

En este tutorial, verás:
- La definición de un Scraper de reservas
- Qué datos se pueden extraer con él
- Cómo crear un script de scraping de Booking.com con Python
¡Empecemos!
¿Qué es un Scraper de Booking?
Un scraper de Booking.com es una herramienta que extrae automáticamente datos de las páginas de Booking.com. Te permite recuperar información de las páginas de listados de propiedades, como nombres de hoteles, precios, reseñas, valoraciones, servicios y disponibilidad. Estos datos se pueden utilizar para diversos fines, como análisis de mercado, comparación de precios y creación de Conjuntos de datos relacionados con los viajes.
Datos que se pueden extraer de Booking.com
A continuación se muestra una lista de los puntos de datos que puedes recuperar de Booking.com:
- Detalles del establecimiento: nombre del hotel, dirección, distancia a puntos de referencia (por ejemplo, centro de la ciudad, centro comercial, etc.).
- Información sobre precios: precio normal, precio con descuento (si está disponible).
- Opiniones y valoraciones: puntuación de las opiniones, número de opiniones, comentarios de los huéspedes
- Disponibilidad: tipos de habitaciones disponibles, opciones de reserva (por ejemplo, cancelación gratuita, desayuno incluido), fechas con disponibilidad
- Medios: Imágenes del establecimiento, imágenes de las habitaciones
- Servicios: instalaciones ofrecidas (por ejemplo, wifi, aparcamiento, piscina), servicios específicos de las habitaciones
- Promociones: ofertas especiales o descuentos, ofertas por tiempo limitado
- Políticas: política de cancelación, horarios de entrada y salida
- Detalles adicionales: descripción del establecimiento, atracciones cercanas, número de habitaciones disponibles para fechas específicas
Extracción de datos de Booking.com en Python: guía paso a paso
En esta sección guiada, aprenderás a crear un Scraper de Booking.com.
El objetivo es crear un script en Python que recopile automáticamente los datos de la página de listado de propiedades:
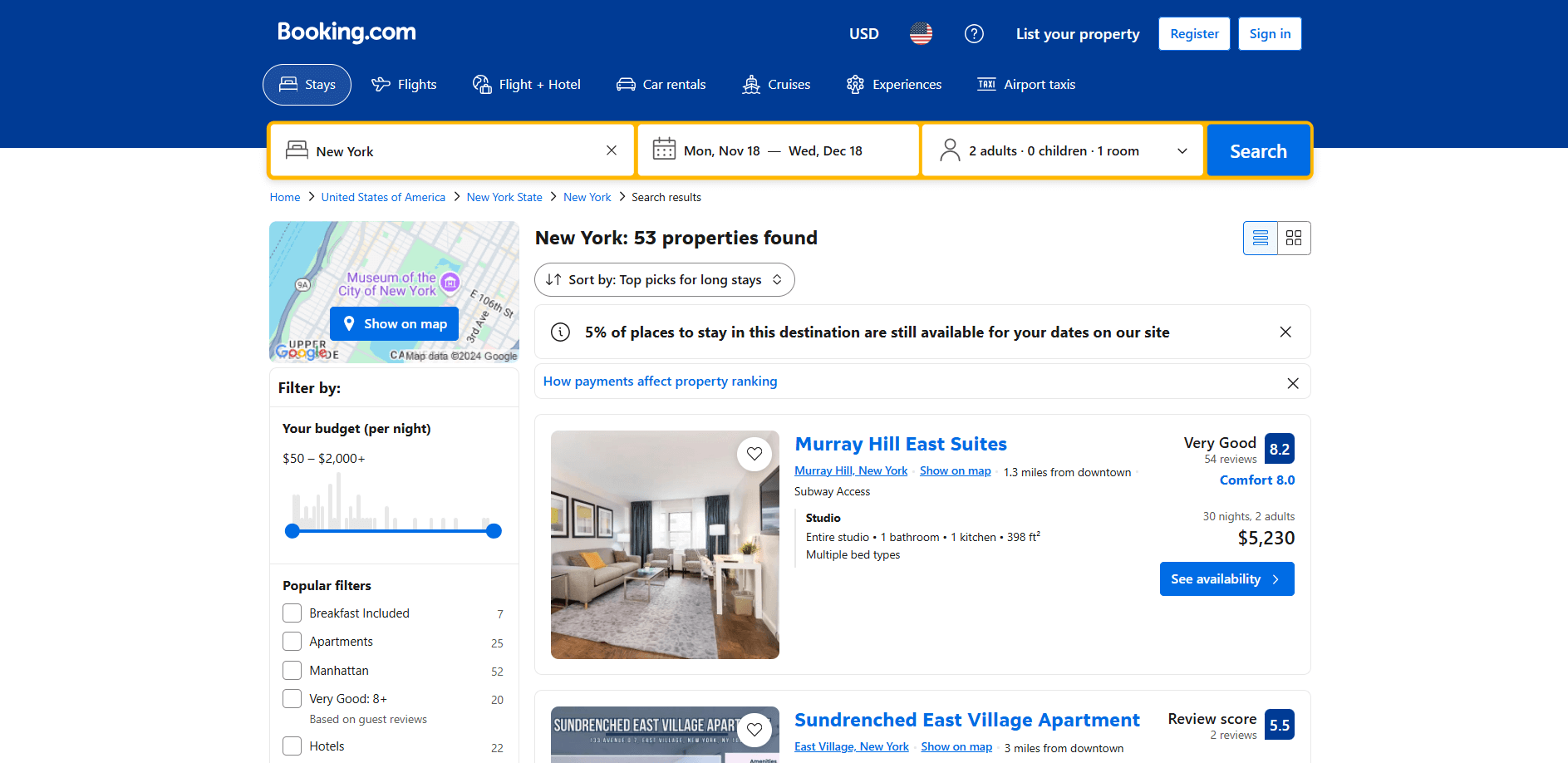
¡Sigue los pasos que se indican a continuación!
Paso n.º 1: Configuración del proyecto
Antes de empezar, asegúrate de tener Python 3 instalado en tu ordenador. Si no es así, descárgalo, ejecuta el archivo ejecutable y sigue las instrucciones del asistente de instalación.
Ahora, utiliza los siguientes comandos para crear una carpeta para tu proyecto:
mkdir booking-scraper
El directorio booking-scraper representa la carpeta del proyecto de su script de scraping de Python Booking.com.
Entra en él e inicializa un entorno virtual dentro de él:
cd booking-Scraper
python -m venv env
Cargue la carpeta del proyecto en su IDE de Python favorito. Visual Studio Code con la extensión Python y PyCharm Community Edition son dos excelentes opciones.
Crea un archivo scraper.py en la carpeta del proyecto, que debe contener esta estructura de archivos:
scraper.py es ahora un script Python en blanco, pero pronto contendrá la lógica de scraping.
En la terminal del IDE, activa el entorno virtual. Para ello, en Linux o macOS, ejecuta este comando:
./env/bin/activate
De forma equivalente, en Windows, ejecuta:
env/Scripts/activate
¡Genial, ahora tienes un entorno Python para el Scraping web!
