

En este tutorial, aprenderás:
- Cómo configurar Snowflake para recibir datos de la infraestructura de entrega de Bright Data.
- Configurar el conjunto de datos de libros de Goodreads para entregarlos directamente en un stage interno de Snowflake.
- Activar un snapshot y cargarlo en una tabla consultable, luego ejecutar SQL sobre más de 6 millones de registros de libros.
¡Empecemos!
Presentación del flujo de trabajo de ingesta en Snowflake
A alto nivel, el pipeline tiene tres fases, cada una cubierta en su propia sección:
- Configuración de Snowflake: Crea la base de datos, el stage, el rol y el usuario de servicio contra el que Bright Data se autenticará. Esta es la parte con más SQL, pero cada comando se proporciona completo y se ejecuta en orden.
- Configuración de Bright Data: Elige un conjunto de datos del marketplace, conéctalo a tu entorno de Snowflake y activa un snapshot. Bright Data envía los archivos directamente a tu stage interno.
- Carga y consulta: Un único comando
COPY INTOmueve los archivos del stage a una tabla estructurada. El resto es SQL estándar.
El resultado es una tabla de Snowflake completamente consultable, poblada con datos web estructurados y actualizada según el calendario que requiera tu caso de uso. Sin exportaciones CSV ni código ETL personalizado.
¡Aprende más sobre cada fase y cómo implementarlas!
1. Configuración de Snowflake
Bright Data entrega archivos autenticándose directamente en tu cuenta de Snowflake. Esto requiere un stage interno dedicado (una zona de aterrizaje para archivos entrantes), un rol de servicio con acceso de escritura a ese stage y un usuario de servicio asignado a ese rol.
Usar objetos dedicados para este propósito mantiene la ingesta separada de tus cargas de trabajo analíticas y facilita auditar, revocar o rotar credenciales más adelante.
2. Configuración del conjunto de datos de Bright Data y entrega del snapshot
El Marketplace de Conjuntos de Datos de Bright Data contiene conjuntos de datos preconstruidos y validados que cubren Amazon, LinkedIn, Crunchbase, Glassdoor, listados de hoteles, bienes raíces, ofertas de empleo y más. Cada conjunto de datos incluye una referencia completa de campos para que puedas diseñar tu esquema de Snowflake antes de que llegue el primer byte.
La entrega directa a Snowflake está disponible para el producto Datasets. Si usas las API de Web Scraper, entrega los archivos a un bucket de S3 y cárgalos desde un stage externo.
Una vez que configures Snowflake como destino de entrega, Bright Data gestiona la transferencia. Se autentica con el usuario de servicio que creaste, almacena los archivos en tu stage interno y registra la entrega en el panel de control. Puedes activar snapshots bajo demanda, según un calendario o mediante la API de Conjuntos de Datos del Marketplace.
3. Carga y consulta
Con los archivos en el stage, un único comando COPY INTO los carga en tu tabla. A partir de ahí, consultas usando SQL estándar sin sintaxis especial ni nuevas herramientas.
Configurar Snowflake para recibir datos de Bright Data
Empecemos a construir el pipeline preparando el lado de Snowflake. Todos los comandos de esta sección se ejecutan en la hoja de trabajo SQL de Snowsight o mediante SnowSQL. Ejecuta esto primero para asegurarte de tener los privilegios necesarios para crear bases de datos, roles y usuarios:
USE ROLE ACCOUNTADMIN;Requisitos previos
Para seguir esta sección, debes tener:
- Una cuenta de Snowflake con privilegios
ACCOUNTADMINoSYSADMIN. - Familiaridad básica con la interfaz de Snowflake (Snowsight).
Paso #1: Crear una base de datos y un esquema
En Snowflake, una base de datos es el contenedor de nivel superior para todos tus objetos de datos. Un esquema reside dentro de una base de datos y agrupa tablas, stages y otros objetos relacionados. Crear una base de datos y un esquema dedicados para Bright Data mantiene sus objetos separados de tus datos existentes y facilita la gestión de permisos.
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;Puedes usar una base de datos existente si lo prefieres. Sustituye su nombre donde aparezca bright_data_db en los comandos siguientes.
Paso #2: Crear un warehouse dedicado
En Snowflake, un warehouse es el clúster de cómputo que ejecuta sentencias SQL, incluido COPY INTO. Está separado del almacenamiento, lo que significa que solo pagas por el cómputo mientras está activo. Un warehouse dedicado para la ingesta de Bright Data mantiene esos costes de cómputo visibles y evita que las cargas de trabajo de ingesta compitan con tus consultas analíticas por recursos.
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60 apaga el warehouse tras 60 segundos de inactividad para que no funcione en vacío entre entregas. AUTO_RESUME = TRUE lo reactiva automáticamente cuando se ejecuta el siguiente COPY INTO. XSmall gestiona cómodamente la mayoría de las entregas de Bright Data. Redimensiona si los volúmenes crecen.
Paso #3: Crear un stage interno con nombre
En Snowflake, un stage es una ubicación con nombre donde residen los archivos antes de cargarse en una tabla. Un stage interno con nombre vive dentro del propio Snowflake. No se requiere bucket de S3 ni almacenamiento en la nube externo.
Este stage es el puente entre Bright Data y tu tabla. En lugar de cargar datos directamente en una tabla fila por fila, Bright Data deposita archivos estructurados (Parquet o JSON) primero en el stage. Snowflake luego lee esos archivos en bloque mediante COPY INTO, lo cual es significativamente más rápido y rentable que las inserciones a nivel de fila. También te proporciona un punto de control: puedes inspeccionar los archivos en el stage, verificar que tienen el aspecto correcto y elegir cuándo activar la carga.
