

En esta guía, aprenderás lo siguiente:
- Qué es un Scraper de AliExpress y cómo funciona
- Los tipos de datos que puede recuperar automáticamente de AliExpress
- Cómo crear un script de scraping de AliExpress utilizando Python
¡Empecemos!
¿Qué es un Scraper de AliExpress?
Un scraper de AliExpress recupera automáticamente datos específicos de las páginas de AliExpress. Navega por las páginas de AliExpress imitando los hábitos de navegación de los usuarios. Transforma el contenido de las páginas web en un formato utilizable, como CSV o JSON, y controla interacciones como la paginación. Su objetivo final es recuperar información estructurada, como imágenes de productos, detalles de productos, opiniones de clientes, precios y mucho más.
Si quieres obtener más información sobre cómo crear scrapers web, lee nuestra guía sobre cómo crear un bot de scraping.
Datos que puede extraer de AliExpress: guía paso a paso
AliExpress contiene una gran cantidad de información, como por ejemplo:
- Detalles de los productos: nombres, descripciones, imágenes, rangos de precios, información del vendedor y mucho más.
- Comentarios de los clientes: valoraciones, reseñas de productos y mucho más.
- Categorías y etiquetas: categorías de productos, etiquetas relevantes o rótulos.
¡Es hora de aprender a extraerlos!
Extracción de datos de AliExpress en Python
Esta sección del tutorial ofrece una guía paso a paso para crear un Scraper de AliExpress.
El objetivo es guiarte en la escritura de un script en Python que extraiga automáticamente la información de la página «silla ergonómica» de AliExpress:
