

Conseguir que un canal de datos de productos de Amazon funcione en tu ordenador portátil es una cosa. Mantenerlo en funcionamiento en producción, con Proxies, CAPTCHAs, cambios de diseño y bloqueos de IP, es otra muy distinta. Incluso si resuelves el problema del scraping en sí, aún necesitas programación, reintentos, gestión de errores y una forma de ver realmente lo que has recopilado.
Aquí construiremos todo eso. Utilizaremos la API de Scraping web de Bright Data y Mage IA para conectar un canal que recopile productos y reseñas de Amazon, ejecute el análisis de sentimientos de Gemini y envíe todo a PostgreSQL y a un panel de control de Streamlit. El canal completo funciona con Docker y una única clave API (más una clave Gemini opcional para el análisis de IA).
TL;DR: Inteligencia de productos de Amazon sin necesidad de crear una infraestructura de scraping.
- Lo que obtienes: un canal que descubre productos por palabra clave, analiza reseñas con IA Gemini y ofrece un panel de control Streamlit en tiempo real.
- Cuánto cuesta: pago por uso, facturado por registro (página de precios), 5-8 minutos de principio a fin.
- Cómo funciona: Bright Data se encarga de los Proxies, los CAPTCHA y el Parseo; Mage IA se encarga de la programación, los reintentos y las ramificaciones.
- Cómo empezar:
docker compose up; todo el código en el repositorio de GitHub.
Qué estamos creando: un canal de integración de Bright Data + IA.
La API de scraping web de Bright Data se encarga de la capa de scraping. Envías una palabra clave o la URL de un producto y obtienes un JSON estructurado (títulos, precios, valoraciones, reseñas, información del vendedor), ya analizado. No hay que gestionar ninguna infraestructura de Proxy ni analizar ningún HTML. Cuando Amazon cambia su sitio web, Bright Data suele actualizar sus analizadores. Tu código sigue siendo el mismo.
Si no has utilizado Mage IA antes, se trata de una herramienta de canalización de datos gratuita y de código abierto, similar a Airflow, pero sin la plantilla. Escribes Python en un editor tipo cuaderno, donde cada bloque es una unidad reutilizable con su propia prueba y vista previa de salida. Lo importante aquí: Mage IA admite canalizaciones ramificadas, básicamente un DAG (grafo acíclico dirigido) con rutas paralelas. También tiene una lógica de reintento integrada por bloque y variables de canalización que puedes cambiar desde la interfaz de usuario, sin necesidad de editar el código.
El canal tiene 6 bloques en dos ramas paralelas:
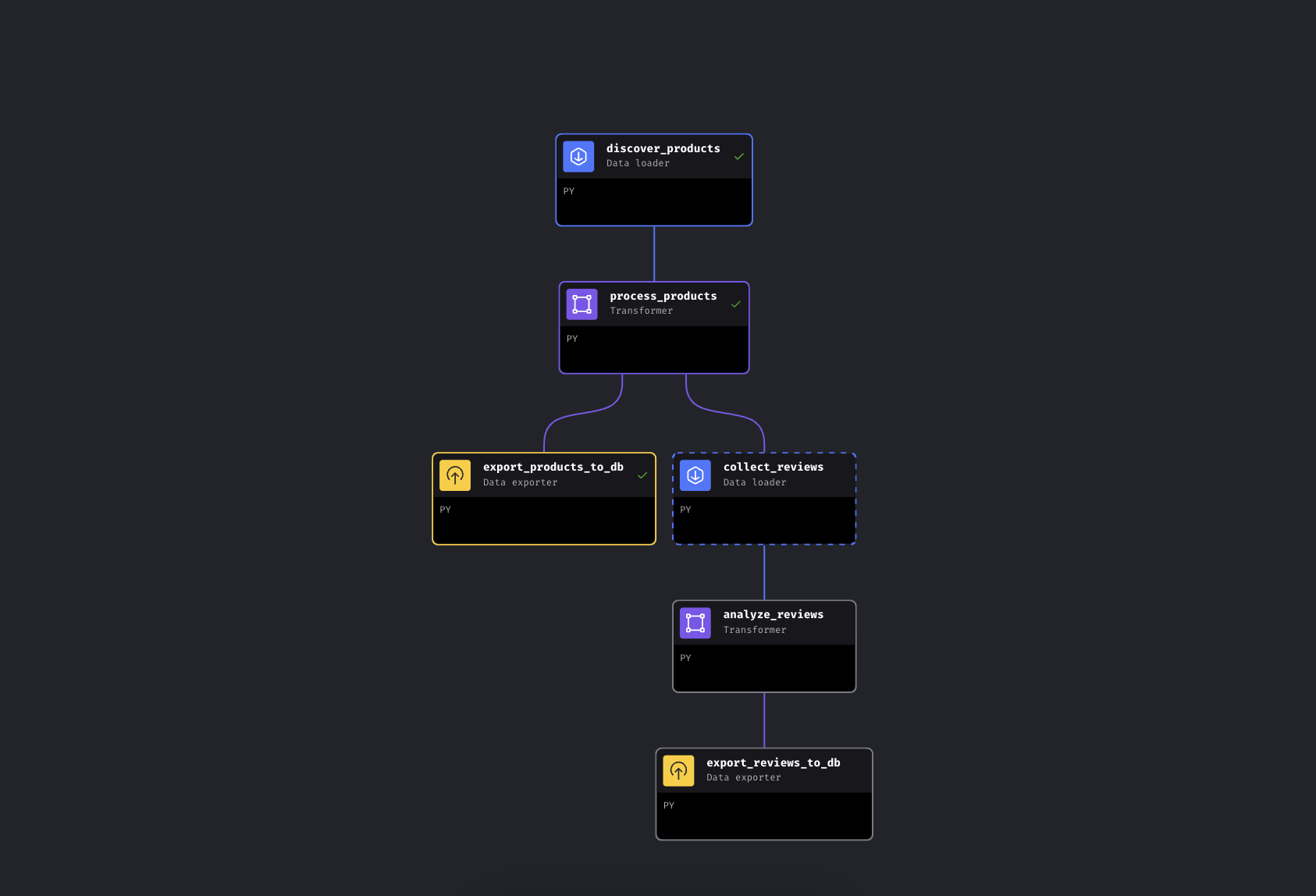
El pipeline ramificado en Mage IA. La rama izquierda exporta los productos inmediatamente, la rama derecha recopila y analiza las reseñas
El canal descubre productos por palabra clave a través de Bright Data, los enriquece con niveles de precios y valoraciones, y luego se ramifica. Una ruta exporta los productos a PostgreSQL inmediatamente, mientras que la otra recopila reseñas de los productos más vendidos, las procesa a través de Gemini para realizar un análisis de opiniones y también las exporta.
