
Este artículo explica cómo ejecutar cargas de trabajo de scraping web a gran escala utilizando PySpark y Bright Data. Si necesitas extraer datos de cientos de miles de páginas de productos, realizar el monitoreo de precios en cientos de sitios web o crear Conjuntos de datos de entrenamiento a partir de millones de páginas, los scripts para una sola máquina no te servirán.
Los patrones que se muestran aquí te enseñan a distribuir el trabajo de scraping entre clústeres, manteniendo la fiabilidad del proceso a medida que aumenta el volumen de solicitudes.
Al final, sabrás cómo:
- Tratar grandes listas de URL como Conjuntos de datos distribuidos utilizando PySpark
- Ejecutar cargas de trabajo de scraping de manera eficiente a nivel de partición
- Diseñar trabajadores que puedan gestionar reintentos y fallos sin reiniciar todo el trabajo
- Gestionar el enrutamiento de Proxies y la fiabilidad de la red a medida que aumenta el volumen de solicitudes
Cuando el Scraping web se convierte en un problema distribuido
La mayoría de los proyectos de scraping comienzan de la misma manera: un desarrollador escribe un script, lee una lista de URL, envía solicitudes y guarda los resultados.
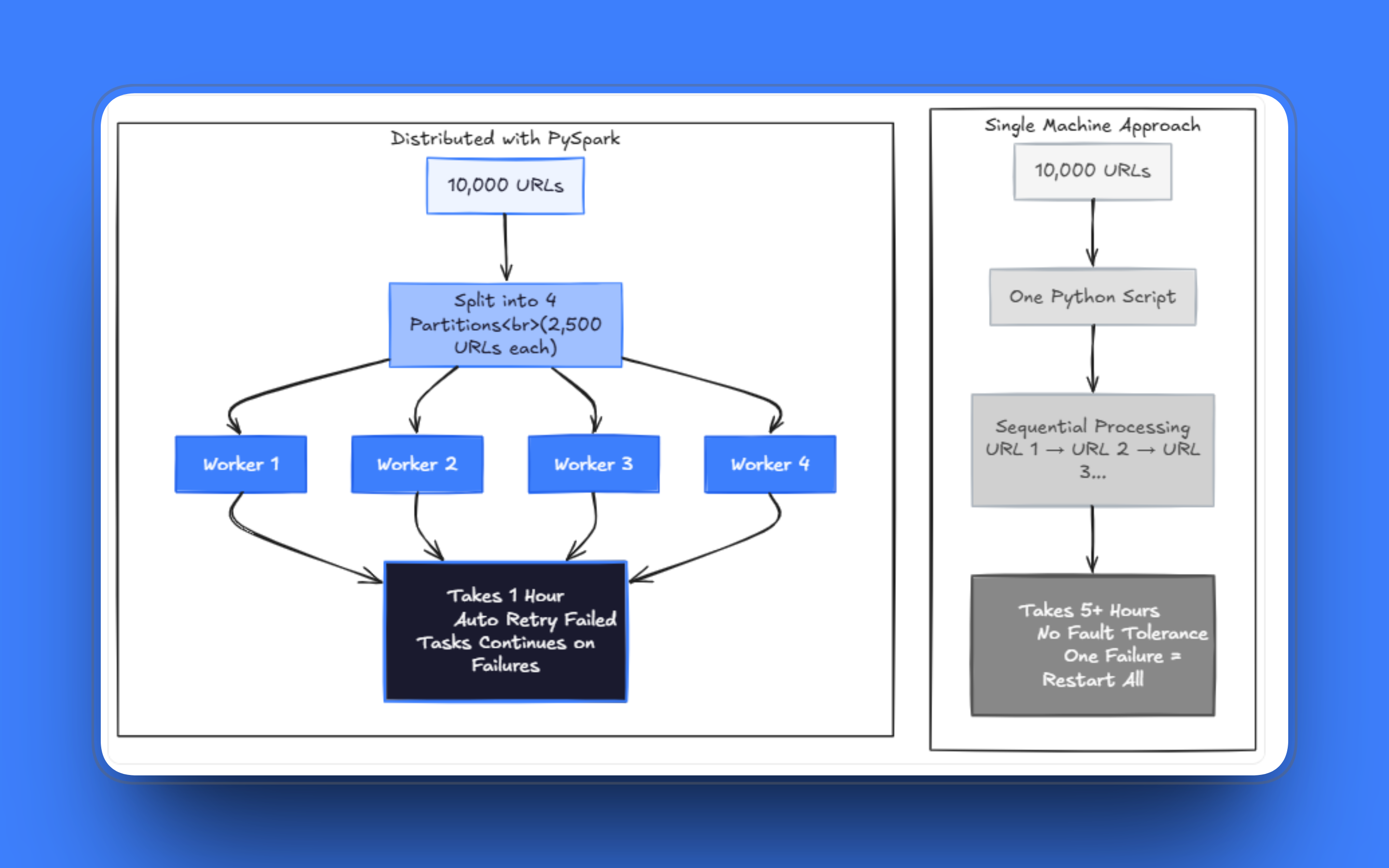
Las grietas aparecen una vez que la carga de trabajo se amplía. Los trabajos que antes tardaban minutos empiezan a tardar horas. Unas pocas solicitudes fallidas pueden paralizar una ejecución tras procesar miles de páginas, y gestionar los reintentos dentro del mismo script mientras se gestiona la obtención y el Parseo se convierte rápidamente en un caos. He visto equipos mantener estos Scrapers de un solo archivo durante meses, parcheando un caso extremo tras otro, cuando el verdadero problema es que la arquitectura ya no se adapta al problema.
