

En este tutorial sobre trucos para extraer información de sitios Next.js, aprenderás:
- Qué es Next y por qué es tan popular
- Por qué es fácil realizar scraping web de páginas web de Next.js gracias al funcionamiento de la hidratación de React
- Cómo aprovechar la hidratación de React para el Scraping web
¡Empecemos!
¿Qué es Next.js y cómo funciona?
Next.js es un marco de trabajo de JavaScript basado en React para crear sitios web renderizados del lado del servidor y generados estáticamente. Simplifica el proceso de desarrollo al proporcionar una API rica y un enfoque estructurado para crear aplicaciones React del lado del servidor.
Next.js ha ganado mucha popularidad a lo largo de los años, convirtiéndose en la quinta biblioteca web más utilizada según Statista. Esto se debe a su facilidad de uso, su gran rendimiento, sus similitudes con React, su amplia documentación y el apoyo de la comunidad. No es de extrañar que muchas grandes empresas y startups elijan Next.js para sus necesidades de desarrollo web.
A alto nivel, Next.js funciona recuperando datos en el servidor y pasándolos a los componentes React para crear documentos HTML prerenderizados. Este proceso mejora el rendimiento al generar contenido HTML en el servidor, que luego se puede enviar al cliente para acelerar la carga inicial de la página.
Cómo aprovechar la hidratación de React para el Scraping web
La hidratación salva la brecha entre el renderizado del lado del servidor y el del lado del cliente. En detalle, la hidratación de Next.js es el proceso mediante el cual el documento HTML generado por Next.js se convierte en una aplicación React del lado del cliente totalmente funcional.
