

El scraping web es el proceso de extraer contenido y datos de sitios web utilizando scripts o herramientas de software automatizadas. La información extraída se exporta normalmente a un formato más útil, como un archivo sin procesar o CSV, para facilitar su consumo.
Si desea simplificar sus flujos de trabajo de Scraping web,Google Sheetses la solución. Se trata de una popular herramienta de gestión de datos ideal para extraer datos estructurados o tabulares de sitios web y para analizar o visualizar sus datos. Por ejemplo, puede utilizarla para extraer detalles y precios de productos de sitios de comercio electrónico o para obtener información de contacto de directorios de empresas. También es útil para realizar un seguimiento de la interacción en las redes sociales o para realizar análisis de la opinión pública con el fin de medir la eficacia de las campañas.
En este tutorial, aprenderás a configurar y utilizar Google Sheets para el Scraping web.
Configuración de Google Sheets
Para empezar a realizar Scraping web con Google Sheets, debe crear una nueva hoja de cálculo de Google accediendo ahttps://sheets.google.comy haciendo clic en el botón+:
Este tutorial muestra cómo extraer información sobre los precios de los libros delsitio webBooks to Scrape, pero puedes utilizar un sitio web diferente modificando la siguiente URL y las consultas.
Comprender las fórmulas de Google Sheets
Google Sheets admite numerosasfórmulas de celdaque se pueden utilizar para diversas operaciones, incluido el Scraping web. Veamos cómo funcionan algunas de estas fórmulas.
IMPORTXML
La funciónIMPORTXMLle permite consultar e importar datos estructurados a Google Sheets. Admite los formatos de archivo XML, HTML, CSV y TSV. La sintaxis de la función es la siguiente:
=IMPORTXML(url, xpath_query)
La función importa datos desde la URL web especificada y utiliza el localizadorXPathpara encontrar el elemento relevante en la página web. Por ejemplo, puede obtener el encabezadoH1del sitioweb Books to Scrapeañadiendo la siguiente fórmula en una celda de Google Sheets:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//h1")
Al utilizarla por primera vez, Google Sheets le pedirá que habilite el acceso antes de obtener datos de sitios web de terceros:
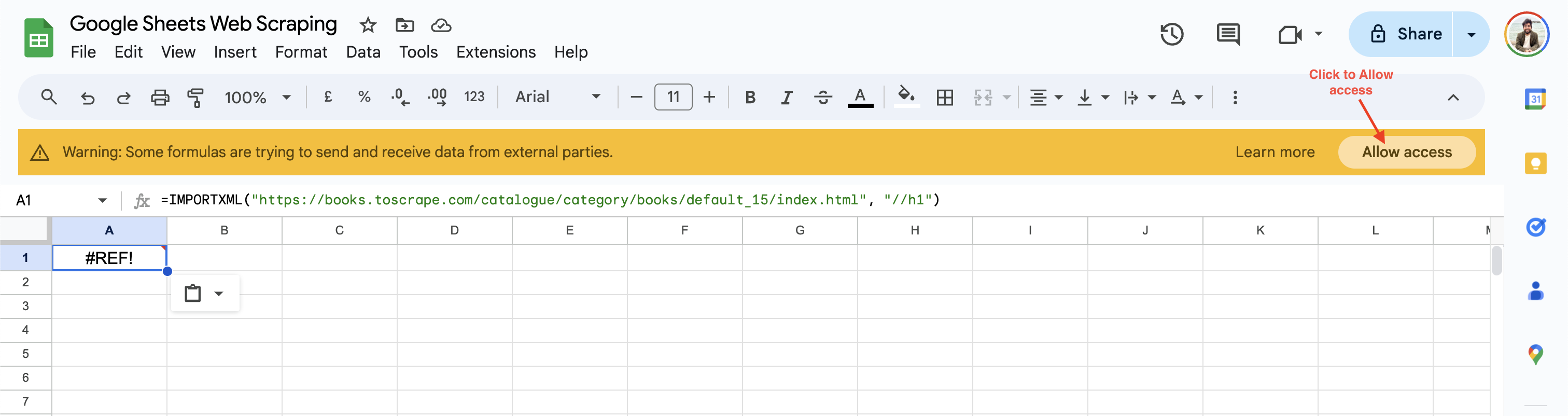
Una vez que hagas clic en Permitir acceso, Google Sheets resolverá el valor de la celda al encabezado H1 de la página web a Predeterminado.