Rastrear cientos de miles de páginas en una sola máquina lleva una cantidad de tiempo poco práctica, incluso con subprocesos. A gran escala, es necesario ejecutar el proceso en múltiples trabajadores, y el sistema debe seguir funcionando incluso cuando falle una parte de las solicitudes. El camino a seguir es dejar de pensar en la lista de URL como una cola ordenada y empezar a tratarla como un Conjunto de datos que se puede distribuir.
Por qué PySpark es una buena opción en este caso
PySpark se basa en la idea de dividir los Conjuntos de datos en particiones y procesarlos en paralelo a través de un clúster de máquinas. El modelo se adapta directamente al Scraping web: cada URL es una unidad de trabajo, las particiones agrupan las URL en lotes y los ejecutores procesan esos lotes de forma independiente.
En lugar de gestionar una cola con Celery o una configuración de multiprocesamiento propia, Spark proporciona tolerancia a fallos y programación sin que tengas que crearlas tú mismo. Si una tarea falla, Spark la reprograma. Si un nodo se cae, el trabajo se reasigna. Aún así, necesitas escribir una lógica de reintento sensata dentro de tus tareas, pero la capa de orquestación ya está gestionada.
Patrón 1: Las URL como un conjunto de datos distribuido
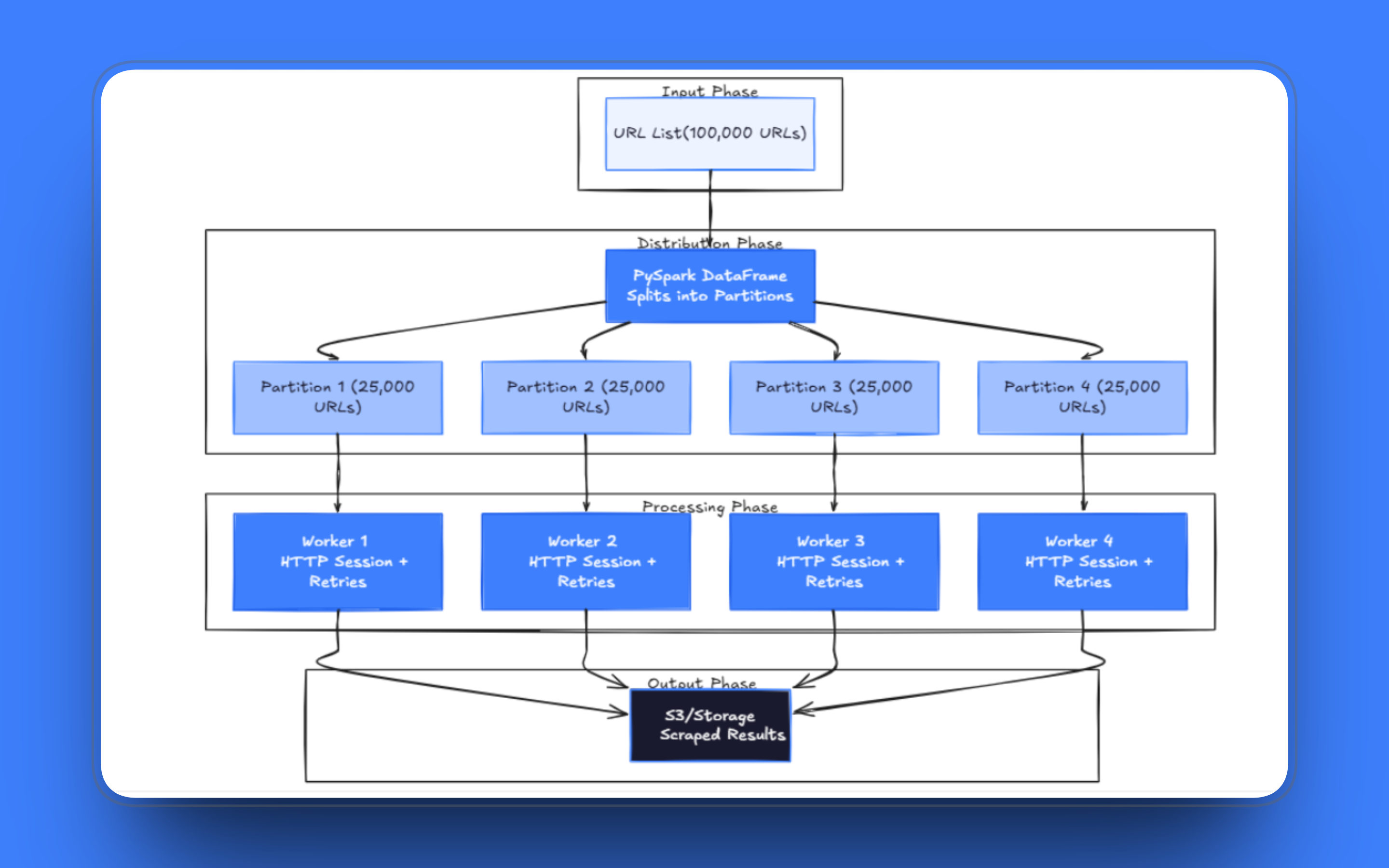
La base de cualquier canal de scraping distribuido es cómo se carga la lista de URL. Con PySpark, las URL se introducen en un DataFrame y Spark las distribuye automáticamente entre los trabajadores. Cada partición contiene una porción de los datos, y Spark asigna esas particiones a los ejecutores disponibles.
Una configuración básica tiene el siguiente aspecto:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])En producción, se cargaría la lista de URL desde un archivo, una tabla de base de datos o un almacenamiento de objetos, en lugar de codificarla de forma estática. El esquema también es importante una vez que se empiezan a añadir metadatos como la prioridad de rastreo o las marcas de tiempo de la última recuperación.
El número de particiones es la primera decisión de ajuste a la que te enfrentarás. Si hay muy pocas particiones, los trabajadores se quedan inactivos esperando solicitudes lentas; si hay demasiadas, Spark dedica una cantidad desproporcionada de tiempo a la sobrecarga de programación en lugar de a la recuperación real.