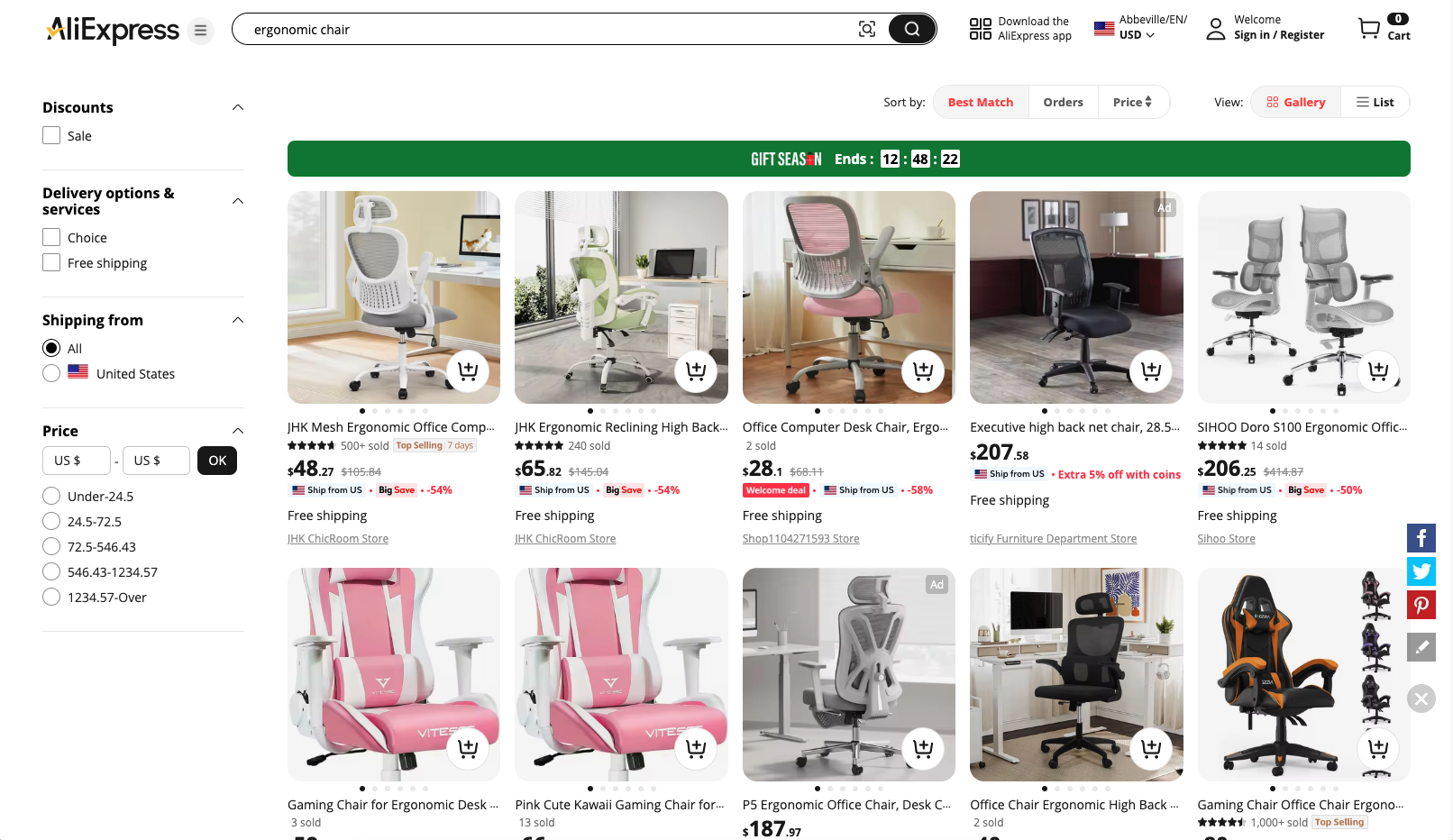
Paso n.º 1: Configuración del proyecto
Asegúrate de tener Python 3 instalado en tu ordenador local. Si no es así, descárgalo desde la documentación oficial y sigue el asistente de instalación para configurarlo.
A continuación, utilice el siguiente comando para crear el directorio de su proyecto:
mkdir aliexpress-scraper
Este directorio contendrá su código Python.
Ingrese al directorio en su terminal y cree un entorno virtual dentro de él:
cd aliexpress-Scraper
python -m venv env
Continúa y carga la carpeta del proyecto en tu IDE de Python preferido, como Visual Studio Code con la extensión Python.
En la terminal de tu IDE, activa el entorno virtual. Ejecuta el siguiente comando si utilizas macOS o Linux:
.env/bin/activate
De forma equivalente, en Windows, utiliza este comando:
env/Scripts/activate
¡Bien!
En el directorio raíz de tu proyecto, crea un archivo Scraper.py. Tu proyecto debería tener ahora esta estructura de carpetas:
¡Genial! Tu entorno Python para el Scraping web de AliExpress está listo.
Paso n.º 2: selecciona la biblioteca de scraping
El objetivo actual es determinar si AliExpress emplea páginas dinámicas o estáticas. Navega a tu página de AliExpress de destino en modo privado o incógnito en tu navegador. A continuación, haz clic con el botón derecho del ratón en un espacio vacío del fondo de la página web, selecciona la opción «Inspeccionar», navega a la pestaña «Red», aplica el filtro «Fetch/XHR» y actualiza la página:
