

En esta guía de raspado web de Goutte, aprenderá:
- Qué es la biblioteca PHP Goutte
- Cómo utilizarlo para el web scraping en un tutorial paso a paso
- Alternativas a Goutte para el web scraping
- Limitaciones de este enfoque y posibles soluciones
Sumerjámonos.
¿Qué es la gota?
Goutte es una librería PHP para screen scraping y web crawling, que ofrece una API intuitiva para navegar por sitios web y extraer datos de respuestas HTML/XML. Incluye un cliente HTTP integrado y capacidades de análisis de HTML, lo que le permite recuperar páginas web a través de peticiones HTTP y procesarlas para el raspado de datos.
Nota: Desde el 1 de abril de 2023, Goutte ya no se mantiene y se considera obsoleto. Sin embargo, en el momento de escribir este artículo, todavía funciona de forma fiable.
Cómo realizar Web Scraping con Goutte: Guía paso a paso
Siga este tutorial paso a paso y vea cómo utilizar Goutte para extraer datos del sitio “Equipos de Hockey“:
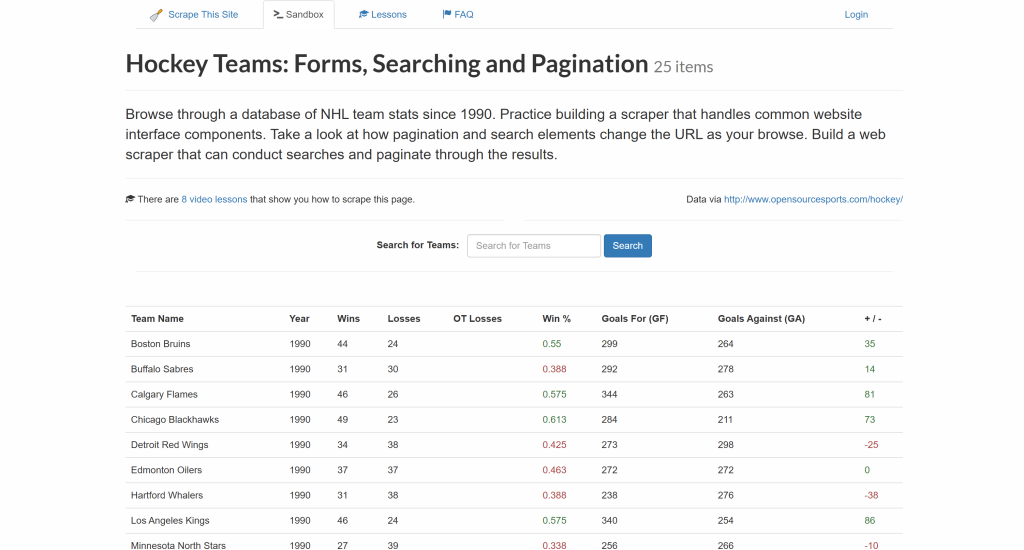
El objetivo es extraer los datos de la tabla anterior y exportarlos a un archivo CSV.
¡Es hora de aprender a hacer web scraping con Goutte!
Paso nº 1: Configuración del proyecto
Antes de empezar, asegúrese de que su sistema cumple los requisitos de Goutte: PHP7.1 o superior. Para comprobar la versión actual de PHP, ejecute el siguiente comando:
php -vEl resultado debería ser algo parecido a esto:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend TechnologiesSi su versión de PHP es inferior a la 7.1, deberá actualizar PHP antes de continuar.
A continuación, ten en cuenta que Goutte se instalará a través de Composer, un gestor de dependencias para PHP. Si Composer no está instalado en tu sistema, descárgalo desde el sitio oficial y sigue las instrucciones de instalación.
Ahora, crea un nuevo directorio para tu proyecto Goutte y navega hasta él en el terminal:
mkdir goutte-parser
cd goutte-parserA continuación, utilice el comando composer init para inicializar un proyecto Composer dentro de la carpeta:
composer initComposer le pedirá que introduzca los detalles del proyecto, como el nombre del paquete y la descripción. Las respuestas predeterminadas funcionarán, pero no dudes en personalizarlas según tus objetivos.
