

En este artículo del blog, aprenderás:
- Qué es IBM Bob y qué ofrece.
- Por qué extenderlo con acceso web ayuda a superar sus limitaciones principales.
- Cómo Bright Data permite al agente de codificación IBM Bob realizar Scraping web, búsqueda web y navegación basada en navegador.
- Cómo conectar Bright Data al agente de codificación IBM Bob a través de MCP.
- Cómo equipar a IBM Bob con conocimiento de las soluciones de Bright Data usando archivos de Agent Skills.
- El poder de combinar IBM Bob con Bright Data, ilustrado a través de un ejemplo completo.
¡Comencemos!
¿Qué es IBM Bob?
IBM Bob es un socio SDLC (Ciclo de Vida del Desarrollo de Software) impulsado por IA que se integra directamente en tu entorno de desarrollo. Te ayuda a construir, entender y mantener bases de código reales con la ayuda de los modelos de IA de IBM.
Bob gestiona preguntas y respuestas sobre tu base de código, automatiza tareas repetitivas y opera a través de modos especializados como planificación, codificación y orquestación. Las características clave que ofrece esta herramienta son:
- Generación de código: Transforma instrucciones en lenguaje natural en código funcional, ayudándote a construir rápidamente funcionalidades, prototipos o implementaciones completas directamente dentro de tu proyecto.
- Completado de código: Proporciona sugerencias inteligentes de una o varias líneas, mejorando la productividad.
- Refactorización y depuración: Mejora automáticamente el código existente limpiando la estructura, corrigiendo problemas y ayudando a identificar y resolver errores en tu base de código.
- Generación y actualización de documentación: Crea y mantiene documentación directamente desde tu código, asegurando que los documentos del proyecto se mantengan precisos y sincronizados con los cambios de implementación.
- Preguntas y respuestas sobre la base de código: Te permite hacer preguntas en lenguaje natural sobre tu proyecto y recibir explicaciones contextuales.
- Automatización de tareas: Optimiza flujos de trabajo repetitivos como la creación de código repetitivo y tareas de desarrollo rutinarias.
- Andamiaje de proyectos: Genera archivos, componentes y estructuras de proyectos completas, ayudándote a inicializar rápidamente nuevas aplicaciones o funcionalidades.
- Acceso al sistema de archivos: Permite leer y escribir archivos directamente dentro de tu proyecto, habilitando modificaciones y actualizaciones fluidas dentro del editor.
- Ejecución de comandos: Ejecuta comandos de terminal y shell directamente desde Bob, reduciendo el cambio de contexto y acelerando los flujos de trabajo de desarrollo.
- Integración MCP: Extiende Bob con herramientas externas a través del Model Context Protocol.
Por qué IBM Bob Necesita Acceso a la Web
Los agentes de codificación IBM Bob eventualmente chocan con un límite conocido por todo LLM: la fecha de expiración de su propio conocimiento. Debido a que un LLM se entrena en un conjunto de datos fijo capturado en un momento específico, refleja una instantánea estática del conocimiento.
En el mundo del desarrollo de software, las bibliotecas evolucionan de la noche a la mañana y las “mejores prácticas” se convierten en deuda técnica en cuestión de meses. Por ello, depender de un conocimiento congelado es una responsabilidad significativa. Tu agente puede sugerir con confianza métodos obsoletos, pasar por alto problemas críticos de seguridad o producir orientación desactualizada. Todo eso, debido a los datos de entrenamiento de IA estáticos.
Cerrar esta brecha requiere transformar tu IA de un sistema cerrado en un participante activo en la web en vivo. ¡Aquí es donde Bright Data se vuelve indispensable!
Al integrar la infraestructura lista para IA de Bright Data, otorgas a tu agente la autonomía para acceder a internet con la misma fluidez que un desarrollador humano. Esta conectividad equipa a Bob con la capacidad de:
- Descubrir información en tiempo real: Realizar búsquedas profundas en Google y otros motores para encontrar los últimos avances técnicos.
- Aprendizaje continuo: Explorar documentación oficial, hilos de Stack Overflow y foros de desarrolladores para autocorregirse y mantenerse actualizado.
- Recuperación de datos: Extraer datos web estructurados para poblar bases de datos o generar respuestas simuladas precisas.
- Soporte de documentación: Sugerir automáticamente enlaces externos relevantes y citas para mejorar tus archivos
README.mdy guías técnicas. - Escalabilidad en el mundo real: Ejecutar flujos de trabajo complejos que requieren contexto externo actualizado más allá del conjunto de entrenamiento inicial.
Lo que distingue a Bright Data es su infraestructura de red a gran escala, impulsada por un Grupo de proxies de más de 400 millones de IPs de Proxies residenciales en 195 países. Esto permite una escalabilidad masiva manteniendo un tiempo de actividad del 99,99% y una tasa de éxito del 99,95%.
Al anclar tu LLM en datos en vivo y verificables, vas más allá de las limitaciones de un modelo estático y entras en el ámbito de un asistente de codificación verdaderamente inteligente.
Cómo Extender IBM Bob con Capacidades de Scraping Web, Búsqueda e Interacción
Bright Data apoya a IBM Bob a través de dos enfoques complementarios:
- Bright Data Web MCP: El servidor MCP oficial de Bright Data, que expone más de 60 herramientas para interactuar con sus productos y servicios basados en API.
- Bright Data skills: Una colección de habilidades compatibles con el estándar Agent Skills, diseñadas para ayudar a los agentes de IA a utilizar los productos de Bright Data de manera más efectiva.
Importante: Estos dos enfoques no son alternativas, funcionan mejor juntos. De hecho, las Bright Data skills incluyen una habilidad dedicada que ayuda a los agentes de IA a orquestar y aprovechar mejor las herramientas Web MCP.
Nota: Las siguientes secciones del tutorial se aplican tanto a IBM Bob Shell como al IBM Bob IDE. Mostraremos cómo integrar Bright Data en el IBM Bob IDE para una guía visual más clara, pero los mismos archivos de configuración y procedimientos también se aplican a IBM Bob Shell.
Bright Data Web MCP
El Bright Data Web MCP proporciona más de 60 herramientas para la recopilación automatizada de datos web, extracción estructurada e interacciones basadas en navegador.
Incluso en el nivel gratuito, expone herramientas útiles como:
| Herramienta | Descripción |
|---|---|
search_engine + versión por lotes |
Recupera resultados de Google, Bing o Yandex en formato JSON o Markdown |
scrape_as_markdown + versión por lotes |
Convierte cualquier página web en Markdown limpio, con manejo anti-bot |
discover |
Encuentra y clasifica resultados web usando puntuación de relevancia basada en IA |
El modo Pro es donde Web MCP se convierte verdaderamente en un elemento transformador. Desbloquea herramientas avanzadas de extracción estructurada para plataformas como Amazon, LinkedIn, Zillow, YouTube, TikTok, Google Maps, Yahoo Finance y más de 35 otras. También expone herramientas para automatización de navegador.
Bright Data Skills
Las Bright Data skills incluyen:
| Habilidad | Descripción |
|---|---|
search |
Busca en Google y devuelve resultados JSON estructurados con soporte de paginación |
scrape |
Extrae cualquier página web como Markdown limpio con manejo de CAPTCHA y renderizado JS |
data-feeds |
Extrae Conjuntos de datos estructurados de más de 40 plataformas (Amazon, LinkedIn, TikTok, etc.) |
bright-data-mcp |
Orquesta herramientas MCP para búsqueda, Scraping, extracción y automatización |
brightdata-cli |
Uso de CLI para Scraping, búsqueda, Proxies y monitoreo |
scraper-builder |
Guía la creación de Scrapers listos para producción de extremo a extremo |
competitive-intel |
Genera información competitiva en tiempo real (precios, SEO, contrataciones, reseñas) |
design-mirror |
Replica sistemas de diseño de UI, tokens y estructuras de componentes |
bright-data-best-practices |
Mejores prácticas para Web Unlocker, API SERP, API Scraper y API de Navegador |
python-sdk-best-practices |
Orientación para usar el SDK de Python de Bright Data (sync/async, errores, datasets) |
Pasos Comunes
Antes de mostrar cómo integrar Bright Data en IBM Bob a través de MCP o skills, hay algunos pasos de requisitos previos comunes que debes completar.
Requisitos previos
Para seguir este tutorial, asegúrate de tener una máquina con:
- macOS, Linux o Windows como sistema operativo.
- Al menos 4 GB de RAM (se recomiendan 8 GB).
- Al menos 500 MB de espacio en disco disponible.
- Una conexión a Internet activa.
También necesitarás:
- Node.js instalado localmente. Esto es necesario para configurar MCP localmente e instalar skills a través del paquete
skills. Si planeas conectarte remotamente al Web MCP y agregar las skills manualmente, puedes omitir este requisito. - Un IBMid, idealmente con una prueba de BOB ya configurada.
- Una cuenta de Bright Data con una clave API configurada.
Para generar una clave API de Bright Data, sigue la guía oficial.
Paso #1: Instalar IBM Bob
Comienza descargando el instalador de IBM BOB para tu sistema operativo y ejecútalo. Una vez disponible en tu máquina, ejecuta el instalador y sigue las instrucciones. Esto es lo que deberías ver:
A continuación, puedes importar configuraciones y extensiones de tu IDE existente, o simplemente omitir este paso. Luego llegarás a la experiencia del IBM Bob IDE:
IBM Bob es muy similar a Visual Studio Code, pero presta atención a la columna de la derecha. Aquí es donde ocurren las interacciones con IBM BOB en una experiencia de codificación agéntica.
¡Bien hecho! IBM Bob está ahora correctamente configurado de forma local.
Paso #2: Completar la Configuración de IBM Bob
Presiona el botón “Abrir carpeta” y carga tu carpeta de proyecto. En este caso, asumiremos que estás abriendo una carpeta ibm-bob-bright-data-example.
Nota: Cualquier otra carpeta también funcionará, incluyendo una que ya contenga un proyecto existente.
A continuación, conecta el servicio Bob en tu cuenta de IBM a tu instancia local de IBM Bob iniciando sesión. Haz clic en el botón “Iniciar sesión en Bob”. O, si aún no has configurado Bob en tu cuenta de IBM, selecciona la opción “Registrarse para una prueba gratuita”.
Sigue las instrucciones, que requerirán que inicies sesión en tu cuenta de IBM en el navegador. Una vez completado, Bob estará completamente operativo.