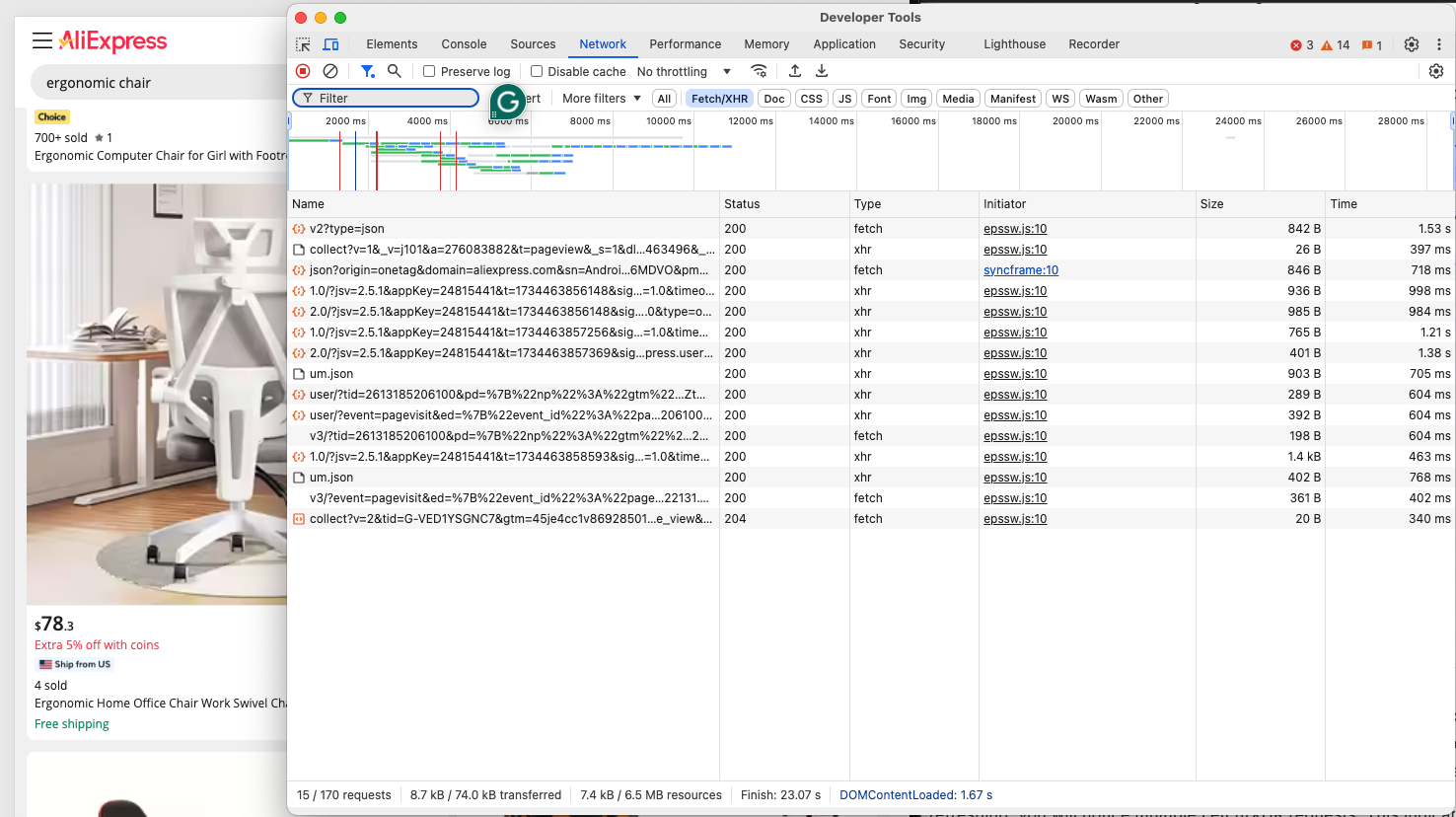
Comprueba si la página realiza alguna consulta dinámica en esta sección de DevTools. Después de actualizar la página, verás varias solicitudes Fetch/XHR. Esto indica que la página utiliza solicitudes dinámicas para cargar contenido adicional. Si echas un vistazo al DOM de la página en comparación con el documento HTML devuelto por el servidor, también verás que AliExpress utiliza renderización JavaScript.
Para extraer datos de AliExpress de forma eficaz, necesitarás una herramienta de automatización del navegador como Selenium, ya que la página de destino utiliza JavaScript para la representación. Nuestro blog sobre el Scraping web con Selenium es un recurso excelente para principiantes.
Con Selenium, puedes manipular un navegador web, imitar las interacciones de los usuarios y extraer contenido renderizado con JavaScript. ¡Instálalo y empieza a utilizarlo!
Paso n.º 3: Instalar y configurar Selenium
En el entorno virtual activado, instala Selenium con este comando:
pip install -U selenium
En el archivo scraper.py, importe WebDriver desde Selenium e inicialícelo.
from selenium import webdriver
# Inicializar el controlador Chrome
driver = webdriver.Chrome()
# lógica de rastreo...
# Cerrar el controlador
driver.quit()
En el código anterior se inicializa un WebDriver para gestionar una instancia de Chrome. Cabe señalar que AliExpress cuenta con medidas antiescraping que podrían impedir que los navegadores sin interfaz gráfica accedan al sitio.