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';Paso #4: Crear un rol y otorgarle los permisos correctos
En Snowflake, un rol es una colección de privilegios que se pueden asignar a usuarios. En lugar de otorgar permisos directamente a un usuario, se los otorgas a un rol y asignas ese rol al usuario. Esto facilita revocar o modificar el acceso más adelante sin tocar la propia cuenta de usuario.
Este rol otorga a Bright Data exactamente el acceso que necesita y nada más.
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;Esto es lo que hace cada concesión y por qué es necesaria:
- USAGE en base de datos y esquema: Permite al rol ver y navegar hasta los objetos dentro de ellos. Sin esto, Snowflake devolverá un error de “objeto no existe” aunque el rol tenga privilegios directamente sobre el stage.
- USAGE en warehouse: Permite al rol ejecutar sentencias SQL contra el warehouse. Esto es lo que permite que
COPY INTOse ejecute realmente. - OPERATE en warehouse: Permite al rol reanudar el warehouse si ha sido suspendido. Sin esto, un warehouse suspendido automáticamente no se reactivará cuando Bright Data active una carga.
- READ en stage: Necesario para que
COPY INTOlea los archivos del stage y los cargue en la tabla. - WRITE en stage: Necesario para que Bright Data deposite archivos en el stage en primer lugar.
Paso #5: Crear el usuario de servicio de Bright Data
Un usuario de servicio es una cuenta de Snowflake creada para un sistema o aplicación en lugar de para una persona. Usar un usuario de servicio dedicado significa que el acceso de Bright Data está aislado de cualquier cuenta de usuario humano, y puedes rotar o revocar sus credenciales sin afectar a nadie más.
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSE evita que Snowflake solicite un restablecimiento de contraseña en el primer inicio de sesión, lo que rompería una conexión automatizada. DEFAULT_ROLE, DEFAULT_WAREHOUSE y DEFAULT_NAMESPACE garantizan que el usuario de servicio siempre se conecte con el contexto correcto independientemente de cómo se inicie la sesión. La última línea asigna el rol bright_data_loader a este usuario, otorgándole exactamente los privilegios definidos en el Paso #4.
Almacena el nombre de usuario y la contraseña de forma segura. Los pegarás en el panel de control de Bright Data en la siguiente sección.
Paso #6: Añadir las IPs de Bright Data a la lista blanca (si usas una política de red)
Si tu cuenta de Snowflake aplica una política de red, los servidores de entrega de Bright Data deben añadirse a la lista permitida. Las IPs siguientes eran las vigentes en el momento de redactar este texto. Verifica los rangos más recientes con el soporte de Bright Data o su documentación antes de aplicarlos, ya que las IPs estáticas pueden cambiar:
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);Si tu cuenta no tiene ninguna política de red activa, omite este paso.
Paso #7: Crear la tabla de destino
Este tutorial usa datos de libros de Goodreads como ejemplo. El esquema siguiente se mapea directamente a los nombres de campo que entrega el conjunto de datos de libros de Goodreads de Bright Data en JSON:
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANT es el tipo semiestructurado de Snowflake. Almacena arrays y objetos anidados tal cual y te permite consultarlos usando notación de punto y sintaxis de corchetes (author[0]:name, community_reviews['5_stars']:reviews_num). Esto evita aplanar campos anidados complejos en el momento de la carga. Puedes hacerlo más tarde con una vista o un LATERAL FLATTEN una vez que sepas qué subcampos necesitas.
Algunas decisiones sobre campos que vale la pena entender:
authorcomo VARIANT: Cada libro puede tener varios autores. El campo llega como un array de objetos. Almacenarlo como VARIANT preserva todos los datos de los autores sin requerir una tabla de unión separada.genrescomo VARIANT: El género también es un array. Un libro puede pertenecer a varios géneros. Aplánalo conLATERAL FLATTEN(INPUT => genres)cuando necesites consultar por género.num_reviewscomo VARCHAR: El diccionario de datos de Bright Data marca este campo como Texto en lugar de Número, lo que significa que puede llegar formateado (por ejemplo,"1,234"en lugar de1234). Conviértelo en el momento de la consulta conTO_NUMBER(REPLACE(num_reviews, ',', ''))si necesitas agregarlo.community_reviewscomo VARIANT: Contiene un desglose de valoraciones por nivel de estrellas, cada una con un recuento y un porcentaje. Almacénalo como VARIANT y consulta los niveles de estrellas específicos según sea necesario.
Nota: Si eliges un conjunto de datos diferente del marketplace (empresas de LinkedIn, ofertas de empleo, productos de Amazon, etc.), ajusta el esquema para que coincida con su lista de campos. Bright Data proporciona una referencia completa de campos para cada conjunto de datos en su página del panel de control.
¡Excelente! Tu entorno de Snowflake ya está listo para recibir datos de Bright Data.
Configurar Bright Data para entregar a Snowflake
Con el lado de Snowflake listo, configuremos Bright Data para enviar datos a él.
Requisitos previos
Para seguir esta sección, debes tener:
- Una cuenta de Bright Data con una suscripción activa o una prueba.
- Los detalles de conexión de Snowflake de la sección anterior: identificador de cuenta, nombre de usuario, contraseña, base de datos, esquema, stage y nombres de warehouse.
