
En este tutorial, trataremos:
- Cómo extraer resultados de búsqueda de Naver utilizando la API SERP de Bright Data
- Crear un Scraper personalizado de Naver con proxies de Bright Data
- Cómo extraer datos de Naver utilizando Bright Data Scraper Studio (IA Scraper) con un flujo de trabajo sin código
¡Empecemos!
¿Por qué extraer datos de Naver?
Naver es la plataforma líder en Corea del Sur y una fuente principal de búsquedas, noticias, compras y contenido generado por los usuarios. A diferencia de los motores de búsqueda globales, Naver muestra servicios propios directamente en sus resultados, lo que lo convierte en una fuente de datos fundamental para las empresas que se dirigen al mercado coreano.
El scraping de Naver permite acceder a datos estructurados y no estructurados que no están disponibles a través de API públicas y que son difíciles de recopilar manualmente a gran escala.
¿Qué datos se pueden recopilar?
- Resultados de búsqueda (SERP): clasificaciones, títulos, fragmentos y URL.
- Noticias: editores, titulares y marcas de tiempo
- Compras: listados de productos, precios, vendedores y reseñas
- Blogs y cafés: contenido generado por los usuarios y tendencias.
Casos de uso clave
- SEO y seguimiento de palabras clave para el mercado coreano
- Supervisión de la marca y la reputación en noticias y contenido de usuarios
- Análisis de comercio electrónico y precios utilizando Naver Shopping
- Estudio de mercado y tendencias a partir de blogs y foros
Con este contexto, pasemos al primer enfoque y veamos cómo extraer los resultados de búsqueda de Naver utilizando la API SERP de Bright Data.
Extracción de datos de Naver con la API SERP de Bright Data
Este enfoque es ideal cuando se desea obtener datos SERP de Naver sin tener que gestionar Proxies, CAPTCHAs o la configuración del navegador.
Requisitos
Para seguir este tutorial, necesitará:
- Una cuenta de Bright Data
- Acceso a la API SERP, los Proxies o Scraper Studio en el panel de control de Bright Data
- Python 3.9 o superior instalado
- Conocimientos básicos de Python y conceptos de Scraping web
Para los ejemplos de Scrapers personalizados, también necesitarás:
- Playwright instalado y configurado localmente
- Chromium instalado a través de Playwright
Crear una zona API SERP en Bright Data
En Bright Data, la API SERP requiere una zona dedicada. Para configurarla:
- Inicie sesión en Bright Data.
- Vaya a API SERP en el panel de control y cree una nueva zona API SERP.
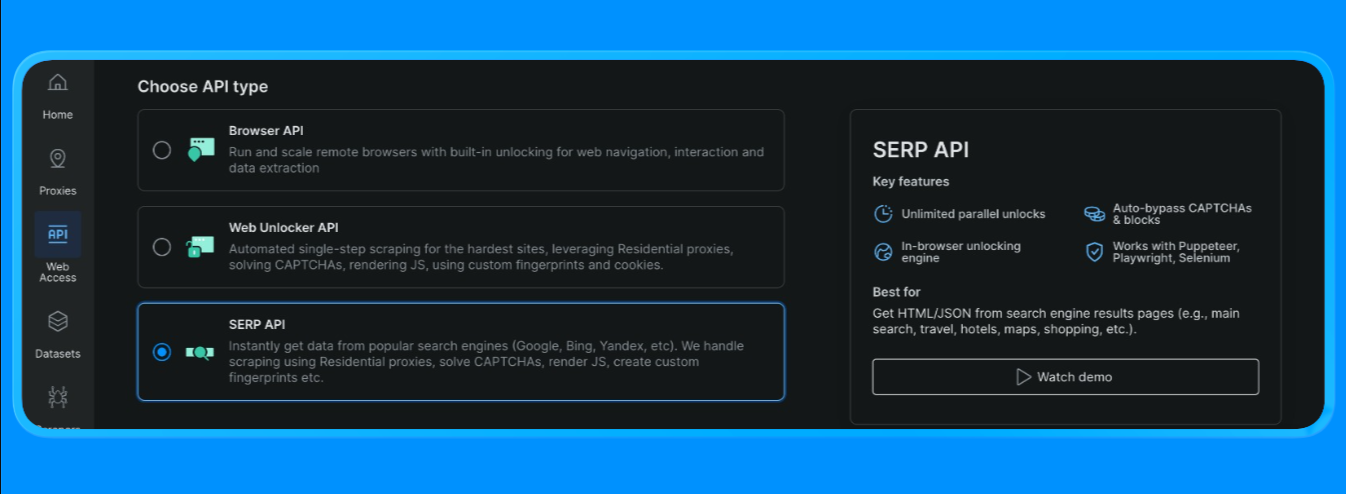
- Copie su clave API.
