

{
“@context”: “https://schema.org”,
“@type”: “HowTo”,
“name”: “Cómo hacer Scraping de Airbnb en 2026”,
“description”: “Cuatro formas de recopilar datos de listados de Airbnb en 2026, desde un Scraper manual de Python hasta una API Scraper gestionada y un conjunto de datos listo para usar.”,
“step”: [
{
“@type”: “HowToStep”,
“position”: 1,
“name”: “Scraping manual con Python”,
“text”: “Envía solicitudes con Python y parsea el HTML. Esto es útil para aprender, pero falla ante la capa anti-bot de Airbnb a gran escala.”
},
{
“@type”: “HowToStep”,
“position”: 2,
“name”: “Web Unlocker para páginas personalizadas”,
“text”: “Usa Bright Data Web Unlocker para obtener la página renderizada superando la detección de bots, luego parsea los campos que necesitas con tu propio código.”
},
{
“@type”: “HowToStep”,
“position”: 3,
“name”: “API Scraper de Airbnb”,
“text”: “Llama a la API Scraper de Airbnb para obtener registros de listados en JSON estructurado y limpio a cualquier volumen, sin parseo ni mantenimiento.”
},
{
“@type”: “HowToStep”,
“position”: 4,
“name”: “Conjunto de datos de Airbnb listo para usar”,
“text”: “Descarga un conjunto de datos de Airbnb listo para usar para datos masivos o históricos, sin necesidad de código ni scraping.”
}
]
}
Airbnb es una de las fuentes de datos más solicitadas en viajes e inmobiliaria, y una de las más difíciles de recopilar: las páginas están protegidas por una capa anti-bot y cambian con frecuencia, y en 2026 esos datos alimentan cada vez más modelos de precios dinámicos y agentes de IA que los necesitan frescos y estructurados. Esta guía muestra cuatro formas de obtenerlos, desde una solicitud Python simple hasta un conjunto de datos completamente gestionado, con código real y probado y salida en vivo para cada uno.
Qué cubre esta guía
- Las cuatro formas de extraer datos de Airbnb en 2026, y cuándo usar cada una
- Un Scraper manual de Python, y exactamente dónde falla
- Web Unlocker para páginas personalizadas, con código de parseo que tú controlas
- La API Scraper de Airbnb para JSON estructurado y limpio a cualquier volumen
- El conjunto de datos de Airbnb listo para usar para datos masivos e históricos
- Alimentar datos de Airbnb a un agente de IA a través del Web MCP
¿Listo para saltarte la construcción? Extrae listados en vivo ahora con la API Scraper de Airbnb, descarga un conjunto de datos de Airbnb listo para usar, o empieza gratis con 5.000 registros al mes y sin tarjeta de crédito.
Qué datos de Airbnb vale la pena recopilar
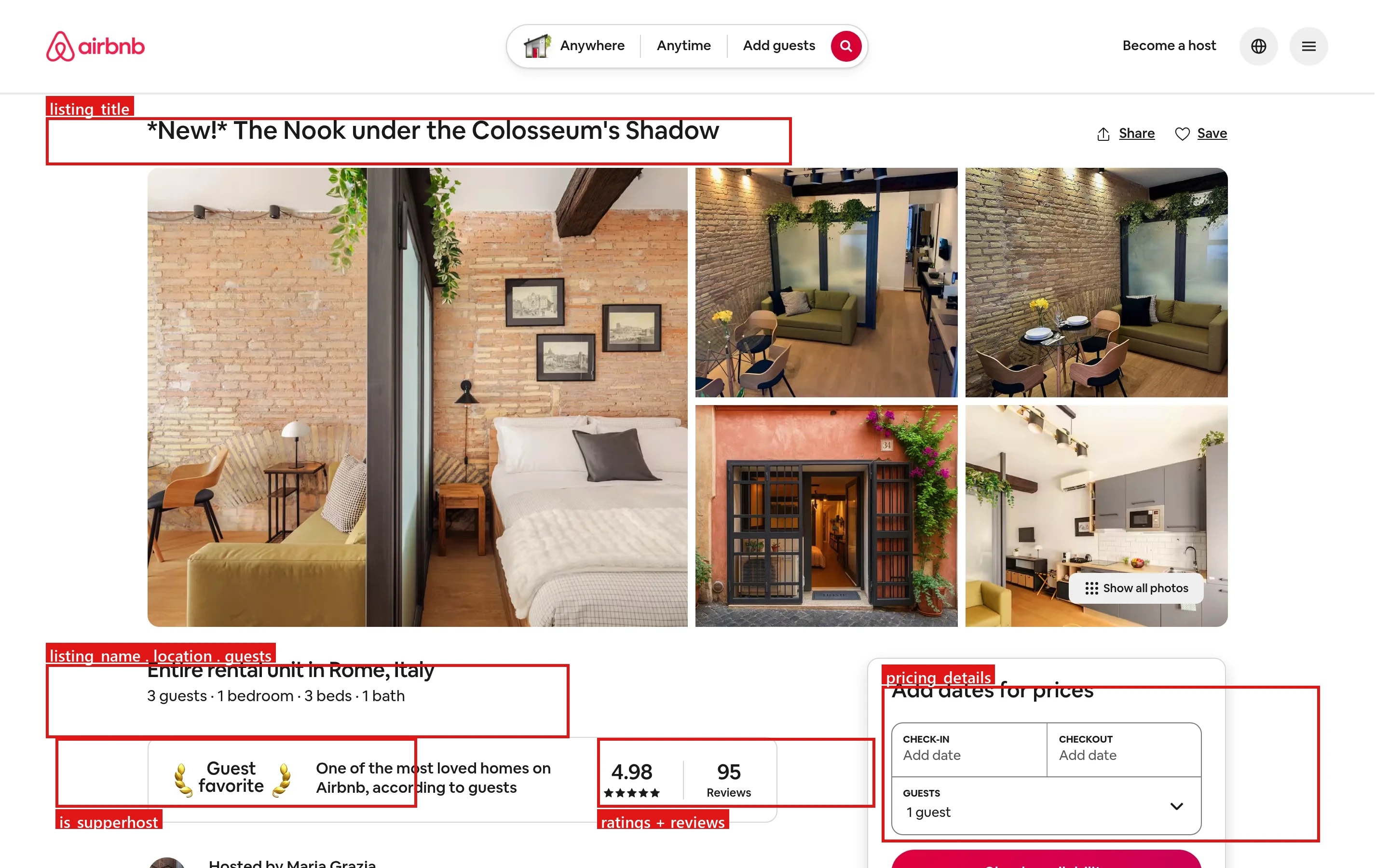
Un solo listado de Airbnb expone mucho más que un precio por noche. Los campos que importan para la mayoría de los proyectos son:
- Precios: tarifa por noche, total antes de impuestos, descuentos y tarifas de limpieza
- Disponibilidad: el calendario de reservas y los requisitos de noches mínimas
- Reseñas y valoraciones: puntuación general, número de reseñas y desglose por categorías
- Señales del anfitrión: estado de superanfitrión, tasa de respuesta e historial
- Detalles de la propiedad: capacidad, comodidades, coordenadas e imágenes
Cada uno de estos se corresponde con un elemento específico en la página del listado en vivo. Los recuadros rojos a continuación muestran de dónde provienen los campos estructurados:
Casos de uso comunes: evaluación de inversiones en alquileres de corta duración, precios dinámicos frente a la competencia local, análisis de ocupación y tendencias de mercado, y suministro de datos de ubicación limpios a pipelines de IA y analítica.