Paso #1: Elegir un conjunto de datos
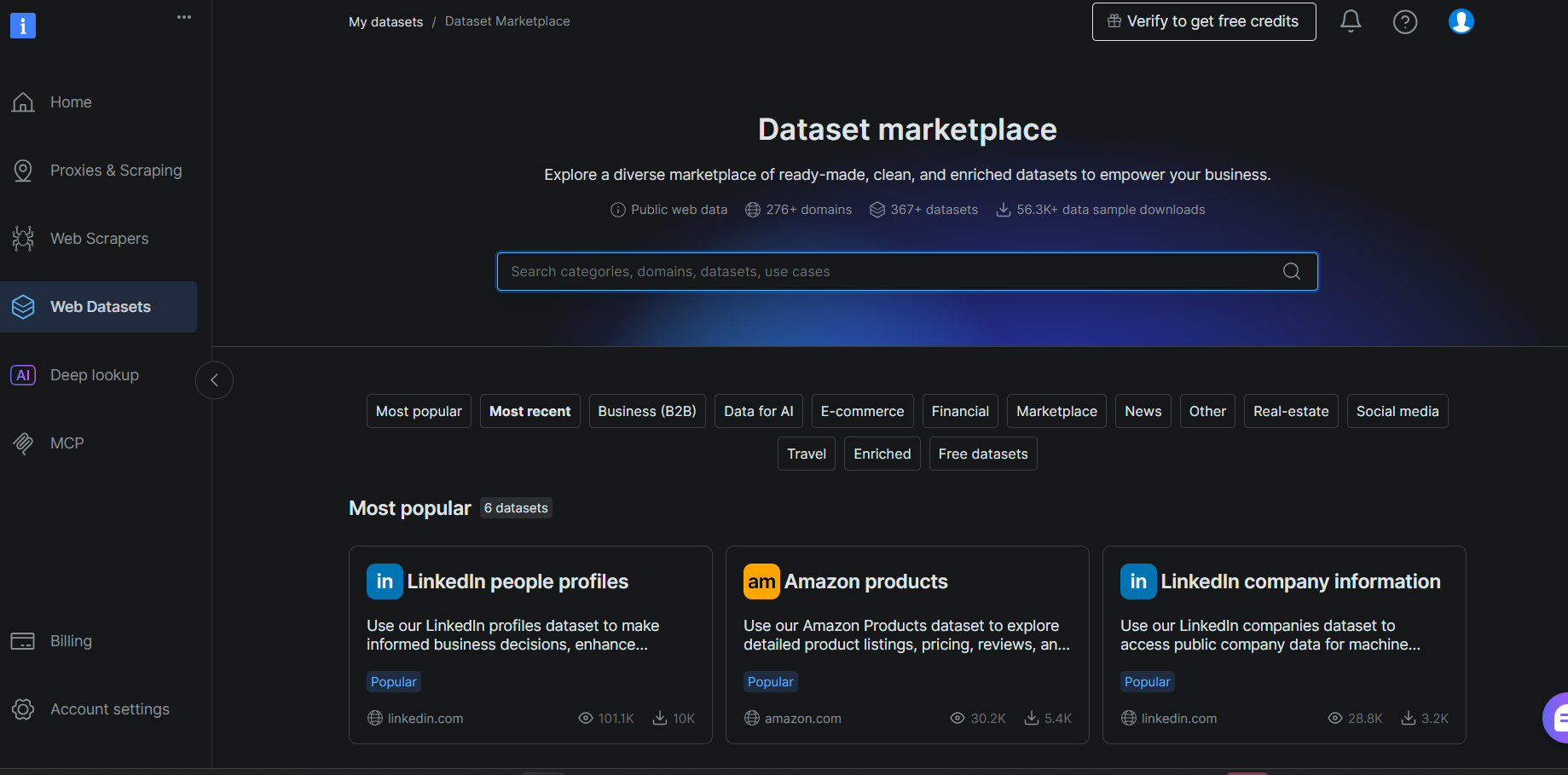
Inicia sesión en tu cuenta de Bright Data y navega a Web Datasets > Dataset Marketplace. Busca Goodreads y selecciona el conjunto de datos Goodreads Books de los resultados.
En la página del conjunto de datos, revisa la lista de campos en el panel izquierdo. Observa cómo cada campo se mapea directamente a una columna de la tabla que creaste en el Paso #7. Esto confirma que tu esquema es correcto antes de que llegue una sola fila.
Paso #2: Configurar Snowflake como destino de entrega
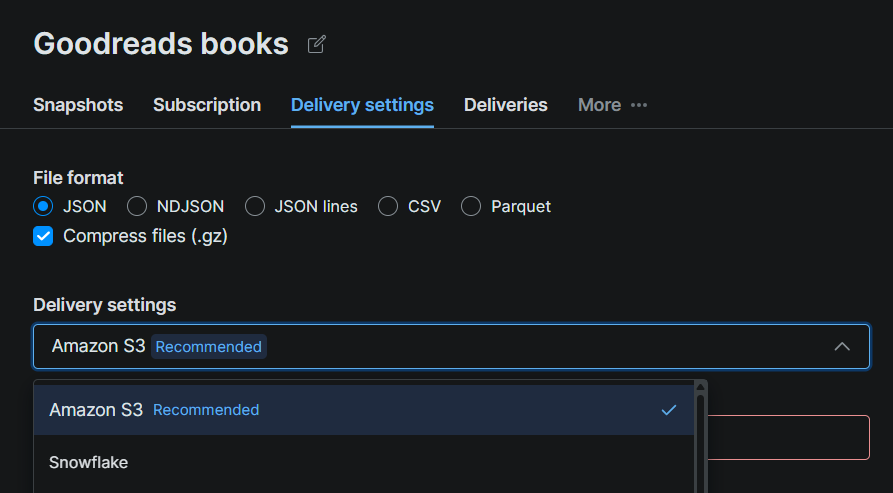
Haz clic en la pestaña Delivery Settings de la página del conjunto de datos y selecciona Snowflake como destino. Rellena el formulario de conexión con los detalles de tu configuración de Snowflake:
| Campo | Valor |
|---|---|
| Identificador de cuenta | La URL de tu cuenta de Snowflake (p. ej. xy12345.us-east-1) |
| Base de datos | bright_data_db |
| Esquema | web_data |
| Stage | bright_data_stage |
| Warehouse | bright_data_wh |
| Rol | bright_data_loader |
| Usuario | brightdata_svc |
| Contraseña | La contraseña que estableciste en el Paso #5 |
Los tres campos debajo del formulario de conexión son opcionales y pueden dejarse con sus valores predeterminados para este tutorial:
- Nombre de archivo del conjunto de datos: Un prefijo personalizado para los archivos que Bright Data almacena en el stage. Déjalo en blanco para usar el nombre predeterminado.
