

En esta entrada del blog aprenderás:
- Por qué TensorFlow es una herramienta ideal para el análisis de datos mediante el aprendizaje automático.
- En qué soluciones debe confiar para recopilar datos de alta calidad que proporcionen información valiosa para su negocio.
- Cómo utilizar TensorFlow para realizar análisis de opiniones en reseñas de productos de Amazon recuperadas a través de Bright Data.
¡Empecemos!
Por qué analizar datos a través de TensorFlow utilizando el aprendizaje automático
Los datos son valiosos por la información que te ayudan a obtener. Esto es especialmente cierto en el caso de las empresas, que aprovechan los datos para tomar decisiones, ajustar estrategias y optimizar resultados. Entre los objetivos comunes se incluyen la mejora de la satisfacción del cliente y la optimización del rendimiento general de las estrategias de marketing.
En lo que respecta al análisis de datos, TensorFlow es una de las bibliotecas de código abierto más populares. Impulsa los sistemas de aprendizaje automático e inteligencia artificial, y es compatible con una amplia gama de tareas.
En concreto, en este artículo utilizaremos TensorFlow para realizar un análisis de opiniones sobre reseñas de productos. Al mismo tiempo, la misma tecnología se puede aplicar a muchos otros casos de uso, como el análisis de comentarios de clientes, los sistemas de recomendación, los modelos predictivos y otros.
Cómo recuperar datos de su empresa
Por muy avanzado que sea su proceso de aprendizaje automático o inteligencia artificial, todos los analistas de datos saben que«más datos son mejores que mejores algoritmos». En pocas palabras, la clave para obtener información significativa es la calidad y la cantidad de los datos.
Pero, ¿cómo se obtienen muchos datos de calidad? La obtención de datos puede ser un reto, por lo que es importante confiar en proveedores de datos fiables, como Bright Data.
Bright Data le ofrece una amplia gama de soluciones de datos, entre las que se incluyen:
- API Web Scraper: acceso programático a datos web estructurados de docenas de dominios populares, recuperados mediante Scraping web.
- Mercado de conjuntos de datos: conjuntos de datos actualizados y listos para usar con miles de millones de entradas de más de 100 sitios web.
- Servicios de adquisición de datos gestionados: servicios de recopilación de datos totalmente gestionados y de nivel empresarial, que le permiten obtener datos e información sin las molestias del desarrollo o el mantenimiento.
Estos productos están dirigidos a investigadores, pymes (pequeñas y medianas empresas) y grandes empresas. En concreto, permiten la recopilación de datos web públicos para impulsar flujos de trabajo de aprendizaje automático, formación en IA, desarrollo de agentes y una larga lista de otros escenarios.
Cómo realizar un análisis de opiniones en las reseñas de productos de Amazon recuperadas a través de Bright Data
En esta sección paso a paso, utilizará TensorFlow para crear un flujo de trabajo de análisis de datos del mundo real. Abordaremos el caso práctico del análisis de opiniones sobre productos.
Supongamos que usted es una empresa que vende múltiples productos en Amazon. Para mejorar la satisfacción del cliente, necesita un proceso que supervise periódicamente las reseñas que dejan los usuarios sobre cada producto y realice un análisis de opiniones para comprender qué funciona bien y qué hay que mejorar.
En este ejemplo, nos centraremos en el siguiente producto de Amazon:
Nota: Puede ampliar este flujo de trabajo a varios productos de Amazon, ya que el Scraper de reseñas de Amazon de Bright Data admite el rascado de reseñas de varios productos con una escalabilidad ilimitada.
Este es un gran ejemplo, ya que tiene un gran número de reseñas que se distribuyen de manera razonable entre las 5 estrellas: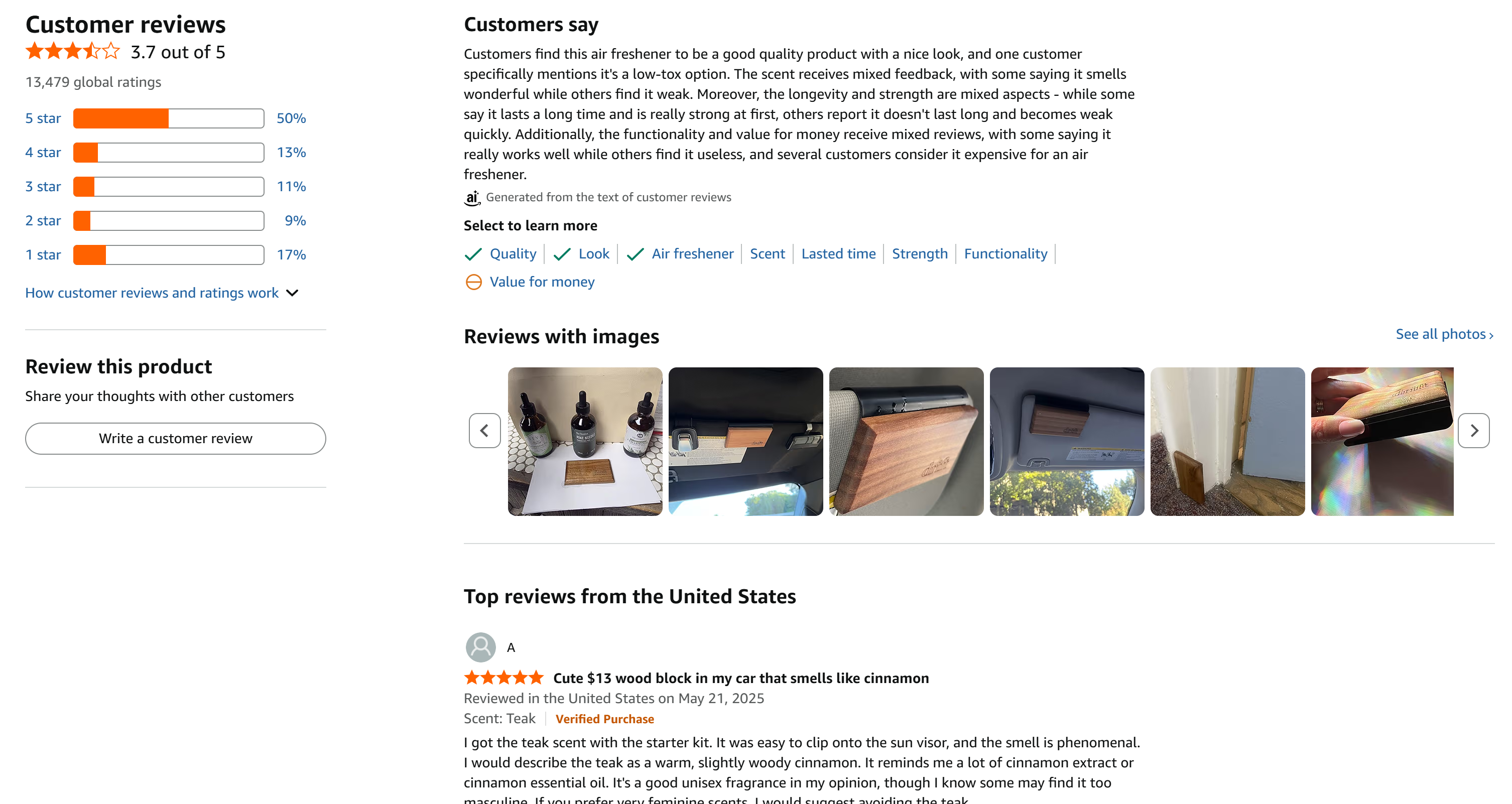
Siga las instrucciones que se indican a continuación para crear un proceso de análisis de opiniones apto para empresas. Las opiniones sobre el producto se recuperarán a través de Bright Data y, a continuación, se analizarán mediante flujos de trabajo de aprendizaje automático en TensorFlow con Python.
