En esta guía, verás:
- Todo lo que necesita saber para dar sus primeros pasos con el scraping de DuckDuckGo.
- Los enfoques más populares y eficaces para el Scraping web de DuckDuckGo.
- Cómo crear un Scraper personalizado de DuckDuckGo.
- Cómo utilizar la biblioteca DDGS para el scraping de DuckDuckGo.
- Cómo recuperar datos de resultados de motores de búsqueda a través de la API SERP de Bright Data.
- Cómo proporcionar datos de búsqueda de DuckDuckGo a un agente de IA a través de MCP.
¡Empecemos!
Introducción al scraping de DuckDuckGo
DuckDuckGo es un motor de búsqueda que ofrece protección integrada contra los rastreadores en línea. Los usuarios lo aprecian por su política centrada en la privacidad, ya que no rastrea las búsquedas ni el historial de navegación. De este modo, destaca entre las plataformas de búsqueda convencionales y ha experimentado un aumento constante de su uso a lo largo de los años.
El motor de búsqueda DuckDuckGo está disponible en dos variantes:
- Versión dinámica: la versión predeterminada, que requiere JavaScript e incluye funciones como«Search Assist», una alternativa a las descripciones generales de la IA de Google.
- Versión estática: una versión simplificada que funciona incluso sin renderización JavaScript.
Dependiendo de la versión que elijas, necesitarás diferentes enfoques de scraping, como se describe en esta tabla resumen:
| Característica | Versión SERP dinámica | Versión SERP estática |
|---|---|---|
| Se requiere JavaScript | Sí | No |
| Formato de URL | https://duckduckgo.com/?q=<SEARCH_QUERY> |
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY> |
| Contenido dinámico | Sí, como resúmenes de IA y elementos interactivos | No |
| Paginación | Compleja, basada en un botón «Más resultados» | Sencillo, mediante un botón tradicional «Siguiente» con recarga de la página |
| Enfoque de scraping | Herramientas de automatización del navegador | Cliente HTTP + analizador HTML |
¡Es hora de explorar las implicaciones del scraping para las dos versiones de la SERP (página de resultados del motor de búsqueda) de DuckDuckGo!
DuckDuckGo: versión dinámica de SERP
De forma predeterminada, DuckDuckGo carga una página web dinámica que requiere renderización JavaScript, con una URL como:
https://duckduckgo.com/?q=<SEARCH_QUERY>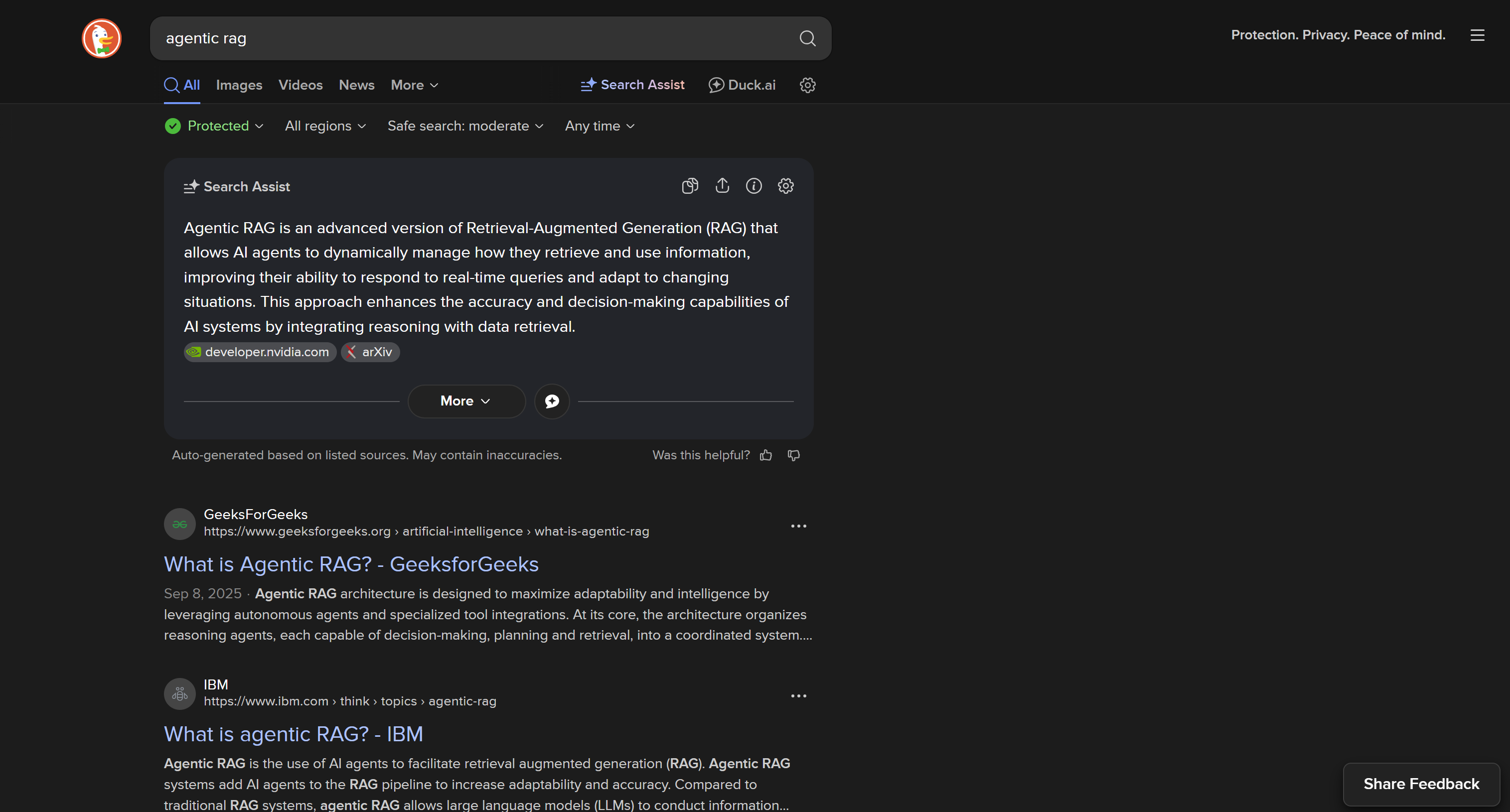
Esta versión incluye interacciones complejas del usuario dentro de la página, como el botón «Más resultados» para cargar dinámicamente otros resultados:
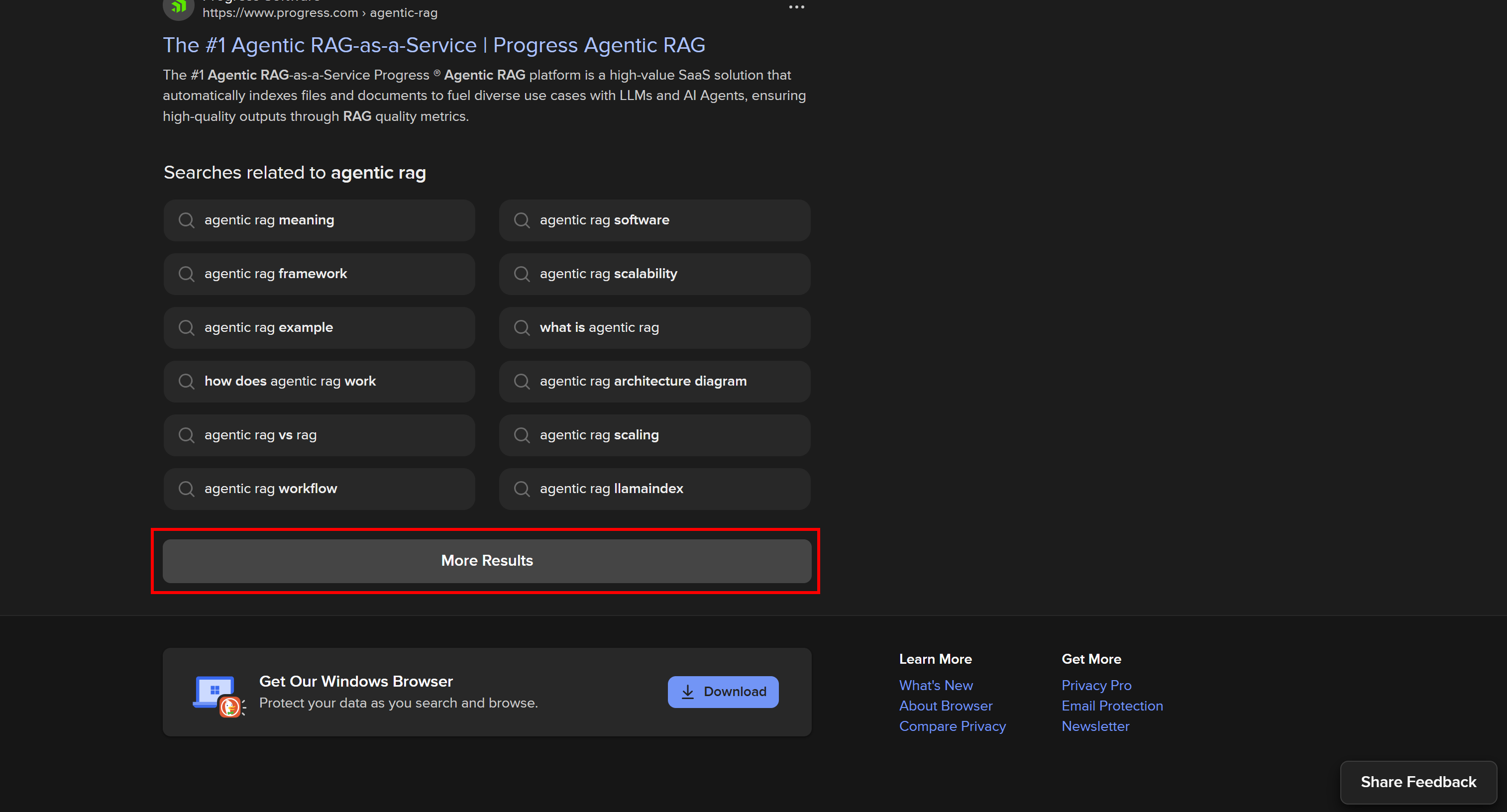
La SERP dinámica de DuckDuckGo ofrece más funciones e información más rica, pero requiere herramientas de automatización del navegador para el scraping. El motivo es que solo un navegador puede renderizar páginas que dependen de JavaScript.