Por lo tanto, no es recomendable establecer el indicador--headless. En su lugar, considere una opción alternativa como Playwright Stealth.
Ahora que ya está todo configurado para empezar a scrapear AliExpress, veamos cómo conectarse a la página de destino.
Paso n.º 4: Conéctese a la página de destino
Utilice el método get() expuesto por el objeto Selenium WebDriver para visitar la página de destino. El archivo scraper.py debería tener ahora este aspecto:
from selenium import webdriver
# Inicializar el controlador Chrome
driver = webdriver.Chrome()
# URL de la página de destino
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
# Conectarse a la página de destino
driver.get(url)
# Lógica de scraping...
# Cerrar el controlador
driver.quit()
Coloca un punto de interrupción de depuración en la última línea e inicia el script con el depurador. El navegador Chrome controlado debería abrirse automáticamente como se muestra a continuación:
¡Genial! La notificación «Chrome está siendo controlado por un software de pruebas automatizado» indica que Selenium está controlando correctamente Chrome según la configuración.
Paso n.º 5: Seleccionar los elementos del producto
Dado que la página de productos de AliExpress contiene varios productos, primero debe inicializar una estructura de datos para almacenar los datos extraídos. Para ello, una matriz funcionará perfectamente:
productos = []
Para garantizar que su Scraper siga funcionando incluso cuando cambie el diseño del sitio, debe crear una función auxiliar que haga que sus selectores sean más resistentes a esos cambios:
def find_element_smart(parent, by_list):
"""Prueba varios selectores hasta encontrar un elemento"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
La función find_element_smart() itera a través de una lista de estrategias de selector by_list para localizar un elemento dentro de un elemento padre dado. Prueba cada par <by_type, selector> hasta que encuentra un elemento visible, devolviéndolo si tiene éxito. De lo contrario, devuelve None si no se encuentra ningún elemento coincidente.
A continuación, inspeccione los elementos HTML de los productos de la página para comprender cómo seleccionarlos, identificar el tipo de datos que contienen y determinar cómo extraer esos datos.
