

Si lleva tiempo realizando Scraping web, es posible que se haya encontrado con un sitio web bloqueado por una geovalla o una prohibición de IP. Los Proxy le ayudan a sortear estas situaciones, ocultando su verdadera identidad y permitiéndole acceder a recursos prohibidos.
Los servidores ProxyRust facilitan lo siguiente:
- Evitar prohibiciones de IP: una Proxy nueva le permite eludir la prohibición y reanudar el rastreo.
- Eludir los bloqueos geográficos: si le interesa el contenido de otro país, un Proxy local le concede la ciudadanía online temporal, lo que le permite acceder al contenido restringido.
- Aceptar el anonimato: un Proxy oculta su dirección IP real, protegiendo su privacidad de miradas indiscretas.
¡Y eso es solo la punta del iceberg! Las potentes bibliotecas y la sólida sintaxis de Rust hacen que configurar y gestionar proxies sea muy fácil. En este artículo, aprenderás todo sobre los servidores Proxy y cómo usar un servidor Proxy en Rust para el Scraping web.
Uso de un Proxy en Rust
Antes de poder utilizar un Proxy en Rust, debes configurarlo. En este tutorial, configurarás un Proxy en un servidor Nginx en tu máquina local y lo utilizarás para enviar solicitudes de scraping a un sandbox de scraping (como https://toscrape.com/) desde un binario Rust.
Comienza instalando Nginx en tu sistema local. Para Linux, puedes instalarlo utilizando Homebrew con el siguiente comando:
sudo apt install nginxA continuación, inicie el servidor con el siguiente comando:
nginx
A continuación, debe configurar el servidor para que actúe como Proxy para determinadas ubicaciones. Por ejemplo, puede configurarlo para que funcione como Proxy para la ubicación / y añadir un encabezado (es decir, X-Proxy-Server) a cada solicitud que gestione. Para ello, debe editar el archivo nginx.conf.
La ubicación del archivo varía en función del sistema operativo del host. Consulte la documentación de Nginx para obtener ayuda. En Linux, puede encontrar nginx.conf en /etc/nginx/nginx.conf. Ábralo y añada el siguiente bloque de código al objeto http.server del archivo:
http {
server {
# Añada el siguiente bloque
location / {
resolver 8.8.8.8;
Proxy_Pass http://$http_host$request_uri;
Proxy_Set_Header 'X-Proxy-Server' 'Nginx';
}
}
}
Esto configura el Proxy para reenviar todas las solicitudes entrantes a la URL original, al tiempo que añade un encabezado a la solicitud. Si tuviera acceso a los registros del servidor de destino, podría comprobar este encabezado para verificar si la solicitud proviene del Proxy o directamente del cliente.
Ahora, ejecuta el siguiente comando para reiniciar el servidor Nginx:
nginx -s reload
Este servidor ya está listo para utilizarse como Proxy de reenvío para el scraping.
Creación de un proyecto de Scraping web en Rust
Para configurar un nuevo proyecto de scraping, crea un nuevo binario Rust utilizando Cargo ejecutando el siguiente comando:
cargo new rust-scraper
Una vez creado el proyecto, debe añadir tres crates. Para empezar, añada reqwest y Scraper. Utilice reqwest para enviar solicitudes al recurso de destino y Scraper para extraer los datos necesarios del HTML recibido por reqwest. A continuación, añada el tercer crate, tokio, para gestionar las llamadas de red asíncronas a través de reqwest.
Para instalarlos, ejecuta el siguiente comando dentro del directorio del proyecto:
cargo add Scraper reqwest tokio --features "reqwest/blocking tokio/full"
A continuación, abre el archivo src/main.rs y añade el siguiente código:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>>{
let url = "http://books.toscrape.com/";
let client = reqwest::Client::new();
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
fn extract_products(html_content: &str) {
let document = Scraper::Html::parse_document(&html_content);
let html_product_selector = Scraper::Selector::parse("article.product_pod").unwrap();
let html_products = document.select(&html_product_selector);
let mut products: Vec<PRODUCT> = Vec::new();
for html_product in html_products {
let url = html_product
.select(&Scraper::Selector::parse("a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let image = html_product
.select(&Scraper::Selector::parse("img").unwrap())
.next()
.and_then(|img| img.value().attr("src"))
.map(str::to_owned);
let name = html_product
.select(&Scraper::Selector::parse("h3").unwrap())
.next()
.map(|title| title.text().collect::<STRING>());
let price = html_product
.select(&Scraper::Selector::parse(".price_color").unwrap())
.next()
.map(|price| price.text().collect::<STRING>());
let product = Product {
url,
image,
name,
price,
};
products.push(product);
}
println!("{:?}", products);
}
#[derive(Debug)]
struct Product {
url: Option<String>,
image: Option<String>,
name: Option<String>,
price: Option<String>,
}
Este código utiliza el crate reqwest para crear un cliente y obtener la página web en la URL https://books.toscrape.com. A continuación, procesa el HTML de la página dentro de una función titulada extract_products para extraer una lista de productos de la página. La lógica de extracción se implementa utilizando el crate Scraper y permanece sin cambios independientemente de si se utiliza un Proxy o no.