Paso n.º 2: selecciona la biblioteca de scraping
Es hora de determinar si Booking.com es un sitio estático o dinámico y seleccionar la biblioteca de scraping adecuada en consecuencia. Esto se puede hacer inspeccionando el comportamiento del sitio. Empieza abriendo Booking.com en tu navegador. Realiza una búsqueda y navega hasta la página de la propiedad:
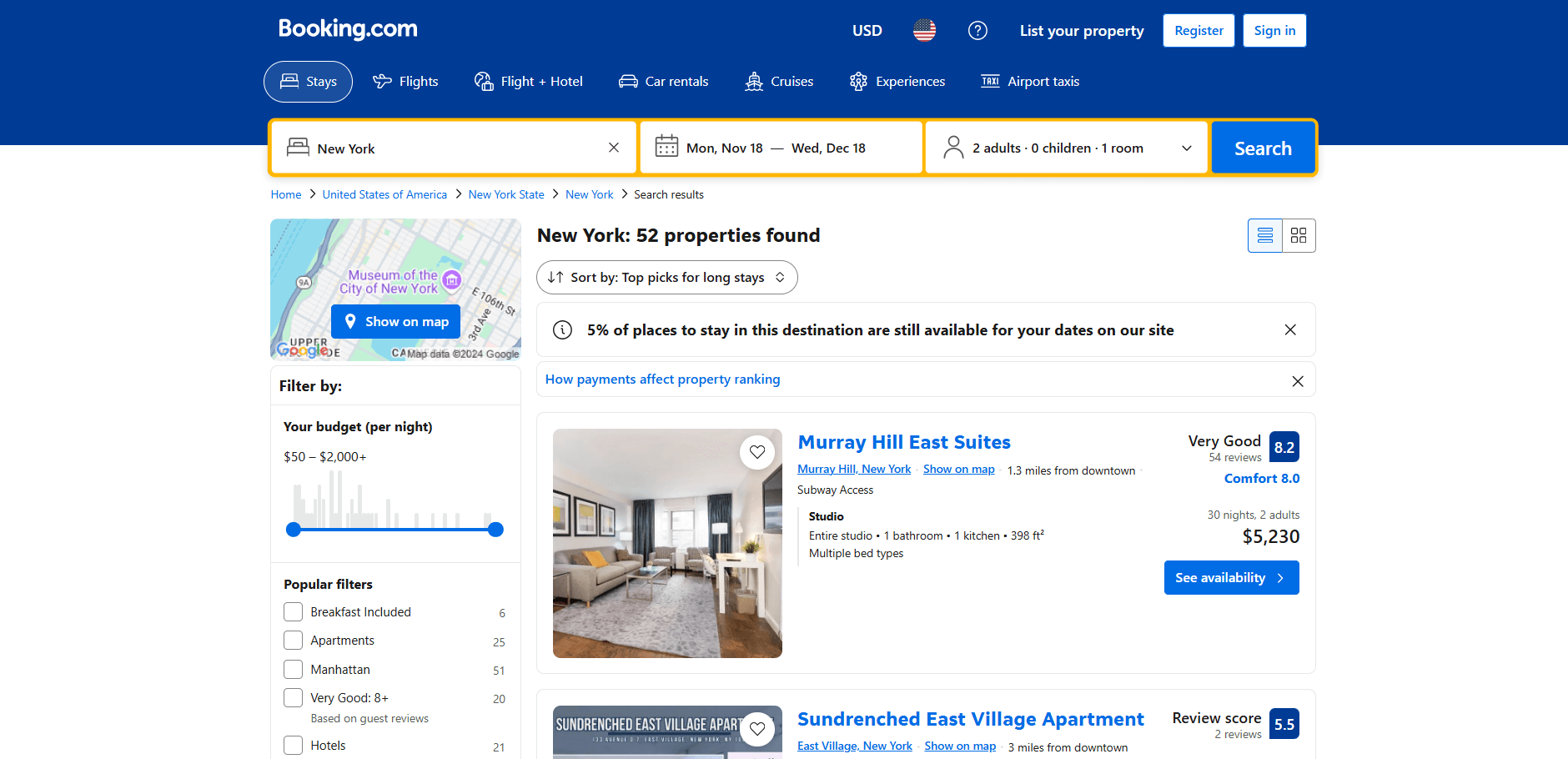
Observe que la página carga nuevos datos dinámicamente a medida que se desplaza hacia abajo:
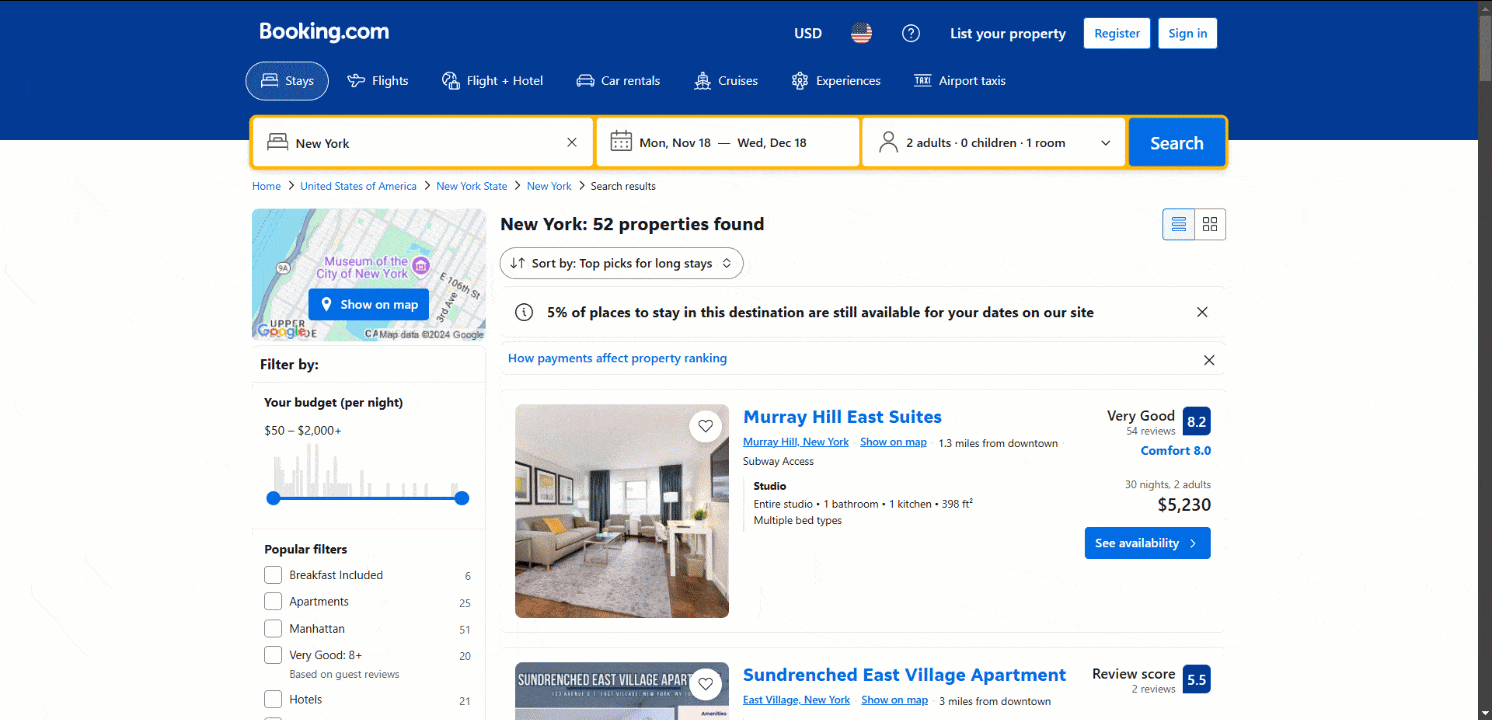
Ese patrón se conoce como desplazamiento infinito y es un sello distintivo de los sitios dinámicos. Obtén más información sobre cómo realizar Scraping web en sitios dinámicos.
Sin siquiera profundizar en el código HTML del documento devuelto por el servidor o inspeccionar la pestaña Red en DevTools (dos pasos comunes para comprender si un sitio es estático o no), ya podemos concluir que Booking.com es un sitio dinámico.
El mejor enfoque para extraer datos de un sitio de contenido dinámico es utilizar una herramienta de automatización del navegador. Estas soluciones le permiten controlar un navegador y realizar interacciones específicas en la página para extraer datos de forma eficaz.
Una de las herramientas de automatización de navegadores más potentes para Python es Selenium, lo que la convierte en una excelente opción para extraer datos de Booking.com. Prepárate para instalarla, ya que será la biblioteca principal para esta tarea.
Paso n.º 3: Instalar y configurar Selenium
En Python, Selenium está disponible a través del paquete pip selenium. En un entorno virtual Python activado, instálalo con este comando:
pip install selenium
Para obtener orientación sobre cómo utilizar la herramienta, lee nuestro tutorial sobre Scraping web con Selenium.
Importa Selenium en scraper.py e inicializa un objeto WebDriver para controlar una instancia de Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
El código anterior inicializa una instancia de Chrome WebDriver para controlar un navegador Chrome. Ten en cuenta que Booking.com parece utilizar tecnología antirraspado que bloquea los navegadores sin interfaz gráfica. Por lo tanto, evita establecer el indicador --headless. Como solución alternativa, lee nuestra guía sobre Playwright Stealth.
Como última línea de su Scraper, recuerde cerrar el controlador web:
driver.quit()
¡Genial! Ya tienes todo configurado para empezar a extraer datos de Booking.com.
