
En esta guía paso a paso, aprenderás a realizar el raspado web en YouTube con Python
Este tutorial cubrirá:
- API de YouTube vs. raspado de YouTube
- Qué datos extraer de YouTube
- Cómo raspar YouTube con Selenium
API de YouTube vs. raspado de YouTube
La API de datos de YouTube es la forma oficial de obtener datos de la plataforma, incluida información sobre vídeos, listas de reproducción y creadores de contenido. Sin embargo, hay al menos tres buenas razones por las que es mejor raspar YouTube que depender únicamente de su API:
- Flexibilidad y personalización: con una araña de YouTube, puedes personalizar el código para seleccionar solo los datos que necesitas. Este nivel de personalización te ayuda a recopilar la información exacta para tu caso de uso específico. Por el contrario, la API solo te da acceso a datos predefinidos.
- Acceso a datos no oficiales: la API proporciona acceso a conjuntos de datos específicos seleccionados por YouTube. Esto significa que es posible que algunos datos de los que dependes actualmente dejen de estar disponibles en el futuro. En cambio, el raspado web te permite obtener cualquier información adicional disponible en el sitio web de YouTube, aunque no esté expuesta a través de la API.
- Sin limitación: las API de YouTube están sujetas a límites de velocidad. Esta restricción determina la frecuencia y el volumen de las solicitudes que puedes realizar en un período de tiempo determinado. Al interactuar directamente con la plataforma, puedes eludir cualquier limitación.
Qué datos extraer de YouTube
Campos de datos principales para extraer de YouTube
- Metadatos de vídeo:
- Título
- Descripción
- Visualizaciones
- Me gusta
- Duración
- Fecha de publicación
- Canal
- Perfiles de usuario:
- Nombre de usuario
- Descripción del usuario
- Suscriptores
- Cantidad de vídeos
- Listas de reproducción
- Otros:
- Comentarios
- Vídeos relacionados
Como se ha visto anteriormente, la mejor manera de obtener estos datos es a través de un raspador personalizado. Pero, ¿qué lenguaje de programación elegir?
Python es uno de los lenguajes más populares para el raspado web gracias a su sintaxis sencilla y su rico ecosistema de bibliotecas. Su versatilidad, legibilidad y amplio apoyo de la comunidad lo convierten en una excelente opción. Consulta nuestra guía detallada para empezar a usar el raspado web con Python.
Cómo raspar YouTube con Selenium
Sigue este tutorial y aprende a crear una secuencia de comandos de Python de raspado web para YouTube.
Paso 1: configuración
Antes de programar, debes cumplir los siguientes requisitos previos:
- Python 3+: descarga el instalador, haz doble clic en él y sigue las instrucciones.
- Un IDE de Python: PyCharm Community Edition o Visual Studio Code con la extensión de Python son dos excelentes opciones gratuitas.
Puedes iniciar un proyecto de Python con un entorno virtual usando los siguientes comandos:
mkdir youtube-scraper
cd youtube-scraper
python -m venv env
El directorio youtube-scraper creado anteriormente representa la carpeta del proyecto de tu secuencia de comandos de Python.
Ábrelo en el IDE, crea un archivo scraper.py e inícialo de la siguiente manera:
print('Hello, World!')
En este momento, este archivo es una secuencia de comandos de ejemplo que solo imprime «¡Hola, mundo!», pero pronto contendrá la lógica de raspado.
Comprueba que la secuencia de comandos funciona pulsando el botón de ejecución de tu IDE o con:
python scraper.py
En la terminal, deberías ver:
Hello, World!
Perfecto, ahora tienes un proyecto de Python para tu raspador de YouTube.
Paso 2: elige e instala las bibliotecas de raspado
Si pasas tiempo en YouTube, te darás cuenta de que es una plataforma muy interactiva. En función de las operaciones de clic y desplazamiento, el sitio carga y renderiza los datos de forma dinámica. Esto significa que YouTube depende en gran medida de JavaScript.
