
Paso 2: Configuración del motor RAG de Vertex IA
Cree un corpus RAG que sirva de base para su base de conocimientos. El corpus almacena documentos indexados, gestiona incrustaciones y maneja consultas de recuperación.
def create_rag_corpus(corpus_name: str, description: str) -> str:
"""Crear un nuevo corpus RAG para el almacenamiento y la recuperación de documentos."""
try:
corpus = rag.create_corpus(
display_name=corpus_name,
description=description,
embedding_model_config=rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
)
corpus_id = corpus.name.split('/')[-1]
print(f"✓ Corpus RAG creado: {corpus_name}")
print(f"✓ ID del corpus: {corpus_id}")
print(f"✓ Modelo de incrustación: text-embedding-004")
return corpus_id
except Exception as e:
print(f"Error al crear el corpus: {str(e)}")
raise
def configure_retrieval_parameters(corpus_id: str) -> Dict[str, Any]:
"""Configurar los parámetros de recuperación para un rendimiento de búsqueda óptimo."""
retrieval_config = {
"corpus_id": corpus_id,
"similarity_top_k": 10,
"vector_distance_threshold": 0.5,
"filter": {},
"ranking_config": {
"rank_service": "default",
"alpha": 0.5
}
}
print(f"✓ Parámetros de recuperación configurados")
print(f" - Resultados principales K: {retrieval_config['similarity_top_k']}")
print(f" - Umbral de distancia: {retrieval_config['vector_distance_threshold']}")
print(f" - Alfa de búsqueda híbrida: {retrieval_config['ranking_config']['alpha']}")
return retrieval_configLa creación del corpus utiliza el modelo text-embedding-004 de Google para obtener incrustaciones semánticas de alta calidad. La configuración de recuperación equilibra la similitud semántica y la coincidencia de palabras clave a través del parámetro alfa, donde 0,5 proporciona una ponderación igual.
Paso 3: Canalización de ingestión de documentos
Cree un canal de ingesta de documentos robusto que maneje múltiples formatos de archivo, extraiga texto limpio y conserve metadatos importantes para mejorar la recuperación.
def extract_text_from_pdf(file_path: str) -> Dict[str, Any]:
"""Extrae texto y metadatos de documentos PDF."""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
metadata = {
'source': file_path,
'num_pages': len(pdf_reader.pages),
'title': pdf_reader.metadata.get('/Title', ''),
'author': pdf_reader.metadata.get('/Author', ''),
'created_date': str(datetime.now())
}
text_content = []
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
text_content.append({
'page': page_num + 1,
'text': page_text,
'char_count': len(page_text)
})
return {
'metadata': metadata,
'content': text_content,
'full_text': ' '.join([p['text'] for p in text_content])
}
def preprocess_document(text: str) -> str:
"""Limpiar y normalizar el texto del documento para una indexación óptima."""
text = ' '.join(text.split())
text = text.replace('x00', '')
text = text.replace('rn', 'n')
líneas = texto.split('n')
líneas_limpias = [
línea para línea en líneas
si len(línea.strip()) > 3
y no línea.strip().isdigit()
]
return 'n'.join(líneas_limpias)La estrategia de fragmentación utiliza los límites de las frases para evitar interrumpir el hilo del pensamiento, implementa la superposición para preservar el contexto entre fragmentos y mantiene metadatos sobre las posiciones de los fragmentos para una cita precisa. El tamaño de los fragmentos de 1000 caracteres equilibra la precisión de la recuperación con la integridad del contexto.
Paso 4: Incrustación e indexación
Cargue los documentos en el corpus RAG y genere incrustaciones vectoriales para la búsqueda semántica. El sistema se encarga automáticamente de la generación de incrustaciones y la optimización de índices.
def chunk_document(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[Dict[str, Any]]:
"""Divide el documento en fragmentos superpuestos para una recuperación óptima."""
chunks = []
start = 0
text_length = len(text)
chunk_id = 0
while start < text_length:
end = start + chunk_size
if end < text_length:
last_period = text.rfind('.', start, end)
if last_period != -1 and last_period > start:
end = last_period + 1
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append({
'chunk_id': chunk_id,
'text': chunk_text,
'start_char': start,
'end_char': end,
'char_count': len(chunk_text)
})
chunk_id += 1
start = end - overlap
print(f"✓ Se han creado {len(chunks)} fragmentos con {overlap} caracteres superpuestos")
return chunks
def upload_file_to_gcs(local_path: str, gcs_bucket: str) -> str:
"""Cargar documento en Google Cloud Storage para la ingestión de RAG."""
storage_client = storage.Client()
bucket = storage_client.bucket(gcs_bucket)
blob_name = f"rag-docs/{Path(local_path).name}"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_path)
gcs_uri = f"gs://{gcs_bucket}/{blob_name}"
print(f"✓ Subido a GCS: {gcs_uri}")
return gcs_uri
def import_documents_to_corpus(corpus_id: str, file_uris: List[str]) -> str:
"""Importar documentos al corpus RAG y generar incrustaciones."""
print(f"⚡ Iniciando la importación de {len(file_uris)} documentos...")
response = rag.import_files(
corpus_name=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}",
paths=file_uris,
chunk_size=1000,
chunk_overlap=200
)
try:
if hasattr(response, 'result'):
print("⏳ Esperando a que se complete la operación de importación (esto puede tardar un minuto)...")
response.result()
else:
print("✓ Solicitud de importación enviada.")
except Exception as e:
print(f"⚠️ Nota sobre la espera: {e}")
print(f"✓ Documentos importados e indexación activada.")
return getattr(response, 'name', 'unknown_operation')
def create_vector_index(corpus_id: str, index_config: Dict[str, Any]) -> str:
"""Crear índice vectorial optimizado para una búsqueda rápida por similitud."""
index_settings = {
'corpus_id': corpus_id,
'distance_measure': 'COSINE',
'algorithm': 'TREE_AH',
'leaf_node_embedding_count': 1000,
'leaf_nodes_to_search_percent': 10
}
print(f"✓ Índice vectorial creado con el algoritmo TREE_AH")
print(f"✓ Medida de distancia: similitud COSINE")
print(f"✓ Optimizado para una cobertura de búsqueda del {index_settings['leaf_nodes_to_search_percent']}%")
return corpus_idEl proceso de importación gestiona automáticamente el parseo, la fragmentación y la generación de incrustaciones de documentos. El algoritmo TREE_AH proporciona una búsqueda rápida y aproximada del vecino más cercano, al tiempo que mantiene un alto nivel de recuperación. La similitud coseno mide la distancia angular entre vectores de incrustación para la coincidencia semántica.
