

En este tutorial, aprenderás:
- Por qué es útil raspar imágenes de un sitio web
- Cómo raspar imágenes de un sitio web con Python usando Selenium
¡Vamos allá!
¿Por qué raspar imágenes de un sitio web?
El raspado web no consiste solo en extraer datos textuales. En su lugar, puede dirigirse a cualquier tipo de datos, incluidos archivos multimedia, como imágenes. En particular, raspar imágenes de un sitio web es útil en varias situaciones. Estas incluyen:
- Recuperar imágenes para entrenar modelos de IA y de aprendizaje automático: entrena un modelo con imágenes descargadas en línea para mejorar su precisión y eficacia.
- Estudiar cómo los competidores abordan la comunicación visual: comprende las tendencias y estrategias proporcionando a tu equipo de mercadotecnia acceso a las imágenes que los competidores utilizan para comunicar mensajes clave a su público.
- Obtener automáticamente imágenes visualmente atractivas de los proveedores en línea: utiliza imágenes de alta calidad para lograr una mayor participación en su sitio y en las plataformas de redes sociales, atrayendo y reteniendo la atención del público.
Python Scrape Images: guía paso a paso
Para raspar imágenes de una página web, debes realizar la siguiente operación:
- Conéctate al sitio de destino
- Selecciona todos los nodos HTML de las imágenes de interés en la página
- Extrae las URL de las imágenes de cada una de ellas
- Descarga los archivos de imágenes asociados a esas URL
Un buen sitio objetivo para esta tarea es Unsplash, uno de los proveedores de imágenes más populares de Internet. Este es el aspecto del panel de control de la palabra de búsqueda «fondo de pantalla» para imágenes gratuitas:
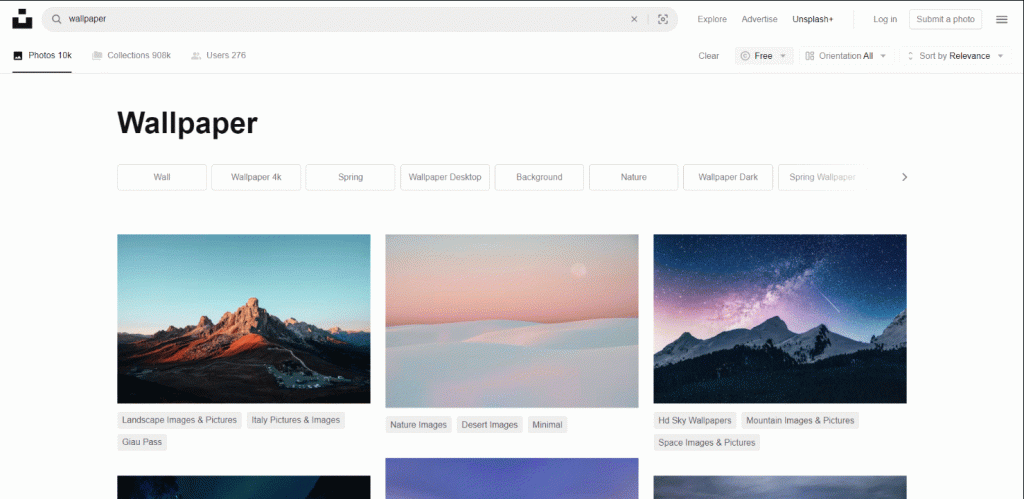
Como puedes ver, la página carga nuevas imágenes a medida que el usuario se desplaza hacia abajo. En otras palabras, es un sitio interactivo que requiere una herramienta de automatización del navegador para realizar el raspado.
La URL de esa página es:
https://unsplash.com/s/photos/wallpaper?license=free¡Es hora de ver cómo raspar imágenes de ese sitio en Python!
Paso 1: comenzar
Para seguir este tutorial, asegúrate de tener Python 3 instalado en tu ordenador. En caso de no ser así, descarga el instalador, haz doble clic en él y sigue las instrucciones.
Inicia tu proyecto de raspado de imágenes de Python con los siguientes comandos:
mkdir image-scraper
cd image-scraper
python -m venv envEsto crea una carpeta image-scraper y añade un entorno virtual de Python en su interior.
Abre la carpeta del proyecto en un IDE de Python de tu elección. PyCharm Community Edition o Visual Studio Code con la extensión de Python serán suficientes.
Crea un archivo scraper.py en la carpeta del proyecto e inícialo de la siguiente manera:
print('Hello, World!')En este momento, este archivo es una secuencia de comandos sencilla que imprime «¡Hola, mundo!», pero pronto contendrá la lógica de raspado de la imagen.