El problema es que controlar un navegador introduce una complejidad adicional y un mayor uso de recursos. Por eso la mayoría de los Scrapers se basan en la versión estática del sitio.
DuckDuckGo: versión estática de SERP
Para los dispositivos que no admiten JavaScript, DuckDuckGo también admite una versión estática de sus SERP. Estas páginas siguen un formato de URL como el siguiente:
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY>
Esta versión no incluye contenido dinámico como el resumen generado por IA. Además, la paginación sigue un enfoque más tradicional con un botón «Siguiente» que te lleva a la página siguiente:
Dado que esta SERP es estática, puede extraerla utilizando un enfoque tradicional de cliente HTTP + analizador HTML. Este método es más rápido, más fácil de implementar y consume menos recursos.
Posibles enfoques para extraer datos de DuckDuckGo
Eche un vistazo a los cuatro posibles enfoques de Scraping web de DuckDuckGo que presentaremos en este artículo:
| Enfoque | Complejidad de la integración | Requiere | Precio | Riesgo de bloqueos | Escalabilidad |
|---|---|---|---|---|---|
| Crear un Scraper personalizado | Medio/alto | Conocimientos de programación en Python | Gratis (puede requerir proxies premium para evitar bloqueos) | Posible | Limitado |
| Depende de una biblioteca de scraping de DuckDuckGo | Bajo | Conocimientos de Python / uso de CLI | Gratuito (puede requerir proxies premium para evitar bloqueos) | Posible | Limitado |
| Utilizar la API SERP de Bright Data | Bajo | Cualquier cliente HTTP | De pago | Ninguno | Ilimitado |
| Integrar el servidor Web MCP | Bajo | Marcos/soluciones de agentes de IA compatibles con MCP | Nivel gratuito disponible, luego de pago | Ninguno | Ilimitado |
A medida que avance en este tutorial, aprenderá más sobre cada uno de ellos.
Independientemente del enfoque que sigas, la consulta de búsqueda objetivo en esta entrada del blog será «agentic rag». En otras palabras, verás cómo recuperar los resultados de búsqueda de DuckDuckGo para esa consulta.
Supondremos que ya tienes Python instalado localmente y que estás familiarizado con él.
Enfoque n.º 1: crear un Scraper personalizado
Utiliza una herramienta de automatización del navegador o un cliente HTTP combinado con un analizador HTML para crear un bot de Scraping web de DuckDuckGo desde cero.
👍 Ventajas:
- Control total sobre la lógica de rastreo.
- Se puede personalizar para extraer exactamente lo que necesitas.
👎 Desventajas:
- Requiere configuración y codificación.
- Puede encontrarse con bloqueos de IP si se realiza scraping a gran escala.
Enfoque n.º 2: confiar en una biblioteca de rastreo de DuckDuckGo
Utiliza una biblioteca de scraping existente para DuckDuckGo, como DDGS (Duck Distributed Global Search), que proporciona todas las funciones que necesitas sin tener que escribir una sola línea de código.
👍 Ventajas:
- Requiere una configuración mínima.
- Gestiona automáticamente las tareas de scraping del motor de búsqueda, mediante código Python o sencillos comandos CLI.
👎 Desventajas:
- Menos flexibilidad en comparación con un Scraper personalizado, con control limitado sobre casos de uso avanzados.
- Sigue encontrando bloqueos de IP.
Enfoque n.º 3: utilizar la API SERP de Bright Data
Aprovecha el punto final premium de la API SERP de Bright Data, al que puedes acceder desde cualquier cliente HTTP. Es compatible con varios motores de búsqueda, incluido DuckDuckGo. Se encarga de todas las complejidades por ti, al tiempo que proporciona un rastreo escalable y de gran volumen.
👍 Ventajas:
- Escalabilidad ilimitada.
- Evita las prohibiciones de IP y las medidas antibots.
- Se integra con clientes HTTP en cualquier lenguaje de programación, o incluso con herramientas visuales como Postman.
👎 Contras:
- Servicio de pago.
Enfoque n.º 4: integrar el servidor Web MCP
Proporcione a su agente de IA capacidades de scraping de DuckDuckGo accediendo a la API SERP de Bright Data de forma gratuita a través del MCP web de Bright Data.
👍 Ventajas:
- Fácil integración de IA.
- Nivel gratuito disponible.
- Fácil de usar dentro de agentes de IA y flujos de trabajo.
👎 Desventajas:
- No se pueden controlar completamente los LLM.
Enfoque n.º 1: crear un Scraper personalizado de DuckDuckGo con Python
Siga los pasos que se indican a continuación para aprender a crear un script de rastreo personalizado de DuckDuckGo en Python.
Nota: Para un parseo de datos simplificado y rápido, utilizaremos la versión estática de DuckDuckGo. Si te interesa recopilar «asistencias de búsqueda» generadas por IA, lee nuestra guía sobre cómo crear un script de rastreo de resultados generales de IA de Google. Puedes adaptarlo fácilmente a DuckDuckGo.
Paso n.º 1: configura tu proyecto
Comience abriendo su terminal y creando una nueva carpeta para su proyecto de Scraper de DuckDuckGo:
mkdir duckduckgo-ScraperLa carpeta duckduckgo-scraper/ contendrá su proyecto de scraping.
A continuación, navega hasta el directorio del proyecto y crea un entorno virtual Python dentro de él:
cd duckduckgo-Scraper
python -m venv .venvAhora, abra la carpeta del proyecto en su IDE de Python preferido. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Crea un nuevo archivo llamado scraper.py en la raíz del directorio de tu proyecto. La estructura de tu proyecto debería tener este aspecto:
duckduckgo-Scraper/
├── .venv/
└── agent.pyEn la terminal, activa el entorno virtual. En Linux o macOS, ejecuta:
source venv/bin/activateDe forma equivalente, en Windows, ejecuta:
venv/Scripts/activateCon el entorno virtual activado, instala las dependencias del proyecto con:
pip install requests beautifulsoup4Las dos bibliotecas necesarias son:
requests: un popular cliente HTTP de Python. Se utilizará para obtener la versión estática de la SERP de DuckDuckGo.beautifulsoup4: una biblioteca Python para el parseo de HTML, que le permite extraer datos de la página de resultados de DuckDuckGo.
¡Genial! Tu entorno de desarrollo Python ya está listo para crear un script de scraping de DuckDuckGo.