IMPORTHTML
La función IMPORTHTML le permite importar datos de una tabla o una lista en una página HTML. La sintaxis de la función es la siguiente:
=IMPORTHTML(url, consulta, índice)
Esta función importa los datos de la url a la hoja basándose en la consulta especificada. El atributo de consulta se puede establecer como una lista o una tabla, según el tipo de datos que desee importar. El índice comienza en 1 y determina qué tabla o lista se debe importar. Por ejemplo, puede obtener la lista de libros de Books to Scrape utilizando esta fórmula:
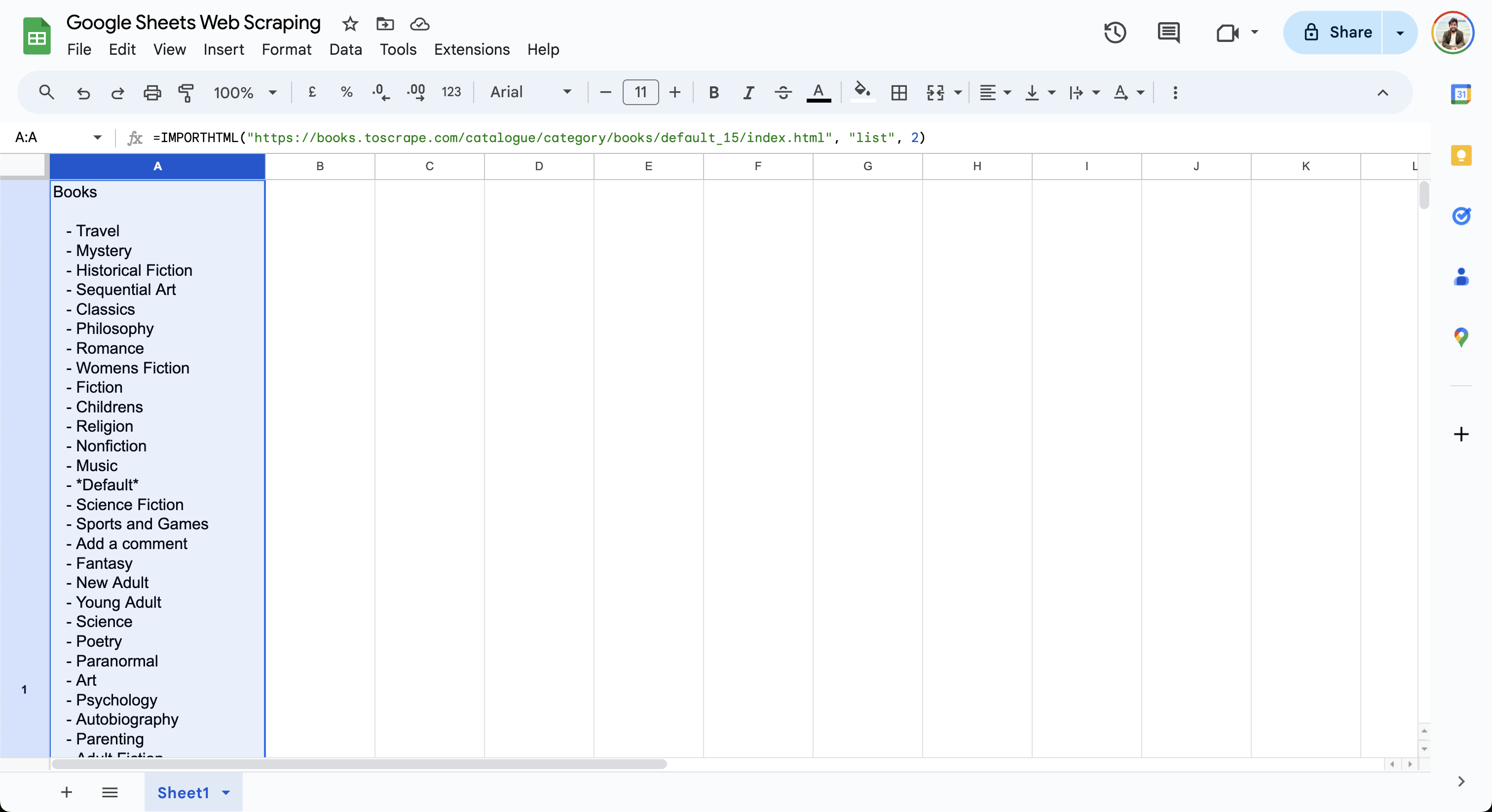
=IMPORTHTML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "list", 2)
Esta fórmula muestra la lista de libros en la celda actual, como se muestra aquí:
Como puede ver, las fórmulasIMPORTXMLeIMPORTHTMLson fáciles de usar y le permiten empezar a extraer datos de una página web mediante consultas sencillas. Para casos de uso más complejos, consulte esta guía que explica cómo utilizar VBA y Selenium para el Scraping web en Excel.
Extracción de datos con IMPORTXML
En la sección anterior, ha aprendido el uso básico deIMPORTXMLpara obtener los encabezados de la página especificando el atributo XPath relevante. El atributo XPath es muy potente y le permite recorrer cualquier elemento de una página web, independientemente de su jerarquía. En la siguiente sección, utilizaráIMPORTXMLpara obtener el título, el precio y la valoración de todos los libros deestapágina webBooks to Scrape.