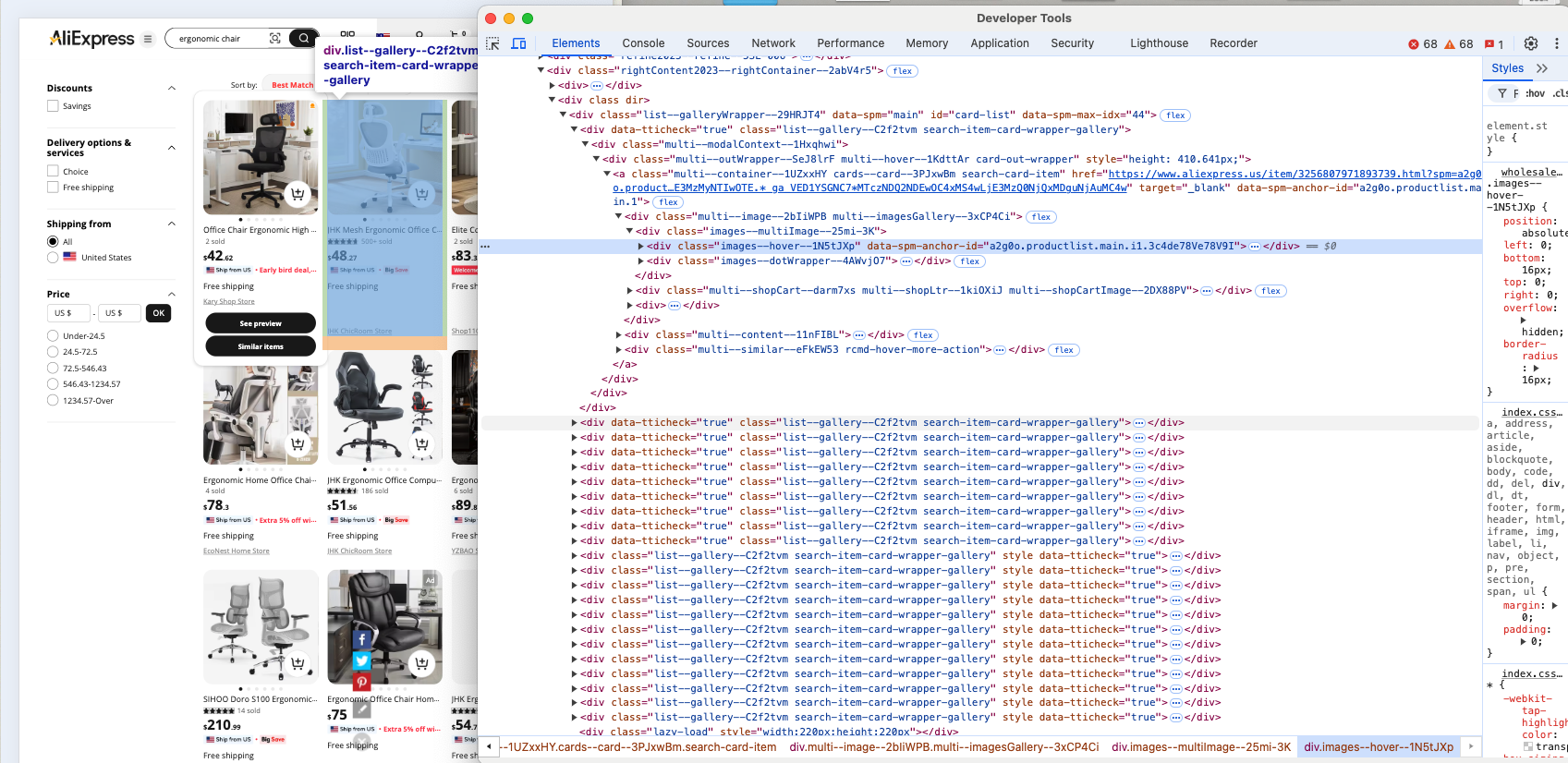
Es obvio que cada elemento de producto es un nodo .list-–gallery—-C2f2tvm.
Tenga en cuenta que list--gallery--C2f2tvm podría cambiar en cualquier momento, ya que contiene una cadena generada aleatoriamente. Por lo tanto, no debe basarse en esa clase para la selección de elementos. En su lugar, debe empezar por buscar productos basándose en su estructura, como elementos div que contengan tanto imágenes como enlaces. Si eso no funciona, intente buscar productos basándose en su contenido o céntrese en elementos HTML más específicos.
Implemente la lógica de selección de productos como se indica a continuación:
# Busque primero los productos utilizando patrones estructurales y, a continuación, recurra a los patrones de clase
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Esperar y obtener productos
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
productos_encontrados = []
para tipo_selector, selector en selectores_de_productos:
intentar:
elementos = esperar.hasta(EC.presencia_de_todos_los_elementos_localizados((tipo_selector, selector)))
si elementos:
productos_encontrados = elementos
romper
excepto:
continuar
El código anterior aplica la estrategia del selector para recuperar elementos de la página con selectores CSS genéricos.
Incluye la siguiente importación en tu script de Python:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
A continuación, introduce una instancia de WebDriverWait justo después de inicializar WebDriver, pero antes de cualquier interacción con la página:
wait = WebDriverWait(driver, 20)
En lugar de buscar inmediatamente elementos en una página al extraer datos de sitios web dinámicos como AliExpress, WebDriverWait le indica al Scraper que sea paciente y espere hasta el tiempo especificado (20 segundos en este caso) para que aparezcan los elementos. Esto es importante porque las páginas web cargan los elementos a diferentes velocidades y, sin una espera adecuada, el Scraper podría quedarse con elementos que aún no se han cargado, lo que provocaría errores.
¡Ahora estás un paso más cerca de rastrear completamente AliExpress!