Cree la URL de búsqueda de Naver
Las SERP de Naver se pueden solicitar mediante un formato de URL de búsqueda estándar:
- Punto final base:
https://search.naver.com/search.naver - Parámetro de consulta:
query=<tu palabra clave>
La consulta se codifica en la URL utilizando quote_plus(), de modo que las palabras clave compuestas por varias palabras (como «tutoriales de aprendizaje automático») se formatean correctamente.
Enviar la solicitud de la API SERP (punto final de solicitud de Bright Data)
El flujo de inicio rápido de Bright Data utiliza un único punto final (https://api.brightdata.com/request) al que se le pasa:
zona:el nombre de su zona API SERPurl:la URL SERP de Naver que desea que Bright Data recupereformat:establezca en raw para devolver el HTML
Bright Data también admite modos de salida analizados (por ejemplo, estructura JSON a través de brd_json=1, o «resultados principales» más rápidos a través de las opciones data_format ), pero para esta sección del tutorial utilizaremos su flujo de parseo HTML
Ahora puede crear un archivo Python e incluir los siguientes códigos
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "su_nombre_de_usuario_brightdata"
BRIGHTDATA_PASSWORD = "su_contraseña_brightdata"
PROXY_SERVER = "tu_host_proxy"
def limpiar_texto(texto: str) -> str:
return re.sub(r"s+", " ", (texto o "")).strip()
def enlace_bloqueado(href: str) -> bool:
"""Bloquear anuncios/enlaces de utilidades; permitir blog.naver.com, ya que queremos resultados de blogs."""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# bloquear redireccionamientos de anuncios + utilidades obvias sin contenido
dominios_bloqueados = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# En el modo blog, puedes:
# (A) permitir solo dominios de blogs/publicaciones de Naver (más «al estilo Naver»)
allowed = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
return not any(netloc == d or netloc.endswith("." + d) for d in allowed)
def pick_snippet(container) -> str:
"""
Heurística: selecciona un bloque de texto similar a una frase cerca del título.
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# evitar líneas tipo breadcrumb
if "›" in txt:
continue
best = txt
break
return best
def extract_blog_results(html: str, limit: int = 10):
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
# Los diseños SERP del blog cambian; utiliza múltiples alternativas
selectors = [
"a.api_txt_lines", # envoltorio común del enlace del título
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
for sel in selectors:
for a in soup.select(sel):
if a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 5:
continúa
si blocked_link(href):
continúa
si href en seen:
continúa
seen.add(href)
contenedor = a.find_parent(["li", "article", "div", "section"]) o a.parent
fragmento = pick_snippet(contenedor) si contenedor, de lo contrario ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# Blog vertical de Naver
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# Proxy-friendly timeouts
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# Bloquear recursos pesados para acelerar y reducir los bloqueos
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# Reintentar una vez (Navers puede ser un poco inestable)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "machine learning tutorial"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Scraped from:", scraped_url)
print("HTML length:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("nResultados extraídos del blog de Naver:")
for i, r in enumerate(results, 1):
print(f"n{i}. {r['title']}n {r['link']}n {r['snippet']}")Utilizando la función fetch_naver_html(), enviamos una URL de búsqueda de Naver al punto final de solicitud de Bright Data y recuperamos la página SERP completamente renderizada. Bright Data gestionó la rotación de IP y el acceso automáticamente, lo que permitió que la solicitud se realizara con éxito sin encontrar bloqueos ni límites de velocidad.
A continuación, realizamos el parseo del HTML con BeautifulSoup y aplicamos una lógica de filtrado personalizada para eliminar los anuncios y los módulos internos de Naver. La función extract_web_results() escaneó la página en busca de títulos de resultados válidos, enlaces y bloques de texto cercanos, los deduplicó y devolvió una lista limpia de resultados de búsqueda.