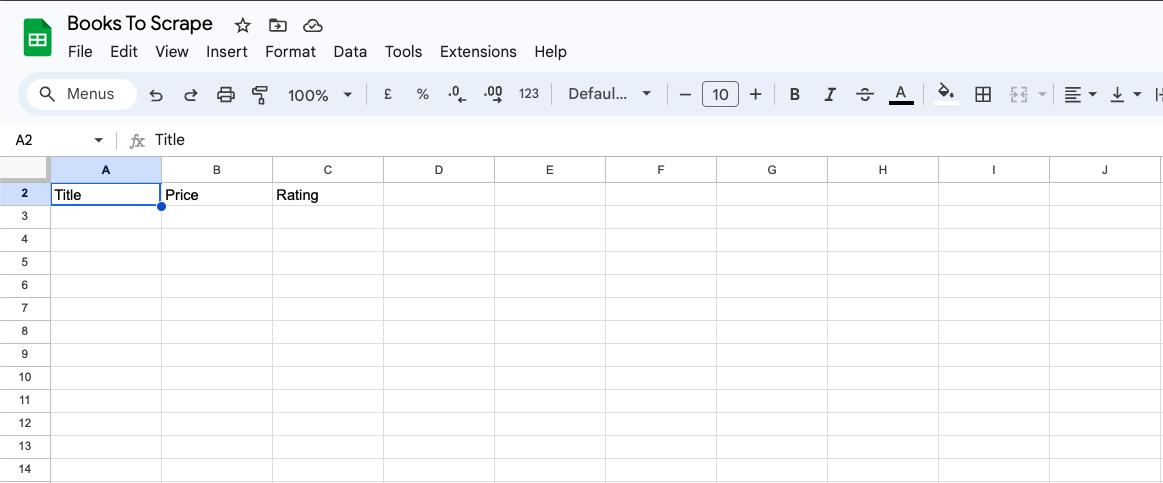
Para empezar, añada las columnas Título, Precio y Valoración en Google Sheets:
Para obtener el título del libro de Books to Scrape, necesita su ubicación XPath, que se puede encontrar utilizando la herramienta Inspeccionar del navegador. Para encontrar el XPath del título del libro, haga clic con el botón derecho del ratón en el título del primer libro y haga clic en Inspeccionar. A continuación, haga clic en Copiar > XPath para copiar su localizador XPath:
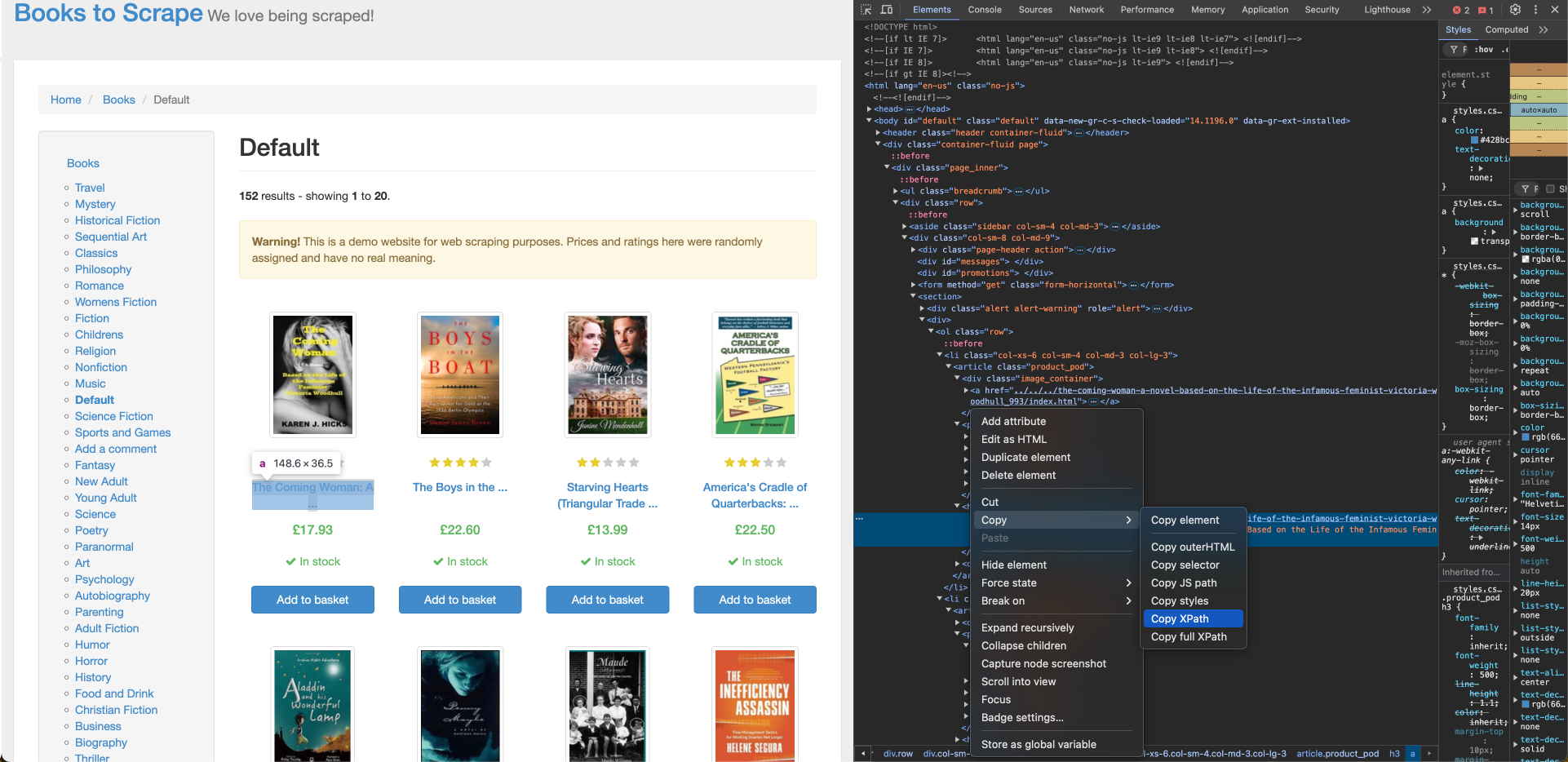
El XPath del título del primer libro corresponde a una etiqueta de anclaje (a) y tiene un aspecto similar a este:
//*[@id="default"]/div/div/div/div/section/div[2]/ol/li[1]/article/h3/a
Debe realizar algunos ajustes en el XPath para garantizar que el título del libro se importe correctamente para todos los libros de la lista:
