

Este tutorial cubre:
- ¿Por qué raspar datos de comercio electrónico de la Web?
- Bibliotecas y herramientas de raspado web de eBay
- Extracción de datos de productos de eBay con Beautiful Soup
¿Por qué raspar datos de comercio electrónico de la Web?
El raspado de datos de comercio electrónico permite recuperar información útil para diferentes escenarios y actividades. Por ejemplo
- Seguimiento de precios: al rastrear sitios web de comercio electrónico, las empresas pueden supervisar los precios de los productos en tiempo real. Esto le ayuda a identificar las fluctuaciones de precios, detectar tendencias y ajustar su estrategia de precios en consecuencia. Si usted es un consumidor, esto le ayudará a encontrar las mejores ofertas y ahorrar dinero.
- Análisis de la competencia: al recopilar información sobre la oferta de productos, precios, descuentos y promociones de sus competidores, puede tomar decisiones basadas en datos sobre sus propias estrategias de precios, surtido de productos y campañas de marketing.
- Estudios de mercado: los datos del comercio electrónico proporcionan información valiosa sobre las tendencias del mercado, las preferencias de los consumidores y las pautas de la demanda. Puede utilizar esa información como fuente de un proceso de análisis de datos para estudiar las tendencias emergentes y comprender el comportamiento de los clientes.
- Análisis de sentimientos: mediante el raspado web de las opiniones de los clientes de los sitios de comercio electrónico, puede obtener información sobre la satisfacción de los clientes, los comentarios sobre los productos y las áreas de mejora.
En lo que respecta al raspado web de comercio electrónico, eBay es una de las opciones más populares por al menos tres buenas razones:
- Tiene una amplia gama de productos.
- Se basa en un sistema de subastas y pujas que permite recuperar muchos más datos que Amazon y plataformas similares.
- Tiene varios precios para los mismos productos (¡Subasta + Cómpralo ya!).
Al extraer datos de eBay, se puede acceder a una gran cantidad de información para apoyar una estrategia de seguimiento, comparación o análisis de precios.
Bibliotecas y herramientas de raspado web en eBay
Python está considerado como uno de los mejores lenguajes para raspar datos gracias a su facilidad de uso, sintaxis sencilla y amplio ecosistema de librerías. Por lo tanto, será el lenguaje de programación elegido para raspar datos en eBay. Explore nuestra guía extensa sobre cómo hacer raspado web con Python.
Ahora tiene que elegir las bibliotecas de raspado web adecuadas entre las muchas disponibles. Para tomar la decisión correcta, explore eBay en el navegador. Al inspeccionar las llamadas AJAX realizadas por la página, te darás cuenta de que la mayoría de los datos del sitio están incrustados en el documento HTML devuelto por el servidor.
Esto significa que serán suficientes un simple cliente HTTP para replicar la petición al servidor y un analizador HTML. Por esta razón, recomendamos:
- Requests: la librería cliente HTTP más popular para Python. Simplifica el proceso de envío de peticiones HTTP y el manejo de sus respuestas, facilitando la recuperación del contenido de las páginas desde los servidores web.
- Beautiful Soup: una biblioteca de Python con todas las funciones de análisis de HTML y XML. Se utiliza sobre todo para el raspado web, ya que proporciona métodos potentes para explorar el DOM y extraer datos de sus elementos.
Gracias a Requests y Beautiful Soup es posible hacer raspado web del sitio objetivo con Python. ¡Veamos cómo!
Extracción de datos de productos de eBay con Beautiful Soup
Siga este tutorial paso a paso y aprenda a construir un script Python de raspado web de eBay.
Paso 1: Empezar
Para implementar el raspado de precios, se necesita cumplir estos prerrequisitos:
- Python 3+ instalado en su ordenador: Descargue el instalador, ejecútelo y siga el asistente de instalación.
- Un IDE de Python de su elección: Visual Studio Code con la extensión Python o PyCharm Community Edition son dos buenas opciones.
A continuación, inicialice un proyecto Python con un entorno virtual llamado ebay-scraper ejecutando los siguientes comandos:
mkdir ebay-scrapernncd ebay-scrapernnpython -m venv env
Entre en la carpeta del proyecto y añada un archivo scraper.py que contenga el siguiente fragmento de código:
print('Hello, World!')
Este es un script de ejemplo que sólo imprime “¡Hola, mundo!” pero que pronto contendrá la lógica para raspar eBay.