Raspar YouTube requiere una herramienta que pueda renderizar páginas web en un navegador, ¡igual que Selenium! Esta herramienta permite raspar sitios web dinámicos en Python, lo que te permite realizar tareas automatizadas en sitios web en un navegador.
Añade Selenium y los paquetes de Webdriver Manager a las dependencias de tu proyecto con:
pip install selenium webdriver-manager
La tarea de instalación puede tardar un poco, así que ten paciencia.
webdriver-manager no es estrictamente necesario, pero facilita la administración de los controladores web en Selenium. Gracias a él, no es necesario descargar, instalar y configurar manualmente los controladores web.
Empieza a usar Selenium en scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# scraping logic...
# close the browser and free up the resources
driver.quit()
Esta secuencia de comandos crea una instancia de WebDriver en Chrome, el objeto a través del cual se controla mediante programación una ventana de Chrome.
De forma predeterminada, Selenium inicia el navegador con la interfaz de usuario. Aunque esto es útil para la depuración, ya que puedes experimentar en línea lo que hace la secuencia de comandos automatizada en la página, requiere muchos recursos. Por este motivo, debes configurar Chrome para que se ejecute en modo sin interfaz gráfica. Gracias a la opción --headless=new, la instancia de navegador controlado se ejecutará en segundo plano sin interfaz de usuario.
¡Perfecto! ¡Es hora de definir la lógica del raspado!
Paso 3: conectarse a YouTube
Para realizar el raspado web en YouTube, primero debes seleccionar un vídeo del que extraer datos. En esta guía, verás cómo raspar el último vídeo del canal de YouTube de Bright Data. Ten en cuenta que cualquier otro vídeo servirá.
Esta es la página de YouTube elegida como objetivo:
https://www.youtube.com/watch?v=kuDuJWvho7Q
Es un vídeo sobre raspado web titulado «Introducción a Bright Data | Navegador de raspado».
Almacena la cadena URL en una variable de Python:
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
Ahora puedes indicarle a Selenium que se conecte a la página de destino con:
driver.get(url)
La función get() indica al navegador controlado que visite la página identificada por la URL pasada como parámetro.
Este es el aspecto que tiene tu raspador de YouTube hasta ahora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up the resources
driver.quit()
Si ejecutas la secuencia de comandos, se abrirá la siguiente ventana del navegador durante una fracción de segundo antes de cerrarla debido a la instrucción quit():
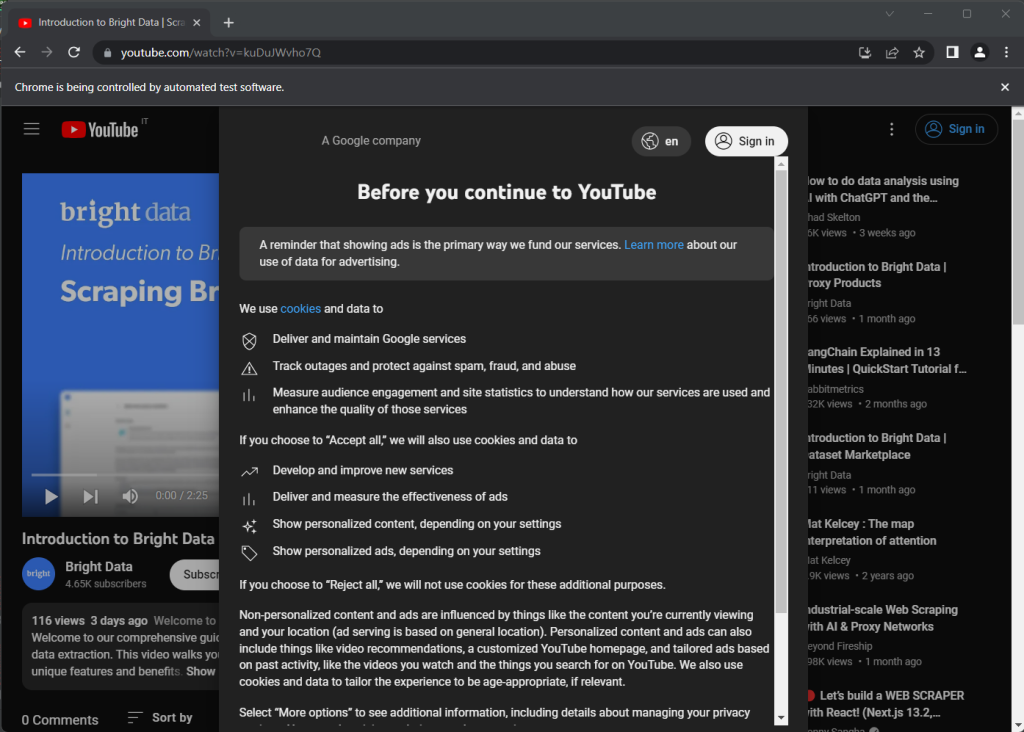
Ten en cuenta el mensaje «Chrome está siendo controlado por un software de prueba automatizado», que garantiza que Selenium funciona correctamente en Chrome.