Paso n.º 4: Visita la página de destino
Las páginas de Booking.com ofrecen numerosas funciones interactivas para refinar su búsqueda:
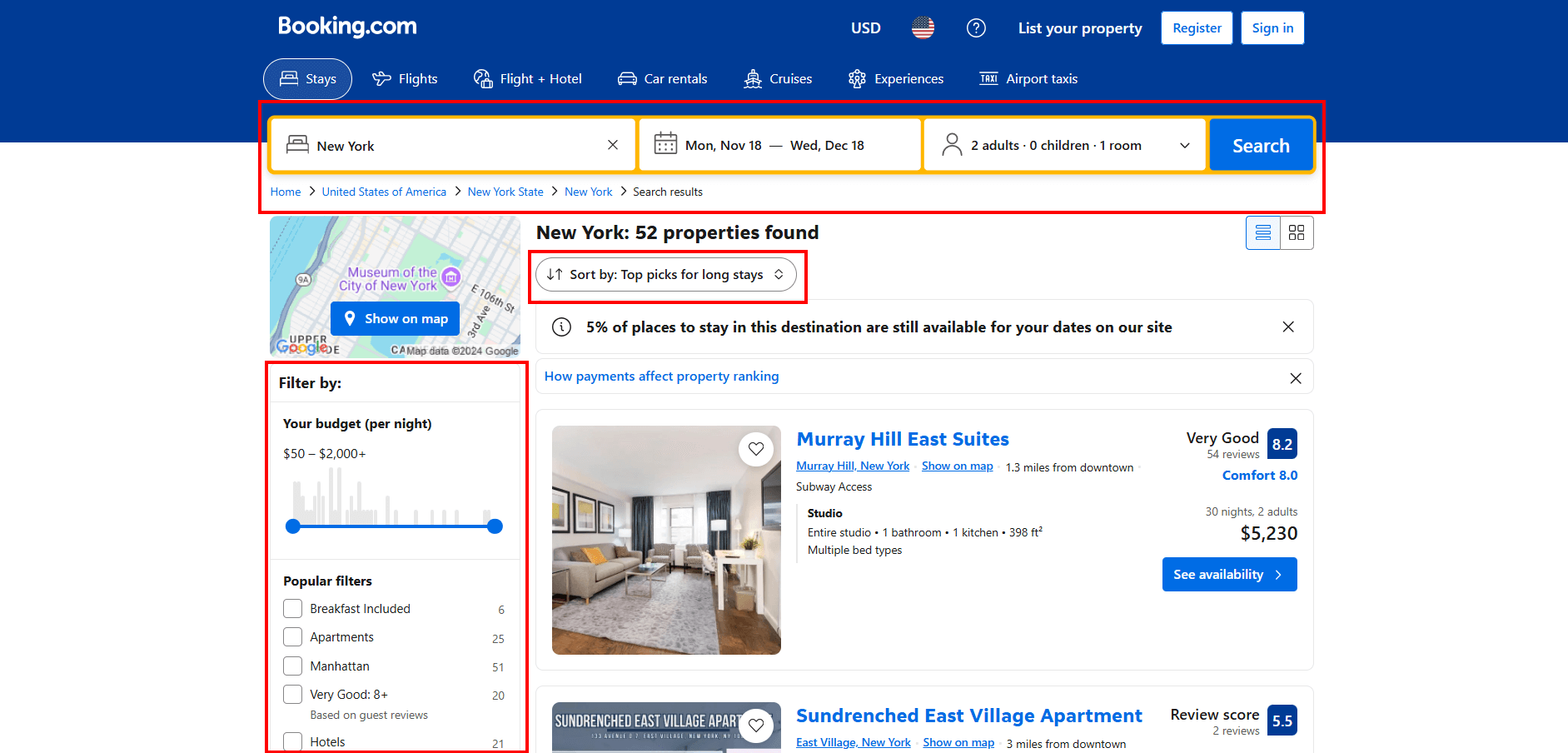
Simular todas estas interacciones mediante programación con Selenium sería complejo y llevaría mucho tiempo. Por lo tanto, para simplificar y acelerar el proceso, primero realiza las interacciones manualmente en tu navegador.
Una vez que haya configurado la consulta de búsqueda que le interesa, copie la URL de la página resultante de la barra de direcciones de su navegador.
Por ejemplo, la URL anterior representa una búsqueda de apartamentos en Nueva York del 18 de noviembre al 18 de diciembre para dos adultos.
Copie la URL e introdúzcala en el método get() que ofrece Selenium:
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
Tu script de scraping se conectará automáticamente a la página deseada de Booking.com.
El archivo scraper.py ahora contendrá estas líneas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
# conectarse a la página de destino
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# lógica de scraping...
# cerrar el controlador web y liberar sus recursos
driver.quit()
Coloca un punto de interrupción de depuración en la última línea y ejecuta el script. A continuación se muestra lo que deberías ver:
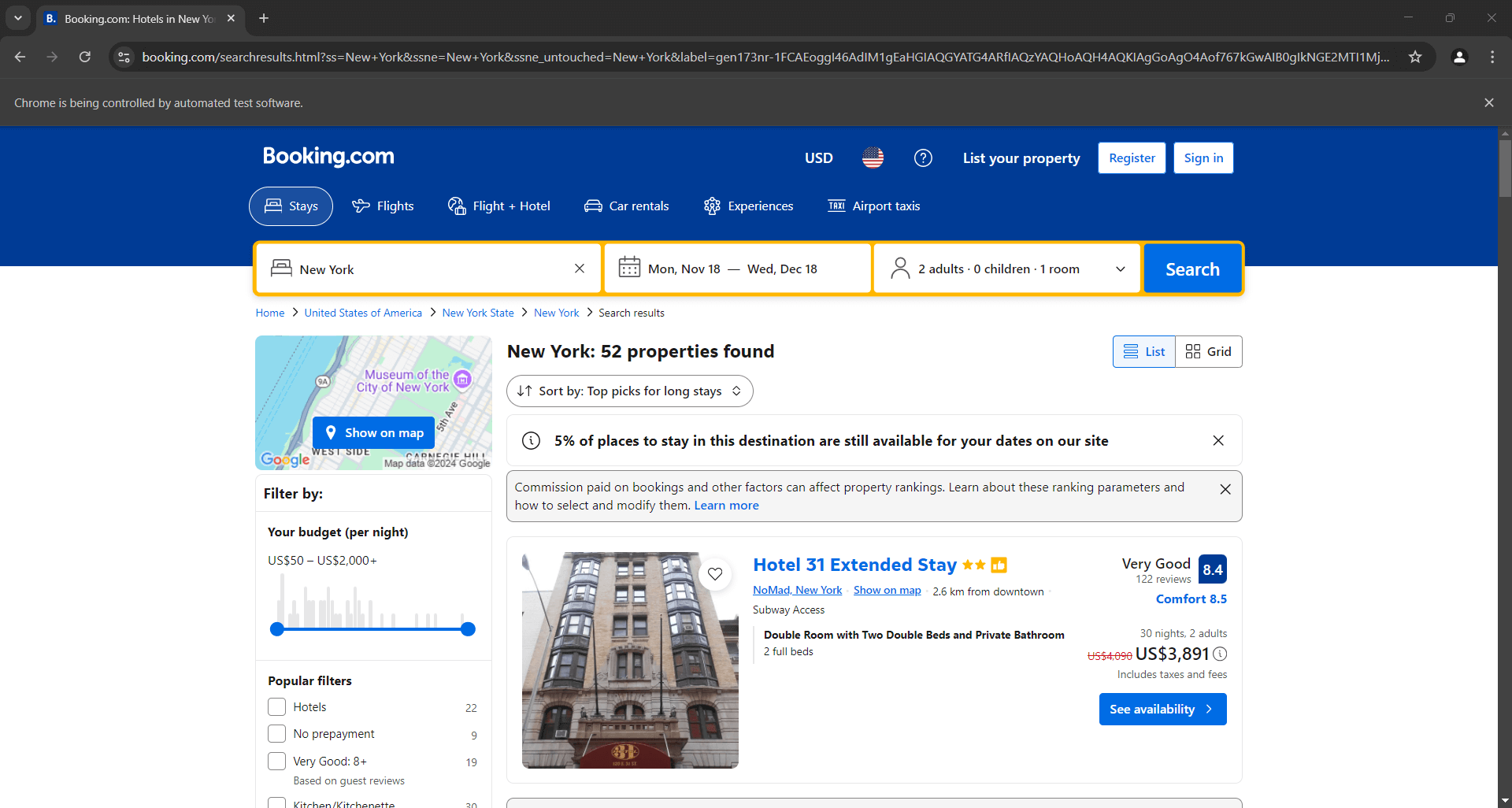
El mensaje «Chrome está siendo controlado por un software de pruebas automatizado» certifica que Selenium está funcionando en Chrome como se desea. ¡Bien hecho!