Paso n.º 2: Conéctese a la página de destino
Comienza importando requests en scraper.py:
import requestsA continuación, realiza una solicitud GET similar a la de un navegador a la versión estática de DuckDuckGo utilizando el método requests.get():
# URL base de la versión estática de DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Ejemplo de consulta de búsqueda
search_query = "agentic rag"
# Para simular una solicitud de navegador y evitar errores 403
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Conectarse a la página SERP de destino
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)Si no estás familiarizado con esta sintaxis, consulta nuestra guía sobre solicitudes HTTP en Python.
El fragmento anterior enviará una solicitud HTTP GET a https://html.duckduckgo.com/html/?q=agentic+rag (la SERP de destino de este tutorial) con el siguiente encabezado User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36Es necesario configurar un User-Agent real como el anterior para evitar recibir errores 403 Forbidden de DuckDuckGo. Obtenga más información sobre la importancia del encabezado User-Agent en el Scraping web.
El servidor responderá a la solicitud GET con el HTML de la página estática de DuckDuckGo. Acceda a ella con:
html = response.textVerifique el contenido de la página imprimiéndolo:
print(html)Debería ver un HTML similar a este:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=3.0, user-scalable=1" />
<meta name="referrer" content="origin" />
<meta name="HandheldFriendly" content="true" />
<meta name="robots" content="noindex, nofollow" />
<title>agentic rag en DuckDuckGo</title>
<!-- Omitido por brevedad... -->
</head>
<!-- Omitido por brevedad... -->
<body>
<div>
<div class="serp__results">
<div id="links" class="results">
<div class="result results_links results_links_deep web-result">
<div class="links_main links_deep result__body">
<h2 class="result__title">
<a rel="nofollow" class="result__a"
href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9">
¿Qué es Agentic RAG? - GeeksforGeeks
</a>
</h2>
<!-- Omitido por brevedad... -->
</div>
</div>
<!-- Otros resultados... -->
</div>
</div>
</div>
</body>
</html>¡Genial! Este HTML contiene todos los enlaces SERP que te interesa extraer.
Paso n.º 3: Parseo del HTML
Importa Beautiful Soup en scraper.py:
from bs4 import BeautifulSoupA continuación, utilízalo para realizar el parseo de la cadena HTML recuperada anteriormente en una estructura de árbol navegable:
soup = BeautifulSoup(html, "html.parser")Esto realiza el parseo del HTML utilizando el «html.parser» integrado en Python. También puede configurar otros analizadores, como lxml o html5lib, tal y como se explica en nuestra guía de Scraping web con BeautifulSoup.
¡Bien hecho! Ahora puede utilizar la API de BeautifulSoup para seleccionar elementos HTML en la página y extraer los datos que necesite.
Paso n.º 4: Prepárate para extraer todos los resultados SERP
Antes de profundizar en la lógica del scraping, debes familiarizarte con la estructura de las SERP de DuckDuckGo. Abre esta página web en modo incógnito (para garantizar una sesión limpia) en tu navegador:
https://html.duckduckgo.com/html/?q=agentic+ragA continuación, haz clic con el botón derecho del ratón en un elemento del resultado SERP y selecciona la opción «Inspeccionar» para abrir las herramientas de desarrollo del navegador:
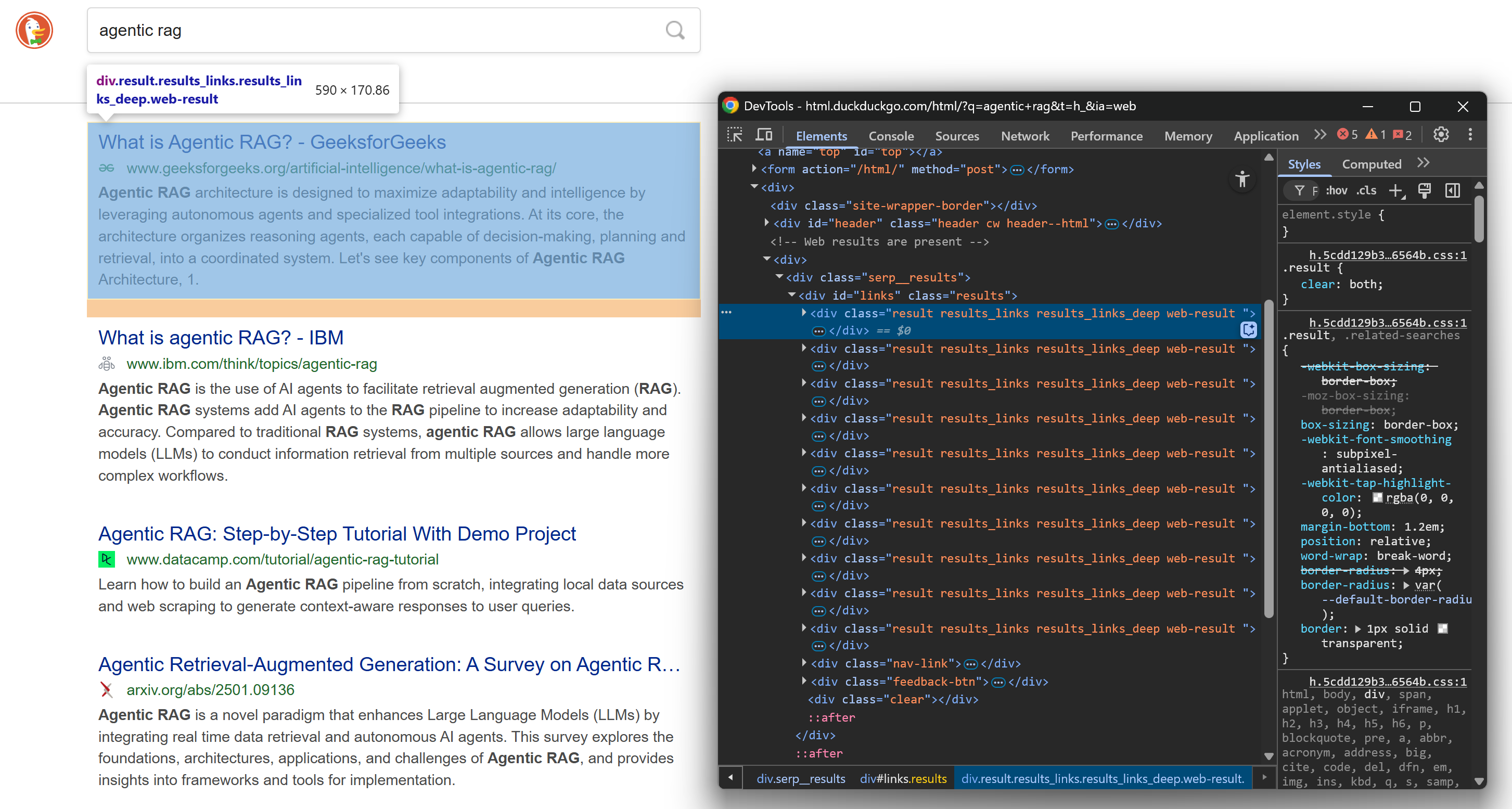
Echa un vistazo a la estructura HTML. Observa que cada elemento SERP tiene la clase result y está contenido en un <div> identificado por el ID links. Esto significa que puedes seleccionar todos los elementos de los resultados de búsqueda utilizando este selector CSS:
#links .resultAplique ese selector a la página parseada con el método select() de Beautiful Soup:
result_elements = soup.select("#links .result") Dado que la página contiene varios elementos SERP, necesitarás una lista para almacenar los datos extraídos. Inicializa una así:
serp_results = []Por último, itera sobre cada elemento HTML seleccionado. Prepárate para aplicar tu lógica de rastreo para extraer los resultados de búsqueda de DuckDuckGo y rellenar la lista serp_results:
for result_element in result_elements:
# Lógica de parseo de datos...¡Genial! Ya estás cerca de alcanzar tu objetivo de rastreo de DuckDuckGo.
Paso n.º 5: extraer los datos de los resultados
Una vez más, inspecciona la estructura HTML de un elemento SERP en la página de resultados:
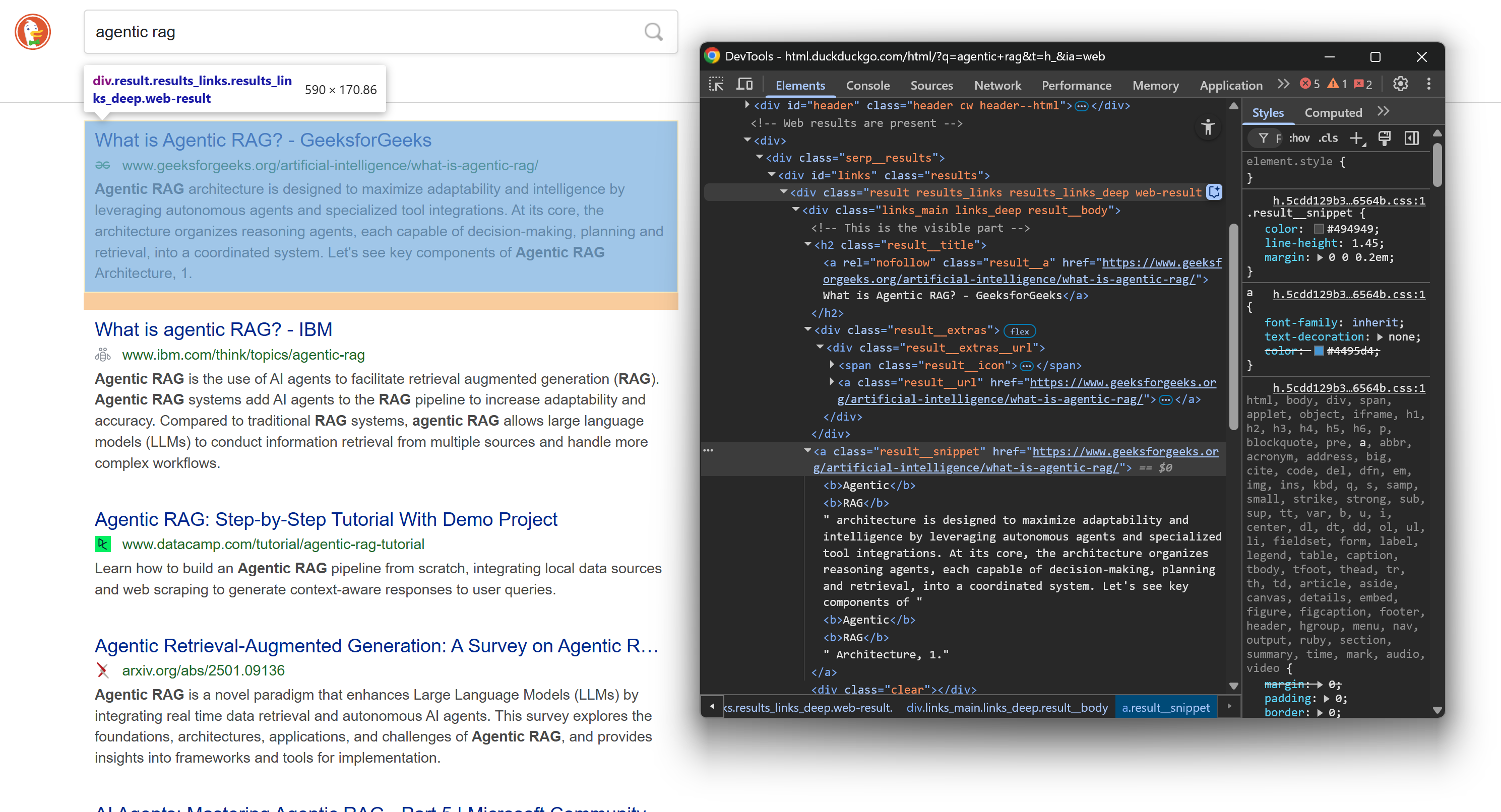
Esta vez, concéntrate en sus nodos HTML anidados. Como puedes ver, a partir de esos elementos, puedes extraer:
- El título del resultado del texto
.result__a - La URL del resultado del atributo
.result__ahref - La URL de visualización del texto
.result__url - El fragmento/descripción del resultado del texto
.result__snippet
Aplica el método select_one() de BeautifulSoup para seleccionar el nodo específico y, a continuación, utiliza .get_text() para extraer el texto o [<attribute_name>] para acceder a un atributo HTML.
Implemente la lógica de scraping con:
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)Nota: strip=True es útil porque elimina los espacios en blanco al principio y al final del texto extraído.
Si te preguntas por qué necesitas concatenar «https:» a title_element["href"], es porque el HTML devuelto por el servidor es ligeramente diferente al que se muestra en tu navegador. El HTML sin procesar, que tu Scraper analiza realmente, contiene URL en un formato como este:
//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9Como puede ver, la URL comienza con // en lugar de incluir el esquema (https://). Al anteponer «https:», se asegura de que la URL sea más usable (fuera de los navegadores, que también admiten ese formato).
Compruebe usted mismo este comportamiento. Haga clic con el botón derecho del ratón en la página y seleccione la opción «Ver código fuente de la página». Esto le mostrará el documento HTML sin formato devuelto por el servidor (sin aplicar ninguna representación del navegador). Verá los enlaces SERP en ese formato:
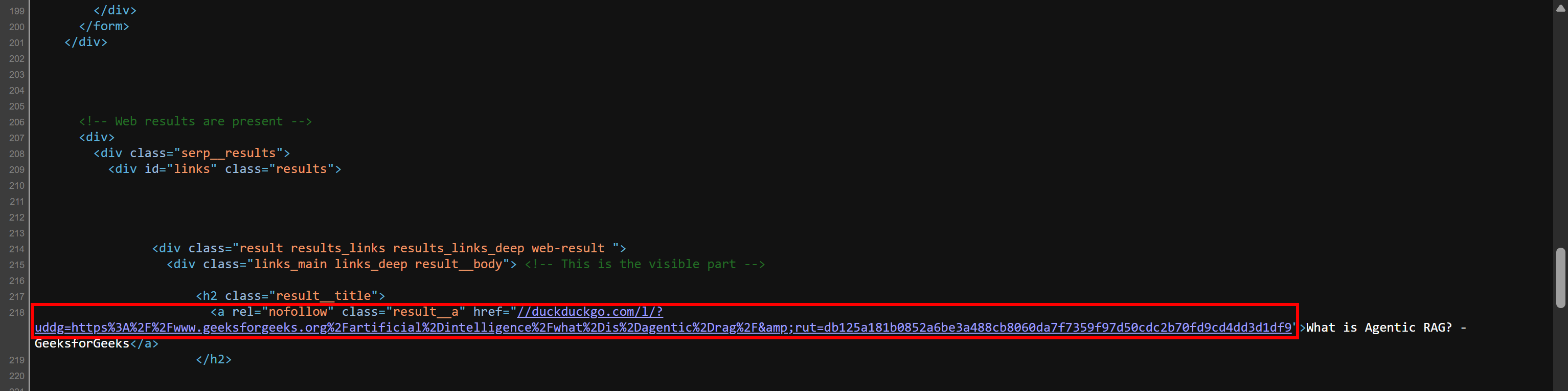
Ahora, con los campos de datos extraídos, cree un diccionario para cada resultado de búsqueda y añádalo a la lista serp_results:
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result) ¡Perfecto! Tu lógica de Scraping web de DuckDuckGo está completa. Solo queda exportar los datos rastreados.
Paso n.º 6: exportar los datos extraídos a CSV
En este punto, tienes los resultados de búsqueda de DuckDuckGo almacenados en una lista de Python. Para que otros equipos o herramientas puedan utilizar esos datos, expórtalos a un archivo CSV utilizando la biblioteca csv integrada en Python:
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Escribir el encabezado
writer.writeheader()
# Escribir todas las filas de datos
writer.writerows(serp_results)No olvides importar csv:
import csvDe esta manera, tu Scraper de DuckDuckGo generará un archivo de salida llamado duckduckgo_results.csv que contiene todos los resultados extraídos en formato CSV. ¡Misión cumplida!
Paso n.º 7: Ponlo todo junto
El código final contenido en scraper.py es:
import requests
from bs4 import BeautifulSoup
import csv
# URL base de la versión estática de DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Ejemplo de consulta de búsqueda
search_query = "agentic rag"
# Para simular una solicitud del navegador y evitar errores 403
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Conectarse a la página SERP de destino
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)
# Recuperar el contenido HTML de la respuesta
html = response.text
# Analizar el HTML
soup = BeautifulSoup(html, "html.parser")
# Buscar todos los contenedores de resultados
result_elements = soup.select("#links .result")
# Dónde almacenar los datos extraídos
serp_results = []
# Iterar sobre cada resultado SERP y extraer datos de él
for result_element in result_elements:
# Lógica de parseo de datos
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)
# Rellenar un nuevo objeto de resultado SERP y añadirlo a la lista.
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)
# Exportar los datos extraídos a CSV
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Escribir el encabezado
writer.writeheader()
# Escribir todas las filas de datos
writer.writerows(serp_results)¡Vaya! En menos de 65 líneas de código, acabas de crear un script para extraer datos de DuckDuckGo.