Comprueba que funciona ejecutándolo con:
python scraper.py
En el terminal, debería verse:
Hello, World!
Genial, ¡ya tiene un proyecto Python!
Paso 2: Instalar las librerías de raspado web
Es hora de añadir las librerías necesarias para realizar el raspado web a las dependencias de su proyecto. Ejecute el siguiente comando en la carpeta del proyecto para instalar los paquetes Beautiful Soup y Requests:
pip install beautifulsoup4 requests
Importe las librerías en scraper.py y prepárese para usarlas para extraer datos de eBay:
import requestsnnfrom bs4 import BeautifulSoupnn# scraping logic...
Asegúrese de que su IDE de Python no informa de ningún error, ¡y ya está listo para implementar la monitorización de precios con raspado web!
Paso 3: Descargar la página web de destino
Si es usuario de eBay, se habrá dado cuenta de que la URL de la página del producto sigue el siguiente formato:
https://www.ebay.com/itm/u003cITM_IDu003e
Como se puede ver, se trata de una URL dinámica que cambia en función del ID del artículo.
Por ejemplo, ésta es la URL de un producto de eBay:
https://www.ebay.com/itm/225605642071?epid=26057553242u0026hash=item348724e757:g:~ykAAOSw201kD1unu0026amdata=enc%3AAQAIAAAA4OMICjL%2BH6HBrWqJLiCPpCurGf8qKkO7CuQwOkJClqK%2BT2B5ioN3Z9pwm4r7tGSGG%2FI31uN6k0IJr0SEMEkSYRrz1de9XKIfQhatgKQJzIU6B9GnR6ZYbzcU8AGyKT6iUTEkJWkOicfCYI5N0qWL8gYV2RGT4zr6cCkJQnmuYIjhzFonqwFVdYKYukhWNWVrlcv5g%2BI9kitSz8k%2F8eqAz7IzcdGE44xsEaSU2yz%2BJxneYq0PHoJoVt%2FBujuSnmnO1AXqjGamS3tgNcK5Tqu36QhHRB0tiwUfAMrzLCOe9zTa%7Ctkp%3ABFBMmNDJgZJi
Aquí, 225605642071 es el identificador único del artículo. Tenga en cuenta que los parámetros de consulta no son necesarios para visitar la página. Puede eliminarlos e eBay seguirá cargando la página del producto correctamente.
En lugar de codificar la página de destino en el script, puede hacer que consulte el ID del artículo desde un argumento de la línea de comandos. De esta manera, se podría raspar los datos de cualquier página de producto.
Para ello, actualice scraper.py como se indica a continuación:
import requestsnnfrom bs4 import BeautifulSoupnnimport sysnn# if there are no CLI parametersnnif len(sys.argv) u003c= 1:nn print('Item ID argument missing!')nn sys.exit(2)nn# read the item ID from a CLI argumentnnitem_id = sys.argv[1]nn# build the URL of the target product pagennurl = f'https://www.ebay.com/itm/{item_id}'nn# scraping logic...nnAssume you want to scrape the product 225605642071. You can launch your scraper with:nnpython scraper.py 225605642071
Gracias a sys, puedes acceder a los argumentos de la línea de comandos. El primer elemento de sys.argv es el nombre de tu script, scraper.py. Para obtener el ID del elemento, debes apuntar al elemento con índice 1.
Si olvida el ID del elemento en la CLI, la aplicación fallará con el siguiente error:
Item ID argument missing!
De lo contrario, consultará el parámetro CLI y lo utilizará en una cadena f para generar la URL de destino del producto a raspar. En este caso, la URL contendrá:
nhttps://www.ebay.com/itm/225605642071
Ahora, puede utilizar requests para descargar esa página web con la siguiente línea de código:
page = requests.get(url)
Detrás del telón, request.get() realiza una petición HTTP GET a la URL pasada como parámetro. page almacenará la respuesta producida por el servidor de eBay, incluyendo el contenido HTML de la página de destino.
¡Fantástico! Aprendamos a recuperar datos de ella.
Paso 4: Analizar el documento HTML
page.text contiene el documento HTML devuelto por el servidor. Pásalo al constructor BeautifulSoup() para analizarlo:
soup = BeautifulSoup(page.text, 'html.parser')
El segundo parámetro especifica el analizador utilizado por Beautiful Soup. Si no le es familiar, html.parser es el nombre del analizador HTML incorporado en Python.