Ahora es el momento de probar este binario para ver si extrae correctamente la lista de productos. Para ello, ejecuta el siguiente comando:
cargo run
Deberías ver un resultado similar a este en tu terminal:
Finished dev [unoptimized + debuginfo] target(s) in 0.80s
Running `target/debug/rust_scraper`
[Product { url: Some("catalogue/a-light-in-the-attic_1000/index.html"), image: Some("media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"), name: Some("A Light in the ..."), price: Some("£51.77") }, Product { url: Some("catalogue/tipping-the-velvet_999/index.html"), image: Some("media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg"), name: Some("Tipping the Velvet"), price: Some("53,74 £") }, Product { url: Some("catalogue/soumission_998/index.html"), image: Some("media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg"), name: Some("Soumission"), price: Some("50,10 £") }, Product { url: Some("catalogue/sharp-objects_997/index.html"), image: Some("media/cache/32/51/3251cf3a3412f53f339e42cac2134093.jpg"), name: Some("Sharp Objects"), price: Some("47,82 £") }, Producto { url: Some("catalogue/sapiens-a-brief-history-of-humankind_996/index.html"), imagen: Some("media/cache/be/a5/bea5697f2534a2f86a3ef27b5a8c12a6.jpg"), name: Some("Sapiens: Una breve historia ..."), price: Some("54,23 £") }, Product { url: Some("catalogue/the-requiem-red_995/index.html"), image: Some("media/cache/68/33/68339b4c9bc034267e1da611ab3b34f8.jpg"), name: Some("The Requiem Red"), price: Some("22,65 £") }, Producto { url: Some("catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"), imagen: Some("media/cache/92/27/92274a95b7c251fea59a2b8a78275ab4.jpg"), name: Some("The Dirty Little Secrets ..."), price: Some("£33.34") }, Product { url: Some("catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html"), image: Some("media/cache/3d/54/3d54940e57e662c4dd1f3ff00c78cc64.jpg"), name: Some("La mujer que viene: Una ..."), price: Some("17,93 £") }, Product { url: Some("catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html"), image: Some("media/cache/66/88/66883b91f6804b2323c8369331cb7dd1.jpg"), name: Some("The Boys in the ..."), price: Some("22,60 £") }, Product { url: Some("catalogue/the-black-maria_991/index.html"), image: Some("media/cache/58/46/5846057e28022268153beff6d352b06c.jpg"), name: Some("La María Negra"), price: Some("52,15 £") }, Producto { url: Some("catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html"), imagen: Some("media/cache/be/f4/bef44da28c98f905a3ebec0b87be8530.jpg"), name: Some("Starving Hearts (Triangular Trade ..."), price: Some("13,99 £") }, Product { url: Some("catalogue/shakespeares-sonnets_989/index.html"), image: Some("media/cache/10/48/1048f63d3b5061cd2f424d20b3f9b666.jpg"), name: Some("Shakespeare's Sonnets"), price: Some("20,66 £") }, Producto { url: Some("catalogue/set-me-free_988/index.html"), imagen: Some("media/cache/5b/88/5b88c52633f53cacf162c15f4f823153.jpg"), name: Some("Set Me Free"), price: Some("17,46 £") }, Product { url: Some("catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html"), image: Some("media/cache/94/b1/94b1b8b244bce9677c2f29ccc890d4d2.jpg"), name: Some("Scott Pilgrim's Precious Little ..."), price: Some("£52.29") }, Product { url: Some("catalogue/rip-it-up-and-start-again_986/index.html"), image: Some("media/cache/81/c4/81c4a973364e17d01f217e1188253d5e.jpg"), name: Some("Rip it Up and ..."), price: Some("35,02 £") }, Producto { url: Some("catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html"), imagen: Some("media/cache/54/60/54607fe8945897cdcced0044103b10b6.jpg"), name: Some("Our Band Could Be ..."), price: Some("57,25 £") }, Product { url: Some("catalogue/olio_984/index.html"), image: Some("media/cache/55/33/553310a7162dfbc2c6d19a84da0df9e1.jpg"), name: Some("Olio"), price: Some("23,88 £") }, Product { url: Some("catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html"), image: Some("media/cache/09/a3/09a3aef48557576e1a85ba7efea8ecb7.jpg"), name: Some("Mesaerion: The Best Science ..."), price: Some("£37.59") }, Product { url: Some("catalogue/libertarianism-for-beginners_982/index.html"), image: Some("media/cache/0b/bc/0bbcd0a6f4bcd81ccb1049a52736406e.jpg"), name: Some("Libertarianism for Beginners"), price: Some("51,33 £") }, Producto { url: Some("catalogue/its-only-the-himalayas_981/index.html"), imagen: Some("media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg"), name: Some("It's Only the Himalayas"), price: Some("£45.17") }]
Esto significa que la lógica de rastreo funciona correctamente. Ahora, ya estás listo para añadir tu Proxy Nginx a este Scraper.
Uso del Proxy
Observará que la solicitud de scraping se envía a través de un cliente reqwest completo en la función main() (en lugar de utilizar una llamada get única). Esto significa que puede configurar fácilmente un Proxy al crear el cliente.
Para configurar el cliente, actualice la siguiente línea de código:
async fn main() -> Result<(), Box<dyn Error>>{
let url = "https://books.toscrape.com/";
# Reemplaza esta línea
let client = reqwest::Client::new();
# Por esta
let client = reqwest::Client::builder()
.Proxy(reqwest::Proxy::https("http://localhost:8080")?)
.build()?;
//...
Ok(())
}
Al configurar el Proxy con
reqwest, es importante tener en cuenta que algunos proveedores de Proxy (incluido Bright Data) funcionan con configuracioneshttpyhttps, pero pueden requerir una configuración adicional. Si tienes problemas al utilizarhttps, prueba a cambiar ahttppara ejecutar la aplicación.
Ahora, intente ejecutar el binario de nuevo utilizando el comando cargo run. Debería recibir una respuesta similar a la anterior. Sin embargo, asegúrese de consultar los registros de su servidor Nginx para ver si una solicitud fue Proxyada a través de él.
Localice los registros de su servidor Nginx siguiendo las instrucciones de su sistema operativo. Para una instalación basada en Homebrew en Mac, los archivos de registro de acceso y de errores se encuentran en la carpeta /opt/homebrew/var/log/nginx. Abra el archivo access.log y debería ver una línea como esta al final del archivo:
127.0.0.1 - - [07/Jan/2024:05:19:54 +0530] "GET https://books.toscrape.com/ HTTP/1.1" 200 18 "-" "-"
Esto indica que la solicitud fue Proxy a través del servidor Nginx. Ahora, puede configurar el servidor en un host remoto para poder utilizarlo para eludir restricciones geográficas o bloqueos de IP.
Proxy rotativo
Cuando se trabaja en proyectos de Scraping web, es posible que sea necesario rotar entre un conjunto de proxies. Esto le permite distribuir la carga de trabajo de scraping entre varias IP y evitar ser detectado debido al alto tráfico procedente de una sola fuente o ubicación.
Para implementar Proxy rotativo, debe añadir las siguientes funciones a su archivo main.rs:
#[derive(Debug)]
struct Proxy {
ip: String,
port: String,
}
fn get_proxies() -> Vec<PROXY> {
let mut proxies = Vec::new();
proxies.push(Proxy {
ip: "http://localhost".to_string(),
port: "8082".to_string(),
});
// Añade más sentencias proxies.push aquí para crear un conjunto más grande de proxies.
proxies
}
Esto te ayuda a definir fácilmente el conjunto de Proxies. A continuación, debes actualizar la función principal de la siguiente manera para utilizar un Proxy aleatorio:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Añade estas dos líneas
let proxies = get_proxies();
let random_proxy = proxies.choose(&mut rand::thread_rng()).unwrap();
let client = reqwest::Client::builder()
// Actualiza la siguiente línea para que coincida con esto
.proxy(reqwest::Proxy::http(format!("{0}:{1}", random_proxy.ip, random_proxy.port))?)
