

En este artículo, aprenderá todo sobre RAG, incluyendo su papel en la mejora de las respuestas LLM y sus componentes.
¿Qué es RAG?
RAG es una técnica de aprendizaje automático (ML) que lleva los LLM tradicionales un paso más allá al vincularlos con sistemas de búsqueda (también conocidos como recuperación). En lugar de basarse únicamente en sus datos de entrenamiento fijos, los modelos impulsados por RAG pueden aprovechar fuentes externas, como bases de datos, documentos o incluso la web, para encontrar información relevante y mejorar la calidad de sus respuestas. Esta combinación de recuperación de información en el momento y generación de lenguaje hace que las respuestas sean más precisas y actualizadas.
Recuperación + Generación
RAG funciona combinando tres partes: un sistema de búsqueda o recuperación, el propio modelo de lenguaje y un proceso que combina ambos. Cuando se le formula una pregunta, el sistema RAG utiliza primero el componente de recuperación para encontrar datos relevantes fuera del conjunto de datos de entrenamiento del modelo de lenguaje. A continuación, se modifica la solicitud original para ampliarla con estos datos. La solicitud actualizada se pasa al componente de generación (el LLM), que utiliza tanto sus propios patrones aprendidos como contenido nuevo para ofrecer una respuesta. De este modo, el resultado no es solo producto del entrenamiento preexistente, sino que se basa en información real y verificada extraída directamente de las fuentes.
RAG combina inteligentemente el poder de la recuperación y la generación, ofreciendo una solución inteligente a las deficiencias de los modelos de lenguaje tradicionales. Proporciona respuestas más fiables y precisas y puede adaptarse a diferentes temas, lo que lo hace ideal para aplicaciones en las que la información debe ser actual o especializada.
Por qué los LLM necesitan ampliación
Aunque los LLM son impresionantes a la hora de generar respuestas similares a las humanas, no están exentos de defectos.
Riesgo de alucinaciones
Uno de los mayores retos de los LLM es el riesgo de alucinaciones, es decir, que el modelo genere información convincente pero incorrecta. Esto ocurre porque los LLM se entrenan con grandes Conjuntos de datos estáticos y carecen de acceso en tiempo real a actualizaciones o hechos ajenos a su ventana de entrenamiento.
Además, si se analiza detenidamente, los LLM no son máquinas de resolución de problemas, sino modelos de completado de texto. Su objetivo final es generar una respuesta que se parezca lo más posible a la respuesta correcta a la pregunta planteada; la respuesta no tiene por qué ser correcta. Dado que no utilizan algoritmos deterministas para llegar a una respuesta,es inevitable queen algún momentoproduzcan alucinaciones.
Verificación de la información
Además, los LLM no pueden verificar la información nueva ni comparar sus respuestas con fuentes en tiempo real, lo que hace que sea fácil pasar por alto o tergiversar los hechos.
Corte de conocimiento
Otra limitación es el corte de conocimiento. Dado que los LLM se entrenan con datos que solo llegan hasta un cierto punto, carecen inherentemente de conocimiento sobre los acontecimientos o descubrimientos que se producen después del corte.
Fuentes fiables
Los LLM también tienen dificultades para citar fuentes fiables, lo que puede hacer que los usuarios cuestionen la exactitud de sus respuestas. Sin acceso a fuentes actualizadas o a una forma de validar la información, estos modelos pueden tener problemas de fiabilidad.
RAG: la solución a las limitaciones de los LLM
Como se ha mencionado anteriormente, RAG está diseñado para abordar las limitaciones de los LLM basando sus respuestas en datos reales y actualizados.
Información actualizada de fuentes relevantes
Cuando un LLM recibe una consulta, en lugar de basarse únicamente en sus datos de entrenamiento estáticos, RAG le permite obtener información actualizada de fuentes externas contextualmente relevantes. Esta configuración reduce eficazmente el riesgo de alucinaciones al basar las respuestas en documentos y datos reales. Dado que consulta activamente fuentes externas, RAG puede responder a preguntas relacionadas con acontecimientos recientes, nuevas tecnologías o cualquier información que un LLM estándar pasaría por alto debido a su límite de conocimientos. Por ejemplo, en un escenario de atención al cliente, RAG puede recuperar las últimas actualizaciones de políticas de una base de conocimientos, lo que garantiza que las respuestas se ajusten a la documentación actual de la empresa.