Comprueba que la secuencia de comandos funciona pulsando el botón de ejecución de tu IDE o ejecutando el siguiente comando:
python scraper.pyDebería aparecer el siguiente mensaje en tu terminal:
Hello, World!¡Genial! Ya tienes un proyecto de Python en marcha. Implementa la lógica necesaria para raspar imágenes de un sitio web en los siguientes pasos.
Paso 2: instalar Selenium
Selenium es una biblioteca excelente para raspar imágenes porque puede gestionar sitios con contenido estático y dinámico. Como herramienta de automatización del navegador, puede renderizar páginas incluso si requieren la ejecución de JavaScript. Obtén más información en nuestra guía sobre el raspado web de Selenium.
En comparación con un analizador HTML como BeautiFoulSoup, Selenium puede dirigirse a más sitios y cubrir más casos prácticos. Por ejemplo, también funciona con proveedores de imágenes que dependen de las interacciones de los usuarios para cargar imágenes nuevas. Ese es exactamente el caso de Unsplash, el sitio objetivo de esta guía.
Antes de instalar Selenium, debes activar el entorno virtual de Python. En Windows, consíguelo con este comando:
envScriptsactivateEn macOS y Linux, ejecuta en su lugar:
source env/bin/activateEn la terminal env, instala el paquete Selenium WebDriver con el siguiente comando pip:
pip install seleniumEl proceso de instalación tardará un poco, así que ten paciencia.
¡Genial! Tienes todo lo que necesitas para raspar imágenes en Python.
Paso 3: conectarse al sitio de destino
Importa Selenium y las clases necesarias para controlar una instancia de Chrome añadiendo las siguientes líneas a scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import OptionsAhora puedes iniciar una instancia de Chrome WebDriver sin interfaz gráfica con este código:
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment while developing
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)Comenta la opción --headless si quieres que Selenium abra una ventana de Chrome con la GUI (interfaz gráfica de usuario). Esto te permitirá seguir lo que hace la secuencia de comandos en la página en tiempo real, lo que es útil para la depuración. En producción, mantén la opción --headless activada para ahorrar recursos.
No olvides cerrar la ventana del navegador añadiendo esta línea al final de la secuencia de comandos:
# close the browser and free up its resources
driver.quit() Algunas páginas muestran las imágenes de forma diferente según el tamaño de la pantalla del dispositivo del usuario. Para evitar problemas con el contenido adaptable, aprovecha al máximo la ventana de Chrome con:
driver.maximize_window()Ahora puedes indicarle a Chrome que se conecte a la página de destino usando el método get():
url = "https://unsplash.com/s/photos/wallpaper?license=free"
driver.get(url)Ponlo todo junto y obtendrás:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up its resources
driver.quit()Inicia la secuencia de comandos de raspado de imágenes en el modo con interfaz gráfica. Aparecerá la siguiente página para una fracción de una sección antes de cerrar Chrome:
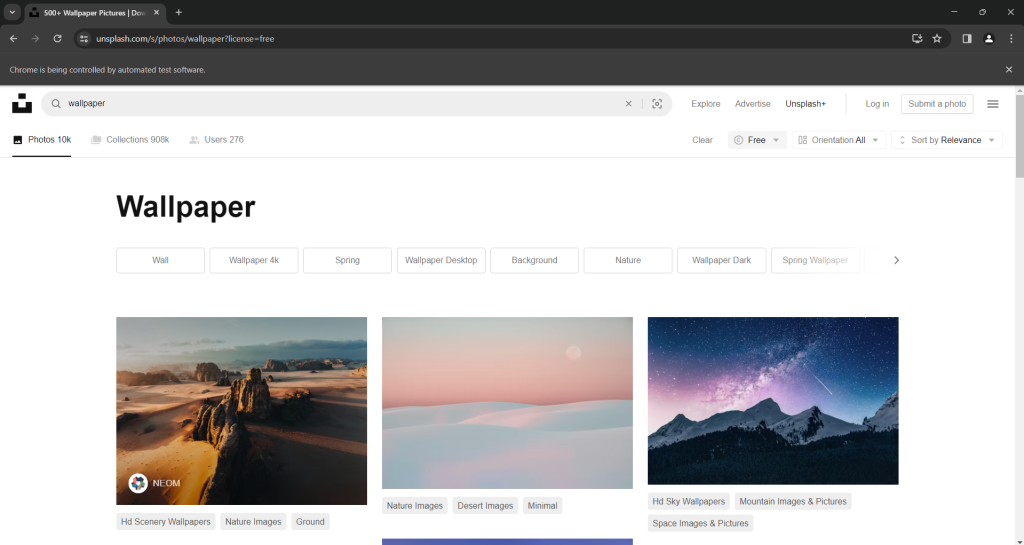
El mensaje que aparece que dice «Chrome está siendo controlado por un software automatizado de prueba» indica que has decidido que Selenium funcione en la ventana de Chrome.