Paso n.º 5: gestionar la alerta de inicio de sesión
Cuando visita Booking.com por primera vez en un navegador, el sitio suele mostrar una alerta de inicio de sesión en los primeros 20 segundos. Esto bloquea el acceso al contenido de la página, lo que dificulta el Scraping web:
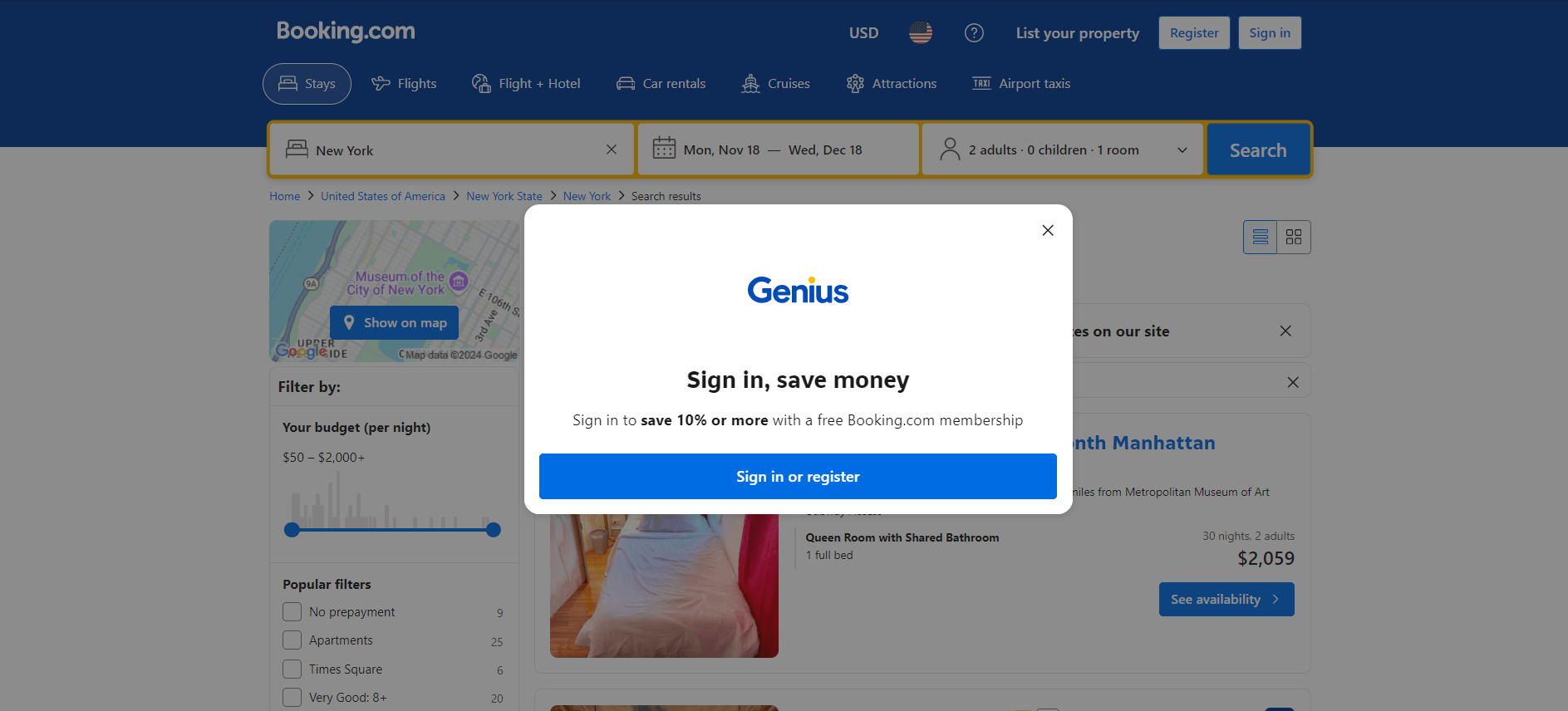
Hasta que no interactúes con ella, no podrás acceder al contenido de la página subyacente.
Para gestionar la alerta, ciérrela con Selenium. Haga clic con el botón derecho del ratón en el botón de cierre y seleccione la opción «Inspeccionar» en el menú contextual:
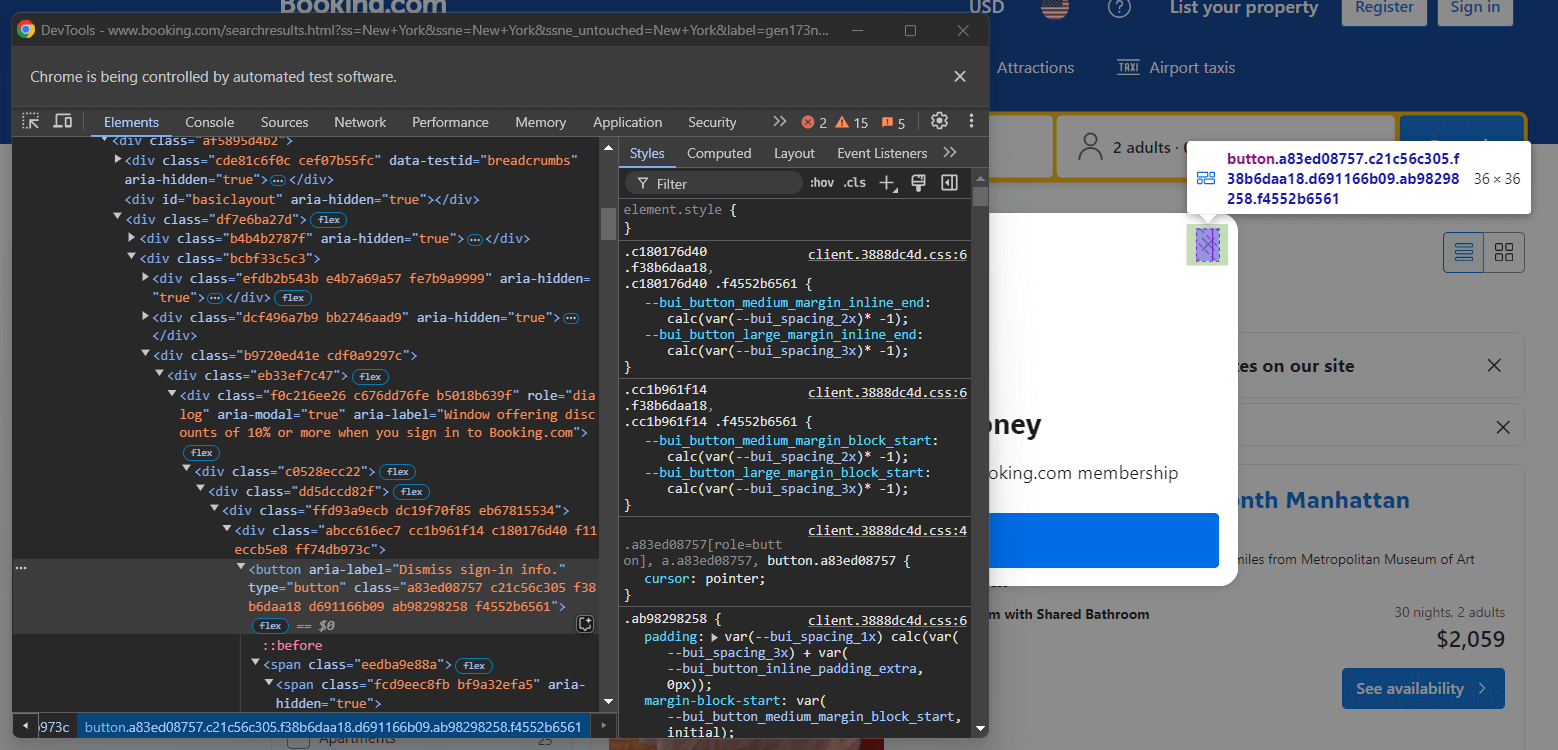
Ten en cuenta que puedes cerrar el modal seleccionando el botón con el siguiente selector CSS:
[role="dialog"] button[aria-label="Dismiss sign-in info."]
Ahora, indica a Selenium que espere hasta 10 segundos a que aparezca la alerta. Una vez que aparezca, ciérrala haciendo clic en el botón de descartar. Dado que el modal puede no aparecer siempre, tiene sentido envolver esta lógica en un bloque try...except:
try:
# esperar hasta 20 segundos a que aparezca la alerta de inicio de sesión
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# hacer clic en el botón Cerrar
close_button.click()
except TimeoutException:
print("El modal de inicio de sesión no apareció, continuando...")
WebDriverWait es una clase especializada de Selenium que pausa el script hasta que se cumple una condición específica en la página. En el ejemplo anterior, espera hasta 10 segundos a que aparezca el botón de cierre de la alerta en la página.
Si la alerta no aparece, Selenium genera la excepción TimeoutException. Importe junto con WebDriverWait, EC y By como se muestra a continuación:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
¡Genial! La alerta de inicio de sesión ya no es un problema.