Mayor transparencia
Además de la precisión, RAG mejora la transparencia con las fuentes de sus respuestas. Al extraer datos de documentos específicos y relevantes, proporciona un rastro más claro del razonamiento, lo que permite a los usuarios ver de dónde proviene la información. Esta verificabilidad no solo mejora la confianza de los usuarios, sino que también hace que los modelos equipados con RAG sean más útiles en campos como los servicios jurídicos y financieros, donde los usuarios requieren respuestas claras y bien fundamentadas.
Casos de uso clave de RAG
RAG destaca en aplicaciones en las que es fundamental disponer de información precisa y actualizada, especialmente en campos que cambian rápidamente. Estos son algunos de los casos de uso más populares de RAG.
Automatización de la atención al cliente
RAG transforma la atención al cliente al aprovechar la base de conocimientos y los artículos de ayuda de una empresa. Ofrece respuestas instantáneas a las consultas de los clientes, extrayendo la información de los documentos más actualizados, la información de los productos y los consejos para la resolución de problemas. Esto significa que los clientes obtienen respuestas precisas y personalizadas según sus necesidades específicas, sin abrumar a los agentes de atención al cliente con preguntas rutinarias.
Servicios jurídicos y financieros
Estos sectores requieren información que no solo sea precisa, sino también trazable a fuentes fiables. Un profesional del ámbito jurídico, por ejemplo, puede utilizar RAG para recuperar jurisprudencia o normativas relevantes a la hora de formarse una opinión. Los analistas financieros pueden utilizar RAG para obtener informes o datos actuales del mercado, proporcionando a los clientes información oportuna y respaldada por datos concretos.
Investigación y creación de contenidos
Los escritores, periodistas e investigadores pueden utilizar RAG para obtener referencias precisas de fuentes fiables, lo que simplifica y agiliza el proceso de verificación de datos y recopilación de información. Ya sea para redactar un artículo o recopilar datos para un estudio, RAG facilita el acceso rápido a material relevante y creíble, lo que permite a los creadores centrarse en producir contenido de alta calidad.
Agentes conversacionales y chatbots
Al integrar RAG, los agentes conversacionales y los chatbots pueden ofrecer respuestas más precisas y contextualmente conscientes, mejorando la experiencia del usuario. Por ejemplo, un chatbot de atención médica podría recuperar información sobre estudios médicos recientes, o un bot de soporte técnico podría extraer los detalles de la última actualización del firmware del dispositivo. La capacidad de RAG para combinar la recuperación de datos en tiempo real con la generación de lenguaje mejora tanto la calidad como la fiabilidad de las respuestas.
Más información sobre cómo crear un chatbot RAG utilizando modelos GPT.
Retos y limitaciones de RAG
Aunque RAG añade un valor significativo a los modelos de lenguaje, también plantea una serie de retos.
Calidad y precisión
Una cuestión importante es la calidad y la precisión de la información recuperada para mejorar la solicitud. Dado que RAG depende de fuentes externas, la respuesta del modelo es tan buena como los datos que obtiene. La respuesta generada podría seguir siendo insuficiente si el sistema de recuperación devuelve documentos irrelevantes o inexactos. Es importante garantizar una recuperación de alta calidad, lo que a menudo requiere ajustes y actualizaciones periódicas para mantener la relevancia y la precisión de los datos.
Coste y complejidad computacional
Otros retos son el coste computacional y la complejidad que implica el funcionamiento de un sistema RAG. A diferencia de los LLM independientes, el RAG necesita tanto un potente sistema de recuperación como un modelo capaz de integrar fácilmente la información recuperada, lo que puede requerir muchos recursos. Este aumento de la carga computacional puede ralentizar los tiempos de respuesta, especialmente si es necesario buscar o procesar grandes cantidades de datos en tiempo real. Las organizaciones que implementan el RAG a menudo necesitan equilibrar la precisión con el rendimiento, buscando formas de configurar la recuperación sin comprometer la velocidad.