¡Estupendo! Eche un vistazo al código HTML de la página para aprender a extraer imágenes de ella.
Paso 4: inspección del sitio de destino
Antes de profundizar en la lógica de imágenes de raspado de Python, debes inspeccionar el código fuente HTML de la página de destino. Solo de esta manera podrás entender cómo definir una lógica de selección de nodos efectiva y descubrir cómo extraer los datos deseados.
Por lo tanto, visita el sitio de destino en tu navegador, haz clic con el botón derecho en una imagen y selecciona la opción «Inspeccionar» para abrir DevTools:
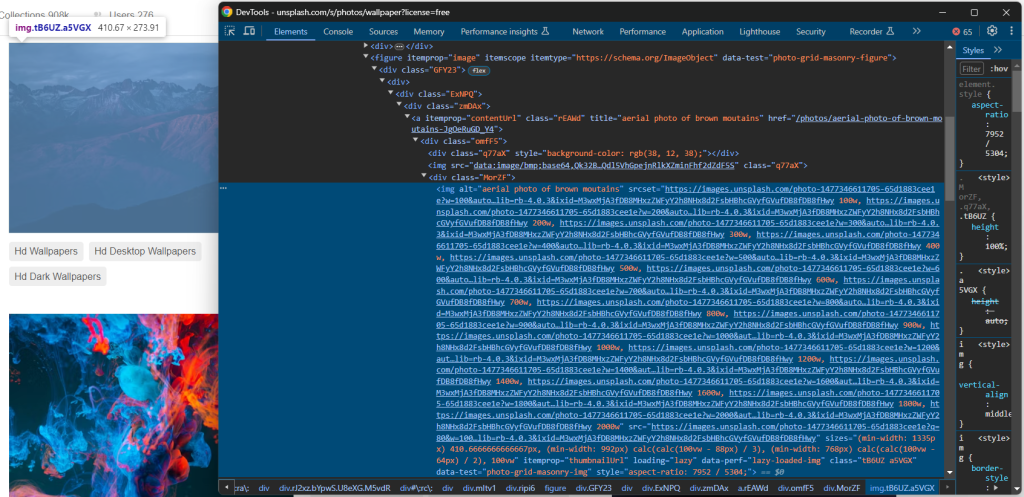
Aquí puedes observar un par de datos interesantes.
En primer lugar, la imagen está contenida en un elemento HTML <img>. Esto significa que el selector de CSS para seleccionar los nodos de la imagen de interés es:
[data-test="photo-grid-masonry-img"]En segundo lugar, los elementos de la imagen tienen el atributo tradicional src y el atributo srcset. Si no estás familiarizado con este último atributo, srcset especifica varias imágenes de origen junto con sugerencias para ayudar al navegador a elegir la correcta en función de los puntos de interrupción adaptables.
En detalle, el valor de un atributo srcset tiene el siguiente formato:
<image_source_1_url> <image_source_1_size>, <image_source_1_url> <image_source_2_size>, ...Dónde:
<image_source_1_url>,<image_source_2_url>, etc. son las URL de las imágenes de diferentes tamaños.<image_source_1_size>,<image_source_2_size>, etc. son los tamaños de cada fuente de imagen. Los valores permitidos son anchos de píxeles (p. ej.,200w) o proporciones de píxeles (p. ej.,1.5x).
Esta situación en la que una imagen tiene ambos atributos es bastante común en los sitios adaptables modernos. Enfocarse directamente en la URL de la imagen en src no es el mejor método, ya que srcset puede contener URL a imágenes de mayor calidad.
En el código HTML anterior, también puedes ver que todas las URL de las imágenes son absolutas. Por lo tanto, no es necesario concatenar la URL base del sitio con ellas.
En el siguiente paso, aprenderás cómo extraer las imágenes correctas en Python usando Selenium.