Los cuatro enfoques de un vistazo
| Enfoque | Esfuerzo | Escala | Mantenimiento | Ideal para |
|---|---|---|---|---|
| Python manual | Alto | Bajo | Alto | Aprendizaje, extracciones puntuales pequeñas |
| Web Unlocker | Medio | Medio | Medio | Parseo personalizado, páginas sin scraper preconstruido |
| API Scraper de Airbnb | Bajo | Alto | Ninguno | Datos de listados estructurados a cualquier volumen |
| Dataset de Airbnb | Ninguno | Masivo | Ninguno | Datos históricos o de todo el mercado, sin código |
El resumen honesto: el scraping manual es la forma más barata de aprender y la más cara de operar. Los otros tres trasladan las partes difíciles, desbloqueo, parseo y mantenimiento, a infraestructura gestionada.
Enfoque 1: Scraping manual, y dónde falla
Empieza por lo obvio: obtén la página de búsqueda con requests y parseala. Aquí está el intento completo.
import requests
url = "https://www.airbnb.com/s/Rome, Italy/homes"
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=30)
print("status:", resp.status_code)
print("DataDome anti-bot active:", "datadome" in resp.text.lower())Al ejecutarlo se muestra a lo que realmente te enfrentas:
status: 200
DataDome anti-bot active: TrueLa solicitud devuelve 200, pero cada respuesta está envuelta en la capa de detección de bots de DataDome. En algunos intentos obtienes una página de desafío sin listados, y en otros una sola solicitud pasa. Esa inconsistencia es el verdadero problema: en cuanto añades paginación, más ciudades o cualquier volumen real de solicitudes, DataDome marca el tráfico y te encuentras con CAPTCHAs, límites de velocidad y bloqueos de IP. Hacerlo confiable implica rotar proxies residenciales, una huella digital real del navegador, resolución automática de CAPTCHA y un parser que sobreviva a los frecuentes cambios de marcado de Airbnb. Eso es un proyecto de mantenimiento, no un script. Si quieres la ruta DIY, nuestra guía de scraping web con Python cubre los fundamentos. Los tres enfoques siguientes eliminan esa carga.
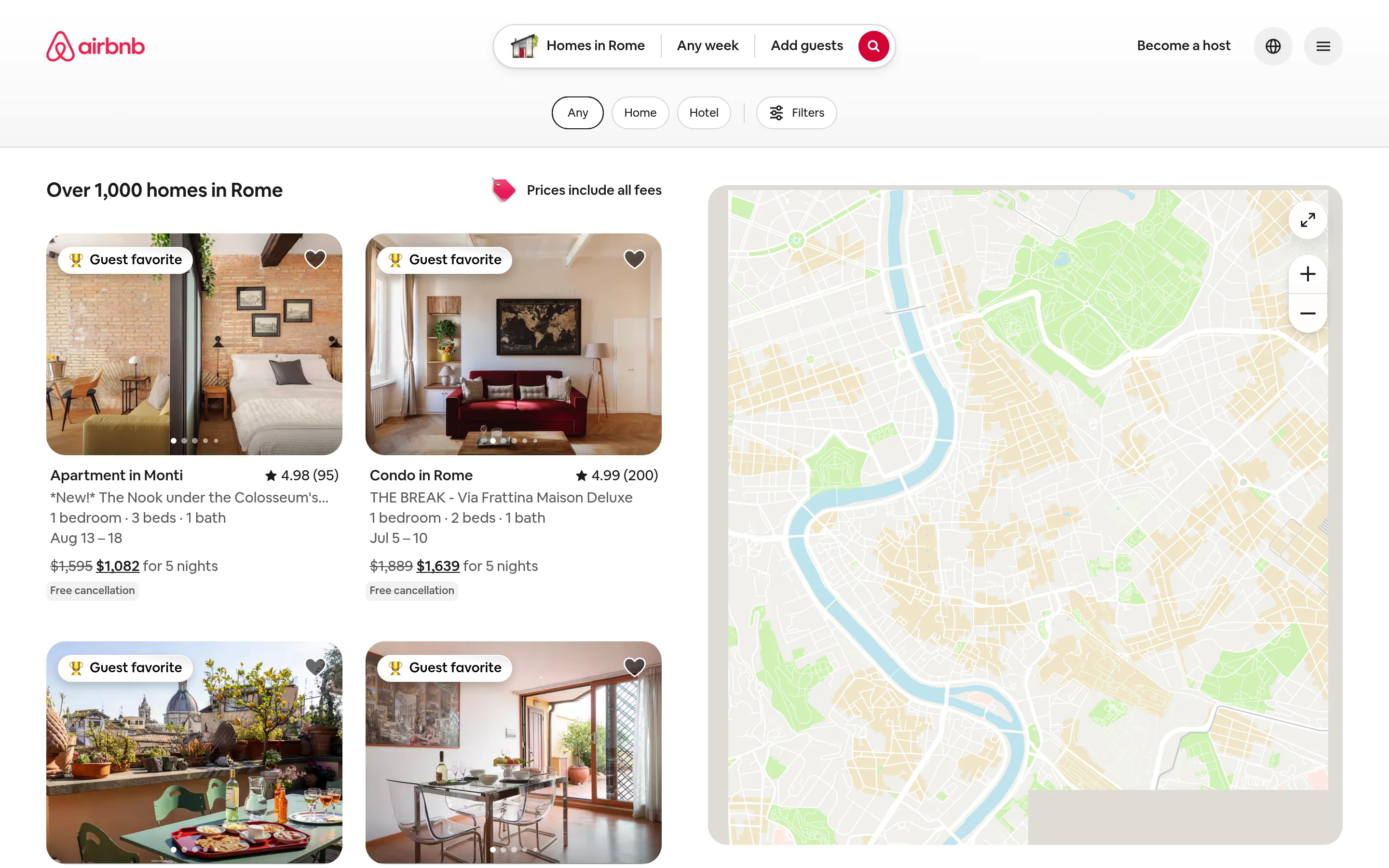
Enfoque 2: Web Unlocker para páginas personalizadas
Cuando necesitas la página sin procesar (por ejemplo, un tipo de página sin scraper preconstruido), Web Unlocker gestiona el desbloqueo y devuelve el HTML completamente renderizado. Tú sigues parseando los datos, lo que es el equilibrio correcto cuando quieres control total sobre la extracción.
