

A medida que la cantidad de datos en Internet sigue creciendo, el rastreo web, el proceso de navegar y extraer información de sitios web de forma automática, se convierte en una habilidad cada vez más importante que los desarrolladores deben aprender. Esto se hace enviando solicitudes HTTP a servidores web y realizando el parseo de la respuesta HTML para extraer los datos deseados.
El proceso de rastreo web puede ser complejo y llevar mucho tiempo; sin embargo, las herramientas y técnicas adecuadas pueden ser de gran ayuda. Gracias a su flexibilidad y facilidad de uso, Python se ha convertido en un lenguaje muy popular para crear rastreadores web, lo que permite a los desarrolladores escribir rápidamente scripts para automatizar el proceso de extracción de datos.
En este artículo, aprenderás todo sobre el rastreo web con Python utilizando la biblioteca Scrapy.
Por qué necesitas el rastreo web
Antes de sumergirnos en el tutorial, es importante reconocer la diferencia entre el rastreo web y el Scraping web. Aunque son similares, el Scraping web extrae datos específicos de las páginas web, mientras que el rastreo web navega por las páginas web para indexarlas y recopila información para los motores de búsqueda.
El rastreo web es útil en todo tipo de situaciones, entre las que se incluyen las siguientes:
- Extracción de datos: el rastreo web se puede utilizar para extraer datos específicos de sitios web, que luego se pueden utilizar para análisis o investigación.
- Indexación de sitios web: los motores de búsqueda suelen utilizar el rastreo web para indexar sitios web y hacerlos buscables para los usuarios.
- Supervisión: el rastreo web se puede utilizar para supervisar los sitios web en busca de cambios o actualizaciones. Esta información suele ser útil para realizar un seguimiento de la competencia.
- Agregación de contenido: el rastreo web se puede utilizar para recopilar contenido de varios sitios web y agregarlo en una única ubicación para facilitar el acceso.
- Pruebas de seguridad: el rastreo web se puede utilizar para realizar pruebas de seguridad con el fin de identificar vulnerabilidades o debilidades en sitios web y aplicaciones web.
Rastreo web con Python
Python es una opción muy popular para el rastreo web debido a su facilidad de uso en la codificación y su sintaxis intuitiva. Además, Scrapy, uno de los marcos de rastreo web más populares, está construido en Python. Este marco potente y flexible facilita la extracción de datos de sitios web, el seguimiento de enlaces y el almacenamiento de los resultados.
Scrapy está diseñado para manejar grandes cantidades de datos y se puede utilizar para una amplia gama de tareas de Scraping web. Las herramientas incluidas en Scrapy, como el descargador HTTP, la araña para rastrear sitios web, el programador para gestionar la frecuencia de rastreo y el canal de elementos para procesar los datos rastreados, lo hacen muy adecuado para diversas tareas de Scraping web.
Para empezar a rastrear la web con Python, es necesario instalar el marco Scrapy en el sistema.
Abre tu terminal y ejecuta el siguiente comando:
pip install scrapyn
Después de ejecutar este comando, tendrá Scrapy instalado en su sistema. Scrapy le proporciona clases llamadas arañas que definen cómo realizar una tarea de rastreo web. Estas arañas se encargan de navegar por el sitio web, enviar solicitudes y extraer datos del HTML del sitio web.
Creación de un proyecto Scrapy
En este artículo, vas a rastrear un sitio web llamado Books to Scrape y guardar el nombre, la categoría y el precio de cada libro en un archivo CSV. Este sitio web fue creado para funcionar como un entorno de pruebas para proyectos de scraping.
Una vez instalado Scrapy, debes crear una nueva estructura de proyecto utilizando el siguiente comando:
scrapy startproject bookcrawlern
(nota: si aparece el error «comando no encontrado», reinicia tu terminal)
La estructura de directorios predeterminada proporciona un marco claro y organizado, con archivos y directorios separados para cada componente del proceso de Scraping web. Esto facilita la escritura, prueba y mantenimiento de tu código de araña, así como el procesamiento y almacenamiento de los datos extraídos de la forma que prefieras. Así es como se ve tu estructura de directorios:
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
Para iniciar el proceso de rastreo en su proyecto Scrapy, es esencial crear un nuevo archivo de araña en el directorio bookcrawler/spiders, ya que es el directorio estándar donde Scrapy busca cualquier araña para ejecutar el código. Para ello, navegue hasta el directorio bookcrawler/spiders y cree un nuevo archivo llamado bookspider.py. A continuación, escriba el siguiente código en el archivo para definir su araña y especificar su comportamiento:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
Este código define un BookCrawler, que es una subclase del CrawlSpider integrado, y proporciona una forma cómoda de definir reglas para seguir enlaces y extraer datos. El atributo start_urls especifica una lista de URL desde las que comenzar el rastreo. En este caso, solo contiene una URL, que es la página de inicio del sitio web.