Requisitos previos
Para seguir este tutorial, asegúrese de tener:
- Python 3.9+ instalado localmente.
- Una cuenta de Bright Data con una clave API.
No se preocupe si aún no tiene una cuenta de Bright Data, ya que se le guiará a través del proceso de configuración en los siguientes pasos.
Estar familiarizado con el modelo Universal Sentence Encoder, cómo funcionan las incrustaciones vectoriales y cómo operan los modelos secuenciales Keras con capas de redes neuronales densas será muy útil para comprender completamente la lógica de TensorFlow en el análisis de sentimientos.
Paso n.º 1: Configurar un proyecto JupyterLab
Dado que este proceso de aprendizaje automático de TensorFlow también incluirá gráficos y visualización de datos, tiene sentido utilizar JupyterLab como entorno de desarrollo. De este modo, el código se puede migrar fácilmente a un canal de ML listo para la producción.
En primer lugar, comience por crear una carpeta de proyecto. Navegue hasta ella:
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysisA continuación, inicialice un entorno virtual dentro de la carpeta:
python -m venv .venvEs hora de activar el entorno virtual. En macOS/Linux, ejecute:
source .venv/bin/activateO, en Windows, ejecute:
.venvScriptsactivateEn el entorno activo, instala JupyterLab a través del paquete jupyterlab:
pip install jupyterlabContinúe iniciando JupyterLab con:
jupyter labVerá la interfaz de JupyterLab:
Defina un nuevo cuaderno haciendo clic en el botón «Python 3 (ipykernel)» en la sección «Notebook»:
Asigne un nombre a su cuaderno y guárdelo.
¡Listo! Ahora tiene un entorno Python configurado, ideal para desarrollar flujos de trabajo de análisis de datos de aprendizaje automático con TensorFlow.
Paso n.º 2: Instalar las bibliotecas
Añada un bloque de código e instale las bibliotecas necesarias con:
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requestsEjecute este bloque para instalar todas las bibliotecas necesarias para esta implementación:
tensorflow: para crear y entrenar modelos de aprendizaje automático.tensorflow-hub: para cargar modelos de aprendizaje automático preentrenados.scikit-learn: para el preprocesamiento de datos, la división entre entrenamiento y prueba, las métricas y la ponderación de clases.pandas: para manejar datos tabulares y realizar agregaciones.numpy: para cálculos numéricos y manejo de matrices.matplotlib: para trazar gráficos y visualizar resultados.requests: Para realizar solicitudes HTTP e interactuar con la API de Bright Data Scraper.
A continuación, añade otro bloque de código para importar y configurar todas las bibliotecas necesarias:
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow import keras
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.utils.class_weight import compute_class_weight
from IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)¡Increíble! Con esto, todos tus bloques de código posteriores estarán listos para impulsar la recuperación de Bright Data y los flujos de trabajo de análisis basados en TensorFlow.
Paso n.º 3: Empieza a utilizar el Scraper de reseñas de Amazon de Bright Data
Antes de escribir el código para recuperar los datos de las reseñas de Amazon, tómate un tiempo para configurar tu cuenta de Bright Data y familiarizarte con la solución de scraping de datos necesaria.
En este tutorial, utilizaremos la API de reseñas de Amazon de Bright Data, que te permite extraer de forma programada datos de reseñas recientes de un producto determinado. Esto es ideal si deseas supervisar las reseñas de tus propios productos.
Alternativamente, para escenarios más generales, Bright Data también proporciona un conjunto de datos«Amazon Reviews»ya preparado con más de 28,6 millones de reseñas: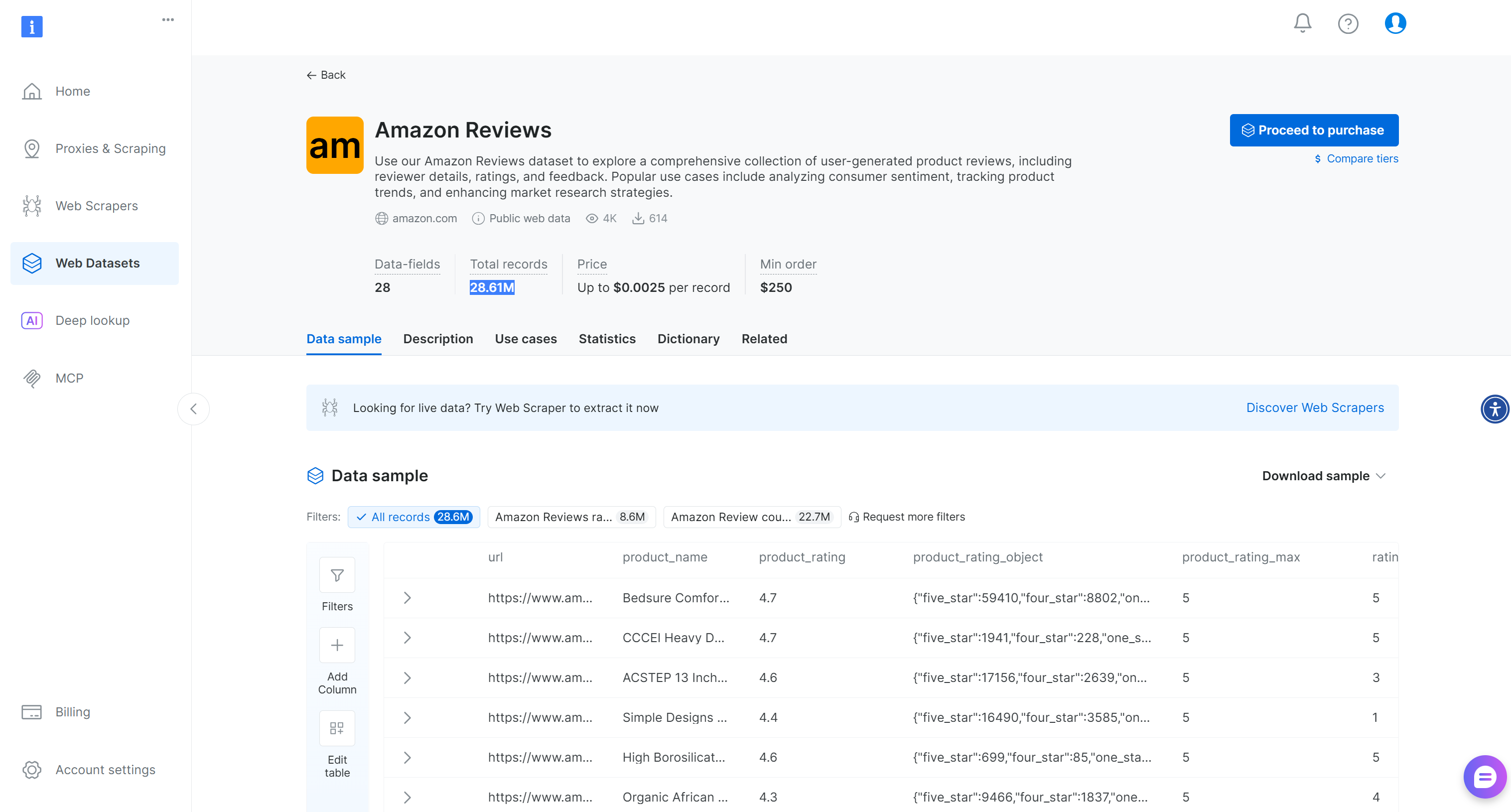
Ahora, si aún no tiene una cuenta de Bright Data, cree una. De lo contrario, inicie sesión y navegue hasta la página«BibliotecadeScrapers web»de su cuenta:
Busque «amazon» y seleccione el Scraper «Amazon Reviews – collect by URL» (Reseñas de Amazon: recopilar por URL):
En esta página, puede ver cómo generar código listo para la integración o probar el Scraper directamente a través de la aplicación web sin código.
