

Si te interesa el scraping web, es fundamental comprender el lenguaje HTML, ya que todos los sitios web están construidos con él. El scraping web se puede utilizar en todo tipo de situaciones y puede ayudar a recopilar datos de sitios web sin API, supervisar los precios de los productos, crear listas de clientes potenciales, realizar investigaciones académicas y mucho más.
En este artículo, aprenderás los conceptos básicos de HTML y cómo extraer, realizar parseo y procesar datos utilizando Python.
¿Te interesa una guía detallada sobre el Scraping web con Python? Haz clic aquí.
Cómo extraer datos de sitios web y extraer HTML
Antes de comenzar este tutorial, dediquemos un momento a repasar los componentes esenciales del HTML.
Introducción al HTML
El HTML es un conjunto de etiquetas que indican al navegador la estructura y los elementos de un sitio web. Por ejemplo,<h1> Texto </h1>indica al navegador que el texto que sigue a la etiqueta es un encabezado, y<a href=""> enlace </a>identifica un hipervínculo.
Un atributo HTML proporciona información adicional sobre una etiqueta. Por ejemplo, el atributohrefde la etiqueta<a> </a>te da información sobre la URL de la página a la que apunta el atributo.
Las clases y los IDson atributos fundamentales para identificar con precisión los elementos de una página. Las clases agrupan elementos similares para darles un estilo coherente mediante CSS o manipularlos de manera uniforme con JavaScript. Las clases se seleccionan utilizando.class-name.
En el sitio web W3Schools, los grupos de clases tienen este aspecto:
<div class="city">
<h2>Londres</h2>
<p>Londres es la capital de Inglaterra.</p>
</div>
<div class="city">
<h2>París</h2>
<p>París es la capital de Francia.</p>
</div>
<div class="city">
<h2>Tokio</h2>
<p>Tokio es la capital de Japón.</p>
</div>
Puedes ver cómo cada título y bloque de ciudad está envuelto con un div que tiene la misma clase de ciudad.
Por el contrario, los ID son únicos para cada elemento (es decir, dos elementos no pueden tener el mismo ID). Por ejemplo, los siguientes H1 tienen ID únicos y se pueden diseñar/manipular de forma única:
<h1 id="header1">¡Hola, mundo!</h1>
<h1 id="header2">Lorem Ipsum Dolor</h1>
La sintaxis para seleccionar elementos con ID es #id-name.
Ahora que ya conoce los conceptos básicos de HTML, comencemos con el Scraping web.
Configura tu entorno de scraping
Este tutorial utiliza Python, ya que ofrece muchas bibliotecas de scraping de HTML y el lenguaje es fácil de aprender. Para comprobar si Python está instalado en tu ordenador, ejecuta el siguiente comando en PowerShell (Windows) o en tu terminal (macOS):
python3
Si Python está instalado, verás el número de versión; si no lo está, recibirás un error. Continúa einstala Pythonsi aún no lo tienes.
A continuación, crea una carpeta llamadaWebScrapery crea un archivo dentro de la carpetaWebScraperllamadoscraper.py. A continuación, ábrelo en el entorno de desarrollo integrado (IDE) que prefieras. Aquí se utilizaVisual Studio Code:
Un IDE es una aplicación multipropósito que permite a los programadores escribir código, depurarlo, probar programas, crear automatizaciones y mucho más. Aquí lo usarás para codificar tu Scraper HTML.
A continuación, debe separar su instalación global de Python de su proyecto de scraping creando un entorno virtual. Esto ayuda a evitar conflictos de dependencias y mantiene toda la aplicación organizada.
Para ello, instala la biblioteca virtualenv con el siguiente comando:
pip3 install virtualenv
Navega hasta la carpeta de tu proyecto:
