

Node.js se ha convertido en una potente opción para crear Scrapers web, ya que ofrece comodidad tanto para desarrollos del lado del cliente como del lado del servidor. Su amplio catálogo de bibliotecas hace que el Scraping web con Node.js sea muy sencillo. En este artículo, se destacará cheerio y se explorarán sus capacidades para un Scraping web eficiente.
Cheerio es una biblioteca rápida y flexible para analizar y manipular documentos HTML y XML. Implementa un subconjunto de características de jQuery, lo que significa que cualquiera que esté familiarizado con jQuery se sentirá cómodo con la sintaxis de cheerio. En segundo plano, cheerio utiliza las bibliotecas parse5 y, opcionalmente, htmlparser2 para realizar el parseo de documentos HTML y XML.
En este artículo, crearás un proyecto que utiliza cheerio y aprenderás a extraer datos de sitios web dinámicos y páginas web estáticas.
Scraping web con cheerio
Antes de comenzar este tutorial, asegúrate de tener Node.js instalado en tu sistema. Si aún no lo tienes, puedes instalarlo siguiendo la documentación oficial.
Una vez que hayas instalado Node.js, crea un directorio llamado cheerio-demo y entra en él con cd:
mkdir cheerio-demo u0026u0026 cd cheerio-demon
A continuación, inicialice un proyecto npm en el directorio:
npm init -yn
Instala los paquetes cheerio y Axios:
npm install cheerio axiosn
Cree un archivo llamado index.js, que es donde escribirá el código para este tutorial. A continuación, abra este archivo en su editor favorito para comenzar.
Lo primero que debe hacer es importar los módulos necesarios:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);n
En este tutorial, extraerá la página Books to Scrape, un entorno de pruebas público para probar los Scrapers web. Primero utilizará Axios para realizar una solicitud GET a la página web con el siguiente código:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n n});n
El objeto de respuesta en la devolución de llamada contiene el código HTML de la página web en la propiedad de datos. Este HTML debe pasarse a la función de carga del módulo cheerio. Esta función devuelve una instancia de CheerioAPI, que se utilizará para acceder y manipular el DOM para el resto del código. Ten en cuenta que la instancia de CheerioAPI se almacena en una variable llamada $, que es un guiño a la sintaxis de jQuery:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);n});n