Ejecútalo con este comando:
python Scraper.pyEl resultado será un archivo duckduckgo_results.csv, que aparecerá en la carpeta de tu proyecto. Ábrelo y deberías ver los datos extraídos de esta manera:

¡Et voilà! Has transformado los resultados de búsqueda no estructurados de una página web de DuckDuckGo en un archivo CSV estructurado.
[Extra] Integra proxies rotativos para evitar bloqueos
El Scraper anterior funciona bien para pequeñas ejecuciones, pero no se puede ampliar mucho. Esto se debe a que DuckDuckGo comenzará a bloquear tus solicitudes si detecta demasiado tráfico procedente de la misma IP. Cuando eso ocurre, sus servidores comienzan a devolver páginas de error 403 Prohibido que contienen un mensaje como este:
Si esto persiste, envíenos un correo electrónico a <a href="mailto:[email protected]?subject=Error getting results">email us</a>.<br />
Nuestra dirección de correo electrónico de asistencia incluye un código de error anónimo que nos ayuda a comprender el contexto de su búsqueda.Esto significa que el servidor ha identificado su solicitud como automatizada y la ha bloqueado, generalmente debido a un problema de limitación de velocidad. Para evitar bloqueos, debe rotar su dirección IP.
La solución es enviar las solicitudes a través de un Proxy rotativo. Si desea obtener más información sobre este mecanismo, consulte nuestra guía sobre cómo rotar una dirección IP.
Bright Data ofrece proxies rotativos respaldados por una red de más de 150 millones de IP. ¡Descubra cómo integrarlos en su Scraper de DuckDuckGo para evitar bloqueos!
Siga la guía oficial de configuración del Proxy y obtendrá una cadena de conexión de Proxy similar a esta:
<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335
Configura el Proxy en Solicitudes, como se muestra a continuación:
proxy_url = "http://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
# definición de parámetros y encabezados...
response = requests.get(
base_url,
params=params,
headers=headers,
proxies=proxies, # enruta la solicitud a través del Proxy rotativo
verify=False,
)Nota: verify=False deshabilita la verificación del certificado SSL. Esto evitará errores relacionados con la validación del certificado del Proxy, pero no es seguro. Para una implementación más lista para la producción, consulte nuestra página de documentación sobre la validación de certificados SSL.
Ahora sus solicitudes GET a DuckDuckGo se enrutarán a través de la red de 150 millones de Proxies residenciales IP de Bright Data, lo que garantiza una IP nueva cada vez y le ayuda a evitar bloqueos relacionados con la IP.
Enfoque n.º 2: confiar en una biblioteca de scraping de DuckDuckGo como DDGS
En esta sección, aprenderá a utilizar la biblioteca DDGS. Este proyecto de código abierto, con más de 1800 estrellas en GitHub, se conocía anteriormente como duckduckgo-search porque se centraba específicamente en DuckDuckGo. Recientemente, se ha renombrado como DDGS (Dux Distributed Global Search), ya que ahora también es compatible con otros motores de búsqueda.
Aquí veremos cómo utilizarlo desde la línea de comandos para extraer los resultados de búsqueda de DuckDuckGo.
Paso n.º 1: Instalar DDGS
Instala DDGS globalmente o dentro de un entorno virtual a través del paquete ddgs PyPI:
pip install -U ddgsUna vez instalado, puede acceder a él a través de la herramienta de línea de comandos ddgs. Verifique la instalación ejecutando:
ddgs --helpEl resultado debería ser similar a este:
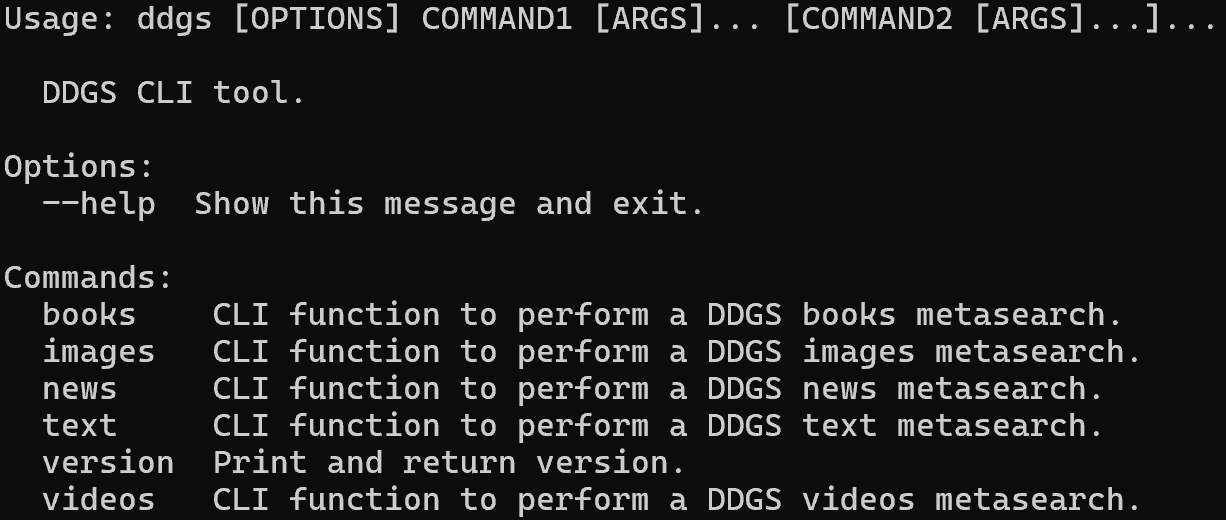
Como puede ver, la biblioteca admite varios comandos para extraer diferentes tipos de datos (por ejemplo, texto, imágenes, noticias, etc.). En este caso, utilizará el comando text, que se centra en los resultados de búsqueda de las SERP.
Nota: También puede llamar a esos comandos a través de la API DDGS en código Python, tal y como se explica en la documentación.
Paso n.º 2: Utilice DDGS a través de la CLI para el Scraping web de DuckDuckGo
En primer lugar, familiarícese con el comando text ejecutando:
ddgs text --helpEsto mostrará todos los indicadores y opciones compatibles:
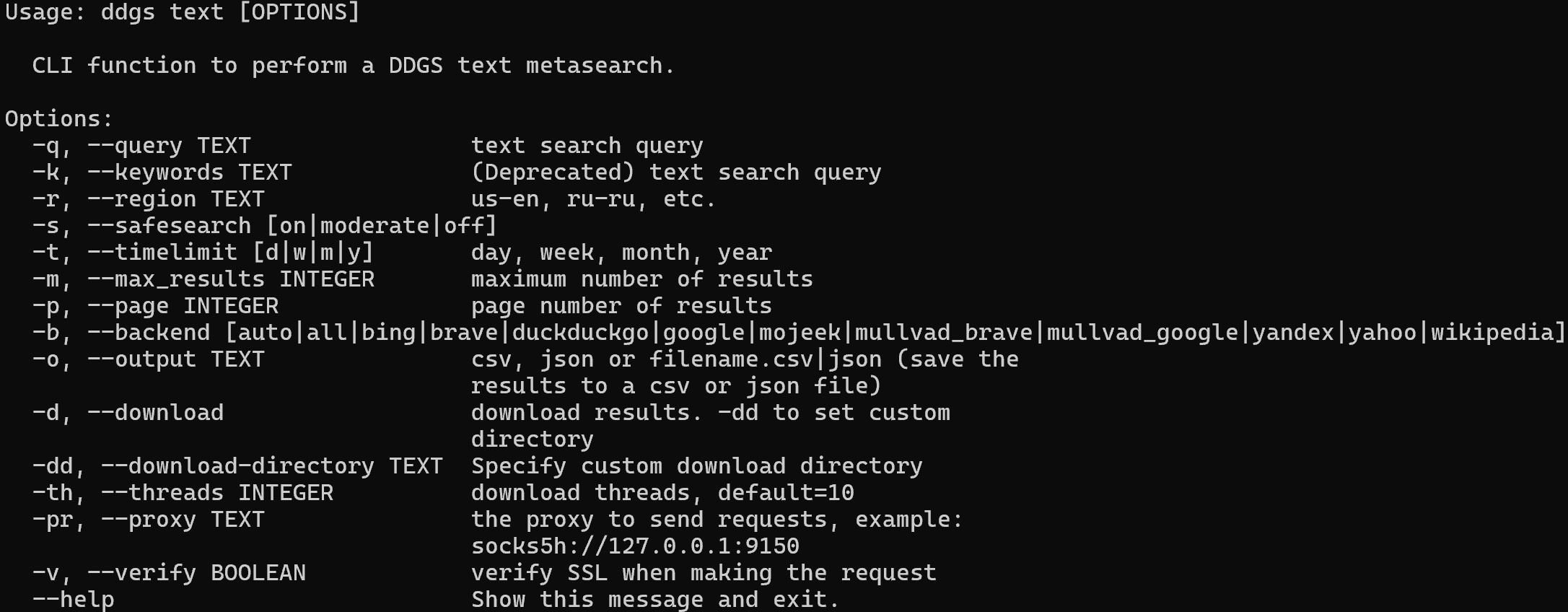
Para extraer los resultados de búsqueda de DuckDuckGo para «agentic rag» y exportarlos a un archivo CSV, ejecute:
ddgs text -q «agentic rag» -b duckduckgo -o duckduckgo_results.csvEl resultado será un archivo duckduckgo_results.csv. Ábralo y debería ver algo como esto:

¡Increíble! Ha obtenido los mismos resultados de búsqueda que con el Scraper personalizado de Python DuckDuckGo, pero con un solo comando CLI.
