

El scraping web es una técnica que se puede utilizar para extraer datos de páginas web. Es especialmente útil cuando el sitio web de destino no ofrece una API, la API no se puede utilizar o no devuelve los datos exactos que se desean.
Regex, abreviatura de «expresión regular», es un potente patrón gramatical para extraer datos de texto y se utiliza habitualmente para el Scraping web. Regex define un patrón que puede coincidir en los textos y se utiliza habitualmente para buscar y extraer información del texto. Como tal, se utiliza ampliamente en el Scraping web.
En este artículo, aprenderás a utilizar regex enPython para el Scraping web. Al final del artículo, sabrás cómo extraer datos de sitios estáticos y dinámicos, y comprenderás algunas de las limitaciones a las que te puedes enfrentar.
¿Qué es Regex?
Una expresión regular se define utilizando tokens que coinciden con un patrón concreto. Describir todos los tokens en detalle queda fuera del alcance de este artículo, pero en la siguiente tabla se enumeran algunos tokens de uso común con los que probablemente te encontrarás:
| Token | Coincidencias |
|---|---|
| Cualquier carácter no especial | El carácter dado |
^ |
Inicio de una cadena |
$ |
Fin de una cadena |
. |
Cualquier carácter excepto n |
* |
Cero o más apariciones del elemento anterior |
? |
Cero o una aparición del elemento anterior |
+ |
Una o más apariciones de los caracteres anteriores |
{Dígito} |
Número exacto del elemento anterior |
d |
Cualquier dígito |
s |
Cualquier carácter de espacio en blanco |
w |
Cualquier carácter de palabra |
D |
Inverso de d |
S |
Inverso de s |
W |
Inverso de w |
Para obtener más información sobre expresiones regulares y adquirir experiencia práctica, visiteregexr.com. Además,este artículocomparte algunos consejos importantes para optimizar el rendimiento de sus expresiones regulares.
Uso de expresiones regulares en Python para el Scraping web
En este tutorial, crearás un sencillo Scraper web en Python utilizando expresiones regulares para extraer datos de páginas web.
Para empezar, crea un directorio para tu proyecto:
mkdir web_scraping_with_regex
cd web_scraping_with_regex
A continuación, cree un entorno virtual Python:
python -m venv venv
Y actívelo:
source ./venv/bin/activate
Para escribir el Scraper web, necesitas instalar dos bibliotecas:
requestspara recuperar páginas webbeautifulsoup4para el parseo del contenido HTML y la búsqueda de elementos
Ejecute el siguiente comando para instalar las bibliotecas:
pip install beautifulsoup4 requests
Nota: Antes de extraer datos de cualquier sitio web, asegúrate de consultar sus términos y condiciones para ver si está permitido hacerlo. No debes extraer datos de un sitio web si está prohibido.
Rastrear un sitio de comercio electrónico