La variable soup almacena ahora una estructura de árbol que expone algunos métodos útiles para seleccionar elementos del DOM. Los más populares son:
- find(): Devuelve el primer elemento HTML que coincida con la condición del selector pasada como parámetro.
- find_all(): Devuelve una lista de elementos HTML que coinciden con la estrategia del selector de entrada.
- select_one(): Devuelve los elementos HTML que coinciden con el selector CSS de entrada.
- select(): Devuelve una lista de elementos HTML que coinciden con el selector CSS pasado como parámetro.
Utilízalos para seleccionar elementos HTML por etiqueta, ID, clases CSS, etc. A continuación, puedes extraer datos de sus atributos y contenido de texto. Ver cómo
Paso 5: Inspeccionar la página del producto
Si desea estructurar una estrategia de raspado de datos eficaz, primero debe familiarizarse con la estructura de las páginas web de destino. Abra su navegador y visite algunos productos de eBay.
Lo primero que notará es que, dependiendo de la categoría del producto, la página contiene información diferente. En los productos electrónicos, tendrá acceso a las especificaciones técnicas.

Cuando visite productos de ropa, podrá ver las tallas y colores disponibles.

Estas incoherencias en la estructura de las páginas web dificultan un poco el raspado. Sin embargo, algunos campos de información están en cada página, como los precios de los productos y de los envíos.
Familiarícese también con las DevTools de su navegador. Haga clic con el botón derecho en un elemento HTML que contenga datos interesantes y seleccione “Inspeccionar”. Se abrirá la siguiente ventana:
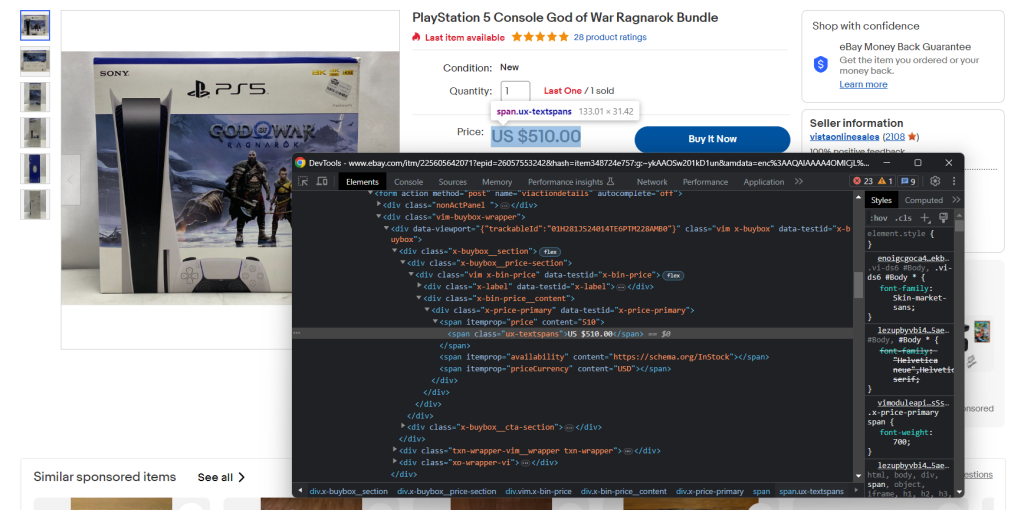
Aquí podrá explorar la estructura DOM de la página y comprender cómo definir estrategias de selección eficaces.
Dedique algún tiempo a inspeccionar las páginas de productos con las DevTools.