Paso n.º 6: Selecciona los elementos de Booking.com
Ten en cuenta que la página de Booking.com que se va a extraer contiene varios elementos. Como quieres extraerlos todos, inicializa una matriz donde almacenar los datos extraídos:
items = []
Ahora, debe comprender cómo seleccionar los elementos HTML asociados a esos elementos. Abra Booking.com en su navegador, realice una búsqueda e inspeccione uno de los elementos de la propiedad:
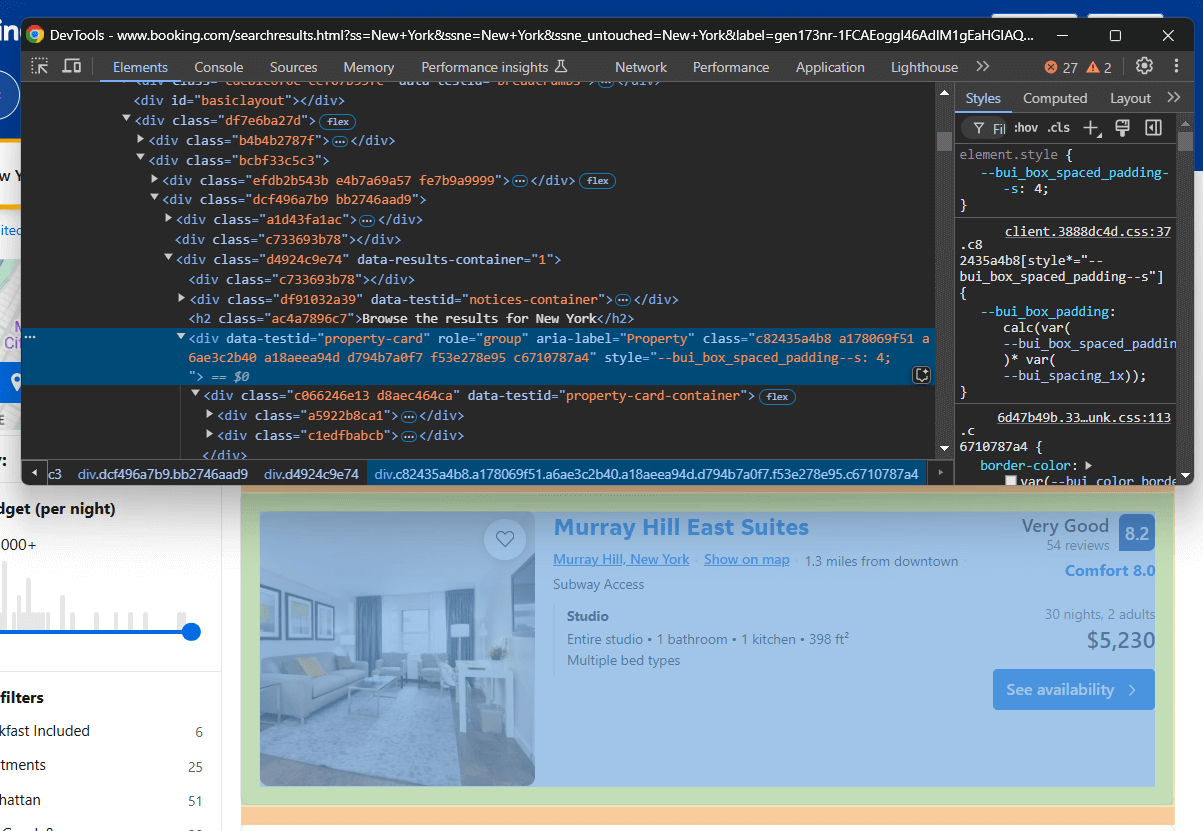
Observe que las clases de los elementos HTML parecen generarse aleatoriamente. Esto significa que es probable que cambien con cada implementación del sitio, lo que los hace poco fiables para la selección de elementos. En su lugar, céntrese en atributos más estables como data-testid.
Los atributosdata-* son excelentes objetivos para el Scraping web.
Utilice el método find_elements() de Selenium para aplicar un selector CSS en la página y seleccionar los elementos de interés:
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
Itere sobre los elementos de la propiedad y prepare su Scraper de Booking.com para extraer algunos datos:
for property_item in property_items:
# lógica de scraping...
¡Genial! El siguiente paso es extraer datos de estos elementos.
Paso n.º 7: extraer los elementos de Booking.com
Echa un vistazo a los elementos de la propiedad en la página y observa que los elementos que contienen son inconsistentes:
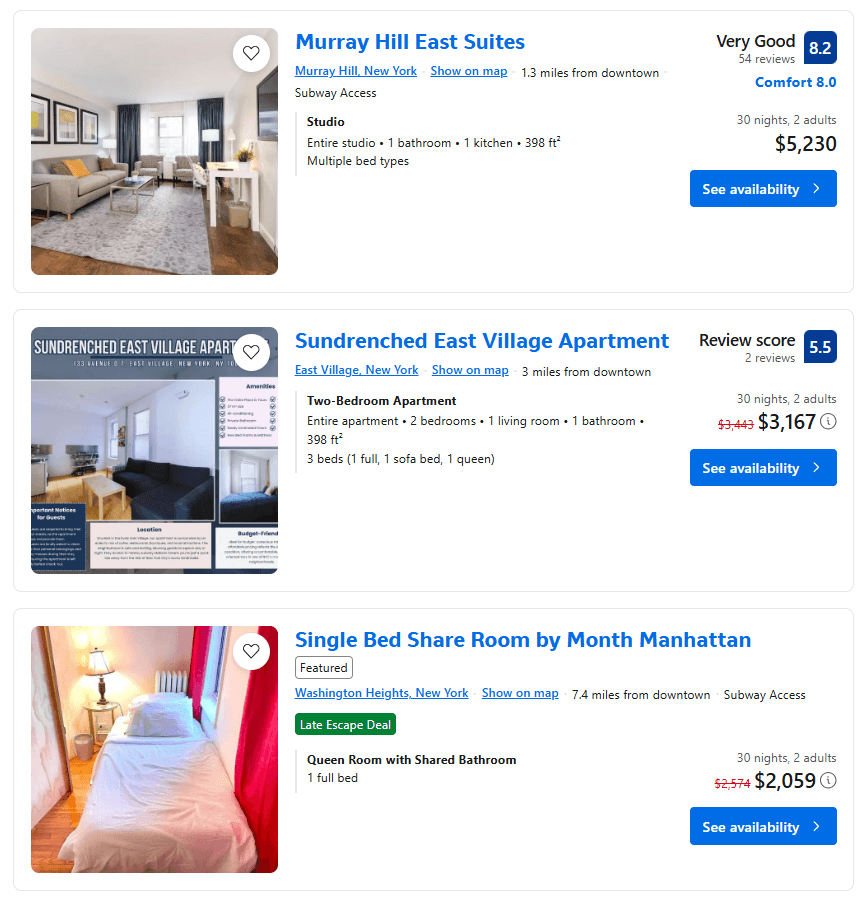
Algunos tienen una puntuación de reseñas, mientras que otros no. De nuevo, algunos tienen un precio con descuento, mientras que otros no.
Estas diferencias dificultan la escritura de una lógica de scraping coherente para todos los elementos de propiedad. Cuando intentas seleccionar un elemento que no está en la página, Selenium genera una excepción NoSuchElementException. Por lo tanto, tiene sentido definir una función para manejar ese escenario:
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
La función anterior acepta una función lambda e intenta ejecutarla. Si genera una excepción NoSuchElementException, la captura y devuelve None. Esto permite que el script de scraping de Booking.com continúe sin interrupciones.
Importar NoSuchElementException:
from selenium.common import NoSuchElementException
Inspeccione un elemento de propiedad que contenga todos los elementos (puntuación de la reseña, precio con descuento, etc.):
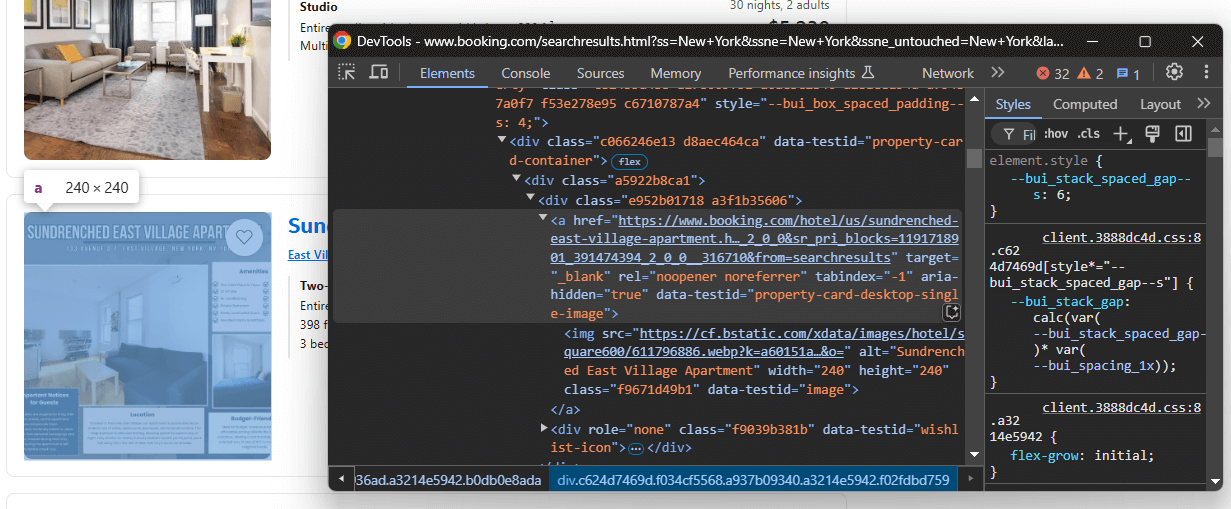
Tenga en cuenta que puede extraer:
- El enlace de la propiedad desde
a[data-testid="property-card-desktop-single-image"] - La imagen de la propiedad desde
img[data-testid=image]
En el bucle «for», aplique la lógica actual para seleccionar esos elementos y extraer datos de ellos:
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
find_element() selecciona un único nodo de la página, mientras que get_attribute() obtiene el contenido dentro del atributo HTML especificado. Tenga en cuenta que las instrucciones de extracción de datos están envueltas por handle_no_such_element_exception para gestionar NoSuchElementExceptions.