En esta sección, crearás un Scraper web para rastrear unsitio de comercio electrónico ficticio sencillo. Rastrearás la primera página y extraerás los títulos y precios de los libros.
Para ello, cree un archivo llamado scraper.py e importe los módulos necesarios:
import requests
from bs4 import BeautifulSoup
import re
Nota: El módulo
rees un módulo integrado en Python que funciona con expresiones regulares.
A continuación, debes realizar una solicitud GET a la página web de destino para obtener el contenido HTML de la página:
page = requests.get('https://books.toscrape.com/')
Pase estos datos a Beautiful Soup, que realiza el parseo de la estructura HTML de la página web:
soup = BeautifulSoup(page.content, 'html.parser')
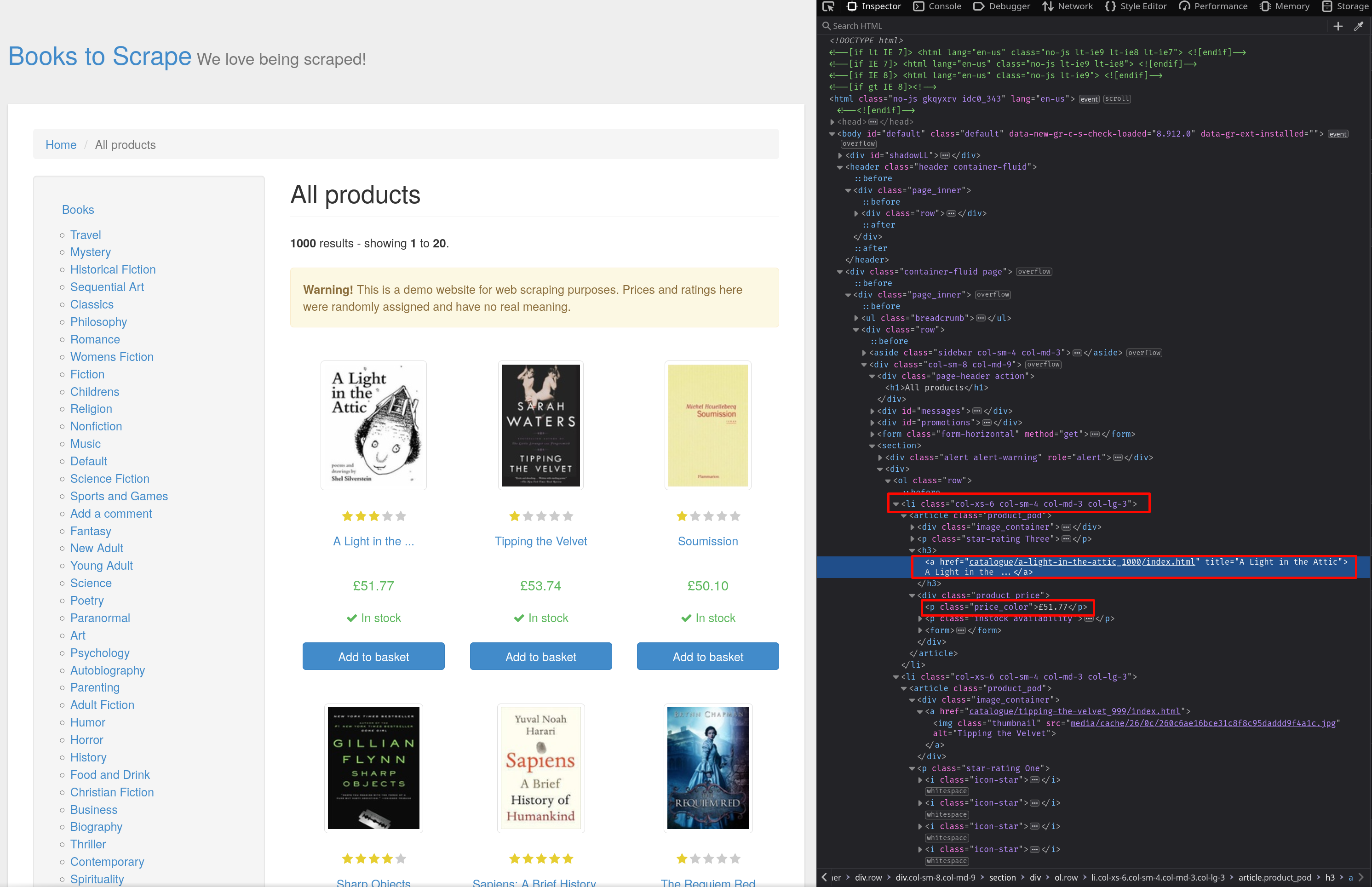
Para averiguar cómo están estructurados los elementos en HTML, utiliza la herramientaInspeccionar elemento. Abre lapágina weben el navegador y pulsaCtrl + Mayús + Ipara abrir elInspector. Como puede ver en la captura de pantalla, los productos se almacenan en elementoslicon la clasecol-xs-6 col-sm-4 col-md-3 col-lg-3. El título del libro se puede encontrar enloselementos a leyendo su atributotitle, y los precios se almacenan en elementospcon la claseprice_color:
Utiliza el método find_all de Beautiful Soup para encontrar todos los elementos li con clase col-xs-6 col-sm-4 col-md-3 col-lg-3:
books = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
content = str(books)
La variable content ahora contiene el texto HTML de los elementos li, y puede utilizar expresiones regulares para extraer los títulos y los precios.
El primer paso es construir una expresión regular que coincida con los títulos y precios del texto. Para ello, debes volver a utilizar la herramienta Inspeccionar elemento.
Observe que los títulos de los libros se almacenan en el atributo title de los elementos a, y que los elementos a tienen este aspecto:
<a href="..." title="...">
Para hacer coincidir el contenido de las comillas dobles después del título, utiliza la expresión regular clásica .*?. El carácter . coincide con un solo carácter, el carácter * coincide con cero o más ocurrencias del elemento precedente (en este caso, cualquier cosa que coincida con .), y el carácter ? coincide con cero o una ocurrencia del elemento precedente (en este caso, cualquier cosa que coincida con .*). Juntos, se utilizan para hacer coincidir el contenido de las comillas dobles en esta expresión completa:
<a href=".*?" title="(.*?)"
Los paréntesis alrededor de.*?se utilizan para crear ungrupo de captura. Los grupos de captura memorizan la información sobre la coincidencia del patrón y, en expresiones complicadas, se utilizan para identificar y hacer referencia a patrones ya coincidentes. Sin embargo, en este caso, el grupo de captura se utiliza para extraer el texto coincidente. Sin el grupo de captura, el texto seguiría coincidiendo, pero no se podría acceder al texto coincidente.