El éxito de RAG depende en gran medida del acceso a fuentes de datos estructuradas y fiables. El sistema de recuperación puede tener dificultades para obtener información útil sin bases de datos externas fiables y bien organizadas. Además, no todas las fuentes de datos son fácilmente accesibles o asequibles, lo que puede suponer un obstáculo para las organizaciones más pequeñas.
A pesar de estos retos, con una configuración cuidadosa y fuentes de datos fiables, el RAG puede seguir ofreciendo beneficios transformadores para una amplia gama de aplicaciones.
Implementación de RAG en la práctica
La configuración de un sistema RAG requiere conectar un modelo de lenguaje con un mecanismo de recuperación eficaz que permita el acceso a datos externos.
El proceso comienza con el establecimiento de una arquitectura de alto nivel que combina un sistema de búsqueda con el modelo de lenguaje. Cuando un usuario envía una consulta, el sistema de recuperación busca información relevante en fuentes externas y, a continuación, envía esta información al LLM junto con la indicación, que genera una respuesta basada tanto en su propio conocimiento como en los datos recuperados. Este enfoque garantiza que las respuestas estén bien fundamentadas y se basen en información reciente y fiable.
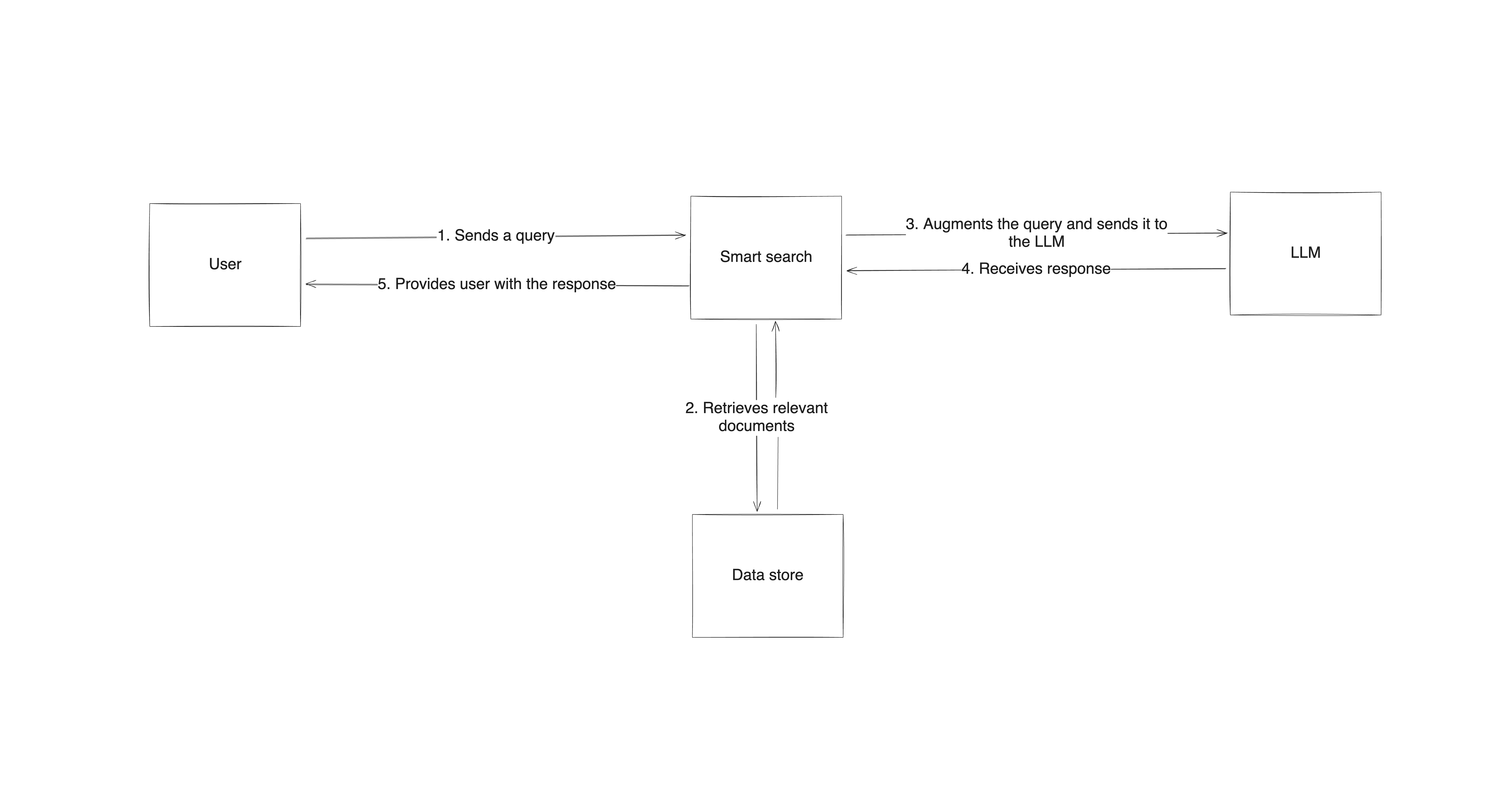
La implementación de RAG requiere herramientas y marcos específicos
En términos prácticos, la implementación de RAG requiere herramientas y marcos específicos que puedan gestionar la recuperación de información, su procesamiento y la generación de la respuesta. Bibliotecas comoLangChainyHaystackson opciones populares, ya que proporcionan componentes listos para usar que integran la recuperación en el proceso de generación de respuestas.
Por ejemplo, LangChain ofrece herramientas paraestructurar las indicaciones,recuperar datos ycanalizar los resultadosdirectamente a un LLM, mientras que Haystack se especializa enla recuperación de alto rendimiento, lo que permite extraer información de bases de datos, documentos o incluso de la web. Estas herramientas se pueden personalizar para que funcionen con diferentes fuentes de datos, lo que las hace muy adaptables a diversas aplicaciones RAG.
RAG es un marco construido sobre un LLM existente