cd WebScraper
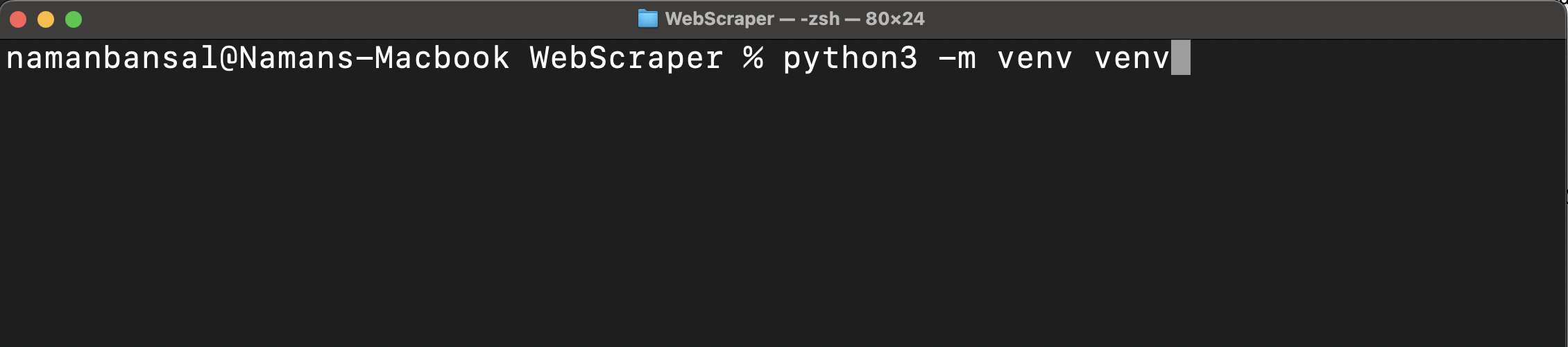
A continuación, cree un entorno virtual:
python<versión> -m venv <nombre-del-entorno-virtual>
Este comando crea una carpeta para todos los paquetes y scripts dentro de la carpeta de tu proyecto:
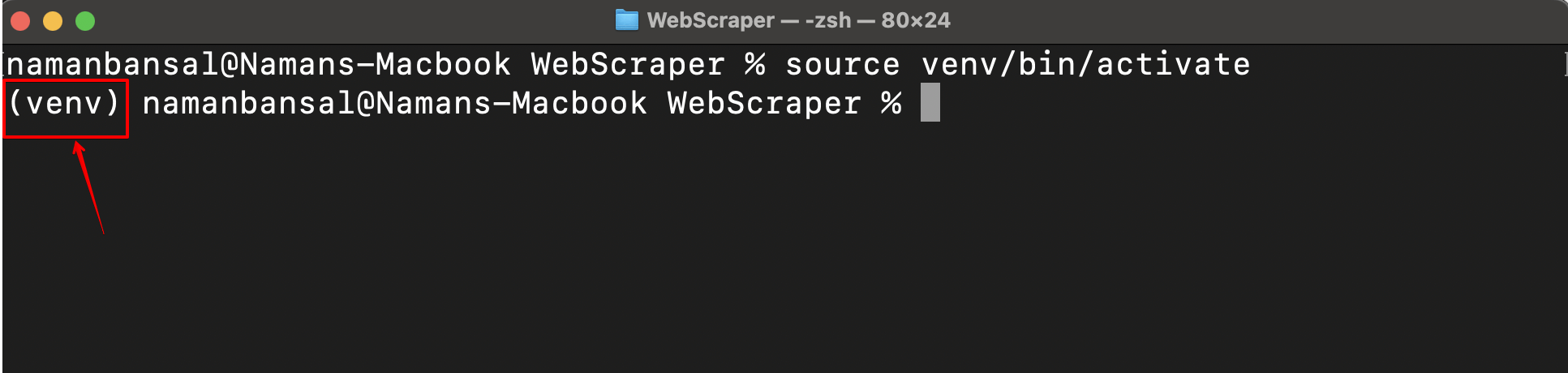
Ahora, debe activar el entorno virtual utilizando uno de los siguientes comandos (según su plataforma):
source <nombre-del-entorno-virtual>/bin/activate #En MacOS y Linux
<nombre-del-entorno-virtual>/Scripts/activate.bat #En CMD
<nombre-del-entorno-virtual>/Scripts/Activate.ps1 #En Powershell
Una vez activado correctamente, verás el nombre de tu entorno virtual en la parte izquierda de la pantalla:
Ahora que su entorno virtual está activado, debe instalar una biblioteca de Scraping web. Existen numerosas opciones, entre ellas Playwright, Selenium, Beautiful Soup y Scrapy. En este caso, utilizará Playwright porque es fácil de usar, es compatible con varios navegadores, puede manejar contenido dinámico y ofrece un modo sin interfaz gráfica (scraping sin interfaz gráfica de usuario (GUI)).
Ejecute pip install pytest-playwright para instalar Playwright; a continuación, instale los navegadores necesarios con playwright install.
Después de instalar Playwright, ya está listo para empezar con el Scraping web.
Extraer HTML de un sitio web
El primer paso de cualquier proyecto de Scraping web es identificar el sitio web que se desea rastrear. Aquí se utiliza este sitio de prueba.
A continuación, debe identificar la información que desea extraer de la página. En este caso, es todo el contenido HTML de la página.
Una vez que haya identificado la información que desea extraer, puede empezar a programar el Scraper. En Python, el primer paso esimportar las bibliotecas necesarias para Playwright. Playwright le permite importar dos tipos de API:sync y async. La biblioteca async se utiliza solo al escribir código asíncrono, por lo que debe importar la biblioteca sync con el siguiente comando:
from playwright.sync_api import sync_playwright
Después de importar la biblioteca sync, debe declarar una función Python utilizando el siguiente fragmento de código:
def main():
#El resto del código estará dentro de esta función
Como puede ver en la nota anterior, debe escribir su código de Scraping web dentro de esta función.
Normalmente, para obtener información de un sitio web, abrirías un navegador web, crearías una nueva pestaña y visitarías ese sitio web. Para extraer el sitio, debes traducir estas acciones a código, que es para lo que utilizarás Playwright. Sudocumentaciónmuestra que puedes llamar a lasync_apiimportada anteriormente y abrir un navegador con este fragmento:
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
Al añadir headless=False entre corchetes, podrás ver el contenido del sitio web.
Después de abrir el navegador, abre una nueva pestaña y visita la URL de destino:
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
Nota: Las líneas anteriores deben añadirse debajo de las líneas anteriores, que iniciaron el navegador. Todo este código va dentro de la función principal y dentro de un archivo.
Este fragmento de código envuelve la funcióngoto()dentro de unbloque try-exceptpara un mejor manejo de errores.
Cuando introduces la URL de un sitio en la barra de búsqueda, tienes que esperar a que se cargue. Para imitar eso en el código, puedes utilizar lo siguiente:
page.wait_for_timeout(7000) #valor en milisegundos entre corchetes
Nota: Estas líneas anteriores deben añadirse debajo de las líneas anteriores.