Paso 5: Desarrollo de agentes con ADK
Cree la arquitectura central del agente que gestiona el contexto, maneja las consultas de los usuarios y coordina la recuperación con la generación de respuestas.
class RAGAgent:
"""Agente RAG inteligente con gestión de contexto y fundamentación."""
def __init__(self, corpus_id: str, model_name: str = "gemini-2.5-flash"):
self.corpus_id = corpus_id
self.model_name = model_name
self.conversation_history = []
self.rag_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"],
similarity_top_k=5,
vector_distance_threshold=0.3
)
)
)
self.model = GenerativeModel(
model_name=model_name,
tools=[self.rag_tool]
)
print(f"✓ Agente RAG inicializado con {model_name}")
print(f"✓ Conectado al corpus: {corpus_id}")
def manage_context(self, query: str, max_history: int = 5) -> List[Dict[str, str]]:
"""Gestiona el contexto de la conversación con truncamiento del historial."""
historial_conversaciones.append({
'rol': 'usuario',
'contenido': consulta,
'marca de tiempo': datetime.now().isoformat()
})
si len(historial_conversaciones) > historial_máximo * 2:
self.conversation_history = self.conversation_history[-max_history * 2:]
formatted_history = []
for msg in self.conversation_history:
formatted_history.append({
'role': msg['role'],
'parts': [msg['content']]
})
return formatted_history
def build_grounded_prompt(self, query: str, retrieved_context: List[Dict[str, Any]]) -> str:
"""Construye una indicación con instrucciones explícitas de fundamentación."""
context_text = "nn".join([
f"[Fuente {i+1}]: {ctx['text']}"
para i, ctx en enumerate(retrieved_context)
])
prompt = f"""Eres un asistente de IA útil con acceso a una base de conocimientos.
Responde a la siguiente pregunta utilizando ÚNICAMENTE la información proporcionada en el contexto que se muestra a continuación.
INSTRUCCIONES IMPORTANTES:
1. Basa tu respuesta estrictamente en el contexto proporcionado.
2. Si el contexto no contiene suficiente información, indícalo explícitamente.
3. Cita fuentes específicas utilizando la notación [Fuente X].
4. No añadas información de tu conocimiento general.
5. Si no estás seguro, reconócelo.
CONTEXTO:
{context_text}
PREGUNTA:
{query}
RESPUESTA:"""
return promptEl agente mantiene el historial de conversaciones para interacciones de varios turnos, gestiona el tamaño de la ventana de contexto para evitar límites de tokens y crea indicaciones con instrucciones explícitas para reducir las alucinaciones. La integración de la herramienta RAG permite la recuperación automática durante la generación.
Paso 6: Procesamiento y recuperación de consultas
Implementar una búsqueda híbrida que combine la comprensión semántica con la coincidencia de palabras clave para obtener una precisión de recuperación óptima.
def hybrid_search(
self,
corpus_id: str,
query: str,
semantic_weight: float = 0.7,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""Realizar una búsqueda híbrida con reintento automático en los límites de cuota."""
rag_resource = rag.RagResource(
rag_corpus=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"
)
max_retries = 3
base_delay = 90
for attempt in range(max_retries):
try:
print(f"🔍 Buscando corpus (Intento {attempt + 1})...")
results = rag.retrieval_query(
rag_resources=[rag_resource],
text=query,
similarity_top_k=top_k,
vector_distance_threshold=0.5
)
# Si tiene éxito, procesa y devuelve los resultados.
fragmentos_recuperados = []
para i, contexto en enumerar(resultados.contextos.contextos):
retrieved_chunks.append({
'rank': i + 1,
'text': context.text,
'source': context.source_uri if hasattr(context, 'source_uri') else 'unknown',
'distance': context.distance if hasattr(context, 'distance') else 0.0
})
print(f"✓ Recuperados {len(retrieved_chunks)} fragmentos relevantes")
return retrieved_chunks
except ResourceExhausted:
wait_time = base_delay * (2 ** attempt)
print(f"⚠️ Cuota alcanzada (Límite: 5/min). Enfriamiento durante {wait_time}s...")
time.sleep(wait_time)
except Exception as e:
print(f"❌ Error de recuperación: {str(e)}")
raise
print("❌ Se ha alcanzado el máximo de reintentos. Error en la recuperación.")
return []
def rerank_results(
self,
results: List[Dict[str, Any]],
query: str,
model_name: str = "gemini-2.5-flash"
) -> List[Dict[str, Any]]:
"""Reordena los resultados recuperados en función de la relevancia de la consulta."""
if not results:
return []
rerank_prompt = f"""Califica la relevancia de cada pasaje para la consulta en una escala del 0 al 10.