Airbnb incrusta sus datos de listados como JSON dentro de la página, así que una vez que tienes el HTML puedes extraer campos directamente sin selectores CSS frágiles.
import os
import re
import requests
API = "https://api.brightdata.com/request"
payload = {
"zone": os.environ["BRIGHTDATA_UNLOCKER_ZONE"],
"url": "https://www.airbnb.com/s/Rome, Italy/homes",
"format": "raw",
"country": "us", # geo-target for consistent currency and language
}
headers = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}"}
html = requests.post(API, json=payload, headers=headers, timeout=120).text
names = re.findall(r'"localizedStringWithTranslationPreference":"([^"]+)"', html)
prices = re.findall(r'"accessibilityLabel":"([^"]*?$[d,]+[^"]*?)"', html)
print(len(set(names)), "listings parsed")
for name, price in list(zip(names[::2], prices))[:4]:
print("-", name, "|", price)Esto devuelve listados reales y parseados:
30 listings parsed
- *New!* The Nook under the Colosseum's Shadow | $1,082 for 5 nights, originally $1,595
- THE BREAK - Via Frattina Maison Deluxe | $1,639 for 5 nights, originally $1,889
- The Unique Home Pantheon | $1,064 for 5 nights, originally $1,481
- 360 penthouse overlooking central Rome | $3,010 for 5 nightsWeb Unlocker te permite superar la barrera y mantienes control total del parseo. El coste es que sigues siendo dueño de la lógica de extracción y debes actualizarla cuando Airbnb cambia la estructura de su página. Si todo lo que quieres son datos de listados limpios, la API Scraper elimina ese paso por completo.
Enfoque 3: La API Scraper de Airbnb
La API Scraper de Airbnb es un Scraper preconstruido. Envías URLs de listados o búsquedas y recibes JSON estructurado. Sin proxies, sin parseo, sin mantenimiento de marcado. Es parte de la API Web Scraper de Bright Data, que cubre más de 700 sitios.
El siguiente ejemplo recopila este listado exacto, el que puedes ver en vivo en Airbnb.
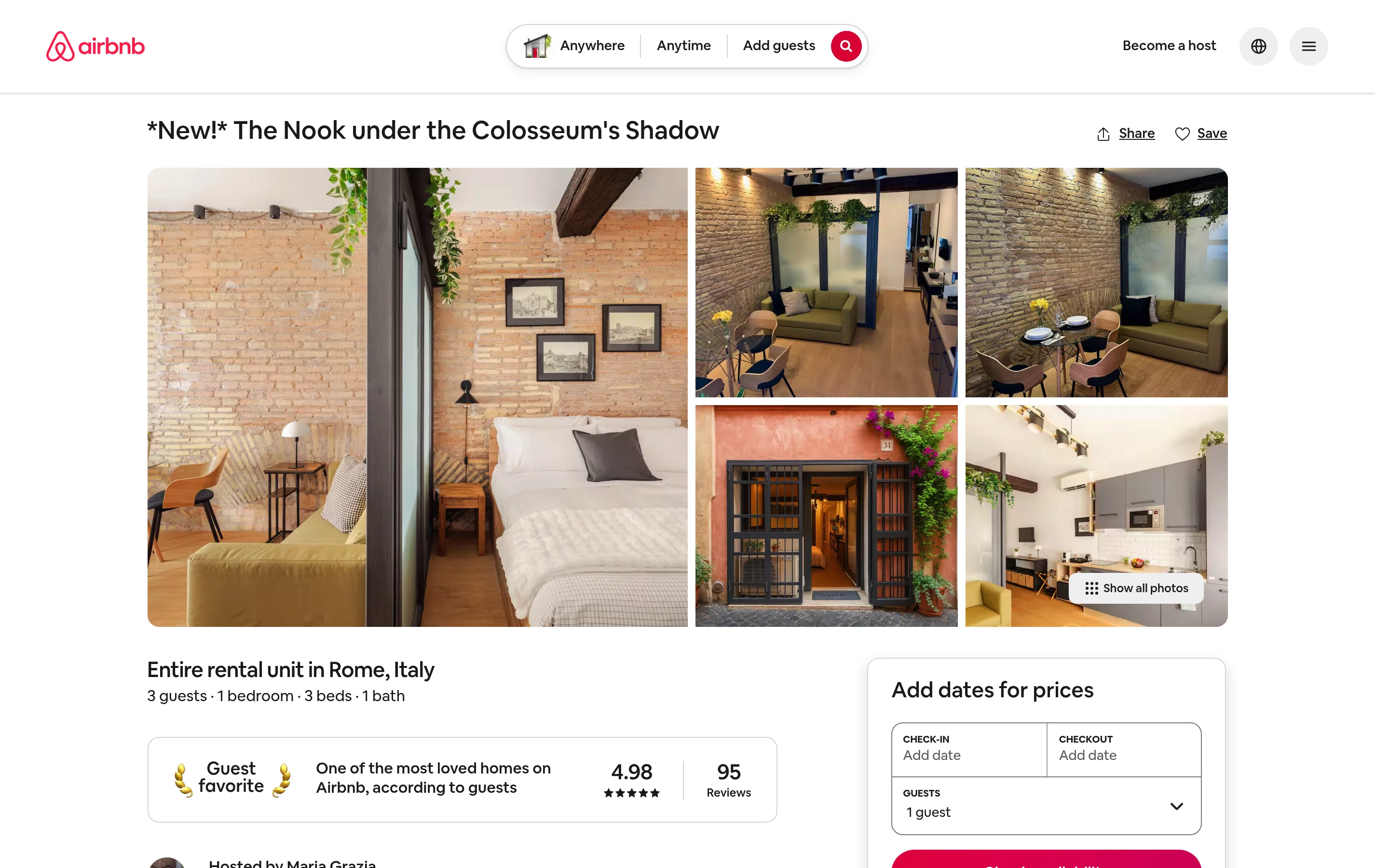
Para hasta 20 URLs, usa el endpoint síncrono y obtén resultados en una sola llamada.