- El XPath contiene
li[1]en la ruta, lo que indica que se ha seleccionado el primer libro. Reemplácelo porlipara recuperar todos los elementos. - El contenido interno de la etiqueta
acontiene un título de libro truncado, pero la etiquetaacontiene un atributotitlecon el título completo del libro. Modifique laaen el XPath aa/@titlepara utilizar el atributo title. - Reemplace cualquier comilla doble dentro de la ruta XPath por una comilla simple para evitar problemas de escape en la fórmula.
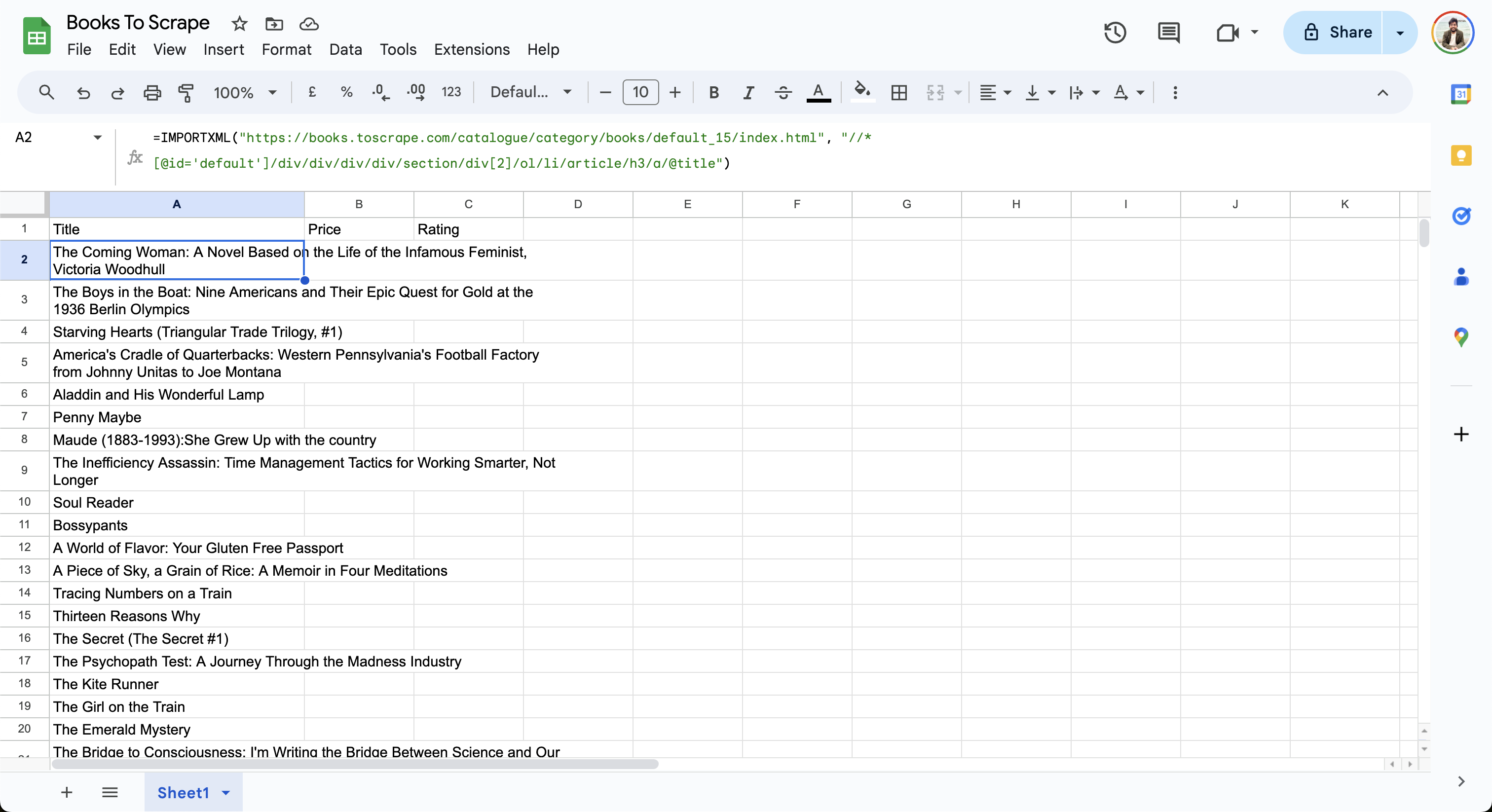
Una vez que haya ajustado el XPath, añada la siguiente fórmula con el XPath actualizado en la celda A2 de su hoja de cálculo de Google:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/h3/a/@title")
