

Wikipedia es una fuente de información extensa y completa, que contiene millones de artículos que abarcan casi todos los temas. Para los investigadores, científicos de datos y desarrolladores, estos datos abren innumerables oportunidades, desde la creación de Conjuntos de datos de aprendizaje automático hasta la realización de investigaciones académicas. En este artículo, le guiaremos paso a paso por el proceso de extracción de datos de Wikipedia.
Uso de la API de Bright Data Wikipedia Scraper
Si desea extraer datos de Wikipedia de forma eficiente, la API de Bright Data Wikipedia Scraper es una excelente alternativa al Scraping web manual. Esta potente API automatiza el proceso, lo que facilita enormemente la recopilación de grandes volúmenes de información.
Casos de uso clave:
- Recopilar explicaciones sobre una amplia gama de temas.
- Comparar la información de Wikipedia con otras fuentes de datos
- Realizar investigaciones utilizando grandes conjuntos de datos
- Extraer imágenes de Wikipedia Commons
Puede obtener sus datos en formatos como JSON, CSV y .gz, y admite varias opciones de entrega, incluyendo Amazon S3, Google Cloud Storage y Microsoft Azure.
Con una sola llamada a la API, puede acceder a una gran cantidad de datos de forma rápida y sencilla.
Cómo extraer datos de Wikipedia con Python
Siga este tutorial paso a paso para extraer datos de Wikipedia con Python.
1. Configuración y requisitos previos
Antes de empezar, asegúrate de que tu entorno de desarrollo está correctamente configurado:
- Instala Python: descarga e instala la última versión de Python desde el sitio web oficial de Python.
- Elige un IDE: utiliza un IDE como PyCharm, Visual Studio Code o Jupyter Notebook para tu trabajo de desarrollo.
- Conocimientos básicos: asegúrate de estar familiarizado con los selectores CSS y de sentirte cómodo utilizando las herramientas de desarrollo del navegador para inspeccionar los elementos de la página.
Si es nuevo en Python, lea esta guía sobre cómo extraer datos con Python para obtener instrucciones detalladas.
A continuación, crea un nuevo proyecto utilizando Poetry, una herramienta de gestión de dependencias que simplifica la gestión de paquetes y entornos virtuales en Python.
poetry new wikipedia-Scraper
Este comando generará la siguiente estructura de proyecto:
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ └── __init__.py
└── tests/
└── __init__.py
Navega hasta el directorio del proyecto e instala las dependencias necesarias:
cd wikipedia-Scraper
poetry add requests beautifulsoup4 pandas lxml
En primer lugar, BeautifulSoup se utiliza para el parseo de documentos HTML y XML, lo que facilita la navegación y la extracción de elementos específicos de las páginas web. La biblioteca requests se encarga de enviar solicitudes HTTP y recuperar el contenido de las páginas web. Pandas es una potente herramienta para manipular y analizar los datos extraídos, especialmente útil cuando se trabaja con tablas. Por último, lxml se utiliza para acelerar el proceso de parseo, mejorando el rendimiento de BeautifulSoup.
A continuación, activa el entorno virtual y abre la carpeta del proyecto en tu editor de código preferido (VS Code en este caso):
poetry shell
code .
Abre el archivo pyproject.toml para verificar las dependencias de tu proyecto. Debería tener este aspecto:
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"
Por último, crea un archivo main.py dentro de la carpeta wikipedia_scraper, donde escribirás tu lógica de scraping. La estructura actualizada de tu proyecto debería tener ahora este aspecto:
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py
Tu entorno ya está configurado y estás listo para empezar a escribir el código Python para extraer datos de Wikipedia.
2. Conexión a la página de Wikipedia de destino
Para empezar, conéctese a la página de Wikipedia que desee. En este ejemplo, extraeremos la siguiente página de Wikipedia.
Aquí tienes un fragmento de código sencillo para conectarte a una página de Wikipedia utilizando Python:
import requests # Para realizar solicitudes HTTP
from bs4 import BeautifulSoup # Para el parseo de contenido HTML
def connect_to_wikipedia(url):
response = requests.get(url) # Enviar una solicitud GET a la URL
# Comprobar si la solicitud se ha realizado correctamente
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # Analizar y devolver el HTML
else:
print(f"No se ha podido recuperar la página. Código de estado: {response.status_code}")
return None # Devuelve None si la solicitud falla
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # Obtiene el objeto soup para la URL especificada
En el código, la biblioteca de solicitudes de Python te permite enviar una solicitud HTTP a la URL, y con BeautifulSoup, puedes realizar el parseo del contenido HTML de la página.
3. Inspeccionar la página
Para extraer datos de forma eficaz, es necesario comprender la estructura del DOM (modelo de objetos de documento) de la página web. Por ejemplo, para extraer todos los enlaces de la página, puede seleccionar las etiquetas <a>, como se muestra a continuación:
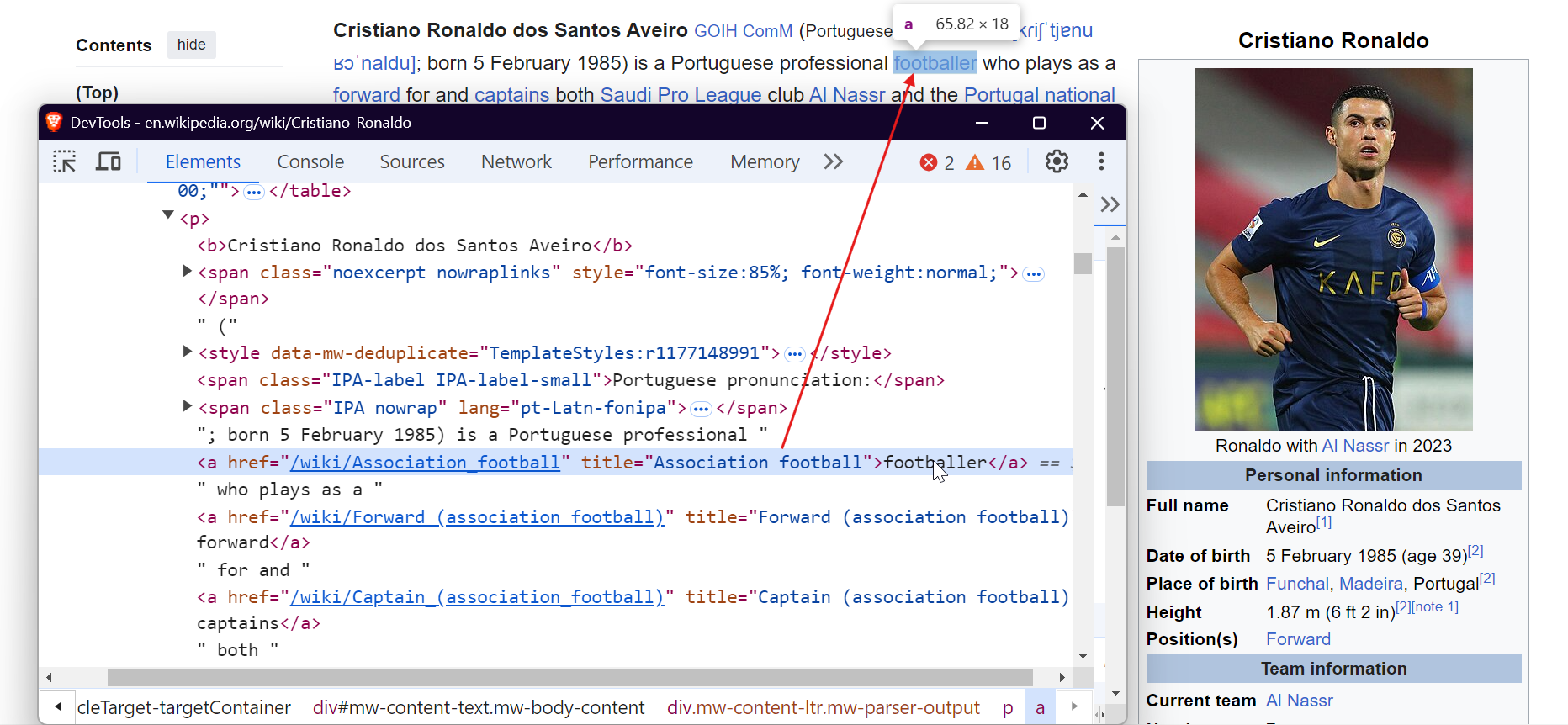
Para extraer imágenes, seleccione las etiquetas <img> y extraiga el atributo src para obtener las URL de las imágenes.