import os
import requests
DATASET_ID = "gd_ld7ll037kqy322v05" # Airbnb Properties Information
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": "https://www.airbnb.com/rooms/1409274854260723534"}]},
timeout=180,
)
listing = resp.json()[0]
for field in ("listing_title", "ratings", "property_number_of_reviews",
"is_supperhost", "guests", "location", "lat", "long"):
print(f"{field}: {listing[field]}")
print("amenities:", len(listing["amenities"]), "| images:", len(listing["images"]),
"| available_dates:", len(listing["available_dates"]))La respuesta es un único registro limpio con 51 campos. Salida real para ese listado:
listing_title: *New!* The Nook under the Colosseum's Shadow
ratings: 4.98
property_number_of_reviews: 95
is_supperhost: True
guests: 3
location: Rome, Lazio, Italy
lat: 41.8949
long: 12.4895
amenities: 12 | images: 66 | available_dates: 185Sin lógica de parseo, sin gestión de proxies, y el esquema se mantiene estable incluso cuando Airbnb cambia su HTML. Esa es la diferencia entre hacer scraping de una página y consumir un producto de datos mantenido.
Para trabajos más grandes, cambia al endpoint asíncrono. Activas una recopilación, consultas el estado hasta que se completa, luego descargas. Esto escala a miles de URLs en un solo trabajo.
import os
import time
import requests
DATASET_ID = "gd_ld7ll037kqy322v05"
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
HEADERS = {"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"}
# 1. Trigger
urls = [
"https://www.airbnb.com/rooms/1409274854260723534",
"https://www.airbnb.com/rooms/667303913003951222",
# ... hundreds more
]
trigger = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
params={"dataset_id": DATASET_ID, "format": "json"},
headers=HEADERS,
json={"input": [{"url": u} for u in urls]},
)
snapshot_id = trigger.json()["snapshot_id"]
# 2. Poll until ready
while True:
status = requests.get(
f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}",
headers=HEADERS,
).json()["status"]
if status == "ready":
break
if status == "failed":
raise RuntimeError("collection failed")
time.sleep(10)
# 3. Download
data = requests.get(
f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}",
params={"format": "json"},
headers=HEADERS,
).json()
print(len(data), "listings collected")Solo pagas por los registros entregados; la API Web Scraper comienza desde $0,70 por 1.000 registros, y cada nueva cuenta obtiene 5.000 registros gratuitos al mes para probar, sin necesidad de tarjeta de crédito. También hay una versión sin código en el panel de control si prefieres no escribir nada de esto.
Enfoque 4: El conjunto de datos de Airbnb listo para usar
Si necesitas historial o cobertura de todo el mercado en lugar de una lista específica de URLs, omite la recopilación por completo y compra el conjunto de datos de Airbnb. Tiene el mismo esquema estructurado, precolectado y actualizado.
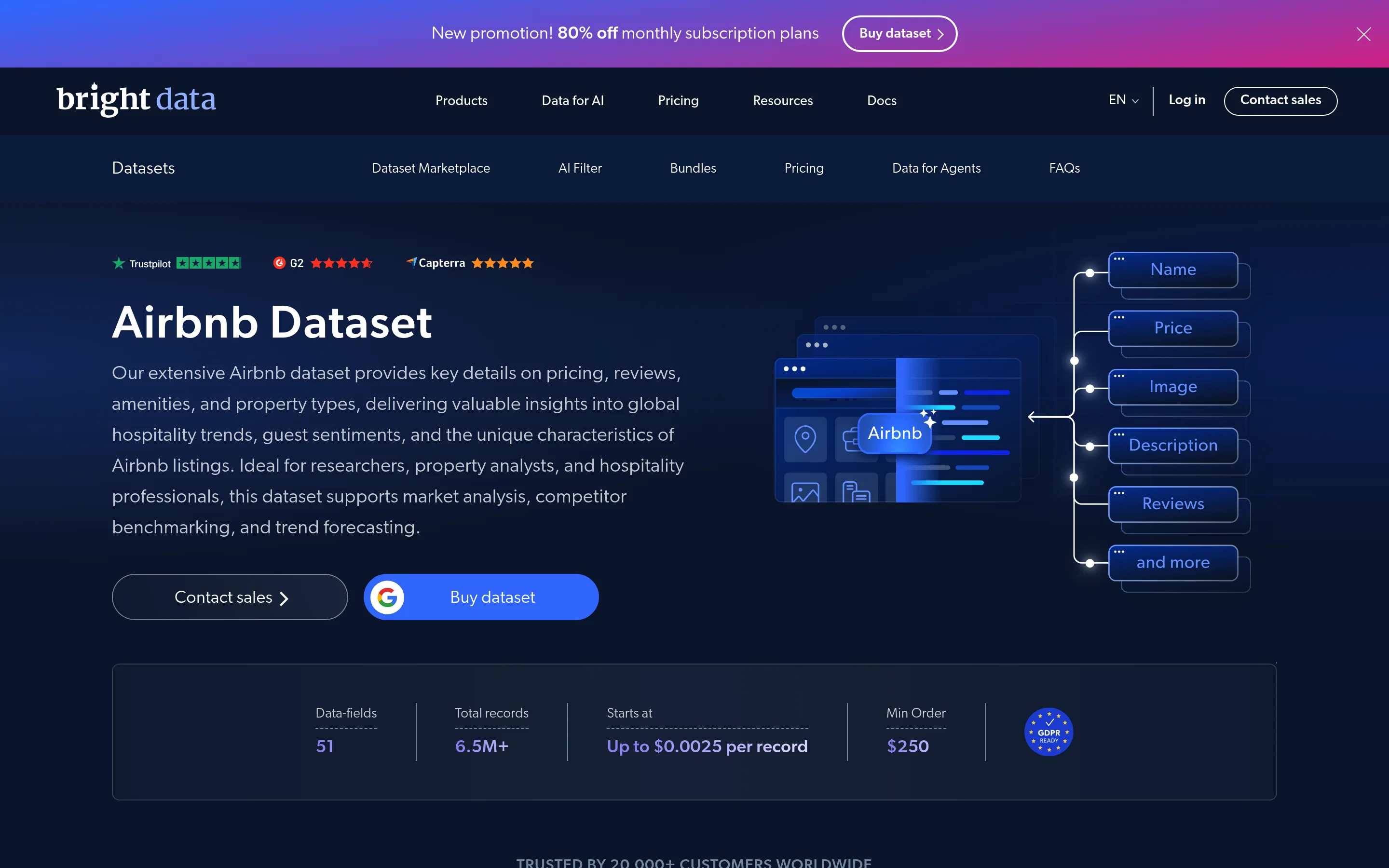
El conjunto de datos del marketplace contiene más de 6,5 millones de registros en 51 campos, con precios desde $0,0025 por registro y un pedido mínimo de $250, como descarga única o suscripción con actualización. Filtras por ubicación, fecha u otros atributos y descargas en JSON, CSV o Parquet. Esta es la opción de comprar frente a construir: cero ingeniería, acceso instantáneo, y una buena opción para probar modelos de precios retrospectivamente o analizar toda una ciudad de una vez. Bright Data también publica datos listos para usar para otros marketplaces, incluidos los mejores proveedores de datos de Amazon y los mejores proveedores de datos de ecommerce.