- Tamaño de lote (número de registros): Cuántos registros empaqueta Bright Data en cada archivo del stage. El valor predeterminado es adecuado para la mayoría de las cargas de trabajo.
- Agrupar lotes en un archivo (.tar): Combina todos los lotes en un único archivo antes del staging. Déjalo sin marcar a menos que tu pipeline requiera específicamente un único archivo por entrega.
Haz clic en Test Snowflake. Una confirmación en verde significa que Bright Data puede autenticarse y escribir en tu stage. Una vez que la prueba sea exitosa, haz clic en Save.
Nota: Si la prueba falla, verifica tres cosas en orden: (1) el formato del identificador de cuenta (Snowflake espera orgname-accountname o el formato heredado accountid.region.cloud); (2) si el usuario de servicio tiene todas las concesiones del Paso #4, incluida la asignación del rol; (3) si las IPs de Bright Data están en la lista blanca en caso de que tu cuenta tenga una política de red activa.
Paso #3: Solicitar un snapshot
En la página del conjunto de datos, haz clic en la pestaña Deliveries. Luego haz clic en Add delivery + en la esquina superior derecha. Esto abre un panel de configuración de entrega donde seleccionas tu destino (Snowflake), eliges un snapshot o rango de fechas para entregar y confirmas.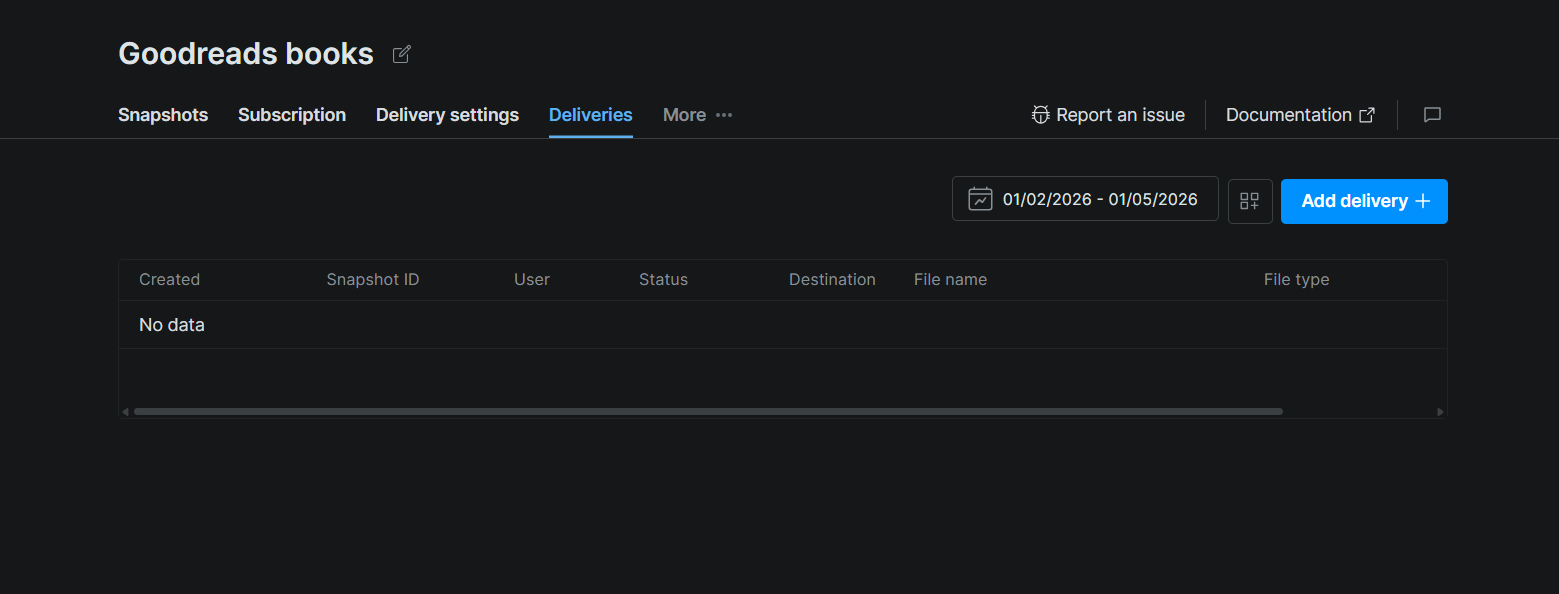
Una vez enviado, la entrega aparece en la tabla con columnas para ID de snapshot, estado, destino, nombre de archivo y tipo de archivo. El estado pasará de pendiente a completado cuando Bright Data haya terminado de enviar los archivos a tu stage.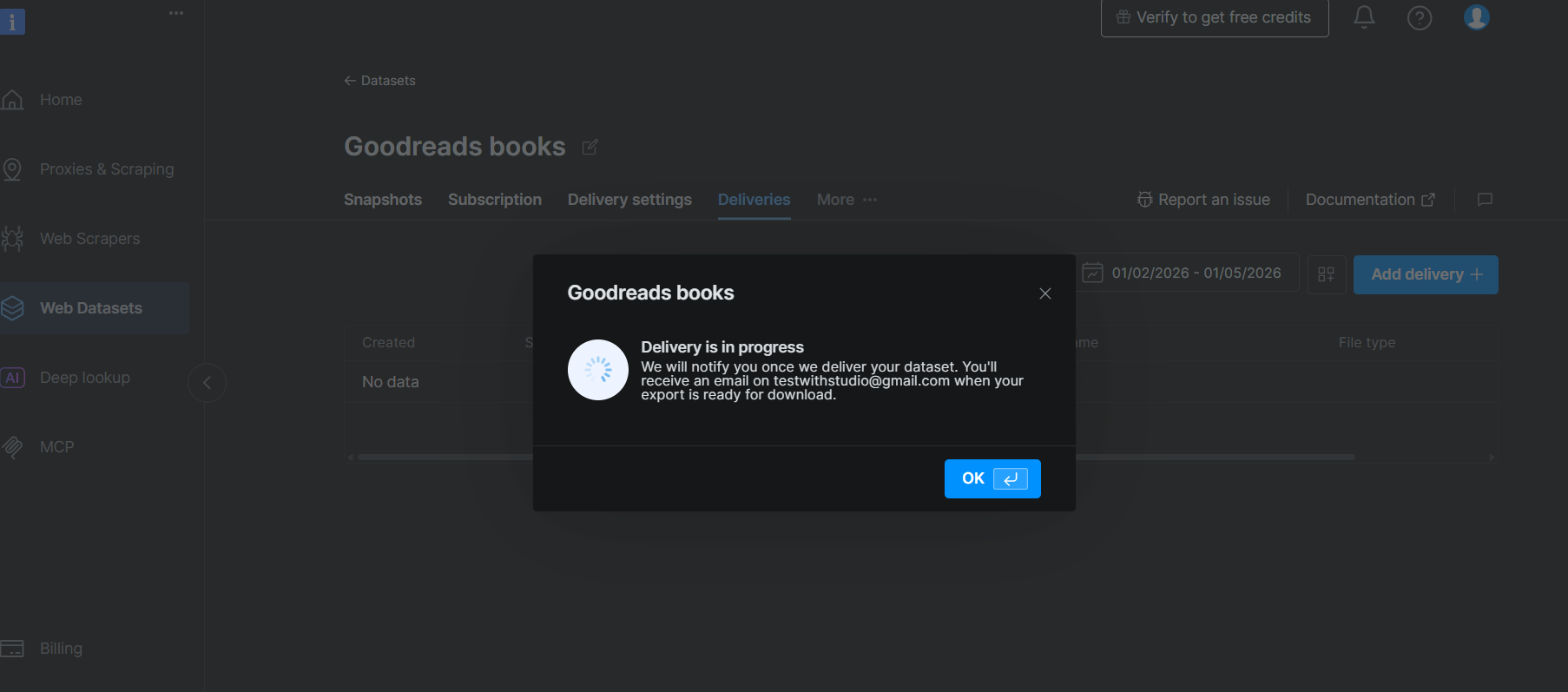
Para activar entregas de forma programática, la API de Conjuntos de Datos del Marketplace usa un flujo de dos pasos: primero llama a la API de filtro para crear un snapshot filtrado, luego llama a Deliver Snapshot para enviarlo a tu stage de Snowflake.
Paso 1: Crear un snapshot filtrado:
curl --request POST