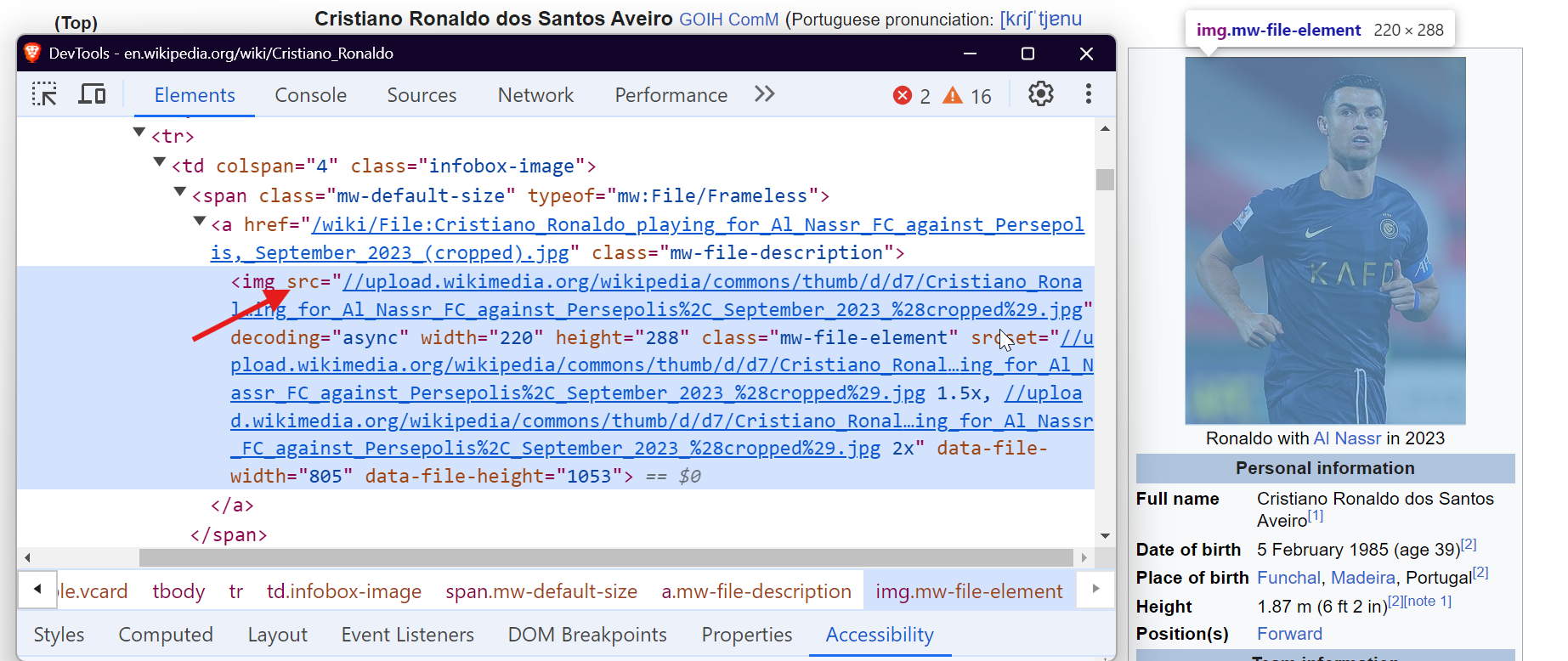
Para extraer datos de tablas, puede seleccionar la etiqueta <table> con la clase wikitable. Esto le permite recopilar todas las filas y columnas de la tabla y extraer los datos necesarios.
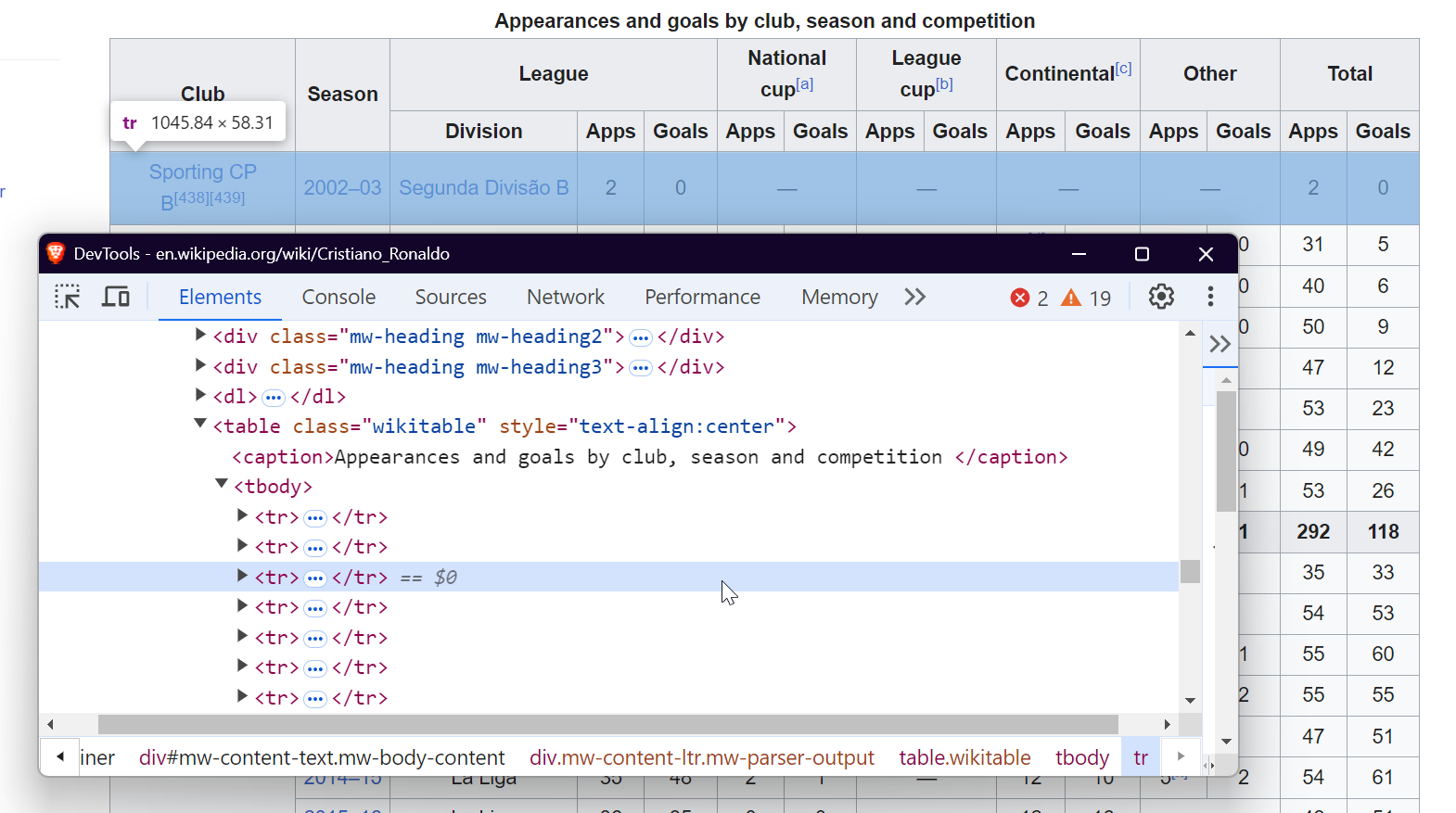
Para extraer párrafos, simplemente seleccione las etiquetas <p> que contienen el contenido textual principal de la página.
