Una institución financiera global necesita combinar datos de mercado en tiempo real de la web con análisis internos confidenciales. Sus datos se dividen entre un almacén local (para datos confidenciales de clientes) y Azure Data Lake (para análisis escalables). Esta guía le enseña cómo conectar ambos a través de las API de Bright Data para una integración segura y casi en tiempo real.
Aprenderá:
- Por qué las organizaciones financieras necesitan configuraciones de datos híbridas
- Cómo recopilar datos web que cumplan con la normativa con Bright Data
- Cómo configurar una sincronización bidireccional segura entre Azure Data Lake y un almacén local
- Cómo validar la sincronización de datos de extremo a extremo
- Cómo ejecutar análisis unificados sin mover datos confidenciales
- Dónde encontrar las configuraciones y scripts de ejemplo en GitHub
¿Qué es la integración híbrida de datos y por qué la necesita el sector financiero?
Las organizaciones financieras operan bajo estrictas regulaciones como GDPR, SOC 2, MiFID II y Basilea III, que controlan dónde pueden residir los datos. Los datos web públicos alimentan la inteligencia de mercado en tiempo real, mientras que los Conjuntos de datos internos existentes respaldan el modelado a largo plazo y el cumplimiento normativo. Los sistemas ETL tradicionales rara vez unifican ambos de forma segura.