Paso 6: Extraer los datos de precios
En primer lugar, necesitas una estructura de datos donde almacenar los datos a raspar. Inicializa un diccionario Python con:
item = {}
Como habrá notado en el paso anterior, los datos de precios están en esta sección:

Inspeccione el elemento HTML precio:
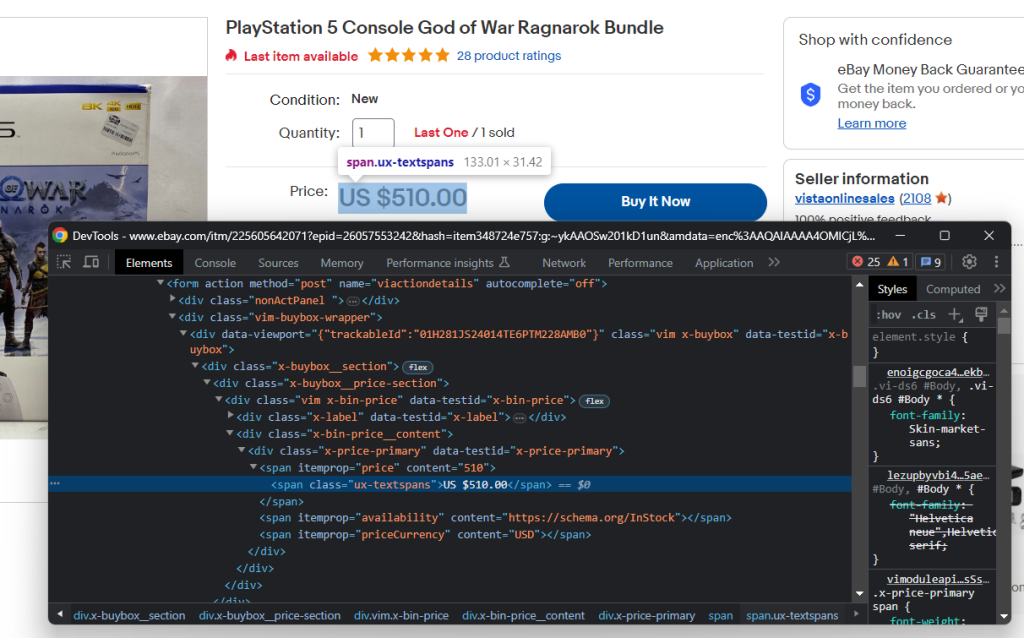
Puede obtener el precio del producto con el siguiente selector CSS:
.x-price-primary span[itemprop=u0022priceu0022]nnAnd the currency with:nn.x-price-primary span[itemprop=u0022priceCurrencyu0022]nnApply those selectors in Beautiful Soup and retrieve the desired data with:nnprice_html_element = soup.select_one('.x-price-primary span[itemprop=u0022priceu0022]')nnprice = price_html_element['content']nncurrency_html_element = soup.select_one('.x-price-primary span[itemprop=u0022priceCurrencyu0022]')nncurrency = currency_html_element['content']
Este fragmento selecciona los elementos HTML de precio y moneda y luego recoge la cadena contenida en su atributo content.
Tenga en cuenta que el precio raspado anteriormente es sólo una parte del precio total que tendrá que pagar para obtener el artículo que desea. También incluye los gastos de envío.
Inspeccione el elemento de envío:
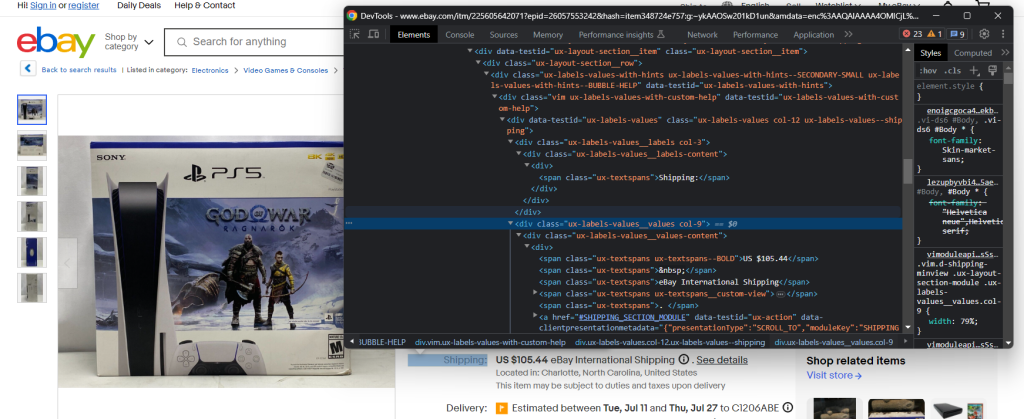
Esta vez, extraer los datos deseados es un poco más complicado ya que no hay un selector CSS fácil para obtener el elemento. Lo que puedes hacer es iterar sobre cada div .ux-labels-values__labels. Cuando el elemento actual contiene la cadena “Shipping:”, puede acceder al siguiente hermano en el DOM y extraer el precio de .ux-textspans–BOLD:
Your Code Here...