Ahora, abre la carpeta del proyecto en tu IDE de PHP favorito. Visual Studio Code con la extensión PHP o IntelliJ WebStorm son buenas opciones.
Crear un archivo index.php vacío en la carpeta del proyecto, que debe contener:
php-html-parser/
├── vendor/
├── composer.json
└── index.phpAbre index.php y añade la siguiente línea de código para importar las librerías de Composer:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...Este archivo contendrá en breve la lógica de raspado de Goutte.
Ahora puede ejecutar su script utilizando este comando:
php index.phpMuy bien. Ya está todo listo para empezar a raspar datos con Goutte en PHP.
Paso 2: Instalar y configurar Goutte
Instala Goutte con el comando Compose que aparece a continuación:
composer require fabpot/goutteEsto añadirá la dependencia fabpot/goutte a tu archivo composer.json, que ahora incluirá:
"require": {
"fabpot/goutte": "^4.0"
}En index.php, importe Goutte añadiendo la siguiente línea de código:
use GoutteClient;Esto expone el cliente HTTP de Goutte que puedes utilizar para conectarte a una página de destino, analizar su HTML y extraer datos de ella. Verás cómo hacerlo en el siguiente paso.
Paso 3: Obtener el HTML de la página de destino
En primer lugar, cree un nuevo cliente HTTP Goutte:
$client = new Client();Entre bastidores, la clase Client de Goutte es simplemente una envoltura alrededor del componente BrowserKitHttpBrowser de Symfony. Míralo en acción en nuestra guía sobre web scraping con Laravel.
A continuación, almacena la URL de la página web de destino en una variable y utiliza el método request() para obtener su contenido:
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);Esto envía una petición GET a la página web, recupera su documento HTML, y lo analiza por ti. En concreto, el objeto $crawler proporciona acceso a todos los métodos del componente DomCrawler de Symfony. $crawler es el objeto que utilizarás para navegar y extraer datos de la página.
¡Increíble! Ya tienes todo lo que necesitas para el web scraping de Goutte.
Paso 4: Preparar el raspado de los datos de interés
Antes de extraer los datos, debe familiarizarse con la estructura HTML de la página de destino.
En primer lugar, recuerde que los datos de interés se presentan en filas dentro de una tabla. Dado que esa tabla contiene múltiples filas, un array es una gran estructura de datos donde almacenar los datos raspados:
$teams = [];Ahora, céntrese en la estructura HTML de la tabla. Visite la página de destino en su navegador, haga clic con el botón derecho en la tabla que contiene los datos de interés y seleccione la opción “Inspeccionar”:
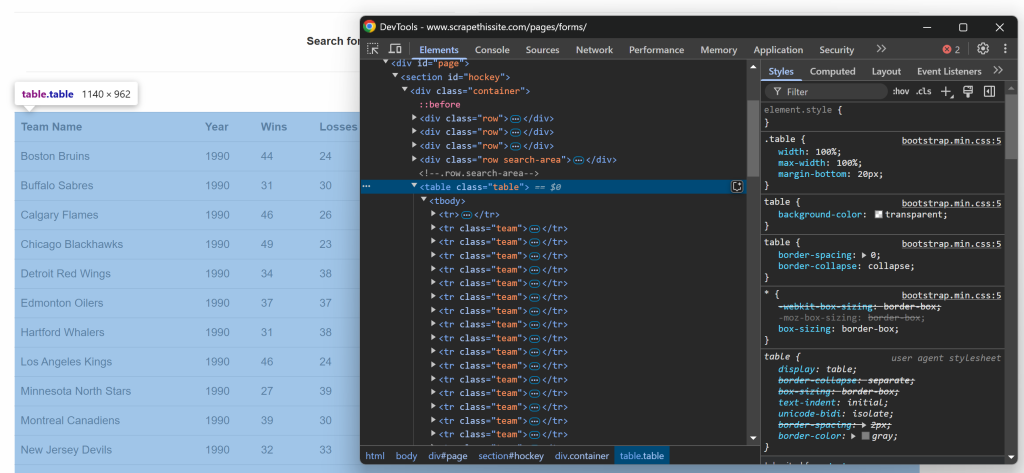
En las DevTools, verás que la tabla tiene una clase table y está contenida dentro de un elemento
id=``"``hockey``". Esto significa que puede apuntar a la tabla utilizando el siguiente selector CSS:
#hockey .tableAplica el selector CSS para seleccionar el nodo de la tabla usando el método $crawler->filter():
$table = $crawler->filter("#hockey .table");A continuación, observe que cada fila está representada por un elemento
equipo. Selecciona todas las filas e itera sobre ellas, preparándote para extraer datos de ellas:
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic...