Seleccione la opción «API del Scraper» y accederá a la página siguiente:
Aquí, revise los parámetros de entrada compatibles y el formato de salida. En concreto, este conjunto de datos devuelve una lista de reseñas de Amazon y tiene el ID gd_le8e811kzy4ggddlq.
Para llamar a este Scraper a través de la API, debe autenticar sus solicitudes utilizando su clave API de Bright Data. Si no tiene una, siga la guía oficial para generarla. Guárdela en un lugar seguro, ya que la necesitará en breve.
¡Genial! Ya está listo para utilizar el Scraper de reseñas de Amazon de Bright Data y recuperar datos de reseñas de productos para su análisis.
Paso n.º 4: Recuperar los datos de reseñas de productos de Amazon
Cree una nueva celda en el cuaderno y pegue el siguiente código:
BRIGHT_DATA_API_KEY = "<TU_CLAVE_API_DE_BRIGHT_DATA>" # Reemplaza con tu clave API de Bright Data
def trigger_snapshot(amazon_product_url):
# Activa la API del Scraper web de Bright Data para una URL de producto de Amazon determinada
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # ID del Scraper «Amazon Reviews - collect by URL»
"include_errors": "true",
}
# Formatear los datos de entrada para la llamada a la API.
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # Autenticar la solicitud.
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"¡Solicitud correcta! ID de instantánea: {snapshot_id}")
return snapshot_id
else:
print(f"¡Solicitud fallida! Código de estado: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# Sondea la API de Bright Data Scraper hasta que la instantánea esté lista y, a continuación, guárdala.
snapshot_url = f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
print(f"Solicitando instantánea para ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("La instantánea está lista. Descargando...")
snapshot_data = response.text
# Escribir la instantánea en un archivo
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"Instantánea guardada en {output_file}")
return
elif response.status_code == 202:
print(f"La instantánea aún no está lista. Reintentando en {tiempo_de_encuesta} segundos...")
time.sleep(tiempo_de_encuesta)
else:
print(f"¡Solicitud fallida! Código de estado: {respuesta.código_estado}")
print(respuesta.texto)
break
# URL del producto de Amazon para recuperar reseñas
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# Activar instantánea y descargar reseñas
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")Reemplaza el marcador de posición <YOUR_BRIGHT_DATA_API_KEY> con tu clave API de Bright Data real generada anteriormente.
El código anterior:
- Activa el Scraper de reseñas utilizando
los Conjuntos de datos/v3/trigger, que inicia un trabajo de rastreo en la nube de Bright Data utilizando el Scraper de reseñas de Amazon. - Solicita la instantánea del conjunto de datos generado utilizando
conjuntos de datos/v3/snapshot/{snapshot_id}, esperando hasta que Bright Data termine de extraer las reseñas. - Exporta los datos finales como un CSV (porque se ha especificado
format="csv") y los guarda localmente enproduct-reviews.csv.
Así es exactamente como funciona el flujo de trabajo de la API Web Scraper. Para obtener más detalles, consulta la documentación oficial de Bright Data.
Al ejecutar el bloque de código, debería ver algo similar a esto: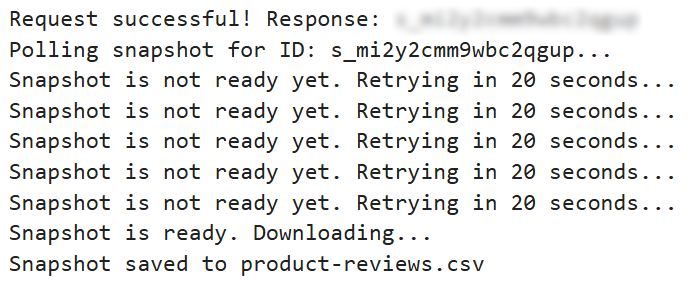
A continuación, aparecerá un archivo product-reviews.csv en la carpeta de su proyecto. Ábralo y verá las reseñas extraídas en formato estructurado: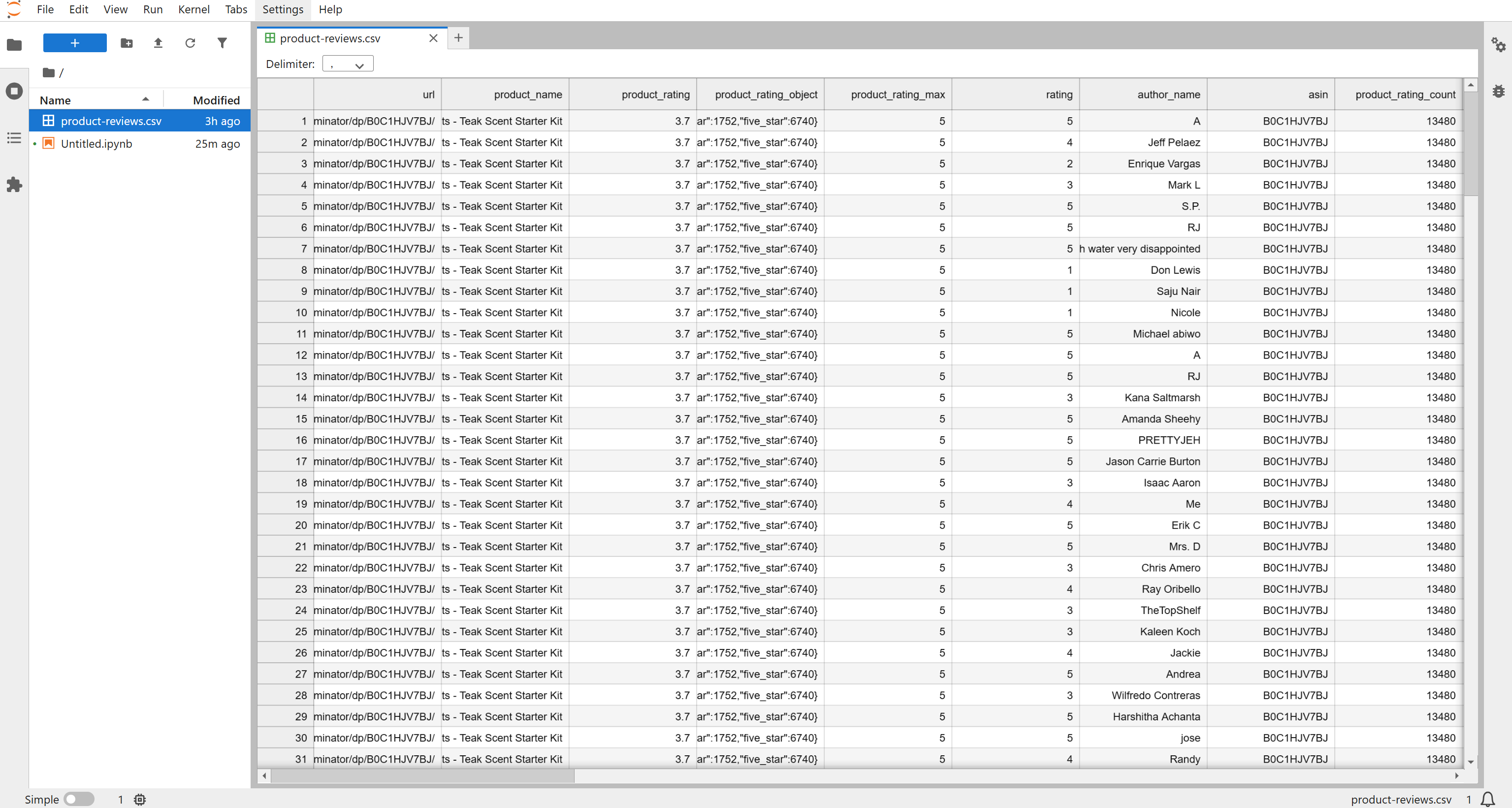
De forma predeterminada, el Scraper devuelve las últimas 200 reseñas, pero puede ajustar las entradas de la API para obtener más si es necesario. Para este tutorial, las 196 reseñas recuperadas son más que suficientes para completar el proceso de análisis de opiniones.