Aquí utilizamos Mage AI porque el proceso se ramifica (es un DAG, no un script lineal; si falla la recopilación de reseñas, los datos de tus productos ya están a salvo), pero las llamadas a la API de Bright Data son solo solicitudes HTTP. Funcionan de la misma manera en Airflow, Prefect, Dagster o un script Python sencillo.
Inicio rápido
Clona el repositorio, añade tus claves API y ejecútalo. Todo se ejecuta en Docker, por lo que no es necesario tener Python instalado localmente.
Requisitos
Necesitarás:
- Docker y Docker Compose (obtener Docker)
- Una cuenta de Bright Data con token API
- Una clave API de Google Gemini (nivel gratuito disponible con límites; consulta la sección Gemini más abajo)
- Conocimientos básicos de Python y Docker. No se necesita experiencia en scraping; esa es la idea
Paso 1: clonar y configurar
Clona el repositorio y crea tu archivo de configuración:
git clone https://github.com/triposat/mage-brightdata-demo.git
cd mage-brightdata-demo
cp .env.example .envAhora añade tus claves API a .env:
BRIGHT_DATA_API_TOKEN=tu_api_token_aquí
GEMINI_API_KEY=tu_gemini_api_key_aquíObtener tu token API de Bright Data: Regístrate en [Bright Data]() (prueba gratuita, no se requiere tarjeta de crédito), luego ve a Configuración de la cuenta y crea una clave API. El canal utiliza dos Scrapers de API de Scraping web (uno para el descubrimiento de productos y otro para las reseñas), que se facturan por registro y se pagan según el uso. Consulta la página de precios para conocer las tarifas actuales.
Cómo obtener su clave API de Gemini: vaya a Google AI Studio, inicie sesión y haga clic en Crear clave API. Nivel gratuito, no se requiere tarjeta de crédito. El canal también funciona sin ella; recurre a la valoración basada en opiniones.
Paso 2: iniciar los servicios
docker compose up -dSi desea comprobar que sus claves están cargadas:
docker compose exec mage python -c "import os; t=os.getenv('BRIGHT_DATA_API_TOKEN',''); assert t and t!='your_api_token_here', 'Token not set'; print('OK')"Esto activa tres contenedores:
| Servicio | URL | Finalidad |
|---|---|---|
| Mage IA | http://localhost:6789 |
Editor y programador de procesos |
| Panel de control Streamlit | http://localhost:8501 |
Visualización de datos en tiempo real + chat |
| PostgreSQL | localhost:5432 |
Almacenamiento de datos |
La primera ejecución extrae imágenes e instala dependencias, lo que tarda entre 3 y 5 minutos, dependiendo de su conexión. El reinicio con docker compose stop/start tarda unos segundos; docker compose down/up reinstala los paquetes pip y tarda aproximadamente un minuto.
Los tres servicios en ejecución
Paso 3: ejecutar el proceso
Abra http://localhost:6789, vaya a Pipelines, haga clic en amazon_product_intelligence, luego haga clic en Triggers en la barra lateral izquierda y pulse Run@once.
El panel de control de IA de Mage
El proceso tarda entre 5 y 8 minutos en completarse. La mayor parte de ese tiempo lo dedican las API de Bright Data a recopilar datos de Amazon; el enriquecimiento y las exportaciones de la base de datos tardan unos segundos, y el análisis de Gemini depende del tamaño del lote y de los límites de velocidad. Cuando los 6 bloques se vuelvan verdes, abra http://localhost:8501 para ver el panel de control.