El atributo rules especifica un conjunto de reglas para determinar qué enlaces debe seguir la araña. En este caso, solo hay una regla definida, que se crea utilizando la clase Rule del módulo scrapy.spiders. La regla se define con una instancia de LinkExtractor que especifica el patrón de enlaces que debe seguir la araña. El parámetro allow del LinkExtractor se establece en /catalogue/category/books/, lo que significa que la araña solo debe seguir los enlaces que contengan esta cadena en su URL.
Para ejecutar la araña, abre tu terminal y ejecuta el siguiente comando:
scrapy crawl bookspidern
Tan pronto como lo ejecute, Scrapy inicializa la clase de araña BookCrawler, crea una solicitud para cada URL en el atributo start_urls y las envía al programador de Scrapy. Cuando el programador recibe una solicitud, comprueba si la solicitud está permitida por el atributo allowed_domains (si se ha especificado) de la araña. Si el dominio está permitido, la solicitud se pasa al descargador, que realiza una solicitud HTTP al servidor y recupera la respuesta.
En este punto, deberías poder ver todas las URL que tu araña ha rastreado en la ventana de la consola:
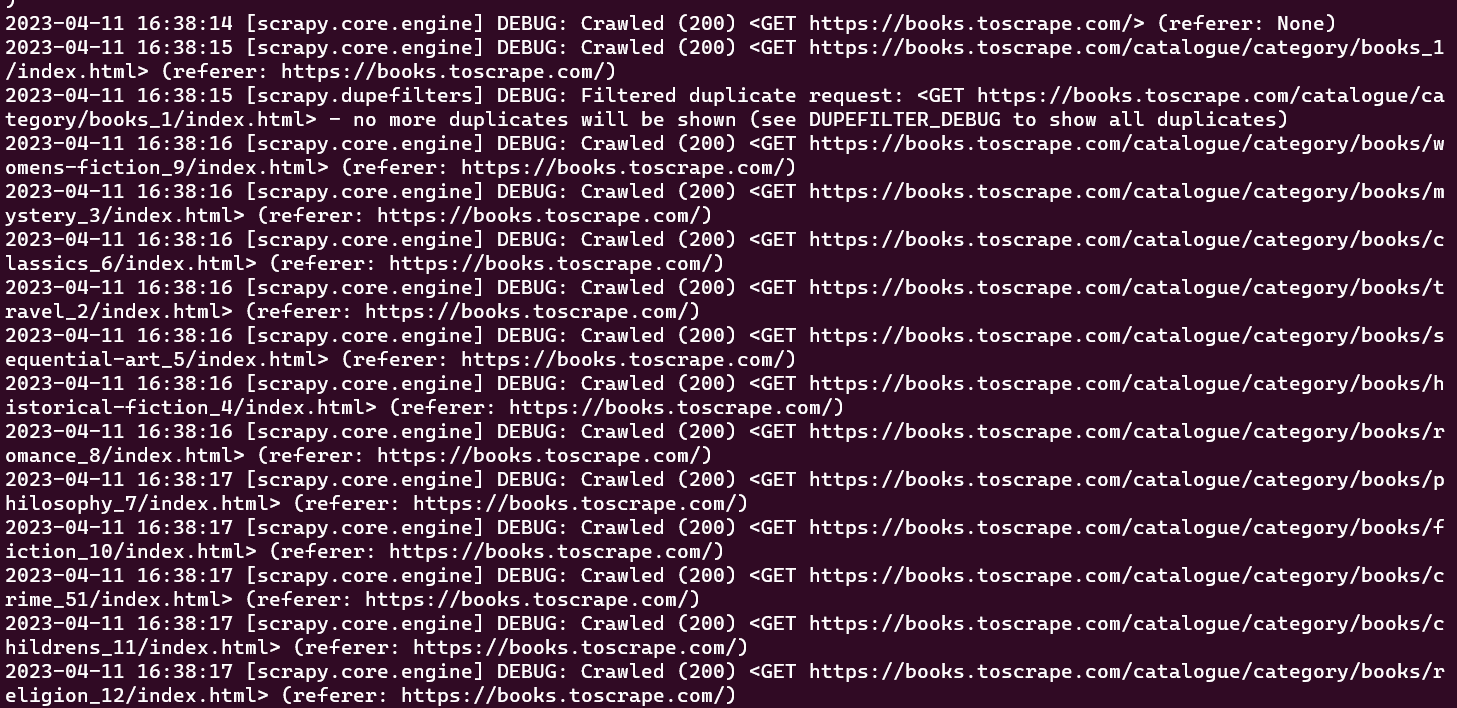
El rastreador inicial que se ha creado solo realiza la tarea de rastrear un conjunto predefinido de URL sin extraer ninguna información. Para recuperar datos durante el proceso de rastreo, es necesario definir una función parse_item dentro de la clase del rastreador. La función parse_item se encarga de recibir la respuesta de cada solicitud realizada por el rastreador y devolver los datos relevantes obtenidos de la respuesta.
