

En esta guía, descubrirá:
- Por qué Perplexity es una buena opción para el raspado web con IA
- Cómo scrapear un sitio web en Python con un tutorial paso a paso
- La principal limitación de este enfoque de web scraping, y cómo sortearla
Empecemos.
¿Por qué utilizar Perplexity para el Web Scraping?
Perplexity es un motor de búsqueda basado en inteligencia artificial que utiliza grandes modelos lingüísticos para generar respuestas detalladas a las consultas de los usuarios. Recupera información en tiempo real, la resume y puede responder con fuentes citadas.
Utilizar Perplexity para el web scraping reduce el proceso de extracción de datos a partir de contenidos HTML no estructurados a una simple consulta. Esto elimina la necesidad de analizar los datos manualmente, lo que facilita considerablemente la extracción de información relevante.
Además, Perplexity está diseñado para escenarios avanzados de rastreo web, gracias a sus capacidades para descubrir y explorar páginas web.
Para obtener más información, consulte nuestra guía sobre el uso de la IA para el web scraping.
Casos prácticos
Algunos ejemplos de casos de uso de Perplexity-powered scraping son:
- Páginas que cambian frecuentemente de estructura: Puede adaptarse a páginas dinámicas en las que los diseños y los elementos de datos cambian a menudo, como los sitios de comercio electrónico como Amazon.
- Rastreo de grandes sitios web: puede ayudar a descubrir y navegar por las páginas o realizar búsquedas basadas en IA que guíen el proceso de raspado.
- Extracción de datos de páginas complejas: Para sitios con estructuras difíciles de analizar, Perplexity puede automatizar la extracción de datos sin necesidad de una lógica de análisis extensa y personalizada.
Escenarios
Algunos ejemplos en los que el raspado con Perplexity resulta útil son:
- Generación mejorada por recuperación (RAG): Mejora de los conocimientos de la IA mediante la integración del raspado de datos en tiempo real. Para ver un ejemplo práctico con un modelo de IA similar, lee nuestra guía sobre la creación de un chatbot RAG con datos SERP.
- Agregación de contenidos: Recopilación de noticias, entradas de blog o artículos de múltiples fuentes para generar resúmenes o análisis.
- Raspado de redes sociales: Extracción de datos estructurados de plataformas con contenidos dinámicos o que se actualizan con frecuencia.
Cómo realizar Web Scraping con Perplexity en Python
Para esta sección, utilizaremos una página de producto específica del sandbox “Ecommerce Test Site to Learn Web Scraping“:

Esta página es un buen ejemplo, porque las páginas de productos de comercio electrónico suelen tener estructuras diferentes y mostrar distintos tipos de datos. Eso es lo que hace que el raspado web de comercio electrónico sea tan difícil, y donde la IA puede ayudar.
En concreto, el rascador impulsado por Perplexity aprovechará la IA para extraer estos detalles del producto de la página sin necesidad de lógica de análisis manual:
- SKU
- Nombre
- Imágenes
- Precio
- Descripción
- Tallas
- Colores
- Categoría
Nota: El siguiente ejemplo será en Python por simplicidad y por la popularidad de los SDKs involucrados. Aún así, puedes obtener el mismo resultado usando JavaScript o cualquier otro lenguaje de programación.
Sigue los pasos que se indican a continuación para aprender a raspar datos web con Perplexity.
Paso 1: Configure su proyecto
Antes de empezar, asegúrese de que Python 3 está instalado en su máquina. Si no lo está, descárgalo y sigue las instrucciones de instalación.
A continuación, ejecute el siguiente comando para inicializar una carpeta para su proyecto de scraping:
mkdir perplexity-scraperEl directorio perplexity-scraper servirá como carpeta de proyecto para su proyecto de web scraping utilizando Perplexity.
Navega hasta la carpeta en tu terminal y crea un entorno virtual Python dentro de ella:
cd perplexity-scraper
python -m venv venvAbre la carpeta del proyecto en tu IDE de Python preferido. Visual Studio Code con la extensión Python o PyCharm Community Edition son excelentes opciones.
Crea un archivo scraper.py en la carpeta del proyecto, que ahora debería tener este aspecto:

En este momento, scraper.py es sólo un script Python vacío, pero pronto contendrá la lógica para el raspado web LLM.
A continuación, active el entorno virtual en el terminal de su IDE. En Linux o macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, utilice:
venv/Scripts/activate¡Genial! Su entorno Python está ahora preparado para el web scraping con Perplexity.
Paso 2: Obtenga su clave API de Perplexity
Como la mayoría de los proveedores de IA, Perplexity expone sus modelos a través de API. Para acceder a ellos mediante programación, primero debe canjear una clave de API de Perplexity. Puedes consultar la “Configuración inicial” oficial o seguir los pasos guiados que se indican a continuación.
Si aún no tiene una cuenta en Perplexity, cree una e inicie sesión. A continuación, vaya a la página “API” y haga clic en “Configurar” para añadir un método de pago si aún no lo ha hecho:

Nota: No se le cobrará en este paso. Perplexity solo almacena tus datos de pago para futuros usos de la API. Puedes utilizar una tarjeta de crédito/débito, Google Pay o cualquier otro método de pago compatible.
Una vez configurado su método de pago, verá la siguiente sección:

Compre algunos créditos haciendo clic en “+ Comprar créditos” y espere a que se añadan a su cuenta. Una vez que los créditos estén disponibles, se activará el botón “+ Generar” en la sección Claves de API. Púlsalo para generar tu clave API Perplexity:

Aparecerá una clave API:

Copia la clave y guárdala en un lugar seguro. Para simplificar, la definiremos como una constante en scraper.py:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"Importante: En los scripts de producción de Perplexity scraping, evita almacenar las claves API en texto plano. En su lugar, almacene secretos como ese en variables de entorno o en un archivo .env gestionado con bibliotecas como python-dotenv.
¡Maravilloso! Ya estás listo para usar el SDK de OpenAI para hacer peticiones API a los modelos de Perplexity en Python.
Paso 3: Configurar Perplexity en Python
La última frase del paso anterior no contiene ningún error tipográfico, aunque mencione el SDK de OpenAI. Esto se debe a que la API de Perplexity es totalmente compatible con OpenAI. En realidad, la forma recomendada de conectarse a la API de Perplexity usando Python es a través del SDK de OpenAI.
Como primer paso, instala el OpenAI Python SDK. En un entorno virtual activado, ejecuta:
pip install openaiA continuación, impórtalo en tu script scraper.py:
from openai import OpenAIPara conectarse a Perplexity en lugar de OpenAI, configure el cliente de la siguiente manera:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")¡Genial! La configuración de Perplexity Python está ahora completa, y estás listo para hacer peticiones API a sus modelos.
Paso 4: Obtener el HTML de la página de destino
Ahora, necesitas recuperar el HTML de la página de destino. Puedes conseguirlo con un potente cliente HTTP de Python como Requests.
En un entorno virtual activado, instale Requests con:
pip install requestsA continuación, importa la biblioteca en scraper.py:
import requestsUtilice el método get() para enviar una solicitud GET a la URL de la página:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)El servidor de destino responderá con el HTML en bruto de la página.
Si imprime response.content, verá el documento HTML completo:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Ahora tienes el HTML exacto de la página de destino en Python. Analicémoslo y extraigamos de él los datos que necesitamos.
Paso 5: Convertir el HTML de la página a Markdown (opcional)
Atención: Este paso no es técnicamente obligatorio, pero puede ahorrarle mucho tiempo y dinero. Por tanto, merece la pena tenerlo en cuenta.
Tómese un momento para explorar cómo otras tecnologías de raspado web impulsadas por IA, como Crawl4AI y ScrapeGraphAI, manejan HTML sin procesar. Verás que ambas ofrecen opciones para convertir HTML a Markdown antes de pasar el contenido al LLM configurado.
¿Por qué lo hacen? Hay dos razones fundamentales:
- Rentabilidad: La conversión a Markdown reduce el número de tokens enviados a la IA, lo que te ayuda a ahorrar dinero.
- Procesamiento más rápido: Menos datos de entrada significa menores costes de cálculo y respuestas más rápidas.
Para más información, lea nuestra guía sobre por qué los nuevos agentes de IA eligen Markdown en lugar de HTML.
Es hora de replicar la lógica de conversión de HTML a Markdown para reducir el uso de tokens.
Comienza abriendo la página web de destino en modo incógnito (para asegurarte de que estás operando en una sesión nueva). A continuación, haz clic con el botón derecho del ratón en cualquier parte de la página y selecciona “Inspeccionar” para abrir las herramientas de desarrollo.
Examine la estructura de la página. Verá que todos los datos relevantes están contenidos en el elemento HTML identificado por el selector CSS #main:

Técnicamente, podría enviar todo el HTML sin procesar a Perplexity para que analizara los datos. Sin embargo, esto incluiría mucha información innecesaria, como encabezados y pies de página. En su lugar, utilizar el contenido de #main como datos brutos de entrada garantiza que sólo se traten los datos más relevantes. Esto reducirá el ruido y limitará las alucinaciones de la IA.
Para extraer sólo el elemento #main, necesitas una librería de análisis HTML de Python como Beautiful Soup. En tu entorno virtual Python activado, instálala con este comando:
pip install beautifulsoup4Si no estás familiarizado con su API, lee nuestra guía sobre raspado web Beautiful Soup.
Ahora, impórtalo en scraper.py:
from bs4 import BeautifulSoupUtiliza Beautiful Soup para:
- Analiza el HTML sin procesar obtenido con Requests
- Seleccione el elemento
#main - Obtener su contenido HTML
Consíguelo con este fragmento:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Si imprimes main_html, verás algo como esto:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>Utiliza la herramienta Tokenizer de OpenAI para comprobar a cuántos tokens corresponde el HTML seleccionado:

A continuación, calcula el coste de enviar estos tokens a la API de Perplexity utilizando la calculadora de precios de API de LLM:

Como puedes ver, este enfoque da como resultado más de 20.000 tokens. Es decir, de 0,21 a unos 0,63 dólares por solicitud. En un proyecto a gran escala con miles de páginas, ¡eso es mucho!
Para reducir el consumo de tokens, convierta el HTML extraído en Markdown utilizando una biblioteca como markdownify. Instálala en tu proyecto de scraping impulsado por Perplexity con:
pip install markdownifyImportar markdownify en scraper.py:
from markdownify import markdownifyA continuación, utilízalo para convertir el HTML de #main a Markdown:
main_markdown = markdownify(main_html)El proceso de conversión de datos producirá un resultado como el que se muestra a continuación:

A partir del elemento “size” al final de las dos áreas de texto, se puede ver que la versión Markdown de los datos de entrada es mucho más pequeña que el HTML original #main. Además, al inspeccionarlo, ¡notarás cómo sigue conteniendo todos los datos clave para el scrape!
Utiliza de nuevo el Tokenizer de OpenAI para comprobar cuántos tokens consume la nueva entrada Markdown:

Con este sencillo truco, redujo 20.658 tokens a 950 tokens, una reducción superior al 95%. Esto también se traduce en una enorme reducción de los costes de la API Perplexity por solicitud:
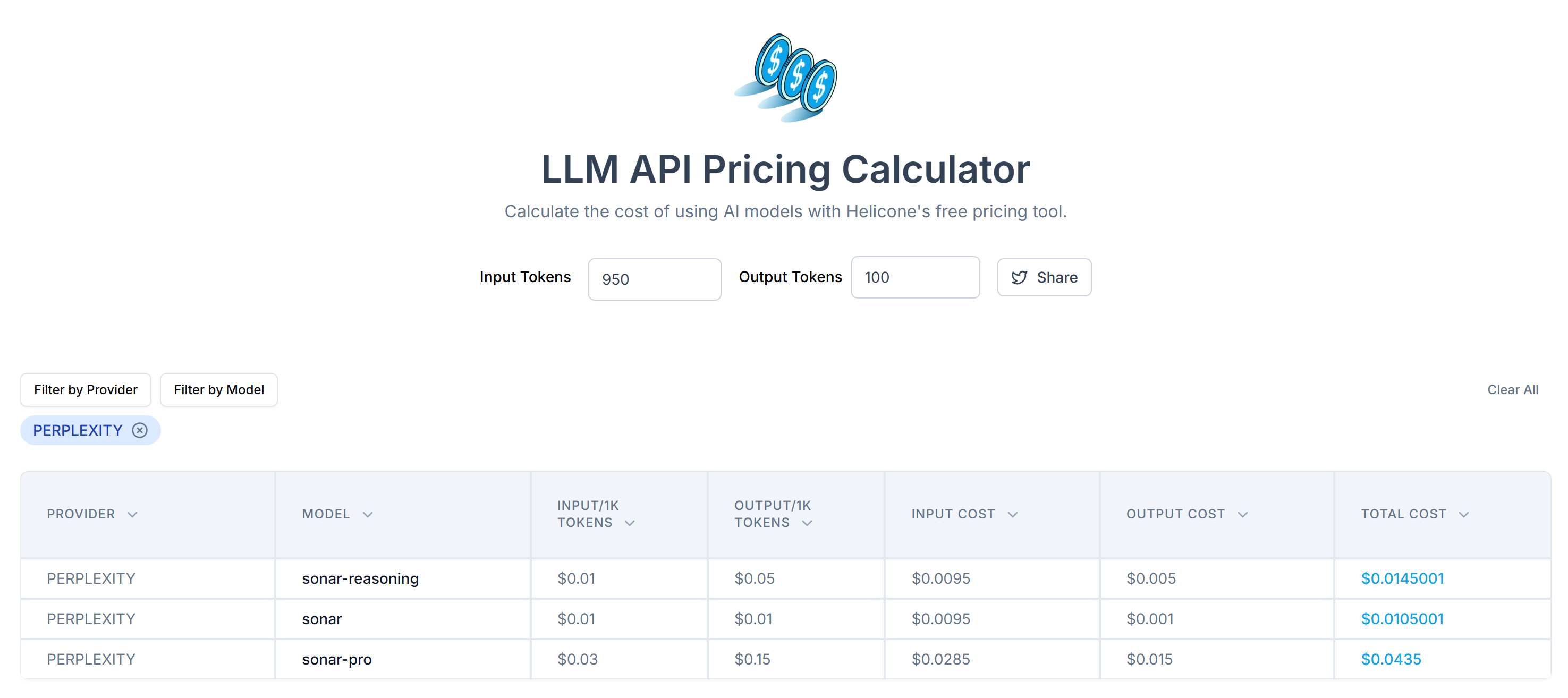
El coste se reduce de unos 0,21 a 0,63 dólares por solicitud a sólo 0,014 a 0,04 dólares por solicitud.
Paso 6: Utilizar la perplejidad para el análisis de datos
Siga estos pasos para raspar datos utilizando Perplexity:
- Escribe un prompt bien estructurado para extraer datos JSON en el formato deseado a partir de la entrada Markdown
- Enviar una solicitud al modelo LLM de Perplexity utilizando el SDK Python de OpenAI
- Analizar el JSON devuelto
Implementa los dos primeros pasos con el siguiente código:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentLa variable prompt indica a Perplexity que extraiga datos estructurados del contenido de main_markdown. Para mejorar los resultados, se recomienda definir un prompt claro para que el sistema sepa cómo comportarse y qué hacer.
Nota: Perplexity todavía se basa en la antigua sintaxis heredada de OpenAI para realizar llamadas a la API. Si intenta utilizar la nueva sintaxis responses.create(), se encontrará con el siguiente error:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'Ahora, product_raw_string debe contener datos JSON en el siguiente formato:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"Como puede ver, Perplexity devuelve los datos en formato Markdown.
Para implementar el paso 3 del algoritmo al principio de esta sección, necesitas extraer el contenido JSON crudo usando una regex. A continuación, puede analizar los datos JSON resultantes al diccionario Python json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)No olvides importar json y re de la biblioteca estándar de Python:
import json
import reNota: Si es usuario de Perplexity Tier-3, puede omitir el paso de análisis regex configurando la API para que devuelva directamente los datos en formato JSON estructurado. Encontrará más información en la guía “Structured Outputs” de Perplexity.
Una vez que haya analizado el diccionario product_data, puede acceder a los campos para procesar más datos. Por ejemplo:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantástico. Ha utilizado con éxito Perplexity para el web scraping. Sólo queda exportar los datos raspados según sea necesario.
Paso 7: Exportar los datos obtenidos
Actualmente, tiene los datos raspados almacenados en un diccionario Python. Para guardarlo como un archivo JSON, utilice el siguiente código:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Esto generará un archivo product.json que contiene los datos raspados en formato JSON.
¡Bien hecho! Tu raspador web potenciado por Perplexity ya está listo.
Paso 8: Póngalo todo junto
Aquí está el código completo de su secuencia de comandos de raspado utilizando Perplexity para el análisis de datos:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Ejecuta el script de scraping con:
python scraper.pyAl final de la ejecución, se generará un archivo product.json en la carpeta de su proyecto. Ábrelo y encontrarás datos estructurados como estos:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}¡Et voilà! El script transformó los datos no estructurados de una página HTML en un archivo JSON perfectamente organizado, todo ello gracias al raspado web impulsado por Perplexity.
Próximos pasos
Para llevar su rascador Perplexity al siguiente nivel, considere estas mejoras:
- Hágalo reutilizable: Modifique el script para que acepte el prompt y la URL de destino como argumentos de la línea de comandos. Esto hará que el scraper sea más flexible y adaptable a diferentes casos de uso y proyectos.