¡Genial! Ahora tienes datos recientes de reseñas de productos de Amazon listos para el análisis de TensorFlow.
Paso n.º 5: Explora los datos extraídos
Comience cargando los datos recopilados del archivo product-reviews.csv:
# Cargar las reseñas de productos del archivo CSV generado a través de Bright Data.
df = pd.read_csv("product-reviews.csv")
# Convertir las fechas de publicación de las reseñas a fecha y hora.
df["date"] = pd.to_datetime(df["review_posted_date"])
# Eliminar reseñas con texto faltante
df = df.dropna(subset=["review_text"])
# Ordenar las reseñas por fecha de publicación (ascendente)
df = df.sort_values(by="date", ascending=True)
print(f"Cargadas {len(df)} reseñas.")Ejecute esta celda y verá el número total de reseñas cargadas:
Se han cargado 196 reseñas.A continuación, analiza la distribución de las valoraciones:
print(df["rating"].value_counts())Deberías obtener algo similar a:
calificación
1 74
2 31
3 16
4 12
5 63Como se muestra arriba, las reseñas están distribuidas de manera bastante uniforme en el rango de 1 a 5 estrellas. Para visualizar mejor esta distribución, utilice un gráfico de barras con Matplotlib:
# Calcular el número de reseñas por calificación (1-5 estrellas)
rating_counts = df["rating"].value_counts().sort_index()
# Trazar la distribución de calificaciones en un gráfico de barras
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("Distribución de valoraciones (1-5 estrellas)")
plt.xlabel("Estrellas")
plt.ylabel("Recuento")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()Obtendrá un gráfico similar al siguiente: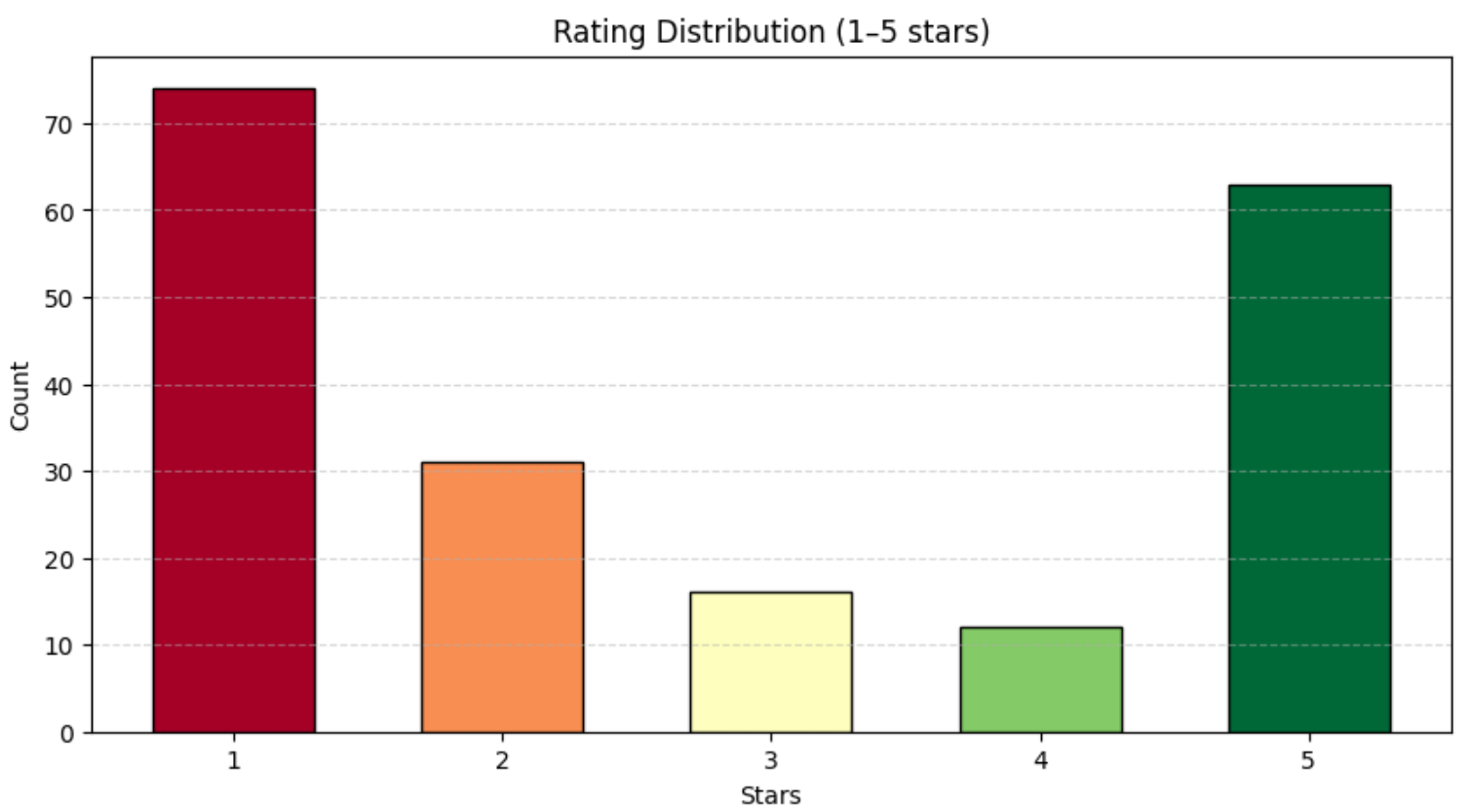
¡Perfecto! Ahora tiene una comprensión clara y de alto nivel del conjunto de datos de reseñas de Amazon que acaba de obtener. Esta base es esencial antes de pasar al entrenamiento del modelo y al análisis de sentimientos.