Durante la hidratación, después de que el navegador carga la página HTML devuelta por el servidor,React añade interactividad a la página. En concreto, adjunta detectores de eventos y gestiona el estado en los nodos DOM que corresponden a los componentes React renderizados en el servidor.
Estos son los pasos que requiere React para hidratar una página prerenderizada:
- Renderización inicial del servidor: el servidor genera el documento HTML con la representación HTML de los componentes React utilizados en la página.
- Ejecución de JavaScript del lado del cliente: cuando el cliente recibe el marcado HTML, ejecuta el paquete JavaScript que contiene el código React.
- Reconciliación: React compara el HTML devuelto por el servidor con la representación DOM virtual generada sobre la marcha. Más información en la documentación oficial.
- Hidratación: si ambos son iguales, React completa el renderizado añadiendo controladores de eventos y gestionando el estado, al tiempo que reutiliza la mayor parte posible del DOM existente.
Para realizar esta operación, React necesita los mismos datos que utiliza el servidor para generar el documento HTML. Por eso Next.js añade algunos elementos DOM especiales que contienen los datos de las propiedades a la página generada.
En algunos sitios de Next.js, puedes encontrar estos datos en el elemento <script> con el ID __NEXT_DATA__. Este nodo DOM especial contiene datos en formato JSON que React utiliza para la hidratación, como se muestra a continuación:
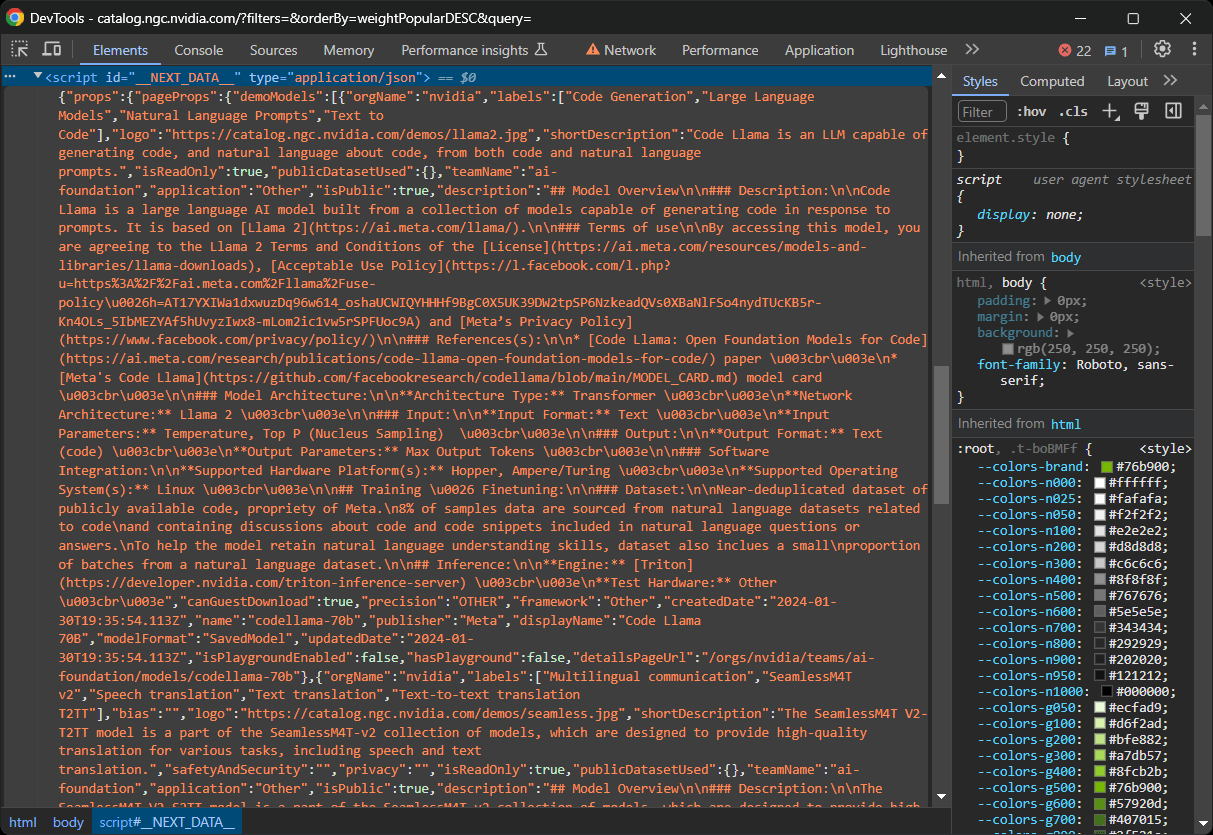
En los sitios Next.js recientes que utilizan el nuevo App Router, los datos de hidratación se almacenan en las llamadas a la función self.__next_f.push() en varios nodos <script>:
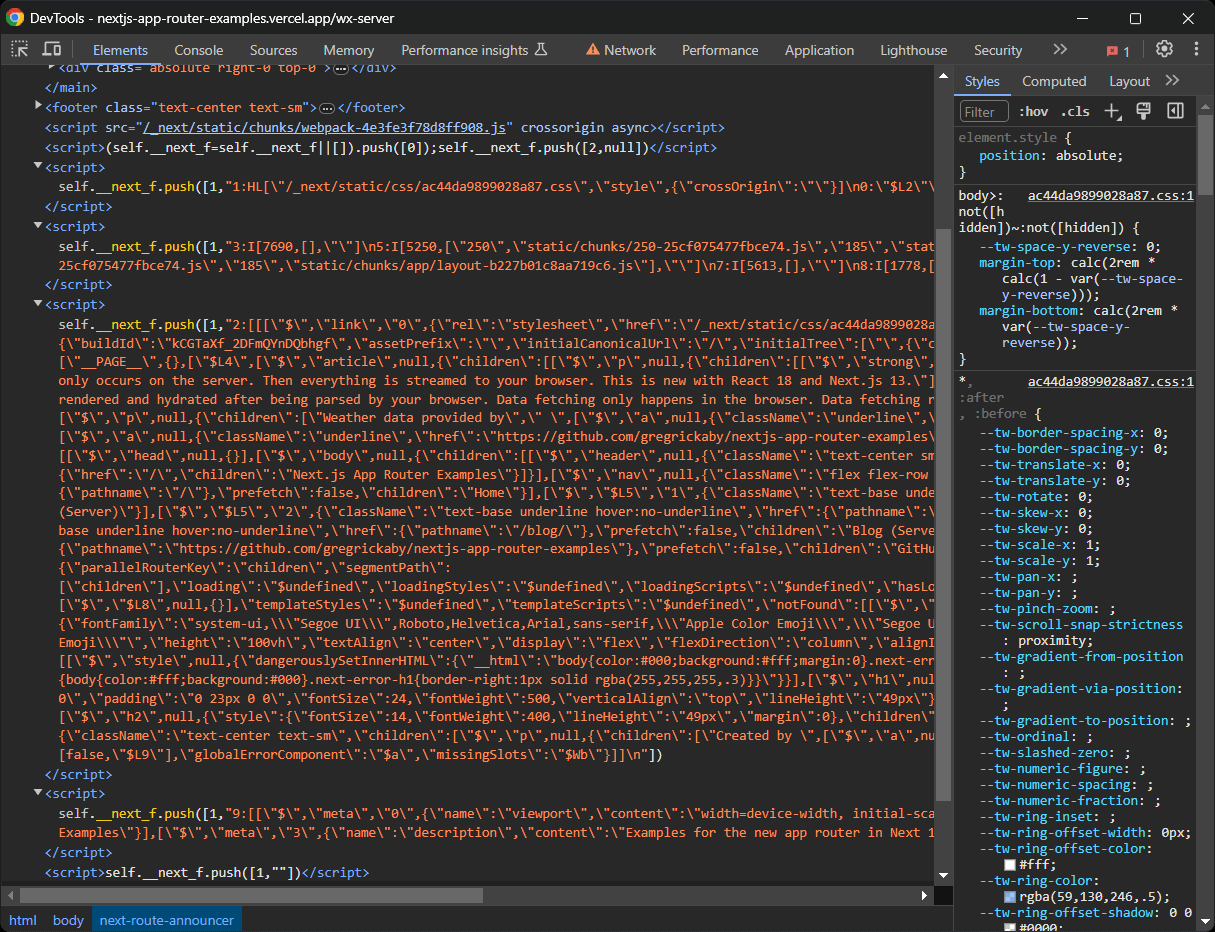
Ten en cuenta que estos nodos pueden contener incluso más datos de los que se muestran en el sitio. ¿Cómo es esto posible? Porque esos elementos de hidratación almacenan todos los datos de la API y la base de datos recuperados del servidor durante la generación de la página y pasados a los componentes de React. Sin embargo, es posible que no se pueda acceder a todos los atributos de esos objetos ni utilizarlos en los componentes.
Ahora bien, no importa si realmente entiendes por qué esos datos deben estar ahí para que React funcione. Lo que importa es que las páginas web generadas a través de Next.js contienen los datos que se van a renderizar en formato JSON dentro de nodos DOM especiales. Como puedes imaginar, esto tiene enormes implicaciones para el Scraping web de Nex.js.
Rastrear sitios Next.js a través de los datos de hidratación
Extraer datos de una página creada en Next.js es tan fácil que ni siquiera necesitas un script de scraping. Las herramientas de desarrollo de tu navegador serán suficientes.
Veamos ahora cómo aprovechar la hidratación de React para extraer datos de sitios Next.js en segundos.
Extracción de datos de __NEXT_DATA__
Supongamos que ha verificado que la página de destino que desea rastrear está creada con Next.js (descubra cómo en la pregunta frecuente).