.build()?;
// El resto permanece igual
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Ahora, debes instalar el crate rand para poder seleccionar aleatoriamente un Proxy de la matriz de Proxies. Puedes hacerlo ejecutando el siguiente comando:
cargo add rand
A continuación, añade la siguiente línea al principio de tu archivo main.rs para importar el crate rand:
use rand::seq::SliceRandom;
Ahora, intente ejecutar el binario de nuevo para ver si funciona utilizando el comando cargo run. Debería mostrar el mismo resultado que antes, lo que indica que la lista aleatoria de Proxies está configurada correctamente.
Servidor Proxy Bright Data
Como has visto, configurar manualmente un Proxy puede suponer mucho trabajo. Además, necesitas alojar el servidor Proxy en un servidor remoto para poder aprovechar todas las ventajas de una nueva dirección IP y ubicación. Si quieres evitar todas esas molestias, considera la posibilidad de utilizar uno de losservidores Proxy de Bright Data.
Aunque existen innumerables proveedores de proxies, Bright Data es conocido por su gran escala y flexibilidad. Con Bright Data, obtienes una amplia red de 400M+ monthly Proxies residenciales, móviles, de centros de datos y de Proxy ISP repartidos por 195 países. Con su gran número de Proxies residenciales, puedes dirigirte a países, ciudades o incluso operadores móviles específicos para realizar un scraping muy preciso.
Además, los Proxies residenciales de Bright Data se integran perfectamente con el tráfico real de los usuarios, mientras que las opciones de centros de datos y móviles proporcionan una velocidad increíble y conexiones fiables. La rotación automática de Bright Data mantiene tu scraping ágil, minimizando el riesgo de detección y bloqueo.