El elemento de precio de envío contiene los datos deseados en el siguiente formato:
US $105.44
Para extraer el precio, puede utilizar una regex con el método re.findall(). No olvide añadir la siguiente línea en la sección de importación de su script:
import re nnAdd the collected data to the item dictionary:nnitem['price'] = pricennitem['shipping_price'] = shipping_pricennitem['currency'] = currencynnPrint it with:nnprint(item)nnAnd you will get:nn{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}
Esto es suficiente para implementar un proceso de seguimiento de precios en Python. Sin embargo, hay mucha más información útil en la página de producto de eBay. Así que vale la pena aprender a extraerla.
Paso 7: Recuperar los detalles del artículo
Si echa un vistazo a la pestaña “Acerca de este artículo”, se dará cuenta de que contiene muchos datos interesantes:
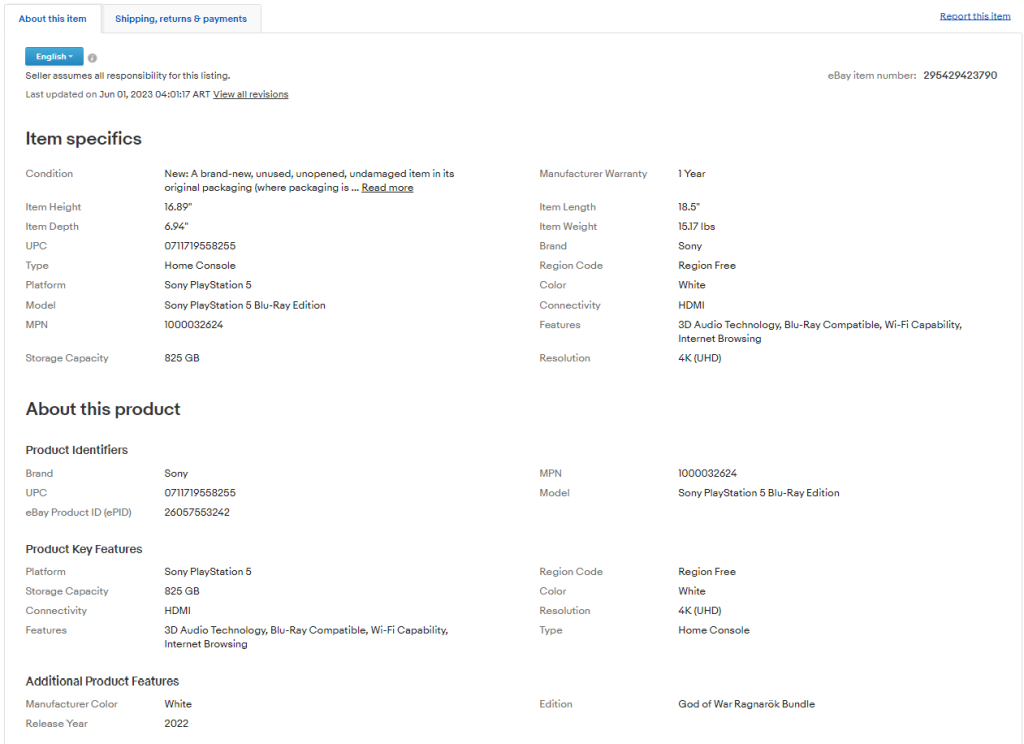
Las secciones y los campos que contienen cambian de un producto a otro, por lo que es necesario encontrar la forma de rasparlos todos con un enfoque inteligente.