- Credenciales de API seguras: Almacena tu clave de API de Perplexity en un archivo .env y utiliza python-dotenv para cargarlo de forma segura. Este enfoque evita la codificación de credenciales sensibles en el script, mejorando la seguridad al mantener los secretos privados y separados de la base de código.
- Implemente el rastreo web: Aproveche las capacidades de búsqueda y rastreo impulsadas por IA de Perplexity para un rastreo inteligente y optimizado. Configure el rastreador para navegar por páginas enlazadas y extraer datos estructurados de diversas fuentes.
Cómo superar la mayor limitación de este método de raspado web
¿Cuál es la mayor limitación de este enfoque basado en la IA para el raspado web? Las peticiones HTTP realizadas por los usuarios.
Si bien el ejemplo anterior funcionó perfectamente, ello se debe a que el sitio de destino es esencialmente un patio de recreo del web scraping. En realidad, las empresas y los propietarios de sitios web comprenden el valor de sus datos, incluso cuando son de acceso público. Para protegerlos, implementan medidas anti-scraping que pueden bloquear fácilmente sus peticiones HTTP automatizadas.
En tales casos, el script fallará con errores 403 Forbidden, como:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
Además, este enfoque no funciona en páginas web dinámicas que dependen de JavaScript para su representación o para obtener datos de forma asíncrona. Por lo tanto, los sitios web ni siquiera necesitan defensas anti-bot avanzadas para bloquear su raspador impulsado por LLM.
Entonces, ¿cuál es la solución a todos estos problemas? Una API de desbloqueo web.
La API Web Unlocker de Bright Data es un punto final de scraping al que puede llamar desde cualquier cliente HTTP. Devuelve el HTML completamente desbloqueado de cualquier URL que se le pase, saltándose los bloqueos anti-scraping. No importa cuántas protecciones tenga un sitio de destino, una simple solicitud al Web Unlocker recuperará el HTML de la página para usted.
Para empezar, siga la documentación oficial de Web Unlocker para obtener su clave API. A continuación, sustituya el código de solicitud existente del “Paso nº 4” por estas líneas:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
Y así de fácil: ¡se acabaron los bloqueos y las limitaciones! Ya puedes raspar la Web con Perplexity sin preocuparte de que te detengan.
Conclusión
En este tutorial, aprendiste a usar Perplexity en combinación con Requests y otras herramientas para crear un scraper potenciado por IA. Uno de los mayores desafíos en el raspado web es el riesgo de ser bloqueado, pero esto se abordó utilizando la API Web Unlocker de Bright Data.
Como ya se ha comentado, al integrar Perplexity con la API Web Unlocker, puede extraer datos de cualquier sitio sin necesidad de una lógica de análisis personalizada. Este es solo uno de los muchos casos de uso soportados por los productos y servicios de Bright Data, que le permiten implementar un raspado web eficiente basado en IA.
Explore nuestras otras herramientas de raspado web:
- Servicios proxy: Cuatro tipos de proxies para eludir las restricciones de ubicación, incluido el acceso a más de 400M+ monthly de IP residenciales.
- API de Web Scraper: Puntos finales dedicados para extraer datos web frescos y estructurados de más de 100 dominios populares.
- API SERP: API para gestionar el desbloqueo continuo para SERPs y extraer páginas individuales.
- Navegador de raspado: Un navegador en la nube compatible con Puppeteer, Selenium y Playwright, que incorpora funciones de desbloqueo.
Regístrese ahora en Bright Data y pruebe gratis nuestros servicios proxy y productos de scraping.