Para probarlo por ti mismo, dirígete a https://brightdata.com/ y haz clic en «Prueba gratuita» en la esquina superior derecha. Una vez que te hayas registrado, se te redirigirá a la página del panel de control:
En esta página, haz clic en «Ver productos Proxy » para navegar a la página «Proxies e Infraestructura de scraping »:
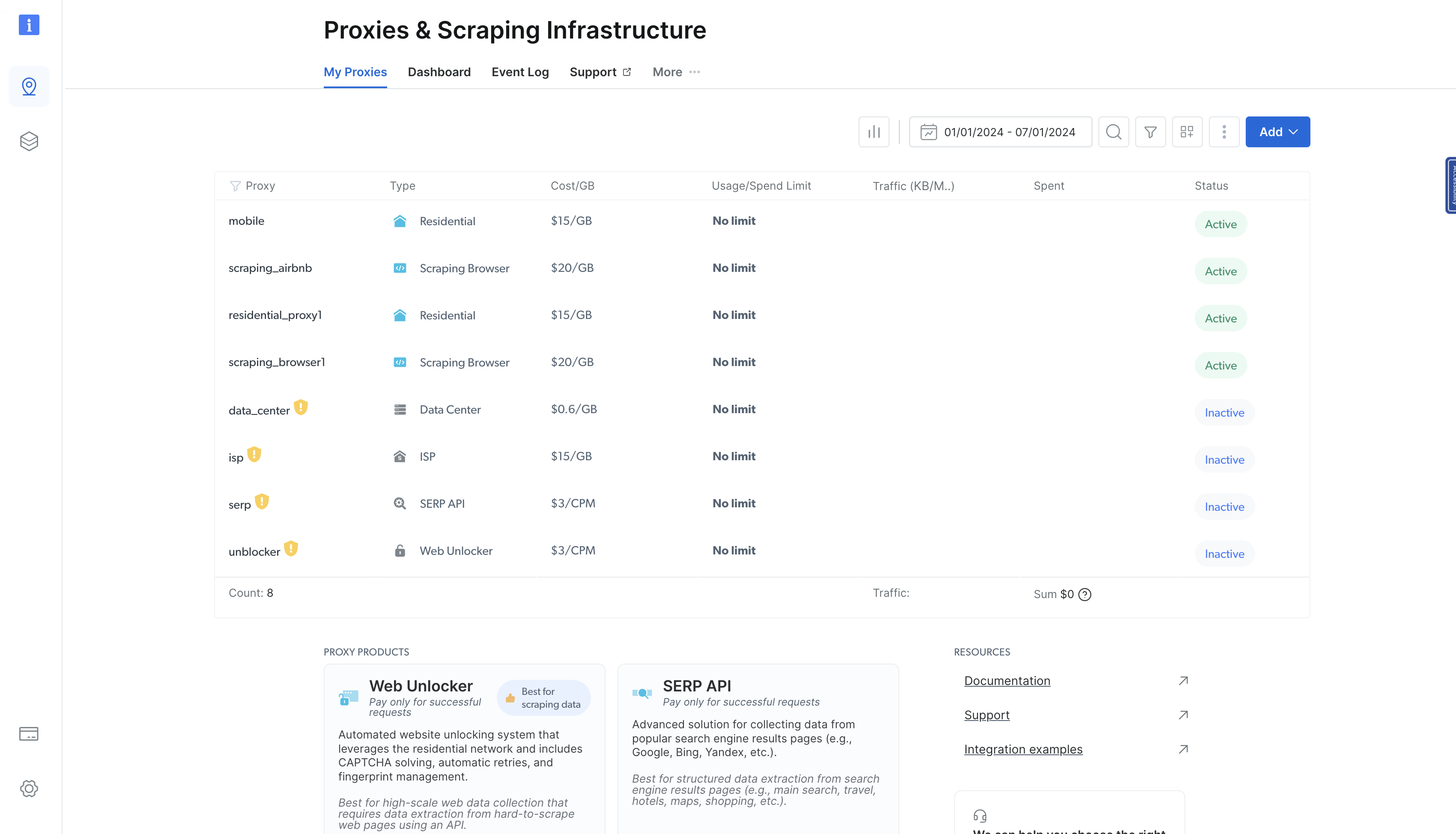
Esta página muestra todos los proxies que ha provisionado anteriormente. Para añadir un proxy, haga clic en el botón azul «Añadir» en la parte superior derecha y seleccione «Proxies residenciales»:
A continuación, aparecerá un formulario en el que podrá configurar su nuevo Proxy residencial. Deje las opciones predeterminadas, desplácese hasta la parte inferior de la página y haga clic en «Añadir».
Una vez creado el Proxy residencial, se le redirigirá a una página que muestra los detalles del Proxy recién creado. Haga clic en la pestaña Parámetros de acceso para ver el host, el nombre de usuario y la contraseña del Proxy:
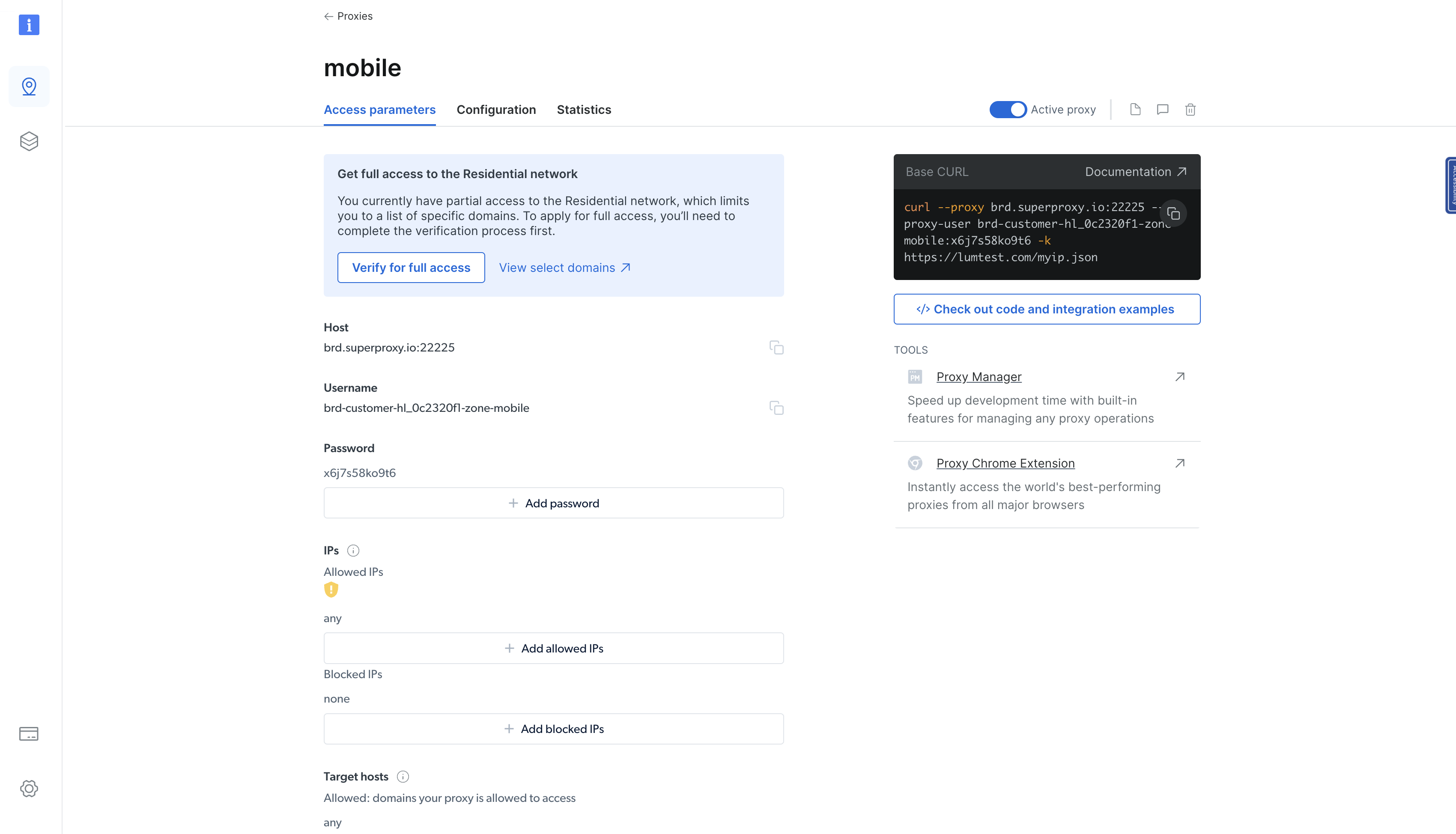
Puede utilizar estos parámetros para integrar el Proxy en su binario Rust. Para ello, actualice la función main() en el archivo src/main.rs de la siguiente manera:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Actualice el siguiente bloque con los datos de la página de detalles del Proxy de Bright Data.
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<NOMBRE de host y puerto del Proxy BD>")?
.basic_auth("<SU nombre de usuario BD>", "<SU contraseña BD>"))
.build()?;
// El resto permanece igual.
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