Considera presionar el ícono de engranaje para ver detalles sobre tu cuenta de IBM y suscripción. Esto es lo que deberías ver:
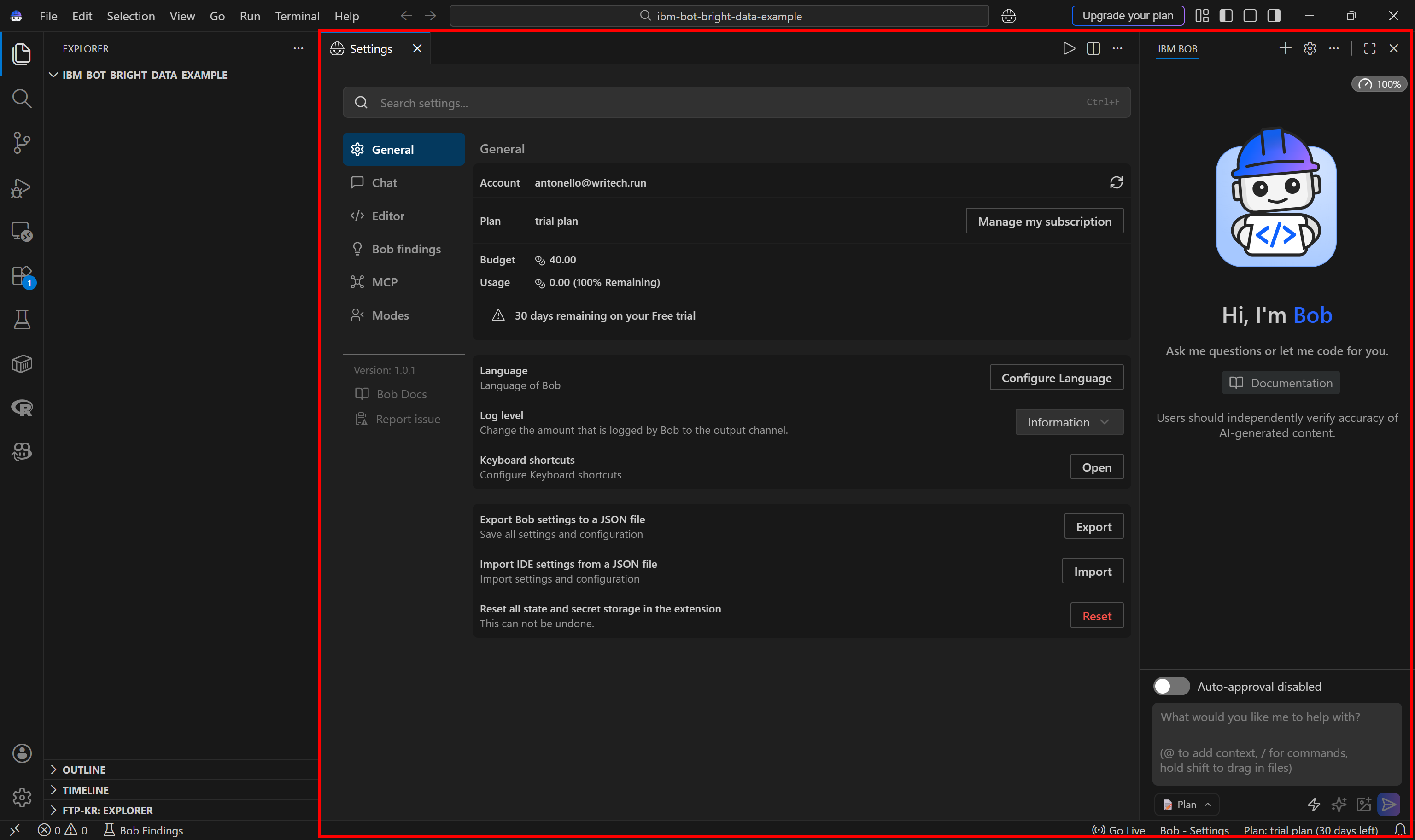
¡Fantástico! IBM Bob está ahora listo para apoyar tus proyectos de codificación.
Conectando Bright Data Web MCP a IBM Bob
Esta sección te guiará a través de la configuración de una instancia local del Bright Data Web MCP en IBM Bob.
Requisitos previos
Para seguir más fácilmente, se recomienda que tengas:
- Un entendimiento básico de cómo funciona MCP.
- Familiaridad con las herramientas expuestas por el Bright Data Web MCP.
Además, ten en cuenta que los requisitos previos descritos en la sección “Pasos Comunes” también se aplican aquí.
Paso #1: Comenzar con el Web MCP de Bright Data
Primero, verifica que el servidor MCP de Bright Data se ejecute en tu máquina. Alternativamente, si deseas configurar una conexión remota al MCP, omite este paso.
Comienza iniciando sesión en tu cuenta de Bright Data. Para una configuración rápida, sigue el asistente en la sección “MCP” del panel de control:
De lo contrario, para obtener orientación adicional, consulta las instrucciones a continuación.
Luego, instala el Web MCP globalmente a través del paquete @brightdata/mcp:
npm install -g @brightdata/mcpVerifica que el servidor MCP se inicia localmente probándolo con este comando:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpReemplaza el marcador de posición <YOUR_BRIGHT_DATA_API> con tu clave API de Bright Data real. Este comando establece la variable de entorno API_TOKEN requerida e inicia una instancia local del servidor Web MCP.
Si tiene éxito, deberías ver algo similar a:

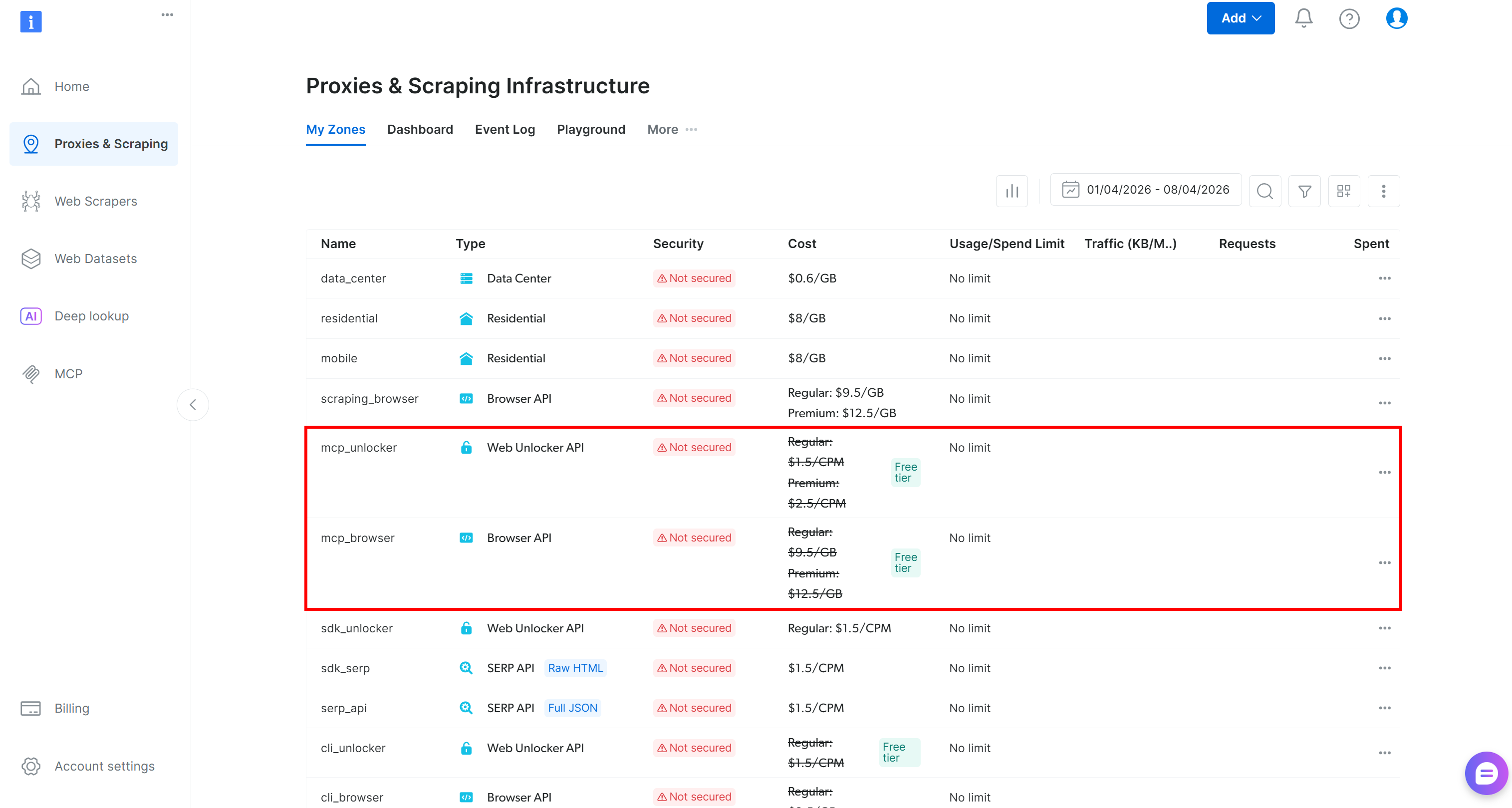
En el primer inicio, el paquete @brightdata/mcp crea automáticamente estas Zonas en tu cuenta de Bright Data:
mcp_unlocker: Una Zona para Web Unlocker.mcp_browser: Una Zona para Browser API.
Esas dos Zonas impulsan las más de 60 herramientas expuestas por la instancia Web MCP. Ten en cuenta que también puedes configurar tus propias Zonas personalizadas, como se explica en la documentación.
Para verificar que las Zonas estándar se han creado, accede a la página “Proxies e Infraestructura de Scraping” en el panel de control de Bright Data. Deberías ver ambas Zonas listadas en la tabla:
Ahora, recuerda que en el nivel gratuito del Web MCP, solo tienes acceso a las siguientes herramientas:
search_engine(+ su versión por lotes)scrape_as_markdown(+ su versión por lotes)discover
Para desbloquear las más de 60 herramientas, activa el modo Pro añadiendo la variable de entorno PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpNota: El modo Pro no está incluido en el nivel gratuito y [genera cargos adicionales](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes).
¡Genial! Acabas de verificar que el servidor Web MCP puede ejecutarse en tu máquina. Pronto, configurarás IBM Bob para lanzar el servidor de forma autónoma y conectarse a él.
Paso #2: Configurar el Web MCP en IBM Bob
Para configurar y gestionar servidores MCP en IBM Bob, comienza abriendo la página “Configuración” y haciendo clic en el ícono de engranaje.

En la sección “MCP”, haz clic en el botón “Abrir” en la entrada “MCPs del Proyecto”:
Nota: Si deseas configurar el Bright Data Web MCP globalmente para todos los proyectos de IBM Bob, haz clic en el botón “Abrir” bajo la entrada “MCPs Globales”.