Consulta: {query}
Pasajes:
{chr(10).join([f"{i+1}. {r['text'][:200]}..." for i, r in enumerate(results)])}
Devuelve solo una lista de puntuaciones separadas por comas (por ejemplo, 8,6,9,3,7)."""
model = GenerativeModel(model_name)
response = model.generate_content(rerank_prompt)
if response.text:
try:
scores = [float(s.strip()) for s in response.text.strip().split(',')]
for i, score in enumerate(scores[:len(results)]):
results[i]['rerank_score'] = score
results.sort(key=lambda x: x.get('rerank_score', 0), reverse=True)
print(f"✓ Resultados reordenados utilizando la puntuación LLM")
except Exception as e:
print(f"Advertencia: error al reordenar, utilizando el orden original: {str(e)}")
return resultsLa búsqueda híbrida recupera candidatos utilizando la similitud vectorial, y luego la reclasificación utiliza el LLM para puntuar la relevancia en función del contexto específico de la consulta. Este enfoque en dos etapas equilibra la eficiencia con la precisión.
Paso 7: Generación de respuestas y fundamentación
Genere respuestas con citas adecuadas e implemente la prevención de alucinaciones mediante una estricta verificación de la fundamentación.
def generate_grounded_response(
self,
agent: 'RAGAgent',
query: str,
retrieved_context: List[Dict[str, Any]],
temperature: float = 0.2
) -> Dict[str, Any]:
"""Generar respuesta con citas y prevención de alucinaciones."""
grounded_prompt = agent.build_grounded_prompt(query, retrieved_context)
chat = agent.model.start_chat()
response = chat.send_message(
grounded_prompt,
generation_config={
'temperature': temperature,
'top_p': 0.8,
'top_k': 40,
'max_output_tokens': 1024
}
)
return {
'answer': response.text,
'sources': retrieved_context,
'query': query,
'timestamp': datetime.now().isoformat()
}
def verify_grounding(
self,
response: str,
sources: List[Dict[str, Any]],
model_name: str = "gemini-2.5-flash"
) -> Dict[str, Any]:
"""Verificar que las afirmaciones de la respuesta se basan en el material fuente."""
verification_prompt = f"""Analiza si la siguiente respuesta está totalmente respaldada por las fuentes proporcionadas.
FUENTES:
{chr(10).join([f"Fuente {i+1}: {s['text']}" for i, s in enumerate(sources)])}
RESPUESTA:
{response}
Comprueba cada afirmación de la respuesta. Responde con JSON:
{{
"is_grounded": true/false,
"unsupported_claims": ["claim1", "claim2"],
"confidence_score": 0.0-1.0
}}"""
model = GenerativeModel(model_name)
verification_response = model.generate_content(verification_prompt)
try:
json_text = verification_response.text.strip()
if '```json' in json_text:
json_text = json_text.split('```json')[1].split('```')[0].strip()
verification_result = json.loads(json_text)
imprimir(f"✓ Verificación de conexión a tierra completada")
imprimir(f" - Conectado a tierra: {resultado_verificación.get('is_grounded', False)}")
imprimir(f" - Confianza: {resultado_verificación.get('confidence_score', 0.0):.2f}")
return verification_result
except Exception as e:
print(f"Advertencia: Verificación de fundamentación fallida: {str(e)}")
return {'is_grounded': True, 'confidence_score': 0.5}La verificación de fundamentación comprueba que cada afirmación de la respuesta pueda remontarse a los documentos originales. Una generación de baja temperatura (0,2) reduce los adornos creativos y mejora la precisión factual.
Paso 8: Implementación multimodal de RAG
Amplíe el sistema RAG para gestionar imágenes, tablas y otros contenidos no textuales para una recuperación de conocimientos completa.
def extract_images_from_pdf(self, pdf_path: str, output_dir: str) -> List[Dict[str, Any]]:
"""Extrae imágenes de documentos PDF para la indexación multimodal."""
doc = fitz.open(pdf_path)
images = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# Guardar imagen
image_filename = f"page{page_num + 1}_img{img_index + 1}.png"
image_path = os.path.join(output_dir, image_filename)
with open(image_path, "wb") as img_file:
img_file.write(image_bytes)
images.append({
'page': page_num + 1,
'image_path': image_path,
'format': base_image['ext'],
'size': len(image_bytes)
})
print(f"✓ Extracted {len(images)} images from PDF")
return images
def process_table_content(self, table_text: str) -> Dict[str, Any]:
"""Process and structure table data for enhanced retrieval."""
lines = table_text.strip().split('n')
if not lines:
return {}
headers = [h.strip() for h in lines[0].split('|') if h.strip()]
rows = []
for line in lines[1:]:
cells = [c.strip() for c in line.split('|') if c.strip()]
if len(cells) == len(headers):
row_dict = dict(zip(headers, cells))
rows.append(row_dict)
return {
'headers': headers,
'rows': rows,
'row_count': len(rows),
'column_count': len(headers)
}
def create_multimodal_embedding(
self,
text: str,
image_path: Optional[str] = None,
table_data: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""Crear una incrustación unificada para contenido multimodal."""
combined_text = text
if table_data and table_data.get('rows'):
table_desc = f"nTabla con {table_data['row_count']} filas y columnas: {', '.join(table_data['headers'])}n"
combined_text += table_desc
if image_path:
combined_text += f"n[Imagen: {Path(image_path).name}]"
return {
'text': combined_text,
'has_image': image_path is not None,
'has_table': table_data is not None,
'modalities': sum([bool(text), bool(image_path), bool(table_data)])
}El procesamiento multimodal extrae e indexa imágenes y tablas junto con el texto. El enfoque de incrustación unificada combina metadatos descriptivos de todas las modalidades en texto buscable. Esto permite que consultas como «muéstrame la tabla de precios del informe del tercer trimestre» recuperen tanto los datos de la tabla como el contexto circundante.