La hoja importa datos de la página web y actualiza las filas de la siguiente manera:
A continuación, construya el XPath para el precio y añádalo a la celda B2 de la hoja de cálculo de Google:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/div[2]/p[1]")
Por último, busca la ruta XPath para la valoración y añádela a la celda C2 de la hoja de cálculo de Google:
=IMPORTXML("https://books.toscrape.com/", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/p/@class")
Los datos finales de la hoja tienen este aspecto:
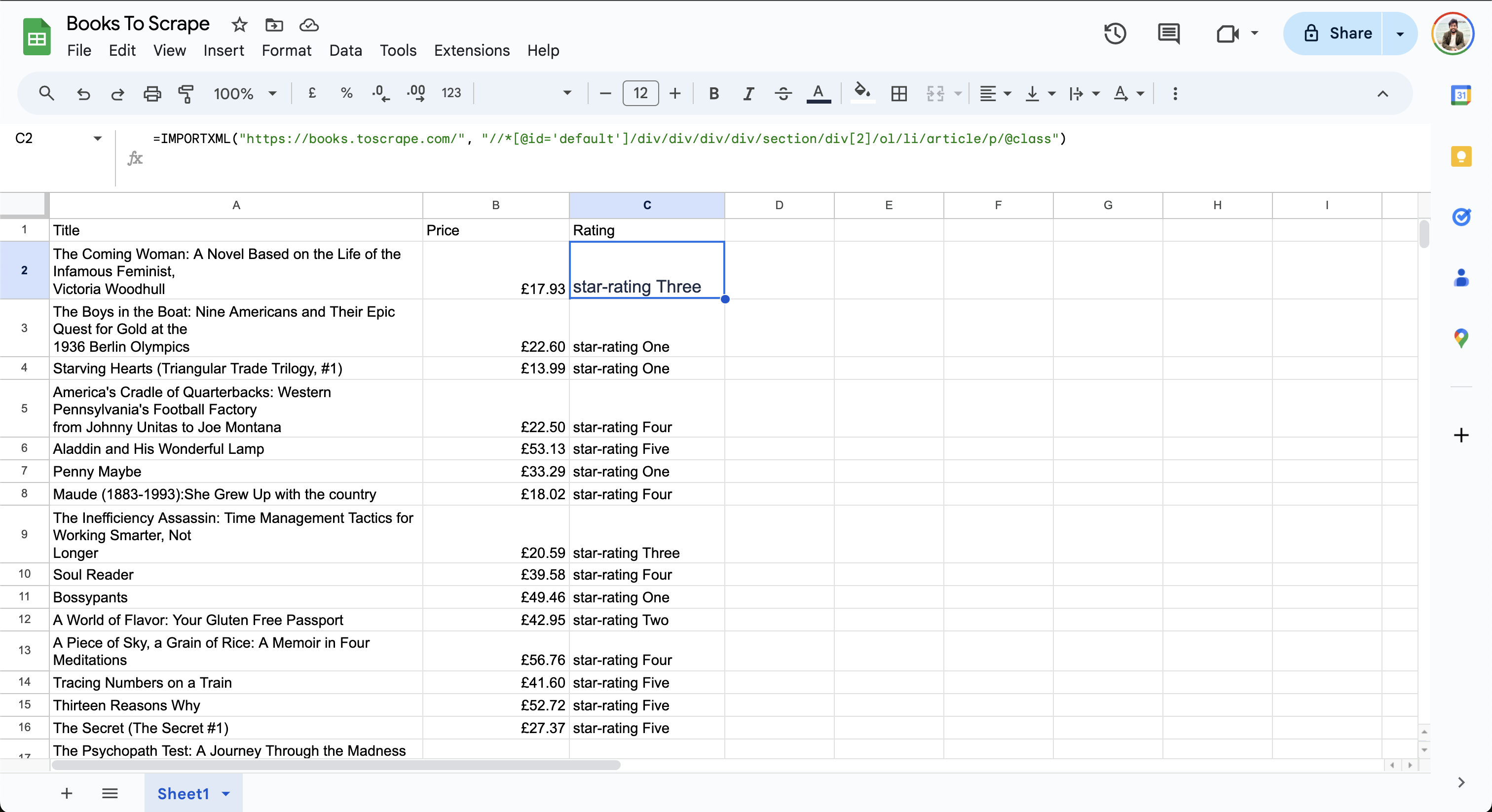
Observe que la columnaCalificaciónmuestrauna calificación de tres estrellasouna calificación de cuatro estrellas. Dado que Google Sheets aún no es compatible conXPath 2.0, no se pueden manipular los datos para simplificar el resultado.