Si lo miras desde lejos, a diferencia de técnicas comoel ajuste fino, RAG no afecta a la estructura ni a los componentes de tu LLM principal. Se trata simplemente de un marco construido sobre tu LLM existente que ayuda a mejorar la calidad de las indicaciones que envías al modelo. Hay quien sostieneque RAG no es más que ingeniería de indicaciones glorificada, y se entiende su punto de vista si se compara la indicación original que se introduce en un sistema RAG con la indicación aumentada que genera antes de generar la respuesta final. He aquí un ejemplo rápido (y extremadamente simplificado) para ayudarle a comprenderlo mejor:
- Solicitud sin procesar
¿Cuáles son los últimos efectos del cambio climático en los arrecifes de coral?
- Respuesta (de un LLM sin RAG)
Los arrecifes de coral se ven afectados por el aumento de las temperaturas y la acidificación de los océanos, lo que provoca el blanqueamiento de los corales y altera los ecosistemas marinos.
- Solicitud aumentada (con RAG)
Utilizando los datos recuperados: «Un informe de 2024 de la NOAA destaca que el calentamiento de los océanos ha provocado episodios de blanqueamiento masivo de corales en el Caribe y el Pacífico, lo que ha dado lugar a una reducción del 40 % de la cobertura de corales en las regiones afectadas. La acidificación también está debilitando los esqueletos de los corales, haciéndolos más vulnerables a los daños causados por las tormentas». Responda a lo siguiente: ¿Cuáles son los últimos impactos del cambio climático en los arrecifes de coral?
- Respuesta (de un LLM con RAG)
Los últimos informes de la NOAA indican que el calentamiento de los océanos está provocando episodios de blanqueamiento masivo, especialmente en el Caribe y el Pacífico, con una disminución de la cobertura de coral del 40 % en algunas zonas. La acidificación también está dañando los esqueletos de los corales, lo que aumenta su vulnerabilidad.
Aunque esto parece respaldar el argumento, es importante destacar que el objetivo de la configuración del RAG es proporcionar al LLM los datos correctos en el contexto de la consulta original. Dependiendo del almacén de datos, el componente de búsqueda puede ser algo tan simple como una consulta SQL o algo tan complejo como una búsqueda en Google y un rastreo web. A continuación, una vez que se dispone de los datos, es necesario priorizarlos y resumirlos de forma correcta y eficiente antes de añadirlos al prompt. Estos dos pasos hacen que el RAG sea mucho más complejo que cualquier técnica de ingeniería de prompts.