Búsqueda de elementos
Cheerio admite el uso de selectores CSS y XPath para seleccionar elementos de la página. Si ha utilizado jQuery, le resultará familiar la sintaxis: pase el selector CSS a la función $(). Utilice esta sintaxis para buscar y extraer información de la primera página del sitio web Books to Scrape.
Visita https://books.toscrape.com/ y abre la consola de desarrollador. Busca la pestaña Inspect Element, donde encontrarás más información sobre la estructura HTML de la página. En este caso, puedes ver que toda la información sobre los libros está contenida en etiquetas de artículo con la clase product-pod:
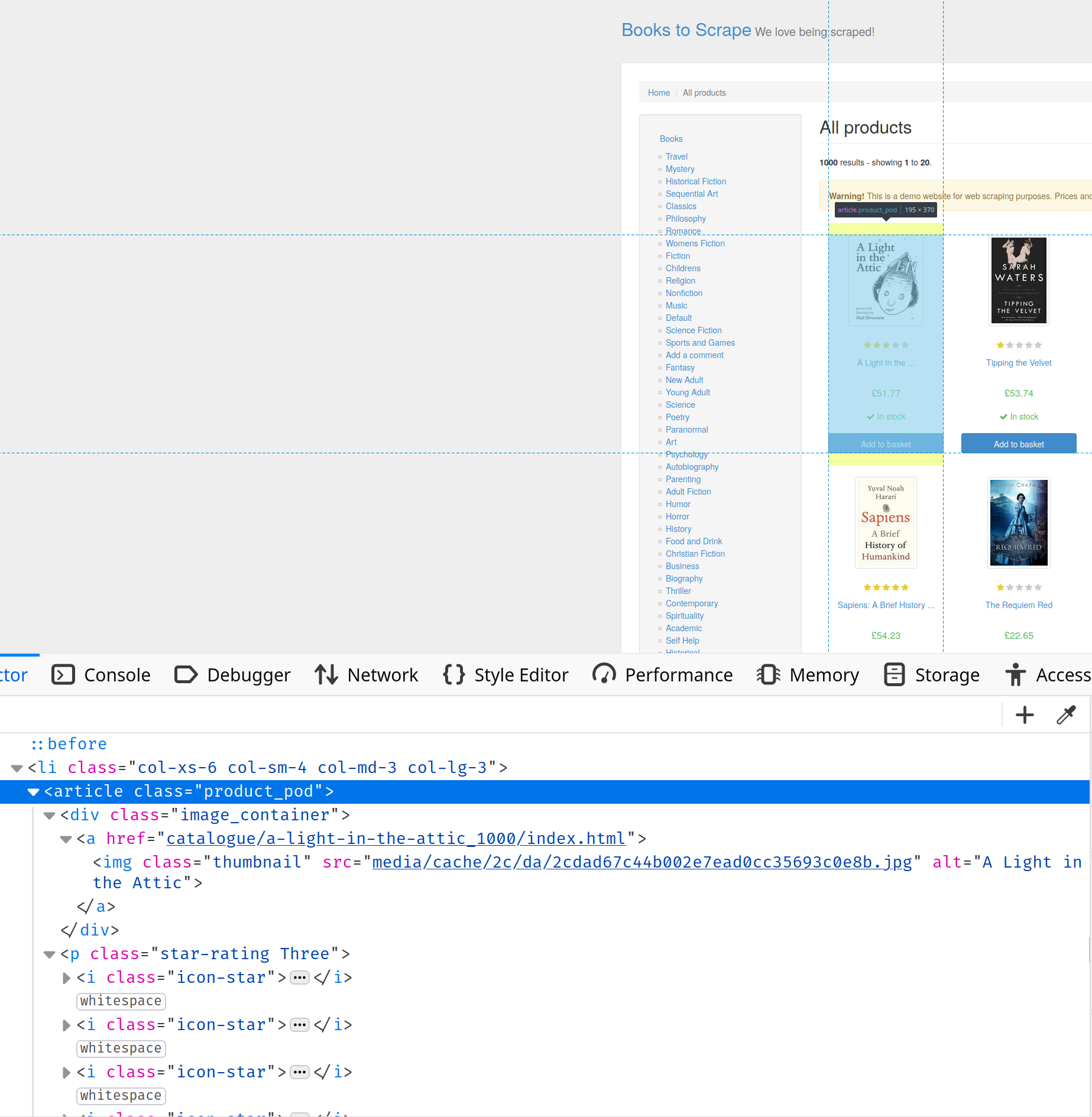
Para seleccionar los libros, debe utilizar el selector CSS article.product_pod de la siguiente manera:
$(u0022article.product_podu0022);n
Esta función devuelve una lista de todos los elementos que coinciden con el selector. Puede utilizar el método each para iterar sobre la lista:
$(u0022article.product_podu0022).each( (i, element) =u003e {nn});n
Dentro del bucle, puedes utilizar la variable element para extraer los datos.
Intenta extraer el título de los libros de la primera página. Volviendo a la consola Inspect Element, puedes ver cómo se almacenan los títulos:

Verás que necesitas encontrar un h3, que es un elemento secundario de la variable element. Dentro del h3, hay un elemento a que contiene el título del libro. Puedes utilizar el método find con un selector CSS para encontrar los elementos secundarios de un elemento, pero inicialmente debes pasar el elemento a través de $ para convertirlo en una instancia de Cheerio:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);nn});n
Ahora puedes encontrar el a dentro de titleH3:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022);n});n
Nota:
titleH3ya es una instancia deCheerio, por lo que no es necesario pasarla por$.
Extracción de texto
Una vez seleccionado un elemento, puedes obtener el texto de ese elemento utilizando el método text.