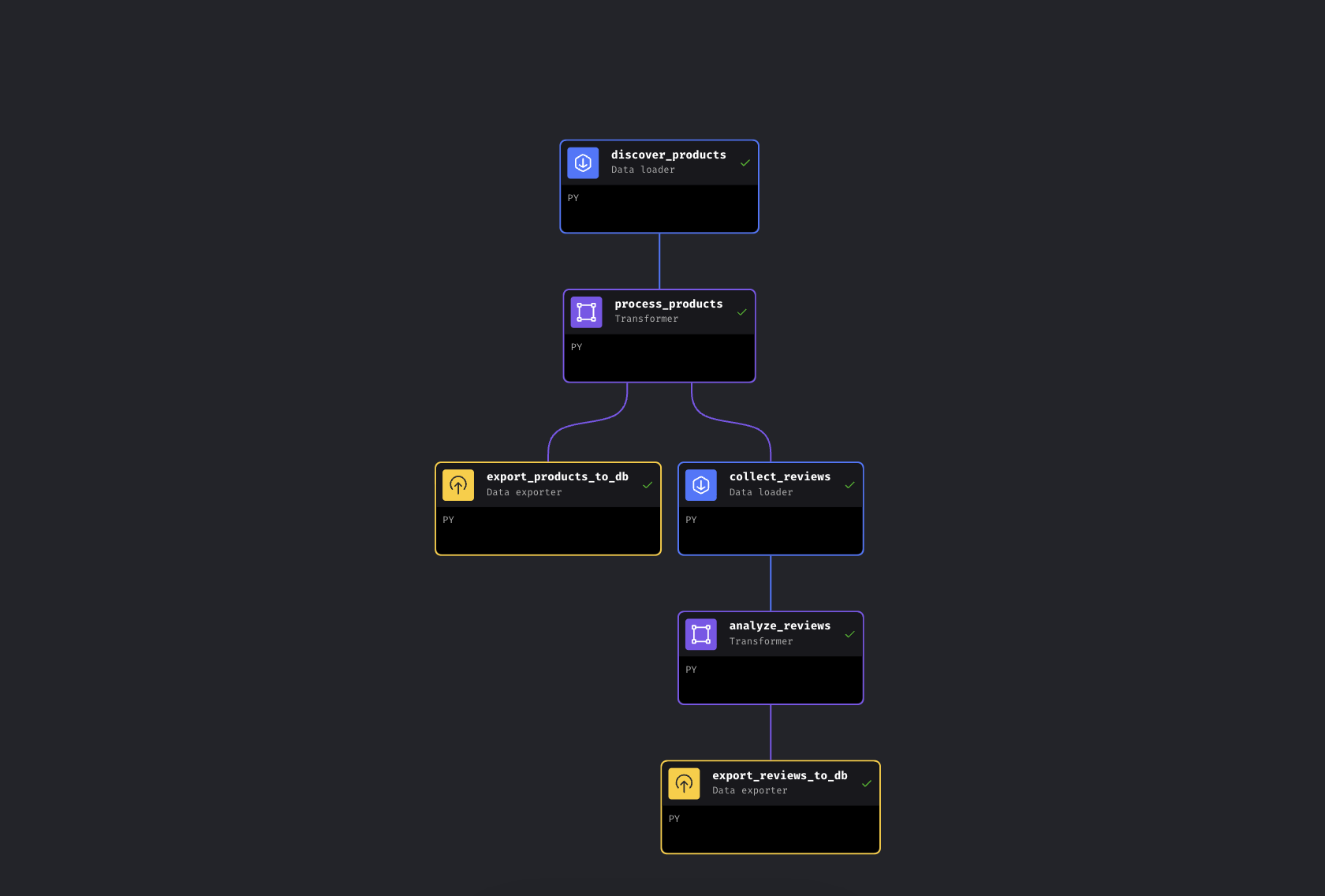
Los 6 bloques están en verde. Canalización completada
Cómo funciona el proceso de datos de Mage IA
Repasemos el código. Nos centraremos en las integraciones de Bright Data y el análisis de Gemini.
Conexión de la API de Scraping web de Bright Data a Mage IA
Enviamos palabras clave a la API de productos de Amazon y obtenemos datos estructurados. Bright Data lo denomina «Scraper de descubrimiento»: encuentra productos por palabra clave o categoría. El bloque de reseñas utiliza posteriormente un Scraper de reseñas independiente, que toma las URL de los productos como entrada. La API utiliza un patrón asíncrono: activa la recopilación, obtiene un ID de instantánea y realiza sondeos hasta que los resultados están listos.
DATASET_ID = "gd_l7q7dkf244hwjntr0" # Amazon Products (consulte el repositorio para ver los ID actuales)
API_BASE = "https://api.brightdata.com/conjuntos_de_datos/v3"
# Activa la recopilación (utiliza /scrape; cambia automáticamente a asíncrono si es >1 min; para producción, considera /trigger)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": DATASET_ID,
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": kwargs.get('limit_per_keyword', 5)},
json={"input": [{"keyword": kw} for kw in keywords]})
snapshot_id = response.json()["snapshot_id"]
# Sondear hasta que los resultados estén listos
data = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers={"Authorization": f"Bearer {api_token}"},
params={"format": "json"}
).json()Esto es lo que devuelve Bright Data:
{
"title": "BESIGN LS03 Aluminum Laptop Stand",
"asin": "B07YFY5MM8", // ID único del producto de Amazon
"url": "https://www.amazon.com/dp/B07YFY5MM8",
"initial_price": 19.99,
"final_price": 16.99,
"currency": "USD",
"rating": 4.8,
«reviews_count»: 22776,
«seller_name»: «BESIGN»,
«categories»: [«Productos de oficina», «Material de oficina y escolar»],
«image_url»: «https://m.media-amazon.com/images/I/...»