La implementación de RAG requiere una gran cantidad de datos de alta calidad
En lo que respecta al almacén de datos en sí, la mayoría de los sistemas RAG necesitan uno, y es útil que la gran cantidad de datos sea precisa, actualizada y específica del dominio. Crear y mantener estos Conjuntos de datos lleva mucho tiempo y es difícil. Los proveedores de datos públicos, comoBright Data, pueden facilitar la tarea suministrando vastos Conjuntos de datos que garantizan que el sistema de recuperación funcione con información actualizada y de alta calidad.
Estas fuentes pueden incluir desde datos web hasta Conjuntos de datos estructurados, lo que mejora enormemente la relevancia del modelo. Al integrarse con los Conjuntos de datos de Bright Data, los modelos RAG tienen acceso a la información más reciente, lo que no solo mejora la precisión de las respuestas, sino que también ayuda en campos en los que los datos en tiempo real son esenciales, como los sistemas meteorológicos o la logística y la gestión de la cadena de suministro.
Cómo puede ayudar Bright Data con la recuperación de datos públicos
Como proveedor de Conjuntos de datos públicos de alta calidad de toda la web, Bright Data puede ser un recurso valioso para los sistemas RAG. Dada la dependencia de RAG de información actualizada y de alta calidad, los Conjuntos de datos de Bright Data permiten extraer contenido relevante para diversas aplicaciones, desde acontecimientos de actualidad hasta investigaciones especializadas.
Datos estructurados en diversos sectores
Los conjuntos de datos de Bright Data incluyen datos estructurados de diversos sectores, como el comercio electrónico, los mercados financieros y las noticias, que pueden integrarse en los sistemas RAG para mejorar la precisión y la relevancia del modelo. Esto puede ayudar a garantizar que los LLM puedan responder con precisión a preguntas que requieren información reciente o específica del sector, lo cual es fundamental para áreas como la atención al cliente y el análisis de la competencia.
Acceda y filtre datos públicos a gran escala
Si desea recopilar datos de la web por su cuenta, laAPI deBright Data ysu amplia infraestructura de Proxypueden ayudarle a acceder y filtrar datos públicos a gran escala, al tiempo que se mantiene el cumplimiento de las políticas de uso de datos. Esto puede resultar muy útil para las aplicaciones RAG que requieren la recuperación dinámica de información. Por ejemplo, una configuración RAG de servicios financieros podría extraer continuamente datos actualizados del mercado de valores o noticias sobre normativa, mejorando la capacidad del modelo para proporcionar información en tiempo real.
El uso de Bright Data como fuente de datos en su sistema RAG le libera de la carga de tener que mantener su almacén de datos, lo que le permite centrarse en perfeccionar la ampliación de las respuestas y la generación de respuestas.
Conclusión
RAG representa un avance significativo en las capacidades de los LLM, ya que les permite superar limitaciones clave como el corte de conocimiento y la alucinación mediante la incorporación de datos en tiempo real de fuentes externas. A través de RAG, los modelos pueden acceder a información actualizada y verificada, lo que mejora tanto la relevancia como la fiabilidad de sus respuestas. Esta técnica transforma los modelos de lenguaje de repositorios de conocimiento estáticos en agentes dinámicos y sensibles al contexto.
Al integrar datos de alta calidad y en tiempo real en las implementaciones de RAG, puede mejorar la precisión, la relevancia y la fiabilidad de sus aplicaciones de IA. Ya sea en la atención al cliente, el análisis financiero, la sanidad o cualquier otro sector, el uso de RAG puede ayudar a mejorar significativamente la experiencia del usuario final.
Bright Data ayuda a desarrollar implementaciones RAG más fácilmente al ofrecer una solución escalable para obtener datos públicos fiables y estructurados. Con su amplia oferta de Conjuntos de datos, Bright Data ayuda a los sistemas RAG a ofrecer respuestas precisas y actualizadas en diversos sectores y aplicaciones.
¡Regístrese ahora y comience su prueba gratuita, que incluye muestras gratuitas de Conjuntos de datos que puede descargar!