Modifique el ejemplo anterior para extraer el título del libro llamando al método text en el resultado del método find:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n});n
El código completo debería tener este aspecto:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n });n});n
Ejecute el código con node index.js y debería ver el siguiente resultado:
A Light in the ...nTipping the VelvetnSoumissionnSharp ObjectsnSapiens: A Brief History ...nThe Requiem RednThe Dirty Little Secrets ...nThe Coming Woman: A ...nThe Boys in the ...nThe Black MarianStarving Hearts (Triangular Trade ...nShakespeare's SonnetsnSet Me FreenScott Pilgrim's Precious Little ...nRip it Up and ...nOur Band Could Be ...nOlionMesaerion: The Best Science ...nLibertarianism for BeginnersnIt's Only the Himalayasn
Navegación por el DOM: búsqueda de elementos secundarios y hermanos
Una vez que haya extraído los títulos, es el momento de extraer el precio y la disponibilidad de cada libro. La herramienta Inspeccionar elemento revela que tanto el precio como la disponibilidad se almacenan en un div con la clase product_price. Puede seleccionar este div con el selector CSS .product_price, pero como ya ha visto los selectores CSS, a continuación se explica otra forma de hacerlo:
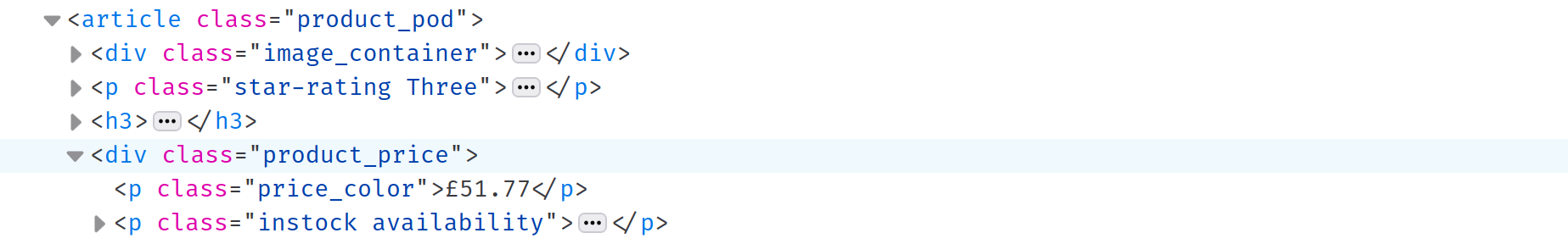
Nota: El
dives un hermano deltitleH3que seleccionaste anteriormente. Al llamar al métodonextdetitleH3, puedes seleccionar el siguiente hermano:
const priceDiv = titleH3.next();n
Ya has visto que puedes utilizar el método find para encontrar los hijos de un elemento basándote en selectores CSS. También puedes seleccionar todos los hijos con el método children y, a continuación, utilizar el método eq para seleccionar un hijo concreto. Esto es equivalente al selector CSS nth-child.
En este caso, el precio es el primer hijo de priceDiv y la disponibilidad es el segundo hijo de priceDiv. Esto significa que puede seleccionarlos con priceDiv.children().eq(0) y priceDiv.children().eq(1), respectivamente. Haga eso e imprima el precio y la disponibilidad:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n console.log(title, price, availability);n});n
Ahora, al ejecutar el código, se muestra el siguiente resultado:
A Light in the ... £51.77 In stocknTipping the Velvet £53.74 In stocknSoumission £50.10 In stocknSharp Objects £47.82 In stocknSapiens: A Brief History ... £54.23 In stocknThe Requiem Red £22.65 In stocknThe Dirty Little Secrets ... £33.34 In stocknThe Coming Woman: A ... £17.93 In stocknThe Boys in the ... £22.60 In stocknThe Black Maria £52.15 In stocknStarving Hearts (Triangular Trade ... £13.99 In stocknShakespeare's Sonnets £20.66 In stocknSet Me Free £17.46 In stocknScott Pilgrim's Precious Little ... £52.29 In stocknRip it Up and ... £35.02 In stocknOur Band Could Be ... £57.25 In stocknOlio £23.88 In stocknMesaerion: The Best Science ... £37.59 In stocknLibertarianism for Beginners £51.33 In stocknIt's Only the Himalayas £45.17 In stockn
Acceso a los atributos
Hasta ahora, ha navegado por el DOM y extraído textos de los elementos. También es posible extraer atributos de un elemento utilizando cheerio, que es lo que hará en esta sección. Aquí, extraerá la calificación de los libros leyendo la lista de clases de los elementos.
La calificación de los libros tiene una estructura interesante. Las calificaciones están contenidas en una etiqueta p. Cada etiqueta p tiene exactamente cinco estrellas, pero las estrellas se colorean utilizando CSS basado en el nombre de clase del elemento p. Por ejemplo, en una p con clase star-rating.Four, las primeras cuatro estrellas son de color amarillo, lo que denota una calificación de cuatro estrellas:

Para extraer la calificación de un libro, debes extraer los nombres de clase del elemento p. El primer paso es encontrar el párrafo que contiene la calificación:
const ratingP = $(element).find(u0022p.star-ratingu0022);n
Al pasar el nombre del atributo al método attr, se pueden leer los atributos de un elemento. En este caso, es necesario leer la lista de clases, como se muestra en el siguiente código:
const starRating = ratingP.attr('class');n
La lista de clases tiene la siguiente forma: star-rating X, donde X es uno de los siguientes: One, Two, Three, Four y Five. Esto significa que debe dividir la lista de clases por espacios y tomar el segundo elemento. El siguiente código hace eso y convierte la calificación textual en una calificación numérica:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];n
Si lo junta todo, su código tendrá este aspecto:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();nn const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);n});n
El resultado es el siguiente:
A Light in the ... £51.77 In stock 3nTipping the Velvet £53.74 In stock 1nSoumission £50.10 In stock 1nSharp Objects £47.82 In stock 4nSapiens: A Brief History ... £54.23 In stock 5nThe Requiem Red £22.65 In stock 1nThe Dirty Little Secrets ... £33.34 In stock 4nThe Coming Woman: A ... £17.93 In stock 3nThe Boys in the ... £22.60 In stock 4nThe Black Maria £52.15 In stock 1nStarving Hearts (Triangular Trade ... £13.99 In stock 2nShakespeare's Sonnets £20.66 In stock 4nSet Me Free £17.46 In stock 5nScott Pilgrim's Precious Little ... £52.29 In stock 5nRip it Up and ... £35.02 In stock 5nOur Band Could Be ... £57.25 In stock 3nOlio £23.88 In stock 1nMesaerion: The Best Science ... £37.59 In stock 1nLibertarianism for Beginners £51.33 In stock 2nIt's Only the Himalayas £45.17 In stock 2n
Guardar los datos
Después de extraer los datos de la página web, lo normal es que quieras guardarlos. Hay varias formas de hacerlo, como guardarlos en un archivo, guardarlos en una base de datos o introducirlos en un proceso de tratamiento de datos. En esta sección, aprenderás la forma más sencilla de todas: guardar los datos en un archivo CSV.