El reto: ¿Cómo se combinan los datos de mercado externos con los análisis internos sin comprometer la seguridad o el cumplimiento normativo?
La solución: Bright Data proporciona datos web estructurados y conformes a través de API, mientras que la infraestructura híbrida de Azure mantiene los datos confidenciales en las instalaciones.
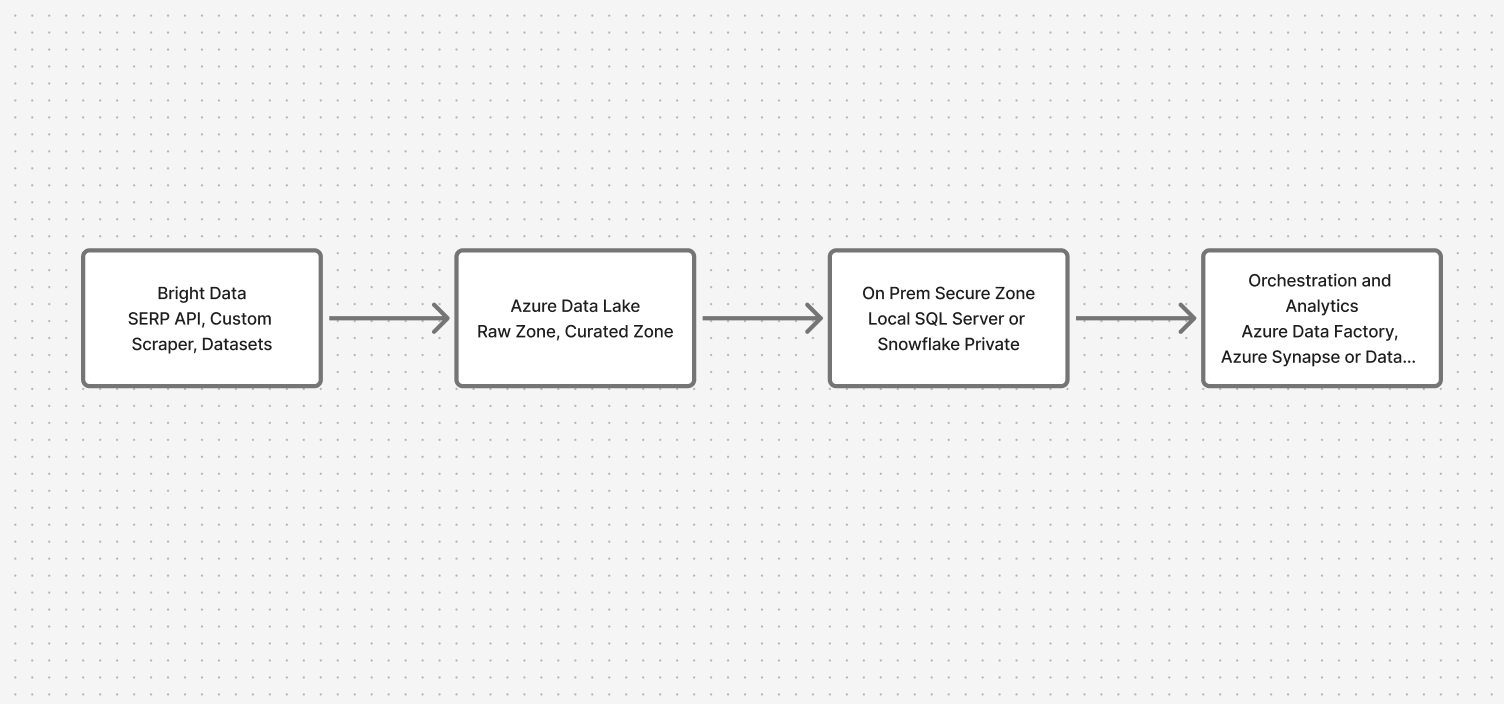
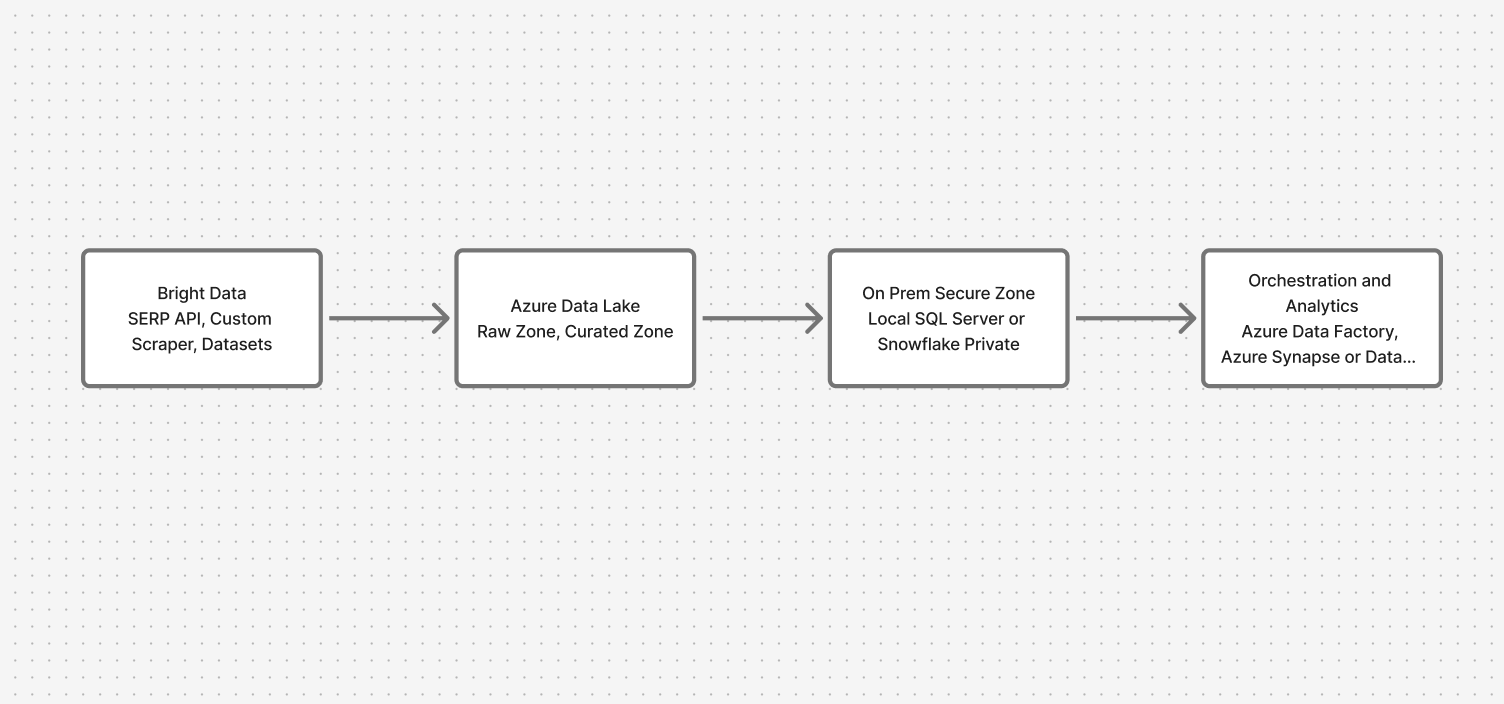
Descripción general de la arquitectura: conectar la nube y las instalaciones locales de forma segura
El sistema se mueve a través de cuatro capas clave:
- Recopilación de datos: API de Bright Data (API SERP, Scraper personalizado, Conjuntos de datos)
- Zona de aterrizaje en la nube: Azure Data Lake (zonas sin procesar y curadas)
- Zona segura local: servidor SQL local o Snowflake
- Orquestación y análisis: Azure Data Factory con puntos finales privados, Synapse/Databricks para consultas federadas
Esto garantiza que los datos web fluyan mientras que los datos confidenciales permanecen en su sitio.