[Extra] Integrar un Proxy rotativo
Como acaba de ver, DDGS es una herramienta de búsqueda SERP y de Scraping web extremadamente potente. Sin embargo, no es mágica. En proyectos de scraping a gran escala, se encontrará con las mismas prohibiciones y bloqueos de IP mencionados anteriormente.
Para evitar estos problemas, al igual que antes, necesitas un Proxy rotativo. No es de extrañar que DDGS venga con soporte nativo para la integración de proxies a través del indicador -pr (o --proxy).
Recupera la URL de tu Proxy rotativo de Bright Data y configúrala en tu comando ddgs CLI de la siguiente manera:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv -pr <BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335¡Listo! Las solicitudes web subyacentes realizadas por la biblioteca ahora se enrutarán a través de la red de Proxy rotativos de Bright Data. Esto le permite realizar el scraping web de forma segura sin preocuparse por los bloqueos relacionados con la IP.
Enfoque n.º 3: uso de la API SERP de Bright Data
En este capítulo, aprenderá a utilizar la API SERP todo en uno de Bright Data para recuperar mediante programación los resultados de búsqueda de la versión dinámica de DuckDuckGo. Siga las instrucciones que se indican a continuación para empezar.
Nota: Para una configuración simplificada y más rápida, asumimos que ya tiene un proyecto Python con la biblioteca de solicitudes instalada.
Paso n.º 1: Configure su zona de API SERP de Bright Data
En primer lugar, crea una cuenta de Bright Data o inicia sesión si ya tienes una. A continuación, se te guiará a través del proceso de configuración del producto API SERP para el scraping de DuckDuckGo.
Para una configuración más rápida, también puede consultar la guía oficial de «Inicio rápido» de la API SERP. De lo contrario, continúe con los siguientes pasos.
Una vez que hayas iniciado sesión, ve a tu cuenta de Bright Data y haz clic en la opción «Proxies y scraping» para llegar a esta página:
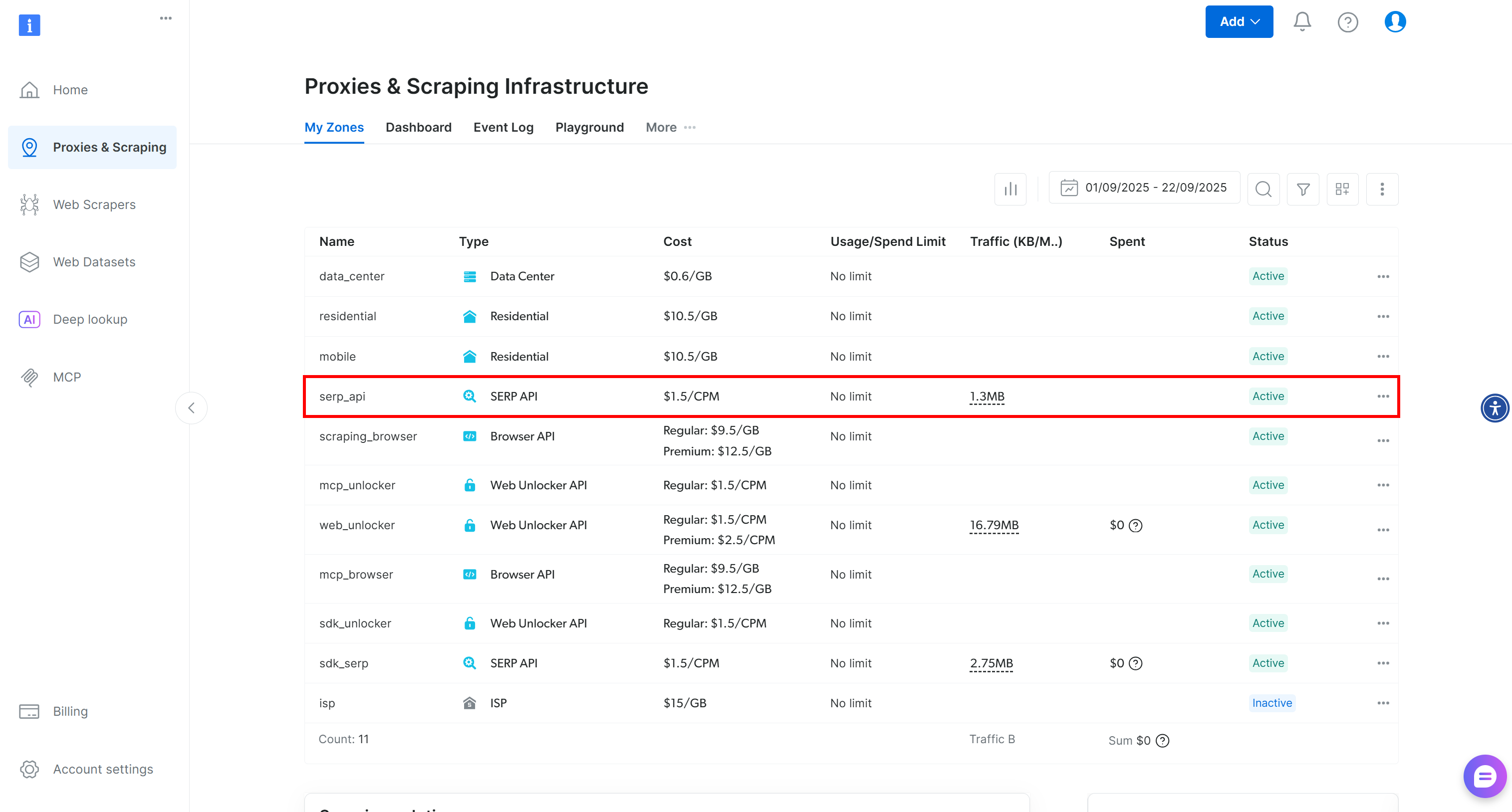
Compruebe la tabla «Mis zonas», que muestra los productos de Bright Data que ha configurado. Si ya existe una zona API SERP activa, ya está listo para empezar. Solo tiene que copiar el nombre de la zona (serp_api, en este caso), ya que lo necesitará más adelante.