Al ejecutar el script, obtendrá un resultado similar al siguiente: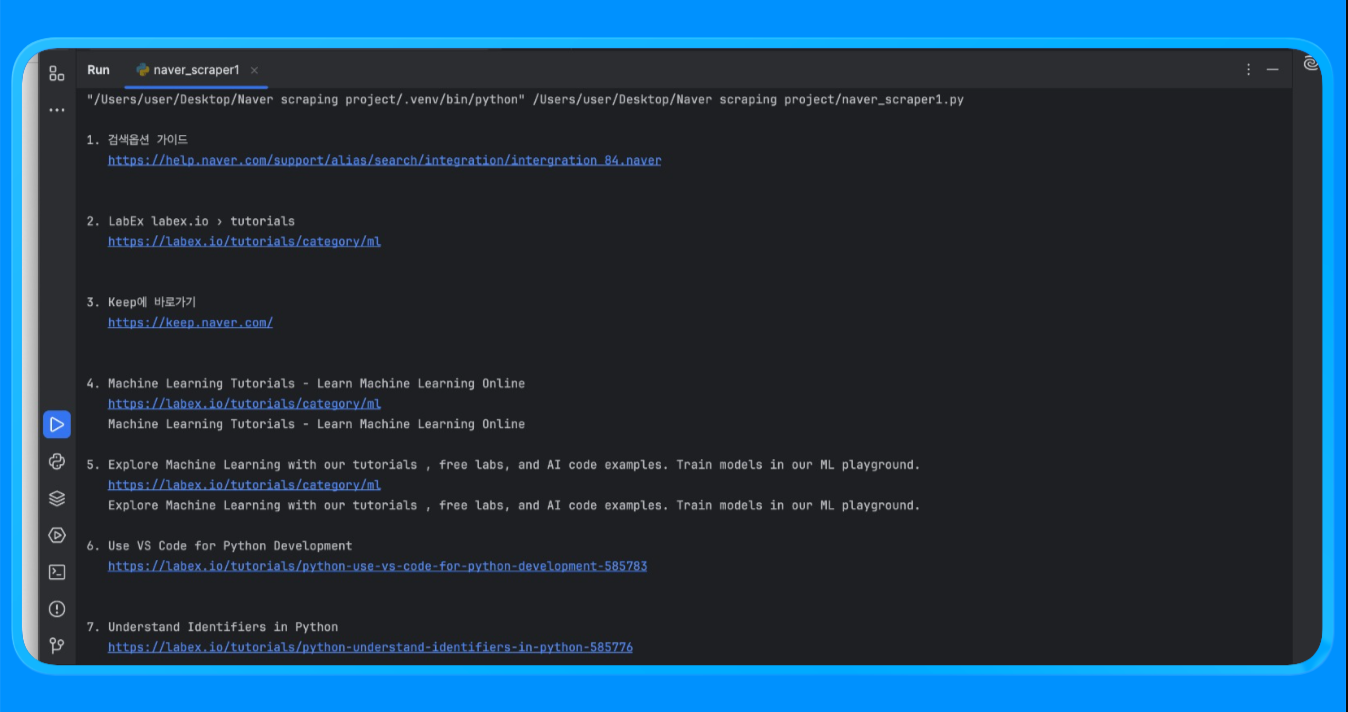
Este método se utiliza para recopilar resultados de búsqueda estructurados de Naver sin necesidad de crear ni mantener un Scraper personalizado.
Casos de uso comunes
- Seguimiento de la clasificación y la visibilidad de las palabras clave en Naver
- Supervisión del rendimiento SEO para los mercados coreanos
- Análisis de características SERP, como noticias, compras y ubicaciones de blogs
Este enfoque funciona mejor cuando se necesitan esquemas de salida consistentes y altos volúmenes de solicitudes con una configuración mínima.
Una vez cubierto el rastreo a nivel SERP, pasemos a crear un Scraper personalizado de Naver utilizando los Proxies de Bright Data para un rastreo más profundo y una mayor flexibilidad.
Creación de un Scraper personalizado de Naver con proxies de Bright Data
Este enfoque utiliza un navegador real para renderizar las páginas de Naver mientras se enruta el tráfico a través de los Proxies de Bright Data. Es útil cuando se necesita un control total sobre las solicitudes, la renderización de JavaScript y la extracción de datos a nivel de página más allá de los SERP.
Antes de escribir cualquier código, primero debe crear una zona de Proxy y obtener sus credenciales de Proxy desde el panel de control de Bright Data.