Extra: envía datos de Airbnb directamente a un agente de IA (MCP)
El mayor cambio de 2026 es que el consumidor de estos datos suele ser un agente de IA, no un panel de control. Los agentes necesitan datos web en vivo bajo demanda, y el Model Context Protocol (MCP) es como llaman a herramientas externas. El servidor Web MCP de Bright Data le da a cualquier LLM, ya sea Claude, GPT o Gemini, búsqueda en vivo (API SERP) y scraping a través de la misma infraestructura de desbloqueo, para que el agente nunca choque con la barrera de DataDome del Enfoque 1.
Apunta tu cliente MCP al servidor alojado con una sola línea, sin instalación requerida:
https://mcp.brightdata.com/mcp?token=YOUR_API_TOKENO ejecútalo localmente con npx:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": { "API_TOKEN": "your-token-here" }
}
}
}Aún más rápido, la CLI de Bright Data conecta el MCP a tu agente con un solo comando:
brightdata add mcp, agent claude-code,cursor,codexEl modo Rapid gratuito expone search_engine, scrape_as_markdown y discover a un crédito por solicitud, usando los mismos 5.000 créditos gratuitos mensuales. Un agente puede entonces responder a un mensaje como «encuentra listados de Airbnb disponibles en Roma por menos de $200 la noche y resume los cinco más baratos» buscando y extrayendo en vivo, sin código de scraping en tu aplicación. El modo Pro añade más de 60 herramientas estructuradas, incluidos extractores de datos web preconstruidos y automatización del Navegador de scraping, para agentes en producción. Para un tutorial completo, consulta el tutorial de scraping con Web MCP.
Antes de conectarlo a un agente, puedes probar exactamente las mismas herramientas desde tu terminal con la CLI de Bright Data, que usa los mismos créditos gratuitos. Una búsqueda rápida con search y scrape contra Airbnb:
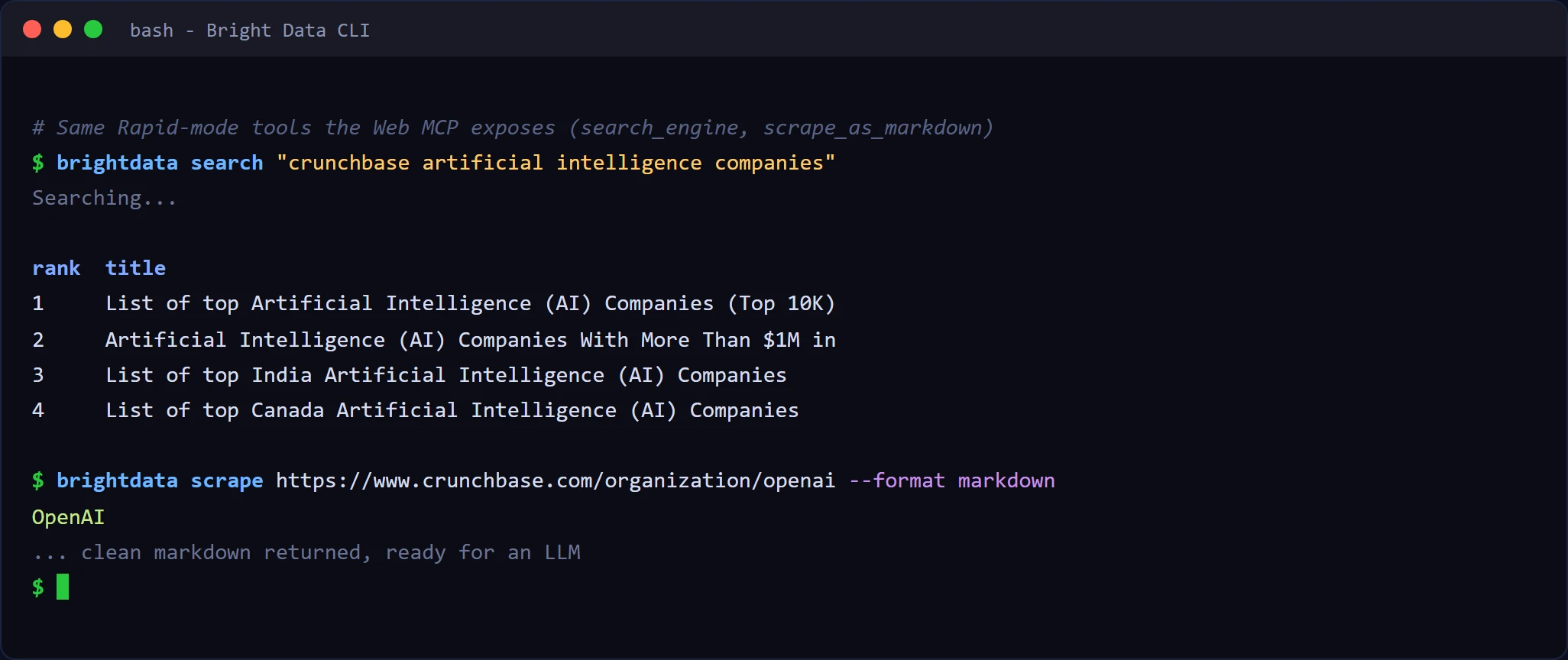
Los comandos search y scrape de la CLI se corresponden uno a uno con las herramientas search_engine y scrape_as_markdown del MCP, por lo que lo que aparece en tu terminal es exactamente lo que recibe el agente una vez conectado.
