

Google Flights es un servicio de reservas de vuelos ampliamente utilizado que proporciona gran cantidad de datos, como precios de vuelos, horarios y detalles de las aerolíneas. Lamentablemente, Google no ofrece una API pública para acceder a estos datos. Sin embargo, el raspado web puede ser una excelente alternativa para extraer estos datos.
En este artículo, te mostraré cómo crear un raspador de Google Flights potente con Python. Repasaremos cada paso para asegurarnos de que todo quede claro.
¿Por qué extraer datos de Google Flights?
Extraer datos de Google Flights ofrece varias ventajas, entre ellas:
- Seguir los precios de los vuelos a lo largo del tiempo.
- Analizar las tendencias de precios.
- Identificar los mejores momentos para reservar vuelos.
- Comparar precios entre diferentes fechas y compañías aéreas.
A los viajeros, les permite encontrar las mejores ofertas y ahorrar dinero. A las empresas, les ayuda en el análisis de mercado, la inteligencia competitiva y el desarrollo de estrategias de precios eficaces.
Creación del Raspador de Google Flights
El rascador que desarrollamos te permite introducir datos como el aeropuerto de salida, el destino, la fecha de viaje y el tipo de billete (de ida o de ida y vuelta). Si vas a reservar un viaje de ida y vuelta, también tendrás que indicar una fecha de regreso. El raspador se encargará del resto: carga todos los vuelos disponibles, extrae los datos y guarda los resultados en un archivo JSON para su posterior análisis.
Si no tienes experiencia en el raspado web con Python, echa un vistazo a este tutorial para empezar.
1. ¿Qué datos puedes extraer de Google Flights?
Google Flights proporciona una gran cantidad de datos, incluidos los nombres de las aerolíneas, las horas de salida y llegada, la duración total, el número de paradas, los precios de los billetes y los datos sobre el impacto ambiental (por ejemplo, las emisiones de CO₂).
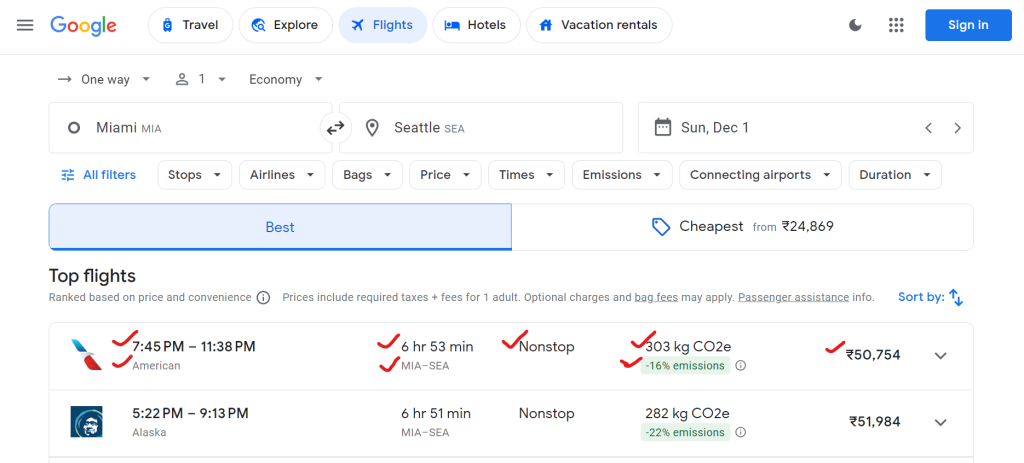
He aquí un ejemplo de los datos que puedes extraer:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2. Configurar el entorno
Primero, configuremos el entorno de tu sistema para ejecutar el raspador.
# Create a virtual environment (optional)
python -m venv flight-scraper-env
# Activate the virtual environment
# On Windows:
.flight-scraper-envScriptsactivate
# On macOS/Linux:
source flight-scraper-env/bin/activate
# Install required packages
pip install playwright tenacity asyncio
# Install Playwright browsers
playwright install chromium
Playwright es ideal para automatizar navegadores e interactuar con páginas web dinámicas, como Google Flights. Usamos Tenacity para implementar un mecanismo de reintento.