Para obtener las credenciales de Proxy utilizadas en este script:
- Inicie sesión en su cuenta de Bright Data
- Desde el panel de control, vaya a Proxies y haga clic en «Crear Proxy»
- Seleccione Proxies de centro de datos (elegimos esta opción para este proyecto, la opción varía en función del alcance y el caso de uso del proyecto).
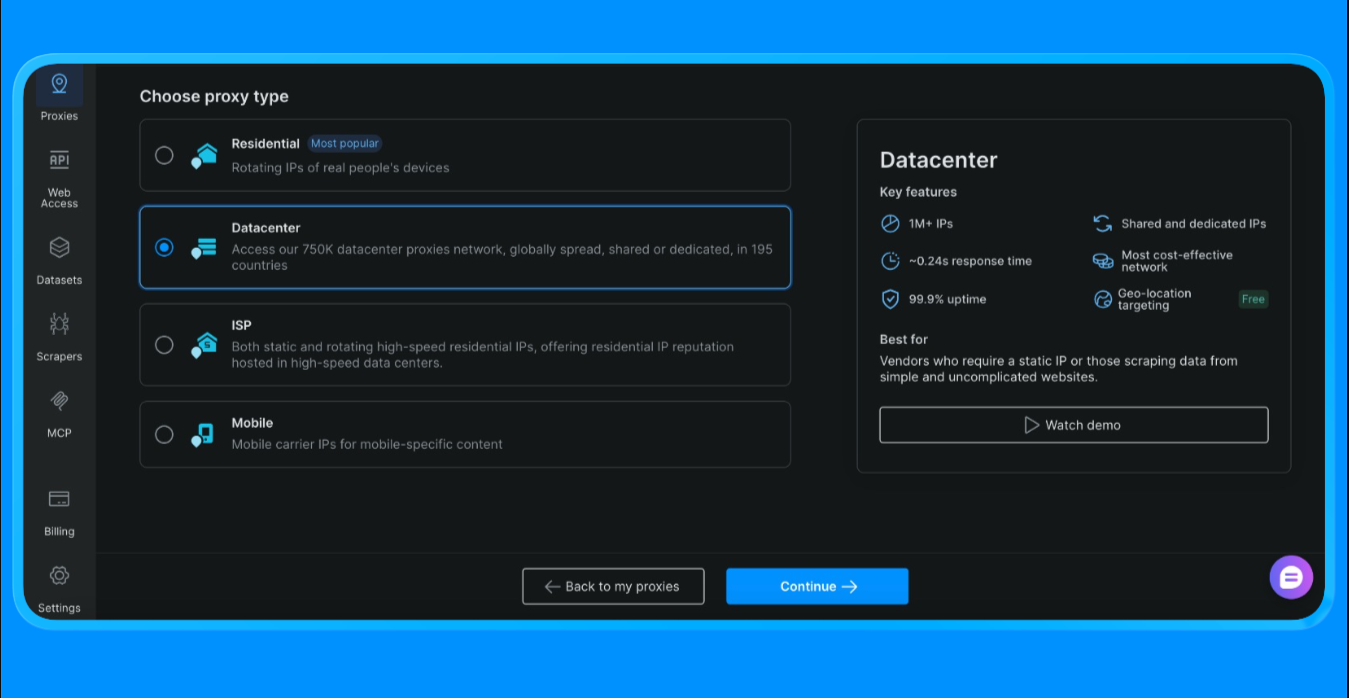
- Cree una nueva zona Proxy
- Abra la configuración de la zona y copie los siguientes valores:
- Nombre de usuario del Proxy
- Contraseña del Proxy
- Punto final y puerto del Proxy
Estos valores son necesarios para autenticar las solicitudes enrutadas a través de la red Proxy de Bright Data.
Añade tus credenciales de Proxy de Bright Data al script
Después de crear la zona Proxy, actualice el script con las credenciales que copió del panel de control.
BRIGHTDATA_USERNAMEcontiene su ID de cliente y el nombre de la zona ProxyBRIGHTDATA_PASSWORDcontiene la contraseña de la zona ProxyPROXY_SERVERapunta al punto final del superproxy de Bright Data
Una vez establecidos estos valores, todo el tráfico del navegador iniciado por Playwright se enrutará automáticamente a través de Bright Data.
