

Si eres vendedor o realizas un estudio de mercado, conocer el ASIN de un producto puede ayudarte a encontrar rápidamente productos exactos, analizar los listados de la competencia y mantenerte a la vanguardia en el mercado. Este artículo te mostrará métodos sencillos y eficaces para extraer ASIN de Amazon a gran escala. También descubrirás la solución de Bright Data, que puede acelerar considerablemente este proceso.
¿Qué es un ASIN en Amazon?
Un ASIN es un código de 10 caracteres que combina letras y números (por ejemplo, B07PZF3QK9). Amazon asigna este código único a cada producto de su catálogo, desde libros hasta productos electrónicos y ropa.
Hay dos formas sencillas de encontrar el ASIN de cualquier producto:
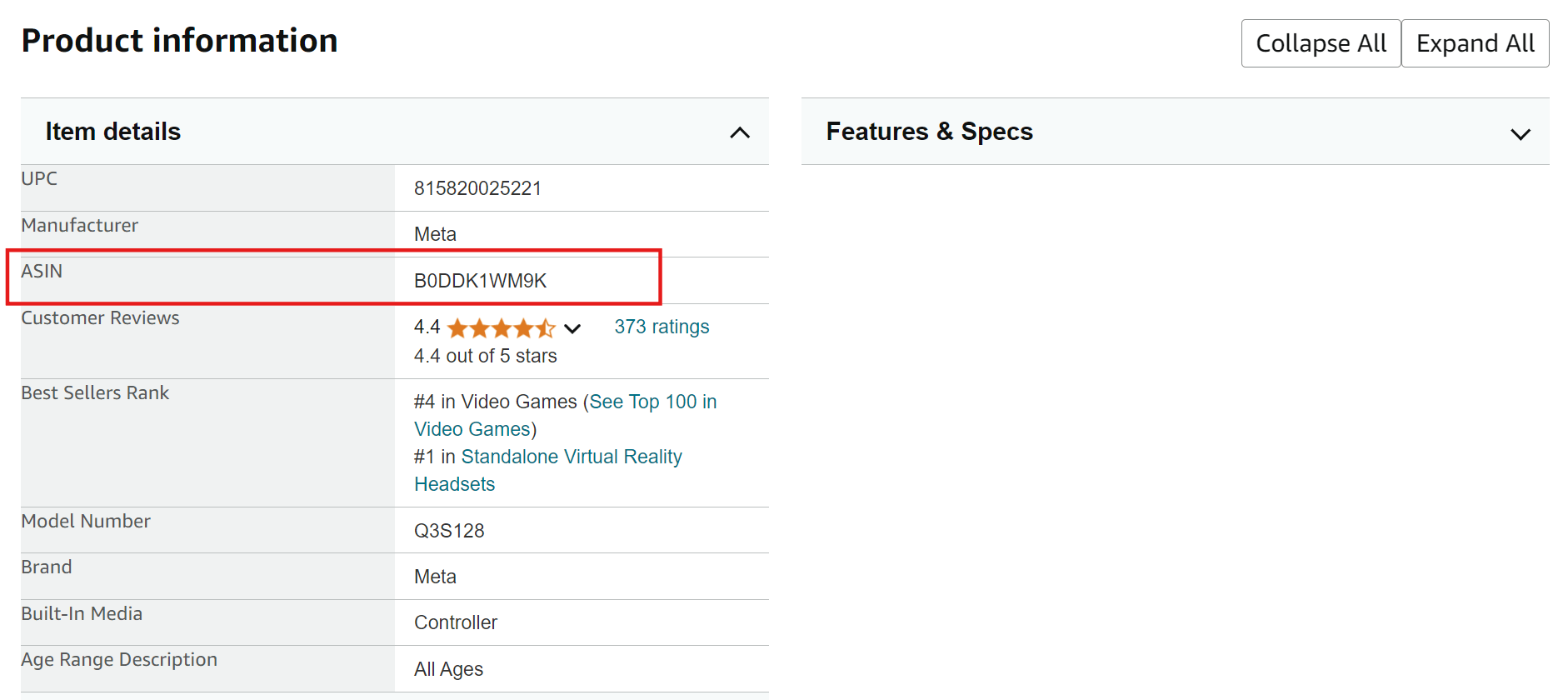
1. Mira la URL del producto: el ASIN aparece justo después de «/dp/» en la barra de direcciones.
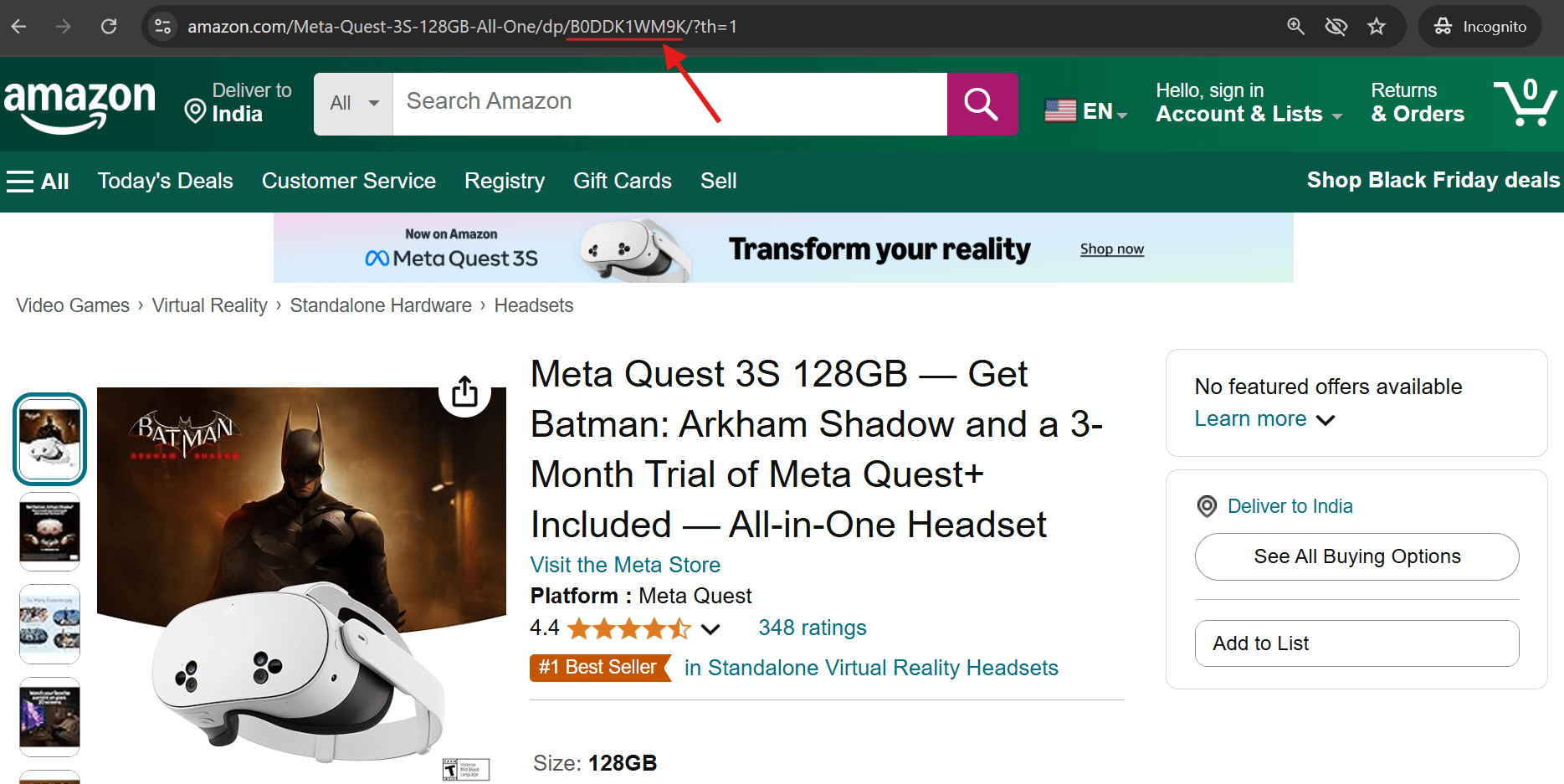
2. Desplázate hacia abajo hasta la sección de información del producto en cualquier lista de Amazon: allí encontrarás el ASIN.