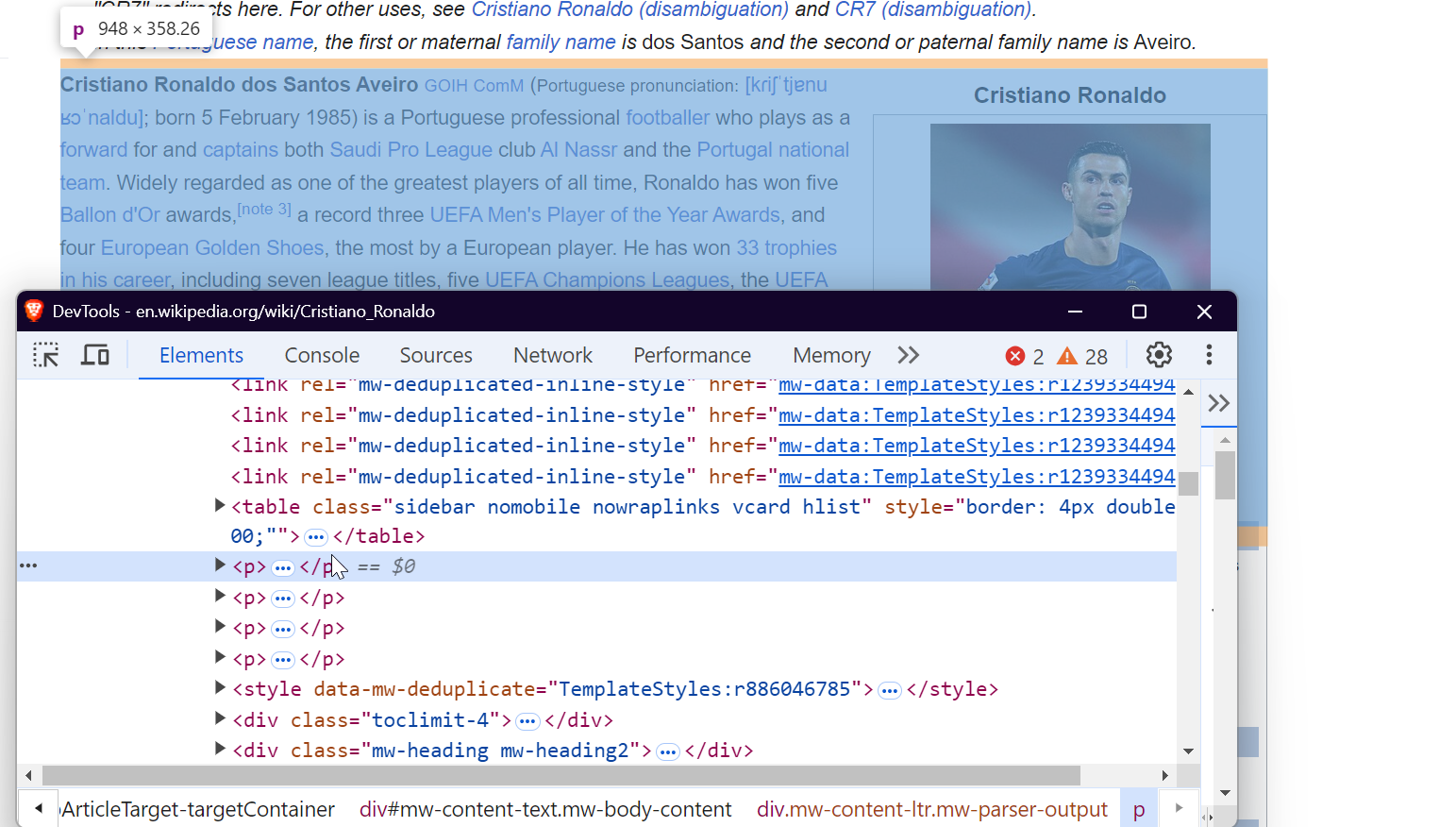
¡Eso es todo! Al seleccionar estos elementos específicos, puede extraer los datos deseados de cualquier página de Wikipedia.
4. Extracción de enlaces
Los artículos de Wikipedia contienen enlaces internos y externos que dirigen a los usuarios a temas relacionados, referencias o recursos externos. Para extraer todos los enlaces de una página de Wikipedia, puede utilizar el siguiente código:
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # Buscar todas las etiquetas de anclaje con el atributo href.
url = link["href"]
if not url.startswith("http"): # Comprueba si la URL es relativa
url = "<https://en.wikipedia.org>" + url # Convierte los enlaces relativos en URL absolutas
links.append(url)
return links # Devuelve la lista de enlaces extraídos
La función soup.find_all('a', href=True) recupera todas las etiquetas <a> de la página que contienen un atributo href, lo que incluye tanto enlaces internos como externos. El código también garantiza que las URL relativas tengan el formato adecuado.
El resultado podría ser similar al siguiente:
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>
5. Extracción de párrafos
Para extraer contenido textual de un artículo de Wikipedia, puede seleccionar las etiquetas <p>, que contienen el cuerpo principal del texto. A continuación se muestra cómo extraer párrafos utilizando BeautifulSoup:
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")] # Extraer texto de las etiquetas de párrafo.
return [p for p in paragraphs if p and len(p) > 10] # Devolver párrafos de más de 10 caracteres.
Esta función captura todos los párrafos de la página y filtra los que están vacíos o son demasiado cortos para evitar contenido irrelevante, como citas o palabras sueltas.
Un ejemplo de resultado:
Cristiano Ronaldo dos Santos AveiroGOIHComM (pronunciación en portugués: [kɾiʃˈtjɐnuʁɔˈnaldu]; nacido el 5 de febrero de 1985) es un futbolista profesional portugués que juega como delantero y capitán tanto del club Al Nassr de la Liga Profesional Saudí como de la selección nacional de Portugal. Ampliamente considerado como uno de los mejores jugadores de todos los tiempos, Ronaldo ha ganado cinco Balones de Oro,[nota 3], un récord de tres premios al Jugador del Año de la UEFA y cuatro Botas de Oro europeas, el mayor número conseguido por un jugador europeo. Ha ganado 33 trofeos en su carrera, incluidos siete títulos de liga, cinco Ligas de Campeones de la UEFA, la Eurocopa de la UEFA y la Liga de Naciones de la UEFA. Ronaldo ostenta los récords de más partidos jugados (183), goles marcados (140) y asistencias (42) en la Liga de Campeones, más partidos jugados (30), asistencias (8) y goles marcados en la Eurocopa (14), goles internacionales (133) y partidos internacionales jugados (215). Es uno de los pocos jugadores que ha disputado más de 1200 partidos como profesional, el mayor número para un jugador de campo, y ha marcado más de 900 goles oficiales en su carrera como senior con su club y su selección, lo que le convierte en el máximo goleador de todos los tiempos.