}El kwargs.get('limit_per_keyword', 5) extrae datos de las variables del canal IA, por lo que puede ajustarlo desde la interfaz de usuario.
Añadir una segunda llamada a la API: recopilación de reseñas de Amazon
El recopilador de reseñas toma los productos procesados del bloque ascendente y los ordena por número de reseñas. Selecciona los N primeros y envía sus URL de Amazon a una segunda API de Bright Data:
REVIEWS_DATASET_ID = "gd_le8e811kzy4ggddlq" # Reseñas de Amazon
# Productos más vendidos de upstream (pasados automáticamente por Mage IA)
top_products = data.sort_values('reviews_count', ascending=False).head(top_n)
product_urls = top_products['url'].dropna().tolist()
# Introducir las URL en la API de reseñas (mismo patrón /scrape)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": REVIEWS_DATASET_ID},
json={"input": [{"url": url} for url in product_urls]})
# Mismo patrón de sondeo asíncrono que los productos...Ambos bloques API tienen una configuración de reintento en el archivo metadata.yaml de la demostración: si una llamada falla, el canal lo reintenta tres veces con un retraso de 30 segundos. Cada bloque de esta demostración también tiene una función @test que se ejecuta después de la ejecución. Si falla, los bloques posteriores no se ejecutan, por lo que los datos erróneos no terminan en su base de datos.
Añadir análisis de IA: bloque de canalización de opiniones Gemini
En lugar de la coincidencia de palabras clave (que marcaría «¡no es barato, gran calidad!» como negativo debido a la palabra «barato»), utilizamos Gemini para comprender el contexto. El bloque procesa las reseñas por lotes con una rotación de 3 modelos para mantenerse dentro de los límites del nivel gratuito:
GEMINI_MODELS = ["gemini-2.5-flash-lite", "gemini-2.5-flash", "gemini-2.5-pro"] # comprueba el repositorio para ver los modelos actuales
prompt = f"""Analiza estas reseñas. Para CADA UNA, devuelve JSON con:
- «sentiment»: «Positivo», «Neutro» o «Negativo»
- «issues»: problemas específicos del producto mencionados
- «themes»: 1-3 etiquetas temáticas
- «summary»: resumen de una frase
Devuelve SOLO JSON.nn{reviews_text}"""
for model in models:
try:
response = client.models.generate_content(model=model, contents=prompt)
return json.loads(response.text.strip())
except Exception as e:
if '429' in str(e):
continue # Tasa limitada: pasar al siguiente modeloLa rotación comienza con flash-lite (el más barato y rápido), pasa a flash y luego a pro. Si se agotan los tres, la reseña obtiene una valoración basada en la opinión. Las cuotas de la tarifa gratuita cambian periódicamente, pero la rotación de tres modelos gestiona automáticamente la mayoría de los límites de velocidad. Gemini devuelve la valoración, problemas específicos (como «se tambalea en superficies irregulares» o «la bisagra se afloja con el tiempo») y entre 1 y 3 etiquetas temáticas por reseña. Cada reseña también incluye un resumen de una frase.
Los bloques restantes (un transformador para los niveles de precios y los cálculos de descuentos, y dos exportadores de bases de datos con lógica upsert) son sencillos. Se encuentran en el repositorio de GitHub, por si quieres profundizar en ellos.
Resultado del proceso: resultados y panel de control de Streamlit
Esto es lo que produjo el proceso en una ejecución con las palabras clave predeterminadas: «soporte para ordenador portátil» y «auriculares inalámbricos». Los resultados variarán en función de los listados actuales de Amazon.
En esta ejecución: 10 productos descubiertos, 20 reseñas analizadas por Gemini. Las reseñas de los auriculares revelaron quejas que no aparecen en la media de 4,3 estrellas, como «calidad del sonido», «duración de la batería» y «conectividad», con problemas específicos asociados.