Paso 4: inspección de la página de destino
Echa un vistazo a la captura de pantalla anterior. Cuando abres YouTube por primera vez, aparece un cuadro de diálogo de consentimiento. Para acceder a los datos de la página, primero debes cerrarla haciendo clic en el botón «Aceptar todo». ¡Aprendamos cómo hacerlo!
Para crear una nueva sesión de navegador, abre YouTube en modo incógnito. Haz clic con el botón derecho en el modal de consentimiento y selecciona «Inspeccionar». Esto abrirá la sección de DevTools de Chrome:
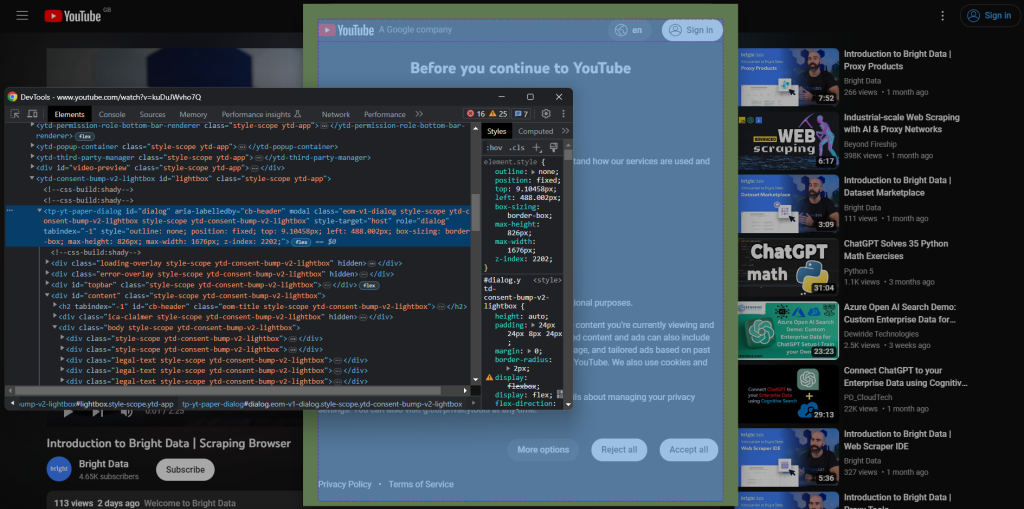
Ten en cuenta que el cuadro de diálogo tiene un atributo id. Esta información es útil para definir una estrategia de selector eficaz en Selenium.