Manejo de páginas web complejas
Aunque Google Sheets es muy adecuado para tareas de scraping sencillas, el scraping puede resultar complicado si el sitio web de destino contiene contenido dinámico y paginación o si requiere interacciones de clic. Por ejemplo, si su página web carga contenido de forma asíncrona utilizando JavaScript, las fórmulasIMPORTXMLeIMPORTHTMLde Google Sheets no pueden extraer datos de ella, ya que solo admiten páginas web estáticas. Del mismo modo, si el contenido depende de interacciones del usuario como hacer clic, escribir o desplazarse, estas fórmulas no podrán extraer los datos. Si desea extraer contenido dinámico, puede escribir un script que utilice un navegador sin interfaz gráfica como Selenium.
Google Sheets tampoco puede gestionar automáticamente las tareas de extracción paginadas. Aunque puede añadir manualmente la fórmula IMPORTXML después de la última fila con una URL actualizada, este método no es escalable, ya que requiere repetir el proceso para cada página.
Si busca casos de uso más avanzados, como el manejo de contenido dinámico o grandes volúmenes de datos, considere el uso de los productos de Bright Data para una extracción de datos eficiente. Bright Data proporciona una API de Scraping web unificada para cualquier tarea de extracción de datos y maneja las complejidades de los Proxies, los CAPTCHA y los agentes de usuario bajo el capó. Su API maneja solicitudes masivas, Parseo y validación, lo que le permite implementar y escalar más rápidamente. Además, proporciona una gran colección de Conjuntos de datos preconstruidosde sitios web populares, comoLinkedInyZillow, que se pueden integrar con sus flujos de trabajo existentes, lo que reduce la molestia de mantener los scripts de scraping.
Automatización de la actualización de datos en Google Sheets