Paso n.º 6: Asignar una puntuación de análisis de sentimientos a las reseñas
Antes de aplicar el aprendizaje automático, es útil simplificar la tarea de clasificación del sentimiento ignorando las reseñas de 3 estrellas. Esto se debe a que esas reseñas suelen ser neutras y no expresan claramente un sentimiento positivo o negativo.
Mantenerlas obligaría al modelo a aprender un problema de tres clases (positivo/neutro/negativo), lo que requiere más datos y un modelado más complejo. En su lugar, vamos a convertir la tarea en una clasificación binaria del sentimiento considerando:
- las reseñas de 4-5 estrellas como «positivas» (
1); - las reseñas de 1-2 estrellas como «negativas» (
0).
Teniendo esto en cuenta, implementa la lógica del análisis de sentimientos en TensorFlow de la siguiente manera:
# Eliminar las reseñas neutras (calificación = 3) para claridad de sentimiento binario.
df = df[df["rating"] != 3]
# Asignar calificaciones al sentimiento: 1 = positivo (>=4), 0 = negativo (<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# Cargar incrustaciones del codificador universal de frases
print("Cargando incrustaciones del codificador universal de frases...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # float32 fijo
y = df["sentiment_label"].values
# Dividir el conjunto de datos en conjuntos de entrenamiento y validación
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# Calcular los pesos de clase para manejar el desequilibrio de clases
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# Construir un clasificador denso simple con la capa de entrada primero
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# Forzar la construcción del modelo para evitar el retraceado.
_ = model(X_emb[:1])
# Entrenar el modelo
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# Predecir en el conjunto de validación y evaluar
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("Informe de clasificación del modelo de sentimiento:")
print(classification_report(y_val, y_pred))
# Predecir en el conjunto de datos completo y guardar las puntuaciones de sentimiento
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()Este bloque de código se basa en el Universal Sentence Encoder para convertir cada reseña en un vector semántico. Si no está familiarizado con ese modelo, el Universal Sentence Encoder es un modelo de Google que convierte el texto en vectores de incrustación de 512 dimensiones para tareas de procesamiento del lenguaje natural, como la clasificación, la similitud semántica y otras.
Esas incrustaciones capturan significados como el tono, el sentimiento y la intención expresados en cada reseña. A continuación, el modelo secuencial de Keras utiliza capas totalmente conectadas (densas) para aprender patrones en las incrustaciones que distinguen el sentimiento positivo del negativo. Su resultado es una puntuación de probabilidad, donde:
- Los valores cercanos a
1,0indican un sentimiento positivo; - Los valores cercanos a
0,0indican un sentimiento negativo.
El modelo asigna una de estas puntuaciones a cada reseña. El informe de clasificación del conjunto de validación es:
Informe de clasificación del modelo de sentimiento:
precisión recuerdo puntuación f1 soporte
0 0,91 0,95 0,93 21
1 0,93 0,87 0,90 15
precisión 0,92 36
macro promedio 0,92 0,91 0,91 36
promedio ponderado 0,92 0,92 0,92 36Esto muestra que:
- El modelo alcanza una precisión del 92 % en datos de validación no vistos.
- La precisión y la recuperación son consistentemente sólidas tanto para las clases positivas como para las negativas.
- La precisión del entrenamiento y la validación son similares, lo que indica que el modelo no presenta un sobreajuste significativo.
Para visualizar mejor el proceso de entrenamiento del aprendizaje automático, considere añadir un gráfico como el que se muestra a continuación:
plt.plot(history.history["accuracy"], label="Precisión del entrenamiento")
plt.plot(history.history["val_accuracy"], label="Precisión de la validación")
plt.title("Rendimiento del entrenamiento del modelo de sentimiento")
plt.xlabel("Época")
plt.ylabel("Precisión")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()Esto mostrará el historial completo del entrenamiento: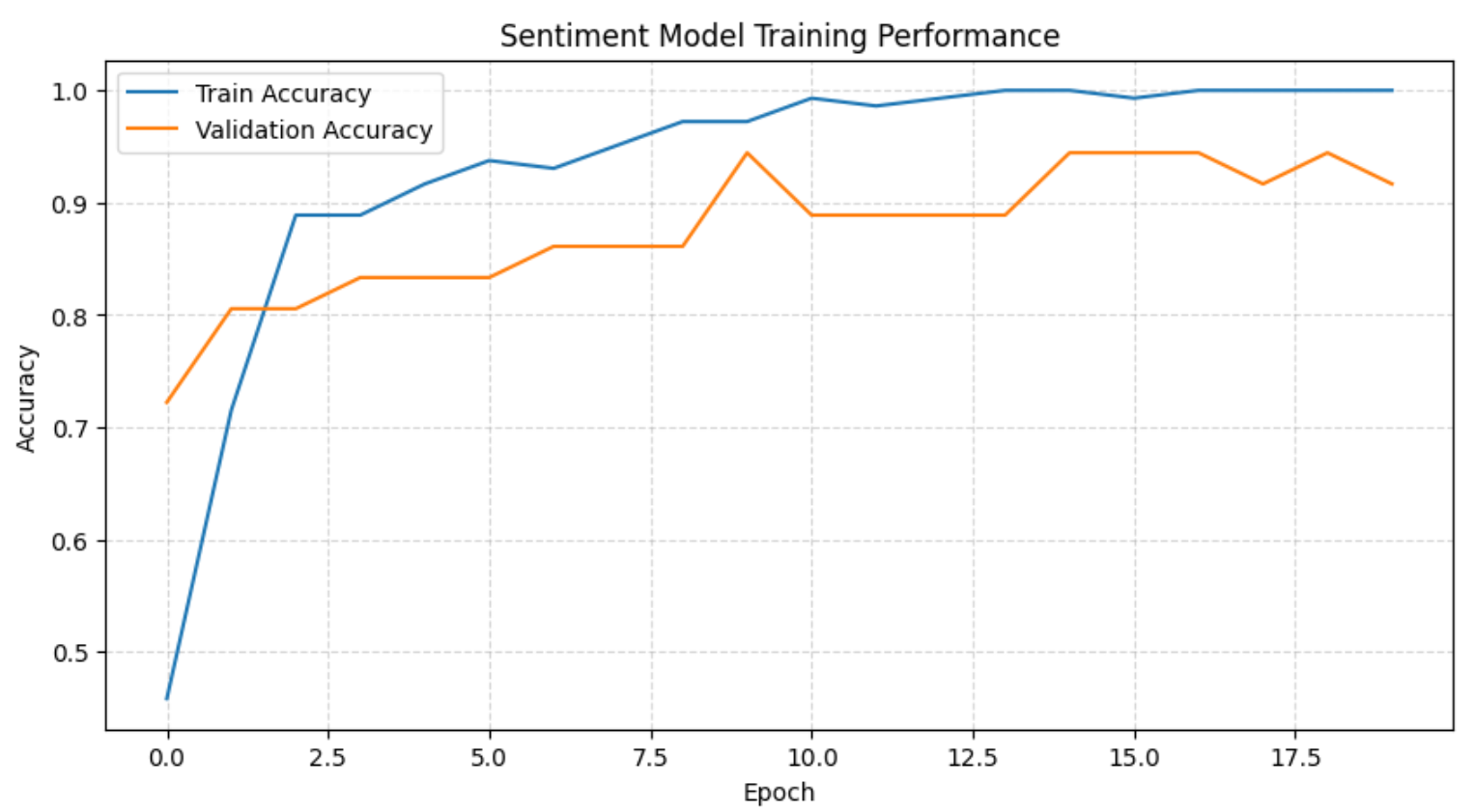
El gráfico anterior, junto con los registros de entrenamiento, muestra que el modelo aprende rápidamente el límite del sentimiento en las primeras épocas antes de estabilizarse con una fuerte precisión de validación. A medida que avanza el entrenamiento, la precisión en el conjunto de entrenamiento alcanza el 100 %, mientras que la precisión de validación se mantiene constantemente alta, lo que indica un sobreajuste leve y aceptable dado el tamaño del conjunto de datos.