Cómo extraer ASIN de Amazon
Extraer datos de Amazon puede parecer sencillo a primera vista, pero resulta bastante complicado debido a sus robustas medidas antiescraping. Amazon se protege activamente contra la recopilación automatizada de datos mediante varios métodos sofisticados:
- Desafíos CAPTCHA
- Errores HTTP 503 que bloquean el acceso a las páginas solicitadas
- Cambios frecuentes en el diseño del sitio web que rompen la lógica de parseo
Aquí hay una captura de pantalla de un error HTTP 503 típico provocado por Amazon:

Puedes probar este sencillo script para extraer los ASIN de Amazon:
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: try: print(f"Obteniendo URL: {url}") response = self.session.get( url, impersonate="chrome120", timeout=30) print(f"Código de estado HTTP: {response.status_code}") if response.status_code == 200: # Comprueba si hay indicadores de bloqueo en la respuesta. if "Sorry" not in response.text: return response.text else: print("Sorry, request blocked!") else: print(f"Unexpected HTTP status code: {response.status_code}") except Exception as e: print(f"Se produjo una excepción durante la obtención: {e}") return None def extract_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) new_asins = set() for container in containers: asin = container.get("data-asin") if asin and asin.strip(): new_asins.add(asin) return new_asins def save_to_csv(self, keyword: str): if not self.asins: print("No hay ASIN que guardar") return # Crear directorio de resultados si no existe os.makedirs("results", exist_ok=True) # Generar nombre de archivo csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # Guardar como CSV with open(csv_path, 'w') as f: f.write("asinn") for asin in sorted(self.asins): f.write(f"{asin}n") print(f"ASIN guardados en: {csv_path}") async def main(): scraper = AsinScraper() keyword = "laptop" max_pages = 5 for page in range(1, max_pages + 1): print(f"Scraping page {page}...") html = await scraper.fetch_page(scraper.create_url(keyword, page)) if not html: print(f"Failed to fetch page {page}") break new_asins = Scraper.extract_asins(html) if new_asins: Scraper.asins.update(new_asins) print(f"Found {len(new_asins)} ASINs on page { page}. Total de ASIN: {len(Scraper.asins)}") else: print("No se han encontrado más ASIN. Finalizando el rastreo.") break # Guardar los resultados en CSV Scraper.save_to_csv(keyword) if __name__ == "__main__": asyncio.run(main())
Entonces, ¿cuál es la solución para extraer ASIN de Amazon? El enfoque más fiable consiste en utilizar Proxies residenciales de los mejores proveedores de proxies junto con encabezados HTTP adecuados.
Uso de los proxies de Bright Data para extraer ASIN de Amazon
Bright Data es un proveedor líder de proxies con una red global de proxies. Ofrece diferentes tipos de proxies tanto en servidores compartidos como privados, lo que permite cubrir una amplia gama de casos de uso. Estos servidores pueden enrutar el tráfico utilizando los protocolos HTTP, HTTPS y SOCKS.
¿Por qué elegir Bright Data para el rastreo de Amazon?
- Amplia red de IP: acceso a 400M+ monthly IP en 195 países
- Segmentación geográfica precisa: diríjase a ciudades, códigos postales o incluso operadores específicos
- Múltiples tipos de proxies: elija entre proxies residenciales, de centro de datos, móviles o de ISP.
- Alta fiabilidad: tasa de éxito del 99,9 % con un tiempo de actividad opcional del 100 %.
- Escalabilidad flexible: opciones de pago por uso disponibles para empresas de todos los tamaños
Configuración de Bright Data para el scraping de Amazon
Si desea utilizar los Proxies de Bright Data para el scraping de ASIN de Amazon, siga estos sencillos pasos:
Paso 1: Regístrese en Bright Data
Visite el sitio web de Bright Data y cree una cuenta. Si ya tiene una cuenta, continúe con el siguiente paso.