Ten en cuenta que la función
parse_itemsolo funciona después de configurar el atributocallbacken tuLinkExtractor.
Para extraer datos de la respuesta obtenida al rastrear páginas web en Scrapy, es necesario utilizar selectores CSS. La siguiente sección ofrece una breve introducción a los selectores CSS.
Un poco sobre los selectores CSS
Los selectores CSS son una forma de extraer datos de la página web especificando etiquetas, clases y atributos. Por ejemplo, aquí hay una sesión de Scrapy shell que se ha inicializado utilizando scrapy shell books.toscrape.com:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003en All products | Books to S...'u003e]n
En esta sesión, la función css toma una etiqueta (es decir, title) y devuelve el objeto Selector. Para obtener el texto dentro de la etiqueta title, debe escribir la siguiente consulta:
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
En este fragmento, se utiliza el pseudo selector text para eliminar la etiqueta title que lo envuelve y devolver solo el texto interior. El método get se utiliza para mostrar solo el valor de los datos.
Para obtener las clases de los elementos, es necesario ver el código fuente de la página haciendo clic con el botón derecho y seleccionando Inspeccionar:
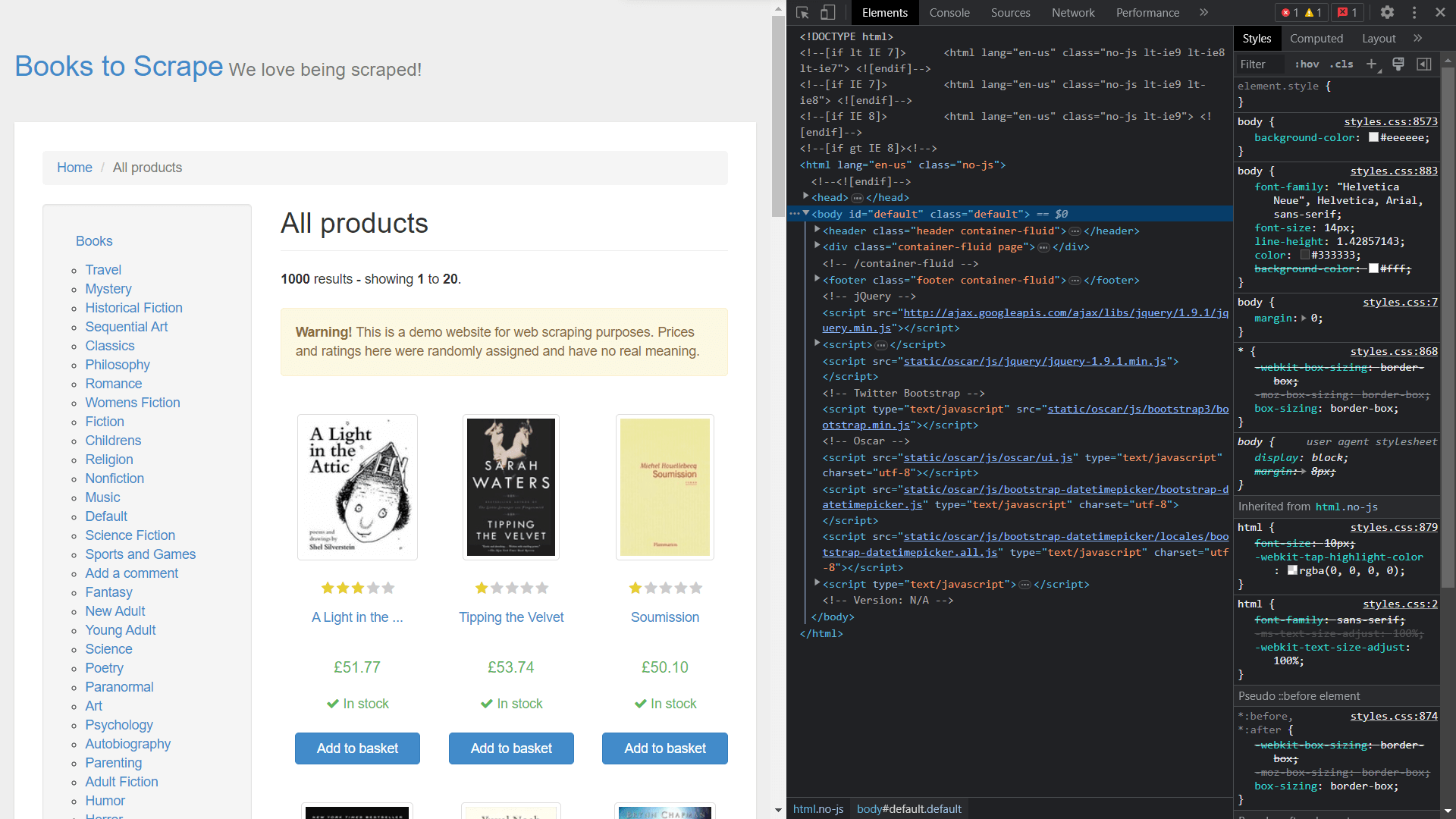
Extracción de datos con Scrapy
Para extraer elementos del objeto de respuesta, debe definir una función de devolución de llamada y asignarla como atributo en la clase Rule.