Véalo funcionar dentro del agente
Una vez conectado, preguntas en lenguaje natural y el agente decide qué herramientas MCP llamar. Mensajes que funcionan de inmediato:
- «Encuentra apartamentos en alquiler en Airbnb en Roma y recomienda algunos con valoraciones.»
- «Extrae los detalles clave de airbnb.com/rooms/ID: valoración, estado de superanfitrión, capacidad.»
- «Compara precios por noche de Airbnbs de dos habitaciones en Roma frente a Florencia.»
- «Resume el sentimiento de las reseñas de este listado en tres puntos clave.»
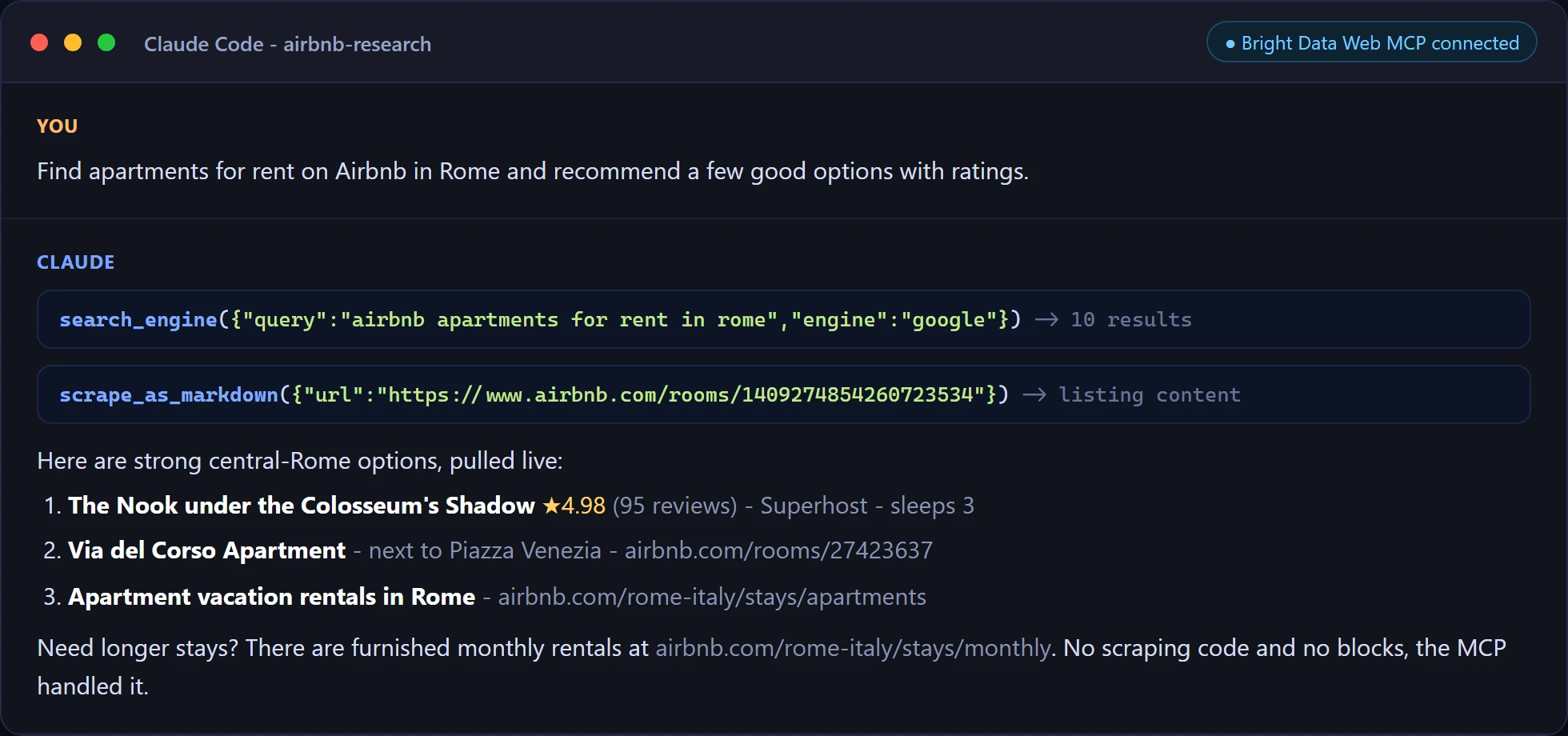
Aquí está el primer mensaje ejecutándose en Claude Code. El agente llama a search_engine y scrape_as_markdown por su cuenta, luego responde con datos en vivo y sin código de scraping en el proyecto.