Por último, es el momento de extraer todo el contenido HTML de la página utilizando esta línea de código:
print(page.content())
El código completo para extraer el HTML de una página tiene este aspecto:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
page.wait_for_timeout(7000)
print(page.content())
main()
En Visual Studio Code, el HTML extraído tiene este aspecto:
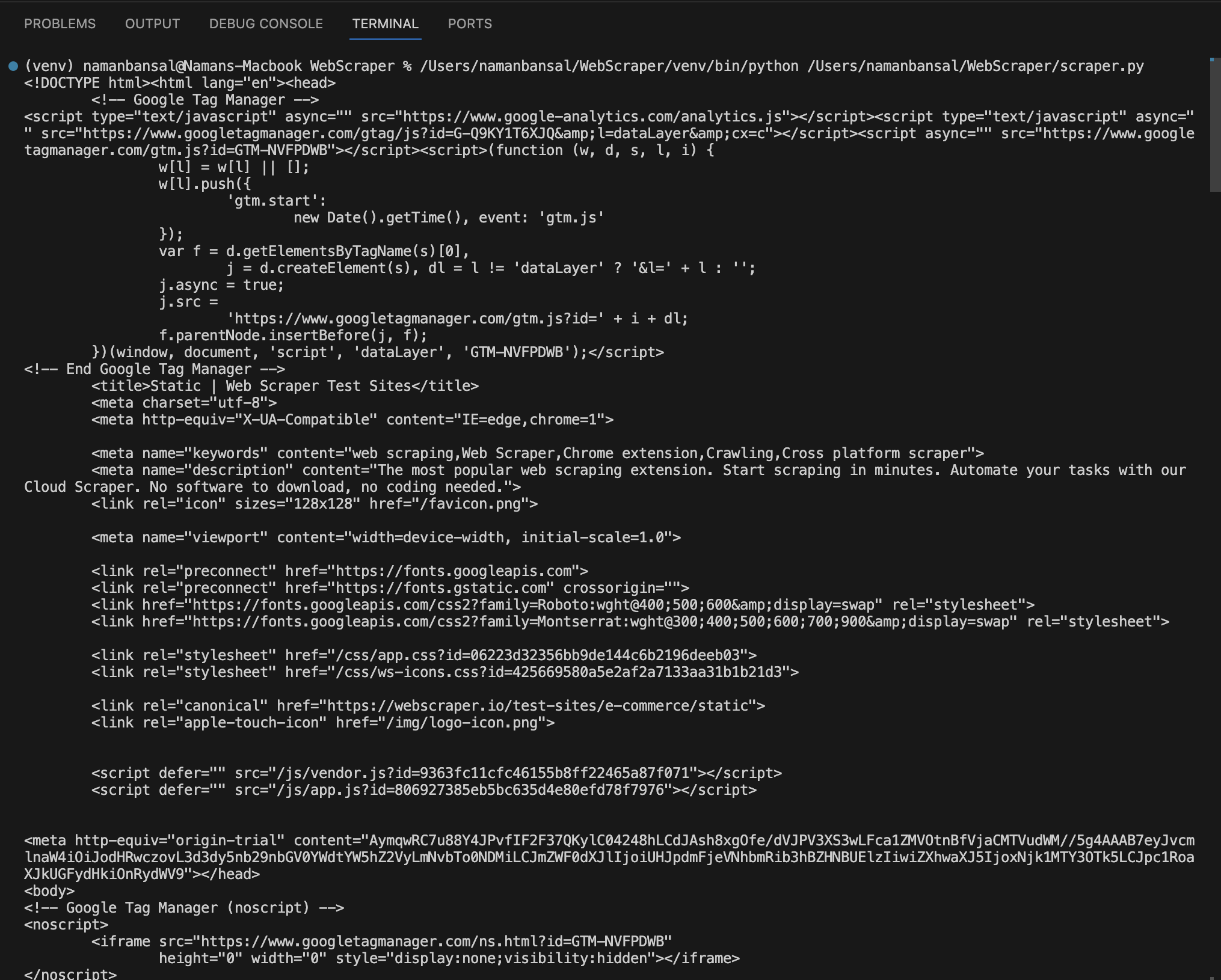
Extraer HTML utilizando atributos específicos
Anteriormente, extrajo todos los elementos de la página web Web Scraper; sin embargo, el Scraping web no es útil a menos que se limite a extraer solo la información que necesita. En esta sección, extraerá solo los títulos de todos los portátiles de la primera página del sitio web:
Para extraer elementos específicos, es necesario comprender la estructura del sitio web de destino. Para ello, haga clic con el botón derecho del ratón y seleccione la opciónInspeccionar, como se muestra a continuación:
También puede utilizar estos atajos de teclado:
- Para macOS, utiliceCmd + Opción + I
- Para Windows, utilizaControl + Mayús + C
Esta es la estructura de la página de destino:
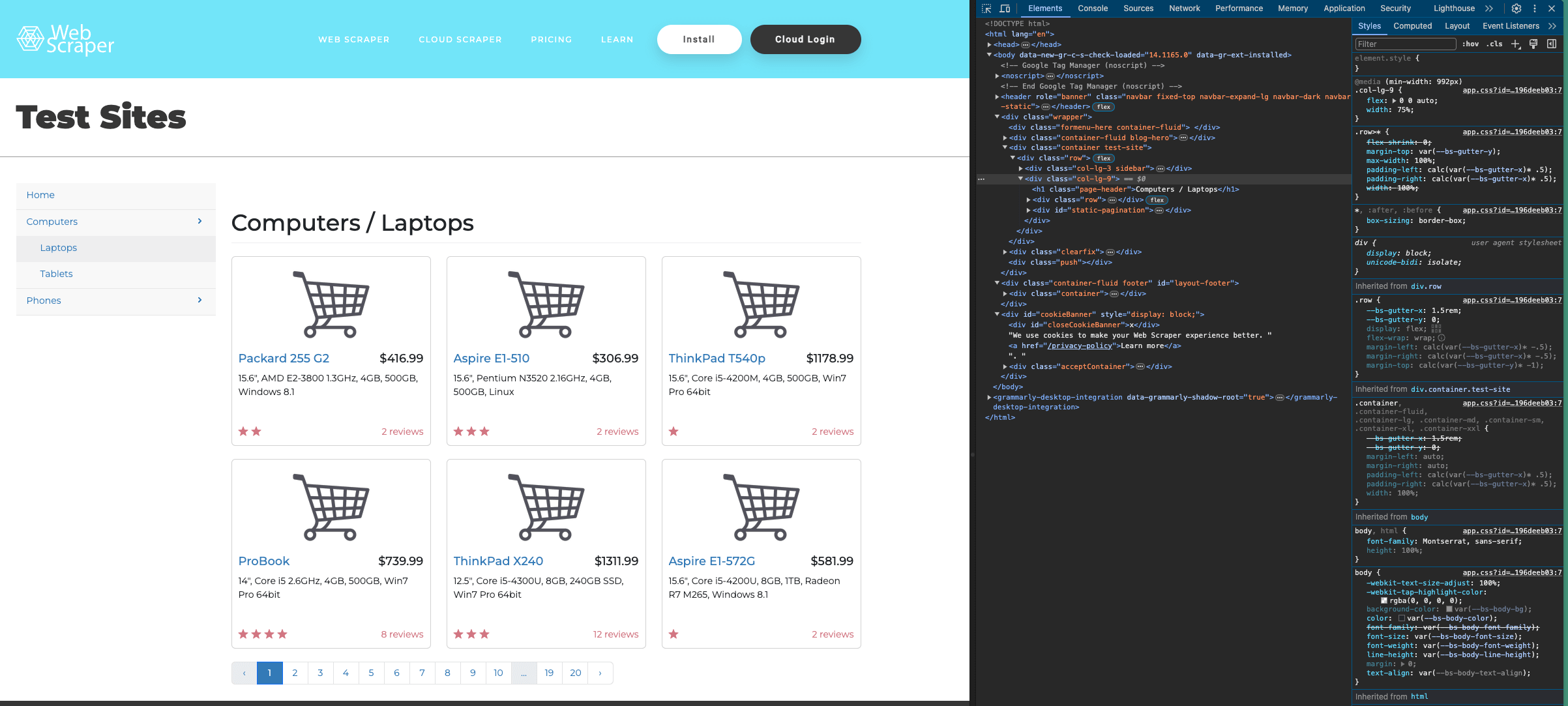
Puede ver el código de un elemento específico de una página utilizando la herramienta de selección situada en la parte superior izquierda de la ventana«Inspeccionar»:

Seleccione uno de los títulos de portátiles en la ventanaInspeccionar:
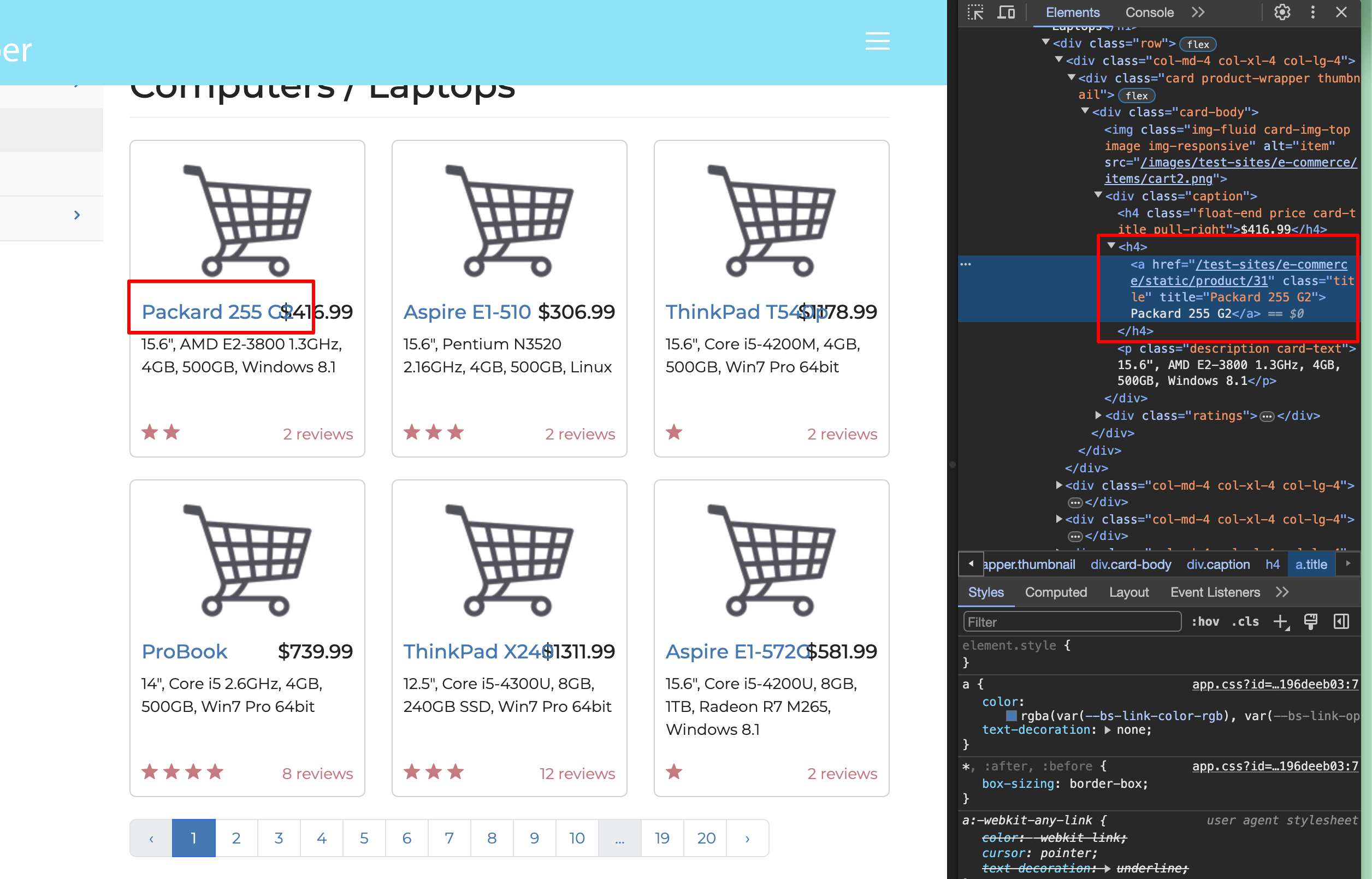
Puede ver que el título se encuentra dentro de una etiqueta <a> </a>, que está envuelta por una etiqueta h4, y que el enlace tiene una clase de título. Eso significa que está buscando etiquetas <a href> (URL) dentro de etiquetas <h4> que tengan una clase de título.