Paso 2: Cree una nueva zona de Proxy
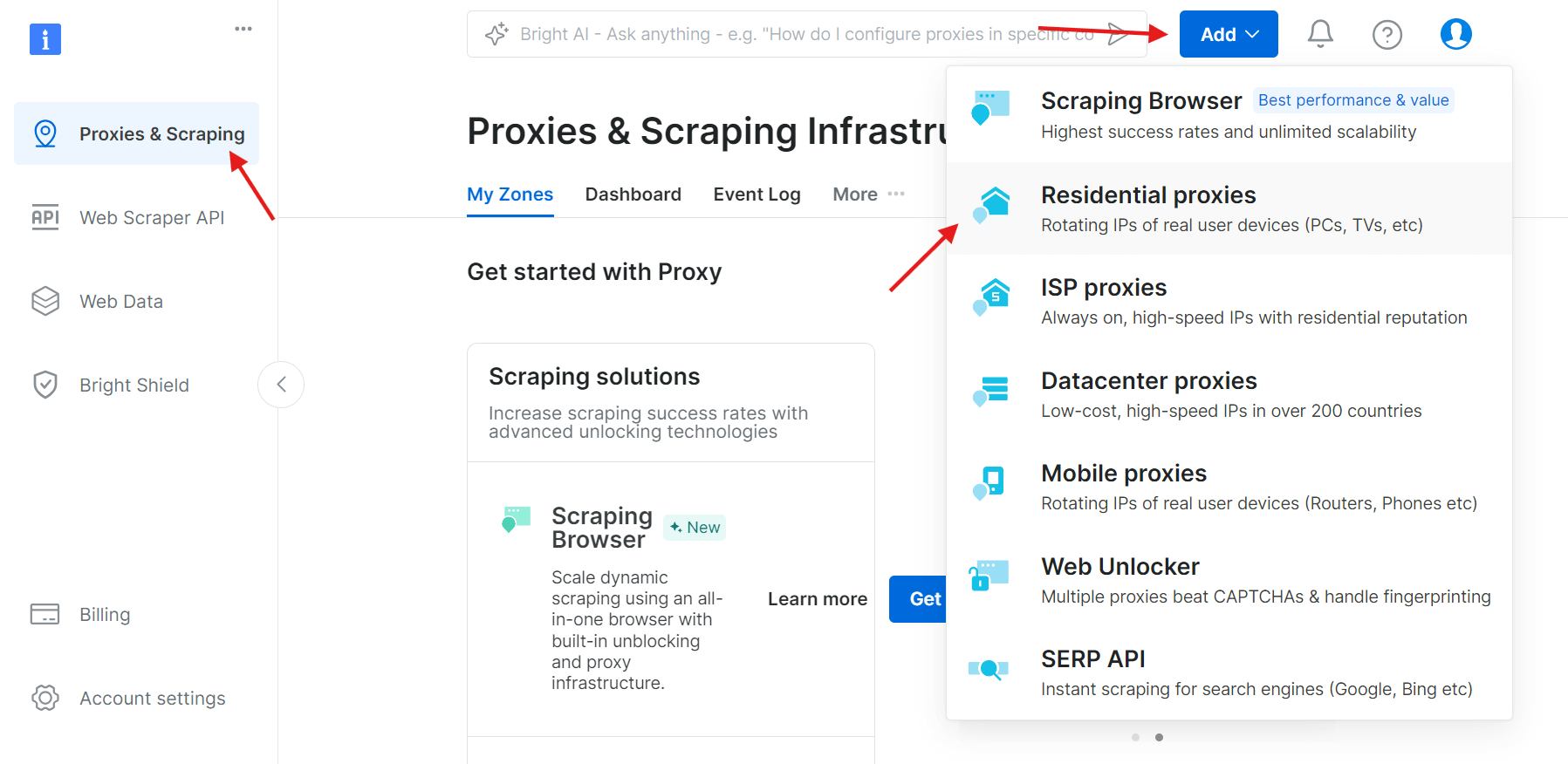
Inicie sesión, vaya a la sección «Proxy & Infraestructura de scraping » (Infraestructura de proxies y scraping ) y haga clic en «Add» (Añadir) para crear una nueva zona de proxy. Seleccione «Proxies residenciales», que son la mejor opción para evitar las restricciones antiscraping, ya que utilizan direcciones IP de dispositivos reales.
Paso 3: Configure los ajustes del Proxy
Elija las regiones o países para navegar. Asigne un nombre adecuado a su Zona (por ejemplo, «asin_scraping»).
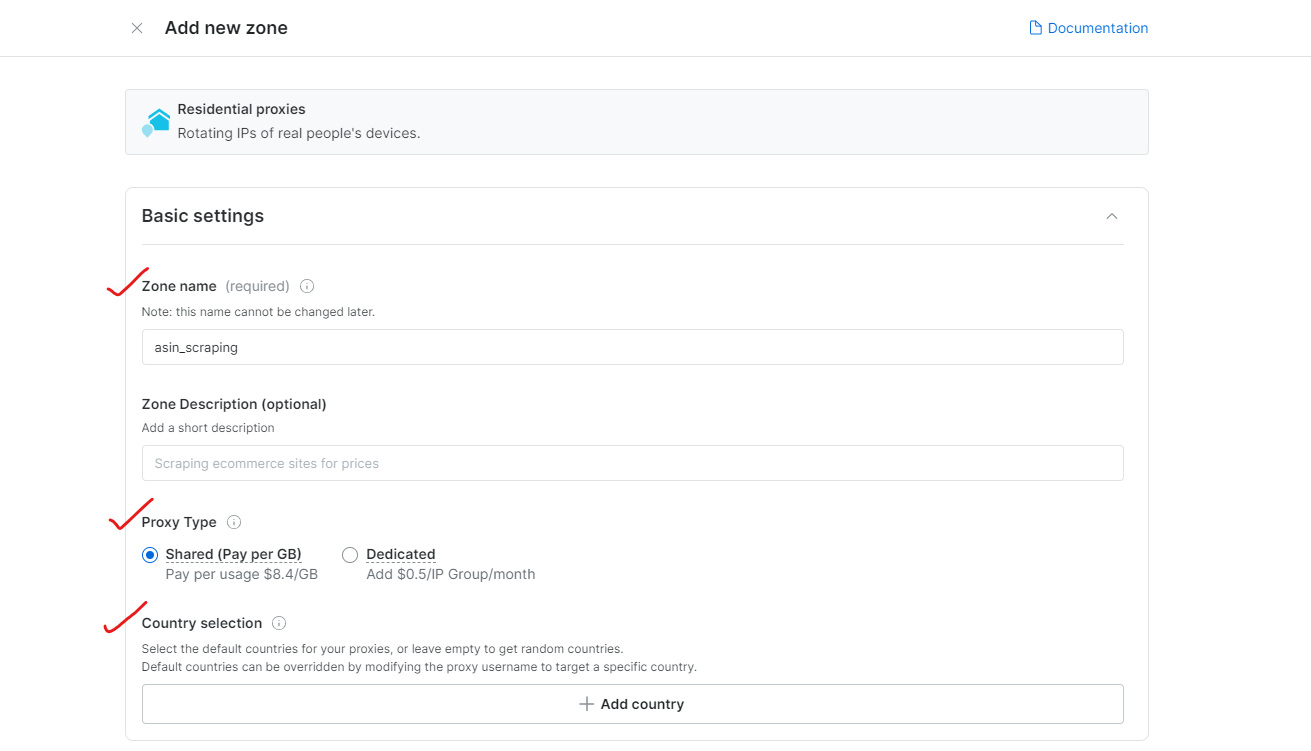
Bright Data permite una geolocalización precisa, hasta la ciudad o el código postal.
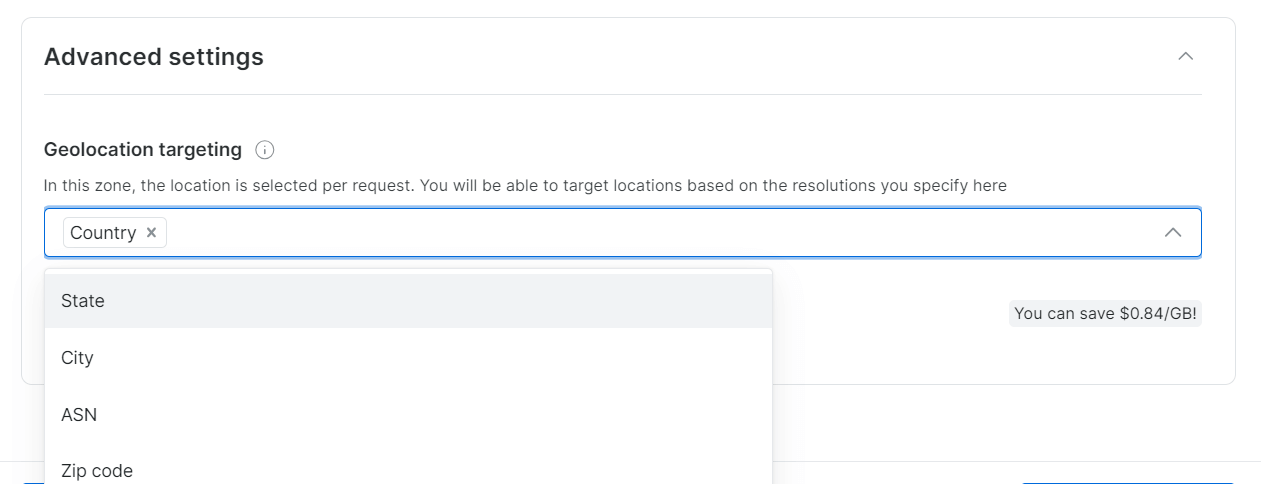
Paso 4: Complete la Verificación KYC
Para obtener acceso completo a los Proxies residenciales de Bright Data, complete el proceso de Verificación KYC.