Paso n.º 6: extrae los elementos del producto de AliExpress
Inspeccione un elemento del producto para comprender su estructura HTML:
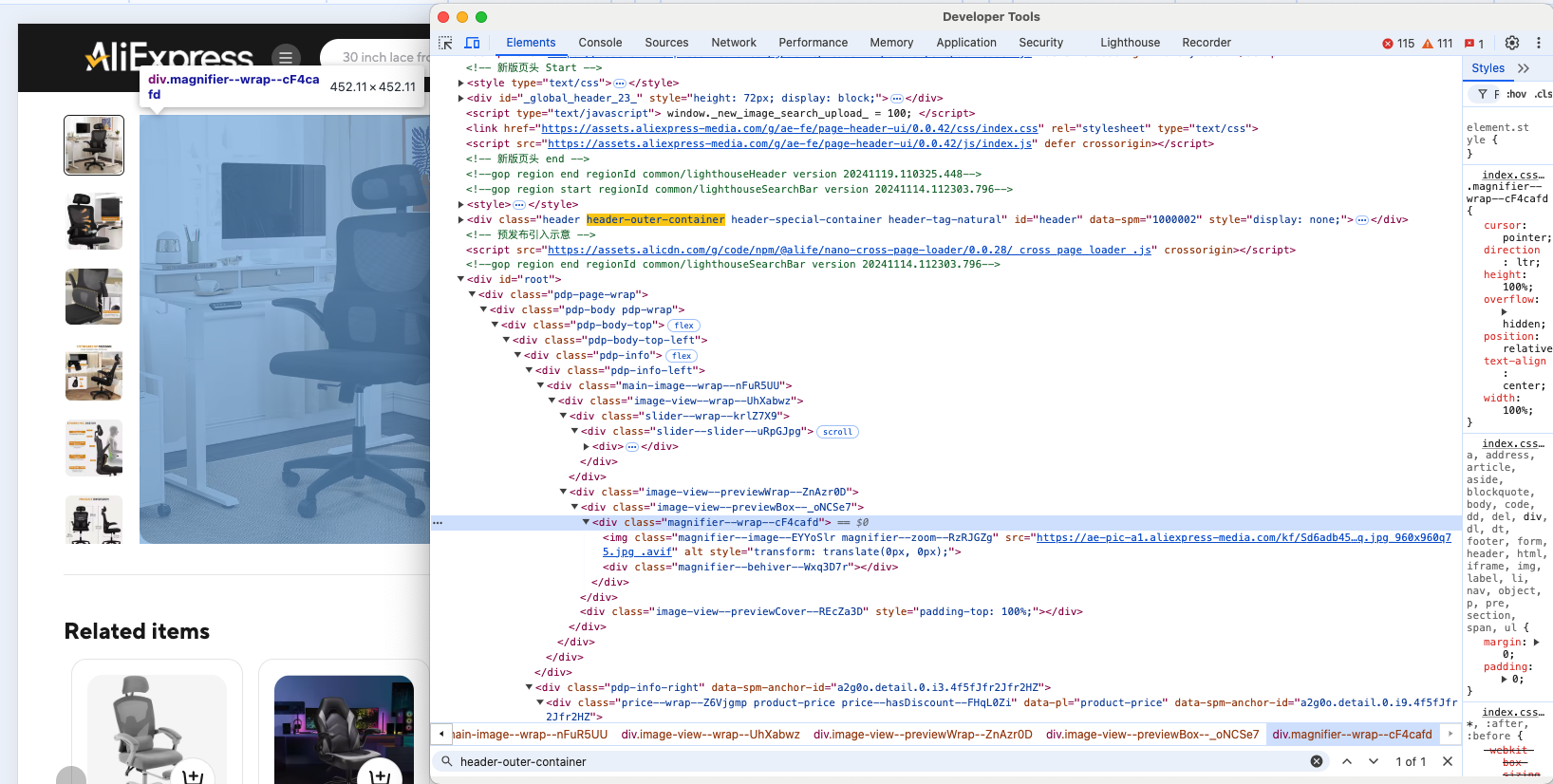
Es evidente que puedes extraer la imagen del producto, la URL, el nombre o título, el precio y el descuento.