Paso 9: Integración del agente ADK de Google
Integre el kit de desarrollo de agentes (ADK) de Google para crear una interfaz de agente mejorada que se conecte a su backend Vertex AI RAG Engine. El ADK ofrece funciones de agente mejoradas, como llamadas a herramientas, conversaciones de varios turnos y respuestas estructuradas.
class ADKRAGAgent:
"""Envoltura del agente ADK de Google que utiliza el motor RAG de Vertex IA como backend."""
def __init__(self, corpus_id: str, project_id: str, location: str):
"""Inicializar el agente ADK con capacidades RAG."""
self.corpus_id = corpus_id
self.project_id = project_id
self.location = location
self.rag_agent = RAGAgent(corpus_id)
self.client = genai.Client(
vertexai=True,
project=project_id,
location=location
)
self.model_name = "gemini-2.0-flash-001"
print(f"✓ Agente Google ADK inicializado")
print(f" - Marco: Google ADK (genai.Client)")
print(f" - Backend: Vertex IA RAG Engine")
print(f" - Proyecto: {project_id}")
print(f" - Ubicación: {location}")
print(f" - Corpus RAG: {corpus_id}")
def create_rag_search_tool(self) -> types.Tool:
"""Crear herramienta de búsqueda RAG para agente ADK."""
def rag_search(query: str) -> str:
"""
Buscar en el corpus RAG y devolver respuestas fundamentadas.
Argumentos:
query: La pregunta del usuario que se va a buscar.
Devuelve:
Una respuesta fundamentada con citas de la base de conocimientos.
"""
try:
results = self.rag_agent.hybrid_search(
self.corpus_id,
query,
semantic_weight=0.7,
top_k=10)
if not results:
return "No se ha encontrado información relevante en la base de conocimientos."
reranked = self.rag_agent.rerank_results(results, query)
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
reranked[:5]
)
verification = self.rag_agent.verify_grounding(
response['answer'],
response['sources']
)
answer = response['answer']
if not verification.get('is_grounded', True):
answer += f"nn[Confidence: {verification.get('confidence_score', 0):.0%}]"
return answer
except Exception as e:
return f"Error searching knowledge base: {str(e)}"
rag_tool = types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="rag_search",
description="Busca en la base de conocimientos de la empresa utilizando RAG (Retrieval-Augmented Generation) para encontrar respuestas precisas y fundamentadas a preguntas sobre documentación técnica, especificaciones de productos y guías de usuario.",
parámetros={
"tipo": "objeto",
"propiedades": {
"consulta": {
"tipo": "cadena",
"descripción": "La pregunta o consulta de búsqueda del usuario"
}
},
"obligatorio": ["consulta"]
}
)
]
)
self.rag_search_function = rag_search
return rag_tool
def create_agent(self) -> Dict[str, Any]:
"""Crear la configuración del agente Google ADK con la herramienta RAG."""
rag_tool = self.create_rag_search_tool()
agent_instructions = """Eres un agente RAG (Retrieval-Augmented Generation) inteligente con acceso a una base de conocimientos empresarial.
Tus capacidades:
- Buscar documentación técnica, especificaciones de productos y guías de usuario.
- Proporcionar respuestas precisas y fundamentadas con citas.
- Manejar conversaciones de varios turnos con conciencia del contexto.
- Verificar la exactitud de la información antes de responder.
Directrices:
1. Utiliza siempre la herramienta rag_search para buscar información antes de responder.
2. Proporciona respuestas específicas y detalladas basadas en los documentos recuperados.
3. Incluye citas y fuentes relevantes.
4. Si no se encuentra la información, indícalo claramente.
5. Mantén el contexto de la conversación a lo largo de múltiples consultas.
Sé útil, preciso y profesional en todas las respuestas."""
agent_config = {
'model': self.model_name,
'instructions': agent_instructions,
'tools': [rag_tool],
'display_name': 'RAG Agent with Vertex IA (Google ADK + Vertex IA RAG Engine)'
}
print(f"✓ Configuración del agente Google ADK creada")
print(f" - Modelo: {self.model_name}")
print(f" - Herramientas: Búsqueda RAG (motor RAG de Vertex IA)")
return agent_config
def chat(self, agent_config: Dict[str, Any], query: str, session_id: str = "default") -> str:
"""Enviar un mensaje al agente ADK y obtener una respuesta utilizando Google GenAI."""
self.rag_agent.manage_context(query)
try:
response = self.client.models.generate_content(
model=agent_config['model'],
contents=query,
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
if response.candidates and len(response.candidates) > 0:
candidate = response.candidates[0]
if candidate.content and candidate.content.parts:
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_name = part.function_call.name
function_args = part.function_call.args
print(f" → Herramienta de llamada del agente ADK: {function_name}")
if function_name == "rag_search":
query_arg = function_args.get("query", query)
tool_result = self.rag_search_function(query_arg)
respuesta = self.client.models.generate_content(
modelo=agent_config['model'],
contenido=[
tipos.Contenido(rol="usuario", partes=[tipos.Parte(texto=consulta)]),
tipos.Contenido(rol="modelo", partes=[parte]),
tipos.Contenido(
rol="función",
parts=[types.Part(
function_response=types.FunctionResponse(
name=function_name,
response={"result": tool_result}
)
)]
)
],
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
elif hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
if response.candidates and response.candidates[0].content.parts:
for part in response.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'asistente',
'content': respuesta,
'timestamp': datetime.now().isoformat()
})
return respuesta
return "No se ha generado ninguna respuesta."
except Exception as e:
error_msg = f"Error en el chat del agente ADK: {str(e)}"
print(f"❌ {error_msg}")
return error_msgLa integración ADK añade el marco de agentes de Google a su agente RAG existente. La clase ADKRAGAgent configura un genai.Client para las operaciones del agente y utiliza su RAGAgent para la recuperación. El método create_rag_search_tool define una función que el agente puede llamar, lo que le permite buscar en su base de conocimientos utilizando el motor Vertex IA RAG.
El mecanismo de llamada de la herramienta permite al agente determinar automáticamente cuándo buscar en la base de conocimientos en función de las consultas de los usuarios. Cuando es necesaria una búsqueda, ejecuta el proceso de búsqueda híbrido, reordena los resultados, genera respuestas fundamentadas y comprueba la precisión antes de proporcionar las respuestas. El método chat gestiona todo el flujo de la conversación, incluida la ejecución de la herramienta y la gestión del contexto de múltiples turnos.