6. Extracción de tablas
Wikipedia suele incluir tablas con datos estructurados. Para extraer estas tablas, utilice este código:
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}): # Buscar tablas con la clase «wikitable»
table_html = StringIO(str(table)) # Convertir el HTML de la tabla en una cadena
df = pd.read_html(table_html)[0] # Leer la tabla HTML en un DataFrame
tables.append(df)
return tables # Devolver la lista de DataFrames
Esta función busca todas las tablas con la clase wikitable y utiliza pandas.read_html() para convertirlas en DataFrames para su posterior manipulación.
Ejemplo de resultado:
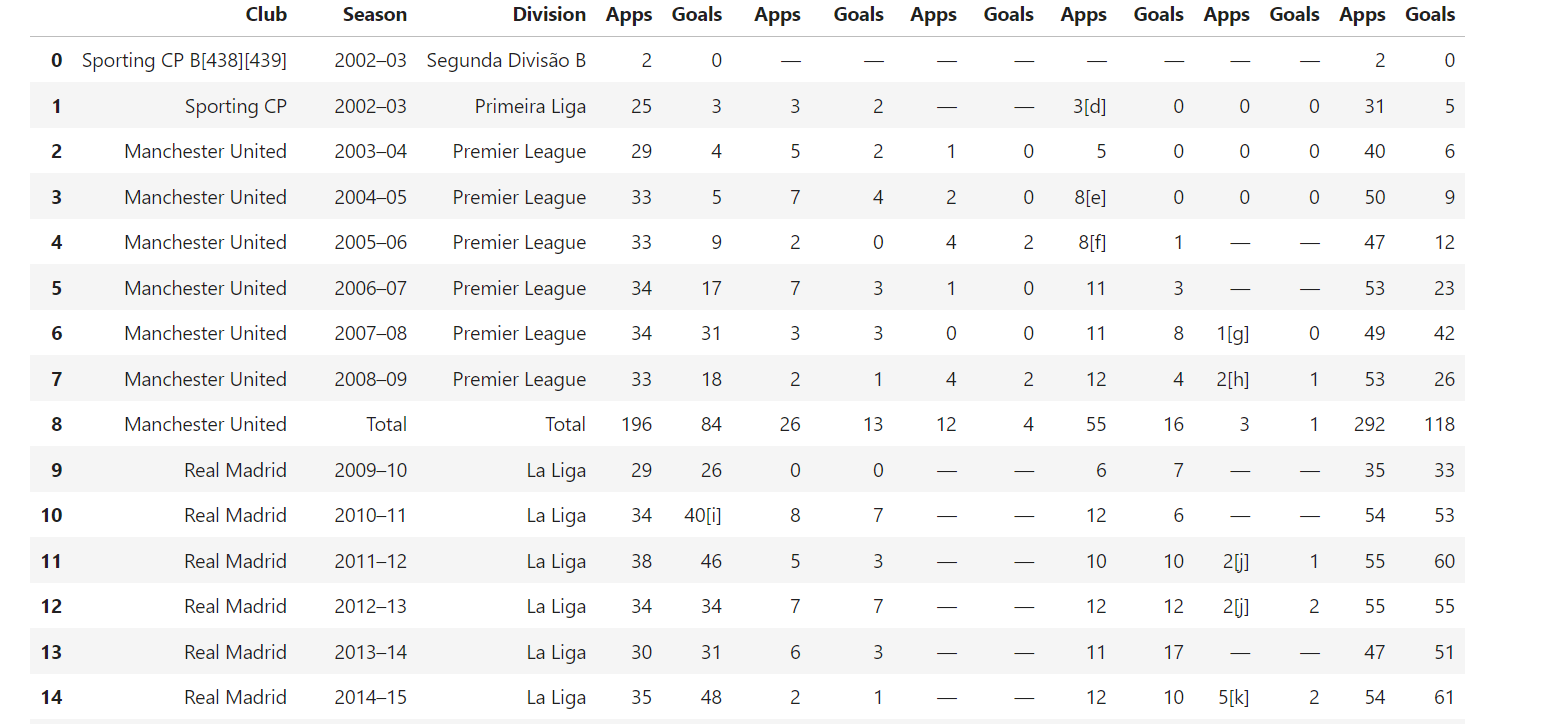
7. Extracción de imágenes
Las imágenes son otro recurso valioso que se puede extraer de Wikipedia. La siguiente función captura las URL de las imágenes de la página:
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True): # Busca todas las etiquetas de imagen con el atributo src
img_url = img["src"]
if not img_url.startswith("http"): # Antepone «https:» a las URL relativas
img_url = "https:" + img_url
if "static/images" not in img_url: # Excluye las imágenes estáticas o no relevantes
images.append(img_url)
return images # Devuelve la lista de URL de imágenes
Esta función busca todas las imágenes (etiquetas<img> ) de la página, añade https: a las URL relativas y filtra las imágenes que no son contenido, asegurando que solo se extraigan las imágenes relevantes.
Ejemplo de resultado:
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>
8. Guardar los datos extraídos
Una vez extraídos los datos, el siguiente paso es guardarlos para su uso posterior. Guardemos los datos en archivos separados para enlaces, imágenes, párrafos y tablas.
def store_data(links, images, tables, paragraphs):
# Guardar enlaces en un archivo de texto
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Guardar imágenes en un archivo JSON
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Guardar párrafos en un archivo de texto
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Guardar cada tabla como un archivo CSV independiente
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
La función store_data organiza los datos recopilados:
- Los enlaces se guardan en un archivo de texto.
- Las URL de las imágenes se guardan en un archivo JSON.
- Los párrafos se almacenan en otro archivo de texto.
- Las tablas se guardan en archivos CSV.
Esta organización facilita el acceso y el trabajo posterior con los datos.
Consulte nuestra guía para obtener más información sobre cómo realizar el parseo y la serialización de datos en JSON en Python.
Poniendo todo junto
Ahora, combinemos todas las funciones para crear un Scraper completo que extraiga y guarde datos de una página de Wikipedia:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# Extraer todos los enlaces de la página
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# Extraer las URL de las imágenes de la página
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True):
img_url = img["src"]
if not img_url.startswith("http"):
img_url = "https:" + img_url
if "static/images" not in img_url: # Excluir imágenes estáticas no deseadas
images.append(img_url)
return images
# Extraer todas las tablas de la página
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # Convertir tabla HTML a DataFrame
tables.append(df)
return tables
# Extraer párrafos de la página
def extract_paragraphs(soup):
párrafos = [p.get_text(strip=True) for p in soup.find_all("p")]
return [p for p in párrafos if p and len(p) > 10] # Filtrar párrafos vacíos o cortos
# Almacenar los datos extraídos en archivos separados
def store_data(links, images, tables, paragraphs):
# Guardar enlaces en un archivo de texto
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Guardar imágenes en un archivo JSON
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Guardar párrafos en un archivo de texto
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Guardar cada tabla como un archivo CSV
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# Función principal para extraer una página de Wikipedia y guardar los datos extraídos
def scrape_wikipedia(url):
response = requests.get(url) # Obtener el contenido de la página
soup = BeautifulSoup(response.text, "html.parser") # Analizar el contenido con BeautifulSoup
links = extract_links(soup)
images = extract_images(soup)
tables = extract_tables(soup)
paragraphs = extract_paragraphs(soup)
# Guardar todos los datos extraídos en archivos
store_data(links, images, tables, paragraphs)
# Ejemplo de uso: extraer la página de Wikipedia de Cristiano Ronaldo
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")
Al ejecutar el script, se crearán varios archivos en tu directorio:
wikipedia_images.json, que contiene todas las URL de las imágenes.wikipedia_links.txtcon todos los enlaces de la página.wikipedia_paragraphs.txtcon los párrafos extraídos.- Archivos CSV para cada tabla encontrada en la página (por ejemplo,
wikipedia_table_1.csv,wikipedia_table_2.csv).