Paso 5: Comience a utilizar los Proxies
Una vez creada la zona de Proxy, verá las credenciales (host, puerto, nombre de usuario, contraseña) para empezar a rastrear.
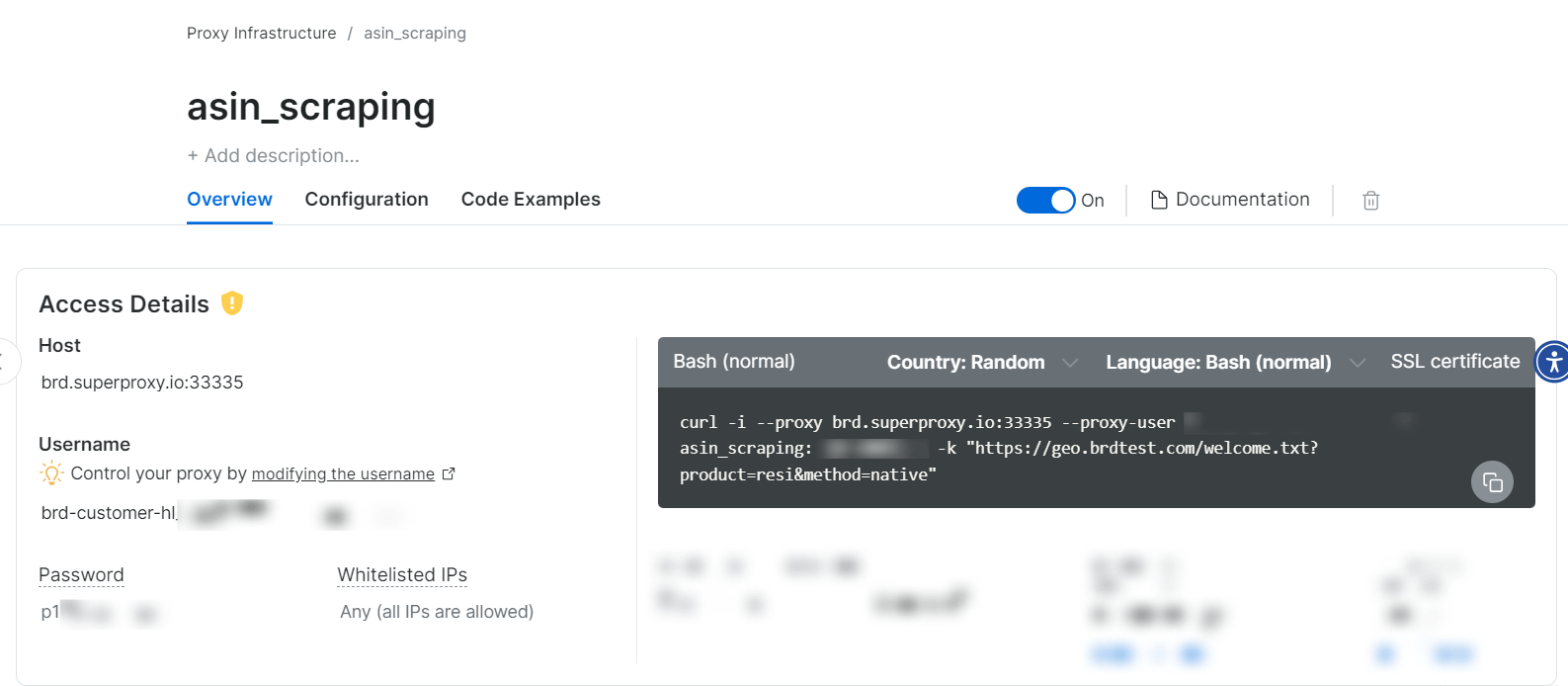
Sí, ¡así de sencillo!
Implementación del Scraper
Paso 1: Configurar los encabezados del navegador
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
Paso 2: Configuración de los ajustes del Proxy
proxy_config = {
"username": "TU_NOMBRE_DE_USUARIO",
"password": "TU_CONTRASEÑA",
"server": "brd.superproxy.io:33335",
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"
Paso 3: Realizar solicitudes
Realiza una solicitud utilizando encabezados y Proxies con la biblioteca curl_cffi:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)
Nota: La biblioteca curl_cffi es una excelente opción para el Scraping web, ya que ofrece capacidades avanzadas de suplantación de navegador que superan a la biblioteca de solicitudes estándar.
Paso 4: Ejecutar el Scraper
Para ejecutar el Scraper, deberá configurar las palabras clave de destino. A continuación se muestra un ejemplo:
keywords = [
"cafetera",
"escritorio de oficina",
"cámara de CCTV"
]
max_pages = None # Establecer en None para todas las páginas
Encuentre el código completo aquí.
El Scraper generará los resultados en un archivo CSV que contiene:
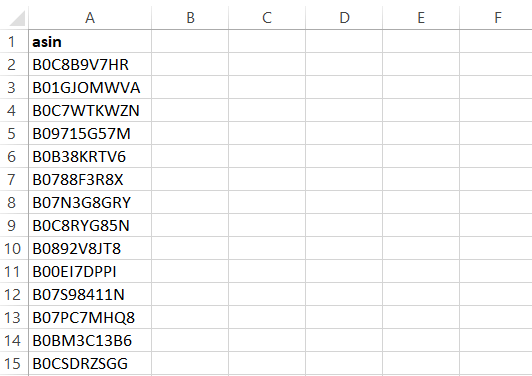
Uso de la API Amazon Scraper de Bright Data para extraer ASIN
Aunque el rastreo basado en proxies funciona, el uso de la API Amazon Scraper de Bright Data ofrece ventajas significativas:
- Sin gestión de infraestructura: no hay que preocuparse por los Proxies, las rotaciones de IP o los captchas
- Rastreo por ubicación geográfica: rastrea desde cualquier región geográfica
- Integración sencilla: implementación en cuestión de minutos con cualquier lenguaje de programación
- Múltiples opciones de entrega de datos:
- Exportación a Amazon S3, Google Cloud, Azure, Snowflake o SFTP.
- Obtenga datos en formatos JSON, NDJSON, CSV o .gz.