Por último, visualice las probabilidades de sentimiento previstas:
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("Predicted Sentiment Score Distribution")
plt.xlabel("Sentiment Score")
plt.ylabel("Count")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()El resultado será: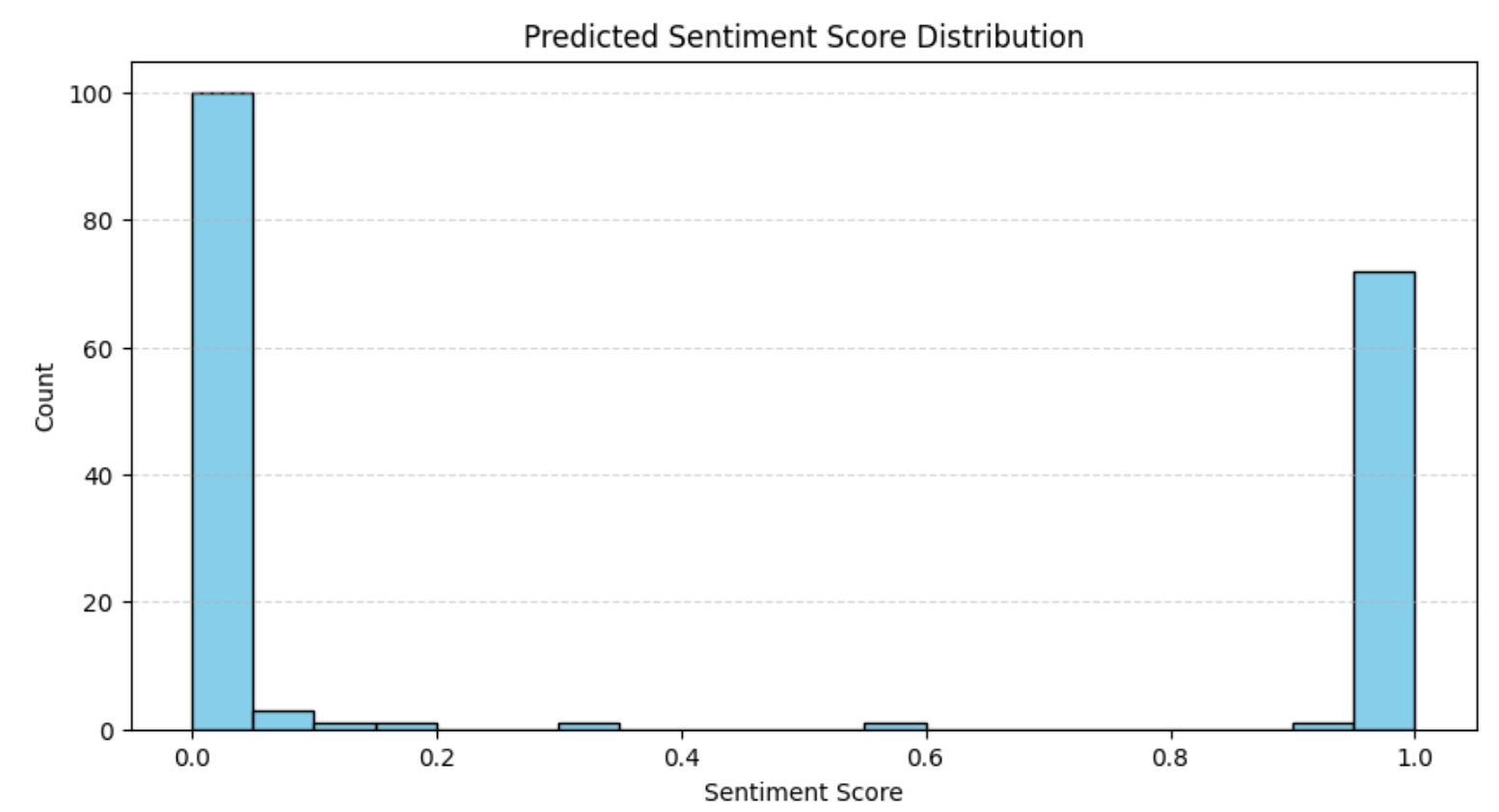
La distribución coincide con lo que observamos anteriormente en el análisis de valoraciones, es decir, la mayoría de las reseñas son muy positivas o muy negativas. Este patrón es habitual en las plataformas de comercio electrónico, donde suelen predominar las opiniones polarizadas.
¡Fantástico! Análisis de opiniones completado.
Paso n.º 7: Estudiar el análisis de sentimientos a lo largo del tiempo
Ahora que cada reseña tiene una puntuación de sentimiento, visualice cómo ha evolucionado el sentimiento de los clientes durante el último año. Aplique una tendencia móvil de 7 días al sentimiento medio diario para suavizar el ruido diario:
# Preparar la puntuación media diaria
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# Filtrar hasta el año pasado
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# Calcular la tendencia móvil de 7 días
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# Establecer una etiqueta del eje x por mes
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # Inicio del mes
)
# Trazar el sentimiento diario y la tendencia móvil
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="Sentimiento diario")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="Tendencia móvil de 7 días")
# Establecer etiquetas del eje x
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("Sentimiento medio diario (último año) + tendencia")
plt.xlabel("Fecha")
plt.ylabel("Puntuación del sentimiento")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()Esto genera el siguiente gráfico de sentimiento a lo largo del tiempo: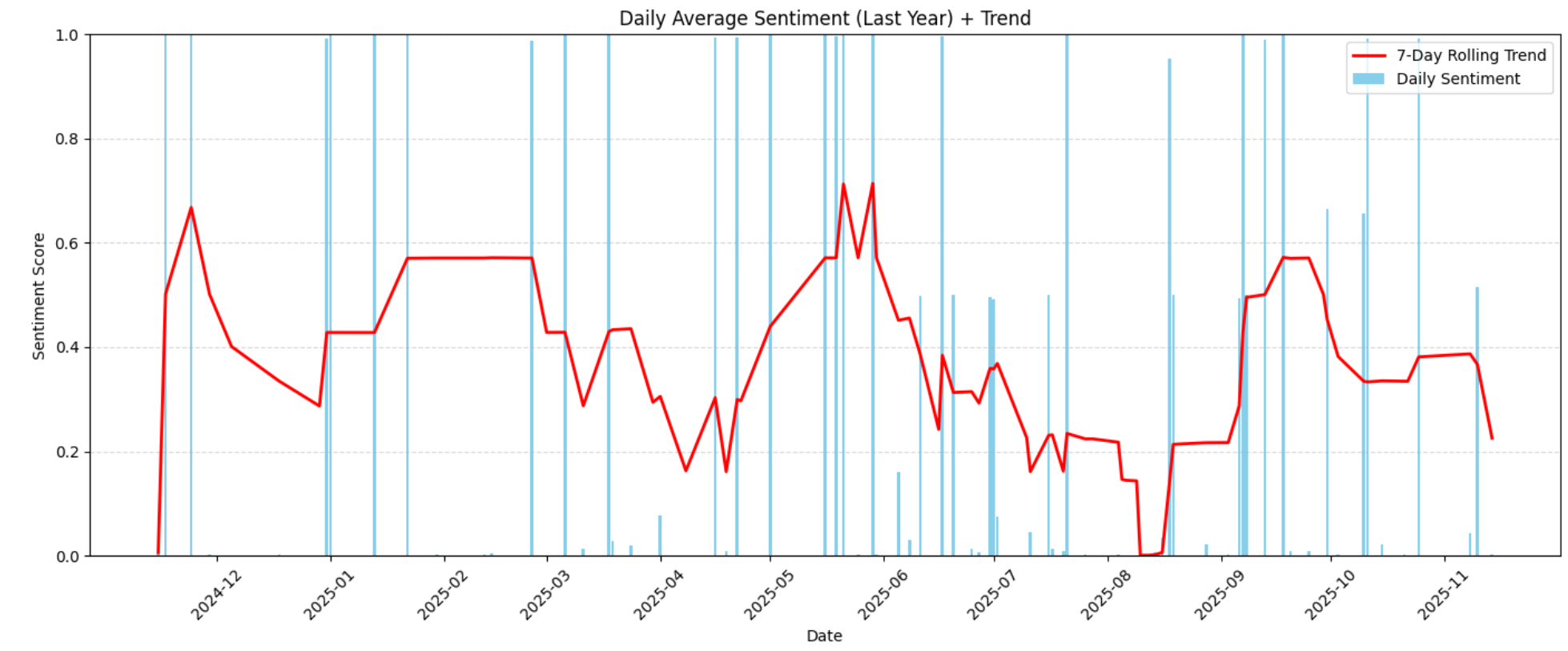
La visualización destaca los patrones de sentimiento crecientes o decrecientes a lo largo del año. Estas tendencias le ayudan a reconocer cuándo mejoró o disminuyó la satisfacción del cliente y si algún factor externo (cambios en el producto, retrasos, defectos, actualizaciones de precios) pudo haber causado cambios en el sentimiento.