El resultado podría ser similar al siguiente:

¡Eso es todo! Ha extraído y almacenado correctamente los datos de Wikipedia en archivos separados.
Configuración de la API de Bright Data Wikipedia Scraper
Configurar y utilizar la API de Bright Data Wikipedia Scraper es muy sencillo y se puede hacer en solo unos minutos. Siga estos pasos para empezar rápidamente y comenzar a recopilar datos de Wikipedia con facilidad.
Paso 1: Crea una cuenta en Bright Data
Vaya al sitio web de Bright Data e inicie sesión en su cuenta. Si aún no tiene una cuenta, cree una: es gratis. Siga estos pasos:
- Vaya al sitio web de Bright Data.
- Haga clic en «Prueba gratuita» y siga las instrucciones para crear su cuenta.
- Una vez que esté en su panel de control, busque el icono de la tarjeta de crédito en la barra lateral izquierda para acceder a la página de facturación.
- Añada un método de pago válido para activar su cuenta.
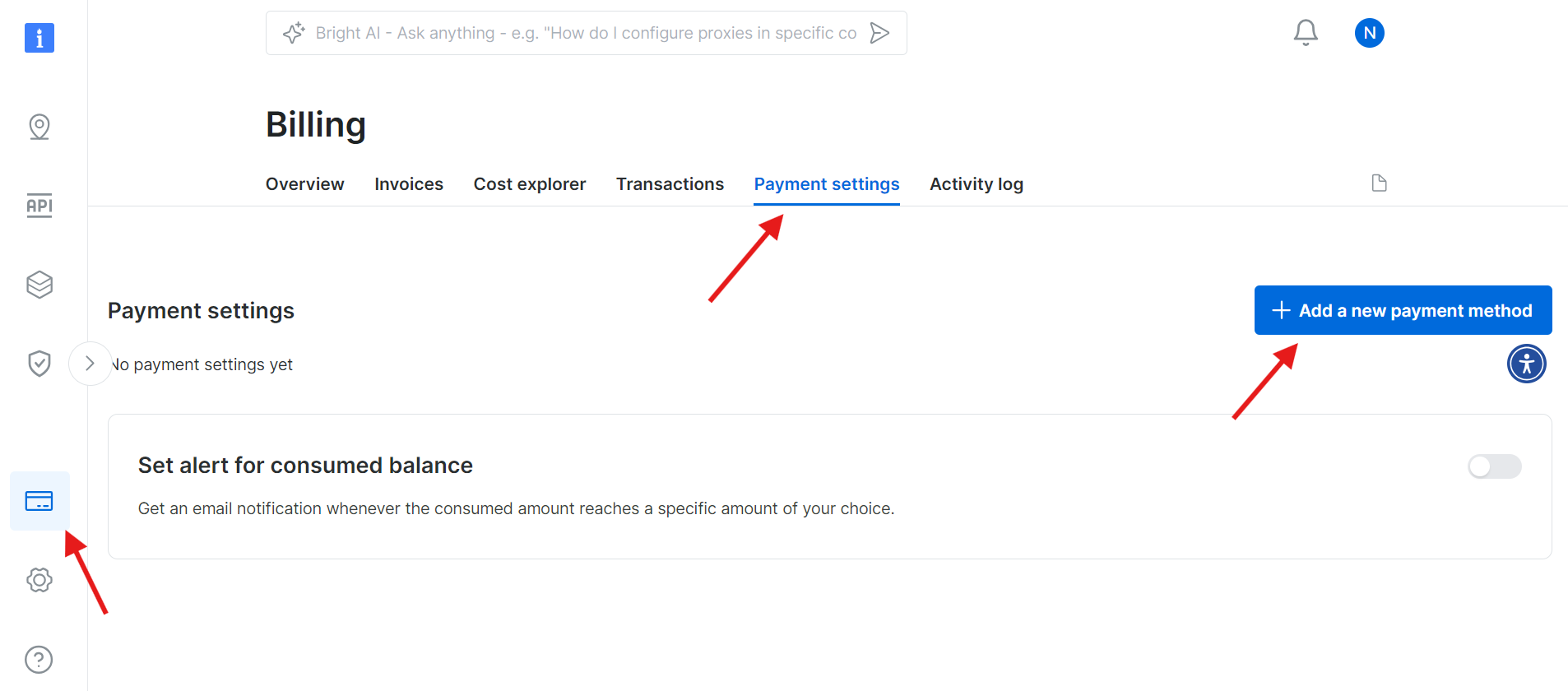
Una vez que su cuenta se haya activado correctamente, vaya a la sección API de Web Scraper en el panel de control. Aquí puede buscar cualquier API de Web Scraper que desee utilizar. Para nuestros fines, busque Wikipedia.
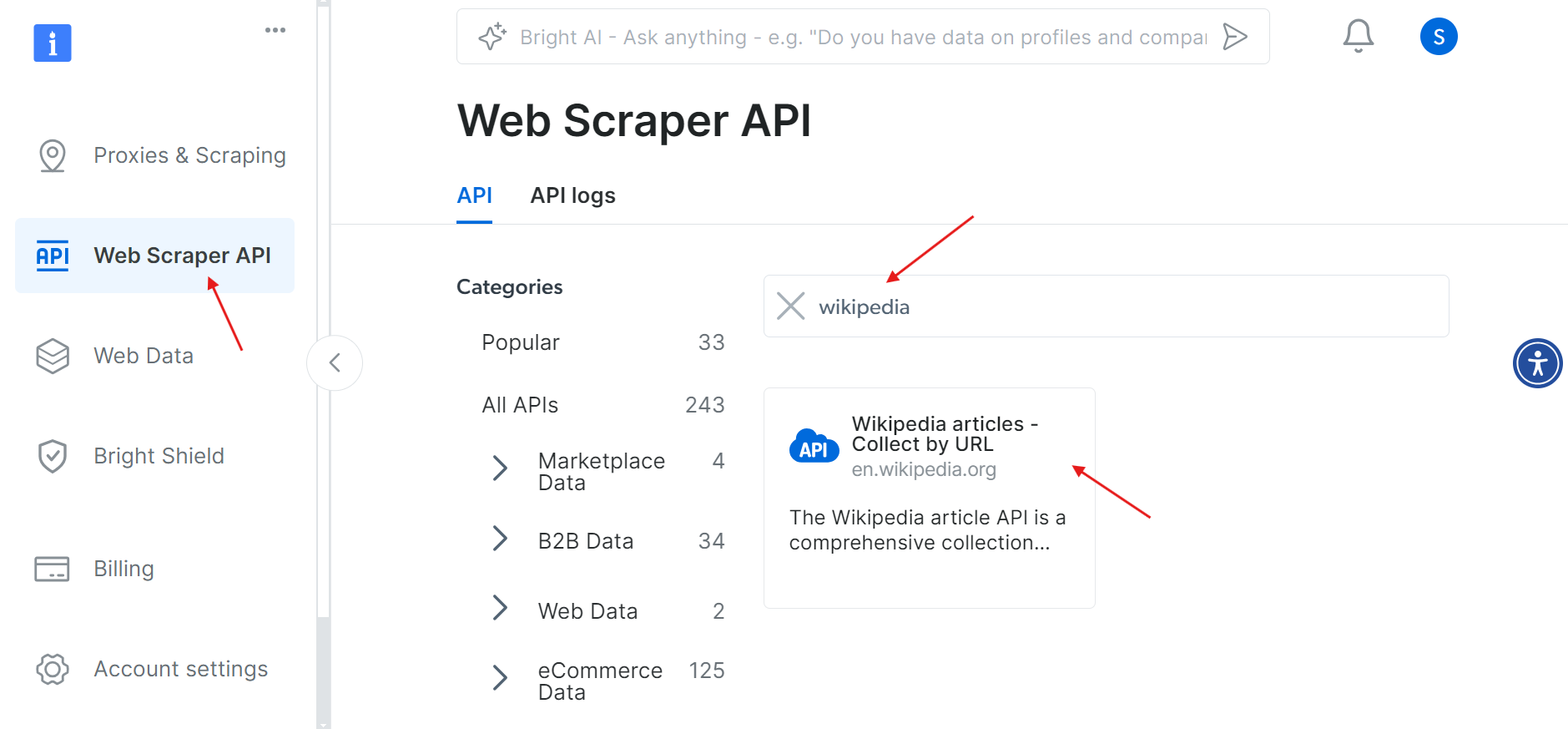
Haga clic en la opción «Artículos de Wikipedia: recopilar por URL ». Esto le permitirá recopilar artículos de Wikipedia simplemente proporcionando las URL.