Paso 10: Potencia tu RAG con datos web en tiempo real de Bright Data
Aunque su sistema RAG destaca en la recuperación de información de su base de conocimientos interna, las aplicaciones de IA empresariales suelen requerir datos nuevos y en tiempo real de fuentes externas. Aquí es donde la plataforma de datos web de Bright Data se vuelve invaluable, ya que permite a su agente RAG acceder a información en vivo de toda la web, manteniendo su base de conocimientos actualizada y completa.
¿Por qué integrar Bright Data con su sistema RAG?
1. Mantenga su base de conocimientos actualizada
- Actualice automáticamente su corpus RAG con la información más reciente sobre productos, datos de precios, inteligencia sobre la competencia y tendencias del mercado.
- Elimine los datos obsoletos que dan lugar a respuestas de IA desactualizadas.
- Programe actualizaciones periódicas de datos para mantener la precisión.
2. Vaya más allá de los documentos internos
- Acceda a datos en tiempo real de más de 120 sitios web populares, incluyendo plataformas de comercio electrónico, sitios de noticias, redes sociales y fuentes específicas del sector.
- Amplíe su documentación técnica con documentación API en directo, debates de la comunidad y especificaciones actualizadas.
- Incorpore opiniones de clientes, comentarios y datos sobre opiniones para mejorar su base de conocimientos sobre productos
3. Habilite la mejora dinámica de consultas
- Cuando su agente RAG detecte una consulta que requiera información actualizada (precios, disponibilidad, noticias recientes), obtenga automáticamente datos recientes.
- Combine el conocimiento interno con datos web externos para obtener respuestas completas.
- Proporcione a los usuarios tanto el contexto histórico como la información actualizada.
4. Amplíe la recopilación de datos sin esfuerzo
- No es necesario gestionar Proxies, manejar CAPTCHAs ni lidiar con sistemas antibots.
- Bright Data se encarga de toda la infraestructura, el desbloqueo y la calidad de los datos.
- Céntrese en el desarrollo de la IA mientras Bright Data se encarga de la adquisición de datos
Implementación: añadir Bright Data a su canalización RAG
Ampliemos su sistema RAG con las capacidades de Bright Data. Añadiremos tres patrones de integración: integración de Conjuntos de datos para datos recopilados previamente, API de Scraping web para el rastreo en tiempo real y Scrapers de IA para obtener información enriquecida generada por IA.
Patrón 1: Integración de Conjuntos de datos para datos históricos
Utilice el mercado de conjuntos de datos de Bright Data para rellenar rápidamente su corpus RAG con datos estructurados de alta calidad.
import requests
from typing import List, Dict
import json
class BrightDataRAGEnhancer:
"""Mejora el sistema RAG con las capacidades de datos web de Bright Data."""
def __init__(self, api_key: str, rag_agent: RAGAgent):
self.api_key = api_key
self.rag_agent = rag_agent
self.base_url = "https://api.brightdata.com"
def fetch_dataset_data(
self,
dataset_id: str,
filters: Dict[str, Any] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""Obtener datos de Bright Data Dataset Marketplace."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/Conjuntos de datos/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
print(f"✓ Recuperados {len(response.json())} registros del conjunto de datos {dataset_id}")
return response.json()
def ingest_dataset_to_rag(
self,
corpus_id: str,
dataset_records: List[Dict[str, Any]],
text_fields: List[str]
) -> None:
"""Procesa los registros del conjunto de datos y los añade al corpus RAG."""
processed_chunks = []
for record in dataset_records:
# Combinar los campos de texto especificados en contenido buscable
combined_text = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if combined_text.strip():
# Añadir metadatos para una mejor recuperación
metadata = {
"source": "bright_data_dataset",
"record_id": record.get("id", "unknown"),
"ingestion_date": datetime.now().isoformat(),
"data_type": "external_web_data"
}
# Dividir el contenido en fragmentos
fragmentos = chunk_document(texto_combinado, tamaño_fragmento=1000, superposición=200)
para fragmento en fragmentos:
fragmento['metadata'] = metadata
fragmentos_procesados.append(fragmento)
print(f"✓ Procesados {len(fragmentos_procesados)} fragmentos del conjunto de datos")
# Crear archivo temporal para subir
temp_file = "temp_dataset_content.txt"
with open(temp_file, 'w') as f:
for chunk in processed_chunks:
f.write(chunk['text'] + "nn")
# Subir a GCS e importar al corpus
gcs_uri = upload_file_to_gcs(temp_file, os.getenv('GCS_BUCKET_NAME'))
import_documents_to_corpus(corpus_id, [gcs_uri])
os.remove(temp_file)
print(f"✓ Contenido del conjunto de datos añadido al corpus RAG")Ejemplo de caso de uso: Rellenar el RAG de comercio electrónico con datos de productos
# Crear primero un corpus RAG
corpus_id = create_rag_corpus(
corpus_name="bright_data_corpus",
description="Corpus para RAG mejorado con Bright Data")
# Inicializar el agente RAG con el corpus
rag_agent = RAGAgent(corpus_id=corpus_id)
# Inicializar el potenciador
enhancer = BrightDataRAGEnhancer(
api_key=os.getenv("BRIGHT_DATA_API_KEY"),
rag_agent=rag_agent)
print("✓ ¡BrightDataRAGEnhancer inicializado correctamente!")