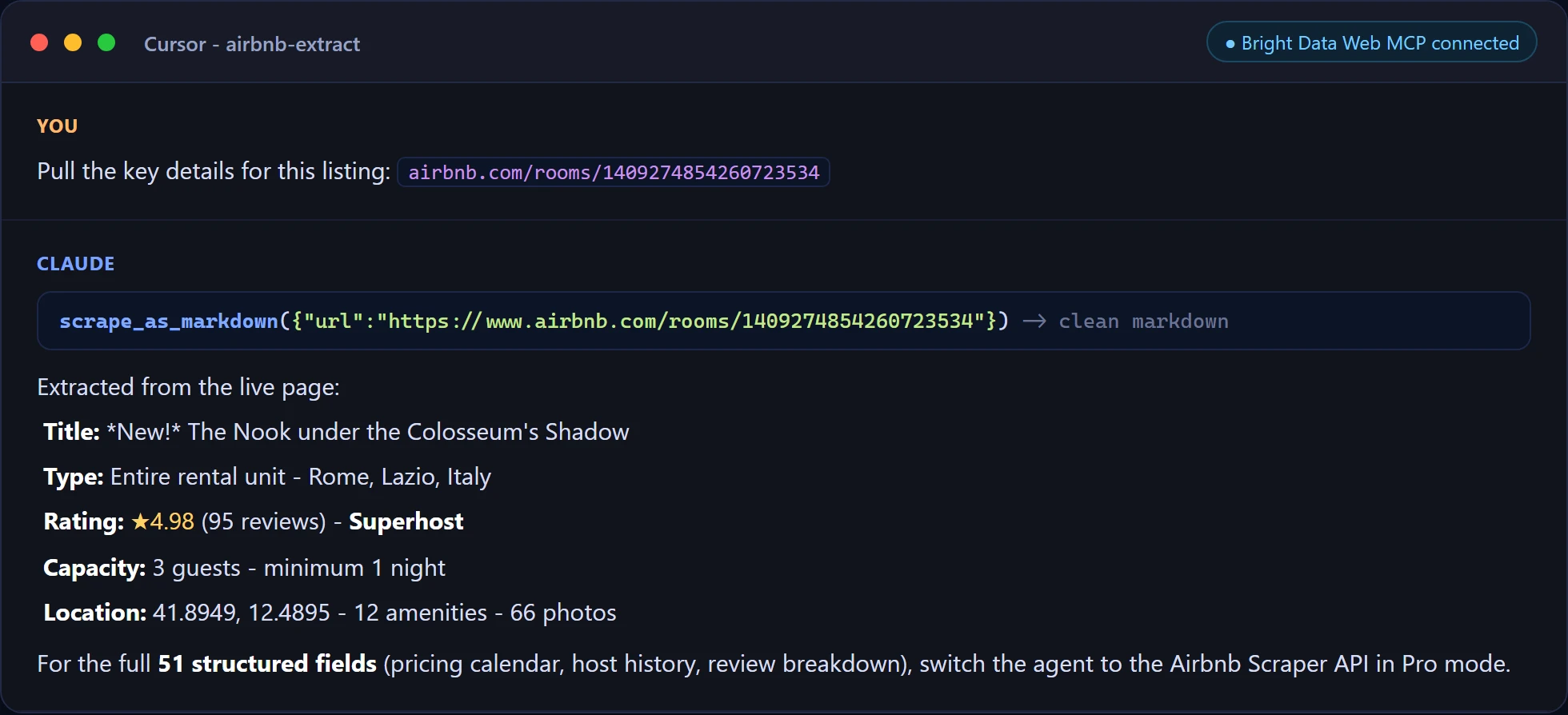
Y una extracción dirigida en Cursor, obteniendo los campos de un listado directamente desde la página en vivo.
Para agentes en producción que necesiten todos los campos, activa el modo Pro y el agente accede a más de 60 herramientas de datos web estructurados para llamar junto con la API Scraper de Airbnb del Enfoque 3.
Convierte los datos en información útil
Una vez que tienes los listados, el análisis es rápido. Usando los precios parseados en el Enfoque 2, un pequeño fragmento de código resume el mercado local.
import statistics
prices = [1082, 1639, 1064, 3010, 904, 1115, 2008, 1398] # USD, 5-night totals
print("listings:", len(prices))
print("median:", statistics.median(prices))
print("range:", min(prices), "to", max(prices))Representar la muestra completa muestra la distribución en el centro de Roma de un vistazo.
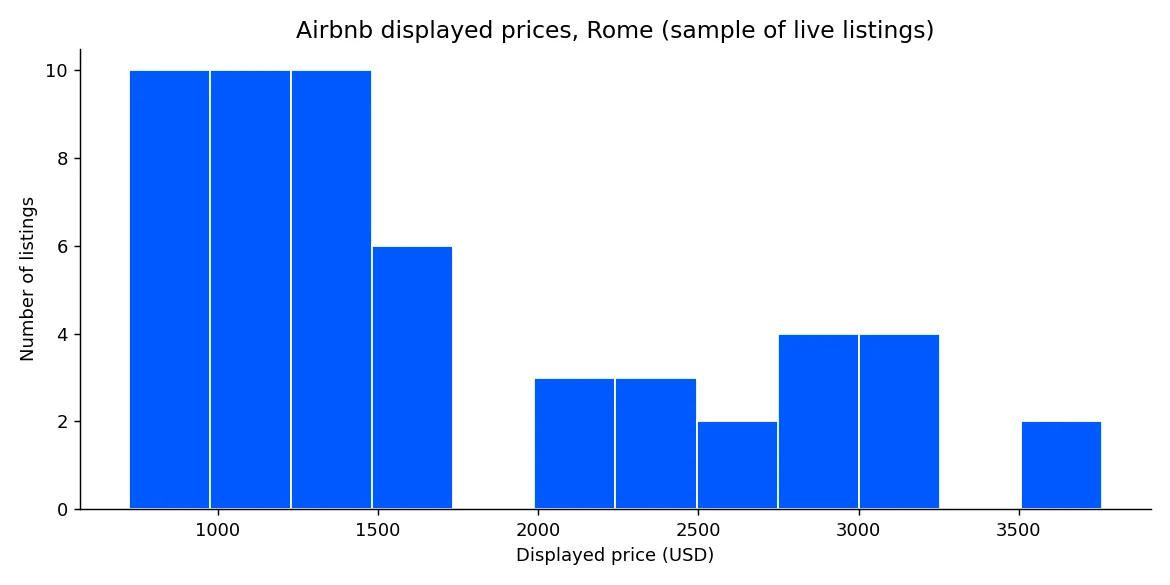
Esa distribución es la base para precios competitivos, detección de valores atípicos y modelos de ocupación.
Cómo elegir
- ¿Solo explorando o aprendiendo? El scraping manual te enseña cómo está construida la página. No lo uses en producción.
- ¿Necesitas una página sin scraper preconstruido y quieres controlar el parseo? Usa Web Unlocker.
- ¿Necesitas datos de listados limpios y estructurados a cualquier volumen? Usa la API Scraper de Airbnb. Esta es la opción predeterminada para la mayoría de los proyectos.
- ¿Necesitas datos históricos o de todo el mercado sin código? Usa el conjunto de datos de Airbnb.