Del mismo modo, inspecciona el botón «Aceptar todo»:
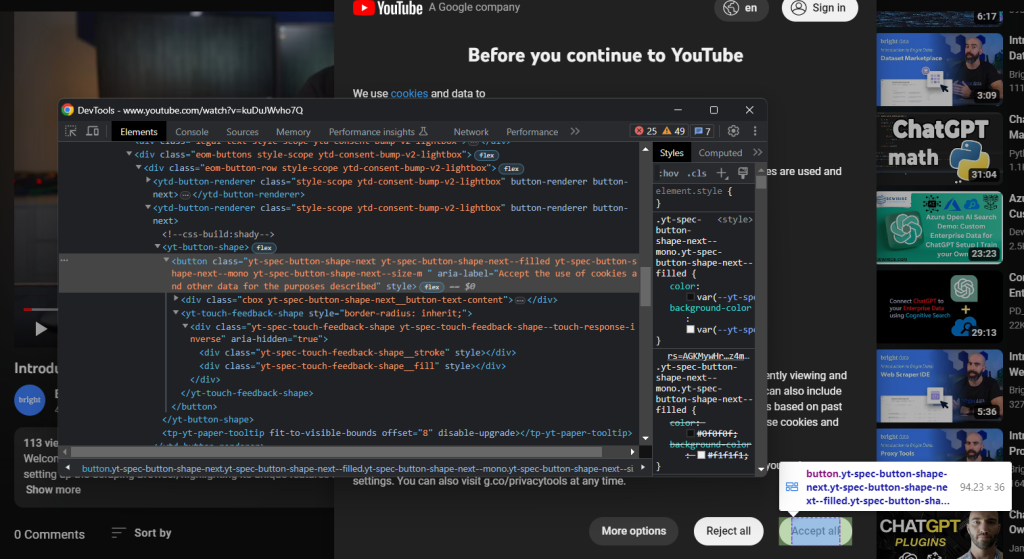
Es el segundo botón identificado por el siguiente selector CSS:
.eom-buttons button.yt-spec-button-shape-next
Combínalo todo y usa estas líneas de código para lidiar con la política de cookies de YouTube en Selenium:
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
El modal de consentimiento se carga de forma dinámica y puede tardar un tiempo en aparecer. Esta es la razón por la que debes usar WebDriverWait para esperar a que se produzca la condición prevista. Si no ocurre nada durante el tiempo de espera especificado, se genera una TimeoutException. YouTube es bastante lento, por lo que se recomienda usar tiempos de espera superiores a 10 segundos.
Dado que YouTube cambia constantemente sus políticas, es posible que el cuadro de diálogo no aparezca en países o situaciones específicos. Por lo tanto, gestiona la excepción con un try-catch para evitar que la secuencia de comandos falle en caso de que el modal no esté presente.
Para que la secuencia de comandos funcione, recuerda añadir las siguientes importaciones:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
Tras pulsar el botón «Aceptar todo», YouTube tarda un tiempo en volver a renderizar la página de forma dinámica:
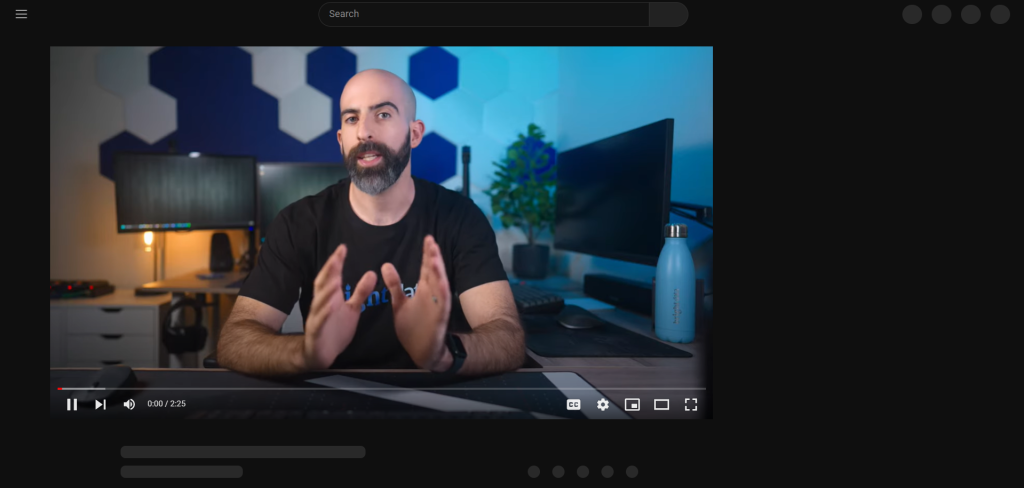
Durante este período de tiempo, no puedes interactuar con la página en Selenium. Si intentas seleccionar un elemento HTML, aparecerá el error «referencia de elemento obsoleta». Esto ocurre porque el DOM cambia mucho en este proceso.