Abra bookspider.py y ejecute el siguiente código:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
La función parse_item de la clase BookCrawler contiene la lógica para extraer los datos y los envía a la consola. El uso de yield permite a Scrapy procesar los datos en forma de elementos, que luego pueden pasar por canalizaciones de elementos para su posterior procesamiento o almacenamiento.
El proceso de selección de la categoría es una tarea sencilla, ya que está codificado dentro de una simple etiqueta <h1>. Sin embargo, la selección de book_titles se realiza mediante un proceso de selección multinivel, en el que el primer paso consiste en seleccionar la etiqueta <article> con la clase product_pod. A continuación, el proceso de recorrido continúa para identificar la etiqueta <a> anidada dentro de la etiqueta <h3>. Se utiliza el mismo enfoque al seleccionar book_prices, lo que permite recuperar la información necesaria de la página web.
En este punto, ya has creado una araña que rastrea un sitio web y recupera datos. Para ejecutar la araña, abre el terminal y ejecuta el siguiente comando:
scrapy crawl bookspider -o books.jsonn
Cuando se ejecuta, las páginas web rastreadas por el rastreador y sus datos correspondientes se muestran en la consola. El uso del indicador -o indica a Scrapy que almacene todos los datos recuperados en un archivo llamado books.json. Una vez completado el script, se crea un nuevo archivo llamado books.json en el directorio del proyecto. Este archivo contiene todos los datos relacionados con los libros recuperados por el rastreador:
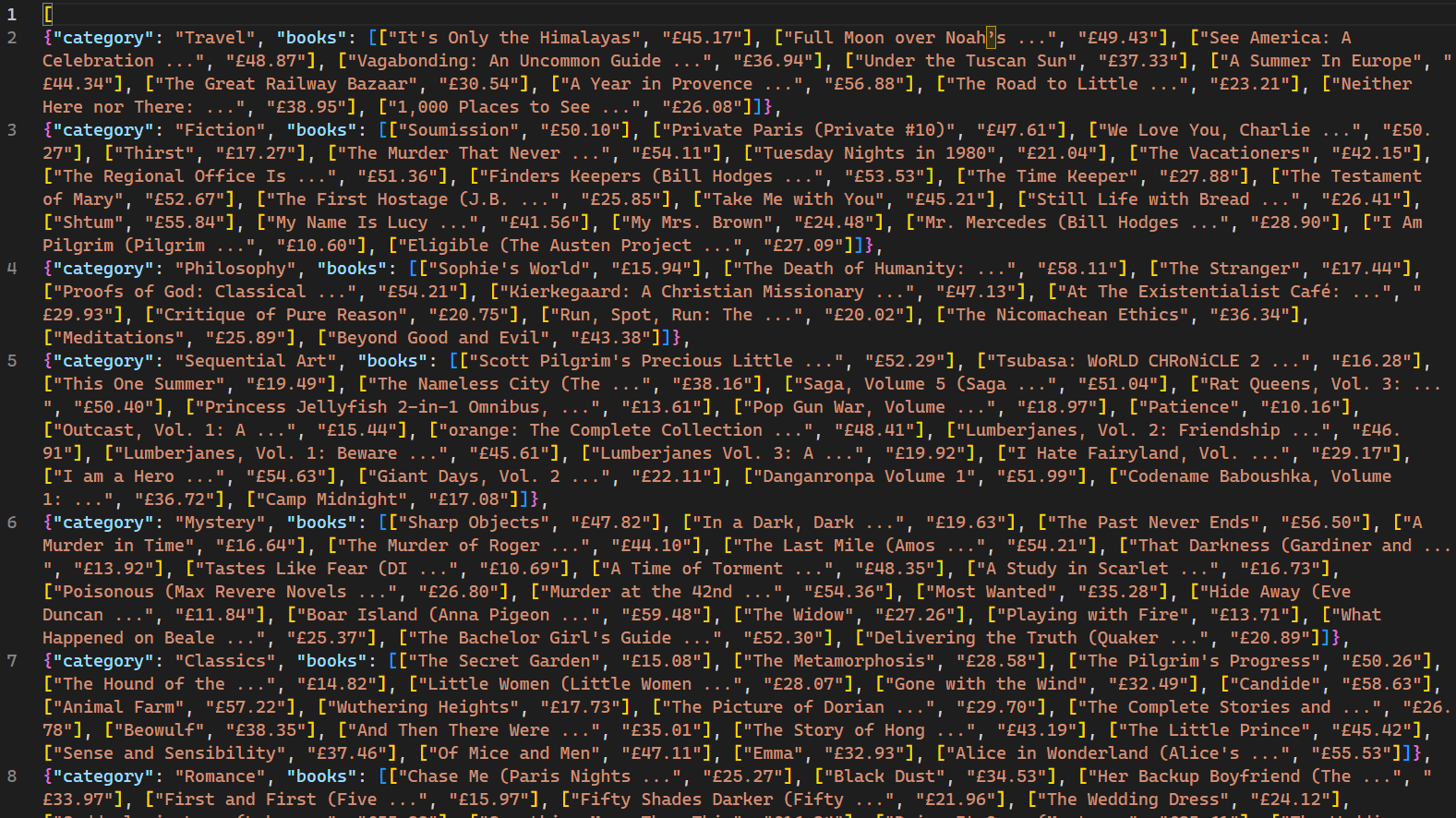
Es importante tener en cuenta que este rastreador web solo es eficaz para sitios web que no emplean mecanismos de bloqueo de IP en respuesta a múltiples solicitudes. Para los sitios que son menos receptivos a los bots y rastreadores web, es necesario un servicio de Proxy como Bright Data para extraer datos a gran escala. Los servicios de Bright Data permiten a los usuarios recopilar datos web de múltiples fuentes, evitando al mismo tiempo los bloqueos y la detección de IP.
Conclusión
El rastreo web, integrado con el Scraping web, es una habilidad muy valiosa para la recopilación de datos y la ciencia de datos. Scrapy, un marco diseñado para el rastreo web, simplifica el proceso al ofrecer rastreadores y Scrapers integrados.
Este artículo le ha guiado a través de la creación de un rastreador web y, a continuación, el scraping de datos utilizando el marco Scrapy. Ha aprendido a utilizar CrawlSpider para realizar un rastreo web sin esfuerzo y ha aprendido conceptos como Rule y LinkExtractor para rastrear patrones específicos de URL. Además, ha cubierto los conceptos de selección de elementos HTML utilizando selectores CSS. Al dominar estas habilidades, estará bien equipado para abordar los retos del rastreo y el Scraping web en la ciencia de datos y más allá.