Se creará una carpeta .bob que contiene un archivo mcp.json en el directorio raíz de tu proyecto:
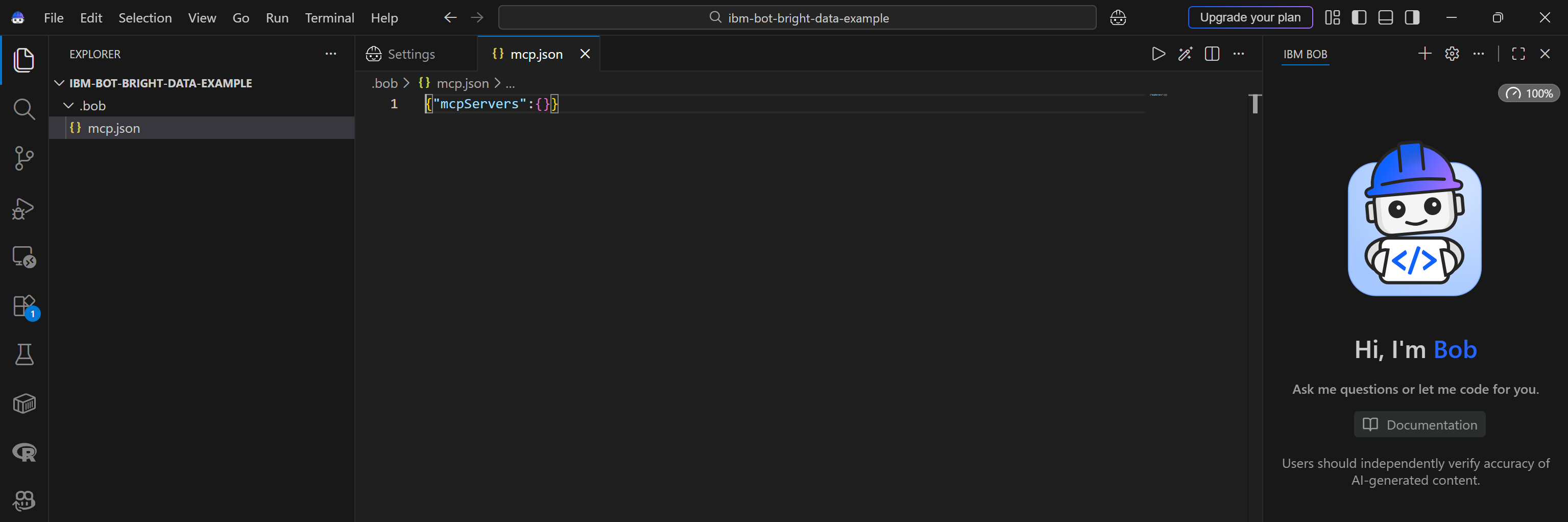
El archivo .bob/mcp.json es el archivo de configuración local utilizado para la integración MCP en IBM Bob (tanto IDE como Shell).
Para conectarte al Web MCP, asegúrate de que tu archivo de configuración incluya lo siguiente:
{
"mcpServers": {
"bright-data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}Esta configuración refleja el comando npx que probaste anteriormente, usando variables de entorno para autenticación y configuración:
API_TOKEN: Requerido. Establécelo con tu clave API de Bright Data.PRO_MODE: Opcional. Elimínalo o establécelo en"false"si no deseas activar el modo Pro.
Consejo: Configura el Web MCP globalmente para todos los proyectos añadiendo la misma configuración a tu archivo ~/.bob/json.json.
Nota: También puedes conectarte al Bright Data Web MCP remoto a través de Streamable HTTP usando el campo httpUrl. Este enfoque es más adecuado para configuraciones de nivel empresarial.
¡Excelente! El Web MCP debería estar ahora disponible en IBM Bob.
Paso #3: Verificar la Conexión
De vuelta en la ventana “Configuración”, ahora deberías ver una entrada del servidor MCP “bright-data”:
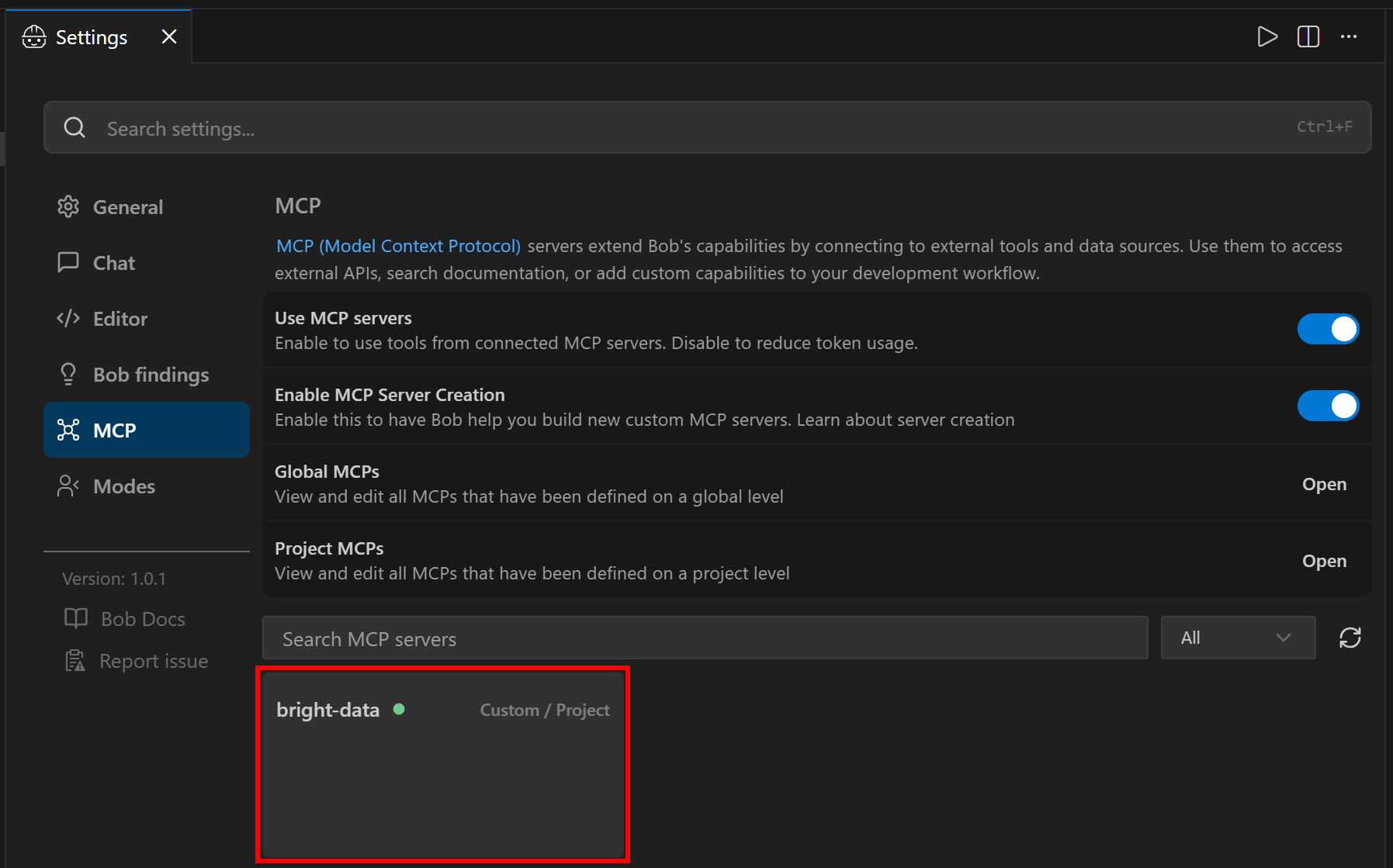
Haz clic en ella y desplázate hacia abajo hasta la sección “Herramientas”:
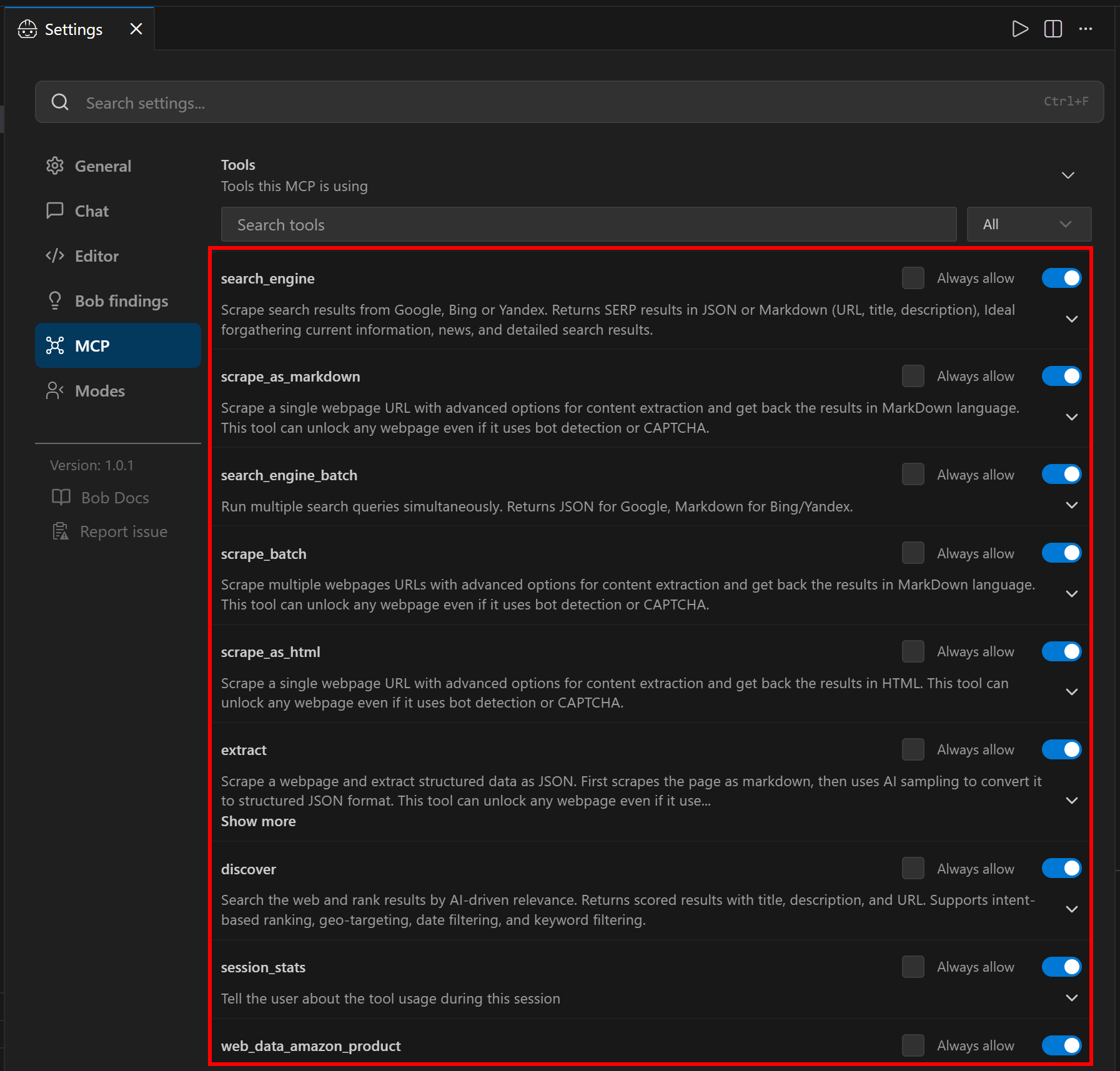
En el modo Rápido (nivel gratuito, cuando PRO_MODE se omite o se establece en false), verás un conjunto limitado de herramientas. En el modo Pro (como se configuró anteriormente), tendrás acceso al conjunto completo de más de 60 herramientas. Desde aquí, puedes controlar qué herramientas están habilitadas y si deben estar siempre disponibles.