Como puedes ver, el elemento «title» contiene una línea gris. Si inspeccionas ese elemento, verás:
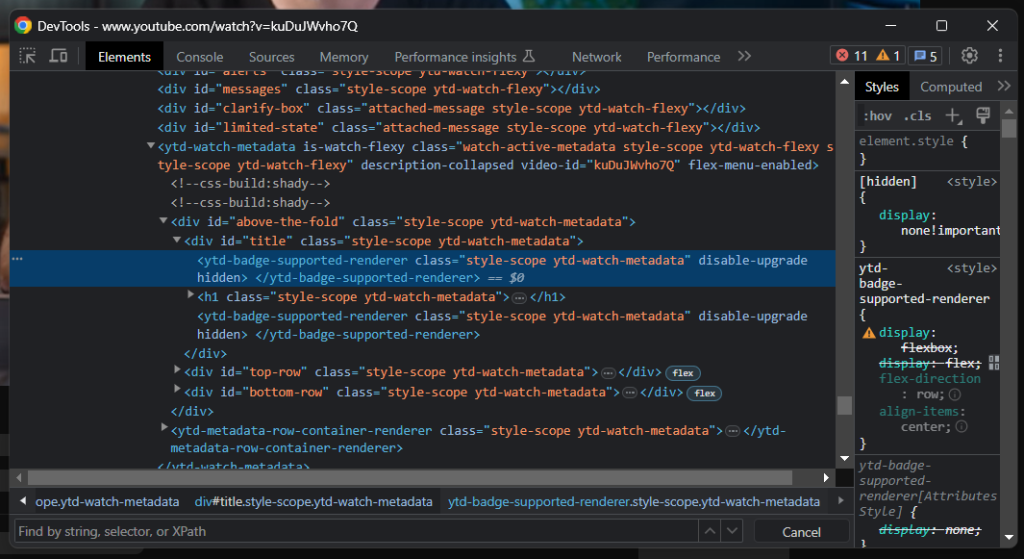
Un buen indicador de cuándo se ha cargado la página es esperar hasta que el elemento «title» sea visible:
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
Estás listo para raspar YouTube en Python. Sigue analizando el sitio de destino en DevTools y familiarízate con su DOM.
Paso 5: extraer datos de YouTube
Primero, necesitas una estructura de datos donde almacenar la información extraída. Inicia un diccionario de Python con:
video = {}
Como habrás notado en el paso anterior, parte de la información más interesante se encuentra en la sección que hay debajo del reproductor de vídeo:

Con el selector CSS h1.ytd-watch-metadata, puedes obtener el título del vídeo:
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
Justo debajo del título, está el elemento HTML que contiene la información del canal:
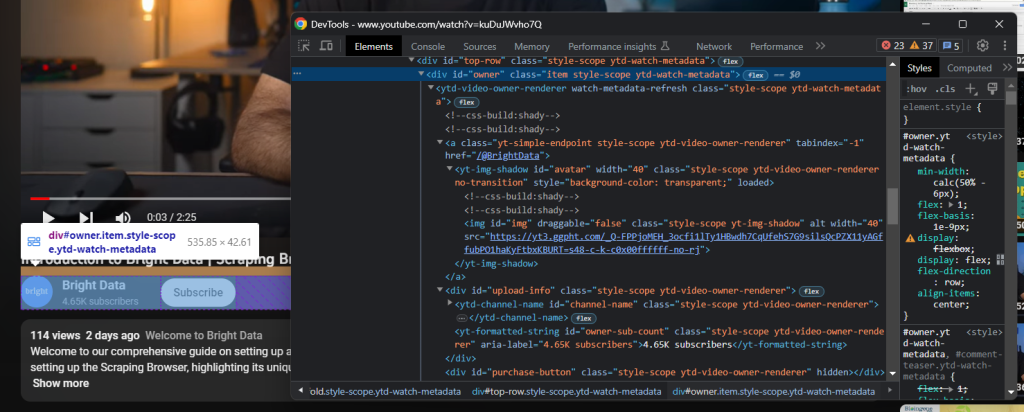
Esto se identifica con el atributo id «owner» y puedes obtener todos los datos de él con:
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
Aún más abajo aparece la descripción del vídeo. Este componente tiene un comportamiento complicado, ya que muestra datos diferentes en función de si está cerrado o abierto.