Por ejemplo, en el gráfico se puede ver claramente que entre junio de 2026 y mediados de agosto de 2026, el sentimiento cayó drásticamente, pasando de moderadamente positivo (alrededor de 0,6) a extremadamente negativo (cerca de 0,0):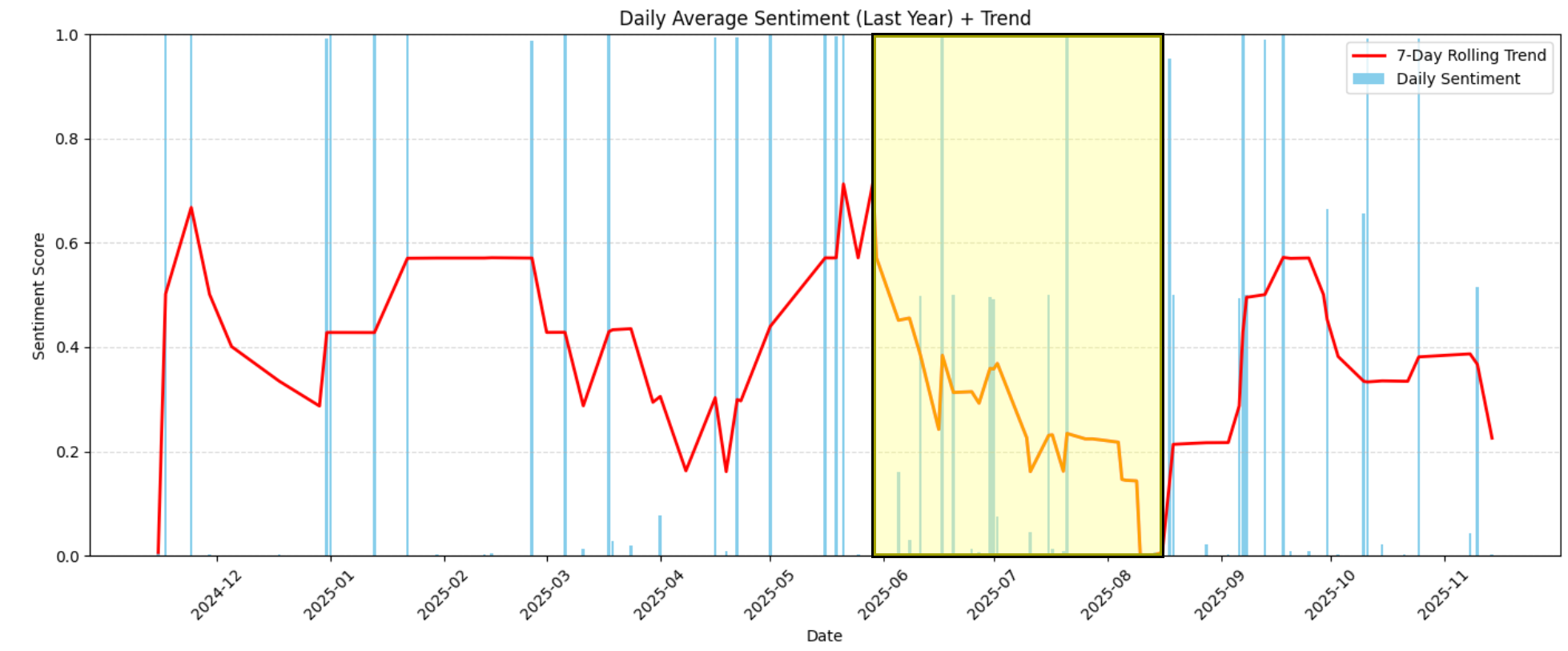
Para comprender lo que sucedió durante este periodo, restrinja los Conjuntos de datos a esas fechas:
# Filtrar reseñas entre junio de 2026 y mediados de agosto de 2026
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"Número de reseñas en el periodo: {len(df_filtered)}")Como muestra el resultado, hay 34 reseñas en ese intervalo:
Número de reseñas en el periodo: 34A continuación, resumamos cómo se distribuye la opinión entre las valoraciones:
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("Resumen de nRating:")
print(rating_summary)El resultado sería:
Resumen de valoraciones:
valoración num_reviews avg_sentiment
0 1 16 0,004767
1 2 11 0,048928
2 4 2 0,998977
3 5 5 0,993221Esto nos indica que 27 de las 34 reseñas fueron de 1 o 2 estrellas, y que sus puntuaciones de sentimiento son muy cercanas a 0,0.