Un punto de partida razonable para una carga de trabajo de scraping es de 2 a 4 particiones por núcleo de ejecutor; luego, ajústalo en función de los registros de tareas. Si los ejecutores terminan las particiones en menos de un segundo o tardan sistemáticamente más de 10 minutos, es necesario ajustar el tamaño de las particiones.
Patrón 2: Ejecutar solicitudes a nivel de partición
El primer intento natural es aplicar una transformación a nivel de fila a cada URL del DataFrame. Este enfoque funciona, pero no es adecuado para el Scraping web. Cada solicitud desencadena una llamada de función independiente, lo que significa una nueva conexión para cada URL a menos que se tenga cuidado. La sobrecarga se acumula rápidamente con millones de filas.
El enfoque correcto es mapPartitions(). En lugar de procesar una fila a la vez, le pasa a tu función una partición completa como un iterador. Creas una sesión HTTP una vez y la reutilizas para cada solicitud de la partición. El uso de un grupo de conexiones durante una sesión de larga duración es significativamente más rápido que establecer una nueva conexión TCP para cada URL, especialmente con servidores que admiten HTTP keep-alive.
from pyspark.sql import SparkSession
import requests
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception:
yield {
"url": url,
"status_code": None,
"html": None
}
results = df.rdd.mapPartitions(scrape_partition)Las solicitudes fallidas devuelven un registro con campos nulos en lugar de generar una excepción. Este enfoque es intencionado. Permitir que se propague una excepción detiene toda la tarea de partición, lo que supone perder todo el trabajo realizado antes del fallo. Devolver un registro nulo mantiene la partición en ejecución y ofrece una forma clara de identificar y volver a intentar las URL fallidas posteriormente.
Una cosa que vale la pena hacer desde el principio es definir un esquema de salida explícito utilizando StructType en lugar de dejar que Spark lo infiera a partir del RDD. La inferencia del esquema requiere un escaneo completo de los datos, lo cual es costoso, y en ocasiones puede producir resultados inesperados cuando el contenido de la respuesta está inesperadamente vacío.