Haz clic en él para acceder a los datos completos:
driver.find_element(By.ID, 'description-inline-expander').click()
Deberías tener acceso al elemento de información de descripción ampliado:
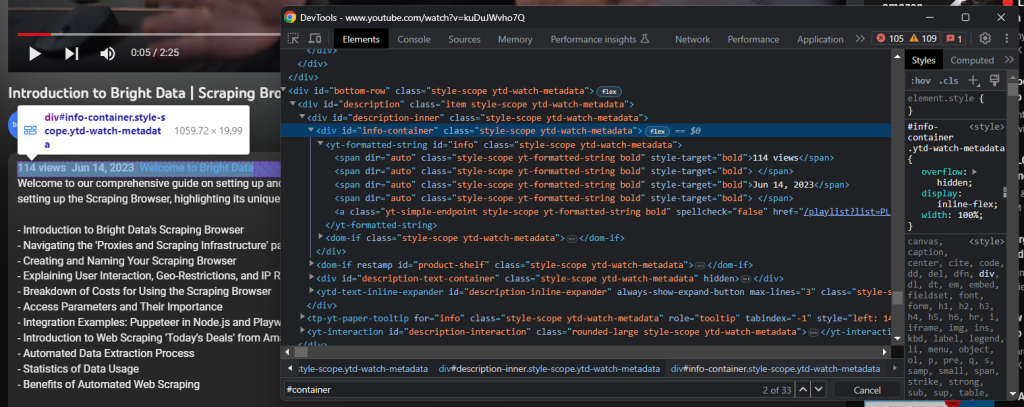
Recupera las visualizaciones del vídeo y la fecha de publicación con:
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
La descripción textual asociada al vídeo se encuentra en el siguiente elemento hijo:
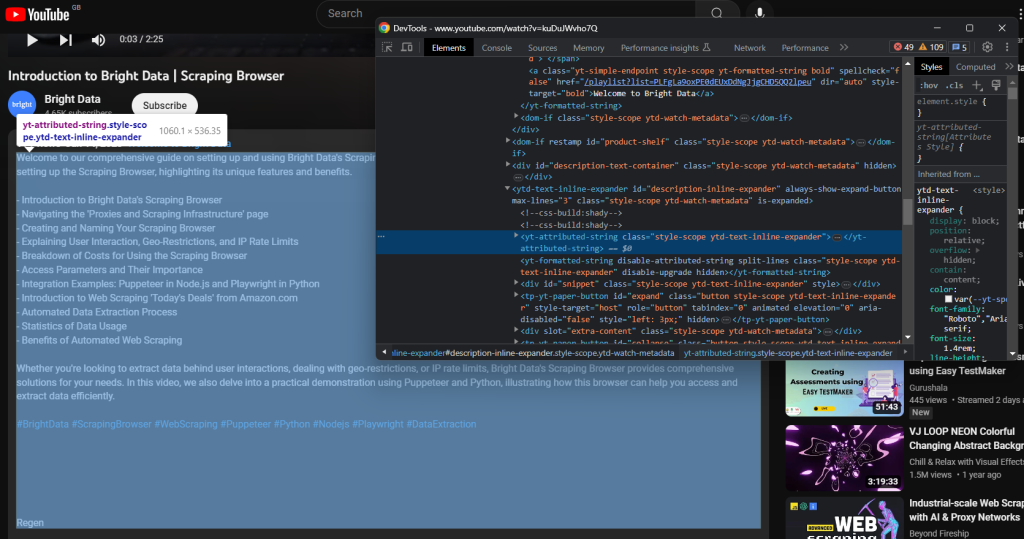
Ráspalo con:
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
A continuación, inspecciona el botón Me gusta:
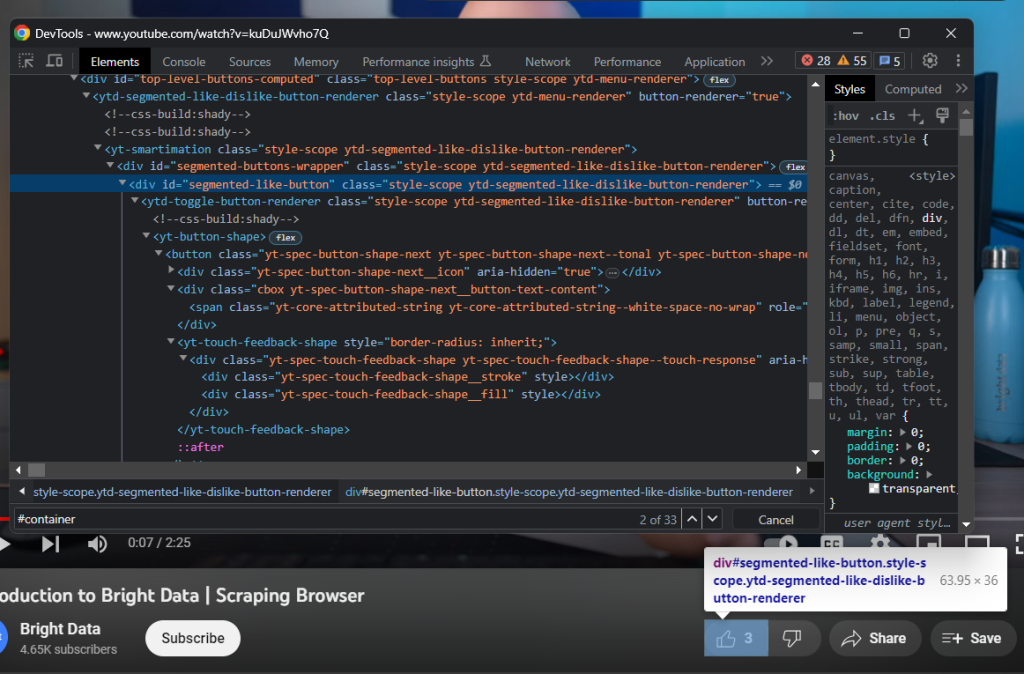
Consigue la cantidad de Me gusta con:
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
Por último, no olvides insertar los datos extraídos en el diccionario video:
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
¡Genial! ¡Acabas de realizar el raspado web en Python!
Paso 6: exportar los datos extraídos a JSON
Los datos de interés ahora se almacenan en un diccionario de Python, que no es el mejor formato para compartirlos con otros equipos. Puedes convertir la información recopilada a JSON y exportarla a un archivo con solo dos líneas de código:
with open('video.json', 'w') as file:
json.dump(video, file)
Este segmento de código inicia un archivo video.json con open(). A continuación, usa json.dump() para escribir la representación JSON del diccionario video en el archivo resultante. Echa un vistazo a nuestro artículo para obtener más información sobre cómo analizar JSON en Python.
No necesitas una dependencia adicional para lograr el objetivo. Todo lo que necesitas es el paquete json de la biblioteca estándar de Python que puedes importar con:
import json
¡Estupendo! Empezaste con datos sin procesar contenidos en una página HTML dinámica y ahora tienes datos JSON semiestructurados. Es hora de ver el raspador completo de YouTube.