Ahora podemos proceder al scraping con los siguientes códigos:
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "tu_nombre_de_usuario"
BRIGHTDATA_PASSWORD = "tu_contraseña"
PROXY_SERVER = "tu_host_proxy"
def clean_text(s: str) -> str:
return re.sub(r"s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
Proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
for a in soup.select("a[href]"):
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continúa
si href en visto:
continúa
visto.añadir(href)
resultados.añadir({"título": título, "enlace": href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}n {r['link']}n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))La función scrape_naver_blog() abre el blog vertical de Naver, bloquea los activos pesados, como imágenes, medios y fuentes, para reducir el tiempo de carga, y reintenta la navegación si se produce un tiempo de espera. Una vez que la página se ha cargado por completo, recupera el HTML renderizado.
A continuación, la función extract_blog_results() realiza el parseo del HTML con BeautifulSoup, aplica reglas de filtrado específicas del blog para excluir anuncios y páginas de utilidades, al tiempo que permite los dominios del blog Naver, y extrae una lista limpia de títulos de blogs, enlaces y fragmentos de texto cercanos.
Una vez ejecutado este script, se obtiene el siguiente resultado:
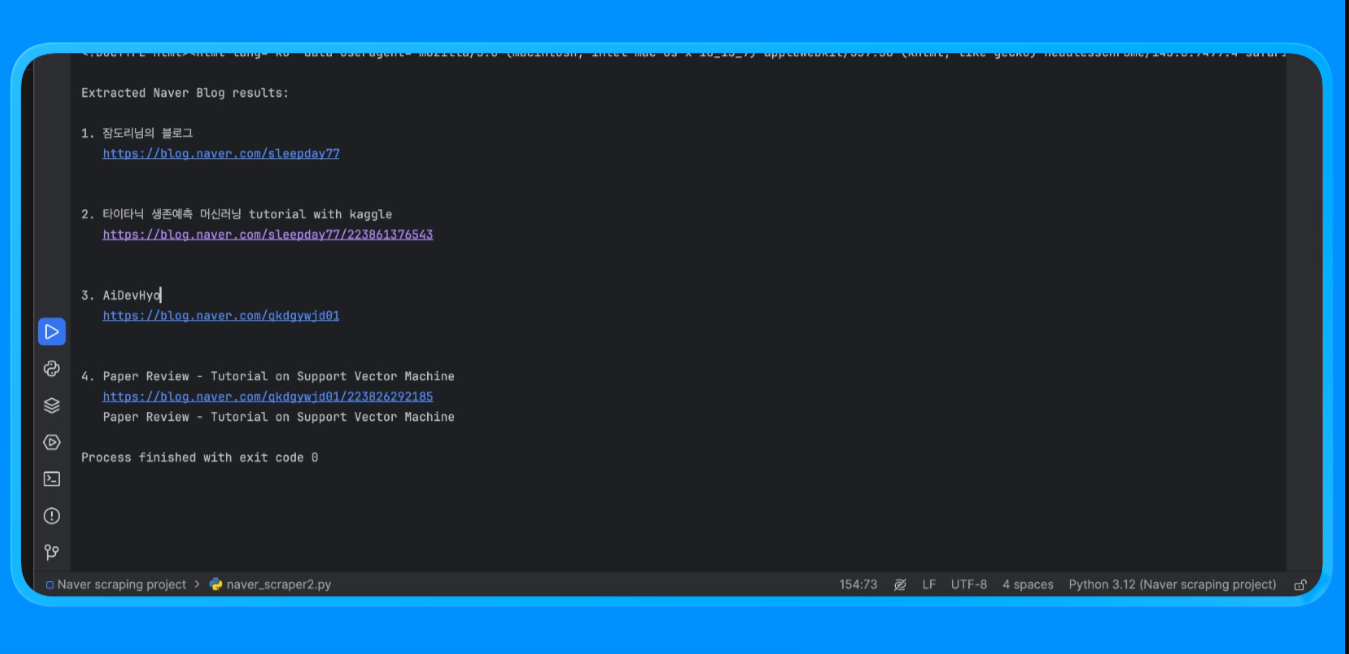
Este método se utiliza para extraer contenido de páginas de Naver que requieren renderización del navegador y lógica de parseo personalizada.
Casos de uso comunes
- Extracción de contenido de blogs y cafés de Naver
- Recopilación de artículos largos, comentarios y contenido de usuarios
- Extracción de datos de páginas con mucho JavaScript
Este enfoque es ideal cuando se requiere renderización de páginas, reintentos y filtrado detallado.