Del mismo modo, céntrese en la información de la sección del título y justo debajo de ella:
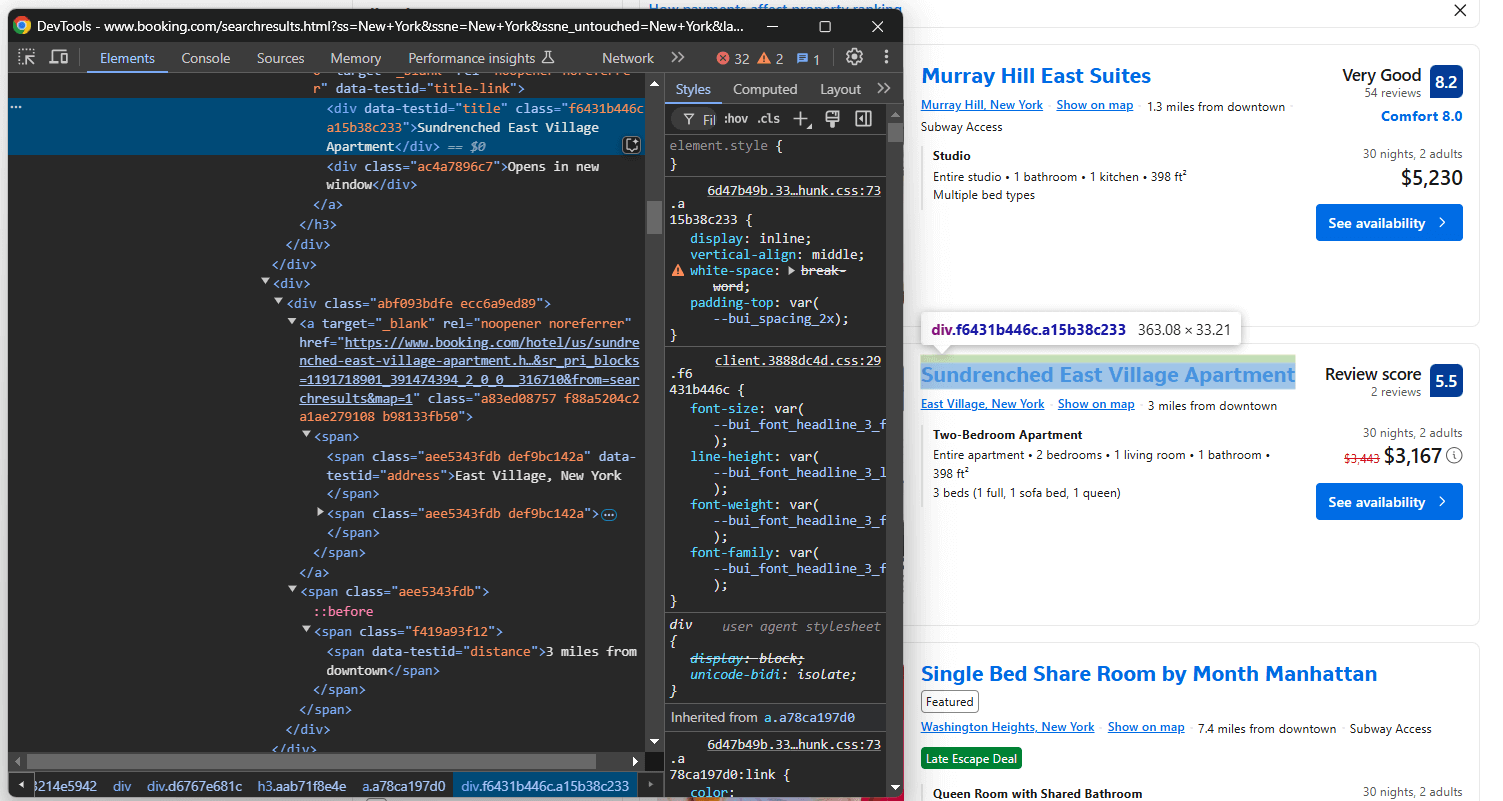
Aquí, puede obtener:
- El título de la propiedad de
[data-testid="title"] - La propiedad dirección de
[data-testid="address"] - La propiedad distance de
[data-testid="distance"]
Recopílelos todos con:
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
El atributo text contiene el texto dentro de los elementos seleccionados.
A continuación, concéntrese en el nodo de puntuación de la reseña:
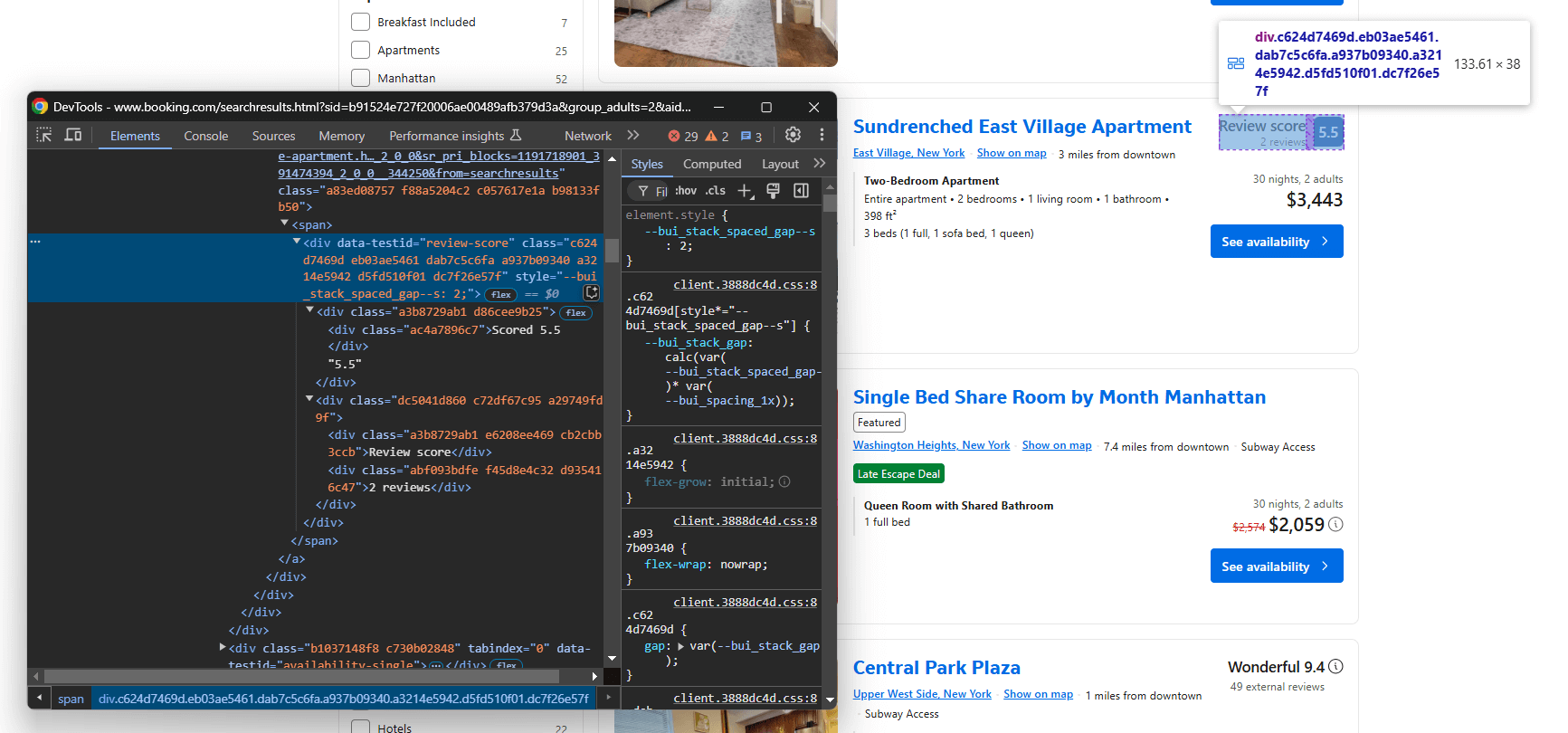
Selecciónelo con data-testid="review-score" y extraiga su texto. Tenga en cuenta que el texto tiene un formato especial, como en este ejemplo:
«Puntuación 8,4n8,4nMuy buenon120 reseñas»
Con algo de lógica personalizada, puede extraer la puntuación de la reseña y el recuento de reseñas:
puntuación_de_la_reseña = Ninguna
número_de_reseñas = Ninguno
texto_de_la_reseña = manejar_excepción_elemento_no_encontrado(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="puntuación-de-la-reseña"]").texto)
si texto_de_la_reseña no es Ninguno:
# dividir la cadena de la reseña por n
partes = texto_de_la_reseña.split("n")