A continuación, vuelve a ejecutar el binario. Debería devolver la respuesta correctamente, como antes. La única diferencia clave aquí es que la solicitud se está Proxy a través de Bright Data, ocultando tu identidad y ubicación real.
Puede confirmarlo enviando una solicitud a una API que muestre la dirección IP del cliente utilizando el siguiente fragmento de código:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "http://lumtest.com/myip.json";
// Actualice el siguiente bloque con los datos de la página de detalles del Proxy de Bright Data.
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD proxy hostname & port>")?
.basic_auth("<YOUR BD username>", "<YOUR BD password>"))
.build()?;
// El resto permanece igual
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
println!("{:?}", html_content);
Ok(())
}Cuando ejecute el código con el comando cargo run, debería ver un resultado similar a este:
"{"ip":"209.169.64.172","country":"US","asn":{"asnum":6300,"org_name":"CCI-TEXAS"},"geo":{"city":"Conroe","region":"TX","region_name":"Texas","postal_code":"77304","latitude":30.3228,"longitude":-95.5298,"tz":"America/Chicago","lum_city":"conroe","lum_region":"tx"}}"
Esto reflejará la IP y los detalles de ubicación del Proxy que estás utilizando para consultar la página.
Conclusión
En este artículo, has aprendido a utilizar Proxies con Rust. Recuerda que los Proxies son como máscaras digitales que te permiten superar las restricciones en línea y echar un vistazo detrás de las restricciones de los sitios web. También te permiten mantener tu anonimato cuando navegas por la web.
Sin embargo, configurar un Proxy por tu cuenta es un proceso complejo. Por lo general, se recomienda recurrir a un proveedor de proxies consolidado, comoBright Data, que ofrece un grupo de 400M+ monthly proxies fáciles de usar.