Lo que el proceso añade a sus datos sin procesar:
| Campo | Ejemplo | Añadido por |
|---|---|---|
best_price |
16,99 | Transformador (calculado) |
discount_percent |
15 | Transformador (calculado) |
nivel_de_precio |
Presupuesto (<25 $) | Transformador (enriquecido) |
Categoría de calificación |
Excelente (4,5-5) | Transformador (enriquecido) |
sentimiento |
Negativo | Gemini IA |
problemas |
«El Bluetooth pierde la conexión con frecuencia» | Gemini IA |
temas |
[“conectividad”, “duración de la batería”] | Gemini IA |
ai_summary |
«La batería solo dura 2 horas, a pesar de que se afirma que dura 8». | Gemini IA |
Así es como se ve en la práctica: los 10 productos con campos enriquecidos visibles:
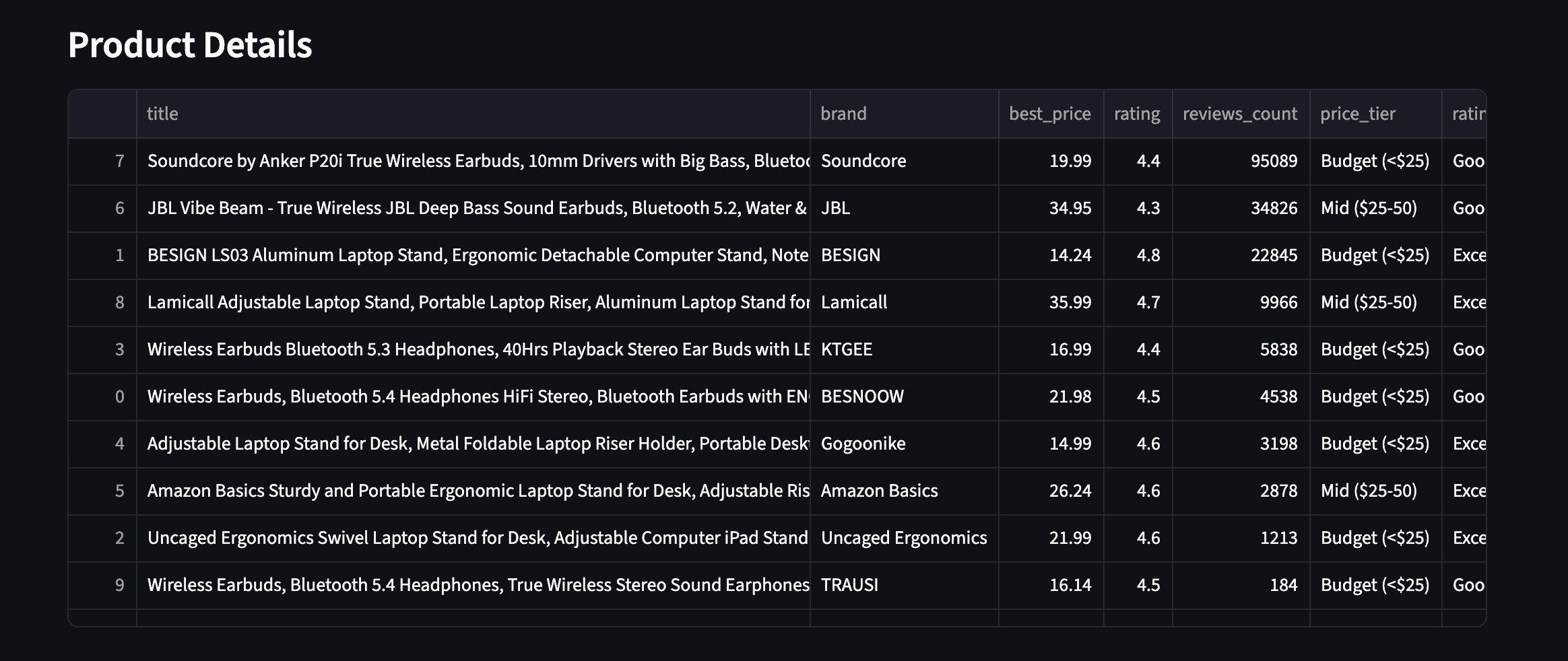
Los 10 productos con campos enriquecidos. Niveles de precios, valoraciones y recuentos de reseñas de dos categorías de productos diferentes
El panel de control
Abre http://localhost:8501 para acceder al panel de control de Streamlit. Haz clic en «Refresh Data» (Actualizar datos ) en la barra lateral para obtener los últimos resultados de PostgreSQL.