# Obtener datos de productos de Amazon
amazon_data = enhancer.fetch_dataset_data(
dataset_id="gd_l7q7dkf244hwxr90h", # Conjunto de datos de productos de Amazon
filters={"category": "Electronics"},
limit=5000
)
# Incorporar al corpus RAG
enhancer.ingest_dataset_to_rag(
corpus_id=corpus_id,
dataset_records=amazon_data,
text_fields=["title", "description", "features", "reviews"]
)Patrón 2: Integración de la API del Scraper web en tiempo real
Para obtener información dinámica y actualizada, integra la API del Scraper web de Bright Data directamente en el canal de consultas de tu agente RAG.
def scrape_real_time_data(
self,
scraper_id: str,
inputs: List[Dict[str, Any]],
wait_for_completion: bool = True)
-> List[Dict[str, Any]]:
"""Ejecuta el Scraping web en tiempo real utilizando los Scrapers de Bright Data."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Activar el Scraper
trigger_url = f"{self.base_url}/dca/trigger"
params = {
"Scraper": Scraper_id,
"queue_next": 1
}
response = requests.post(
trigger_url,
headers=headers,
params=params,
json=inputs
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
print(f"✓ Scraper triggered. Snapshot ID: {snapshot_id}")
if not wait_for_completion:
return {"snapshot_id": snapshot_id, "status": "processing"}
# Sondeo de resultados
results_url = f"{self.base_url}/dca/conjuntos de datos"
params = {"id": snapshot_id}
max_retries = 30
for i in range(max_retries):
time.sleep(10) # Esperar 10 segundos entre sondeos
results_response = requests.get(results_url, headers=headers, params=params)
if results_response.status_code == 200:
data = results_response.json()
print(f"✓ Scraping completado. Se han recuperado {len(data)} registros")
return data
elif results_response.status_code == 202:
print(f"⏳ Todavía procesando... ({i+1}/{max_retries})")
continue
else:
print(f"❌ Error al recuperar los resultados: {results_response.status_code}")
break
return []
def create_dynamic_rag_tool(self) -> types.Tool:
"""Crear herramienta RAG con aumento de datos web en tiempo real."""
def augmented_rag_search(query: str, include_live_data: bool = False) -> str:
"""
Buscar en la base de conocimientos con enriquecimiento opcional de datos web en tiempo real.
Argumentos:
query: La pregunta del usuario.
include_live_data: Si se deben recuperar datos web recientes.
Devuelve:
Respuesta fundamentada que combina datos internos y externos.
"""
# Primero, busca en la base de conocimientos interna.
internal_results = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=5
)
combined_results = internal_results
# Si la consulta requiere información actualizada, obtener datos en tiempo real
if include_live_data or self._requires_fresh_data(query):
print("🌐 Obteniendo datos web en tiempo real...")
# Ejemplo: recopilar información sobre precios
if "price" in query.lower() or "cost" in query.lower():
live_data = self.scrape_real_time_data(
scraper_id="your_product_scraper_id",
inputs=[{"url": "https://example.com/products"}],
wait_for_completion=True
)
# Convertir datos en tiempo real en fragmentos buscables
for record in live_data[:3]: # 3 resultados principales
combined_results.append({
'rank': len(combined_results) + 1,
'text': f"{record.get('title', '')}: {record.get('price', '')} - {record.get('description', '')}",
'source': f"Datos web en tiempo real: {record.get('url', 'unknown')}",
'distance': 0.3 # Alta relevancia para datos recientes
})
# Generar respuesta con todo el contexto disponible
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
combined_results
)
return response['answer']
return types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="augmented_rag_search",
description="Buscar en la base de conocimientos interna y, opcionalmente, obtener datos web en tiempo real para obtener información actualizada",
parameters={
"type": "object",
"properties": {
"query": {"type": "string", "description": "Pregunta del usuario"},
"include_live_data": {"type": "boolean", "description": "Obtener datos web actualizados"}
},
"required": ["query"]
}
)
]
)
def _requires_fresh_data(self, query: str) -> bool:
"""Determina si la consulta requiere datos en tiempo real."""
fresh_data_keywords = [
"último", "actual", "hoy", "ahora", "reciente",
"precio", "coste", "disponible", "en stock"
]
return any(keyword in query.lower() for keyword in fresh_data_keywords)Patrón 3: Integración de Scrapers de IA para una inteligencia enriquecida
Aprovecha los Scrapers de IA de Bright Data (ChatGPT, Perplexity, Gemini) para mejorar tu RAG con información generada por IA y un contexto web completo.
def query_ai_scraper(
self,
scraper_type: str,
prompt: str,
country_code: str = "us"
) -> Dict[str, Any]:
"""Consulte los rastreadores de IA (ChatGPT, Perplexity, etc.) para obtener un contexto enriquecido."""
scraper_ids = {
"chatgpt": "chatgpt_scraper_id",
"perplexity": "perplexity_scraper_id",
"gemini": "gemini_scraper_id"
}
inputs = [{
"prompt": prompt,
"country": country_code
}]
results = self.scrape_real_time_data(
scraper_id=scraper_ids.get(scraper_type),
inputs=inputs,
wait_for_completion=True
)
if results:
return {
"answer": results[0].get("answer", ""),
"sources": results[0].get("sources", []),
"citations": results[0].get("citations", [])
}
return {}
def create_hybrid_intelligence_agent(self) -> Dict[str, Any]:
"""Crear un agente que combine RAG con inteligencia de Scraper de IA."""
def hybrid_search(query: str) -> str:
"""
Combinar RAG interno con inteligencia de Scraper de IA externo.
Esto proporciona:
1. Contexto de la base de conocimientos interna.
2. Información generada por IA en tiempo real a partir de la web.
3. Respuestas completas y bien documentadas.
"""
# Obtener conocimientos internos.
internal_answer = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=3
)
internal_context = "n".join([r['text'][:200] for r in internal_answer])
# Obtener enriquecimiento del Scraper de IA
print("🤖 Obteniendo inteligencia web mejorada por IA...")
ai_insight = self.query_ai_scraper(
scraper_type="perplexity", # Conocido por sus respuestas bien documentadas
prompt=query
)
# Sintetizar ambas fuentes
synthesis_prompt = f"""Sintetizar una respuesta completa utilizando tanto el conocimiento interno como los conocimientos externos de IA.