En concreto, las secciones más importantes son “Datos específicos del artículo” y “Acerca de este producto”. Estas dos están presentes en la mayoría de los productos. Inspeccione una de las dos y observe que puede seleccionarlas con el:
.section-title
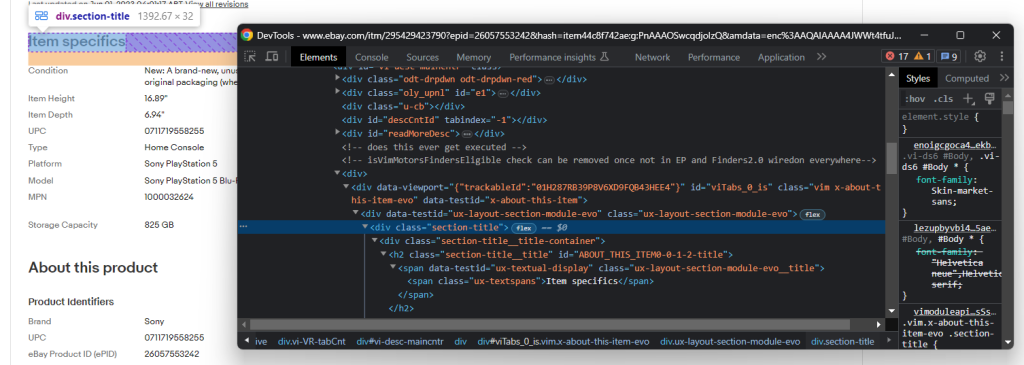
Dada una sección, explore su estructura DOM:
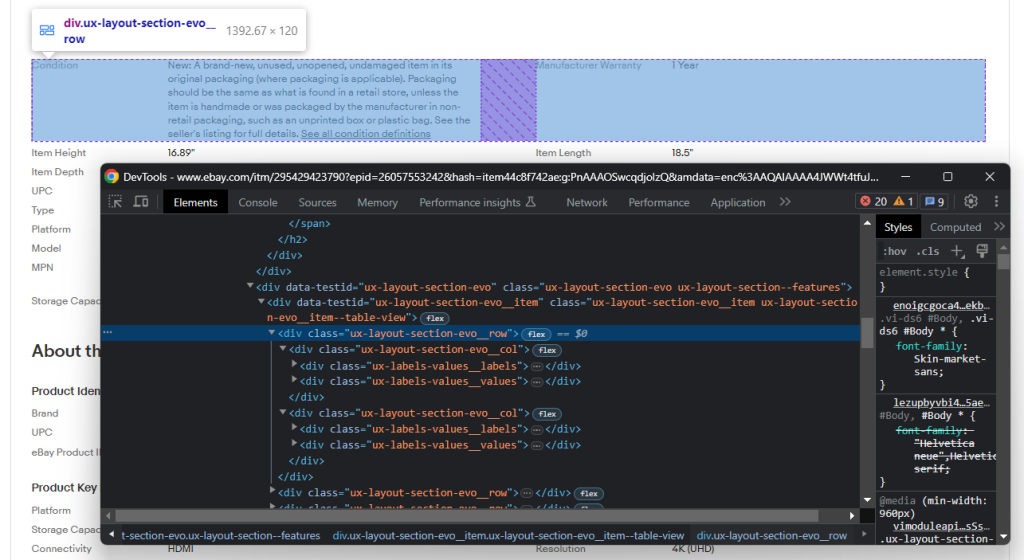
Observe que consta de varias filas, cada una con algunos elementos .ux-layout-section-evo__col. Éstos contienen dos elementos:
- .ux-labels-values__labels: El nombre del atributo.
- .ux-labels-values__labels: El nombre del atributo.
Ya es posible extraer toda la información de la sección de detalles mediante programación:
section_title_elements = soup.select('.section-title')nnfor section_title_element in section_title_elements:nn if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:nn # get the parent element containing the entire sectionnn section_element = section_title_element.parentnn for section_col in section_element.select('.ux-layout-section-evo__col'):nn print(section_col.text)nn col_label = section_col.select_one('.ux-labels-values__labels')nn col_value = section_col.select_one('.ux-labels-values__values')nn # if both elements are presentnn if col_label is not None and col_value is not None:nn item[col_label.text] = col_value.text
Este código recorre cada elemento HTML del campo de detalle y añade el par clave-valor asociado a cada atributo del producto al diccionario del elemento.
Al final del bucle for, item contendrá:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD', 'Condition': u0022New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details. See all condition definitionsopens in a new window or tab u0022, 'Manufacturer Warranty': '1 Year', 'Item Height': '16.89u0022', 'Item Length': '18.5u0022', 'Item Depth': '6.94u0022', 'Item Weight': '15.17 lbs', 'UPC': '0711719558255', 'Brand': 'Sony', 'Type': 'Home Console', 'Region Code': 'Region Free', 'Platform': 'Sony PlayStation 5', 'Color': 'White', 'Model': 'Sony PlayStation 5 Blu-Ray Edition', 'Connectivity': 'HDMI', 'MPN': '1000032624', 'Features': '3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing', 'Storage Capacity': '825 GB', 'Resolution': '4K (UHD)', 'eBay Product ID (ePID)': '26057553242', 'Manufacturer Color': 'White', 'Edition': 'God of War Ragnarök Bundle', 'Release Year': '2022'}
¡Maravilloso! Alcanzó su objetivo de recuperación de datos.