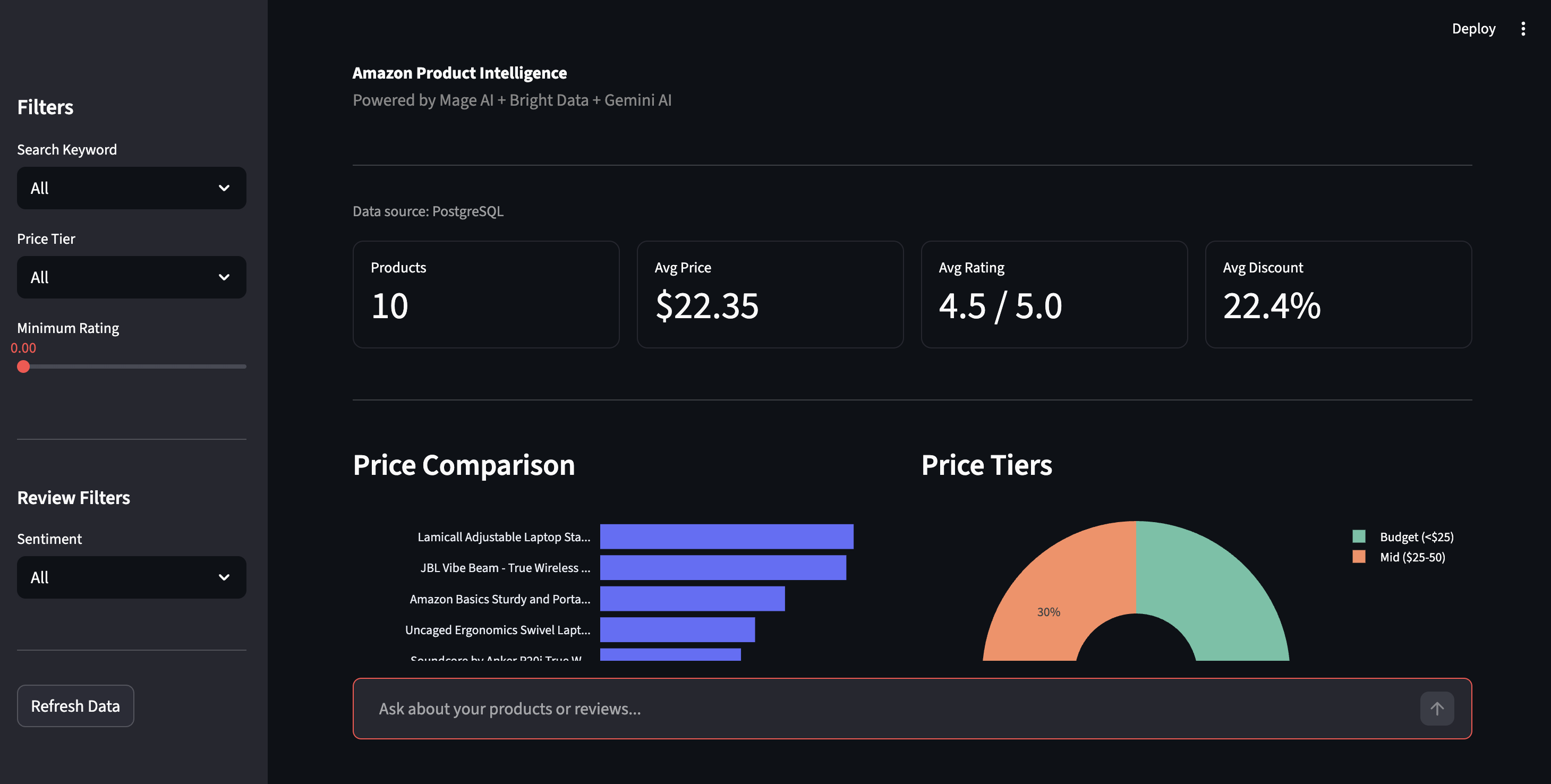
Panel de control de inteligencia de productos: comparación de precios, niveles de precios y controles de filtrado
La barra lateral le permite filtrar por nivel de precios, valoración o opinión. La vista de opiniones muestra el desglose positivo/negativo de todas las reseñas, con los problemas específicos que Gemini ha detectado: «El Bluetooth pierde la conexión», «La bisagra se afloja con el tiempo», el tipo de detalles que las valoraciones con estrellas ocultan.

Desglose de opiniones y problemas del producto detectados por IA. Quejas reales extraídas por Gemini, no coincidencias de palabras clave
El panel de control también cuenta con la función «Chat with Your Data» (Ch atea con tus datos ). Haz preguntas en inglés sencillo y Gemini responderá utilizando tus datos reales recopilados como contexto. Aquí tienes un ejemplo de una ejecución independiente con más productos:
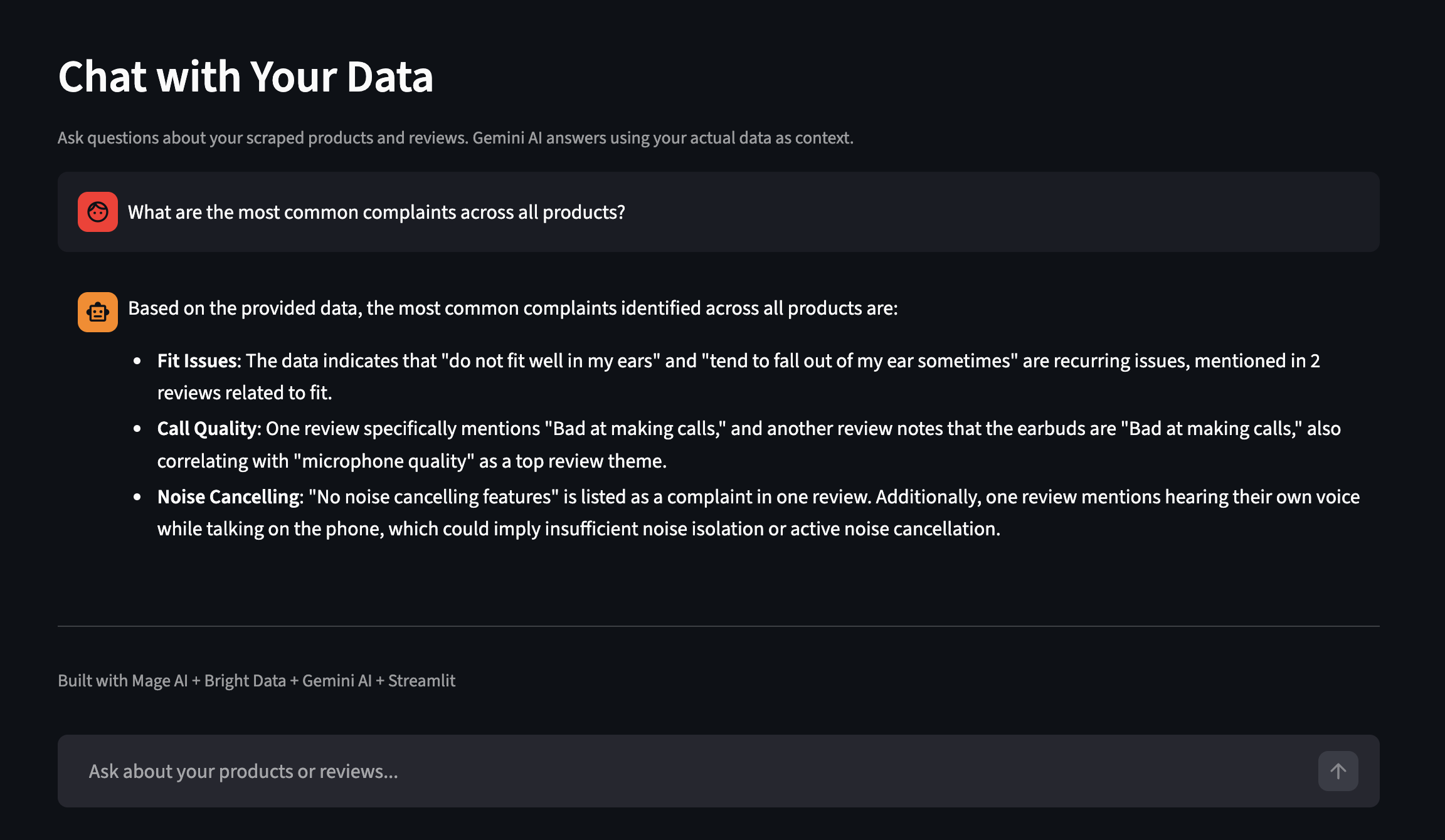
Haga preguntas sobre sus datos recopilados en inglés sencillo
Ampliación del proceso
La demostración se ejecuta con dos palabras clave y 10 productos.
Variables del proceso
Todas configurables desde la interfaz de usuario de IA o metadata.yaml:
| Variable | Qué controla | Predeterminado |
|---|---|---|
palabras clave |
Términos de búsqueda de Amazon | ["soporte para portátil", "auriculares inalámbricos"] |
límite_por_palabra_clave |
Productos por palabra clave de Bright Data | 5 |
top_n_products |
¿Cuántos productos principales obtienen reseñas recopiladas? | 2 |
reviews_per_product |
Máximo de reseñas por producto | 10 |
sort_by |
Cómo clasificar los productos para la selección de reseñas | reviews_count |
Cambia las palabras clave a ["funda para teléfono", "concentrador USB-C"] y obtendrás un conjunto de datos completamente diferente. Sin cambios en el código.
Variables de canalización en la interfaz de usuario de Mage IA
Programación
Para ejecutar esto según una programación, vaya a «Triggers» (Desencadenantes) en la barra lateral de Mage IA, haga clic en «+ New trigger» (Nuevo desencadenante), seleccione «Schedule» (Programación) y elija una frecuencia (una vez, cada hora, cada día, cada semana, cada mes o cron personalizado).
