

En esta guía, verá:
- Razones por las que es útil analizar HTML en PHP
- Los requisitos para empezar con el objetivo del artículo
- Cómo parsear HTML en PHP usando:
DomHTMLDocumento- Analizador DOM de HTML simple
DomCrawlerde Symfony
- Cuadro comparativo de los tres enfoques
Sumerjámonos.
¿Por qué analizar HTML en PHP?
El análisis sintáctico de HTML en PHP implica convertir el contenido HTML en su estructura DOM(Document Object Model). Una vez en el formato DOM, puede navegar y manipular fácilmente el contenido HTML.
En particular, las principales razones para analizar HTML en PHP son:
- Extracción de datos: Recopilar contenido específico de páginas web, como texto o atributos de elementos HTML.
- Automatización: Automatice tareas como el scraping de contenidos, la elaboración de informes y la agregación de datos a partir de contenidos HTML.
- Manipulación de contenidos HTML del lado del servidor: Analiza HTML para manipular, limpiar o dar formato al contenido web en el servidor antes de mostrarlo en tu aplicación.
Descubre las mejores bibliotecas de análisis sintáctico de HTML.
Requisitos previos
Antes de empezar a codificar, asegúrate de que tienes PHP 8.4+ instalado en tu máquina. Puede comprobarlo ejecutando el siguiente comando:
php -v
El resultado debería ser algo parecido a esto:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies
A continuación, desea inicializar un proyecto Composer para facilitar la gestión de dependencias. Si Composer no está instalado en su sistema, descárguelo y siga las instrucciones de instalación.
En primer lugar, cree una nueva carpeta para su proyecto PHP HTML:
mkdir php-html-parser
Navega a la carpeta en tu terminal e inicializa un proyecto Composer dentro de ella usando el comando composer init:
composer init
Durante este proceso, se le harán algunas preguntas. Las respuestas por defecto funcionarán, pero si lo desea, puede añadir detalles más específicos para su proyecto de análisis PHP HTML.
A continuación, abra la carpeta del proyecto en su IDE favorito. Visual Studio Code con la extensión PHP o IntelliJ WebStorm son buenas opciones para el desarrollo PHP.
Ahora, añade un archivo index.php vacío a la carpeta del proyecto. La estructura del proyecto debería ser la siguiente:
php-html-parser/
├── vendor/
├── composer.json
└── index.php
Abre index.php y añade el siguiente código para inicializar tu proyecto:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...
Este archivo pronto contendrá la lógica para parsear HTML en PHP.
Ahora puede ejecutar su script con este comando:
php index.php
Muy bien. Ya está todo listo para comenzar a analizar HTML en PHP. A partir de aquí, puede empezar a añadir la lógica necesaria de recuperación y análisis de HTML a su script.
Recuperación de HTML en PHP
Antes de analizar HTML en PHP, se necesita algo de HTML para analizar. En esta sección, veremos dos enfoques diferentes para acceder al contenido HTML en PHP.
Con CURL
PHP soporta de forma nativa cURL, un popular cliente HTTP utilizado para realizar peticiones HTTP. Habilite la extensión cURL o instálela en Linux con:
sudo apt-get install php8.4-curl
Puede utilizar cURL para enviar una solicitud HTTP GET a un servidor en línea y recuperar el documento HTML devuelto por el servidor.
A continuación se muestra un script de ejemplo que realiza una simple petición GET y recupera contenido HTML:
// initialize cURL session
$ch = curl_init();
// set the URL you want to make a GET request to
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// return the response instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// execute the cURL request and store the result in $response
$html = curl_exec($ch);
// close the cURL session
curl_close($ch);
// output the HTML response
echo $html;
Añada el fragmento anterior a index.php y ejecútelo. Producirá el siguiente código HTML:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hockey Teams: Forms, Searching and Pagination | Scrape This Site | A public sandbox for learning web scraping</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- Omitted for brevity... -->
</html>
Obtenga más información en nuestra guía sobre solicitudes GET cURL en PHP.
Desde un archivo
Otra forma de obtener el contenido HTML es almacenarlo en un archivo específico. Para ello:
- Visite una página de su elección en el navegador
- Haga clic con el botón derecho en la página
- Seleccione la opción “Ver fuente de la página
- Copiar y pegar el HTML en un archivo
También puede escribir su propia lógica HTML en un archivo.