¡Felicitaciones! Esto confirma que el Bright Data Web MCP está exponiendo correctamente herramientas a IBM Bob. (Más adelante en este artículo, mostraremos el Web MCP en acción junto con las Bright Data skills.)
Añadiendo Bright Data Skills a IBM Bob
En esta sección, verás cómo añadir las Bright Data skills a IBM Bob usando el flujo de trabajo guiado proporcionado por la CLI de skills de Vercel.
Nota: Si prefieres una configuración manual, clona el repositorio de Bright Data Skills y simplemente copia los archivos requeridos en tu proyecto:
git clone https://github.com/brightdata/skills
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.bob/skills/Dicho esto, ¡el enfoque presentado a continuación es más simple y guiado!
Requisitos previos
Para completar esta sección, asegúrate de tener:
- Un entendimiento básico de cómo funcionan los estándares de Agent Skills.
- Familiaridad con la CLI de skills de Vercel.
- Algún conocimiento de las Bright Data skills.
Además de los requisitos previos listados en la sección “Pasos Comunes”, también necesitarás:
- Una Zona de Web Unlocker API configurada en tu cuenta de Bright Data.
- El paquete
jqinstalado localmente.
Para instalar jq (una herramienta Shell para procesar JSON) en sistemas operativos basados en Debian, ejecuta:
sudo apt-get install curl jqDe manera equivalente, en macOS, ejecuta:
brew install curl jqPara una configuración rápida de la Zona de Web Unlocker API, consulta la guía “Crea tu Primera API Unlocker“. Alternativamente, sigue el siguiente paso.
Paso #1: Crear una Zona de Web Unlocker API
Inicia sesión en tu cuenta de Bright Data. En el panel de control, navega a la página “Proxies y Scraping” y echa un vistazo a la tabla “Mis Zonas”:
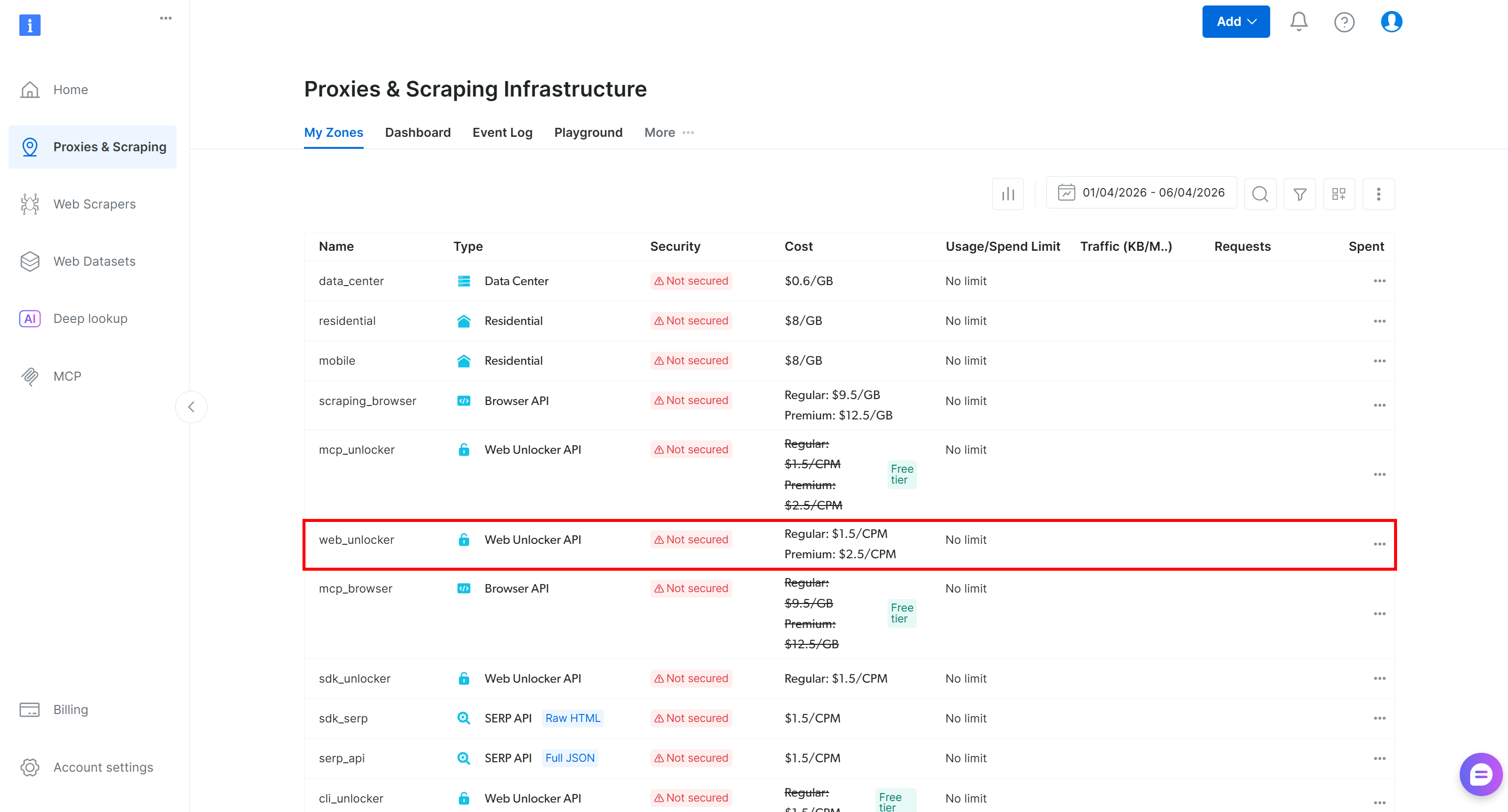
Si ya existe una Zona de Web Unlocker API (por ejemplo, web_unlocker), ¡perfecto!
Si no, desplázate hasta la sección “API Unblocker” y haz clic en “Crear zona”:
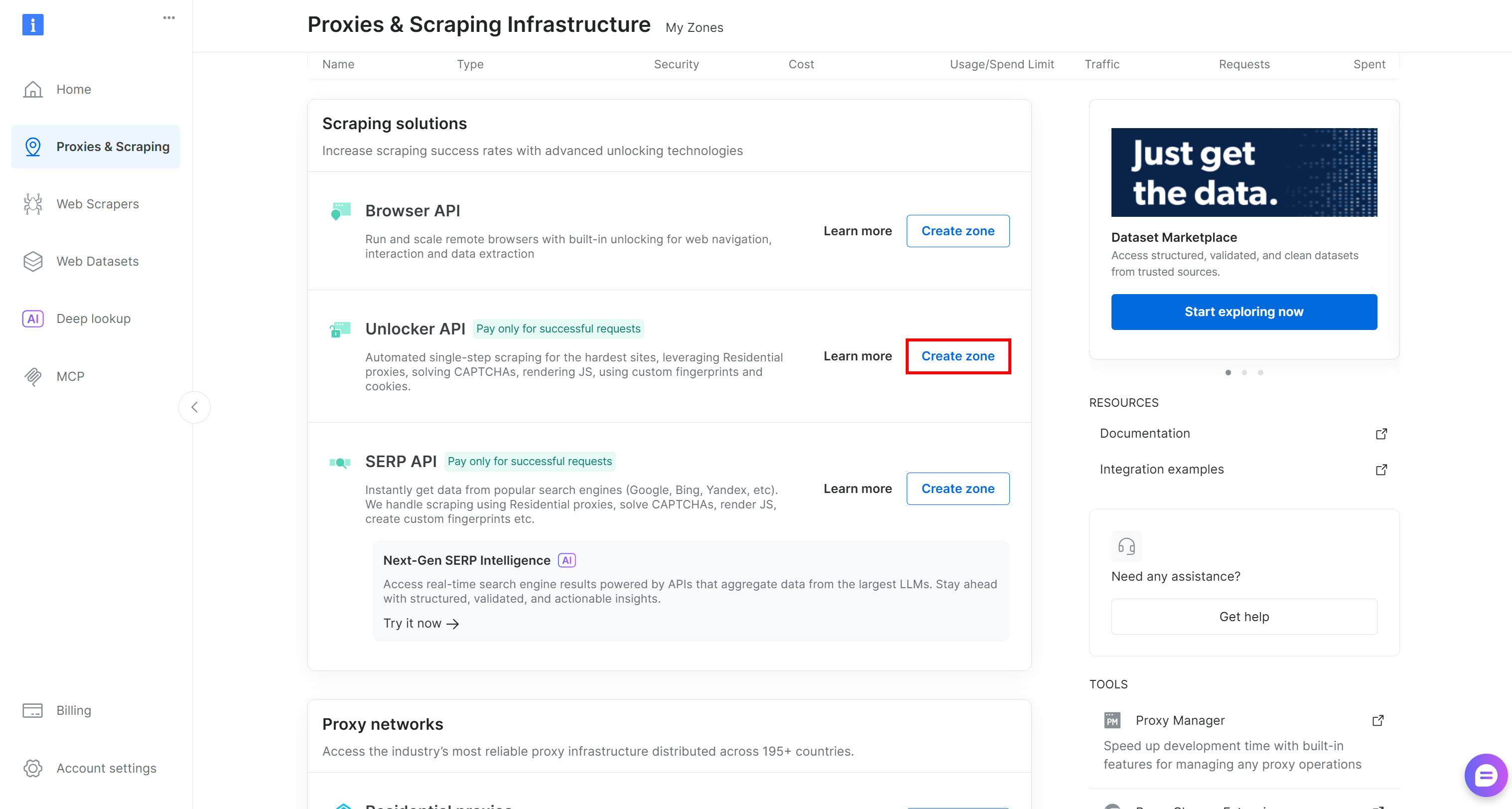
Elige un nombre claro para tu Zona y completa el asistente de configuración hasta que esté activa. ¡Perfecto!