Para extraer el precio, utilice la misma expresión regular (.*?). Los precios se almacenan en elementos p con la clase price_color, por lo que la expresión regular completa es <p class="price_color">(.*?)</p>.
Defina los dos patrones:
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'
Nota:Si te preguntas por qué es necesario el
?después de.*,esta respuesta de Stack Overflowexplica bien la función del?.
Ahora puedes usar re.findall() para encontrar todas las coincidencias de expresiones regulares en la cadena HTML:
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)
Por último, itera sobre las coincidencias e imprime los resultados:
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")
Puedes ejecutar este código con python scraper.py. El resultado es el siguiente:
A Light in the Attic: 51,77 £
Tipping the Velvet: 53,74 £
Soumission: 50,10 £
Sharp Objects: 47,82 £
Sapiens: A Brief History of Humankind: 54,23 £
The Requiem Red: 22,65 £
The Dirty Little Secrets of Getting Your Dream Job: 33,34 £
The Coming Woman: Una novela basada en la vida de la famosa feminista Victoria Woodhull: 17,93 £.
The Boys in the Boat: Nueve estadounidenses y su épica búsqueda del oro en los Juegos Olímpicos de Berlín de 1936: 22,60 £.
The Black Maria: 52,15 £.
Starving Hearts (Trilogía Triangular Trade, n.º 1): 13,99 £.
Los sonetos de Shakespeare: 20,66 £
Set Me Free: 17,46 £
La preciosa vida de Scott Pilgrim (Scott Pilgrim n.º 1): 52,29 £
Rip it Up and Start Again: 35,02 £
Our Band Could Be Your Life: Escenas del underground indie estadounidense, 1981-1991: 57,25 £
Olio: 23,88 £
Mesaerion: Las mejores historias de ciencia ficción 1800-1849: 37,59 £
Libertarianismo para principiantes: 51,33 £
It's Only the Himalayas: 45,17 £
Raspando una página de Wikipedia
Ahora, creemos un Scraper que pueda extraer unapágina de Wikipediay extraer información sobre todos los enlaces.
Crea un nuevo archivo llamado wiki_scraper.py. Al igual que antes, empieza importando las bibliotecas, realizando una solicitud GET y realizando el parseo del contenido:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
Para encontrar todos los enlaces, utiliza el método find_all():
links = soup.find_all("a")
content = str(links)
Los textos de los enlaces se almacenan en el atributo title, y las URL de los enlaces se almacenan en el atributo href. Puede utilizar la misma expresión regular (.*?) para extraer la información. La expresión completa tiene este aspecto:
<a href="(.*?)" title="(.*?)">.*?</a>
Tenga en cuenta que el tercer .*? no está en un grupo de captura porque no le interesa el contenido de las etiquetas a.
Como antes, utilice findall() para encontrar todas las coincidencias e imprimir el resultado:
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")
Cuando ejecutas esto con python wiki_scraper.py, obtienes el siguiente resultado:
RESULTADO TRUNCADO POR BREVEDAD
/wiki/Category:Scraping web => Categoría:Scraping web
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Categoría:CS1 maint: múltiples nombres: lista de autores
/wiki/Category:CS1_Danish-language_sources_(da) => Categoría:CS1 Fuentes en danés (da)
/wiki/Category:CS1_French-language_sources_(fr) => Categoría:CS1 fuentes en francés (fr)
/wiki/Categoría:Artículos con descripción breve => Categoría:Artículos con descripción breve
/wiki/Categoría:Descripción breve coincide con Wikidata => Categoría:Descripción breve coincide con Wikidata
/wiki/Categoría:Artículos que necesitan referencias adicionales a partir de abril de 2023 => Categoría:Artículos que necesitan referencias adicionales a partir de abril de 2023
/wiki/Categoría:Todos_los_artículos_que_necesitan_referencias_adicionales => Categoría:Todos los artículos que necesitan referencias adicionales
/wiki/Categoría:Artículos_con_alcance_geográfico_limitado_desde_octubre_de_2015 => Categoría:Artículos con alcance geográfico limitado desde octubre de 2015
/wiki/Categoría:Centrados en Estados Unidos => Categoría:Centrados en Estados Unidos
/wiki/Categoría:Todos los artículos con afirmaciones sin fuentes => Categoría:Todos los artículos con afirmaciones sin fuentes
/wiki/Categoría:Artículos con afirmaciones sin fuentes de abril de 2023 => Categoría:Artículos con afirmaciones sin fuentes de abril de 2023
Rastrear un sitio dinámico
Hasta ahora, todas las páginas web que has extraído eran estáticas. El scraping de páginas web dinámicas es un poco más difícil, ya que requiere una herramienta de automatización del navegador comoSelenium. A continuación se muestra un ejemplo de extracción de la página de iniciode OpenWeatherMappara Londres y el uso de expresiones regulares y Selenium para extraer la temperatura actual:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()
Este código utiliza Selenium para iniciar una instancia de Firefox y utiliza el selector CSS para seleccionar el elemento con la temperatura actual. A continuación, utiliza la expresión regular <span .*?>(.*?)</span> para extraer la temperatura.