Si no tienes experiencia con Playwright, consulta la guía de Raspado web con Playwright.
3. Definir las clases de datos
Al usar la clase de datos de Python, puedes estructurar ordenadamente los parámetros de búsqueda y los datos de vuelo.
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
Aquí, la clase SearchParameters almacena los datos de la búsqueda de vuelos, como la salida, el destino, las fechas y el tipo de billete, mientras que la clase FlightData almacena datos sobre cada vuelo, incluida la aerolínea, el precio, las emisiones de CO₂ y otros detalles relevantes.
4. La lógica del raspador en la clase FlightScraper
La lógica principal de raspado se encuentra encapsulada en la clase FlightScraper. Este es un desglose detallado:
4.1 Definir los selectores CSS
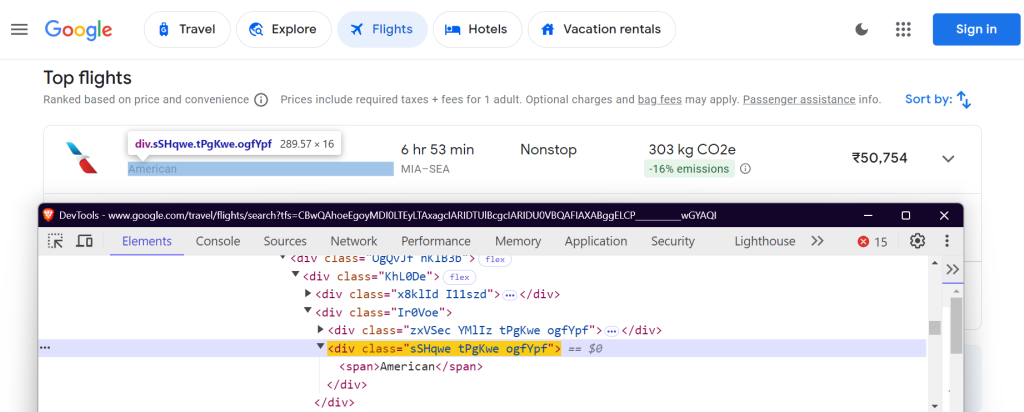
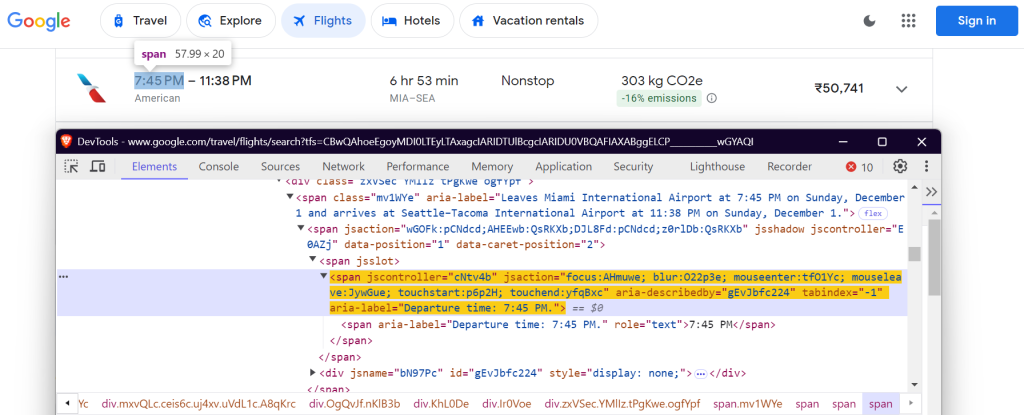
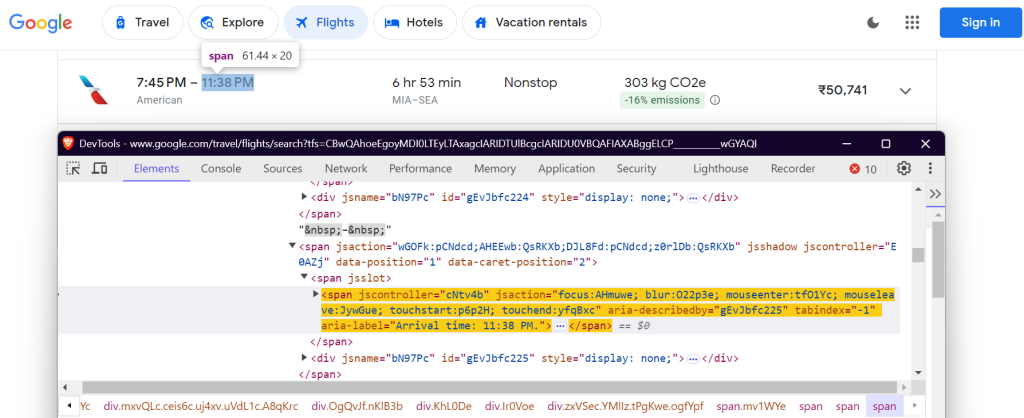
Debes localizar elementos específicos en la página de Google Flights para extraer los datos. Esto se hace mediante selectores de CSS. Así es como se definen los selectores en la clase FlightScraper:
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
"departure_time": 'span[aria-label^="Departure time"]',
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
"stops": "div.hF6lYb span.rGRiKd",
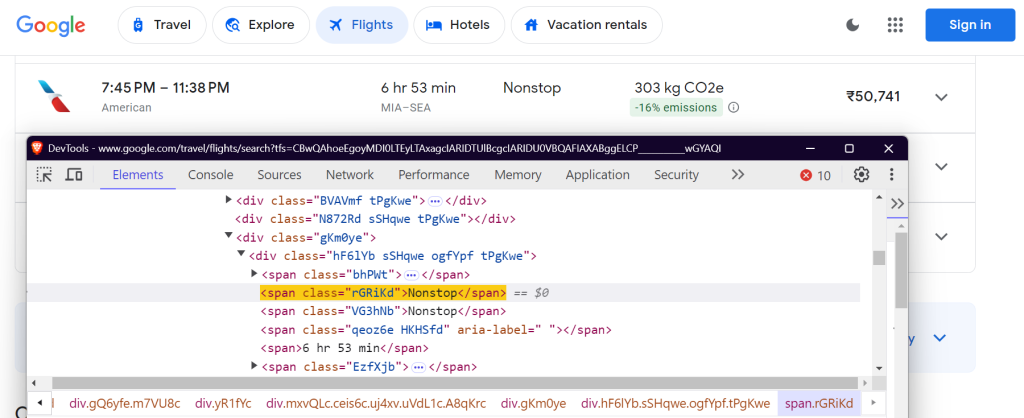
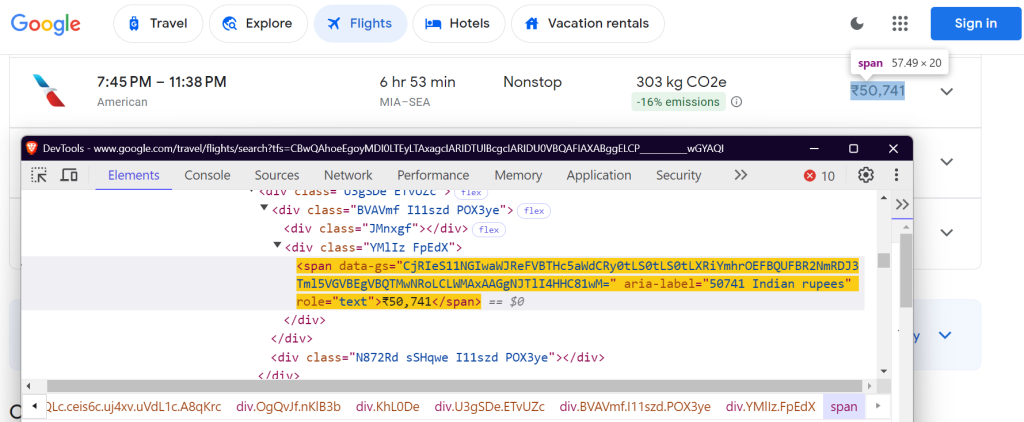
"price": "div.FpEdX span",
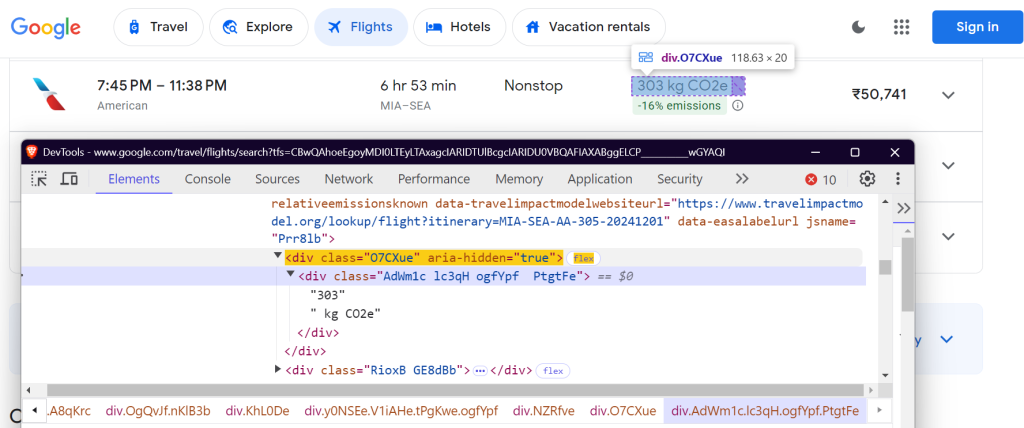
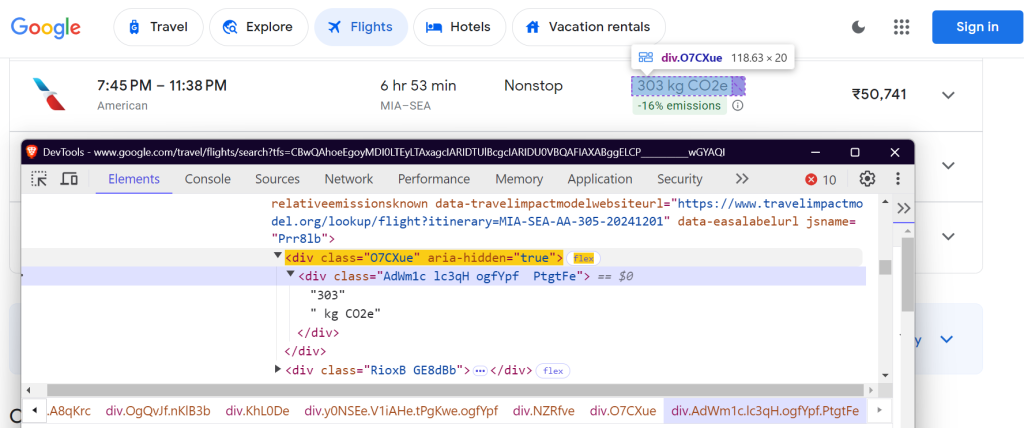
"co2_emissions": "div.O7CXue",
"emissions_variation": "div.N6PNV",
}
Estos selectores se centran en el nombre de la aerolínea, los horarios de los vuelos, la duración, las paradas, el precio y los datos sobre emisiones.
Nombre de la aerolínea:
Hora de salida:
Hora de llegada:
Duración del vuelo:

Número de paradas:
Precio:
CO₂e:
Variación de las emisiones de CO₂:
4.2 Cumplimentación del formulario de búsqueda (Filling the Search Form)
El método _fill_search_form simula la cumplimentación del formulario de búsqueda con los datos de salida, destino y fecha:
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# First, let's pick our ticket type
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# Now, let's fill in our departure and destination
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... rest of the form filling code
4.3 Carga de todos los resultados
Google Flights usa la paginación para cargar los vuelos. Debes hacer clic en el botón «Mostrar más vuelos» para cargar todos los vuelos disponibles:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 Extraer datos de vuelo
Una vez cargados los vuelos, puedes buscar los datos del vuelo:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5. Incorporar un mecanismo de reintento
Para que nuestro raspador sea más fiable, añadiremos una lógica de reintento mediante la biblioteca tenacity:
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... rest of the search implementation
6. Guardar los resultados extraídos
Guarda los datos de vuelo extraídos en un archivo JSON para analizarlos en el futuro.