Para algunas tareas de scraping, como el seguimiento de precios o de la interacción en redes sociales, es necesario actualizar automáticamente los datos extraídos a intervalos periódicos para garantizar el acceso a datos precisos para el análisis y la toma de decisiones.
Para establecer el intervalo de cálculo en Google Sheets, solo tienes que hacer clic en Archivo > Configuración y navegar hasta la pestaña Cálculo:
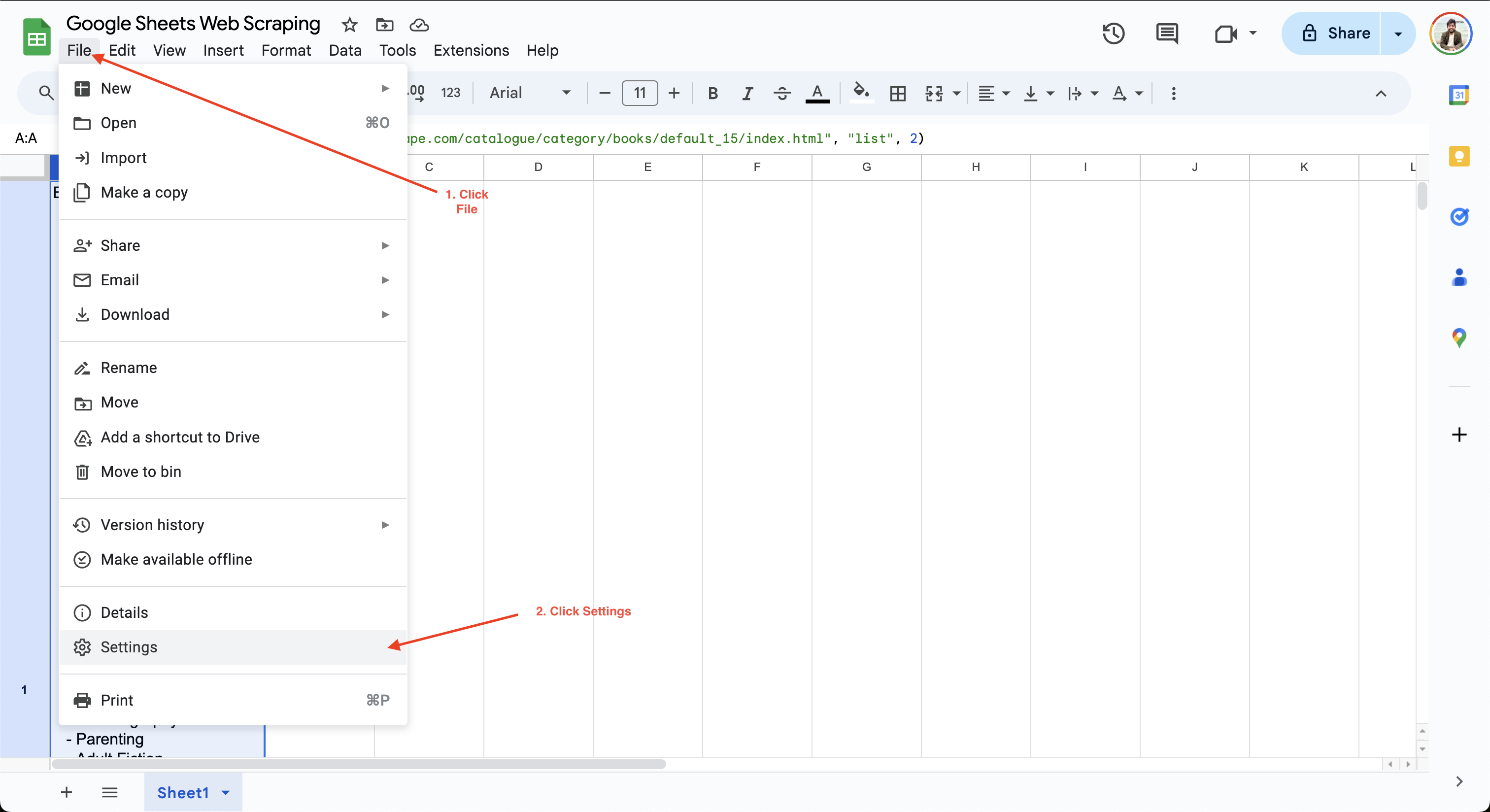
A continuación, puede actualizar el intervalo de cálculo a un minuto o una hora. Por ejemplo, aquí, la configuración de Recálculo se actualiza a Al cambiar y cada minuto para garantizar que los datos se actualicen automáticamente cada minuto:
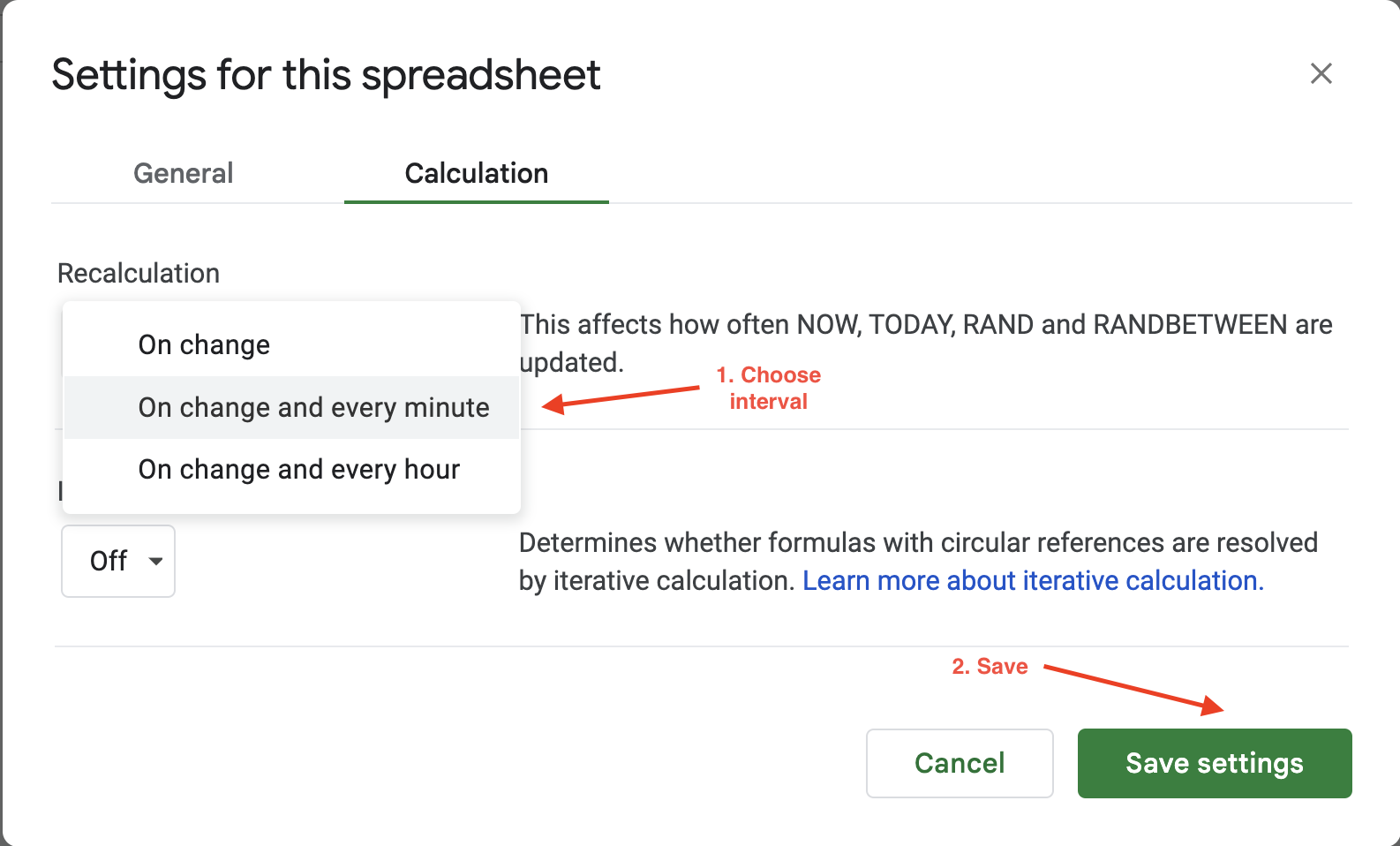
Las opciones de actualización automática de Google Sheets ofrecen una flexibilidad limitada para configurar la frecuencia de actualización o los desencadenantes, ya que solo se puede elegir entre dos valores: cada hora o cada minuto. Si busca más flexibilidad, Bright Data ofrece conjuntos de datos limpios, validados y actualizados en múltiples formatos de archivo, como JSON, CSV y Parquet. Por lo tanto, es ideal para tareas de scraping a gran escala que, de otro modo, requerirían el mantenimiento de una vasta infraestructura.
Implementación de las mejores prácticas y resolución de problemas
Si quieres mejorar la eficiencia de tu scraping, asegúrate de ser selectivo con los datos que extraes. Intentar extraer datos innecesarios puede ralentizar tu proceso y aumentar la carga en el sitio web de destino.
Si desea extraer grandes volúmenes de datos, añada retrasos artificiales entre las solicitudes y considere la posibilidad de ejecutar las tareas en horas de menor actividad para garantizar que el sitio web no se sobrecargue con tráfico inesperado. Los altos volúmenes de tráfico pueden dar lugar a prohibiciones de IP o limitaciones de velocidad, lo que le impedirá continuar con su tarea de extracción. Obtenga más información sobre cómo extraer datos de sitios web sin ser bloqueado.