Si buscas más información que te ayude a empezar a realizar scraping web de páginas web dinámicas con Selenium, echa un vistazo aeste tutorial.
Limitaciones de las expresiones regulares para el Scraping web
Las expresiones regulares son herramientas poderosas para la coincidencia de patrones y la extracción de información de textos. Los desarrolladores suelen aprender expresiones regulares e intentan utilizarlas para el Scraping web. Sin embargo, las expresiones regulares por sí solas no son adecuadas para el Scraping web. Las expresiones regulares funcionan con texto y no tienen ningún concepto ni comprensión de las estructuras HTML. Esto significa que los resultados dependen en gran medida de la forma en que está escrito el código HTML. Por ejemplo, en el ejemplo de Wikipedia, es posible que hayas notado que algunos enlaces no se extrajeron correctamente:

Si editas el código Python y añades print(content) para imprimir la cadena HTML devuelta por Beautiful Soup, verás que el culpable tiene este aspecto:
<a href="#cite_ref-9">^</a>
Aquí falta el atributo title, pero en la expresión regular se asumió la estructura <a href="(.*?)" title="(.*?)">.*?</a>. Dado que la expresión regular no tiene ni idea de los elementos HTML, en lugar de generar un error o detener la coincidencia, el patrón .*? siguió coincidiendo ciegamente con los caracteres hasta que pudo coincidir con " title="(.*?)">.*?</a> para completar el patrón. Esto terminó devorando las siguientes etiquetas a y muestra que el uso de expresiones regulares puede causar efectos no deseados si el código HTML está escrito de una manera inesperada.
Además, HTML no es un lenguaje regular, lo que significa que las expresiones regulares por sí solas no pueden utilizarse para el parseo de datos HTML arbitrarios. Estarespuesta de Stack Overflowes un clásico de culto entre los desarrolladores por burlarse de los desarrolladores que intentan realizar el parseo de HTML con expresiones regulares. Sin embargo, hay algunas situaciones en las que se pueden utilizar expresiones regulares para el parseo y la extracción de datos HTML.
Por ejemplo, si se dispone de un conjunto conocido y limitado de código HTML y se conoce perfectamente cómo está estructurado el código, se pueden utilizar expresiones regulares. Por ejemplo, si se sabe que todas las etiquetas a del HTML tienen los atributos href y title y se ajustan a un patrón fijo, se pueden utilizar expresiones regulares para extraer información. Sin embargo, una solución mejor y más robusta es utilizar un analizador HTML como Beautiful Soup para encontrar elementos y extraer datos textuales de ellos.
Una vez que hayas extraído los datos textuales, puedes utilizar expresiones regulares para procesarlos más a fondo. Por ejemplo, aquí tienes una versión modificada del Scraper de Wikipedia que utiliza Beautiful Soup para extraer los atributos href y title y, a continuación, utiliza expresiones regulares para filtrar cualquier etiqueta que contenga caracteres no alfanuméricos:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")
Conclusión
Regex es una herramienta poderosa para encontrar patrones en datos textuales. Gracias a su solidez, se utiliza a menudo en el Scraping web para extraer información.
En este artículo, has aprendido qué es regex y cómo utilizarlo con Beautiful Soup para extraer datos de sitios web de comercio electrónico, Wikipedia y páginas web dinámicas. También has aprendido algunas de las limitaciones de regex y cómo utilizarlo de la mejor manera posible junto con otra herramienta.
Incluso si se aprovecha al máximo regex, el scraping web está lleno de retos. El scraping web repetido puede provocar que la dirección IP de su Scraper sea bloqueada. También puede encontrarse con CAPTCHAs que pueden impedir que su Scraper funcione correctamente. Bright Dataofrece potentes proxies que pueden eludir las prohibiciones de IP. Su red mundial de proxies incluyeproxies de centros de datos,proxies residenciales,proxies ISP yproxies móviles. ConWeb Unlocker, puede eludir la detección de bots y resolver CAPTCHAs sin ningún tipo de molestia. ¡Comience hoy mismo una prueba gratuita!