Para crear un programa de scraping que apunte con precisión a estos elementos, debe importar las bibliotecas para crear una función Python, iniciar el navegador y navegar hasta el sitio web de destino:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
Observe que la URL de destino dentro de la función page.goto() se ha actualizado para apuntar a la primera página que contiene la lista de ordenadores portátiles.
Una vez creado el programa de scraping, debe localizar el elemento de destino basándose en el análisis de la estructura de su sitio web. Playwright cuenta con una herramienta llamadalocalizadoresque le permite localizar elementos en una página basándose en diversos atributos, como los siguientes:
get_by_label()localiza el elemento de destino utilizando la etiqueta asociada a un elemento.get_by_text()localiza el elemento de destino utilizando el texto que contiene el elemento.get_by_alt_text()localiza el elemento objetivo y realiza acciones en las imágenes utilizando su texto alternativo.get_by_test_id()localiza el elemento de destino utilizando el ID de prueba de un elemento.
Puede consultarla documentación oficialpara obtener más métodos para localizar elementos.
Para extraer todos los títulos de los portátiles, debe localizar las etiquetas <h4>, ya que envuelven todos los títulos de los portátiles. Puede utilizar el localizador get_by_role() para encontrar elementos en función de su función, como botones, casillas de verificación y encabezados. Esto significa que, para encontrar todos los encabezados de la página, debe escribir lo siguiente:
titles = page.get_by_role("heading").all()
Después, puede imprimirlo en su consola con el siguiente código:
print(titles)
Después de imprimirlo, verás que te da una matriz de elementos:
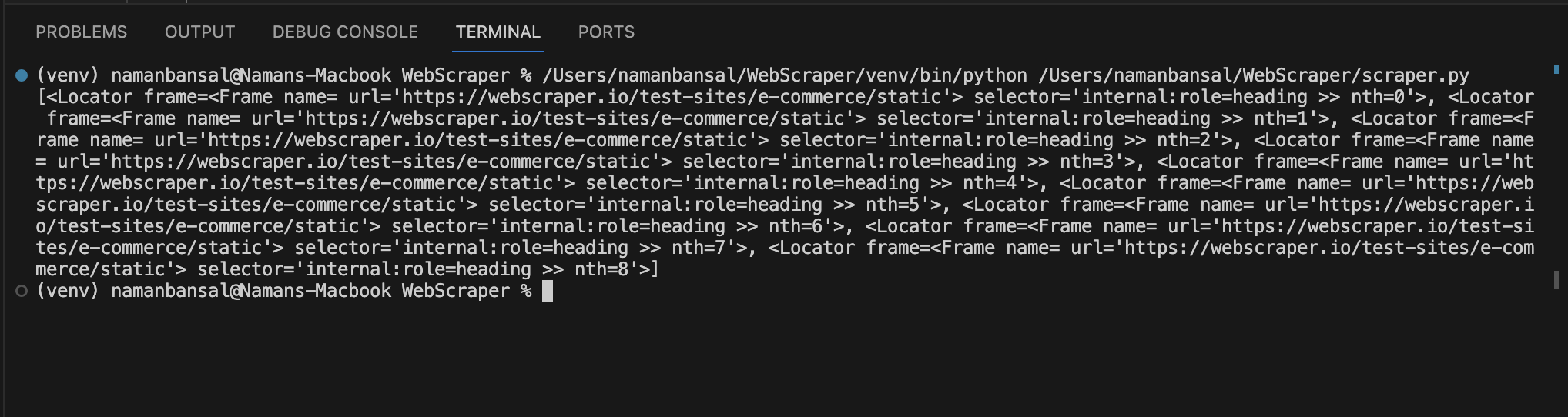
Esta salida no incluye títulos, pero sí hace referencia a elementos que coinciden con las condiciones del selector. Debes recorrer estos elementos para encontrar una etiqueta <a> con una clase de título y el texto que contiene.