Paso 5: recuperar todas las URL de las imágenes
Usa el método findElements() para seleccionar todos los nodos de imagen HTML que desees en la página:
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]") Para funcionar, esa instrucción requiere la siguiente importación:
from selenium.webdriver.common.by import ByA continuación, inicia una lista que contendrá las URL extraídas de los elementos de la imagen:
image_urls = []Repite los nodos de image_html_nodes, recopila la URL de src o la URL de la imagen más grande de srcset (si está presente) y añádela a image_urls:
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continueTen en cuenta que Unsplash es un sitio bastante dinámico y, cuando ejecutes este bucle, es posible que algunas imágenes ya no estén en la página. Para protegerse contra ese error, detecta la StaleElementReferenceException.
De nuevo, no olvides añadir esta importación:
from selenium.common.exceptions import StaleElementReferenceExceptionAhora puedes imprimir las URL de las imágenes raspadas con:
print(image_urls)El archivo scraper.py actual debe contener:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# log in the terminal the scraped data
print(image_urls)
# close the browser and free up its resources
driver.quit()Ejecuta la secuencia de comandos para raspar imágenes y obtendrás un resultado similar al siguiente:
[
'https://images.unsplash.com/photo-1707343843598-39755549ac9a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDF8MHxzZWFyY2h8MXx8d2FsbHBhcGVyfGVufDB8fDB8fHwy',
# omitted for brevity...
'https://images.unsplash.com/photo-1507090960745-b32f65d3113a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxzZWFyY2h8MjB8fHdhbGxwYXBlcnxlbnwwfHwwfHx8Mg%3D%3D'
]¡Allá vamos! La matriz anterior contiene las URL de las imágenes que se van a recuperar. Solo queda ver cómo descargar imágenes en Python.
Paso 6: descargar las imágenes
La forma más sencilla de descargar una imagen en Python es usar el método urlretrieve() del paquete url.request de la biblioteca estándar. Esa función copia un objeto de red especificado por una URL a un archivo local.
Importa url.request añadiendo la siguiente línea en la parte superior de tu archivo scraper.py:
import urllib.requestEn la carpeta del proyecto, crea un directorio images:
mkdir imagesAquí es donde la secuencia de comandos escribirá los archivos de imagen.
Ahora, repite la lista con las URL de las imágenes raspadas. Para cada imagen, genera un nombre de archivo incremental y descarga la imagen con urlretrieve():
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1Esto es todo lo que necesitas para descargar imágenes en Python. Las instrucciones print() no son obligatorias, pero son útiles para entender lo que hace la secuencia de comandos.
¡Guau! Acabas de aprender a raspar imágenes de un sitio web en Python. Es hora de ver el código completo de la secuencia de comandos de Python para raspar imágenes.
Paso 7: juntarlo todo
Este es el código del scraper.py final:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
import urllib.request
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# to keep track of the images saved to disk
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1
# close the browser and free up its resources
driver.quit()¡Fantástico! Puedes crear una secuencia de comandos automatizada para descargar imágenes de un sitio en Python con menos de 100 líneas de código.
Ejecútala con el siguiente comando:
python scraper.pyLa secuencia de comandos de raspado de imágenes de Python registrará la siguiente cadena:
downloading image no. 1 ...
images downloaded successfully to "./images/1.jpg"
# omitted for brevity...
downloading image no. 20 ...
images downloaded successfully to "./images/20.jpg"Explora la carpeta /images y verás las imágenes descargadas automáticamente por la secuencia de comandos:
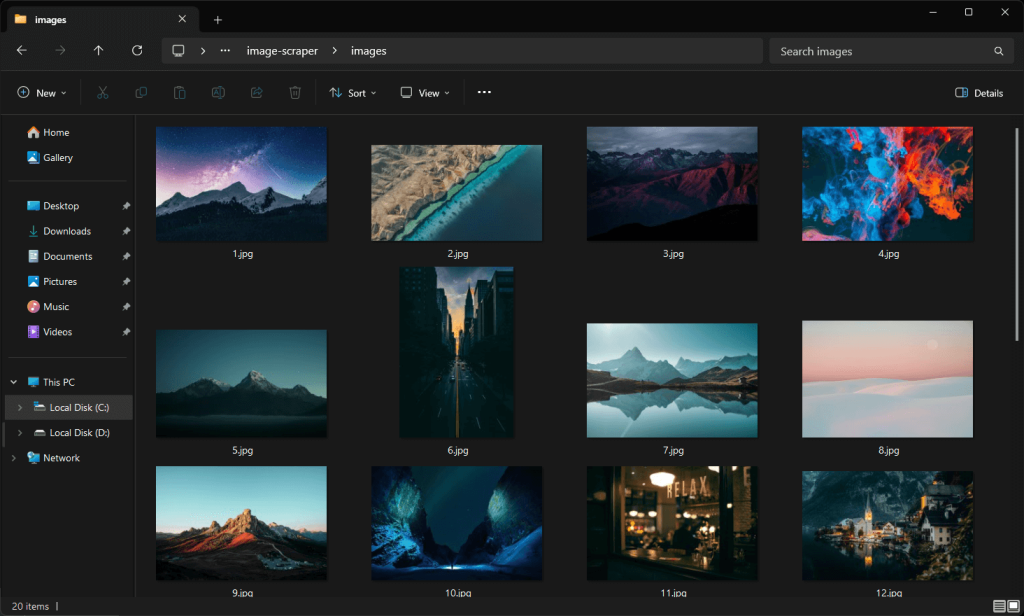
Ten en cuenta que estas imágenes son diferentes a las de la captura de pantalla de la página de Unsplash vistas anteriormente porque el sitio sigue recibiendo contenido actualizado.