Paso #2: Completar la Configuración de Bright Data Skills
Las Bright Data skills requieren estas variables de entorno:
BRIGHTDATA_API_KEY: Utilizada para autenticar solicitudes a las APIs de Bright Data.BRIGHTDATA_UNLOCKER_ZONE: Utilizada para conectarse a tu Zona de Web Unlocker API (usada tanto para capacidades de Scraping como de búsqueda, ya que también puede operar como una Zona de API SERP).
Establécelas en tu entorno:
export BRIGHTDATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>"Reemplaza los marcadores de posición, ¡y las Bright Data skills ya están listas para ser añadidas!
Paso #3: Instalar las Bright Data Skills
En la carpeta de tu proyecto, ejecuta el siguiente comando:
npx skills add brightdata/skills -a bobEste comando instala la CLI de skills (si aún no está disponible) e inicia un proceso de configuración interactivo que:
- Descargará las Bright Data skills del Directorio oficial de Agent Skills.
- Las configurará en tu proyecto de IBM Bob.
Primero verás una pantalla donde puedes elegir qué skills instalar:
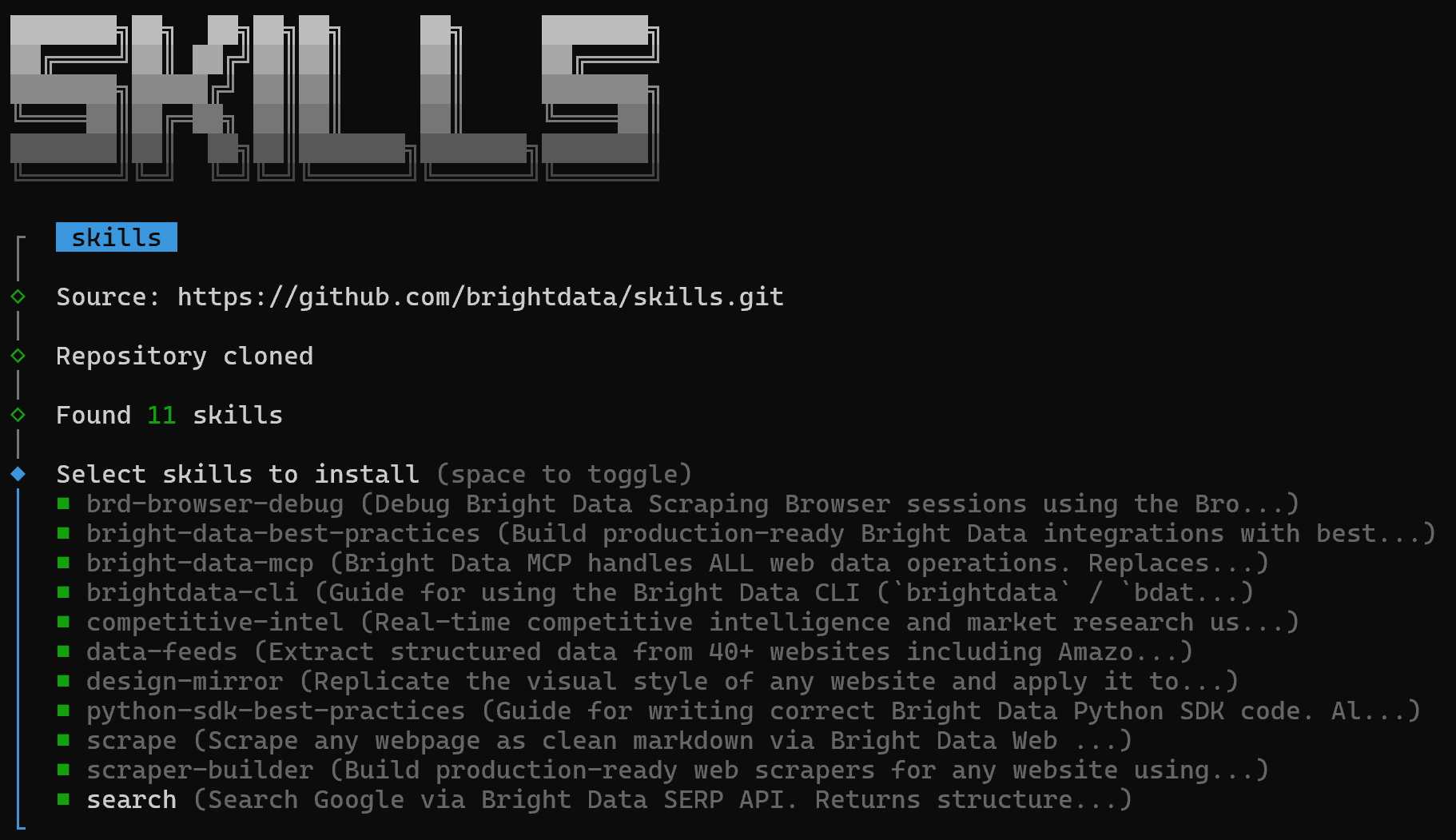
Para instalarlas todas, activa cada skill usando la barra espaciadora, luego presiona Enter.
A continuación, selecciona el alcance de instalación (se recomienda a nivel de proyecto) y continúa:

Finalmente, se te mostrarán las secciones “Resumen de Instalación” y “Evaluación de Riesgos de Seguridad”. Revísalas y presiona Enter para confirmar.
Una vez completado, recibirás un mensaje de confirmación final como este:
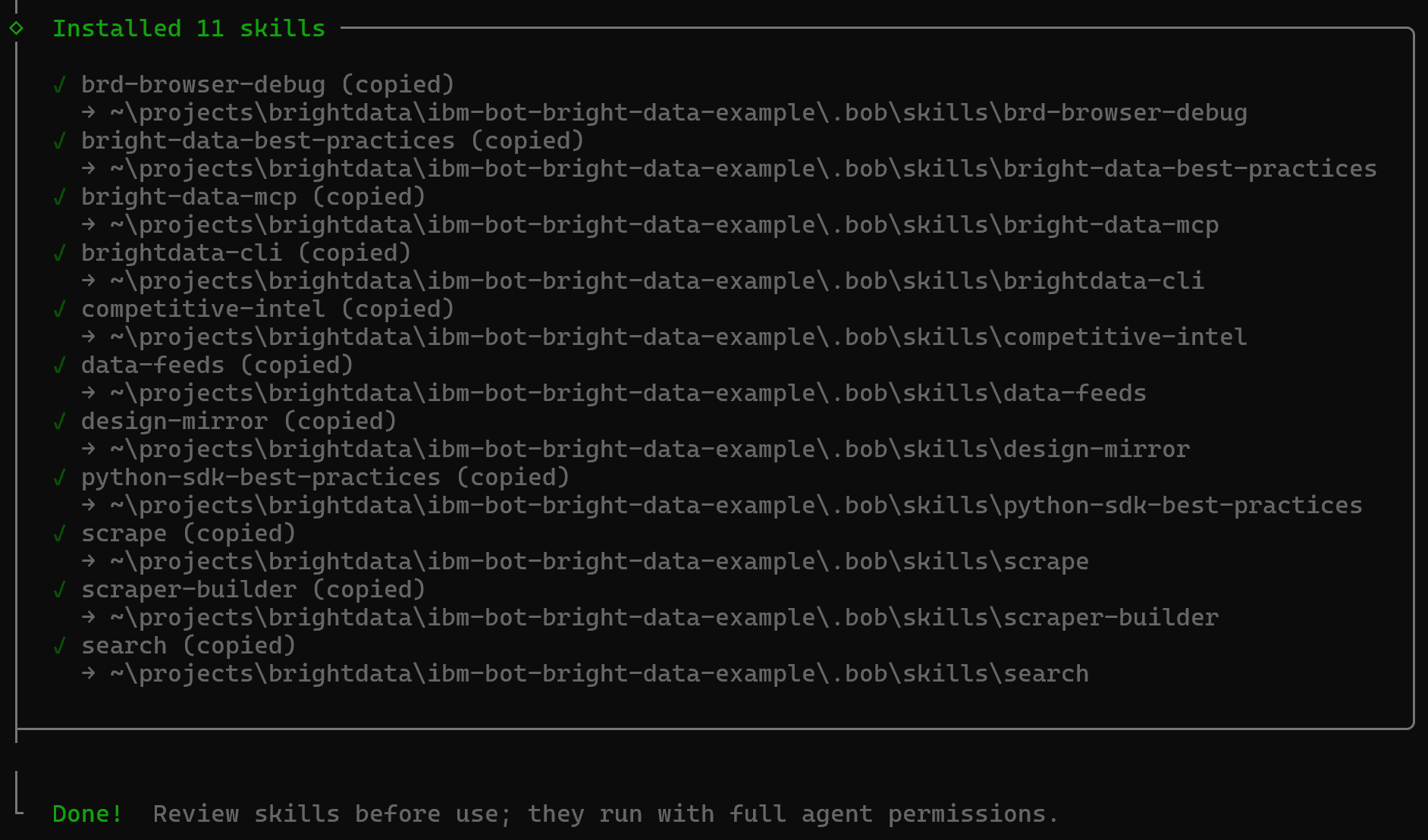
Las Bright Data skills se añadirán a tu proyecto bajo el directorio .bob/skills:
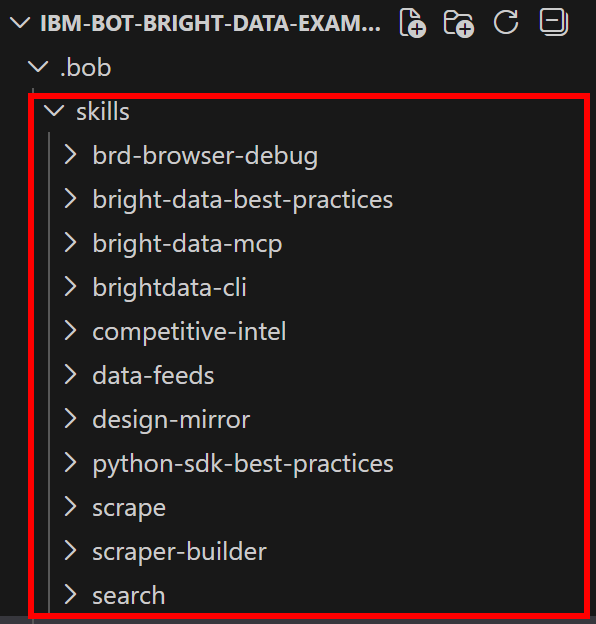
¡Misión cumplida! Las Bright Data skills están ahora instaladas y disponibles en IBM Bob.