Se recomienda utilizar el localizador CSS para encontrar un elemento basado en su ruta y clase, y puede utilizar la función all_inner_texts() para extraer el texto interno de un elemento de esta manera:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
Al ejecutar este código, el resultado debería ser similar al siguiente:
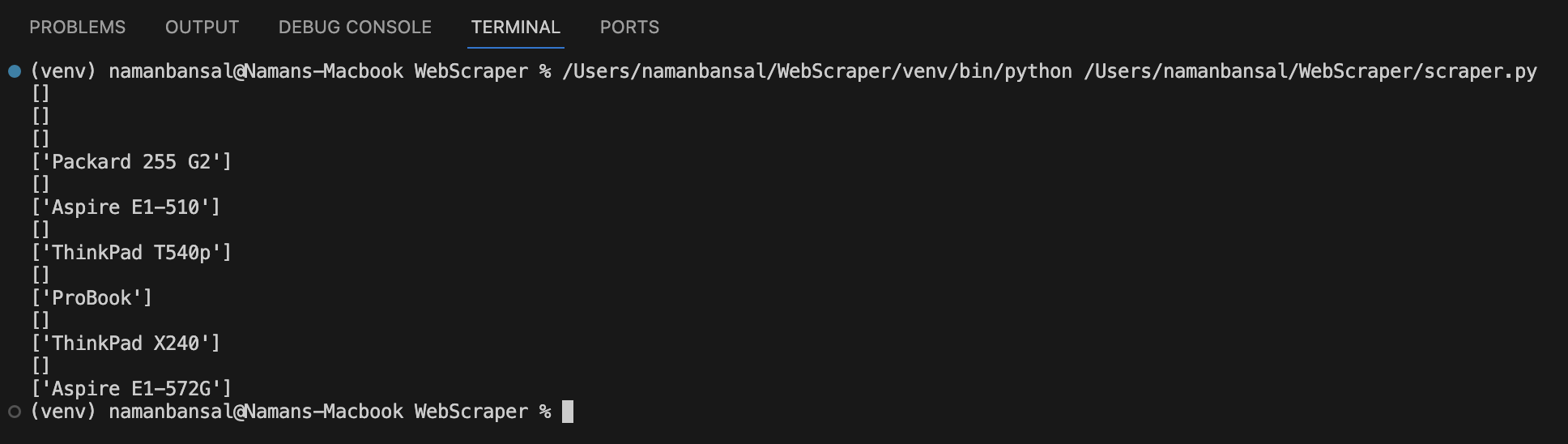
Para rechazar matrices sin valores, escriba lo siguiente:
if len(laptop) == 1:
print(laptop[0])
Una vez que rechaces las matrices sin valores, habrás creado con éxito un programa de scraping que extrae solo elementos específicos.
Este es el código completo para este Scraper:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()
Interactuar con elementos
Ahora vamos a dar un paso más y crear un programa que extraiga los títulos de la primera página que contiene ordenadores portátiles, navegue hasta la segunda página y extraiga también esos títulos.
Como ya sabes cómo extraer títulos de una página, solo tienes que averiguar cómo navegar a la siguiente página de ordenadores portátiles.
Es posible que ya hayas visto los botonesde paginaciónen la página en la que te encuentras actualmente.
Debes localizarel 2y hacer clic en él con tu programa de scraping. Al inspeccionar la página, verás que el elemento requerido es un elemento de lista (etiqueta<li>) y tiene el texto interno2:
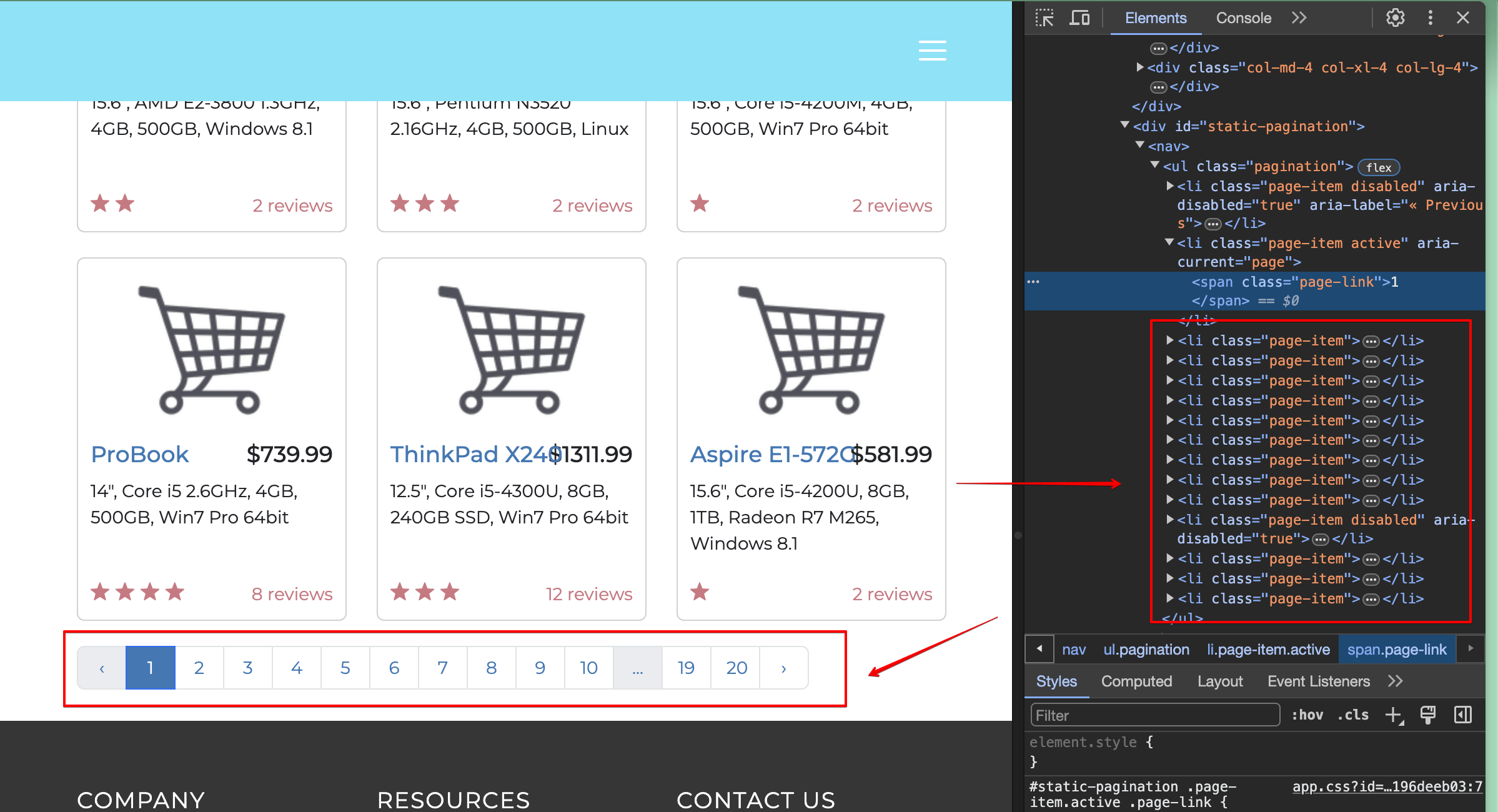
Eso significa que puedes utilizar el selector get_by_role() para encontrar un elemento de la lista y el selector get_by_text() para encontrar un elemento con 2 como texto.