- Cumplimiento GDPR y la CCPA: garantiza el cumplimiento de la privacidad para un Scraping web ético
- 20 llamadas API gratuitas: pruebe el servicio antes de comprometerse
- Asistencia 24/7: asistencia dedicada para ayudarle con cualquier pregunta o problema relacionado con la API
Configuración de la API de Amazon Scraper
La configuración de la API es sencilla y se puede completar en unos pocos pasos.
Paso 1: Acceda a la API
Vaya a la API de Web Scraper y busque «amazon products search» en las API disponibles:
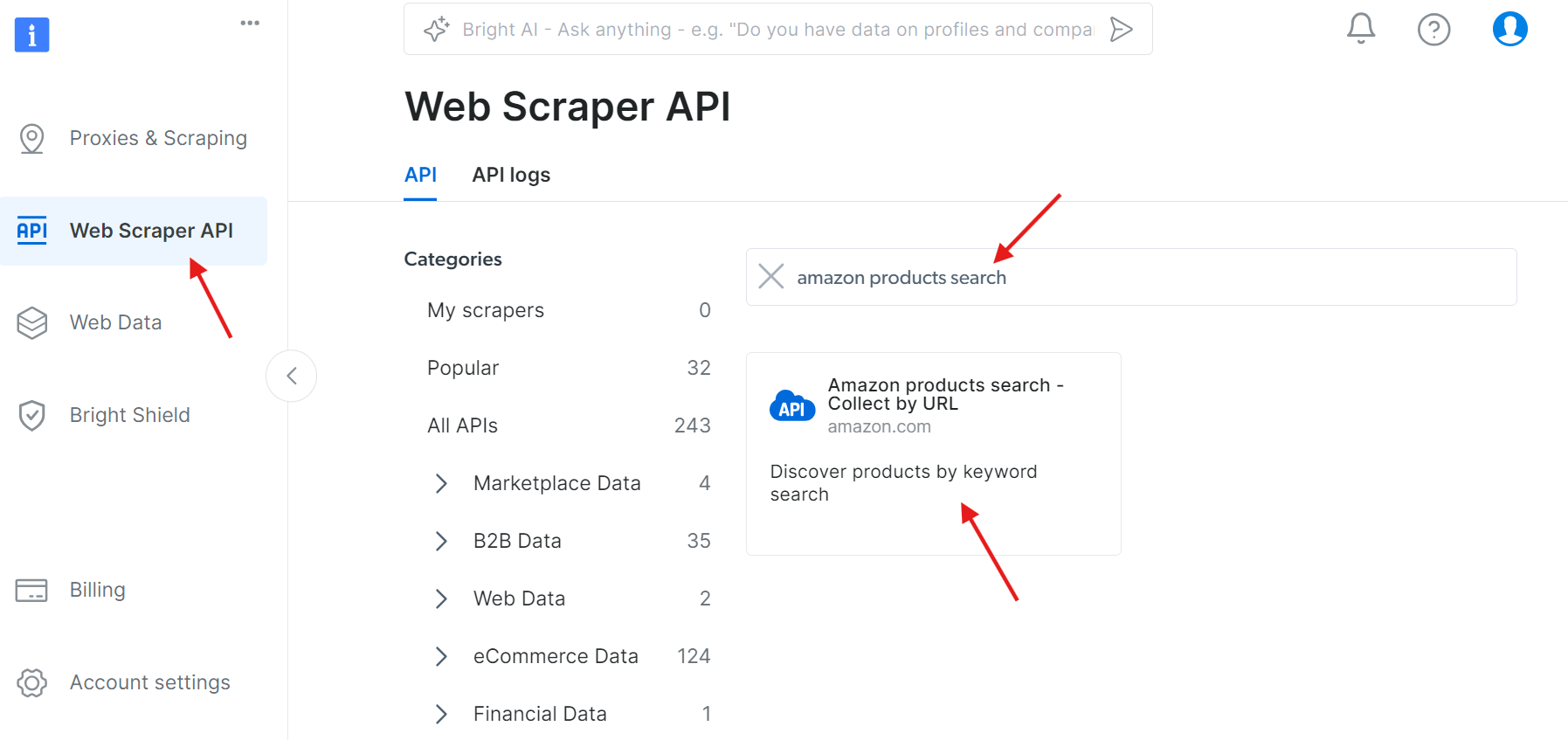
Haga clic en «Start setting an API call» (Empezar a configurar una llamada a la API):
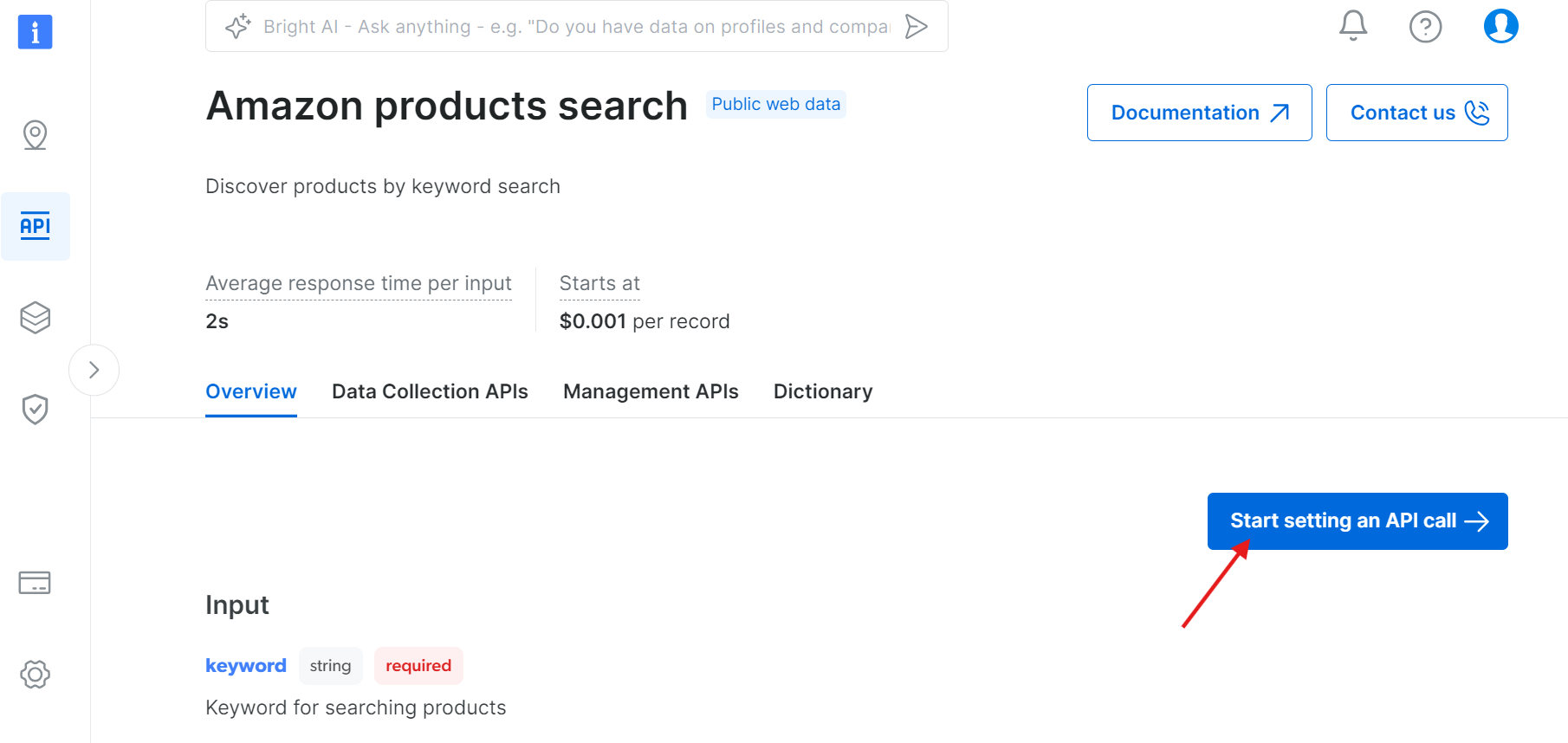
Paso 2: Obtenga su token de API
Haga clic en «Obtener token API»:
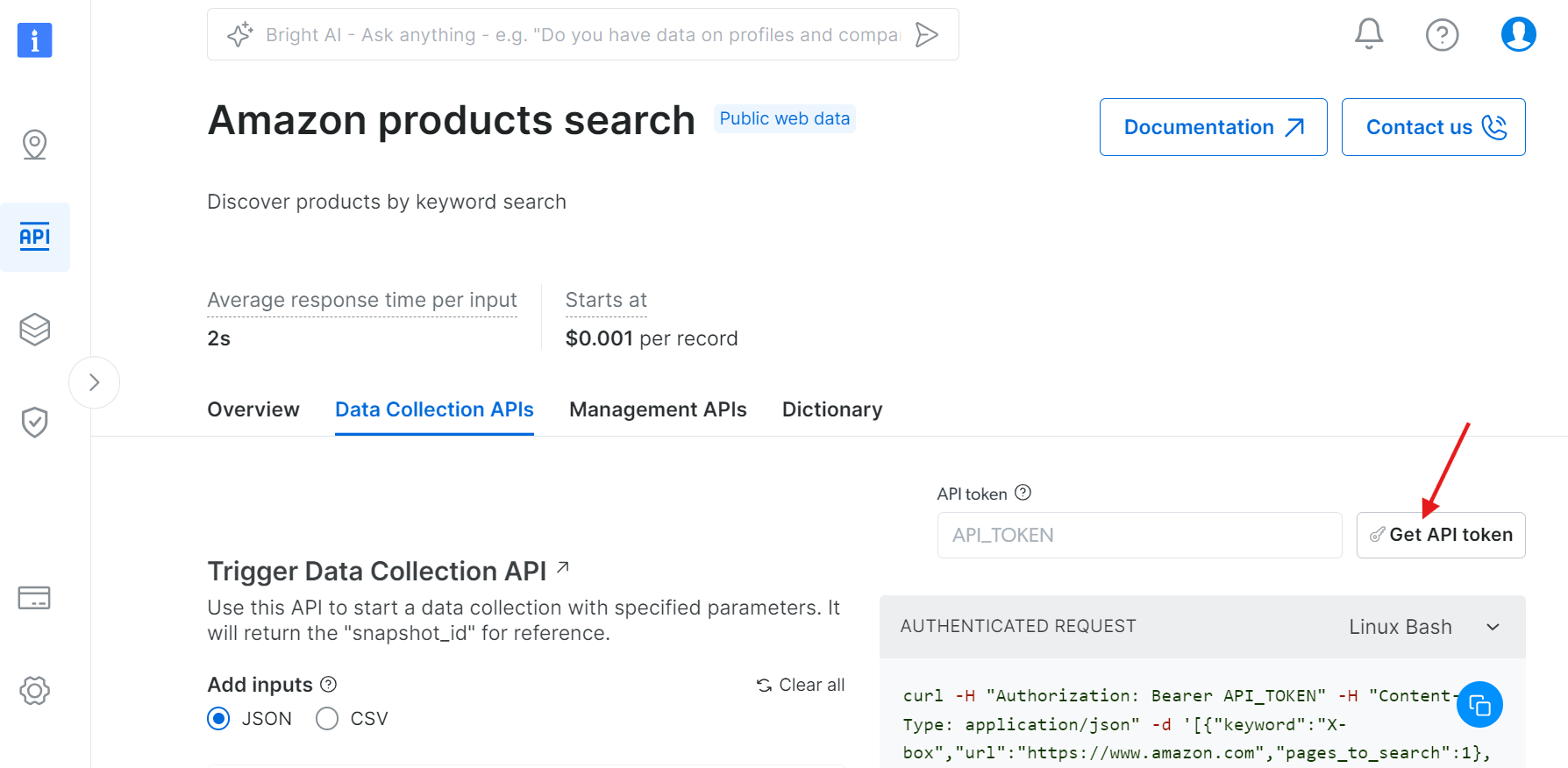
Seleccione «Añadir token»:
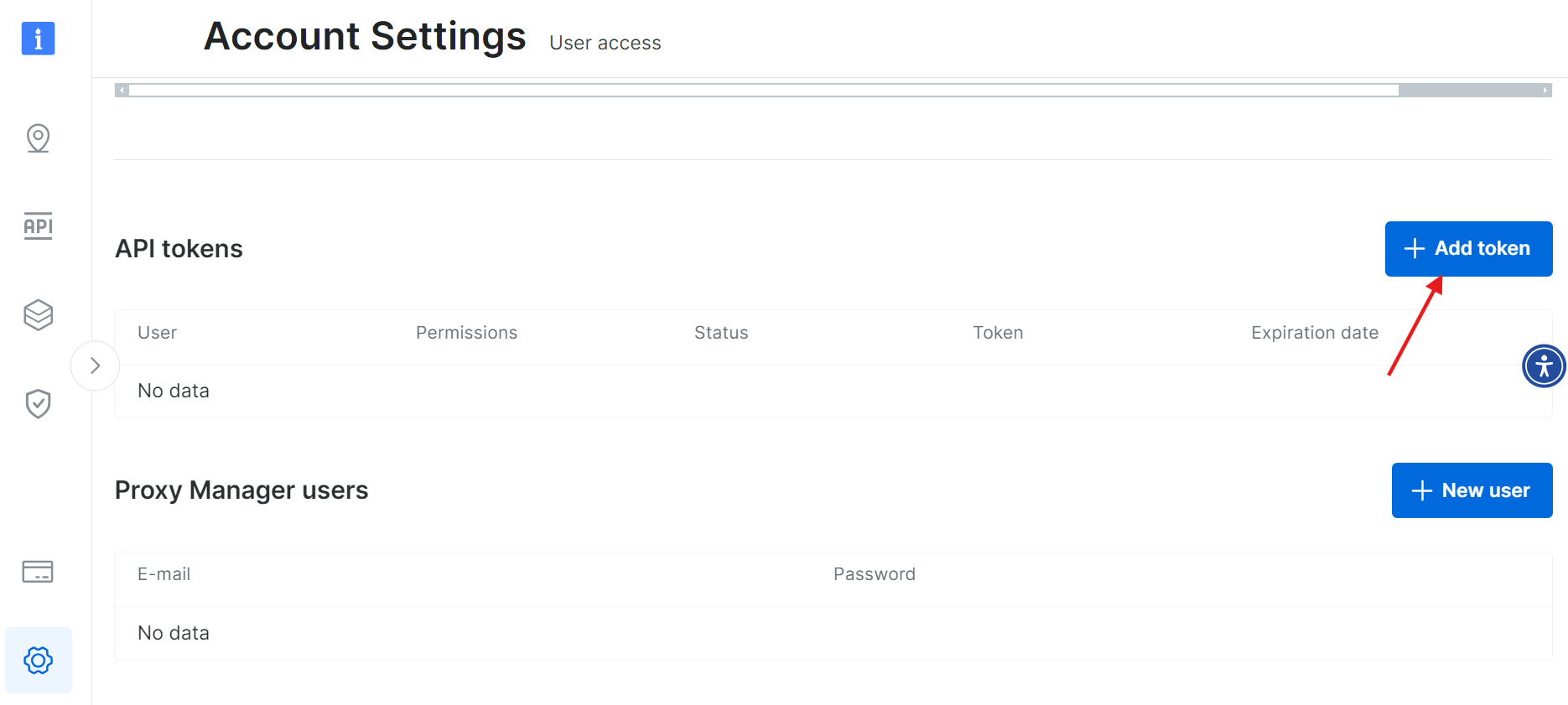
Guarde su nuevo token API de forma segura:
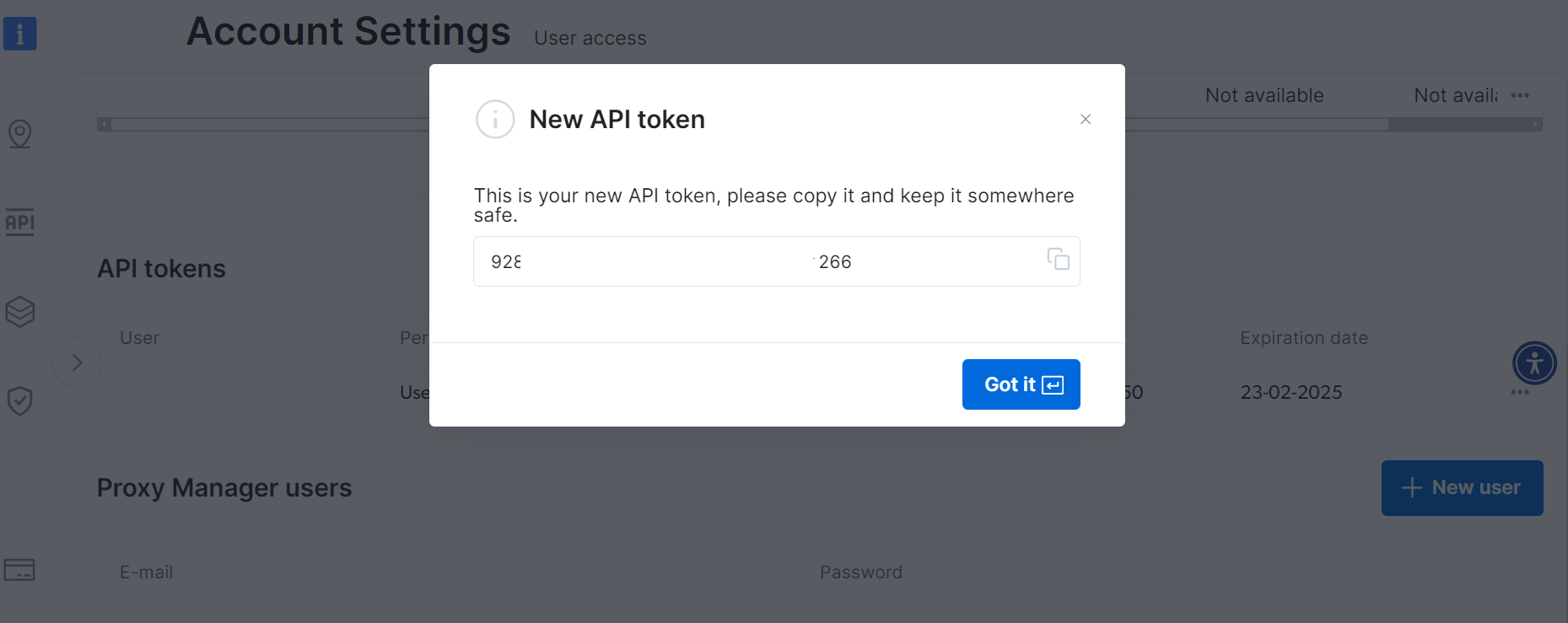
Paso 3: Configure la recopilación de datos
En la pestaña «API de recopilación de datos»:
- Especifique las palabras clave para la búsqueda de productos
- Establezca los dominios de Amazon de destino
- Defina el número de páginas que se van a rastrear
- Filtros adicionales (opcional)
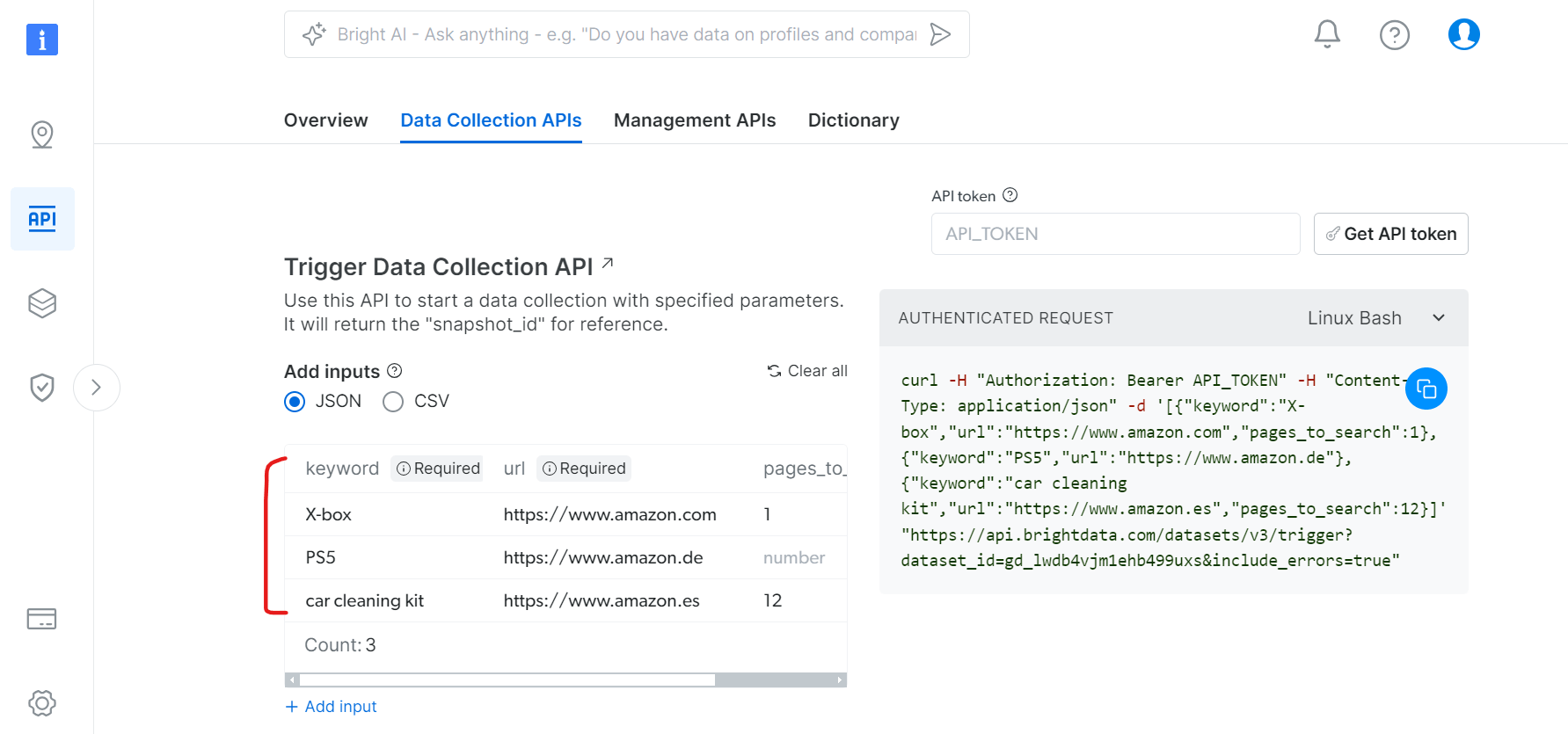
Uso de la API con Python
A continuación se muestra un ejemplo de script en Python para activar la recopilación de datos y recuperar los resultados:
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = "processing"
FAILED = "failed"
TIMEOUT = "timeout"
class BrightDataAmazonScraper:
def __init__(self, api_token: str, dataset_id: str):
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/conjuntos-de-datos/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# Configurar el registro con formato personalizado