Paso 2: Comience a configurar una llamada API
Una vez que haya hecho clic, se le dirigirá a una página donde podrá configurar su llamada API.
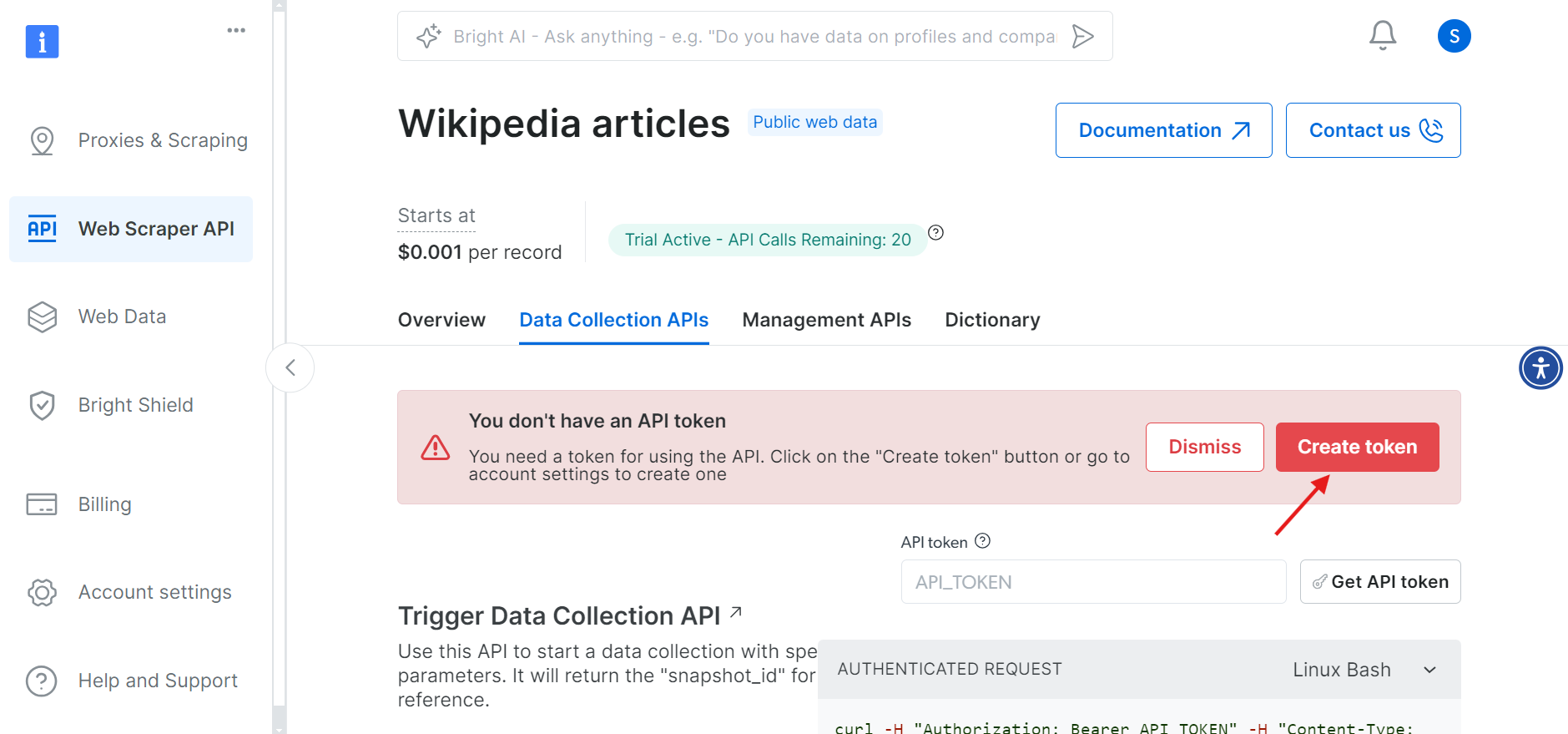
Antes de continuar, debe crear un token de API para autenticar sus llamadas a la API. Haga clic en el botón «Crear token» y copie el token generado. Guarde este token en un lugar seguro, ya que lo necesitará más adelante.
Paso 3: Configure los parámetros y genere la llamada a la API
Ahora que tiene su token, está listo para configurar su llamada API. Proporcione las URL de las páginas de Wikipedia que desea extraer y, en la parte derecha, se generará un comando cURL basado en su entrada.