Representa gráficamente la relación entre las valoraciones y el sentimiento:
# Traza el sentimiento frente a la calificación en un gráfico
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="Número de reseñas")
ax1.set_xlabel("Calificación")
ax1.set_ylabel("Número de reseñas", color="skyblue")
ax1.tick_params(axis="y", labelcolor="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="Sentimiento promedio")
ax2.set_ylabel("Puntuación de sentimiento promedio", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("Análisis de sentimiento frente a valoración (del 1 de junio de 2026 al 15 de agosto de 2026)")
fig.tight_layout()
plt.show()El gráfico resultante será: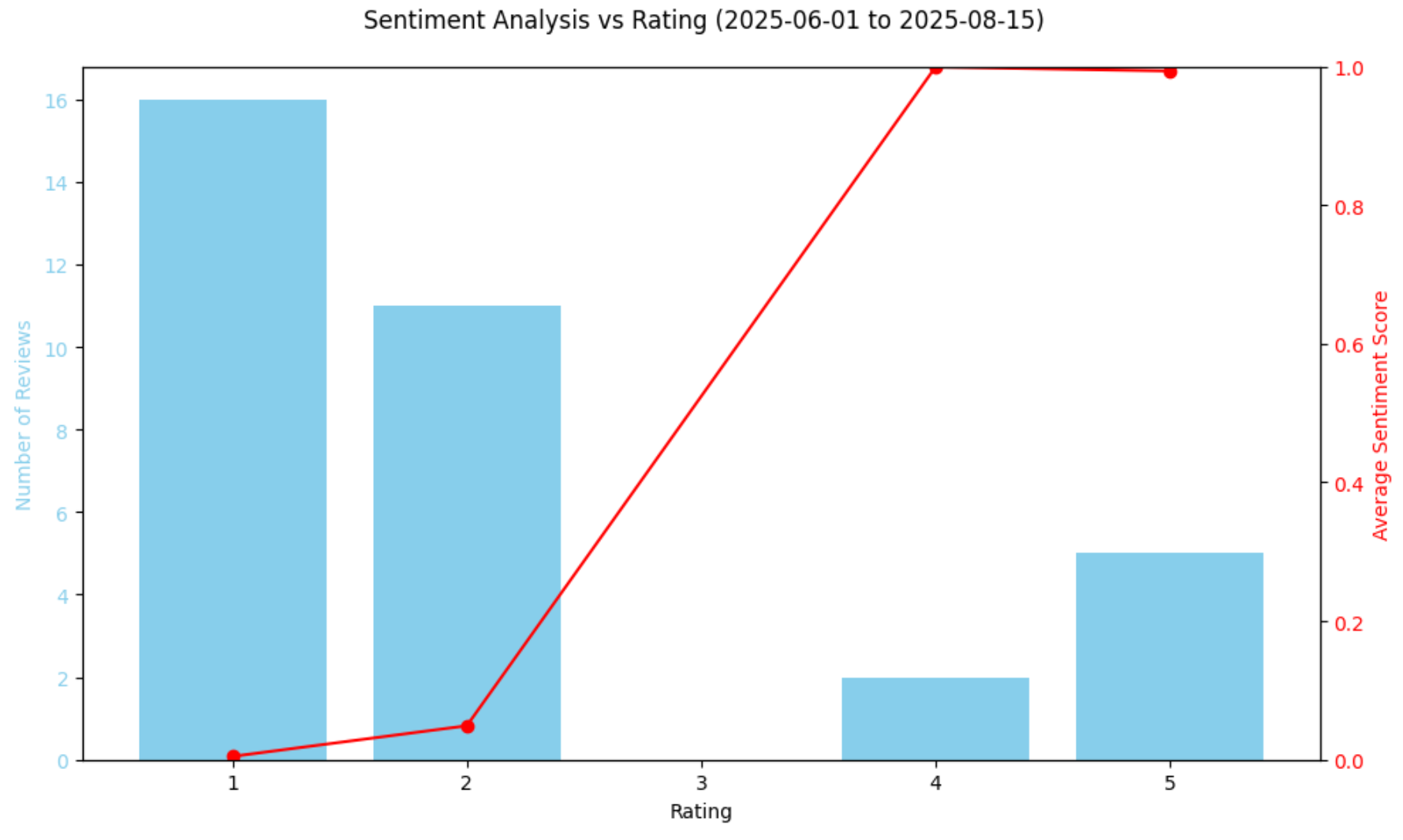
El gráfico anterior confirma la fuerte caída del sentimiento, ya que la mayoría de las reseñas de ese periodo son totalmente negativas. Curiosamente, el modelo clasifica ligeramente las reseñas de 4 estrellas de forma más positiva que las de 5 estrellas a través de sus puntuaciones de análisis del sentimiento. No se trata de un error, ya que refleja que la calificación por estrellas por sí sola no siempre refleja el tono emocional. Algunas reseñas de 5 estrellas pueden seguir conteniendo preocupaciones, mientras que algunas reseñas de 4 estrellas pueden expresar un lenguaje extremadamente positivo.
Al fin y al cabo, aunque las puntuaciones por estrellas dan una idea rápida de cómo se sienten los clientes, no siempre captan todos los matices del texto de la reseña. Al comparar las puntuaciones de sentimiento predichas por el modelo con las puntuaciones numéricas, se puede ver si el lenguaje de las reseñas se ajusta a las estrellas asignadas. Esto ayuda a identificar anomalías, como expresiones negativas en reseñas que, por lo demás, tienen una puntuación alta, o sutiles matices positivos en reseñas con puntuaciones más bajas.
¡Continuemos analizando este interesante patrón identificado en la disminución de las puntuaciones de las reseñas!
Paso n.º 8: Leer las reseñas relevantes
El último paso para comprender realmente lo que ocurrió durante el descenso de las reseñas entre junio de 2026 y mediados de agosto de 2026 es inspeccionarlas directamente. Para ello, haz lo siguiente:
# Seleccionar las columnas relevantes
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# Mostrar la tabla en el cuaderno mediante HTML
display(HTML(df_table.to_html(index=False)))El resultado será la siguiente tabla HTML:

Como se puede observar, la mayoría de las reseñas durante este periodo se quejan de que el aroma desaparece rápidamente o no es lo suficientemente intenso. Esto pone de relieve posibles problemas de producción en los productos enviados durante esas semanas.
Esta información es extremadamente valiosa, ya que permite investigar el proceso de producción, abordar problemas recurrentes y, potencialmente, ponerse en contacto con los clientes insatisfechos para ofrecerles soluciones como vales o descuentos.
Nota: Este proceso de análisis de reseñas también podría automatizarse aún más utilizando un LLM, lo que lo convertiría en un proceso totalmente autónomo y listo para la producción.
¡Et voilà! Gracias a las capacidades de scraping de Bright Data, ha recuperado los datos de los productos de Amazon. A continuación, ha aplicado TensorFlow para el análisis de sentimientos, ha estudiado las tendencias y ha identificado las razones que explican la caída de las reseñas en un periodo de tiempo específico.
Conclusión
En este artículo, ha visto cómo recuperar datos de reseñas de un producto de Amazon a través de Bright Data y procesarlos para identificar tendencias de análisis de opiniones utilizando flujos de trabajo de aprendizaje automático creados con TensorFlow en un cuaderno de Python.
El proyecto que se presenta aquí satisface las necesidades de las pequeñas y medianas empresas o de las grandes empresas que buscan formas de supervisar las reseñas de los usuarios y mejorar la satisfacción de los clientes. Este análisis no sería posible sin los servicios de datos que ofrece Bright Data para empresas.
Estas soluciones incluyen un rico mercado de Conjuntos de datos y API de Scraper web que le ayudan a recopilar datos antiguos o recién actualizados de más de 100 dominios, entre los que se incluyen Amazon, LinkedIn, Yahoo Finance y muchos otros. Una vez obtenidos los datos, puede introducirlos en TensorFlow o tecnologías similares para analizarlos mediante aprendizaje automático.
¡Cree hoy mismo una cuenta gratuita en Bright Data para probar nuestras API de Scraper o explorar nuestros Conjuntos de datos!