--url "https://api.brightdata.com/datasets/filter"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'La respuesta contiene un snapshot_id. Pásalo a la siguiente llamada.
Paso 2: Entregar el snapshot a tu stage de Snowflake:
curl --request POST
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"destination": "snowflake"
}'Bright Data usará el formato configurado para tu conjunto de datos de forma predeterminada. Si quieres especificarlo explícitamente, añade "format": "parquet" o "format": "ndjson" al cuerpo de la solicitud. Cualquier formato que llegue al stage es el que pasas a FILE_FORMAT en COPY INTO.
Consulta GET /datasets/snapshots/YOUR_SNAPSHOT_ID para verificar el estado de la entrega, o monitoréalo en la pestaña Deliveries del panel de control. Cuando la columna de estado muestre completado, tus archivos están en el stage y listos para cargar. ¡Genial!
Cuando finalice la entrega, también recibirás un correo electrónico con un enlace a la página del snapshot en el panel de control. Allí puedes previsualizar los primeros 30 registros, comprobar el recuento total de registros y descargar un informe resumido de costes. A $2,50 por 1.000 registros, el informe te muestra exactamente cuántos registros llegaron y cuánto costaron. ¡Genial!
Cargar los datos en Snowflake
El trabajo de Bright Data termina cuando los archivos aterrizan en tu stage interno. Cargarlos en la tabla es tu responsabilidad, y requiere un solo comando SQL. Esta separación vale la pena entenderla: significa que tú controlas cuándo se ejecuta la carga, qué manejo de errores se aplica y con qué frecuencia actualizas la tabla.
Requisitos previos
Para seguir esta sección, debes tener:
- Completadas las secciones de configuración de Snowflake y configuración de Bright Data anteriores.
- Confirmado que una entrega de snapshot ha finalizado (por correo electrónico o en la página del snapshot en el panel de control de Bright Data).