Paso 8: Exportar los datos obtenidos a JSON
En este momento, los datos obtenidos se almacenan en un diccionario Python. Para hacerlos más fáciles de compartir y leer, puedes exportarlos a JSON con:
import jsonnn# scraping logic...nnwith open('product_info.json', 'w') as file:nn json.dump(item, file)
Primero, necesita inicializar un archivo product_info.json con open(). A continuación, puede escribir la representación JSON del diccionario de elementos en el archivo de salida con json.dump(). Echa un vistazo a nuestro artículo para aprender más sobre cómo analizar y serializar datos para JSON en Python.
El paquete json viene de Python Standard Library, así que ni siquiera necesitas instalar una dependencia extra para lograr el objetivo.
¡Genial! Ha comenzado con datos brutos contenidos en una página web y ahora tiene datos JSON semiestructurados. Es hora de echar un vistazo a todo el raspador de eBay.
Paso 9: Conjuntando todo
Paso 9: Conjuntando todo
Your Code Here...
Aquí está el script scraper.py completo:
Como ejemplo, láncelo contra el artículo identificado por el ID 225605642071 con:
python scraper.py 225605642071
Al final del proceso, el archivo product_info.json aparecerá en la carpeta raíz de tu proyecto:
{nn u0022priceu0022: u0022499.99u0022,nn u0022shipping_priceu0022: u002272.58u0022,nn u0022currencyu0022: u0022USDu0022,nn u0022Conditionu0022: u0022New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full detailsu0022,nn u0022Manufacturer Warrantyu0022: u00221 Yearu0022,nn u0022Item Heightu0022: u002216.89"u0022,nn u0022Item Lengthu0022: u002218.5"u0022,nn u0022Item Depthu0022: u00226.94"u0022,nn u0022Item Weightu0022: u002215.17 lbsu0022,nn u0022UPCu0022: u00220711719558255u0022,nn u0022Brandu0022: u0022Sonyu0022,nn u0022Typeu0022: u0022Home Consoleu0022,nn u0022Region Codeu0022: u0022Region Freeu0022,nn u0022Platformu0022: u0022Sony PlayStation 5u0022,nn u0022Coloru0022: u0022Whiteu0022,nn u0022Modelu0022: u0022Sony PlayStation 5 Blu-Ray Editionu0022,nn u0022Connectivityu0022: u0022HDMIu0022,nn u0022MPNu0022: u00221000032624u0022,nn u0022Featuresu0022: u00223D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsingu0022,nn u0022Storage Capacityu0022: u0022825 GBu0022,nn u0022Resolutionu0022: u00224K (UHD)u0022,nn u0022eBay Product ID (ePID)u0022: u002226057553242u0022,nn u0022Manufacturer Coloru0022: u0022Whiteu0022,nn u0022Editionu0022: u0022God of War Ragnarok Bundleu0022,nn u0022Release Yearu0022: u00222022u0022nn}
¡Enhorabuena! ¡Acabas de aprender a raspar eBay en Python!
Conclusión
En esta guía, se demostró por qué eBay es uno de los mejores objetivos de raspado web para rastrear los precios de los productos y cómo lograrlo. En detalle, hemos enseñado a construir un raspador en Python que puede recuperar datos de artículos en un tutorial paso a paso. Como se muestra aquí, no es complejo y sólo requiere unas pocas líneas de código.
Al mismo tiempo, hemos mostrado lo inconsistente que es la estructura de las páginas de Ebay. Por lo tanto, el raspador construido aquí podría funcionar para un producto pero no para otro. Además, la interfaz de usuario de eBay cambia a menudo, lo que le obliga a mantener continuamente el script. Afortunadamente, ¡puede evitar esto con nuestro raspador de eBay!
Si desea ampliar su proceso de raspado y extraer precios de otras plataformas de comercio electrónico, tenga en cuenta que muchas de ellas dependen en gran medida de JavaScript. Cuando se trata de estos sitios, un enfoque tradicional basado en un analizador HTML no funcionará. En su lugar, necesita una herramienta que pueda procesar JavaScript y sea capaz de gestionar automáticamente las huellas dactilares, los CAPTCHA y los reintentos automatizados. ¡Esto es exactamente de lo que trata nuestra nueva solución Scraping Browser!
¿No quiere ocuparse en absoluto del raspado web de eBay pero le interesan los datos de los artículos? Compre un conjunto de datos de eBay.