Paso 7: juntarlo todo
Esta es la secuencia de comandos scraper.py completa:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import json
# enable the headless mode
options = Options()
# options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
# initialize the dictionary that will contain
# the data scraped from the YouTube page
video = {}
# scraping logic
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
# click the description section to expand it
driver.find_element(By.ID, 'description-inline-expander').click()
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
# close the browser and free up the resources
driver.quit()
# export the scraped data to a JSON file
with open('video.json', 'w') as file:
json.dump(video, file, indent=4)
¡Puedes crear un raspador web para obtener datos de vídeos de YouTube con solo unas 100 líneas de código!
Ejecuta la secuencia de comandos y el siguiente archivo video.json aparecerá en la carpeta raíz de tu proyecto:
{
"url": "https://www.youtube.com/watch?v=kuDuJWvho7Q",
"title": "Introduction to Bright Data | Scraping Browser",
"channel": {
"url": "https://www.youtube.com/@BrightData",
"name": "Bright Data",
"image": "https://yt3.ggpht.com/_Q-FPPjoMEH_3ocfi1lTy1HBwdh7CqUfehS7G9silsQcPZX11yAGffubPO1haKyFtbxKBURT=s48-c-k-c0x00ffffff-no-rj",
"subs": "4.65K"
},
"views": "116",
"publication_date": "Jun 14, 2023",
"description": "Welcome to our comprehensive guide on setting up and using Bright Data's Scraping Browser for efficient web data extraction. This video walks you through the process of setting up the Scraping Browser, highlighting its unique features and benefits.nn- Introduction to Bright Data's Scraping Browsern- Navigating the 'Proxies and Scraping Infrastructure' pagen- Creating and Naming Your Scraping Browsern- Explaining User Interaction, Geo-Restrictions, and IP Rate Limitsn- Breakdown of Costs for Using the Scraping Browsern- Access Parameters and Their Importancen- Integration Examples: Puppeteer in Node.js and Playwright in Pythonn- Introduction to Web Scraping 'Today's Deals' from Amazon.comn- Automated Data Extraction Processn- Statistics of Data Usagen- Benefits of Automated Web ScrapingnnWhether you're looking to extract data behind user interactions, dealing with geo-restrictions, or IP rate limits, Bright Data's Scraping Browser provides comprehensive solutions for your needs. In this video, we also delve into a practical demonstration using Puppeteer and Python, illustrating how this browser can help you access and extract data efficiently.nn#BrightData #ScrapingBrowser #WebScraping #Puppeteer #Python #Nodejs #Playwright #DataExtraction",
"likes": "3"
}
¡Enhorabuena! ¡Acabas de aprender a raspar YouTube en Python!
Conclusión
En esta guía, has aprendido por qué es mejor raspar YouTube que usar sus API de datos. En concreto, has visto un tutorial paso a paso sobre cómo crear un raspador de Python que pueda recuperar datos de vídeos de YouTube. Como se demuestra aquí, no es complejo y solo requiere unas líneas de código.
Al mismo tiempo, YouTube es una plataforma dinámica que sigue evolucionando, por lo que es posible que el raspador creado aquí no funcione para siempre. Mantenerlo para hacer frente a los cambios en el sitio de destino requiere mucho tiempo y es complicado. Por eso hemos creado YouTube Scraper, una solución fiable y fácil de usar para obtener todos los datos que deseas sin preocupaciones.
Además, no pases por alto los sistemas antibot de Google. Selenium es una gran herramienta, pero no puede hacer nada contra tecnologías tan avanzadas. Si Google decide proteger YouTube de los bot, se eliminarán la mayoría de las secuencias de comandos automatizadas. Si esto sucediera, necesitarías una herramienta que pueda renderizar JavaScript y gestionar automáticamente las huellas dactilares, los CAPTCHA y el antirraspado por ti. ¡Pues existe y se llama Scraping Browser!
¿No te interesa para nada el raspado web de YouTube, pero sí los datos de elementos? Solicita un conjunto de datos de YouTube.