});Estupendo. Ahora tiene un esqueleto listo para el raspado de datos de Goutte.
Paso 5: Implementar la lógica de extracción de datos
Al igual que antes, esta vez inspeccione las filas dentro de la tabla:
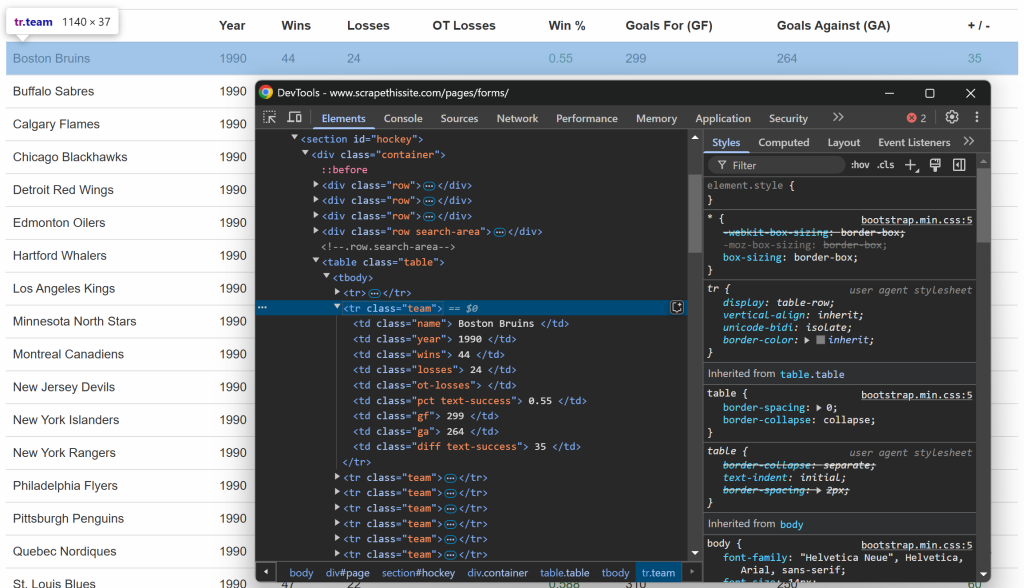
Lo que puede observar es que cada fila contiene la siguiente información en columnas específicas:
- Nombre del equipo → dentro del elemento
.name - Año de temporada → dentro del elemento
.year - Número de victorias → dentro del elemento
.wins - Número de pérdidas → dentro del elemento
.losses - Pérdidas en tiempo extra → dentro del elemento
.ot-losses - Porcentaje de victorias → dentro del elemento
.pct - Goles marcados (Goals For – GF) → dentro del elemento
.gf - Goles encajados (Goles en contra – GA) → dentro del elemento
.ga - Diferencia de goles → dentro del elemento
.diff
Para recuperar una única información, hay que aplicar estos dos pasos:
- Seleccionar el elemento HTML mediante
filter() - Extrae su contenido textual mediante el método
text()y elimina los espacios sobrantes contrim()
Por ejemplo, puedes raspar el nombre del equipo con:
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());Del mismo modo, extienda esta lógica a todas las demás columnas:
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());Una vez que haya extraído los datos de interés de la fila, almacénelos en la matriz $teams:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];Después de recorrer todas las filas, la matriz $teams contendrá:
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[wins] => 36
[losses] => 29
[ot_losses] =>
[win_perc] => 0.45
[goals_for] => 257
[goals_against] => 236
[goal_diff] => 21
)
)¡Fantástico! Goutte data scraping realizado con éxito.