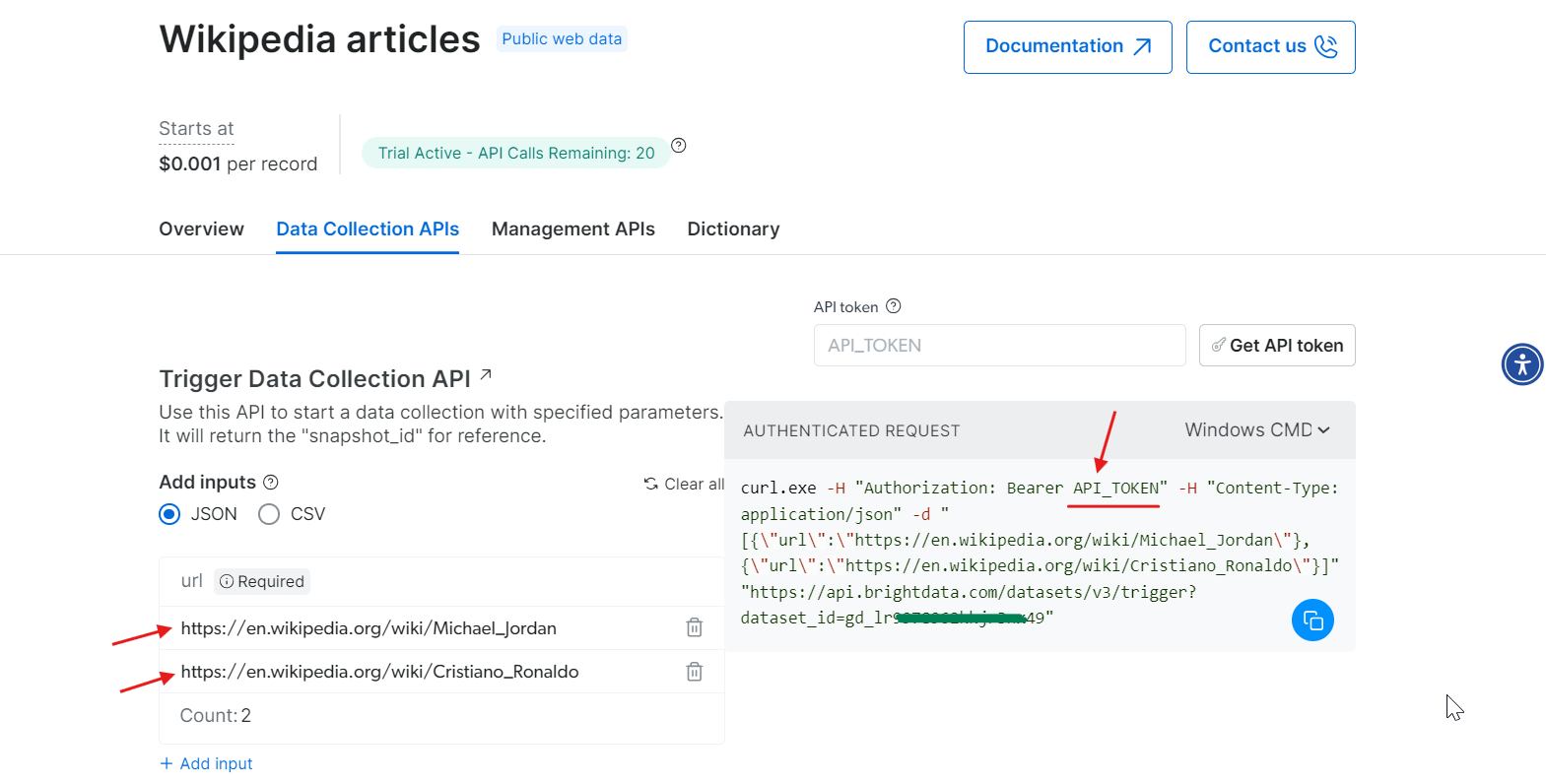
Copie el comando cURL, sustituya API_Token por su token real y ejecútelo en su terminal. Esto generará un snapshot_id, que utilizará para recuperar los datos extraídos.
Paso 4: Recuperar los datos
Con el snapshot_id que ha generado, ya puede recuperar los datos. Solo tiene que pegar este ID en el campo Snapshot ID y la API generará automáticamente un nuevo comando cURL en la parte derecha. Puede utilizar este comando para extraer los datos. Además, puede elegir el formato de archivo de los datos, como JSON, CSV u otras opciones disponibles.
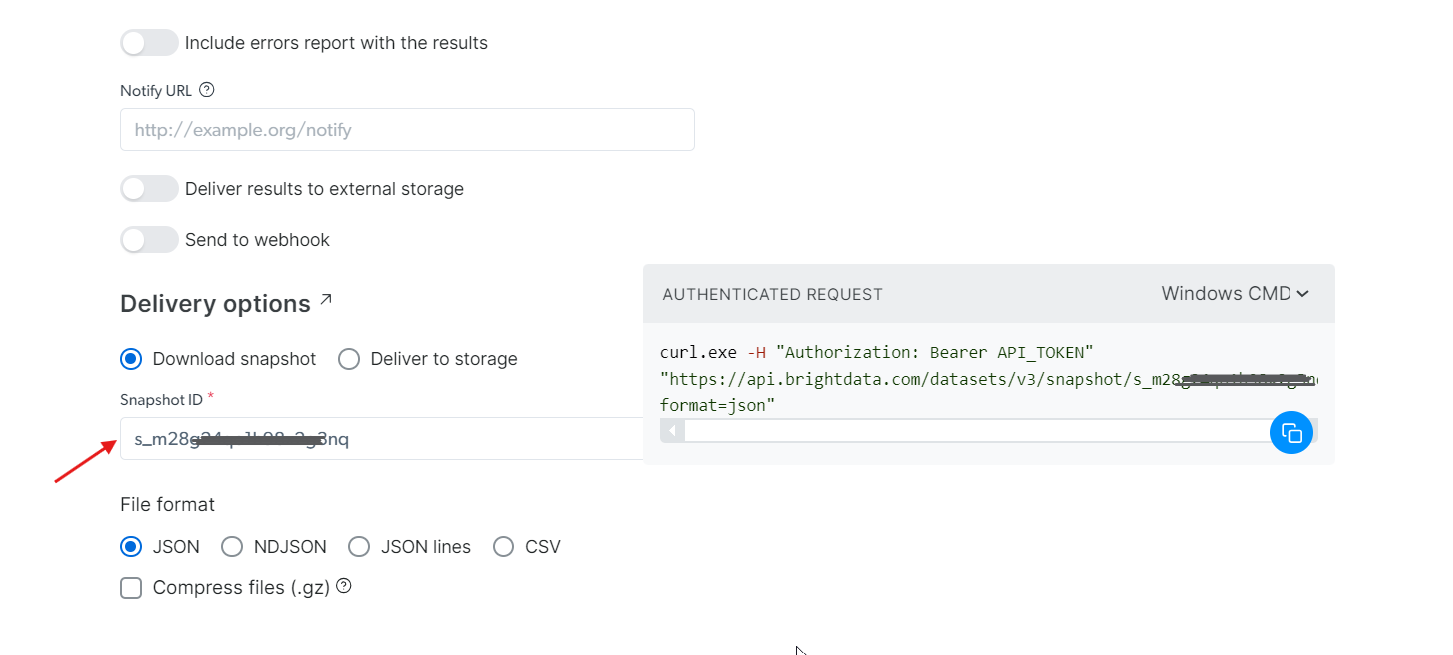
También tiene la opción de enviar los datos a diferentes servicios de almacenamiento, como Amazon S3, Google Cloud Storage o Microsoft Azure Storage.