Ahora que tenemos un Scraper personalizado que funciona a través de los Proxies de Bright Data, pasemos a la opción más rápida para extraer datos sin escribir código. En la siguiente sección, rastrearemos Naver utilizando Bright Data Scraper Studio, el flujo de trabajo sin código impulsado por IA y construido sobre la misma infraestructura.
Rastreando Naver con Bright Data Scraper Studio (rastreador de IA sin código)
Si no desea escribir ni mantener código de rastreo, Bright Data Scraper Studio ofrece una forma sin código de extraer datos de Naver utilizando la misma infraestructura subyacente que la API SERP y la red de Proxies.
Para empezar:
- Inicie sesión en su cuenta de Bright Data
- Desde el panel de control, abra la opción «Scrapers» en el menú de la izquierda y haga clic en «Scraper studio». Verá un panel de control similar a este:
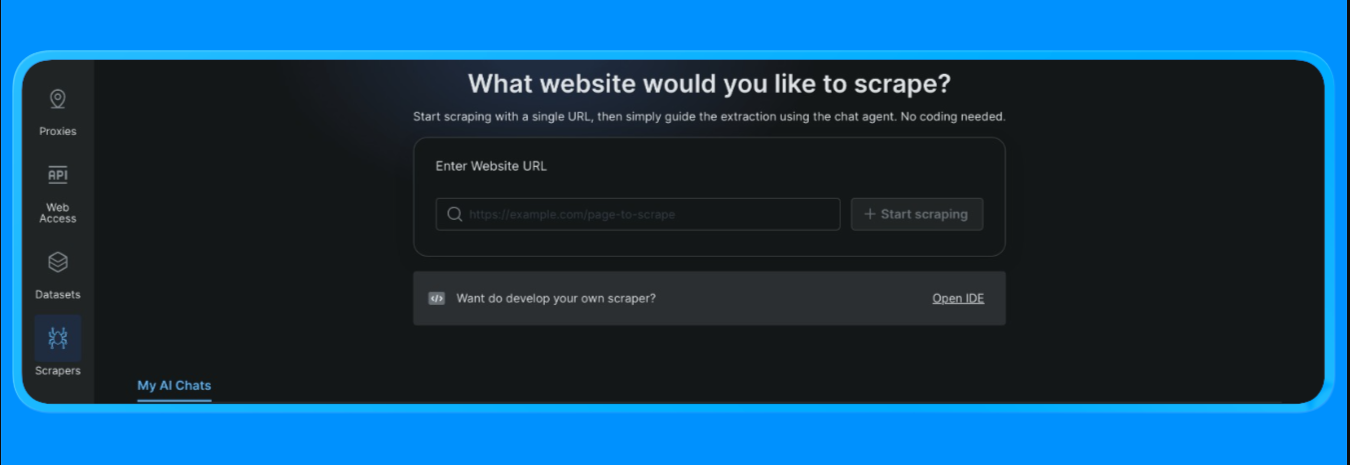
Introduzca la URL de destino que desea extraer y, a continuación, haga clic en el botón «Start Scraping» (Iniciar extracción).
Scraper Studio procederá a extraer la información del sitio y le proporcionará los datos que necesita.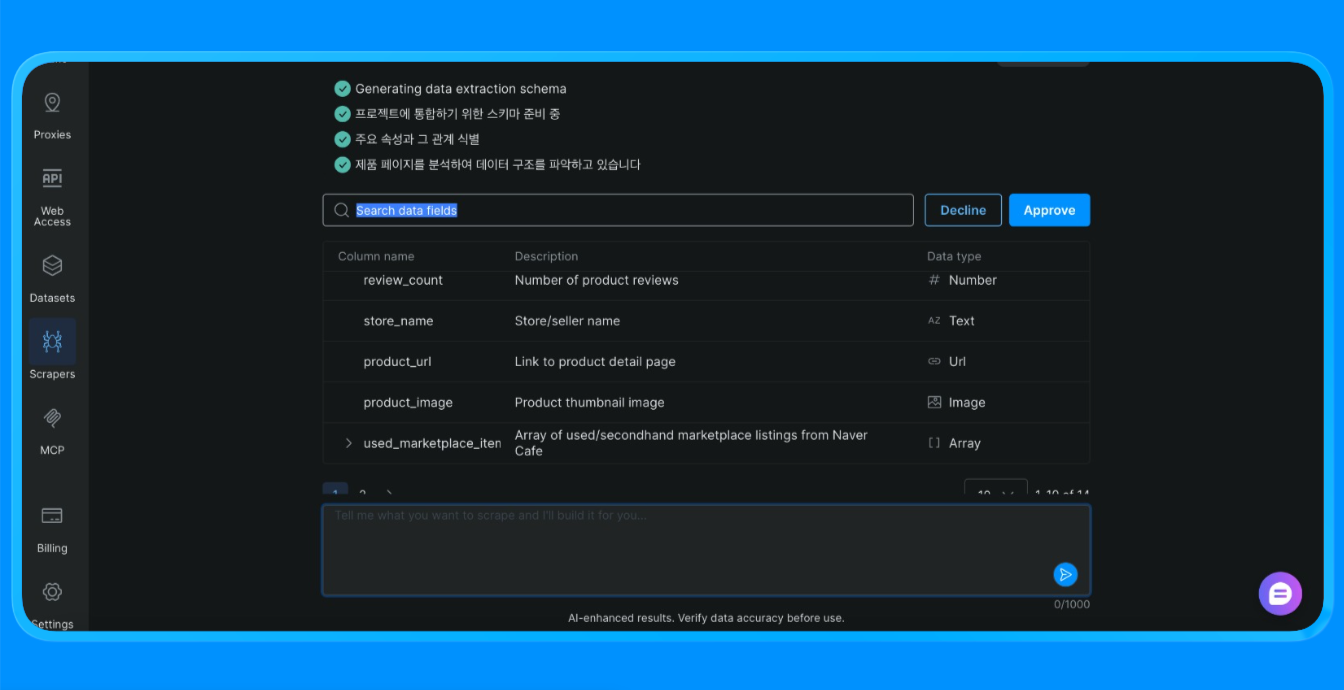
Scraper Studio cargó la página de Naver a través de la infraestructura de Bright Data, aplicó reglas de extracción visual y devolvió datos estructurados que, de otro modo, requerirían un scraper personalizado o la automatización del navegador.
Casos de uso comunes
- Recopilación de datos puntual
- Proyectos de prueba de concepto
- Equipos no técnicos que recopilan datos web
Scraper Studio es una buena opción cuando la velocidad y la simplicidad son más importantes que la personalización.
Comparación de los tres enfoques de scraping de Naver
| Enfoque | Esfuerzo de configuración | Nivel de control | Escalabilidad | Ideal para |
|---|---|---|---|---|