# procesar cada parte
for part in parts:
part = part.strip()
# comprobar si esta parte es un número (puntuación potencial de la reseña)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# comprueba si contiene la cadena «reviews»
elif «reviews» in part:
# extrae el número antes de «reviews»
review_count = int(part.split(" ")[0].replace(«,», »))
Selecciona el elemento de descripción:
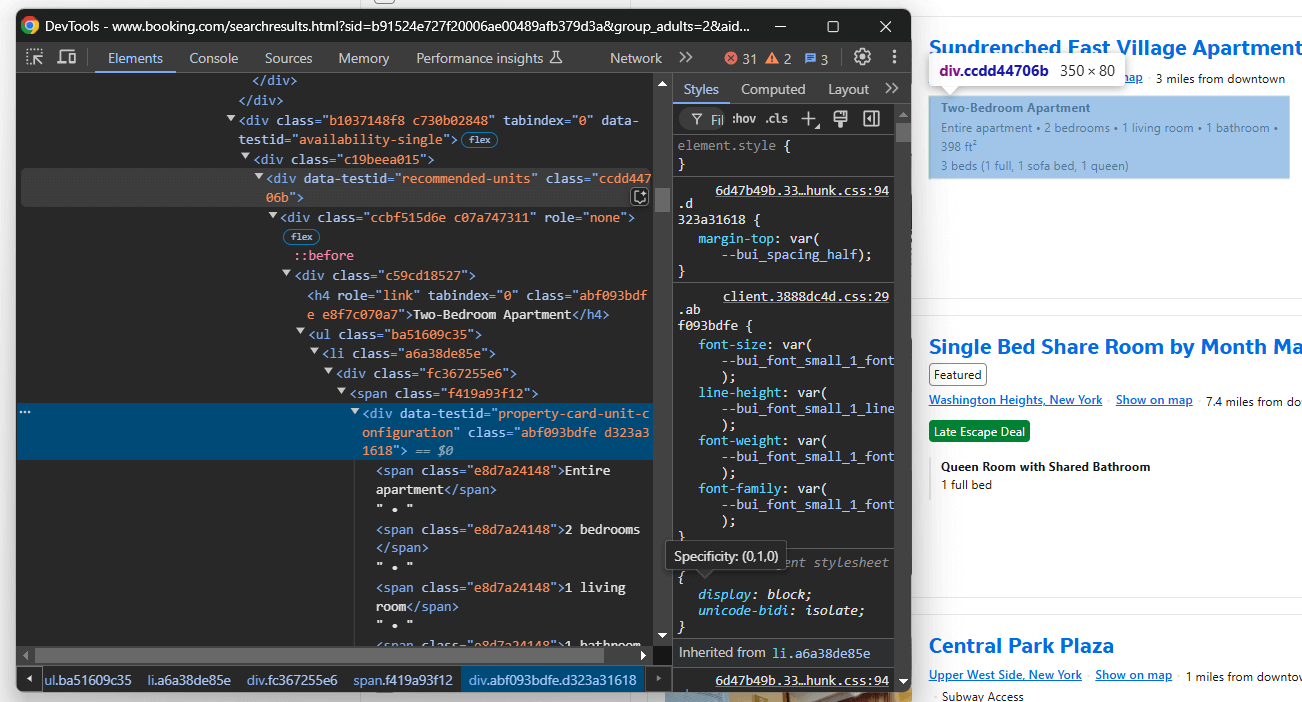
Seleccionarlo con data-testid="recommended-units" y extraer la descripción:
description = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
Por último, céntrate en los elementos de precio:
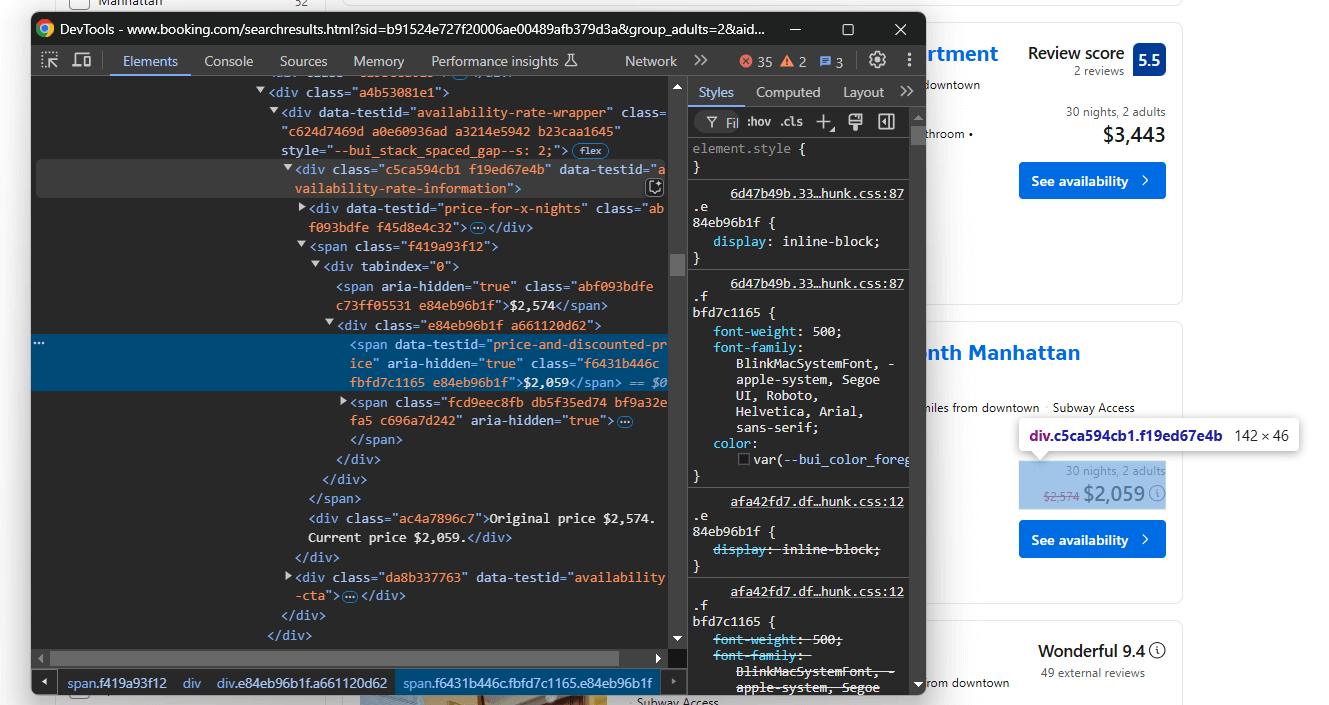
Desde el elemento data-testid="availability-rate-information", selecciona:
- El precio original del nodo que tiene el atributo
aria-hidden="true"y no tiene el atributodata-testid - El precio con descuento/actual de
data-testid="price-and-discounted-price"
Escriba la lógica de extracción de precios como se indica a continuación:
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
¡Vaya! La lógica de scraping de Booking.com está casi completa.