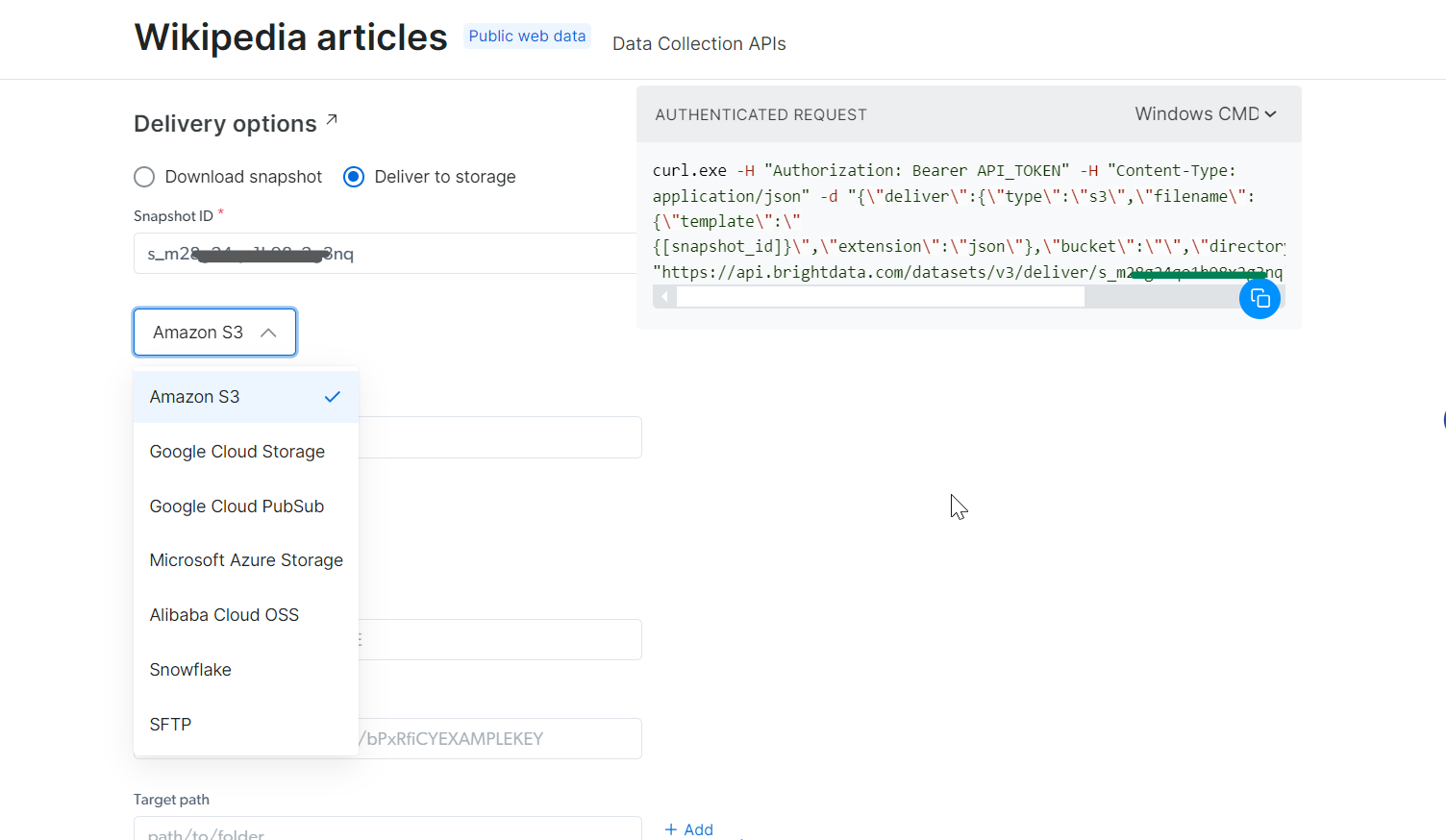
Paso 5: Ejecutar el comando
Para este ejemplo, supongamos que desea obtener los datos en un archivo JSON. Elija JSON como formato de archivo y copie el comando cURL generado. Si desea guardar los datos directamente en un archivo, simplemente añada -o my_data.json al final del comando cURL. Si prefiere almacenar estos datos en su máquina local, al añadir -o los datos se almacenarán automáticamente en el archivo especificado.
Ejecútelo en su terminal y tendrá todos los datos extraídos en solo unos segundos.
curl.exe -H "Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487" "<HTTPS://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json>" -o my_data.json
¿No quieres encargarte tú mismo del Scraping web de Wikipedia, pero sigues necesitando los datos? Considera la posibilidad de comprar un Conjunto de datos de Wikipedia.
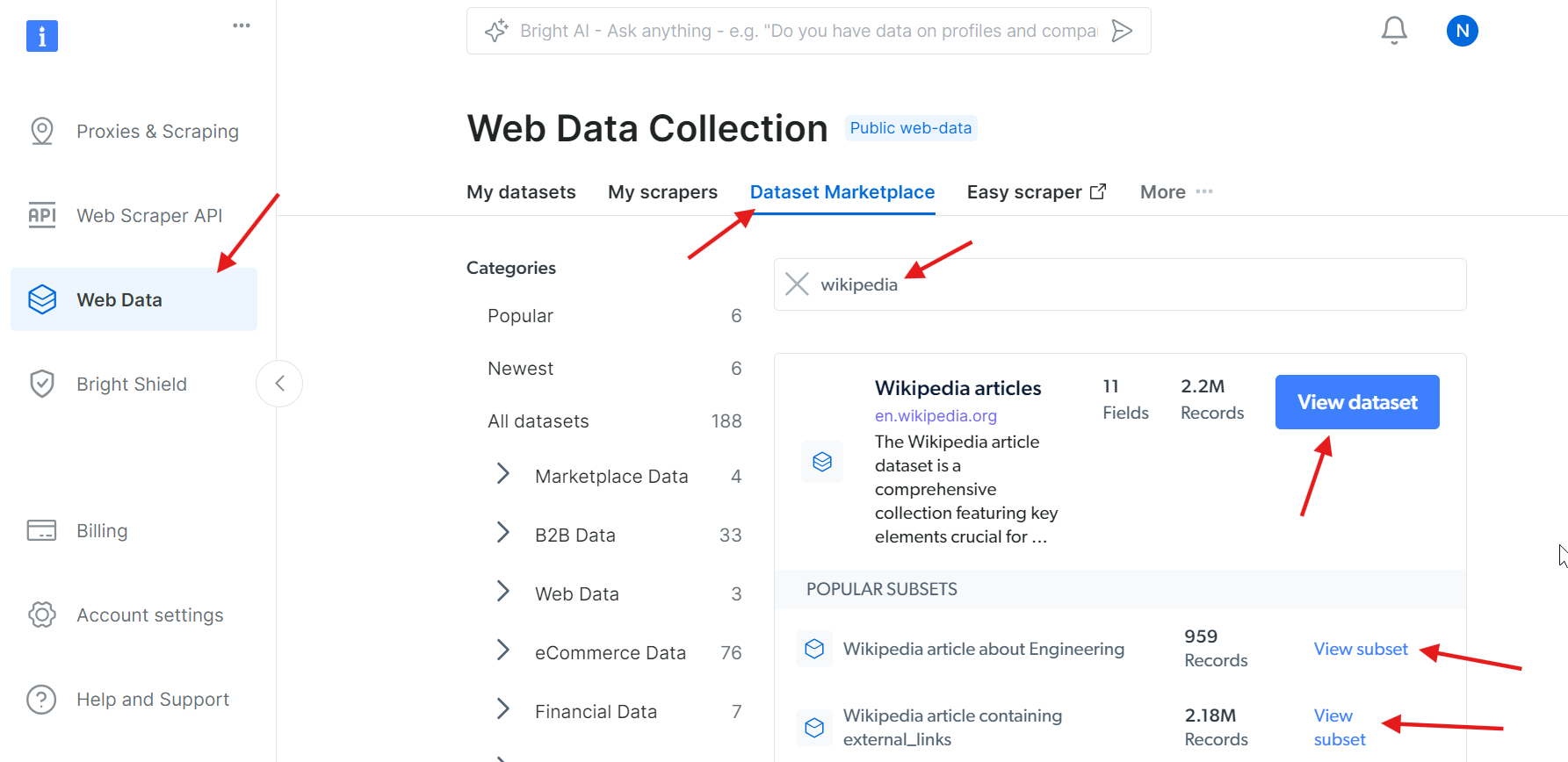
Sí, ¡así de sencillo!
Conclusión
Este artículo ha cubierto todo lo que necesitas para empezar a extraer datos de Wikipedia con Python. Hemos extraído con éxito una gran variedad de datos, incluyendo URL de imágenes, contenido de texto, tablas y enlaces internos y externos. Sin embargo, para una extracción de datos más rápida y eficiente, utilizar la API Wikipedia Scraper de Bright Data es una solución sencilla.
¿Quiere extraer datos de otros sitios web? Regístrese ahora y pruebe nuestra API Web Scraper. ¡Comience hoy mismo su prueba gratuita!