¡Ya está! Misión completada.
Paso 8: próximos pasos
Aunque hemos conseguido el objetivo, hay algunas posibles implementaciones para mejorar tu secuencia de comandos de Python. Las más importantes son:
- Exportar las URL de las imágenes a CSV o almacenarlas en una base de datos: de esta forma, podrás descargarlas o usarlas en el futuro.
- Evitar descargar imágenes que ya estén en la carpeta
/images: esta mejora ahorra recursos de red al omitir las imágenes que ya se han descargado. - Extrae también la información de los metadatos: recuperar las etiquetas y la información del autor puede resultar útil para obtener información completa sobre las imágenes descargadas. Descubre cómo hacerlo en nuestra guía sobre raspado web en Python.
- Extrae más imágenes: simula la interacción de desplazamiento infinito, carga más imágenes y descárgalas todas.
Conclusión
En esta guía, has aprendido por qué es útil raspar imágenes de un sitio web y cómo hacerlo en Python. En concreto, has visto un tutorial paso a paso sobre cómo crear una secuencia de comandos de raspado de imágenes en Python que pueda descargar automáticamente imágenes de un sitio. Como se demuestra aquí, no es complejo y solo requiere unas líneas de código.
Al mismo tiempo, no tienes que pasar por alto los sistemas antibot. Selenium es una gran herramienta, pero no puede hacer nada contra tecnologías tan avanzadas. Estos sistemas pueden detectar tu secuencia de comandos como un bot e impedir que acceda a las imágenes del sitio.
Para evitarlo, necesitas una herramienta que pueda renderizar JavaScript y gestionar las huellas dactilares, los CAPTCHA y el antirraspado por ti. ¡De eso se trata exactamente el Scraping Browser de Bright Data!
Habla con uno de nuestros expertos en datos sobre nuestras soluciones de raspado
Preguntas frecuentes
¿Es legal raspar imágenes de un sitio web?
El raspado de imágenes de un sitio web no es una actividad ilegal en sí misma. Al mismo tiempo, es esencial descargar solo imágenes públicas, respetar el archivo robots.txt al raspar y cumplir con los términos y condiciones del sitio. Mucha gente piensa que el raspado web no es legal, pero esto es un mito. Obtén más información en nuestro artículo sobre los mitos del raspado web.
¿Cuáles son las mejores bibliotecas para descargar imágenes con Python?
En sitios de contenido estático, un cliente HTTP como requests y un analizador HTML como beautifulsoup4 será suficiente. En sitios de contenido dinámico o páginas altamente interactivas, necesitarás una herramienta de automatización del navegador como Selenium o Playwright. Consulta la lista de las mejores herramientas de navegador sin interfaz gráfica para el raspado web.
¿Cómo solucionar el «Error HTTP 403: Forbidden» en urllib.request?
El error HTTP 403 se produce porque el sitio de destino reconoce que la solicitud realizada con urllib.request proviene de una secuencia de comandos automatizada. Una forma eficaz de evitar este problema es establecer el encabezado User-Agent en un valor real. Cuando usas el método urlretrieve(), puedes hacerlo de la siguiente manera:
opener = urllib.request.build_opener()
user_agent_string = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
opener.addheaders = [("User-Agent", user_agent_header)]
urllib.request.install_opener(opener)
# urllib.request.urlretrieve(...)