Para comparaciones directas de herramientas dedicadas, consulta nuestros resúmenes de los mejores scrapers de Airbnb y los mejores proveedores de datos de Airbnb.
El patrón que se mantiene en todos ellos: deja que la infraestructura gestionada se encargue del desbloqueo y la estructura para que tu equipo dedique su tiempo al análisis, no a supervisar scrapers. La red de Bright Data está construida exactamente para esto, con infraestructura alineada con el GDPR y CCPA, certificada ISO 27001 y de fuentes éticas detrás de cada solicitud.
Conclusión
Hacer scraping de Airbnb en 2026 tiene menos que ver con un parseo inteligente y más con elegir el nivel de abstracción adecuado. El código manual está bien para aprender, pero falla ante la capa anti-bot de Airbnb. Web Unlocker te da la página cuando necesitas control personalizado. La API Scraper de Airbnb te da registros estructurados con cero mantenimiento. El conjunto de datos te da todo el mercado con cero código. Empieza con las 5k solicitudes en la API Scraper, apúntala a los listados que te interesan y construye desde ahí.
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “¿Puedo hacer scraping de Airbnb con solicitudes Python simples?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “No de forma fiable. Airbnb protege sus páginas con la detección de bots de DataDome. Una solicitud estándar suele devolver una página de desafío, y aunque alguna pase, falla a escala con CAPTCHAs, límites de velocidad y bloqueos de IP. Necesitas desbloqueo gestionado, una huella digital real del navegador y proxies, por eso la mayoría de los equipos usan Web Unlocker o la API Scraper de Airbnb.”
}
},
{
“@type”: “Question”,
“name”: “¿Qué datos puede devolver la API Scraper de Airbnb?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Un solo registro incluye 51 campos: título y tipo de listado, precio por noche y total, calendario de disponibilidad, valoraciones y número de reseñas, señales del anfitrión y superanfitrión, comodidades, coordenadas, imágenes y más. Lo recibes como JSON limpio sin necesidad de parseo.”
}
},
{
“@type”: “Question”,
“name”: “¿Debo usar la API Scraper o el conjunto de datos listo para usar?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Usa la API Scraper cuando tienes URLs específicas de listados o búsquedas y quieres datos frescos bajo demanda. Usa el conjunto de datos cuando necesites cobertura histórica o de todo el mercado sin proporcionar URLs. El conjunto de datos contiene más de 6,5 millones de registros y comienza en $0,0025 por registro.”
}
},
{
“@type”: “Question”,
“name”: “¿Cuánto cuesta empezar?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Cada nueva cuenta de Bright Data incluye 5.000 registros gratuitos al mes en la API Web Scraper, Web Unlocker y API SERP, sin necesidad de tarjeta de crédito. A partir de ahí, la API Web Scraper comienza desde $0,70 por 1.000 registros y solo pagas por los datos entregados.”
}
},
{
“@type”: “Question”,
“name”: “¿Puede un agente de IA recopilar datos de Airbnb a través de MCP?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Sí. El servidor Web MCP de Bright Data conecta cualquier LLM compatible con MCP (Claude, GPT, Gemini) a datos web en vivo. En el modo Rapid gratuito, el agente accede a search_engine y scrape_as_markdown a un crédito por solicitud, por lo que puede extraer listados actuales de Airbnb bajo demanda sin ningún código de scraping en tu app. El modo Pro añade más de 60 herramientas de datos estructurados para agentes en producción.”
}
},
{
“@type”: “Question”,
“name”: “¿Cómo gestiono trabajos grandes de scraping de Airbnb?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Usa el endpoint asíncrono: activa una recopilación con tu lista de URLs, consulta el endpoint de progreso hasta que el snapshot esté listo, luego descarga en JSON, CSV o NDJSON. Un solo trabajo gestiona miles de URLs, y los snapshots están disponibles durante 30 días.”
}
}
]
}
Preguntas frecuentes
¿Puedo hacer scraping de Airbnb con solicitudes Python simples?
No de forma fiable. Airbnb protege sus páginas con la detección de bots de DataDome. Una solicitud estándar suele devolver una página de desafío, y aunque alguna pase, falla a escala con CAPTCHAs, límites de velocidad y bloqueos de IP. Necesitas desbloqueo gestionado, una huella digital real del navegador y proxies, por eso la mayoría de los equipos usan Web Unlocker o la API Scraper de Airbnb.
¿Qué datos puede devolver la API Scraper de Airbnb?
Un solo registro incluye 51 campos: título y tipo de listado, precio por noche y total, calendario de disponibilidad, valoraciones y número de reseñas, señales del anfitrión y superanfitrión, comodidades, coordenadas, imágenes y más. Lo recibes como JSON limpio sin necesidad de parseo.
¿Debo usar la API Scraper o el conjunto de datos listo para usar?
Usa la API Scraper cuando tienes URLs específicas de listados o búsquedas y quieres datos frescos bajo demanda. Usa el conjunto de datos cuando necesites cobertura histórica o de todo el mercado sin proporcionar URLs. El conjunto de datos contiene más de 6,5 millones de registros y comienza en $0,0025 por registro.
¿Cuánto cuesta empezar?
Cada nueva cuenta de Bright Data incluye 5.000 registros gratuitos al mes en la API Web Scraper, Web Unlocker y API SERP, sin necesidad de tarjeta de crédito. A partir de ahí, la API Web Scraper comienza desde $0,70 por 1.000 registros y solo pagas por los datos entregados.
¿Puede un agente de IA recopilar datos de Airbnb a través de MCP?
Sí. El servidor Web MCP de Bright Data conecta cualquier LLM compatible con MCP (Claude, GPT, Gemini) a datos web en vivo. En el modo Rapid gratuito, el agente accede a search_engine y scrape_as_markdown a un crédito por solicitud, por lo que puede extraer listados actuales de Airbnb bajo demanda sin ningún código de scraping en tu app. El modo Pro añade más de 60 herramientas de datos estructurados para agentes en producción.
¿Cómo gestiono trabajos grandes de scraping de Airbnb?
Usa el endpoint asíncrono: activa una recopilación con tu lista de URLs, consulta el endpoint de progreso hasta que el snapshot esté listo, luego descarga en JSON, CSV o NDJSON. Un solo trabajo gestiona miles de URLs, y los snapshots están disponibles durante 30 días.