Paso #1: Confirmar que los archivos llegaron al stage
Ejecuta esto antes que cualquier otra cosa:
LIST @bright_data_db.web_data.bright_data_stage;Deberías ver uno o más archivos listados con sus tamaños y marcas de tiempo. Si el stage está vacío, el snapshot aún no ha terminado de entregarse. Comprueba su estado en la página del snapshot en el panel de control de Bright Data.
Observa la extensión del archivo en los resultados. El formato que usa Bright Data para la entrega determina el FILE_FORMAT que pasas a COPY INTO en el siguiente paso. Para snapshots activados desde la interfaz, Bright Data normalmente entrega NDJSON a menos que hayas especificado otro formato al configurar la entrega. Para snapshots activados por API mediante el endpoint deliver-snapshot, el formato es el que pasaste en el cuerpo de la solicitud. Si ves archivos .parquet, usa TYPE = 'PARQUET'. Si ves archivos .json o .ndjson, usa TYPE = 'JSON'.
Paso #2: Cargar los archivos en la tabla
Para archivos Parquet:
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';Para archivos JSON o NDJSON:
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME (solo Parquet) mapea los nombres de columnas automáticamente para que el orden no importe. ON_ERROR = CONTINUE omite las filas malformadas en lugar de abortar toda la carga.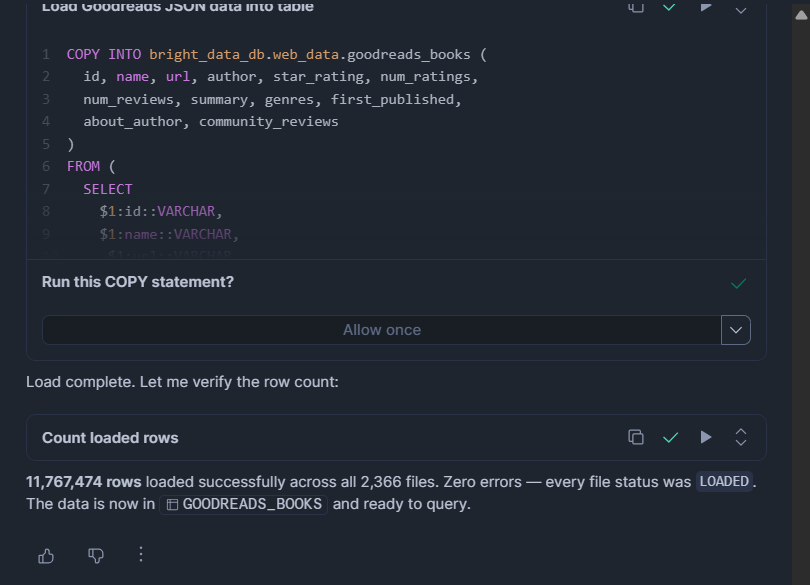
Paso #3: Verificar la carga
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORY muestra las filas cargadas, las filas omitidas, los nombres de archivos procesados y el mensaje de error exacto para cualquier fila que haya fallado. Revísalo después de cada carga, especialmente la primera vez.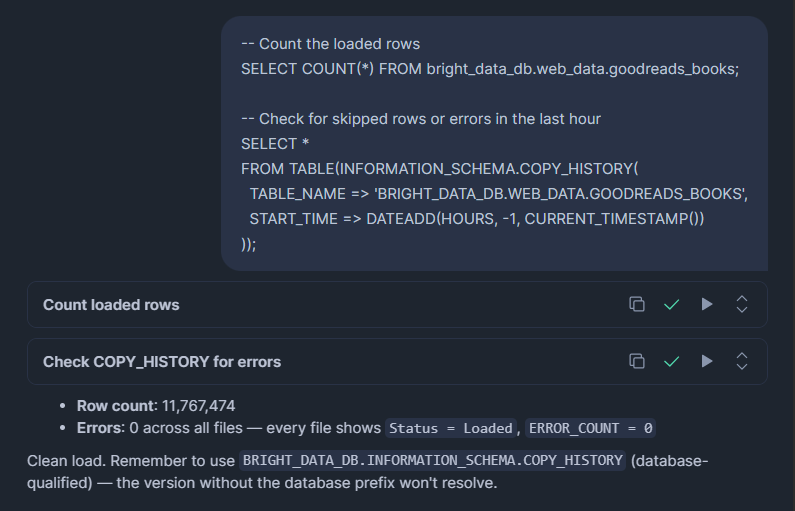
Consultar los datos
Con los datos de libros de Goodreads en Snowflake, el valor está en comprender las tendencias de lectura, el rendimiento de los autores y la popularidad de los géneros a escala entre millones de títulos. Las consultas siguientes reflejan directamente esos casos de uso.
Inspeccionar los datos en bruto
Antes de escribir consultas analíticas, verifica que los datos tienen el aspecto esperado:
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;RESULTADO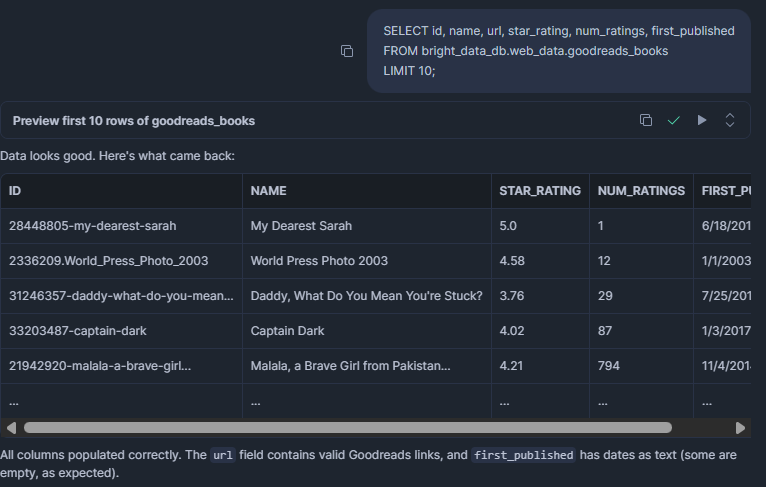
¿Qué libros tienen la mayor validación de lectores?