Al momento de redactar esto, no hay una sección dedicada para ver las skills disponibles en IBM Bob. ¡Así que pasemos directamente a poner esta configuración en práctica!
IBM Bob + Bright Data para una Experiencia de Agente de Codificación IA Mejorada
Ahora tienes Bright Data integrado en IBM Bob a través de MCP y skills. ¡Es hora de ver qué permite esta configuración en la práctica! Recorreremos un ejemplo concreto del mundo real, aunque muchos otros casos de uso son posibles.
Imagina que deseas poblar una tabla products en tu base de datos con datos del mundo real. El objetivo es descubrir los productos más vendidos en Amazon para una categoría determinada, extraer sus datos y utilizarlos para poblar tu base de datos.
En lugar de buscar productos manualmente y recopilar los datos tú mismo, delega la tarea completa a tu asistente de codificación.
Primero, establece el agente de codificación en modo “Avanzado”:
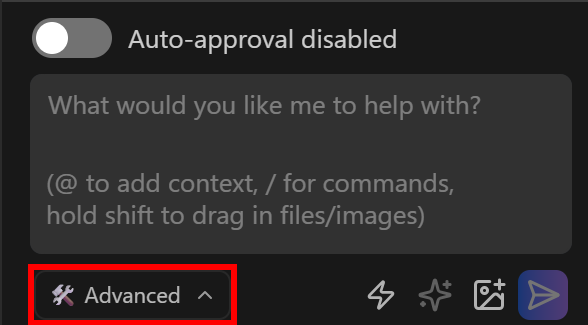
Esto le dará la capacidad de crear y modificar archivos.
Luego, ejecuta un prompt como este:
Discover the Amazon Best Sellers page for electronics products. Then, visit the page and retrieve the top 5 products. For each product, scrape its data in a structured format. Populate a local JSON file with all the scraped data. Then, create a products.sql MySQL script to define