Cada ejecución actualiza por ASIN: sustituye los datos de los mismos productos, pero conserva los resultados de otras palabras clave. También se guarda una copia de seguridad CSV con marca de tiempo para realizar comparaciones históricas.
Una vez que tenga algunas ejecuciones de datos, puede consultar PostgreSQL directamente para detectar las quejas que las valoraciones con estrellas pasan por alto:
-- Buscar productos con un alto sentimiento negativo.
SELECT asin, product_name,
AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) as negative_rate
FROM amazon_reviews
GROUP BY asin, product_name
HAVING AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) > 0.2;Para supervisar sus propios productos en lugar de buscar palabras clave, elimine los parámetros type, discover_by y limit_per_input y pase las URL de sus productos directamente como [{"url": "https://www.amazon.com/dp/YOUR_ASIN"}].
Si necesita paneles de control y alertas sin tener que crearlos usted mismo, Bright Insights lo hace sin necesidad de una configuración adicional para los datos minoristas.
Ampliación. Esta demostración se ejecuta en Docker en una sola máquina, pero Mage IA es compatible con un ejecutor de Kubernetes para la producción, y las API de Bright Data gestionan la concurrencia por su parte (con límites de velocidad para las solicitudes por lotes). La ampliación consiste en añadir capacidad a Mage IA, no en cambiar el código de recopilación de datos.
Integración de otros scrapers de Bright Data
El mismo patrón de canalización funciona con cualquiera de los Scrapers listos para usar de Bright Data para más de 100 sitios web. Por ejemplo, consulte los repositorios Google Maps Scraper, LinkedIn Scraper y Crunchbase Scraper. Para cambiar de Amazon a otra plataforma, intercambie el DATASET_ID en los bloques del cargador de datos y ajuste los parámetros de entrada para que coincidan con el esquema del nuevo Scraper.