Así es como se codifica en su archivo:
page.get_by_role("listitem").get_by_text("2", exact=True)
Esto encuentra un elemento que cumple dos condiciones: en primer lugar, debe ser un elemento de lista y, en segundo lugar, debe tener 2 como texto.
exact=True es un argumento de función para encontrar el elemento con el texto dado.
Para hacer clic en el botón, modifica el código anterior para que quede así:
page.get_by_role("listitem").get_by_text("2", exact=True).click()
En este código, la función click() hace clic en el elemento dado.
Espere a que se cargue la página y extraiga todos los títulos de nuevo:
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
Tu bloque de código completo debería tener este aspecto:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
page.get_by_role("listitem").get_by_text("2", exact=True).click()
página.esperar_tiempo_de_espera(5000)
títulos = página.obtener_por_rol("encabezado").todos()
para título en títulos:
ordenador portátil = título.localizador("a.title").todos_textos_internos()
si len(ordenador portátil) == 1:
imprimir(ordenador portátil[0])
main()
Extraer HTML y escribirlo en un CSV
Si no almacenas y analizas los datos que extraes, no sirven de nada. En esta sección, crearás un programa avanzado que toma la entrada del usuario para el número de páginas de portátiles que se van a extraer, extrae los títulos y los almacena en un archivo CSV en la carpeta de tu proyecto.
Para este programa, necesitas una biblioteca CSV preinstalada, que se puede importar con el siguiente comando:
import csv
Una vez instalada la biblioteca CSV, debes averiguar cómo visitarás un número variable de páginas en función de la entrada del usuario.
Si observa la estructura de la URL del sitio web, verá que cada página de ordenadores portátiles se indica mediante un parámetro de URL. Por ejemplo, la URL de la segunda página del directorio de ordenadores portátiles es https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2.
Puede visitar diferentes páginas modificando el parámetro URL ?page=2 con diferentes valores numéricos. Eso significa que debe pedir al usuario que introduzca el número de páginas que desea rastrear con el siguiente comando:
pages = int(input("introduzca el número de páginas que desea extraer: "))
Para visitar cada página desde la 1 hasta el número de páginas introducido por el usuario, utiliza un bucle «for» como este:
for i in range(1, páginas+1):
Dentro de esta función de rango, utiliza 1 y páginas+1 como argumentos de la función para representar los valores en los que comienza y termina el bucle. El segundo argumento de la función se excluye del bucle. Por ejemplo, si la función de rango es rango(1,5), el programa solo haría un bucle del 1 al 4.
A continuación, debe visitar cada página introduciendo el valoricomo parámetro URL en la iteración. Puede añadir variables a una cadena utilizandocadenas f de Python.
Al generar una cadena, antepone una f a las comillas para indicar que se trata de una cadena f. Dentro de las comillas, puede utilizar llaves para indicar variables.
A continuación se muestra un ejemplo de cómo se pueden utilizar las cadenas f para imprimir variables junto con cadenas:
print(f"El valor de la variable es {nombre_de_la_variable_aquí}")
Volviendo al Scraper, puede utilizar cadenas f escribiendo este bloque de código en el archivo:
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
Espera a que se cargue la página con una función de tiempo de espera y extrae los títulos utilizando lo siguiente:
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
Una vez que tengas todos los elementos del título, debes abrir tu archivo CSV, recorrer cada título, extraer el texto requerido y escribirlo en tu archivo.
Para abrir un archivo CSV, utilice la siguiente sintaxis:
with open("laptops.csv", "a") as csvfile:
Aquí, está abriendo el archivolaptops.csvcon el modo de añadir (a). Utiliza el modo de añadir porque no quiere perder los datos antiguos cada vez que se abre el archivo. Si el archivo no existe, la biblioteca crea uno en la carpeta del proyecto.CSV ofrece varios modospara abrir un archivo, entre los que se incluyen los siguientes:
- res la opción predeterminada que se utiliza si no se especifica nada. Abre el archivo en modo de solo lectura.
- wabre un archivo solo para escribir. Cada vez que se abre un archivo, se sobrescriben los datos anteriores.
- aabre un archivo para añadir datos. Los datos anteriores no se sobrescriben.
- r+abre un archivo tanto para lectura como para escritura.
- xcrea un nuevo archivo.
Debajo del código anterior, debedeclarar un objetoescritorque le permita manipular el archivo CSV:
writer = csv.writer(csvfile)
A continuación, recorra cada elemento del título y extraiga el texto con lo siguiente:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
Esto le dará varias matrices, cada una con el título de cada portátil. Para rechazar las matrices vacías, escriba el siguiente código condicional en el archivo CSV:
if len(laptop) == 1:
writer.writerow([laptop[0]])
La función writerow le permite escribir nuevas filas en un archivo CSV.