BASE DE CONOCIMIENTOS INTERNA:
{internal_context}
INFORMACIÓN EXTERNA DE IA:
{ai_insight.get('answer', 'No hay información externa disponible')}
FUENTES:
{json.dumps(ai_insight.get('citations', []), indent=2)}
PREGUNTA: {query}
Proporcione una respuesta completa que:
1. Priorice el conocimiento interno para la información específica de la empresa.
2. Utilice información externa para un contexto más amplio y desarrollos recientes.
3. Cite claramente todas las fuentes.
4. Indique cuándo la información proviene de fuentes externas frente a fuentes internas.
model = GenerativeModel("gemini-2.0-flash-001")
response = model.generate_content(synthesis_prompt)
return response.text
return {
'search_function': hybrid_search,
'description': 'Sistema híbrido RAG + IA Scraper Intelligence'
}Ejecución del sistema RAG Agent
Reúna todos los componentes en un flujo de trabajo completo que procese documentos, gestione consultas y genere respuestas fundamentadas. Además, descargue los documentos PDF que desee procesar y colóquelos en la carpeta docs/ para permitir que la IA cree un contexto sobre su producto.
def main():
"""Flujo de ejecución principal para el sistema de agente RAG."""
print("=" * 60)
print("Sistema de agente RAG - Inicialización")
print("=" * 60)
initialize_adk()
corpus_id = create_rag_corpus(
corpus_name="enterprise-knowledge-base-3",
description="Documentación empresarial multimodal y repositorio de conocimientos"
)
retrieval_config = configure_retrieval_parameters(corpus_id)
print(f"n✓ Uso de la configuración de recuperación con top_k={retrieval_config['similarity_top_k']}")
print("n" + "=" * 60)
print("Canalización de ingestión de documentos")
print("=" * 60)
document_paths = [
"docs/technical_manual.pdf",
"docs/product_specs.pdf",
"docs/user_guide.pdf"
]
gcs_uris = []
all_chunks = []
extracted_images = []
for doc_path in document_paths:
if os.path.exists(doc_path):
extracted = extract_text_from_pdf(doc_path)
print(f"n✓ Extracted {extracted['metadata']['num_pages']} pages from {Path(doc_path).name}")
cleaned_text = preprocess_document(extracted['full_text'])
print(f"✓ Texto preprocesado: {len(cleaned_text)} caracteres")
chunks = chunk_document(cleaned_text, chunk_size=1000, overlap=200)
all_chunks.extend(chunks)
print(f"✓ Documento dividido en {len(chunks)} segmentos")
gcs_uri = upload_file_to_gcs(doc_path, os.getenv('GCS_BUCKET_NAME'))
gcs_uris.append(gcs_uri)
print(f"n✓ Total de fragmentos creados: {len(all_chunks)}")
print(f"✓ Total de imágenes extraídas: {len(extracted_images)}")
if gcs_uris:
import_documents_to_corpus(corpus_id, gcs_uris)
index_config = {"distance_measure": "COSINE", "algorithm": "TREE_AH"}
create_vector_index(corpus_id, index_config)
time.sleep(180)
# ========================================================================
# Inicializar Google ADK Agent con Vertex AI RAG Engine
# ========================================================================
print("n" + "=" * 60)
print("Inicialización de Google ADK Agent")
print("=" * 60)
adk_agent = ADKRAGAgent(
corpus_id=corpus_id,
project_id=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
agent = adk_agent.create_agent()
for doc_path in document_paths:
if os.path.exists(doc_path):
try:
images = adk_agent.rag_agent.extract_images_from_pdf(doc_path, "extracted_images")
extracted_images.extend(images)
if images:
print(f"✓ Extracted {len(images)} images for multi-modal processing")
except Exception as e:
print(f"⚠️ Image extraction skipped: {str(e)}")
queries = [
"What are the system requirements for installation?",
"How do I configure the authentication settings?",
«¿Cuáles son los niveles de precios y sus características?»
]
print("n" + "=" * 60)
print("Agente Google ADK: procesamiento de consultas")
print("=" * 60)
print("Uso: Google ADK + motor RAG de Vertex IA»)
print("=" * 60)
session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
for idx, query in enumerate(queries):
print(f"n📝 Consulta {idx + 1}: {query}")
print("-" * 60)
try:
answer = adk_agent.chat(agent, query, session_id)
print(f"n💬 Respuesta del agente ADK:n{answer}n")
print(f"✓ Historial de conversación: {len(adk_agent.rag_agent.conversation_history)} mensajes")
except Exception as e:
print(f"❌ Error: {str(e)}")
import traceback
traceback.print_exc()
print("-" * 60)
if idx < len(queries) - 1:
time.sleep(90)
if extracted_images:
print("n" + "=" * 60)
print("Demostración de procesamiento multimodal")
print("=" * 60)
sample_table = """Característica | Básico | Pro | Empresa
Almacenamiento | 10 GB | 100 GB | Ilimitado
Usuarios | 1 | 10 | Ilimitado
Precio | 10 $ | 50 $ | Personalizado"""
table_data = adk_agent.rag_agent.process_table_content(sample_table)
print(f"n✓ Tabla procesada con {table_data.get('row_count', 0)} filas")
if all_chunks and extracted_images:
multimodal_embed = adk_agent.rag_agent.create_multimodal_embedding(
text=all_chunks[0]['text'][:500],
image_path=extracted_images[0]['image_path'] if extracted_images else None,
table_data=table_data
)
print(f"✓ Creado incrustación multimodal con {multimodal_embed['modalities']} modalidades")
print(f" - Tiene imagen: {multimodal_embed['has_image']}")
print(f" - Tiene tabla: {multimodal_embed['has_table']}")
print("n" + "=" * 60)
print(f"Sistema agente RAG de Google ADK - Completo")
print(f"✓ Arquitectura: Google ADK + Motor RAG de Vertex IA")
print(f"✓ Total de turnos de conversación: {len(adk_agent.rag_agent.conversation_history)}")
print("=" * 60)
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"n❌ Error: {str(e)}")
import traceback
traceback.print_exc()Ejecuta el sistema del agente RAG:
python3 rag_agent.pyVerá el proceso de procesamiento del agente en la consola a medida que:
- Inicializa el cliente Google ADK y la conexión Vertex IA.