Requisitos previos
Antes de empezar:
- Cuenta activa de Bright Data con acceso a la API
- Suscripción a Azure con Data Lake, Data Factory y Synapse o Databricks
- Base de datos local accesible a través de una red privada (ODBC o JDBC)
- Enlace privado seguro (ExpressRoute, VPN de sitio a sitio o punto de conexión privado)
- Cuenta de GitHub para clonar el repositorio de muestra
💡 Sugerencia: primero, ejecute todos los pasos en un área de trabajo que no sea de producción.
Implementación paso a paso
1. Recopilar datos financieros web con Bright Data
Configuraremos el Scraper personalizado de Bright Data para extraer precios de acciones, documentos normativos y noticias financieras. El Scraper genera un JSON estructurado listo para su análisis.
Así es como se ven los datos:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
Configuración simplificada: El archivo scraper_config.yaml define qué extraer y con qué frecuencia. Se centra en sitios web financieros, extrae puntos de datos específicos y programa la recopilación cada hora con notificaciones webhook.
Este enfoque garantiza que se obtengan datos limpios y estructurados sin intervención manual.
# scraper_config.yaml
nombre: financial_data_aggregator
descripción: >
Recopila precios de acciones en tiempo real, documentos presentados ante la SEC y titulares de noticias financieras
para la integración de la nube híbrida.
objetivos:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
selectors:
- name: symbol
type: text
selector: "h1[data-testid='quote-header'] span"
- nombre: precio
tipo: texto
selector: "fin-streamer[data-field='regularMarketPrice']"
- nombre: titular
tipo: texto
selector: "article h3 a"
- nombre: tipo_archivo
tipo: texto
selector: "td[class*='filetype']"
- nombre: fecha_archivo
tipo: texto
selector: "td[class*='filedate']"
- nombre: filing_url
tipo: enlace
selector: "td[class*='filedesc'] a"
paginación:
tipo: enlace siguiente
selector: "a[aria-label='Siguiente']"
salida:
formato: json
nombre_archivo: financial_data.json
programación:
frecuencia: cada hora
zona horaria: UTC
webhook: "https://<tu-punto-final-webhook>/brightdata/ingest"
notificaciones:
correo_eléctrico_en_caso_de_éxito: [email protected]
correo_eléctrico_en_caso_de_fallo: [email protected]2. Ingesta de datos de forma segura en Azure Data Lake
Ahora enviamos los datos recopilados a Azure Data Lake mediante una función de Azure. Esta función actúa como una puerta de enlace segura:
- Recibe datos JSON a través de HTTPS POST desde Bright Data
- Autentica utilizando Managed Identity (sin secretos que gestionar)
- Organiza los archivos por fuente y marca de tiempo para facilitar el seguimiento
- Añade etiquetas de metadatos para el seguimiento del cumplimiento
El resultado: sus datos de mercado se almacenan en carpetas particionadas, lo que facilita su gestión y consulta.