Si no existe ninguna zona, desplácese hacia abajo hasta la sección «Soluciones de scraping» y haga clic en el botón «Crear zona» de la tarjeta «API SERP»:
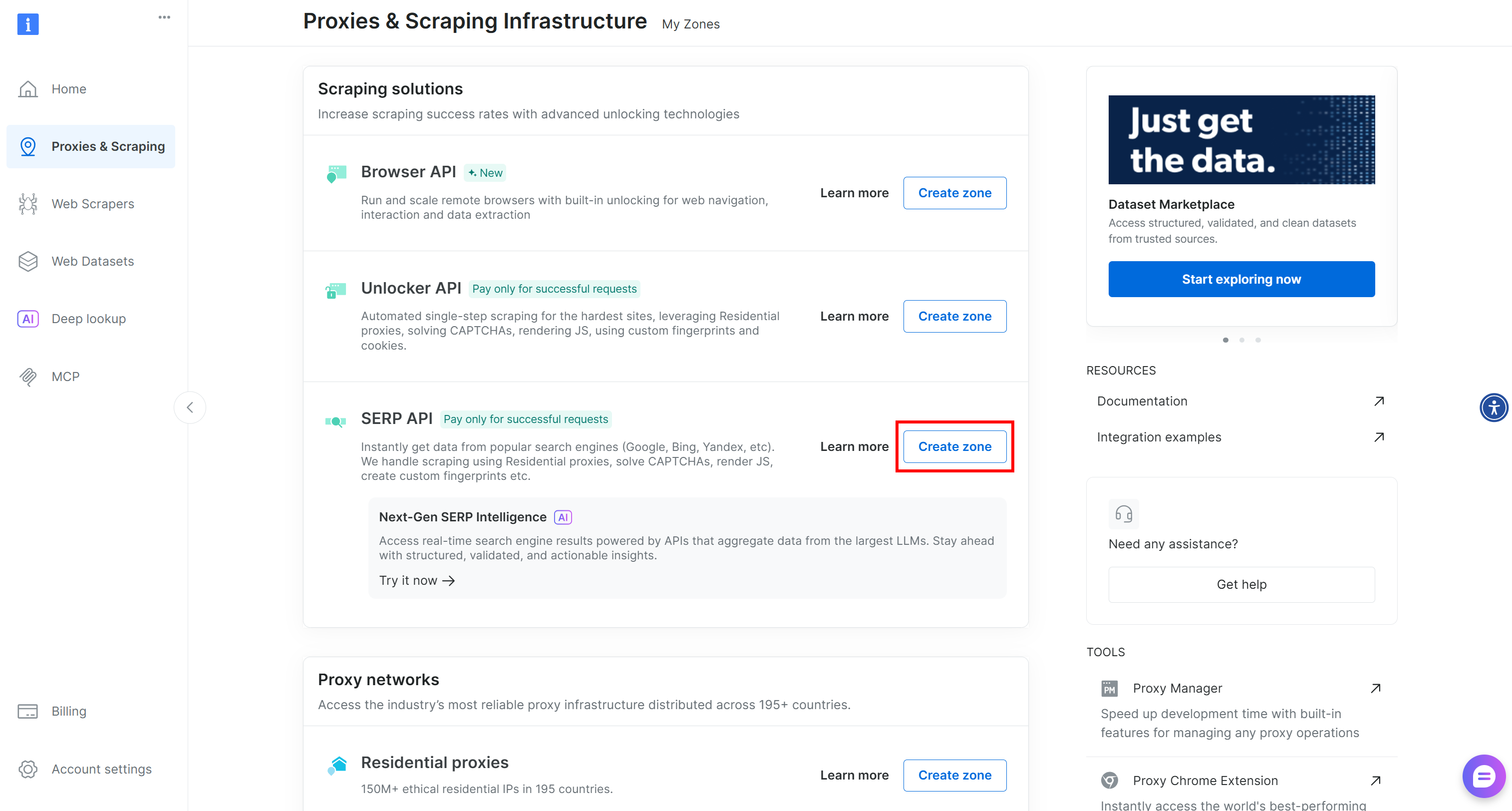
Asigne un nombre a su zona (por ejemplo, API SERP) y pulse «Añadir»:
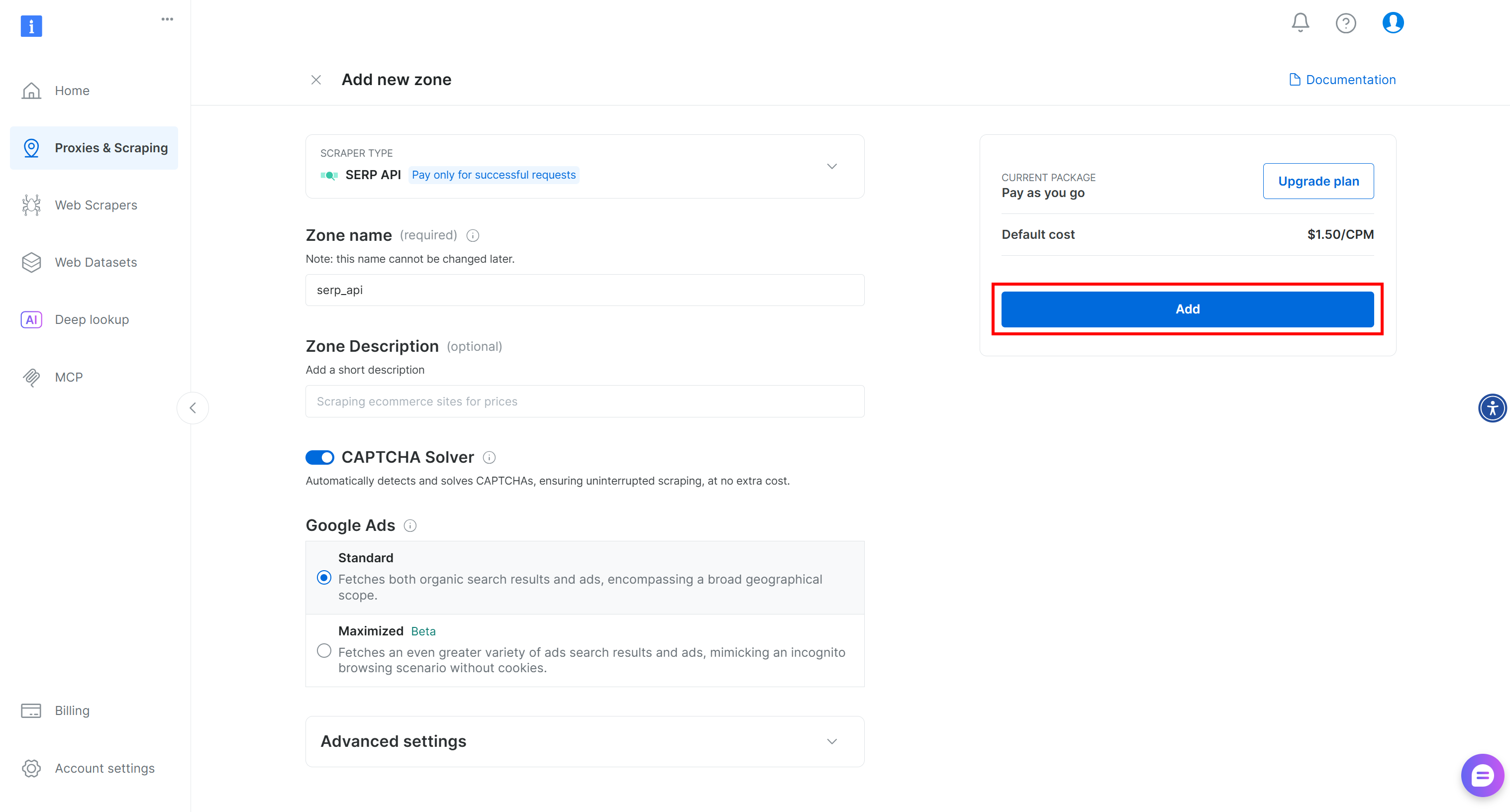
A continuación, vaya a la página de productos de la Zona y asegúrese de que está habilitada cambiando el interruptor a «Active»:
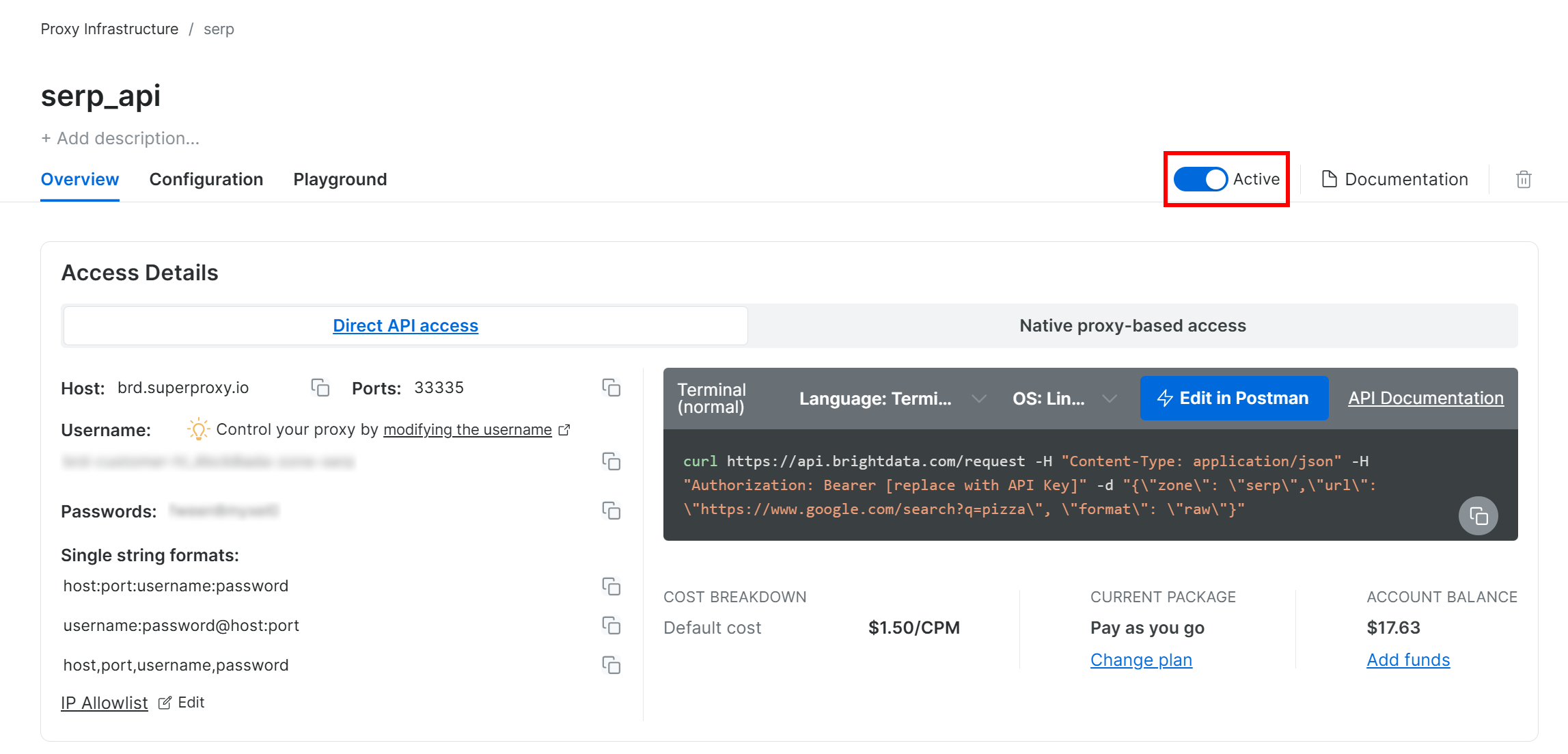
¡Genial! Ya ha configurado correctamente la API SERP de Bright Data.