a products table and populate it with that data.Nota: Un LLM independiente no podría completar esta tarea. Esto se debe a que requiere descubrimiento web, navegación y Scraping, capacidades que los modelos de IA no tienen por defecto. Para obtenerlas, debes conectar el modelo a la infraestructura de Bright Data a través de herramientas MCP y skills.
Ejecuta el prompt, y deberías ver algo como:
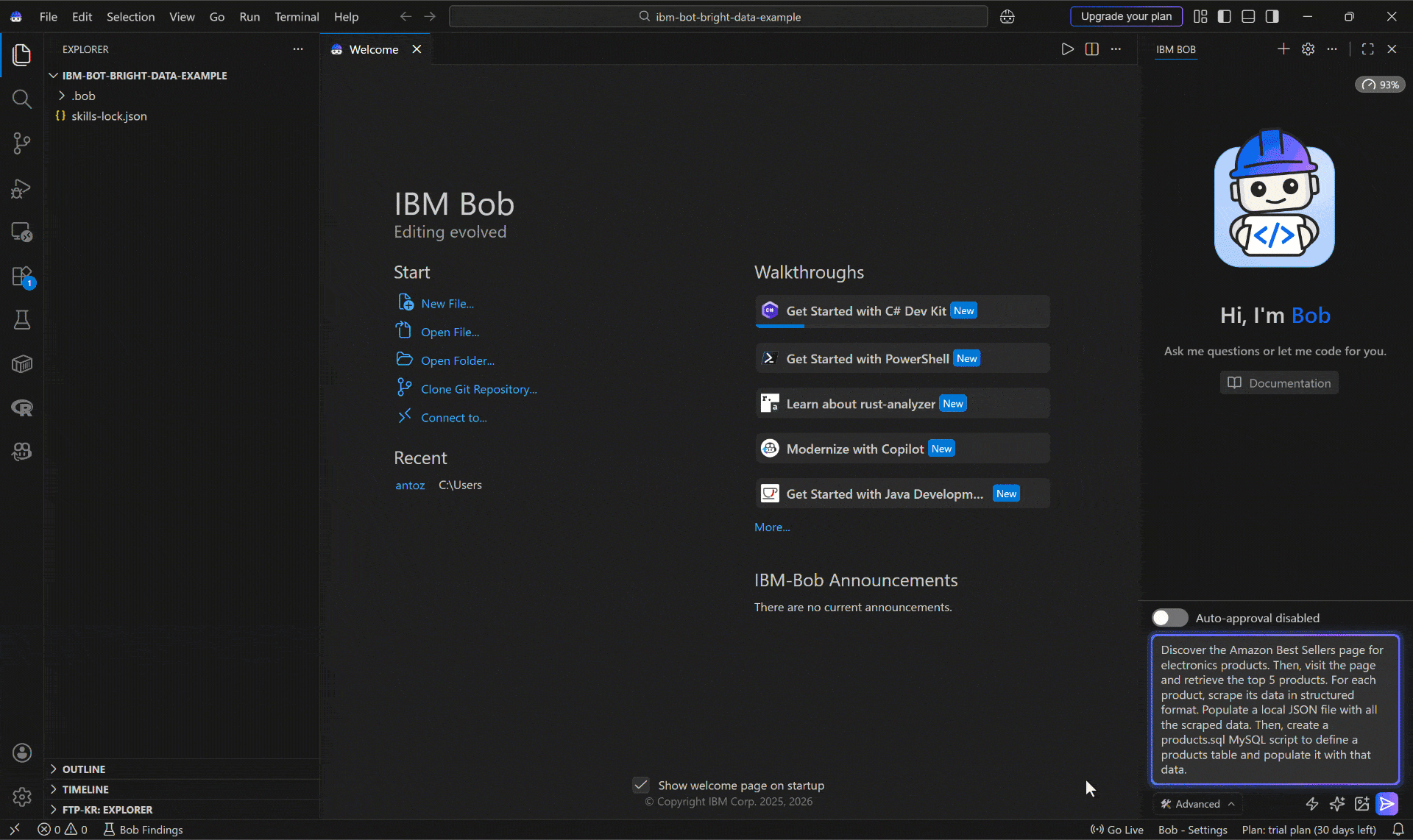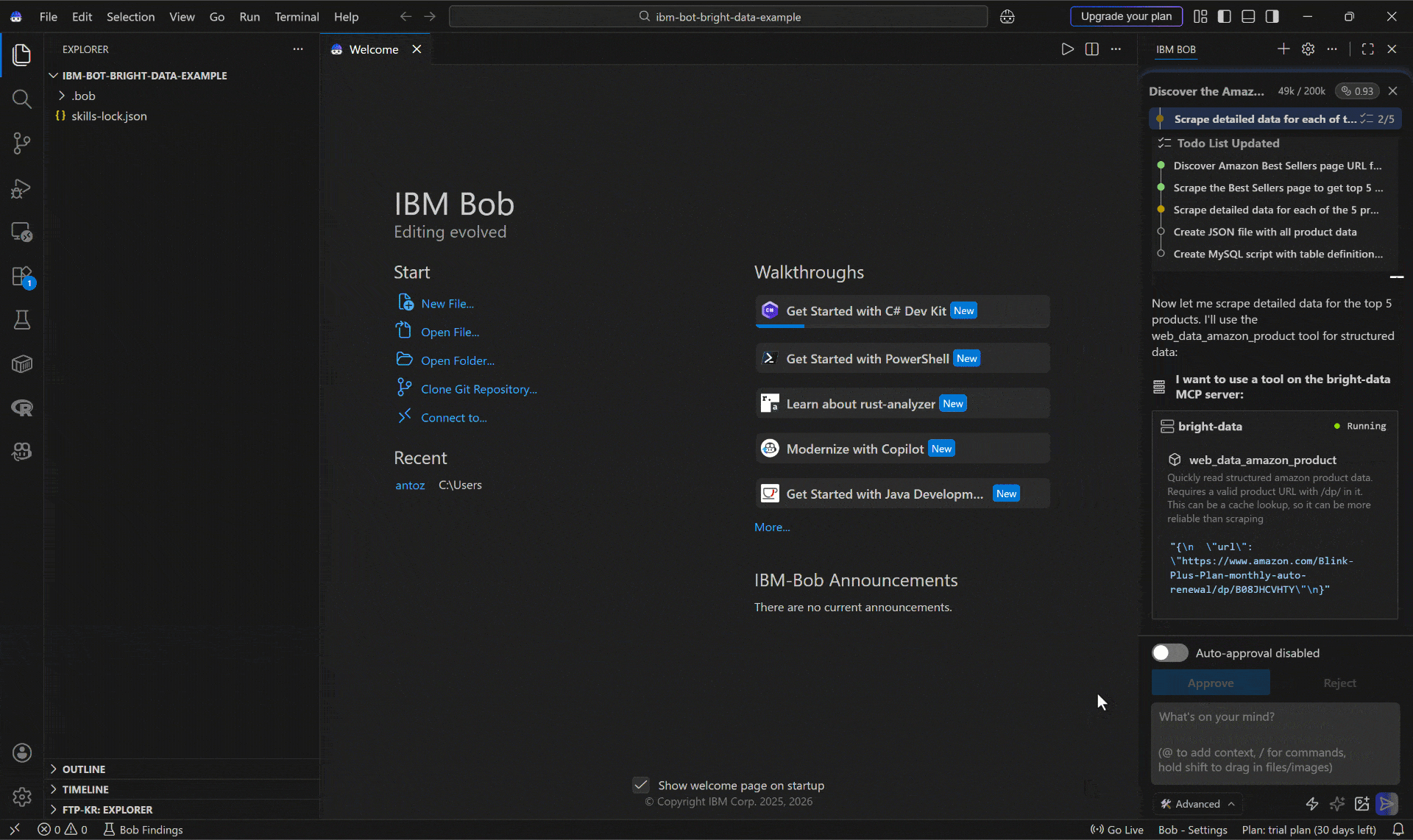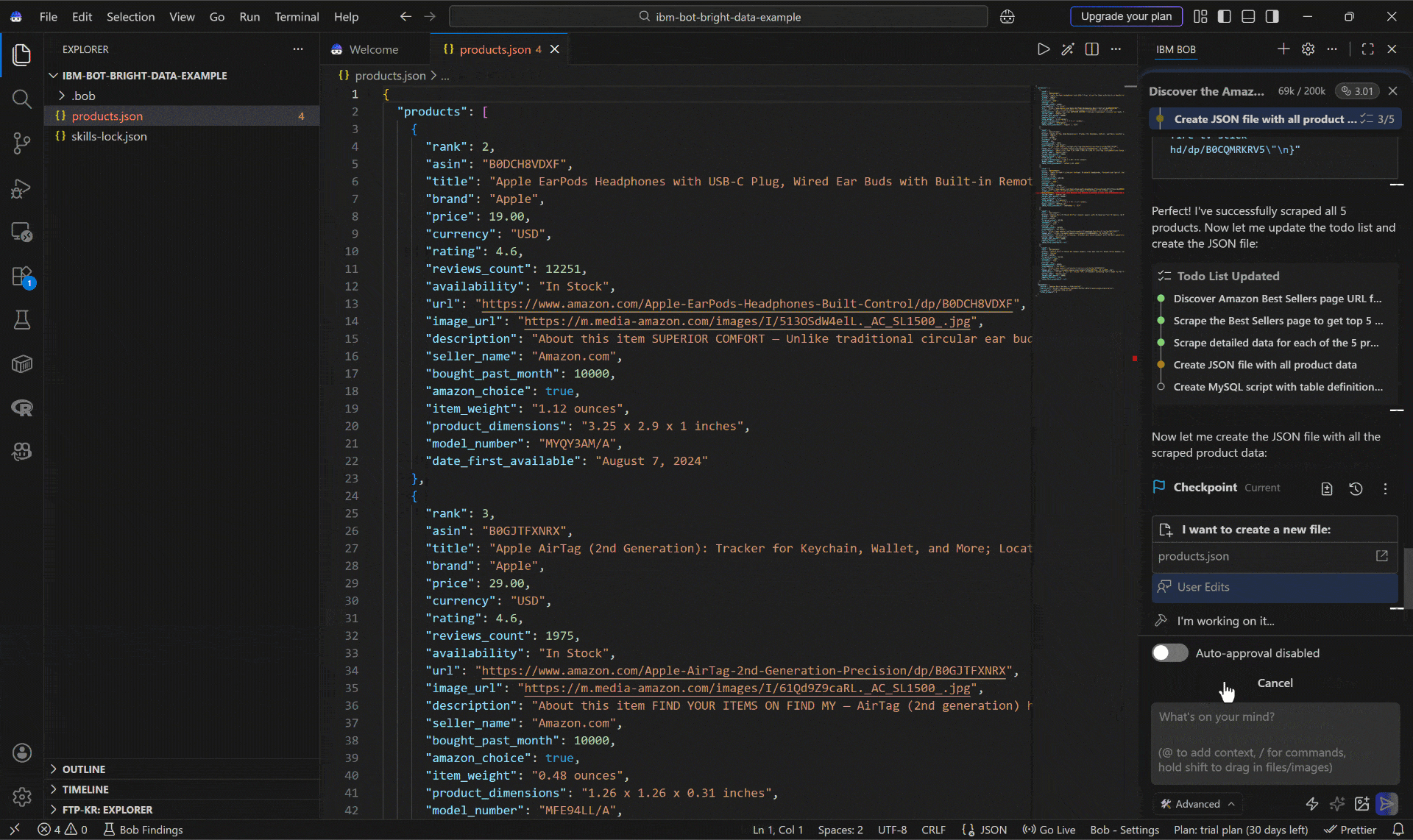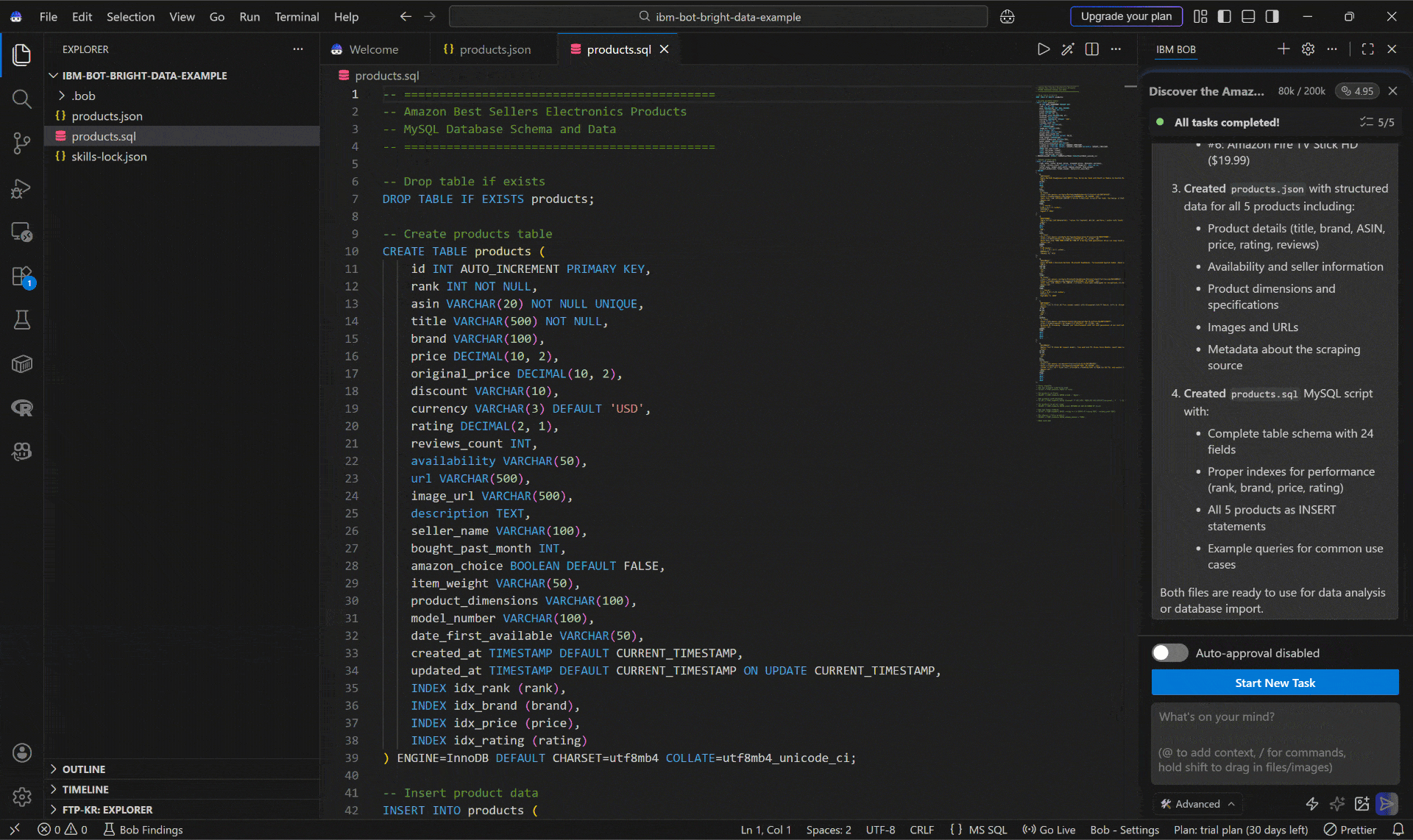
A continuación se muestra cómo el agente de codificación IBM Bob manejó la tarea:
- Usó la API Discover de Bright Data (a través de la herramienta
discover) para localizar la página de Mejores Vendedores de Electrónica de Amazon. - Extrajo la página descubierta (es decir,
https://www.amazon.com/Best-Sellers-Electronics/zgbs/electronics) como Markdown usando la herramientascrape_as_markdowna través de la Web Unlocker API. - Identificó los 5 productos principales de la página.
- Pasó cada URL de producto a la herramienta de Scraping
web_data_amazon_productdel Web MCP (que se conecta a la API Scraper de Amazon de Bright Data). - Generó un archivo
products.jsoncon los datos extraídos estructurados. - Crea un script
products.sqlcon el esquema MySQL y las declaracionesINSERT.