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# Variables de entorno
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # p. ej., "https://myaccount.blob.core.windows.net"
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# Inicializar el cliente blob con identidad administrada
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Parseo del JSON entrante de Bright Data
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# Preparar la ruta de destino
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# Cargar el archivo JSON
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"Datos de {source} guardados en {blob_path}",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""Ayuda sencilla para identificar el nombre de la fuente."""
# Buscar el campo «source» en el primer elemento de la matriz.
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. Sincronizar subconjuntos no confidenciales con el entorno local
No todos los datos tienen que viajar entre entornos. Utilizamos Azure Data Factory como filtro inteligente, seleccionando cuidadosamente solo los subconjuntos de datos que son seguros para sincronizar con su almacén local.
Así es como funciona el proceso en la práctica:
La canalización comienza escaneando los nuevos archivos que han llegado a su lago de datos. A continuación, aplica un filtrado inteligente para incluir solo datos públicos y no confidenciales, como precios de mercado y símbolos bursátiles, pero no información de clientes ni análisis propietarios.
¿Qué lo hace seguro y fiable?
Los puntos de conexión privados crean un túnel dedicado entre Azure y su infraestructura local, sin pasar por la Internet pública. Esto elimina la exposición a amenazas externas y garantiza un rendimiento constante.
La carga incremental con seguimiento de marcas de agua significa que el sistema solo mueve los registros nuevos o modificados. En combinación con la validación automática de esquemas, esto evita duplicados y mantiene ambos entornos perfectamente alineados.
Ahora veamos cómo se traduce esto en código de canalización real:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"name": "Filter_PublicData",
"type": "Filter",
"dependsOn": [
{
"activity": "Get_Metadata",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
"preCopyScript": "IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));"
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Log_Load_Status",
"type": "StoredProcedure",
"dependsOn": [
{
"activity": "Copy_To_OnPrem_SQL",
"dependencyConditions": ["Succeeded", "Failed"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
"linkedServiceName": {
"referenceName": "OnPrem_SQL_LinkedService",
"type": "LinkedServiceReference"
}
}
],
"annotations": ["HybridIntegrationDemo"]
}
}Desglose de los componentes clave:
- Lookup_NewFiles actúa como el control de su canalización: primero identifica qué datos nuevos han llegado al lago de datos y necesitan procesarse. Esto evita que el sistema vuelva a procesar archivos antiguos innecesariamente.
- Get_Metadata examina estos archivos detenidamente, comprobando su tamaño, fechas de modificación y estructura. Este paso garantiza que estamos trabajando con archivos completos y válidos antes de continuar.
- Filter_PublicData es donde se produce la magia de la seguridad. Utilizando los metadatos de clasificación que hemos incorporado anteriormente, filtra automáticamente cualquier dato confidencial, asegurando que solo la información pública del mercado continúe por el canal.
- Copy_To_OnPrem_SQL se encarga de la transferencia real, pero con medidas de seguridad inteligentes. El preCopyScript garantiza que la tabla de destino exista con el esquema correcto, mientras que la conexión del punto final privado mantiene todo dentro de su red segura.
- Log_Load_Status proporciona una visibilidad crucial, ya que cada operación de sincronización se registra en su base de datos local. Esto crea el registro de auditoría que requieren los equipos de cumplimiento normativo, al tiempo que ofrece al personal de operaciones una visibilidad inmediata del estado del proceso.
La ventaja real: su equipo local obtiene el contexto del mercado y la información en tiempo real que necesita, mientras que los datos confidenciales de sus clientes y los modelos patentados permanecen seguros donde deben estar. Es lo mejor de ambos mundos: agilidad y seguridad.
4. Habilite la validación de sincronización bidireccional
La coherencia de los datos es esencial para tomar decisiones empresariales fiables. Necesita tener la seguridad de que sus análisis en la nube y sus informes locales muestran los mismos números. Hemos creado comprobaciones de validación de datos automatizadas que se ejecutan continuamente para ofrecer esta garantía.
Así es como funciona el proceso de validación:
- Las comparaciones del recuento de filas sirven como su primer sistema de alerta. Esta comprobación inicial identifica rápidamente problemas importantes, como transferencias fallidas o cargas de datos incompletas. Si los recuentos no coinciden entre la nube y las instalaciones locales, sabrá inmediatamente que hay algo que requiere investigación.