Antes de extraer cada producto, comprueba si es visible en la ventana gráfica:
wait.until(EC.visibility_of(product))
Ahora, configura los selectores para extraer los datos de cada producto. En lugar de utilizar nombres de clase específicos que podrían fallar, utiliza patrones como estos:
# Obtener imagen: buscar imágenes de productos por patrones de origen
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Obtener URL: buscar enlaces de productos
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Obtener título: buscar primero el elemento de texto más largo
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Obtener precio: buscar símbolos/patrones de moneda
price_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '$') or contains(text(), 'US') or contains(text(), 'GHS')]"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Intentar obtener descuento si está disponible
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
La función find_element() devuelve el primer elemento que coincide con el selector CSS especificado. A continuación, puede utilizar el atributo text para extraer su contenido de texto.
Añada los datos extraídos a la matriz de productos y utilícelos para rellenar un diccionario de productos:
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
Tu lógica de extracción de datos ya está completa y lista para usar.
Paso n.º 7: exportar los datos extraídos a CSV
En su configuración actual, los datos extraídos se almacenan en la matriz de productos. Para que otros puedan compartirlos y acceder a ellos, debe exportarlos a un formato legible para los humanos, como un archivo CSV. A continuación se explica cómo crear y rellenar un archivo CSV con los datos extraídos:
# Escribir datos en CSV
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["image_url", "product_url", "product_title", "product_price", "product_discount"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for product in products:
writer.writerow(product)
Este código crea un archivo CSV que funciona como una hoja de cálculo: cada producto tiene su propia fila y los diferentes detalles sobre el producto (imagen, URL, título, precio y cualquier descuento) se colocan en columnas separadas. Cuando abras el archivo final aliexpress_products.csv, verás toda la información de los productos de AliExpress recopilada y organizada cuidadosamente en columnas.
Por último, desde la biblioteca estándar de Python, importa la biblioteca csv en tu script:
import csv
Paso n.º 8: Ponlo todo junto
Así es como debería quedar tu script de recopilación final después de juntar todo el código:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
def find_element_smart(parent, by_list):
"""Prueba varios selectores hasta encontrar un elemento"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
# Inicializar el controlador
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 20)
# URL de destino
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
driver.get(url)
# Esperar a que se carguen los productos iniciales
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div[class*='gallery']")))
# Dónde almacenar los datos extraídos
products = []
# Buscar productos utilizando primero patrones y, a continuación, recurrir a patrones de clase
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Esperar y obtener productos
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elementos = esperar.hasta(EC.presencia_de_todos_los_elementos_localizados((tipo_selector, selector)))
si elementos:
productos_encontrados = elementos
romper
excepto:
continuar
# Iterar sobre los productos encontrados y extraer datos de ellos
para producto en productos_encontrados:
# Esperar a que el producto sea visible e interactivo
wait.until(EC.visibility_of(product))
# Obtener imagen: buscar imágenes de productos por patrones de origen
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Obtener URL: buscar enlaces de productos.