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7. Ejecutar el raspador
Así es como se ejecuta el raspador de Google Flights:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"Successfully found {len(flights)} flights")
except Exception as e:
print(f"Error during flight search: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
Resultados finales
Tras ejecutar el raspador, los datos de tu vuelo se guardarán en un archivo JSON con el siguiente aspecto:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6 hr 53 min",
"stops": "Nonstop",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% emissions"
},
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
},
{
"airline": "Alaska",
"departure_time": "9:00 AM",
"arrival_time": "12:40 PM",
"duration": "6 hr 40 min",
"stops": "Nonstop",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% emissions"
}
]
}
Puedes encontrar el código completo en mi GitHub Gist.
Problemas habituales al ampliar el raspado de Google Flights
A la hora de escalar el scraping de datos de Google Flights, son comunes los problemas como el bloqueo de IP y los CAPTCHA . Por ejemplo, si envías demasiadas solicitudes en poco tiempo utilizando un raspador, los sitios web pueden bloquear tu dirección IP. Para evitarlo, puedes utilizar la rotación manual de IP u optar por uno de los principales servicios de proxy. Si no tienes claro qué tipo de proxy es el más adecuado para tu caso, consulta nuestra guía sobre los mejores proxies para raspado web.
Otro reto es el manejo de CAPTCHA. Los sitios web suelen utilizarlos cuando sospechan de tráfico bot y bloquean tu raspador hasta que se resuelva el CAPTCHA. Gestionarlo manualmente lleva mucho tiempo y es complejo.
Entonces, ¿cuál es la solución? ¡Veámoslo a fondo!
La solución: herramientas de raspado web de Bright Data
Bright Data ofrece una gama de soluciones diseñadas para simplificar y escalar tus esfuerzos de raspado web de manera eficiente. Analicemos cómo Bright Data puede ayudarte a superar estos problemas comunes.
1. Proxies residenciales
Los proxies residenciales de Bright Data te ofrecen la posibilidad de acceder a sofisticados sitios web de destino y rasparlos. Los proxies residenciales permiten enrutar las solicitudes de raspado web a través de conexiones residenciales legítimas. Tus solicitudes aparecerán en los sitios web de destino como si procedieran de usuarios reales de una región o área específica. Como resultado, son una solución eficaz para acceder a páginas protegidas por medidas antiraspado basadas en IP.
2. Web Unlocker
Web Unlocker de Bright Data es ideal para proyectos de raspado que deben enfrentarse a CAPTCHA o restricciones. En lugar de tratar estos problemas manualmente, Web Unlocker los gestiona automáticamente, adaptándose a los cambios en los bloques del sitio con una alta tasa de éxito (normalmente del 100 %). Solo tienes que enviar una solicitud y Web Unlocker se encarga del resto.
3. Scraping Browser
Scraping Browser de Bright Data es otra potente herramienta para los desarrolladores que utilizan navegadores sin interfaz como Puppeteer o Playwright. A diferencia de los navegadores sin interfaz tradicionales, Scraping Browser gestiona la resolución de CAPTCHA, las huellas dactilares del navegador, los reintentos y mucho más, todo de forma automática, para que puedas centrarte en recopilar datos sin preocuparte de las restricciones del sitio web.
Conclusión
En este artículo se explica cómo extraer datos de Google Flights con Python y Playwright. Aunque el raspado manual puede ser eficaz, a menudo conlleva problemas como las prohibiciones de IP y la necesidad de un mantenimiento continuo de los scripts. Para simplificar y mejorar tu trabajo de recopilación de datos, considera la posibilidad de aprovechar las soluciones de Bright Data, como los proxies residenciales, Web Unlocker y Scraping Browser.
¡Regístrate hoy mismo para obtener una prueba gratuita con Bright Data!
Además, consulta nuestras guías sobre el raspado de otros servicios de Google, como Google Search Result Data, Google Trends, Google Scholar y Google Maps.