Patrón 3: Diseñar trabajadores capaces de gestionar ejecuciones prolongadas
Un trabajo que rastrea un millón de páginas se ejecutará durante horas. Durante las ejecuciones prolongadas, verás reinicios de conexión, tiempos de espera de DNS, errores 429 de servidores con límite de velocidad y servidores que ocasionalmente pierden la conexión en medio de una respuesta. Ninguno de estos es un error en tu código; son simplemente lo que ocurre cuando realizas solicitudes HTTP a gran escala.
La función de partición es el lugar adecuado para gestionar todos estos problemas. La lógica de reintentos, los retrasos de retroceso, la configuración de tiempos de espera y el registro de fallos deben estar todos allí. Mantener todo en una única función de partición mantiene limpio el resto del pipeline de Spark y te permite probar el comportamiento de los trabajadores de forma independiente.
import requests
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts) # retroceso exponencial
if not success:
yield {
"url": url,
"status_code": None,
"html": None
}Hay algunas cosas que hay que tener en cuenta aquí. El retraso entre reintentos utiliza un retroceso exponencial en lugar de un tiempo de espera fijo. Un retraso fijo de 2 segundos está bien para fallos ocasionales de la red, pero ralentiza considerablemente a los trabajadores cuando se conectan a un servidor que está constantemente saturado. Además, registra el tipo de excepción antes de generar el registro nulo; la diferencia entre un tiempo de espera de conexión agotado y un error 403 Forbidden te da información muy diferente sobre lo que está pasando en la red.
Supervisión de trabajos en producción
Cuando un trabajo procesa millones de URL durante varias horas, necesitas visibilidad de lo que está sucediendo mientras se ejecuta. Como mínimo, realiza un seguimiento de estas métricas de cada partición:
def scrape_partition(rows):
session = requests.Session()
partition_stats = {
"urls_attempted": 0,
"urls_succeeded": 0,
"urls_failed": 0,
"status_codes": {}
}
for row in rows:
partition_stats["urls_attempted"] += 1
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
partition_stats["urls_succeeded"] += 1
code = response.status_code
partition_stats["status_codes"][code] =
partition_stats["status_codes"].get(code, 0) + 1
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
partition_stats["urls_failed"] += 1
yield {
"url": url,
"status_code": None,
"html": None
}
# Registrar estadísticas cuando se complete la partición
print(f"Estadísticas de la partición: {partition_stats}")Observa la interfaz de usuario de Spark para ver las tasas de finalización de tareas mientras se ejecuta el trabajo. Si las tareas terminan a velocidades muy diferentes, tus particiones están desequilibradas. Si ves códigos 403 o 429 constantes en los registros, debes ajustar la rotación de proxies o añadir retrasos en las solicitudes. El objetivo es detectar los problemas mientras el trabajo aún se está ejecutando, no descubrirlos seis horas más tarde cuando falla.
Escribir resultados desde los trabajadores (el patrón de producción)
Para los trabajos que duran más de una hora, hay un modo de fallo contra el que la lógica de reintentos no puede proteger: que el proceso del controlador se bloquee a mitad de la ejecución. Spark reprograma las tareas individuales si fallan, pero cuando un controlador se bloquea, se pierde todo el trabajo.
La solución consiste en escribir los resultados en un almacenamiento persistente a medida que finaliza cada partición, en lugar de enviarlo todo de vuelta al controlador y mantener los resultados en memoria hasta que el trabajo se complete. Utilice foreachPartition(), que procesa cada partición y le permite escribir la salida directamente desde el trabajador sin que los datos pasen por el controlador:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import requests, time, uuid
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
spark.sparkContext.setCheckpointDir("s3://your-bucket/checkpoints/")
schema = StructType([
StructField("url", StringType(), True),
StructField("status_code", IntegerType(), True),
StructField("html", StringType(), True)
])
def scrape_and_write(rows):
session = requests.Session()
results = []
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
results.append((url, response.status_code, response.text))
success = True
except Exception as e:
intentos += 1
time.sleep(2 ** intentos)
if no éxito:
resultados.append((url, None, None))
# Escribe los resultados de esta partición directamente desde el trabajador
partition_id = str(uuid.uuid4())
spark.createDataFrame(results, schema).write.mode("append").parquet(
f"s3://your-bucket/scrape-results/batch={partition_id}"
)
df.rdd.foreachPartition(scrape_and_write)Cada trabajador escribe su propio archivo de salida de forma independiente. Si el controlador se detiene a mitad del proceso, las particiones completadas ya se encuentran en el almacenamiento, y solo es necesario volver a ejecutar las que están en curso. Para trabajos con transformaciones Spark posteriores sobre los datos extraídos, rdd.checkpoint() es una alternativa más ligera: materializa el RDD en el directorio de puntos de control antes de que se ejecute la transformación, lo que evita que Spark tenga que repetir todo el paso de extracción si falla una etapa posterior.