- Crea el corpus RAG con la configuración del modelo de incrustación.
- Procesa los documentos extrayéndolos, limpiándolos y dividiéndolos en fragmentos.
- Carga los archivos en Cloud Storage y los importa al corpus.
- Genera incrustaciones vectoriales y crea el índice de búsqueda.
- Ejecuta consultas con expansión, recuperación y reclasificación.
- Produce respuestas fundamentadas con citas y verificaciones.
- Califica la calidad de las respuestas en función de su relevancia, exhaustividad, precisión y claridad.
La salida de la consola muestra el progreso detallado de cada paso.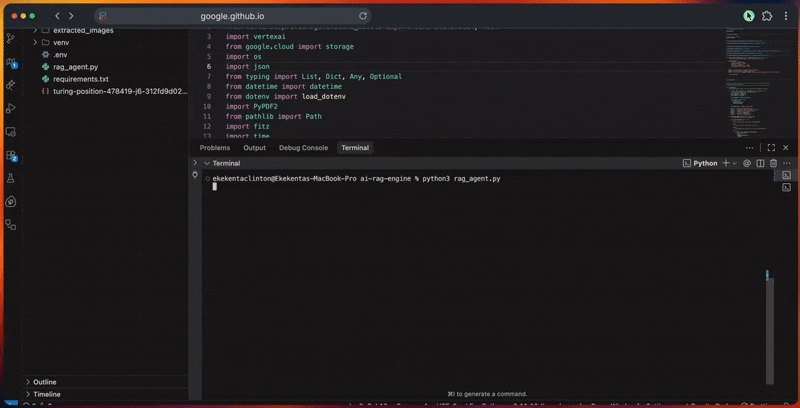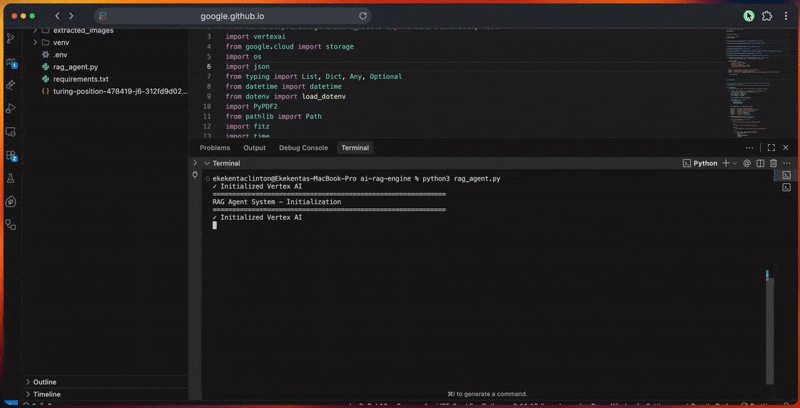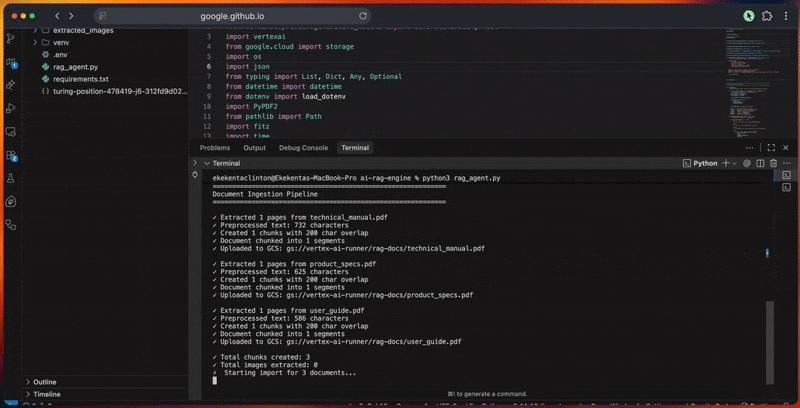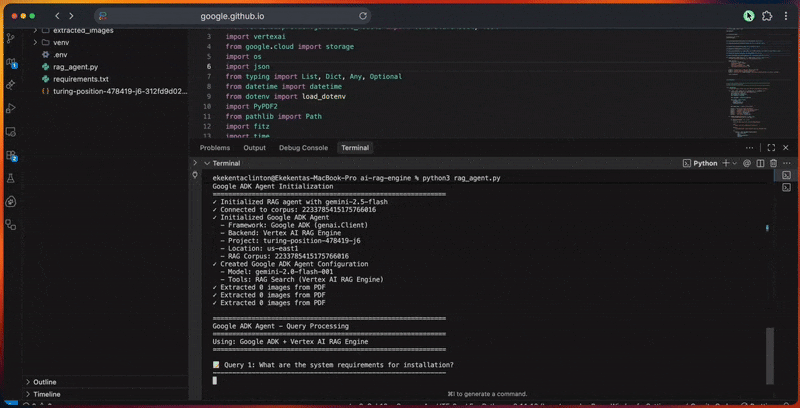
Reflexiones finales
Ahora dispone de un sistema de agente RAG listo para su producción que combina el kit de desarrollo de agentes de Google con Vertex IA. El sistema ingesta documentos, recupera el contexto relevante mediante una búsqueda híbrida y genera respuestas precisas con citas.
Mejórelo optimizando las estrategias de fragmentación, añadiendo bucles de retroalimentación, integrando fuentes de datos adicionales o habilitando la supervisión en tiempo real. El diseño modular permite una fácil personalización.
Explore los flujos de trabajo avanzados de IA y la infraestructura de IA de Bright Data para obtener más capacidades.
Cree una cuenta gratuita para empezar a construir.