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Obtener título: buscar primero el elemento de texto más largo
title_element = find_element_smart(product, [
(By.XPATH, ".//div[string-length(text()) > 20]"),
(By.XPATH, ".//*[contains(@class, 'title')]"),
(By.CSS_SELECTOR, "[class*='name']")
])
# Obtener precio
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, «.//*[contains(@class, 'price')]»)
])
if all([img_element, url_element, title_element, price_element]):
# Obtener descuento si está disponible
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
# Guardar resultados
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image_url", "product_url", "product_title", "product_price", "product_discount"])
writer.writeheader()
writer.writerows(products)
driver.quit()
Ahora, inicia el Scraper con el siguiente comando:
python Scraper.py
El script debería ejecutarse correctamente y el archivo aliexpress_products.csv debería contener los datos extraídos, tal y como se muestra:
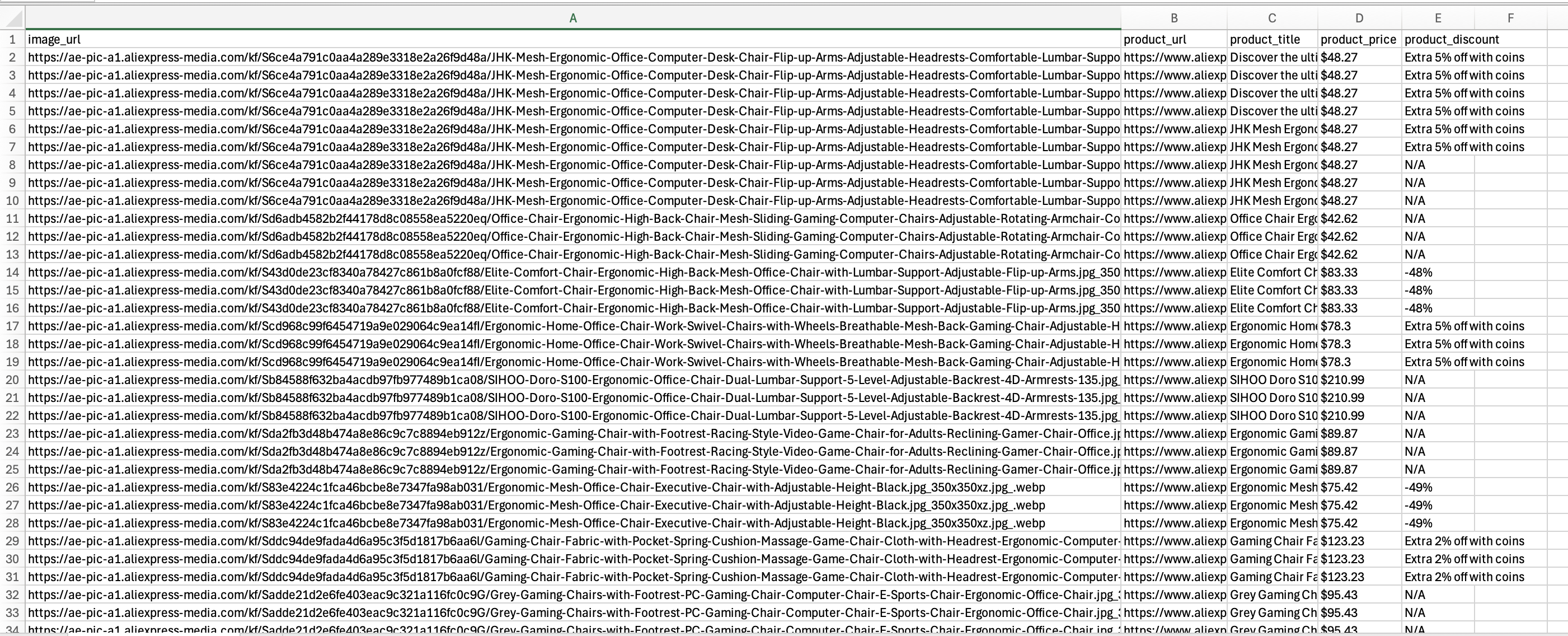
Hay varios pasos adicionales que puede seguir después de crear un script de rastreo funcional. Entre ellos se incluyen la automatización del proceso de ejecución y la implementación de optimizaciones para garantizar que el Scraper siga proporcionando datos valiosos a lo largo del tiempo.
Conclusión
En esta guía, ha descubierto qué es un Scraper de AliExpress y los tipos de datos que puede extraer. También ha aprendido a crear un script de Python para rascar productos de AliExpress con un código mínimo.
Sin embargo, el scraping de AliExpress presenta varios retos. La plataforma implementa estrictas protecciones anti-bot y utiliza características como la paginación, lo que añade complejidad al proceso de scraping. Desarrollar una solución de scraping de Alibaba eficaz puede ser todo un reto.
Nuestra API AliExpress Scraper ofrece una solución especializada que le permitirá eliminar esos retos. Con llamadas API sencillas, puede obtener datos del sitio de destino sin problemas y mitigar el riesgo de ser bloqueado. ¿Necesita los datos rápidamente?
¿Quiere probar nuestras API de Scraper o explorar nuestros conjuntos de datos? ¡Cree una cuenta en Bright Data hoy mismo y comience su prueba gratuita!