Además de las prohibiciones de IP, presentar a los usuarios undesafío CAPTCHAes otra técnica anti-bot común utilizada por los sitios web para restringir el acceso al contenido hasta que el usuario verifique que es humano. Considere la posibilidad de utilizar losProxies residenciales de Bright Datapara tareas de extracción avanzadas que se beneficiarían de la rotación de IP y los solucionadores automáticos de CAPTCHA.
Antes de extraer cualquier dato, también debe revisar los términos de servicio del sitio web para garantizar su cumplimiento. Sus scripts deben seguir las instruccionesdel archivo robot.txtpara interactuar con el sitio web. Consulteesta guíapara obtener más información sobre cómo utilizar las reglasdel archivo robot.txtpara el Scraping web.
Conclusión
Google Sheets es muy adecuado para extraer datos de sitios web estáticos que no incluyen contenido dinámico, elementos ocultos o paginación. En este artículo, ha aprendido a automatizar fácilmente las tareas de extracción de datos utilizando las fórmulas IMPORTXML e IMPORTHTML sin necesidad de tener experiencia previa en scripting.
Para tareas de scraping complejas que implican contenido dinámico o grandes volúmenes de datos,Bright Dataproporciona API fáciles de usar, flexibles, escalables y de alto rendimiento para extraer datos web en diferentes formatos, incluidos JSON, CSV o NDJSON. En segundo plano, se encarga de las complejidades del scraping ocupándose de la rotación de IP y agentes de usuario, CAPTCHAs y contenido dinámico. Si está listo para llevar su Scraping web al siguiente nivel, considere probar la mejor API de Scraper.
¡Regístrese hoy mismo para obtener una prueba gratuita y comience a optimizar sus flujos de trabajo de datos!