Aquí está el código completo del programa:
from playwright.sync_api import sync_playwright
import csv
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pages = int(input("enter the number of pages to scrape: "))
for i in range(1, pages+1):
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
página.wait_for_timeout(7000)
títulos = página.get_by_role("heading").all()
con open("laptops.csv", "a") como csvfile:
escritor = csv.writer(csvfile)
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
writer.writerow([laptop[0]])
browser.close()
main()
Después de ejecutar este código, tu archivo CSV debería tener este aspecto:
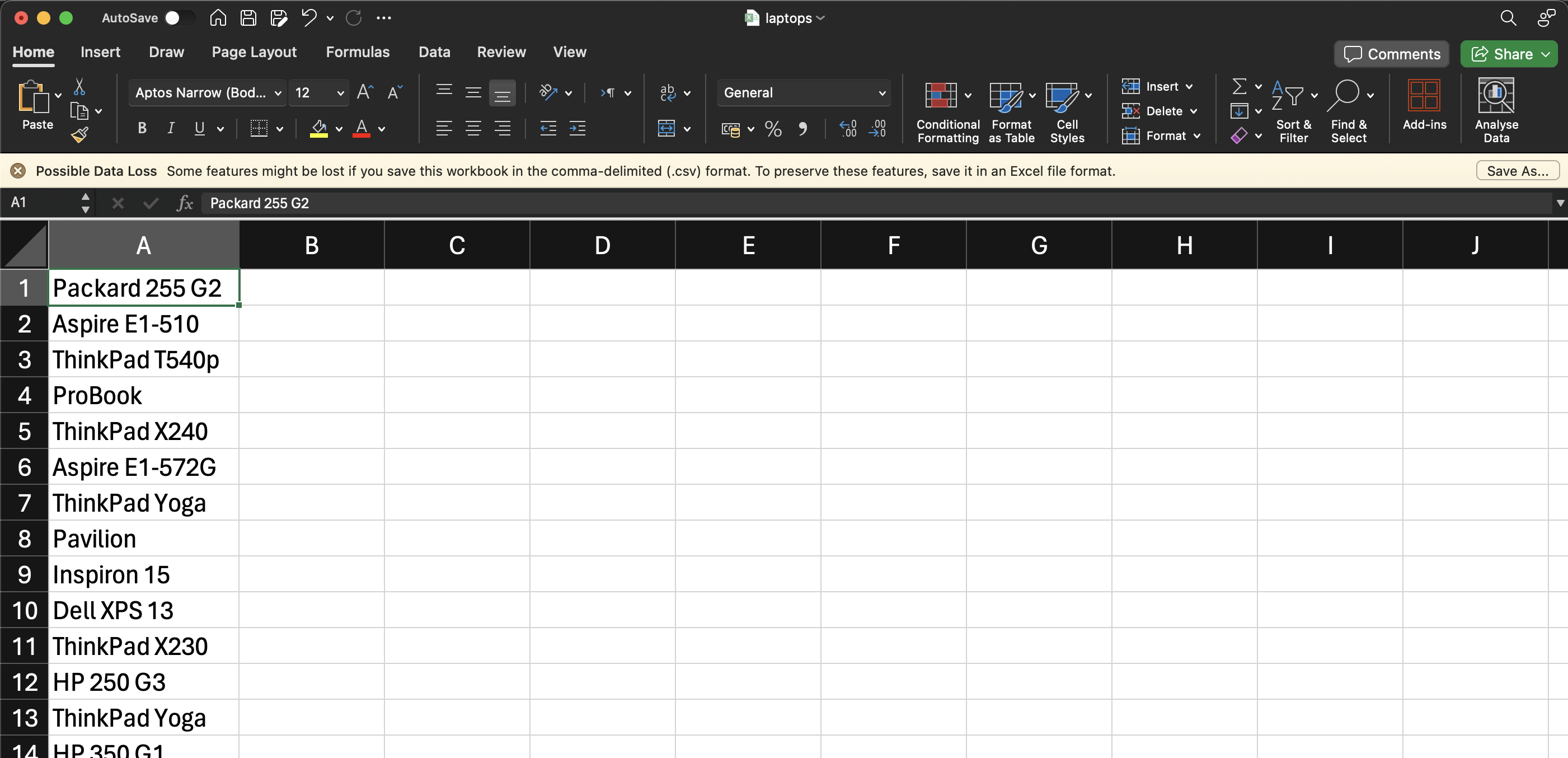
Conclusión
En este artículo, has aprendido a extraer, realizar el parseo y almacenar HTML utilizando Python.
Aunque este tutorial ha sido relativamente sencillo, en un escenario real es probable que te encuentres con varios obstáculos al realizar el scraping, como CAPTCHAs, límites de velocidad, cambios en el diseño del sitio web o requisitos normativos. Afortunadamente,Bright Datapuede ayudarte. Bright Data ofrece herramientas comoProxies residenciales avanzadospara mejorar su scraping, unIDE deWebScraperpara crear Scrapers a gran escala y unWeb Unblockerpara desbloquear sitios web públicos, incluida la Resolución de CAPTCHA. Estas herramientas pueden ayudarle a recopilar datos precisos a gran escala y a superar los obstáculos. Además, el compromiso de Bright Data con el scraping ético le garantiza que cumplirá con los términos de servicio y las normativas legales de los sitios web.
Con la plataforma rica en funciones de Bright Data, puede centrarse en extraer los datos valiosos que necesita, dejando atrás las complejidades del Scraping web. ¡Comience su prueba gratuita hoy mismo!