Para este ejemplo, supondremos que el archivo se llama index.html. Contiene el HTML de la página “Equipos de hockey” de Scrape This Site, que se recuperó previamente mediante cURL:
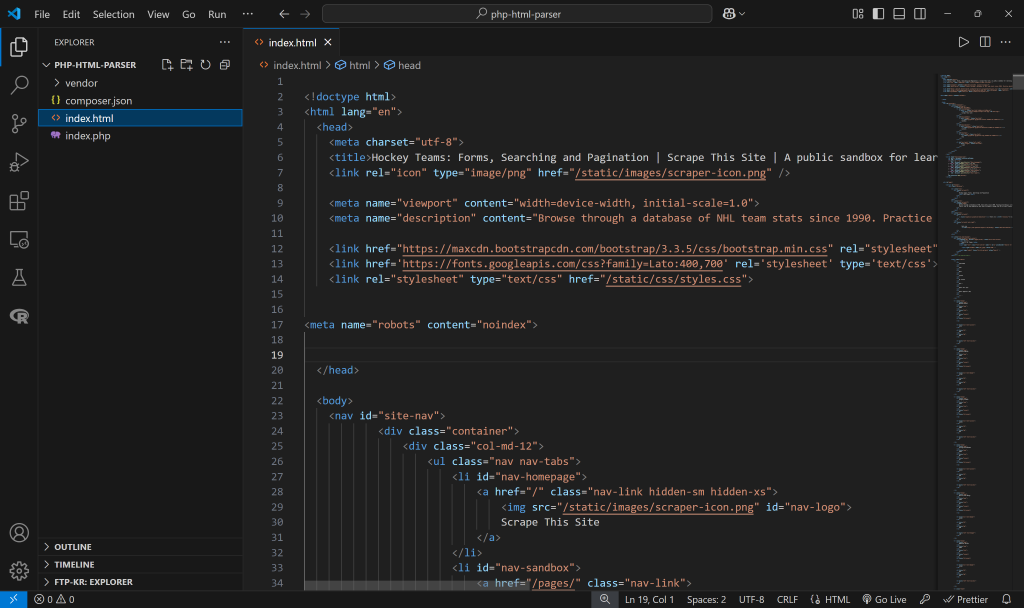
Análisis de HTML en PHP: 3 Enfoques
En esta sección, aprenderá a utilizar tres bibliotecas diferentes para analizar HTML en PHP:
- Uso de
DomHTMLDocumentpara PHP vainilla - Uso de la biblioteca Simple HTML DOM Parser
- Uso del componente
DomCrawlerde Symfony
En los tres casos, verá cómo analizar la cadena HTML recuperada a través de cURL o el contenido HTML leído del archivo local index.html.
A continuación, aprenderá a utilizar los métodos proporcionados por cada biblioteca PHP de análisis sintáctico HTML para seleccionar todas las entradas del equipo de hockey de la página y extraer datos de ellas:
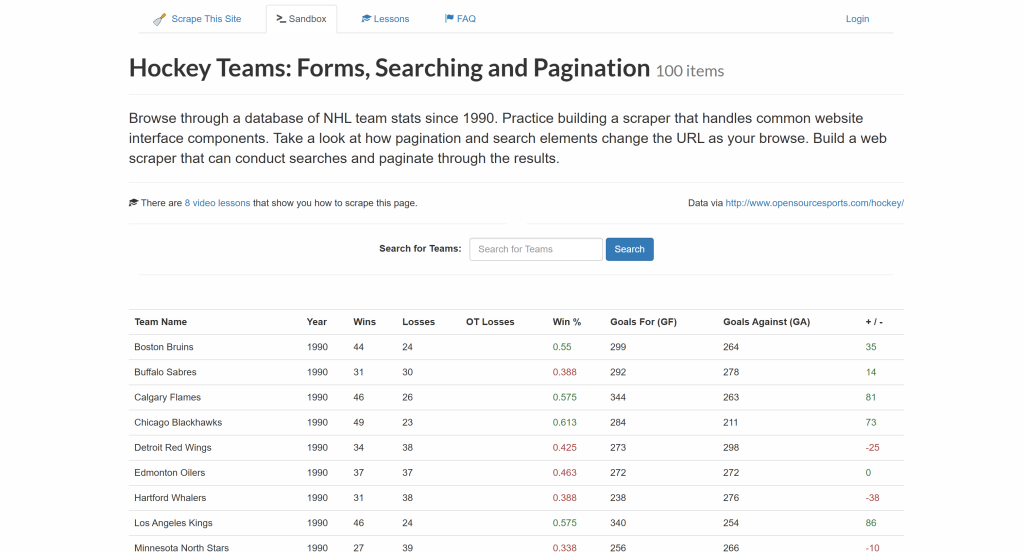
El resultado final será una lista de entradas de equipos de hockey raspados con los siguientes detalles:
- Nombre del equipo
- Año
- Gana
- Pérdidas
- Gana %.