Paso 6: Implementar la lógica de rastreo
No olvide que el sitio de destino presenta los datos en varias páginas, mostrando sólo una parte cada vez. Debajo de la tabla, hay un elemento de paginación que proporciona enlaces a todas las páginas:

Así, puede gestionar la paginación en su script de scraping con estos sencillos pasos:
- Seleccione los elementos del enlace de paginación
- Extraer las URL de las páginas paginadas
- Visite cada página y aplique la lógica de raspado ideada anteriormente
Empiece por inspeccionar los elementos del enlace de paginación:
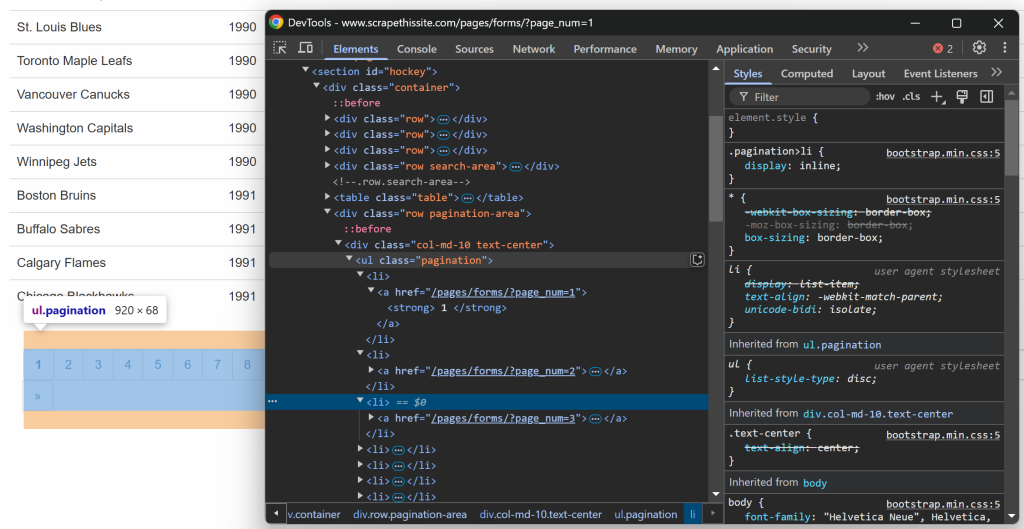
Tenga en cuenta que puede seleccionar todos los enlaces de paginación utilizando el siguiente selector CSS:
.pagination li aPara implementar el paso 2 y recopilar todas las URL de paginación, utilice esta lógica:
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});Inicializa una lista de URLs que almacenarán los enlaces de paginación, empezando por la URL de la primera página. A continuación, selecciona todos los elementos de paginación e itera sobre ellos, añadiendo nuevas URLs a la matriz $urls sólo si no están ya presentes. Como las URLs de la página son relativas, deben convertirse en URLs absolutas antes de añadirlas a la lista.
Dado que el manejo de la paginación sólo debe ejecutarse una vez y no está directamente ligado a la extracción de datos, es mejor envolverlo en una función:
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}Puede llamar a la función getPaginationUrls() así:
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");Tras la ejecución, $urls contendrá todas las URL paginadas:
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)Perfecto. Acabas de implementar el rastreo web en Goutte.
Paso 7: Extraer datos de todas las páginas
Ahora que tienes todas las URLs de las páginas almacenadas en un array, puedes rasparlas una a una mediante:
- Iterar sobre la lista
- Recuperación y análisis del contenido HTML de cada URL
- Extracción de los datos necesarios
- Almacenamiento de la información obtenida en la matriz
$teams.
Implementa la lógica anterior de la siguiente manera:
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// data extraction logic
}Observe la instrucción echo para registrar la página actual en la que está operando el scraper. Esa información es útil para entender lo que el script está haciendo durante la ejecución.
¡Precioso! Sólo queda exportar los datos raspados a un formato legible por humanos como CSV.
Paso 8: Exportar los datos a CSV
En este momento, los datos raspados se almacenan en la matriz $teams. Para que otros equipos puedan acceder a ellos y sea más fácil analizarlos, expórtalos a un archivo CSV.