Paso n.º 7: recopilar los datos extraídos
Ahora tienes los datos extraídos repartidos en varias variables dentro del bucle «for ». Crea un nuevo objeto «item», rellénalo con esos datos y añádelo a la matriz «items »:
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"description": description,
"original_price": original_price,
"price": price
}
items.append(item)
Al final del bucle «for», «items» contendrá todos los datos extraídos. Compruébelo imprimiendo «items»:
print(items)
Esto producirá el siguiente resultado:
[{'url': 'https://www.booking.com/hotel/us/murray-hill-east-manhattan.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=1&hapos=1&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=5604802_204869446_2_0_0&highlighted_blocks=5604802_204869446_2_0_0&matching_block_id=5604802_204869446_2_0_0&sr_pri_blocks=5604802_204869446_2_0_0__523000&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/84564452.webp?k=ff50b7387e08e01ba7a400effa788e668f894cabe4a295f60d6cd018ec9ac4d0&o=', 'title': 'Murray Hill East Suites', 'address': 'Murray Hill, Nueva York', 'distance': «1,3 millas del centro», «puntuación»: 8,2, «número de reseñas»: 54, «descripción»: «EstudioEstudio completo • 1 baño • 1 cocina • 398 pies cuadradosnVarios tipos de camas», «precio original»: Ninguno, «precio»: «5230 $»},
# omitido por brevedad...
, {'url': 'https://www.booking.com/hotel/us/renaissance-times-square.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=12&hapos=12&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=2315604_274565698_0_2_0&highlighted_blocks=2315604_274565698_0_2_0&matching_block_id=2315604_274565698_0_2_0&sr_pri_blocks=2315604_274565698_0_2_0__1805400&from_sustainable_property_sr=1&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/437371642.webp?k=d1a06036e365573e326e6b0f1b045f8f43b6ad0d18e119cfb92d92cc81fa5c88&o=', 'title': 'Renaissance New York Times Square by Marriott', 'address': 'Manhattan, Nueva York', 'distance': '0,6 millas del centro', 'review_score': 8,4, 'review_count': 2209, 'description': 'Habitación King con 1 cama king size', 'original_price': '20060 $', 'price': '18054 $'}]
¡Fantástico! Solo queda exportar esta información a un archivo legible para humanos, como CSV.
Paso n.º 8: Exportar a CSV
Importa el paquete csv de la biblioteca estándar de Python:
import csv
A continuación, utilícelo para exportar elementos a un archivo CSV:
# especifique el nombre del archivo CSV de salida
archivo_salida = "propiedades.csv"
# exporte la lista de elementos a un archivo CSV
con open(archivo_salida, modo="w", nueva_línea="", codificación="utf-8") como archivo:
#crear un objeto escritor CSV
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "description", "original_price", "price"])
# escribir la fila del encabezado
writer.writeheader()
# escribir cada elemento como una fila en el CSV
writer.writerows(items)
Este fragmento de código rellena un archivo CSV llamado properties.csv utilizando datos de las matrices de elementos. Las funciones clave utilizadas anteriormente son:
open(): Abre el archivo especificado en modo de escritura con codificación UTF-8.csv.DictWriter(): Crea un escritor CSV con los nombres de campo dados.writeheader(): Escribe la fila de encabezado en el archivo CSV basándose en los nombres de campo especificados.writer.writerow(): Escribe cada elemento del diccionario como una fila en el CSV.
Paso n.º 9: Juntarlo todo
scraper.py ahora debería contener estas líneas:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common import NoSuchElementException
import csv
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service())
# conectarse a la página de destino
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# gestionar la alerta de inicio de sesión
try:
# esperar hasta 20 segundos a que aparezca la alerta de inicio de sesión
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# hacer clic en el botón Cerrar
close_button.click()
except e:
print("No apareció el modal de inicio de sesión, continuando...")
# dónde almacenar los datos extraídos
items = []
# seleccionar todos los elementos de la propiedad en la página
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
# iterar sobre los elementos de la propiedad y
# extraer datos de ellos
for property_item in property_items:
# lógica de extracción...
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# divide la cadena de la reseña por n
parts = review_text.split("n")
# procesar cada parte
for part in parts:
part = part.strip()
# comprobar si esta parte es un número (puntuación potencial de la reseña)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# comprobar si contiene la cadena «reviews»
elif «reviews» in part:
# extraer el número antes de «reviews»
review_count = int(part.split(" ")[0].replace(",", ""))
decription = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
# rellenar un nuevo elemento con los datos extraídos
elemento = {
"url": url,
"imagen": imagen,
"título": título,
"dirección": dirección,
"distancia": distancia,
"review_score": review_score,
"review_count": review_count,
"decription": decription,
"original_price": original_price,
"price": price
}
# añadir el nuevo elemento a la lista de elementos extraídos
items.append(item)
# especificar el nombre del archivo CSV de salida
archivo_salida = "propiedades.csv"
# exportar la lista de elementos a un archivo CSV
con open(archivo_salida, modo="w", nueva_línea="", codificación="utf-8") como archivo:
#crear un objeto escritor CSV
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "decription", "original_price", "price"])
# escribir la fila del encabezado
writer.writeheader()
# escribir cada elemento como una fila en el CSV
writer.writerows(items)
# cerrar el controlador web y liberar sus recursos
driver.quit()
¿Te lo puedes creer? En solo unas 110 líneas, acabas de crear un Scraper de Python para Booking.com.
Comprueba que funciona ejecutando el script de rastreo. En Windows, ejecuta el Scraper con:
python Scraper.py
De forma equivalente, en Linux o macOS, ejecuta:
python3 Scraper.py
Espera a que el script termine de ejecutarse. Aparecerá un archivo properties.csv en el directorio raíz de tu proyecto. Abre el archivo para ver los datos extraídos:
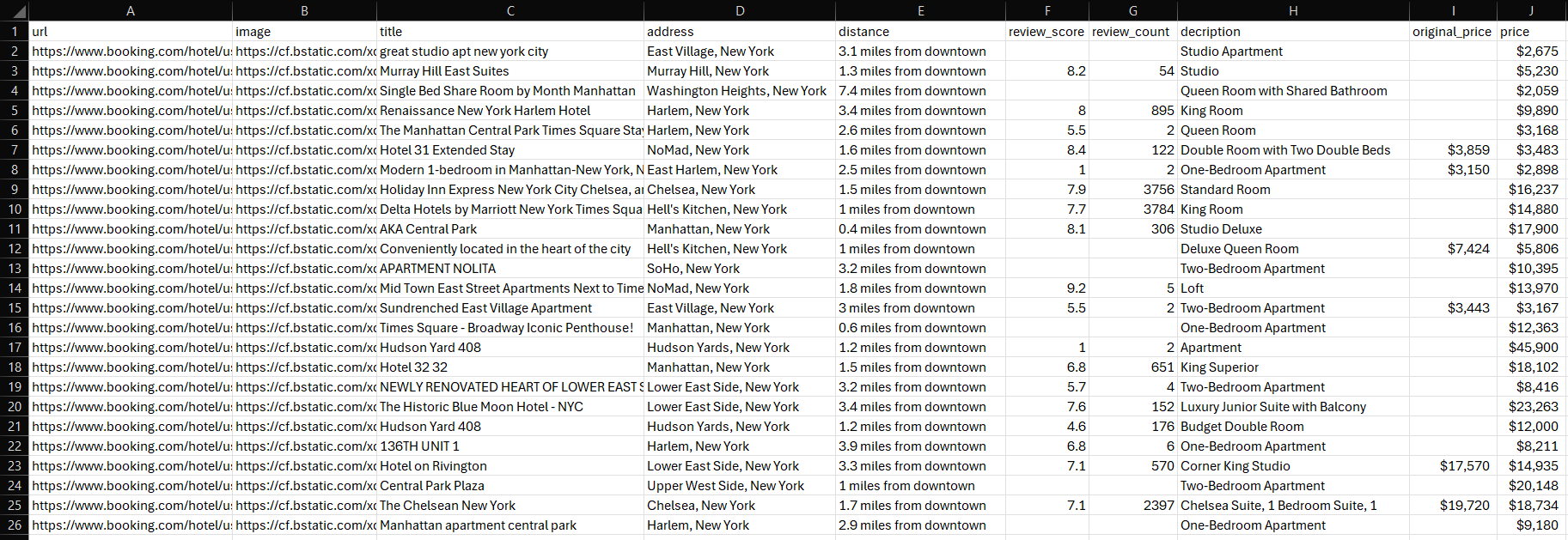
¡Enhorabuena, misión completada!
Conclusión
En este tutorial, ha aprendido qué es un Scraper de Booking.com y cómo crear uno utilizando Python. Como se ha mostrado, crear un script básico para recuperar automáticamente datos de Booking.com solo requiere unas pocas líneas de código.
Sin embargo, el ejemplo que se presenta aquí no aborda muchos de los retos que puedes encontrar al extraer datos de Booking.com. Problemas como las medidas contra los navegadores sin interfaz gráfica, el manejo de las interacciones de los usuarios para generar resultados de búsqueda y el desplazamiento infinito pueden complicar rápidamente tus operaciones de extracción.
¿Buscas una solución de scraping más fácil, completa y potente? ¡Prueba la API Booking Scraper de Bright Data!
La API Booking Scraper proporciona potentes puntos finales para extraer datos públicos de hoteles, reseñas, valoraciones y mucho más. Con simples llamadas a la API, puede recuperar datos en formatos JSON o HTML.
¿Prefiere soluciones preconstruidas? ¡Bright Data también ofrece Conjuntos de datos de Booking.com listos para usar!
Crea hoy mismo una cuenta gratuita en Bright Data para probar nuestras API de Scraper o explorar nuestros Conjuntos de datos.