- Goles a favor (GF)
- Goles en contra (GA)
- Diferencia de goles
Puede extraerlos de la tabla HTML con esta estructura:
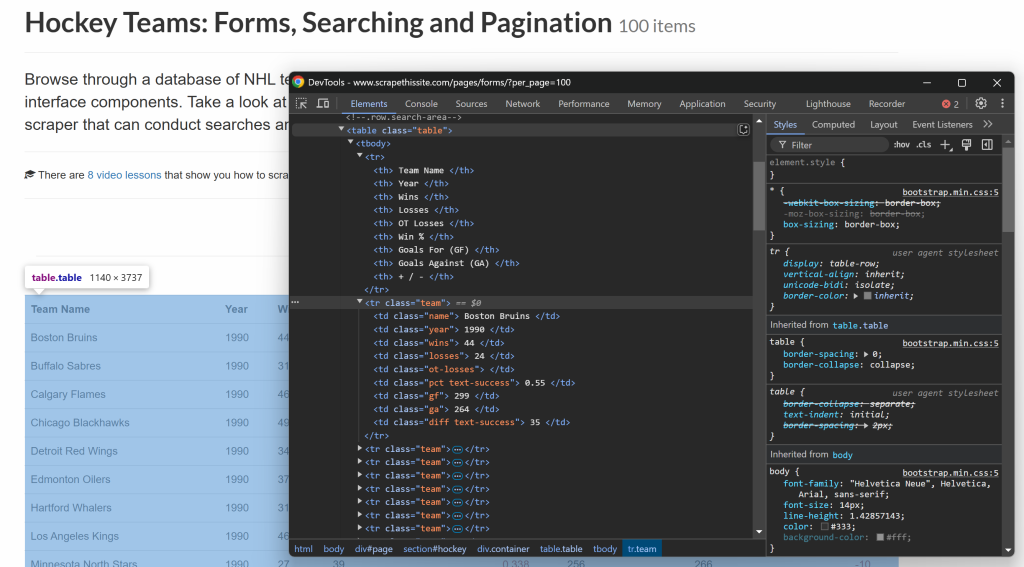
Como puede ver, cada columna de una fila de tabla tiene una clase específica. Puedes extraer datos de ella seleccionando elementos utilizando su clase como selector CSS y luego recuperando su contenido accediendo a su texto.
Tenga en cuenta que el análisis de HTML es sólo un paso en un script de web scraping. Para profundizar más, lee nuestro tutorial sobre web scraping con PHP.
Ahora, vamos a explorar tres enfoques diferentes para el análisis sintáctico de HTML en PHP.
Método nº 1: Con DomHTMLDocument
PHP 8.4+ viene con una clase DomHTMLDocument incorporada. Esto representa un documento HTML y le permite analizar el contenido HTML y navegar por el árbol DOM. Vea cómo usarla para analizar HTML en PHP.
Paso 1: Instalación y configuración
DomHTMLDocument es parte de la Librería Estándar de PHP. Aún así, necesita habilitar la extensión DOM o instalarla con este comando de Linux para usarla:
sudo apt-get install php-dom
No es necesaria ninguna otra acción. Ahora está listo para usar DomHTMLDocument para el análisis de HTML en PHP.
Paso 2: Análisis de HTML
Puede analizar la cadena HTML como se indica a continuación:
$dom = DOMHTMLDocument::createFromString($html);
De forma equivalente, puede analizar el archivo index.html con:
$dom = DOMHTMLDocument::createFromFile("./index.html");
$dom es un objeto DomHTMLDocument que expone los métodos necesarios para el análisis sintáctico de datos.
Paso 3: Análisis de datos
Puede seleccionar todas las entradas del equipo de hockey utilizando DOMHTMLDocument con el siguiente enfoque:
// select each row on the page
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// iterate through each row and extract data
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// extracting the data from each column
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// create an array for the scraped team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
}
DOMHTMLDocument no ofrece métodos avanzados de consulta. Así que tienes que confiar en métodos como getElementsByTagName() y la iteración manual.
He aquí un desglose de los métodos utilizados:
getElementsPorNombreDeEtiqueta(): Recupera todos los elementos de una etiqueta dada (como<table>,<tr>o<td>) dentro del documento.item(): Devuelve un elemento individual de una lista de elementos devueltos porgetElementsByTagName().contenido de texto: Esta propiedad proporciona el contenido de texto en bruto de un elemento, lo que permite extraer los datos visibles (como el nombre del equipo, el año, etc.).
También utilizamos trim() para eliminar los espacios en blanco adicionales antes y después del contenido del texto para obtener datos más limpios.
Cuando se añade a index.php, el fragmento anterior producirá este resultado:
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// omitted for brevity...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[win_pct] => 0.688
[goals_for] => 180
[goals_against] => 117
[goal_diff] => 63
)
Método nº 2: Uso de un analizador DOM de HTML simple
Simple HTML DOM Parser es una librería PHP ligera que facilita el análisis y la manipulación de contenido HTML. La biblioteca se mantiene activamente y tiene más de 880 estrellas en GitHub.