Patrón 4: Enrutamiento de solicitudes a través de una red Proxy
Ejecutar varios trabajadores en paralelo aumenta el rendimiento, pero el servidor de destino verá una avalancha de solicitudes procedentes del rango de IP de su clúster. La mayoría de los sitios tienen configurada la limitación de velocidad o el bloqueo precisamente para este patrón de tráfico concentrado procedente de un único rango de IP. El enrutamiento de solicitudes a través de una red de Proxies residenciales distribuye el tráfico entre varias direcciones IP, lo que ayuda a mantener los trabajadores en funcionamiento sin activar bloqueos.
El Proxy se configura una vez por sesión dentro de la función de partición, y todas las solicitudes que realiza la sesión se enrutan a través de la red automáticamente:
import requests
BRIGHTDATA_PROXY = (
"http://brd-customer-<CUSTOMER_ID>-zona-<ZONE_NAME>:"
"<ZONE_PASSWORD>@brd.superproxy.io:33335"
)
def scrape_partition(rows):
session = requests.Session()
session.proxies = {
"http": BRIGHTDATA_Proxy,
"https": BRIGHTDATA_Proxy
}
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception as e:
yield {
"url": url,
"status_code": None,
"html": None
}Dependiendo de la configuración de zona de Bright Data, las solicitudes pueden generar errores de verificación SSL porque el tráfico pasa a través de su capa de certificados intermedios. Una solución rápida es pasar verify=False y seguir adelante, pero este enfoque deshabilita por completo la validación de certificados, lo que significa que tus trabajadores ya no pueden detectar una conexión comprometida entre el Proxy y el destino.
La solución correcta es descargar el certificado CA de Bright Data y pasarlo mediante verify='/path/to/brightdata-ca.crt', lo que mantiene intacta la validación completa. También cabe destacar que la URL del Proxy del ejemplo debe obtenerse de una variable de entorno o de un gestor de secretos en producción. En un entorno distribuido, esas credenciales se serializan y se envían a cada nodo de trabajo, por lo que una filtración expone más información de la que lo haría en una sola máquina.
Para los destinos que sirven contenido renderizado en JavaScript, el enrutamiento a través de un Proxy estándar no será suficiente. El Navegador de scraping de Bright Data gestiona la ejecución de JavaScript, la Resolución de CAPTCHA y la huella digital del navegador, y se integra con Playwright y Puppeteer. La estructura de la función de partición sigue siendo la misma; simplemente se cambia la sesión de solicitud por una instancia del navegador Playwright apuntando al punto final del Navegador de scraping.
Solución de problemas comunes
Hay algunos problemas que surgen constantemente en producción. Si las tareas de partición agotan el tiempo de espera repetidamente, comprueba primero el tamaño de la partición. Las particiones con más de 10 000 URL superarán el tiempo de espera predeterminado de Spark cuando las solicitudes sean lentas. Repartición en lotes más pequeños o aumenta spark.task.maxFailures y spark.network.timeout.
Si se producen errores 429 a pesar de utilizar Proxy, significa que varios trabajadores están accediendo al mismo dominio simultáneamente. Añade un retraso aleatorio entre las solicitudes:
import random
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
time.sleep(random.uniform(1, 3))
# ... resto de la lógica de scrapingLos errores de memoria en los ejecutores suelen indicar que se está acumulando el HTML completo antes de escribirlo. Escribe los resultados con mayor frecuencia, o realiza el parseo y descarta el HTML dentro de la función de partición si solo necesitas los campos extraídos.
Las particiones que finalizan a velocidades muy diferentes indican una distribución desequilibrada. Vuelve a particionar con un recuento mayor para distribuir los dominios lentos entre los trabajadores.
Conclusión
Estos patrones te proporcionan una base que se mantiene a gran escala: distribuye la lista de URL, ejecuta las solicitudes a nivel de partición, crea trabajadores que resistan ejecuciones prolongadas y enruta el tráfico a través de una red Proxy que permanezca desbloqueada a medida que aumenta el volumen.
Los trabajos de producción necesitarán esquemas explícitos, puntos de control y un manejo adecuado de los secretos, pero las decisiones estructurales son las mismas independientemente del tamaño. En cuanto a la red y la infraestructura, Bright Data cubre la mayor parte de lo que, de otro modo, tendrías que construir y mantener tú mismo.