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # Formato simplificado para mostrar solo mensajes
)
self.logger = logging.getLogger(__name__)
# Configurar sesión con estrategia de reintento
self.session = self._create_session()
# Seguimiento del progreso
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""Crear una sesión con estrategia de reintento"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""Activar la recopilación de datos para los Conjuntos de datos especificados"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
try:
response = self.session.post(
trigger_url,
headers=self.headers,
json=Conjuntos de datos
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Inicializando la recopilación de datos de Amazon...")
return snapshot_id
else:
self.logger.error("No se puede inicializar la recopilación de datos.")
return None
except requests.exceptions.RequestException as e:
self.logger.error(f"Collection initialization failed: {str(e)}")
return None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""Comprueba el estado actual de una instantánea"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
try:
response = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
except requests.exceptions.RequestException:
return SnapshotStatus.FAILED, None
def wait_for_snapshot_data(
self,
snapshot_id: str,
timeout: Optional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Optional[Dict]:
"""Esperar los datos de la instantánea con una salida mínima en la consola"""
start_time = datetime.now()
current_interval = check_interval
attempts = 0
progress_shown = False
while True:
attempts += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("Data collection exceeded time limit.")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"¡Recopilación de datos de Amazon completada con éxito!")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("Se ha producido un error en la recopilación de datos.")