Una star_rating alta por sí sola no es suficiente. Un libro con 4,8 estrellas de 12 personas te dice muy poco. Esta consulta muestra los libros que tienen tanto una alta valoración como una amplia audiencia, que es la combinación que indica que un libro tiene verdadera permanencia.
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;Resultado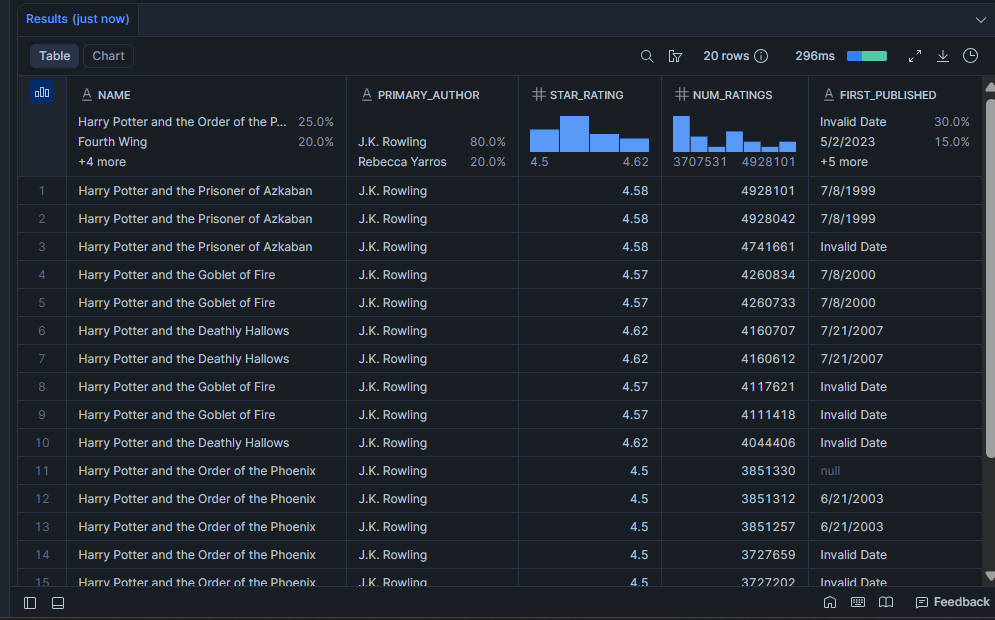
¿Qué géneros tienen más títulos y la valoración media más alta?
Útil para entender dónde se concentra la demanda de los lectores. Un género con muchos títulos pero una valoración media baja puede estar saturado de entradas de baja calidad, lo que representa una oportunidad para editores o motores de recomendación.
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;Resultado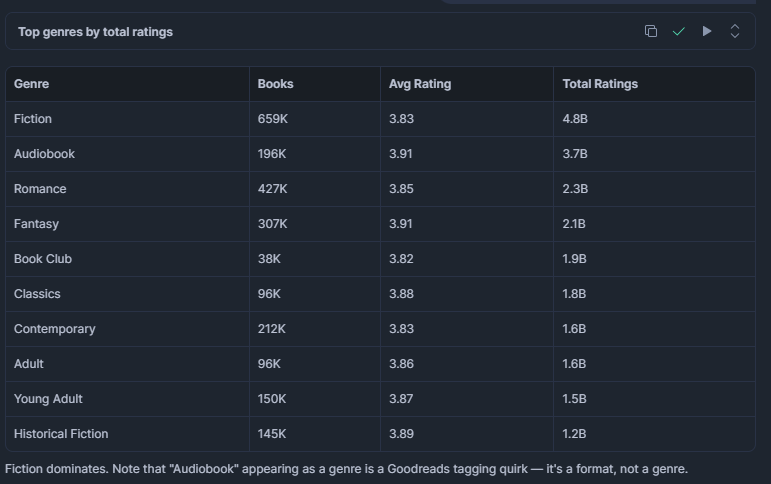
¿Quiénes son los autores con más seguidores en el conjunto de datos?
El número de seguidores de un autor es un indicador del tamaño de su audiencia en la plataforma. Combinarlo con la valoración media del libro muestra si los autores con más seguidores también son los más respetados, o si el número de seguidores y la calidad divergen.
about_author es un objeto plano en cada registro de libro, lo que facilita su consulta sin indexación de arrays. Ten en cuenta que esto refleja al autor tal como se describe en la página de ese libro específico, que puede diferir ligeramente de author (el array de autores acreditados).