Paso n.º 2: Recupera tu clave API de Bright Data
La forma recomendada de autenticar las solicitudes de la API SERP es utilizando su clave API de Bright Data. Si aún no ha generado una, siga la guía oficial para obtenerla.
Al realizar una solicitud POST a la API SERP, incluya la clave API en el encabezado de autorización de la siguiente manera para la autenticación:
«Authorization: Bearer <BRIGHT_DATA_API_KEY>»¡Genial! Ahora ya tiene todos los elementos necesarios para llamar a la API SERP de Bright Data en un script de Python (o a través de cualquier otro cliente HTTP).
Paso n.º 3: Llama a la API SERP
Junte todo y llame a la API SERP de Bright Data en la página de búsqueda «agentic rag» de DuckDuckGo con este fragmento de Python:
# pip install requests
import requests
# Credenciales de Bright Data (TODO: reemplazar con sus valores)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"
# Tu página de búsqueda DuckDuckGo de destino
duckduckgo_page_url = "https://duckduckgo.com/?q=agentic+rag"
# Realizar una solicitud a la API SERP de Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zona": bright_data_serp_api_zona_name,
"url": duckduckgo_page_url,
"format": "raw"
})
# Acceder al HTML renderizado desde la versión dinámica de DuckDuckGo
html = response.text
# Lógica de parseo...Para ver un ejemplo más completo, consulte el «Proyecto Python de la API SERP de Bright Data» en GitHub.
Ten en cuenta que, en esta ocasión, la URL de destino puede ser la versión dinámica de DuckDuckGo (por ejemplo, https://duckduckgo.com/?q=agentic+rag). La API SERP se encarga de la representación de JavaScript, se integra con la red de proxies de Bright Data para la rotación de IP y gestiona otras medidas antiscraping, como las huellas digitales del navegador y los CAPTCHA. Por lo tanto, no habrá problemas al extraer SERP dinámicas.
La variable html contendrá el HTML completamente renderizado de la página DuckDuckGo. Verifíquelo imprimiendo el HTML con:
print(html)Obtendrá algo como esto:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agentic RAG en DuckDuckGo</title>
<!-- Omitido por brevedad ... -->
</head>
<body>
<div class="site-wrapper" style="min-height: 825px;">
<div id="content">
<div id="duckassist-answer" class="answer-container">
<DIV class="answer-content-block">
<P class="answer-text">
<SPAN class="highlight">Agentic RAG</SPAN> es una versión avanzada de Retrieval-Augmented Generation (RAG) que permite a los agentes de IA gestionar dinámicamente cómo recuperan y utilizan la información, mejorando su capacidad para responder a consultas en tiempo real y adaptarse a situaciones cambiantes. Este enfoque mejora la precisión y la capacidad de toma de decisiones de los sistemas de IA al integrar el razonamiento con la recuperación de datos.
</P>
<!-- Omitido por brevedad... -->
</DIV>
<!-- Omitido por brevedad... -->
</DIV>
<ul class="results-list">
<li class="result-item">
<article class="result-card">
<div <!-- Omitido por brevedad... -->
<div class="result-body">
<h2 class="result-title">
<a href="https://www.geeksforgeeks.org/artificial-intelligence/what-is-agentic-rag/" rel="noopener" target="_blank" class="result-link">
<span class="title-text">¿Qué es Agentic RAG? - GeeksforGeeks</span>
</a>
</h2>
<div class="result-snippet-container">
<div class="result-snippet">
<div>
<span class="snippet-text">
<span class="snippet-date">8 de septiembre de 2026</span>
<span>
<b>La arquitectura Agentic RAG</b> está diseñada para maximizar la adaptabilidad y la inteligencia mediante el aprovechamiento de agentes autónomos y la integración de herramientas especializadas. En esencia, la arquitectura organiza los agentes de razonamiento, cada uno de los cuales es capaz de tomar decisiones, planificar y recuperar información, en un sistema coordinado. Veamos los componentes clave de la arquitectura <b>Agentic RAG</b>. 1.
</span>
</span>
</div>
</div>
</div>
</div>
</article>
</li>
<!-- Otros resultados de búsqueda ... -->
</ul>
<!-- Omitido por brevedad ... -->
</div>
<!-- Omitido por brevedad ... -->
</div>
</body>
</html>Nota: El HTML resultante también puede incluir el resumen generado por la IA «Search Assist», ya que se trata de la versión dinámica de la página.
Ahora, realice el parseo de este HTML como se muestra en el primer enfoque para acceder a los datos de DuckDuckGo que necesita.
Enfoque n.º 4: integración de una herramienta de scraping de DuckDuckGo en un agente de IA a través de MCP
Recuerde que el producto API SERP también está disponible a través de la herramienta search_engine disponible en Bright Data Web MCP.
Ese servidor MCP de código abierto proporciona acceso de IA a las soluciones de recuperación de datos web de Bright Data, incluidas las capacidades de scraping de DuckDuckGo. En concreto, la herramienta search_engine está disponible en el nivel gratuito de Web MCP, por lo que puede integrarla en sus agentes de IA o flujos de trabajo sin ningún coste.
Para integrar el MCP web en su solución de IA, generalmente necesita tener Node.js instalado localmente y un archivo de configuración como este:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}Por ejemplo, esta configuración funciona con Claude Code. Descubre otras integraciones en la documentación.
Gracias a esta integración, podrás recuperar datos SERP en lenguaje natural y utilizarlos en tus flujos de trabajo o agentes basados en IA.
Conclusión
En este tutorial, has visto los cuatro métodos recomendados para extraer datos de DuckDuckGo:
- A través de un Scraper personalizado
- Utilizando DDGS
- Con la API de búsqueda de DuckDuckGo
- Gracias a Web MCP
Como se ha demostrado, la única forma fiable de extraer datos de DuckDuckGo a gran escala y evitar bloqueos es utilizando una solución de extracción estructurada respaldada por una sólida tecnología anti-bot y una gran red de Proxies, como Bright Data.
¡Crea una cuenta gratuita en Bright Data y empieza a explorar nuestras soluciones de scraping!