return None
elif status == SnapshotStatus.PROCESSING:
# Mostrar el indicador de progreso solo cada 30 segundos
current_time = time.time()
if not progress_shown:
self.logger.info("Recopilando datos de Amazon...")
progreso_mostrado = True
elif hora_actual - self.última_actualización_progreso >= 30:
self.logger.info("Recopilación de datos en curso...")
self.última_actualización_progreso = hora_actual
if callback:
callback(intentos, (datetime.now() -
hora_inicio).total_segundos())
time.sleep(current_interval)
current_interval = min(current_interval * 1.5, max_interval)
def store_data(self, data: Dict, filename: str = "amazon_data.json") -> None:
"""Almacena los datos recopilados en un archivo JSON"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"Datos guardados correctamente en {filename}")
except IOError as e:
self.logger.error(f"Error al guardar los datos: {str(e)}")
else:
self.logger.warning("No hay datos disponibles para guardar.")
def progress_callback(attempts: int, elapsed_time: float):
"""Función de devolución de llamada mínima: se puede personalizar según las necesidades"""
pass # Silenciosa por defecto
def main():
# Configuración
API_TOKEN = "TU_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# Inicializar el Scraper
scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# Definir los parámetros de búsqueda
datasets = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# Ejecutar proceso de scraping
snapshot_id = scraper.trigger_collection(Conjuntos de datos)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
Scraper.store_data(data)
print("n¡Proceso de scraping completado con éxito!n")
if __name__ == "__main__":
main()
Para ejecutar este código, asegúrese de sustituir los siguientes valores:
API_TOKENpor tu token API real.- Modifique la lista
de Conjuntos de datospara incluir los productos o palabras clave que desea buscar.
A continuación se muestra una estructura JSON de ejemplo de los datos recuperados:
{
"asin": "B0CJ3XWXP8",
"url": "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
"name": "Xbox Series X Console (Renewed) Xbox Series X Console (Renewed)Sep 15, 2023",
"sponsored": "false",
"initial_price": 449.99,
"final_price": 449.99,
"currency": "USD",
"sold": 2000,
"rating": 4.1,
"num_ratings": 1529,
"variations": null,
"badge": null,
"business_type": null,
"brand": null,
"delivery": ["Entrega GRATIS el domingo 1 de diciembre", "O entrega más rápida el viernes 29 de noviembre"],
«keyword»: «X-box»,
«image»: «https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg»,
«domain»: «https://www.amazon.com/»,
«bought_past_month»: 2000,
«page_number»: 1,
«rank_on_page»: 1,
«timestamp»: «2024-11-26T05:15:24.590Z»,
"input": {
"keyword": "X-box",
"url": "https://www.amazon.com",
"pages_to_search": 1,
},
}
Puede ver el resultado completo descargandoeste archivo JSON de muestra.
Conclusión
Hemos analizado el proceso de recopilación de ASIN de Amazon utilizando Python, pero también nos hemos enfrentado a varios retos por el camino. Problemas como los CAPTCHA y los límites de velocidad pueden obstaculizar significativamente nuestros esfuerzos de recopilación de datos. Como solución, podemos utilizar herramientas como los Proxies de Bright Data o la API Amazon Scraper. Estas opciones pueden ayudar a acelerar el proceso y a sortear los obstáculos más comunes. Si prefiere evitar la molestia de configurar sus herramientas de scraping, Bright Data también ofrece Conjuntos de datos de Amazon listos para usar que puede utilizar de inmediato.
¡Regístrese ahora y comience su prueba gratuita!