Paso 1: Instalación y configuración
Puede instalar Simple HTML Dom Parser a través de Composer con este comando:
composer require voku/simple_html_dom
También puede descargar e incluir manualmente el archivo simple_html_dom.php en su proyecto.
Luego, impórtalo en index.php con esta línea de código:
use vokuhelperHtmlDomParser;
Paso 2: Análisis de HTML
Para analizar una cadena HTML, utilice el método file_get_html():
$dom = HtmlDomParser::str_get_html($html);
Para analizar index.html, escriba file_get_html() en su lugar:
$dom = HtmlDomParser::file_get_html($str);
Esto cargará el contenido HTML en un objeto $dom, lo que le permitirá navegar por el DOM fácilmente.
Paso 3: Análisis de datos
Extraer los datos del equipo de hockey del HTML utilizando Simple HTML DOM Parser:
// find all rows in the table
$rows = $dom->findMulti("table tr.team");
// loop through each row to extract the data
foreach ($rows as $row) {
// extract data using CSS selectors
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print("n");
}
Las características del Simple HTML DOM Parser utilizadas anteriormente son:
findMulti(): Selecciona todos los elementos identificados por el selector CSS dado.findOne(): Localiza el primer elemento que coincide con el selector CSS dado.texto sin formato: Un atributo para obtener el contenido de texto sin formato dentro de un elemento HTML.
Esta vez, utilizamos selectores CSS con una lógica más completa y robusta. Aún así, el resultado será el mismo que en el enfoque inicial de PHP de análisis de HTML.
Método nº 3: Utilizar el componente DomCrawler de Symfony
El componente DomCrawler de Symfony proporciona una forma sencilla de analizar documentos HTML y extraer datos de ellos.
Nota: El componente forma parte del framework Symfony pero también se puede utilizar de forma independiente, como haremos en esta sección.
Paso 1: Instalación y configuración
Instala el componente DomCrawler de Symfony con este comando de Composer:
composer require symfony/dom-crawler
A continuación, impórtelo en el archivo index.php:
use SymfonyComponentDomCrawlerCrawler;
Paso 2: Análisis de HTML
Para analizar una cadena HTML, cree una instancia de Crawler con el método html():
$crawler = new Crawler($html);
Para analizar un archivo, utilice file_get_contents() y cree la instancia Crawler:
$crawler = new Crawler(file_get_contents("./index.html"));
Las líneas anteriores cargarán el contenido HTML en el objeto $crawler, que proporciona métodos sencillos para recorrer y extraer datos.
Paso 3: Análisis de datos
Extraiga los datos del equipo de hockey utilizando el componente DomCrawler:
// select all rows within the table
$rows = $crawler->filter("table tr.team");
// loop through each row to extract the data
$rows->each(function ($row, $i) {
// extract data using CSS selectors
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
});
Los métodos DomCrawler utilizados son:
each(): Para iterar sobre una lista de elementos seleccionados.filter(): Selecciona elementos basándose en selectores CSS.texto(): Extrae el contenido de texto de los elementos seleccionados.
¡Maravilloso! Ahora eres un maestro del parseo PHP HTML.
Análisis de HTML en PHP: Tabla comparativa
Puede comparar los tres enfoques de análisis sintáctico de HTML en PHP explorados aquí en la siguiente tabla resumen:
| Documento HTML | Analizador DOM de HTML simple | DomCrawler de Symfony | |
|---|---|---|---|
| Tipo | Componente nativo PHP | Biblioteca externa | Componente Symfony |
| Estrellas de GitHub | – | 880+ | 4,000+ |
| Compatibilidad con XPath | ❌ | ✔️ | ✔️ |
| Selector CSS | ❌ | ✔️ | ✔️ |
| Curva de aprendizaje | Bajo | Bajo a medio | Medio |
| Simplicidad de uso | Medio | Alta | Alta |
| API | Básico | Rich | Rich |
Conclusión
En este artículo, usted aprendió acerca de tres enfoques para el análisis sintáctico de HTML en PHP, que van desde el uso de extensiones incorporadas hasta bibliotecas de terceros.
Aunque todas estas soluciones funcionan, tenga en cuenta que la página web de destino puede utilizar JavaScript para la representación. En ese caso, los métodos simples de análisis de HTML como los presentados anteriormente no funcionarán. En su lugar, necesita un navegador de raspado completo con capacidades avanzadas de análisis de HTML como Scraping Browser.
¿Quiere saltarse el análisis de HTML y obtener los datos inmediatamente? Consulte nuestros conjuntos de datos listos para usar, que abarcan cientos de sitios web.
Cree una cuenta gratuita de Bright Data hoy mismo para probar nuestras soluciones de datos y scraping con una prueba gratuita.