PHP proporciona soporte incorporado para la exportación CSV a través de la función fputcsv(). Utilícela para escribir los datos raspados en un archivo llamado teams.csv como se indica a continuación:
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Misión cumplida. El rascador Goutte es completamente funcional.
Paso 9: Póngalo todo junto
Tu script de Goutte web scraping debería contener ahora:
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// initialize a new Goutte HTTP client
$client = new Client();
// get the URLs of the pages to scrape
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// where to store the scraped data
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// select the table element with the data of interest
$table = $crawler->filter("#hockey .table");
// iterate over each row and extract data from them
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// add the scraped data to the array
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];
});
}
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Ejecútalo con este comando:
php index.phpEl scraper registraría la siguiente salida:
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=1"...
// omitted for brevity..
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=24"...Al final de la ejecución, aparecerá en la carpeta del proyecto un archivo teams.csv con estos datos:
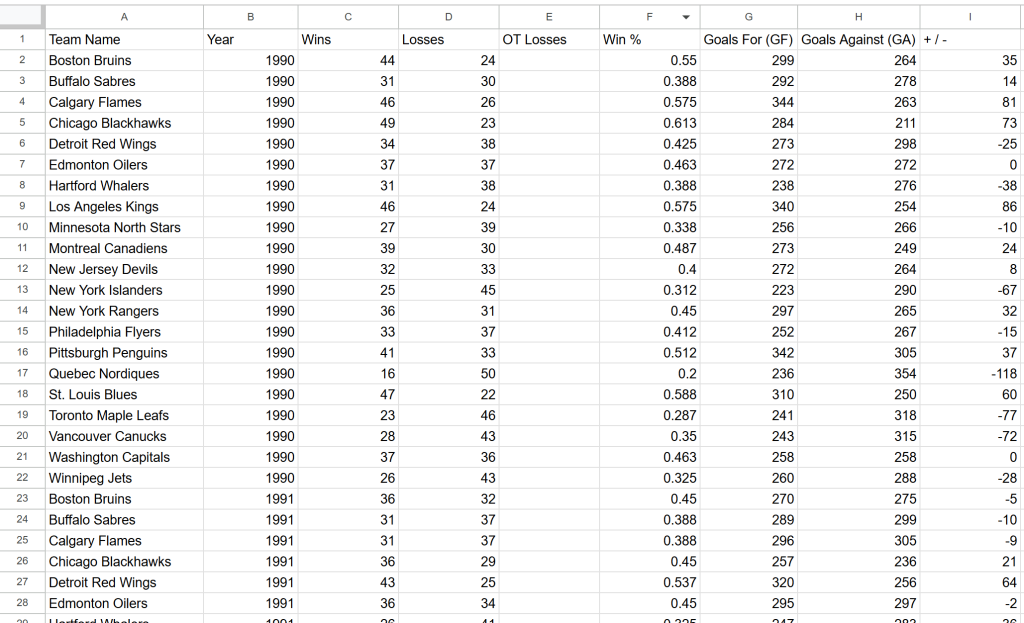
¡Et voilà! Los datos exactos del sitio de destino están ahora disponibles en un formato estructurado.
Alternativas a la librería PHP Goutte para Web Scraping
Como se mencionó al principio de este artículo, Goutte está obsoleto y ya no se mantiene. Esto significa que deberías considerar soluciones alternativas.