| API SERP de Bright Data | Bajo | Medio | Alta | Seguimiento SEO, monitorización de palabras clave, datos SERP estructurados |
| Scraper personalizado con proxies de Bright Data | Alto | Muy alto | Muy alto | Rastreo de blogs, páginas dinámicas, flujos de trabajo personalizados |
| Bright Data Scraper Studio | Muy bajo | Bajo a medio | Medio | Extracción rápida, equipos sin código, creación de prototipos |
Cómo elegir:
- Utilice la API SERP cuando necesite resultados de búsqueda fiables y estructurados a gran escala.
- Utilice Proxies con un Scraper personalizado cuando necesite un control total sobre la representación, los reintentos y la lógica de extracción.
- Utilice Scraper Studio cuando la velocidad y la simplicidad sean más importantes que la personalización.
Conclusión
En este tutorial, hemos visto tres formas listas para la producción de extraer datos de Naver utilizando Bright Data:
- Una API SERP gestionada para datos de búsqueda estructurados
- Un scraper personalizado con Proxies para una flexibilidad y un control totales
- Un flujo de trabajo sin código de Scraper Studio para una extracción rápida de datos
Cada opción se basa en la misma infraestructura de Bright Data. La elección correcta depende del nivel de control que necesites, la frecuencia con la que planees extraer datos y si deseas escribir código.
Puede explorar Bright Data para acceder a la API SERP, la infraestructura de Proxies y Scraper Studio sin código, y elegir el enfoque que mejor se adapte a su flujo de trabajo.
Para obtener más guías y tutoriales sobre Scraping web:
- Scraping web con Python: la guía completa
- Cómo extraer datos de sitios web dinámicos con Python
- Las mejores API SERP para el scraping web
- Scraping web con Playwright
- Los mejores proveedores de Proxy para el scraping web
- Los mejores proveedores de proxies residenciales
- Bibliotecas de Python para Scraping web
- Los mejores servicios de Scraping web