- Las sumas de comprobación hash crean huellas digitales de sus datos. En lugar de comparar manualmente miles de registros, generamos hash criptográficos únicos para cada Conjunto de datos. Incluso un solo cambio de carácter produce un hash completamente diferente. Este método permite detectar instantáneamente la corrupción de datos o las transferencias parciales.
- La sincronización casi en tiempo real significa que las validaciones se ejecutan cada pocos minutos. No hay que esperar a que se realicen trabajos por lotes durante la noche para descubrir los problemas. El sistema detecta los problemas en cuestión de minutos, no de días, lo que mantiene sus datos actualizados y fiables.
- Las alertas automatizadas convierten los problemas de datos en acciones inmediatas. Cuando el sistema detecta discrepancias, envía notificaciones a través de Slack, correo electrónico o sus herramientas de supervisión existentes. Su equipo puede abordar los problemas antes de que afecten a las decisiones empresariales.
Así es como funciona en la práctica:
def validate_sync():
# Comparar el recuento de registros entre sistemas
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"Discrepancia en el recuento de registros: Nube {cloud_count} frente a Local {onprem_count}")
return False
# Generar sumas de comprobación para la validación de la integridad de los datos
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"Fallo en la integridad de los datos: las sumas de comprobación no coinciden")
return False
# Verificar la puntualidad de la sincronización
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"Se ha detectado un retraso en la sincronización: Última sincronización {last_sync_time}")
return False
return True5. Cree análisis unificados sin mover datos confidenciales
Aquí está la parte más potente: puede unir datos en la nube y locales de forma virtual sin mover información confidencial.
Ejemplo de consulta:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapse crea tablas externas que apuntan a su almacén local, mientras que Databricks utiliza conexiones JDBC con controles de acceso basados en roles.
Prácticas recomendadas de cumplimiento y registro de auditoría
Cumplir con los requisitos legales y de auditoría requiere un enfoque sistemático del seguimiento y la seguridad de los datos. Así es como creamos un marco que cumple con la normativa:
- El registro completo del movimiento de datos garantiza que cada transferencia se registre en Azure Monitor y en su SIEM local. Esto crea un registro inmutable de qué datos se han movido, dónde y cuándo, lo que proporciona a los auditores una trazabilidad completa.
- La procedencia clara de los datos utiliza los ID de fuente de Bright Data como huellas digitales. Estas etiquetas permanecen con sus datos durante todo su ciclo de vida, lo que le permite rastrear cualquier análisis hasta su colección de origen original.
- El seguimiento automatizado del linaje con Azure Purview mapea cómo se transforman los datos a través de sus canalizaciones. Documenta automáticamente qué fuentes de datos sin procesar contribuyen a informes específicos y qué transformaciones se aplicaron.
- El control de acceso centralizado sincroniza Azure AD con LDAP local. Esto aplica sus políticas de seguridad existentes a ambos entornos, lo que garantiza una gestión coherente de los permisos en los sistemas en la nube y locales.
El resultado es la generación automatizada de informes de cumplimiento, la gestión centralizada de la seguridad y un marco que protege los datos sin ralentizar a su equipo.
Retos comunes y cómo ayuda Bright Data
| Reto | Característica de Bright Data |
|---|---|
| Bloqueos de IP o límites de velocidad | Proxiesresidenciales y de ISP (más de 150 millones de IP) |
| CAPTCHAs o barreras de inicio de sesión | Web Unlocker para resolución automatizada |
| Sitios web con mucho JavaScript | Navegador de scraping (renderización basada en Playwright) |
| Cambios frecuentes en el sitio | Servicios de datos gestionados con corrección automática mediante IA |
Conclusión y próximos pasos
Las organizaciones financieras pueden fusionar de forma segura datos públicos y privados utilizando las API de Bright Data junto con la infraestructura híbrida de Azure.
El resultado es un sistema compatible que ofrece agilidad y control.
💡 Si prefiere un acceso a los datos totalmente gestionado, utilice los servicios de datos gestionados de Bright Data para gestionar el scraping y la entrega de principio a fin.