Para ello, instala el paquete node-csv:
npm install csvn
En index.js, importe los módulos fs y csv-stringify:
const fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);n
Para escribir un archivo local, debe crear un WriteStream:
const filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);n
Declare los nombres de las columnas, que se añaden al archivo CSV como encabezados:
const columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];n
Cree un stringifier con los nombres de las columnas:
const stringifier = stringify({ header: true, columns: columns });n
Dentro de la función each, utilizará el stringifier para escribir los datos:
$(u0022article.product_podu0022).each( (i, element) =u003e {n ...nn const data = { title, rating, price, availability };n stringifier.write(data);nn});n
Por último, fuera de la función each, debe escribir el contenido del stringifier en la variable writableStream:
stringifier.pipe(writableStream);n
En este punto, su código debería tener este aspecto:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nconst fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);nnconst filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);nnconst columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];nconst stringifier = stringify({ header: true, columns: columns });nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();n n const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);nn const data = { title, rating, price, availability };n stringifier.write(data);nn });nn stringifier.pipe(writableStream);nn});n
Ejecute el código y debería crear un archivo scraped_data.csv con los datos extraídos en su interior:
title,rating,price,availabilitynA Light in the ...,3,£51.77,In stocknTipping the Velvet,1,£53.74,In stocknSoumission,1,£50.10,In stocknSharp Objects,4,£47.82,In stocknSapiens: A Brief History ...,5,£54.23,In stocknThe Requiem Red,1,£22.65,In stocknThe Dirty Little Secrets ...,4,£33.34,In stocknThe Coming Woman: A ...,3,£17.93,In stocknThe Boys in the ...,4,£22.60,In stocknThe Black Maria,1,£52.15,In stocknStarving Hearts (Triangular Trade ...,2,£13.99,In stocknShakespeare's Sonnets,4,£20.66,In stocknSet Me Free,5,£17.46,In stocknScott Pilgrim's Precious Little ...,5,£52.29,In stocknRip it Up and ...,5,£35.02,In stocknOur Band Could Be ...,3,£57.25,In stocknOlio,1,£23.88,In stocknMesaerion: The Best Science ...,1,£37.59,In stocknLibertarianism for Beginners,2,£51.33,In stocknIt's Only the Himalayas,2,£45.17,In stockn
Conclusión
Como has visto aquí, la biblioteca cheerio facilita el Scraping web con su sintaxis similar a jQuery y su funcionamiento ultrarrápido. En este artículo, has aprendido a hacer lo siguiente:
- Cargar y realizar el parseo de una página web HTML con cheerio
- Buscar elementos con selectores CSS
- Extraer datos de los elementos
- Navegar por el DOM
- Guardar los datos extraídos en un archivo local
Puedes encontrar el código completo en GitHub.
Sin embargo, cheerio es solo un analizador HTML, por lo que no puede ejecutar código JavaScript. Eso significa que no puede utilizarlo para extraer páginas web dinámicas y aplicaciones de una sola página. Para extraerlas, debe buscar más allá de cheerio y recurrir a herramientas complejas como Selenium o Playwright. Y ahí es donde entra en juego Bright Data. Las amplias soluciones de scraping web de Bright Data incluyen un navegador de scraping Selenium y un navegador de scraping Playwright. Para obtener más información sobre los productos, puede visitar nuestra documentación sobre navegadores de scraping.