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;Resultado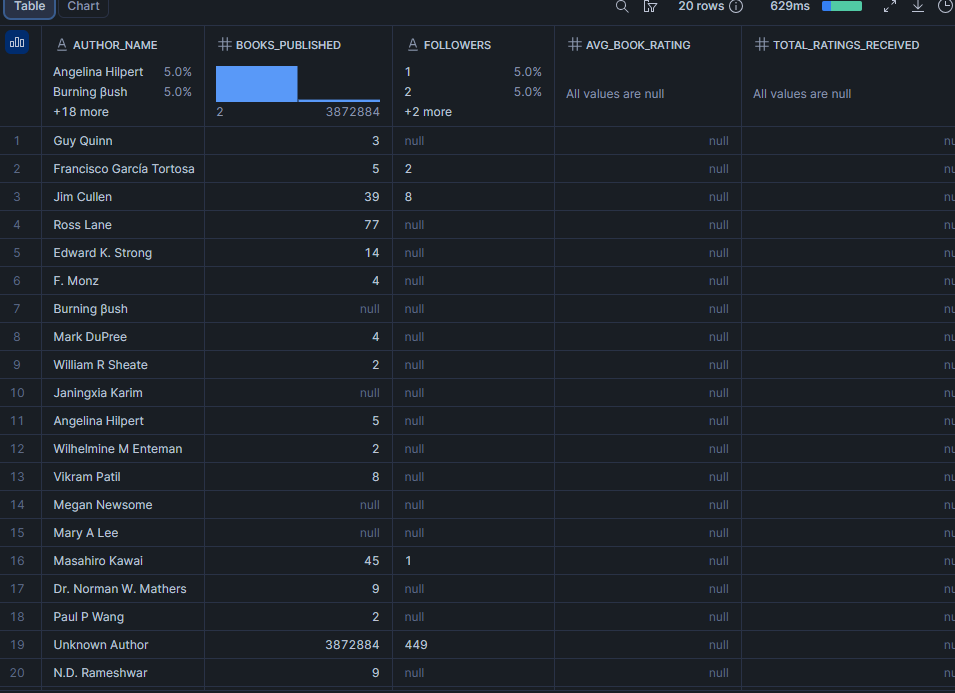
Nota: followers se ordena como texto porque el campo de origen es VARCHAR (puede contener valores formateados como "12.3k"). Si tu conjunto de datos entrega un entero limpio, conviértelo con TO_NUMBER(followers) y ordena numéricamente.
¿Qué tan polarizante es un libro? Extraer el desglose de estrellas de las reseñas de la comunidad
Un libro con una valoración media alta pero una gran proporción de reseñas de 1 estrella puede ser controvertido en lugar de universalmente amado. Esta consulta extrae la distribución de valoraciones para cualquier libro específico.
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviews proporciona el recuento total de reseñas escritas junto al desglose de estrellas, útil para distinguir los libros que atraen opiniones escritas extensas de los que acumulan valoraciones silenciosas.
¡Et voilà! Ahora tienes un pipeline funcional que extrae datos web estructurados de Bright Data y los hace consultables en Snowflake.
Automatizar las actualizaciones
Para uso en producción, querrás que los nuevos snapshots se carguen automáticamente en lugar de ejecutar COPY INTO manualmente cada vez. Empieza con la Opción A. Solo pasa a la Opción B si necesitas que la tabla se actualice en segundos tras completarse la entrega.
Opción A: Tarea de Snowflake para ingesta basada en calendario
Una tarea de Snowflake ejecuta COPY INTO según un calendario cron y no requiere infraestructura adicional. Establece un calendario de entrega equivalente en Bright Data para que los archivos estén listos en el stage cuando se active la tarea.
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;Consejo profesional: En tu primera ejecución automatizada, verifica COPY_HISTORY después de que se active la tarea para confirmar que el calendario está alineado con cuándo termina de entregar Bright Data. Una tarea que se ejecute antes de que la entrega se complete encontrará un stage vacío y cargará cero filas.
Opción B: API REST de Snowpipe para ingesta basada en eventos de baja latencia
Snowpipe carga archivos del stage en segundos tras su llegada, activado de forma programática mediante su endpoint REST insertFiles. Úsalo solo si tu caso de uso requiere datos casi en tiempo real. Añade una complejidad de configuración significativa en comparación con la Opción A.
La configuración tiene dos partes. Primero, crea el pipe:
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;Observa la ausencia de AUTO_INGEST = TRUE. Para stages internos con nombre, la ingesta automática mediante mensajería en la nube solo está disponible para cuentas de Snowflake alojadas en AWS y actualmente es una función en versión preliminar. El enfoque con la API REST funciona en todas las plataformas en la nube.
Segundo, conecta tu manejador de webhook para listar los archivos del stage y enviarlos a Snowpipe cuando un snapshot esté listo:
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")Nota: La API REST de Snowpipe requiere autenticación por par de claves, no por contraseña. Genera un par de claves RSA, asigna la clave pública a brightdata_svc en Snowflake (ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...') y pasa la ruta del archivo de clave privada arriba. Instala el SDK con pip install snowflake-ingest.
Conclusión
En este artículo, aprendiste a construir un pipeline completo de ingesta de datos web desde Bright Data a Snowflake. El flujo de trabajo:
- Prepara Snowflake con una base de datos, stage, rol y usuario de servicio dedicados contra los que Bright Data se autentica directamente.
- Configura un conjunto de datos de Bright Data con Snowflake como destino de entrega, sin necesidad de almacenamiento intermedio.
- Activa un snapshot mediante la pestaña Deliveries del panel de control o la API de Conjuntos de Datos, luego monitorea el estado de la entrega hasta que los archivos lleguen al stage.
- Carga los archivos del stage en una tabla estructurada de Snowflake con un único comando
COPY INTOy consulta los datos con SQL estándar.
La misma configuración funciona para cualquier conjunto de datos del marketplace de Bright Data: productos de Amazon, empresas de LinkedIn, ofertas de empleo, listados de hoteles, registros de Crunchbase y más. Cada uno sigue el mismo patrón de entrega; solo cambia el esquema de la tabla.
¡Crea una cuenta gratuita de Bright Data hoy y empieza a incorporar datos web en vivo a tu entorno de Snowflake!