Para encontrar el ID y los campos de entrada correctos, explore la biblioteca de Scrapers en su panel de control o llame al punto final /datasets/list: el generador de solicitudes API del panel de control le muestra exactamente lo que espera cada Scraper. El análisis Gemini y la estructura del pipeline se mantienen tal cual; es posible que sea necesario ajustar los nombres de las columnas de los bloques de enriquecimiento y exportación si los campos de respuesta del nuevo Scraper difieren de los de Amazon.
Solución de problemas
Si algo sale mal durante la configuración o la ejecución, estas son las soluciones más comunes:
- El puerto 6789 u 8501 ya está en uso. Otro servicio está ocupando el puerto. Detenga ese servicio o edite
docker-compose.ymlpara reasignar los puertos (por ejemplo, cambie6789:6789por6790:6789). - La API de Bright Data devuelve 401 No autorizado. Falta su token de API o tiene un formato incorrecto. Vaya a Configuración de la cuenta, copie el token completo y asegúrese de que no haya espacios al final en su archivo
.env. El token es una cadena hexadecimal larga (64 caracteres). Si lo que ha copiado es corto o tiene guiones como un UUID, es posible que haya copiado el campo incorrecto. - Gemini devuelve 429 (límite de velocidad) en todos los modelos. El nivel gratuito tiene límites por minuto que cambian periódicamente. La canalización gestiona esto rotando entre tres modelos, pero si los tres se agotan, las reseñas recurren a la valoración basada en la opinión. Para evitarlo: reduce
reviews_per_producten las variables de la canalización, añade untime.sleep(60)entre lotes en el bloque Gemini o habilita la facturación en tu proyecto de IA para obtener cuotas más altas. Consulte la página de límites de velocidad de Google para conocer las cuotas actuales. - Un bloque del proceso aparece en rojo (fallido). Vaya a la página Logs (Registros) de su proceso (accesible desde la barra lateral izquierda) para ver el error. Puede filtrar por nombre de bloque y nivel de registro. Causas comunes: token de API caducado, tiempo de espera de red agotado en la API de Bright Data (aumente
max_wait_secondsen el bloque) o una respuesta de Gemini que no es JSON válida (la función@testdel bloque lo detecta). - Docker Compose es lento o falla en Apple Silicon. La imagen Mage IA es multiarch y funciona en ARM, pero la extracción inicial puede tardar más tiempo. Si la compilación falla con un error de memoria, aumenta la asignación de memoria de Docker Desktop a al menos 4 GB en Configuración → Recursos.
Próximos pasos
Ya tienes un proceso que recopila datos de productos de Amazon, ejecuta análisis de reseñas con IA y almacena todo en PostgreSQL, sin proxies, sin analizadores sintácticos y sin tareas cron que te den miedo tocar.
Si ha seguido los pasos, hágalo suyo. Cambie la lista de palabras clave en metadata.yaml por una categoría de productos diferente, sin necesidad de modificar el código. Para una personalización más profunda, diríjase a ASIN específicos o cambie a un Scraper de Bright Data completamente diferente.
¿Es nuevo aquí? [Comience con una prueba gratuita de Bright Data]() (no se requiere tarjeta de crédito), clone el repositorio de demostración y ejecute docker compose up.
Preguntas frecuentes
Preguntas frecuentes sobre esta configuración:
¿Cómo puedo extraer datos de productos de Amazon con Python?
Puede crear su propio Scraper con requests y BeautifulSoup (que deja de funcionar cuando Amazon cambia los diseños), o utilizar el Scraper de Amazon de Bright Data, que devuelve JSON estructurado desde una única llamada a la API. Para ver un ejemplo independiente en Python, consulte el repositorio Amazon Scraper. Para obtener más información, consulte la guía completa de Bright Data sobre el scraping de Amazon.
¿Cuánto cuesta extraer datos de Amazon con Bright Data?
La API de Scraping web utiliza un sistema de pago por uso, que se factura por cada 1000 registros recopilados. El nivel gratuito de Gemini cubre el análisis de IA. Las cuentas nuevas obtienen una prueba gratuita. Consulte la página de precios para conocer las tarifas actuales.
¿Puedo extraer datos de Walmart, eBay u otros sitios de comercio electrónico con este proceso?
Cambie el DATASET_ID en los bloques del cargador de datos y ajuste los parámetros de entrada para que coincidan con el nuevo esquema del Scraper. El análisis de Gemini y la estructura del canal se mantienen; es posible que sea necesario modificar los nombres de las columnas en los bloques de enriquecimiento y exportación.
¿Qué ocurre cuando Amazon cambia el diseño de su página?
Nada por su parte. Bright Data mantiene los analizadores, por lo que cuando Amazon actualiza su HTML, sus llamadas a la API y el formato de respuesta suelen permanecer igual.
¿Necesito Gemini o puedo utilizar otro LLM?
El pipeline funciona sin Gemini; recurre al sentimiento basado en la calificación. Para cambiar a un LLM diferente (OpenAI, Claude, Llama), modifique la función analyze_reviews en el bloque Gemini. El formato del prompt sigue siendo el mismo; solo hay que cambiar la llamada a la API.