Echa un vistazo al archivo products.json generado:
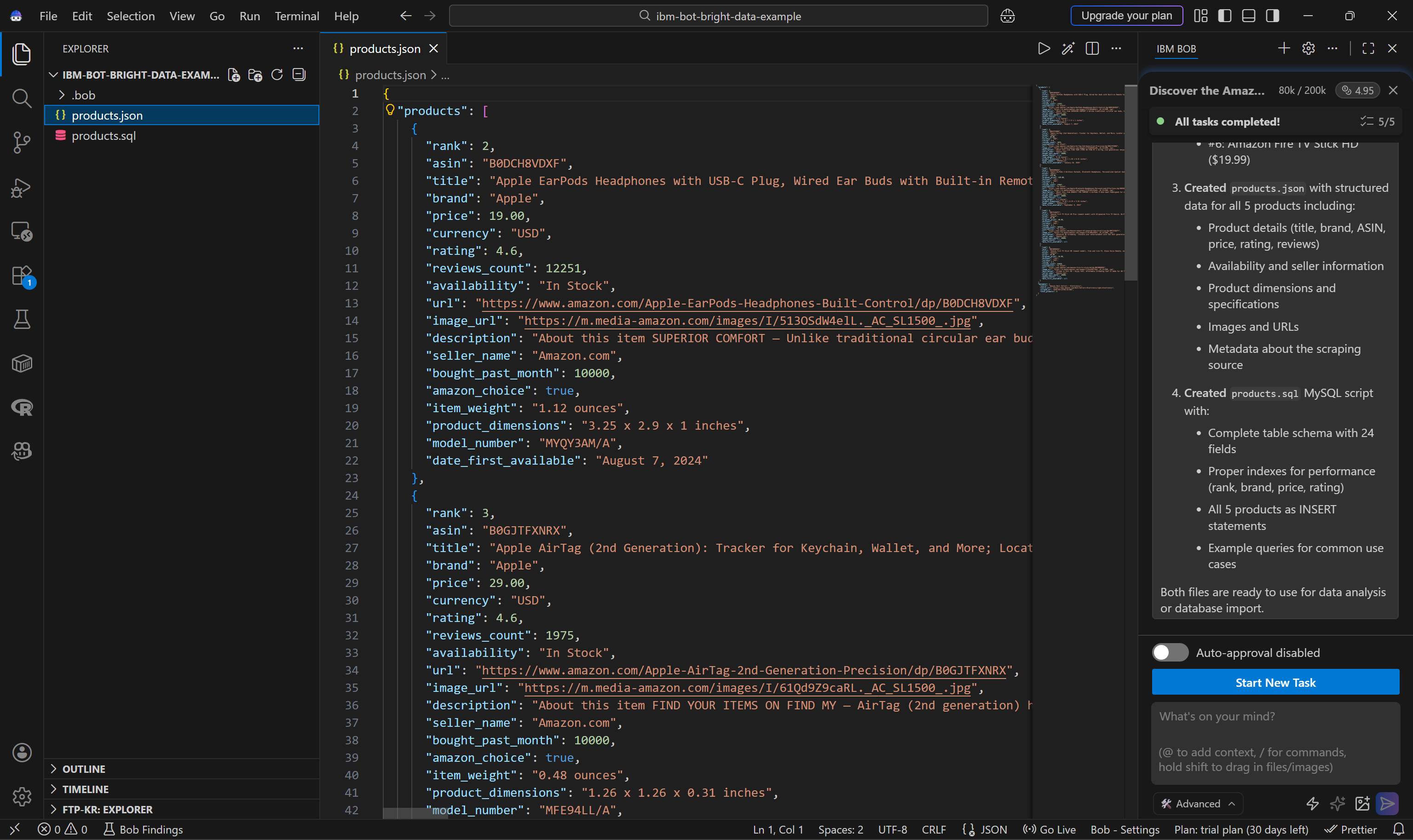
Esto incluye:
- Apple EarPods Headphones with USB-C Plug ($19.00)
- Apple AirTag (2nd Generation) ($29.00)
- Apple AirPods 4 Wireless Earbuds ($119.00)
- Amazon Fire TV Stick 4K Plus ($29.99)
- Amazon Fire TV Stick HD ($19.99)
Estos corresponden exactamente a los productos principales de la lista de Mejores Vendedores de Electrónica:
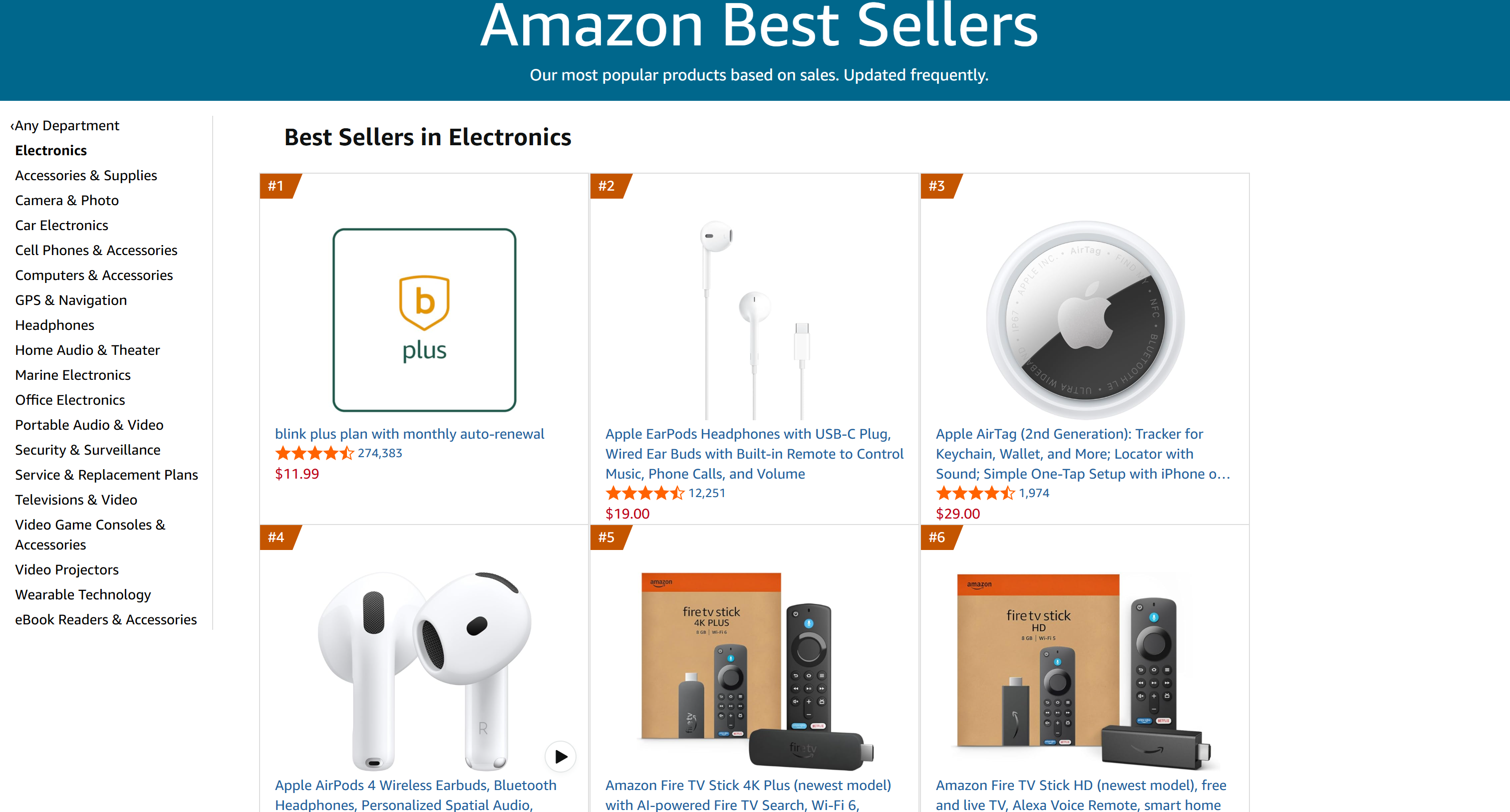
Observa que el elemento #1 fue excluido porque no era un producto real, sino una colocación promocional. La combinación de IA + Bright Data manejó correctamente este caso especial.
Esto también confirma que los datos no son alucinados. IBM Bob se apoya en la infraestructura de Bright Data para recuperar información real y actualizada. Extraer datos de productos de Amazon es notoriamente desafiante debido a las protecciones anti-bot (por ejemplo, CAPTCHA de Amazon), por lo que esta integración es tan poderosa.
El agente también genera un script products.sql:
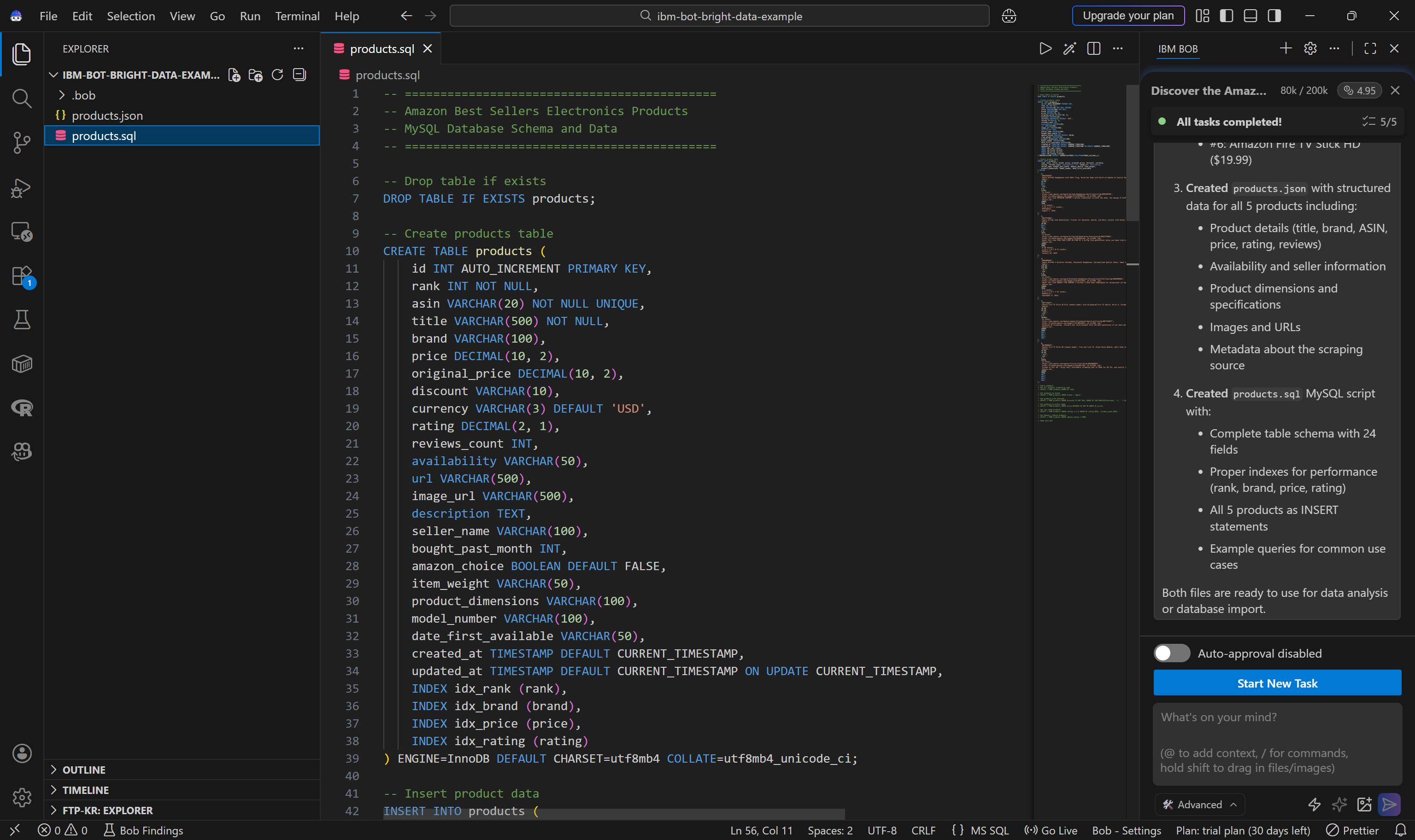
Puedes ejecutar fácilmente este script en tu base de datos para crear y poblar la tabla products.
¡Et voilà! Este sencillo ejemplo muestra claramente cuán versátil se vuelve IBM Bob cuando se combina con las capacidades de Bright Data.
Conclusión
En este artículo, entendiste qué aporta IBM Bob en cuanto al desarrollo de software impulsado por IA. En detalle, viste por qué y cómo extenderlo conectándolo a Bright Data a través de Web MCP y Agent Skills.
Esta integración equipa al agente de codificación IBM Bob con nuevas y poderosas capacidades, mejorando enormemente su efectividad. Estas incluyen búsqueda web, descubrimiento, extracción de datos estructurados, recuperación de datos web en tiempo real e interacciones web automatizadas.
Para flujos de trabajo aún más avanzados, puedes explorar la gama completa de servicios listos para IA en el ecosistema de Bright Data.
¡Crea una cuenta gratuita de Bright Data hoy y comienza a experimentar con nuestras herramientas de datos web aptas para IA!