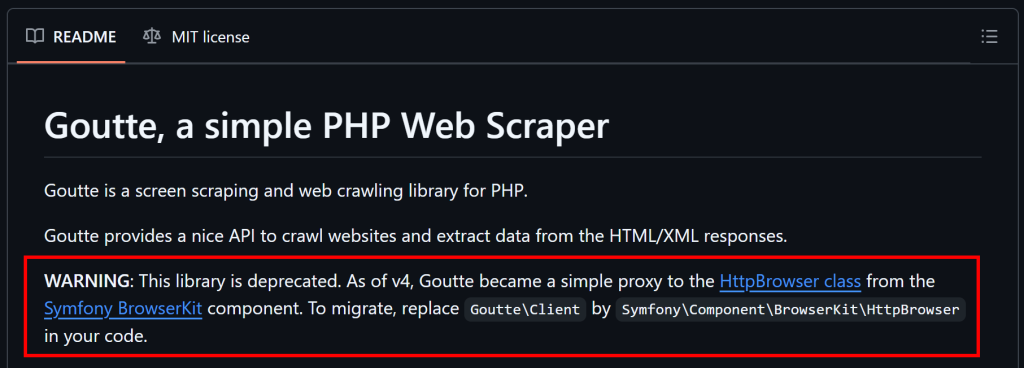
Como se explica en GitHub, dado que Goutte v4 se ha convertido esencialmente en un proxy de la clase HttpBrowser de Symfony, deberías migrar a ella. Para ello, solo necesitas instalar estas librerías:
composer require symfony/browser-kit symfony/http-clientEntonces, reemplaza:
use GoutteClient;con
use SymfonyComponentBrowserKitHttpBrowser;Por último, elimina Goutte como dependencia en tu proyecto. La API subyacente sigue siendo la misma, por lo que no deberías tener que cambiar mucho en tu script.
En lugar de Goutte, también puede combinar un cliente HTTP con un analizador HTML. Algunas alternativas recomendadas:
- Guzzle o cURL para realizar peticiones HTTP.
DomHTMLDocument, Simple HTML DOM Parser, oDomCrawlerpara analizar HTML en PHP.
Todas estas alternativas le dan más flexibilidad y garantizan que su script de web scraping siga siendo mantenible a largo plazo.
Limitaciones de este enfoque del Web Scraping
Goutte es una herramienta potente, pero su uso para el web scraping tiene varias limitaciones:
- La biblioteca está obsoleta
- Su API ya no se mantiene
- Está sujeta a limitadores de tarifa y bloques antirrobo
- No puede gestionar páginas dinámicas basadas en JavaScript
- Tiene un soporte de proxy integrado limitado, que es esencial para evitar bloqueos de IP.
Algunas de estas limitaciones se pueden mitigar mediante el uso de bibliotecas alternativas o enfoques diferentes, como se cubre en nuestra guía sobre web scraping con PHP. Aún así, siempre te enfrentarás a medidas anti-scraping que sólo pueden ser eludidas utilizando una API de Web Unlocker.
Una API de Web Unlocker es un punto final de raspado especializado diseñado para eludir las protecciones anti-bot y recuperar el HTML sin procesar de cualquier página web. Su uso es tan sencillo como realizar una llamada a la API y analizar el contenido devuelto. Este enfoque se integra perfectamente con Goutte (o los componentes actualizados de Symfony), tal y como se demuestra en este artículo.
Conclusión
En esta guía, usted exploró lo que es Goutte y lo que ofrece para el web scraping a través de un tutorial paso a paso. Dado que esta librería está obsoleta, también has tenido la oportunidad de explorar algunas de sus alternativas.
Independientemente de la biblioteca de scraping PHP que elija, el mayor reto es que la mayoría de los sitios web protegen sus datos mediante tecnologías anti-bot y anti-scraping. Estos mecanismos pueden detectar y bloquear solicitudes automatizadas, haciendo que los métodos tradicionales de scraping sean ineficaces.
Afortunadamente, Bright Data ofrece un conjunto de soluciones para evitar cualquier problema:
- Web Unlocker: Una API que elude las protecciones anti-scraping y entrega HTML limpio de cualquier página web con el mínimo esfuerzo.
- Navegador de raspado: Un navegador controlable basado en la nube con renderizado JavaScript. Maneja automáticamente CAPTCHAs, huellas digitales del navegador, reintentos, y más para usted. Se integra perfectamente con Panther o Selenium PHP.
- API de raspado web: Puntos finales para el acceso programático a datos web estructurados de docenas de dominios populares.
¿No quiere ocuparse del web scraping pero sigue interesado en ‘datos web en línea’? Explore nuestros conjuntos de datos listos para usar.
Regístrese ahora en Bright Data y comience su prueba gratuita para probar nuestras soluciones de scraping.