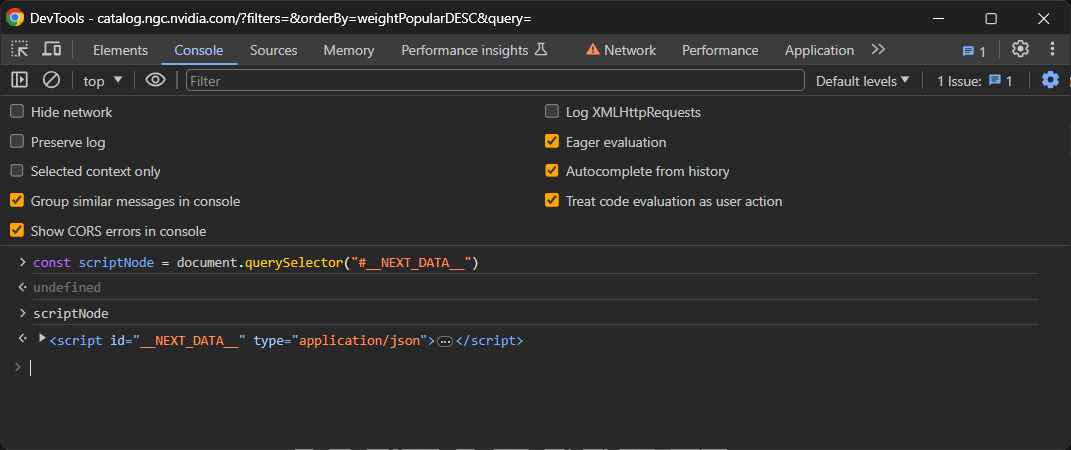
Ahora, visita la página en tu navegador, haz clic con el botón derecho y selecciona «Inspeccionar» para acceder a DevTools. Ve a la pestaña Consola y ejecuta la línea de JavaScript siguiente para seleccionar el elemento <script> deseado:
const scriptNode = document.querySelector("#__NEXT_DATA__")Esto utilizará la función querySelector() para seleccionar el elemento en el DOM con el ID __NEXT_DATA__ y lo asignará a la variable scriptNode.
Si escribe scriptNode en la consola y pulsa Intro, obtendrá el nodo deseado:
Accede a su contenido HTML interno yrealiza el parseo como contenido JSONcon:
const jsonData = JSON.parse(scriptNode.innerHTML)
¡Et voilà! El objeto jsonData ahora contendrá todos los datos que React utilizó para renderizar los componentes en la página:
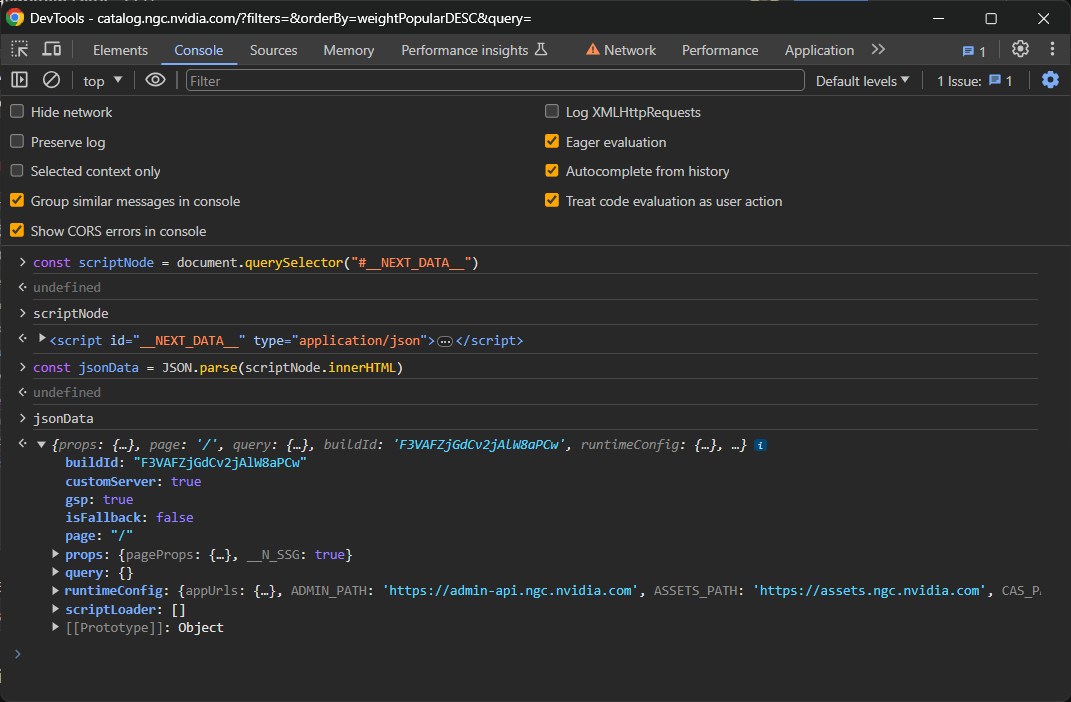
En detalle, céntrate en el campo pageProps dentro de props:
jsonData.props.pageProps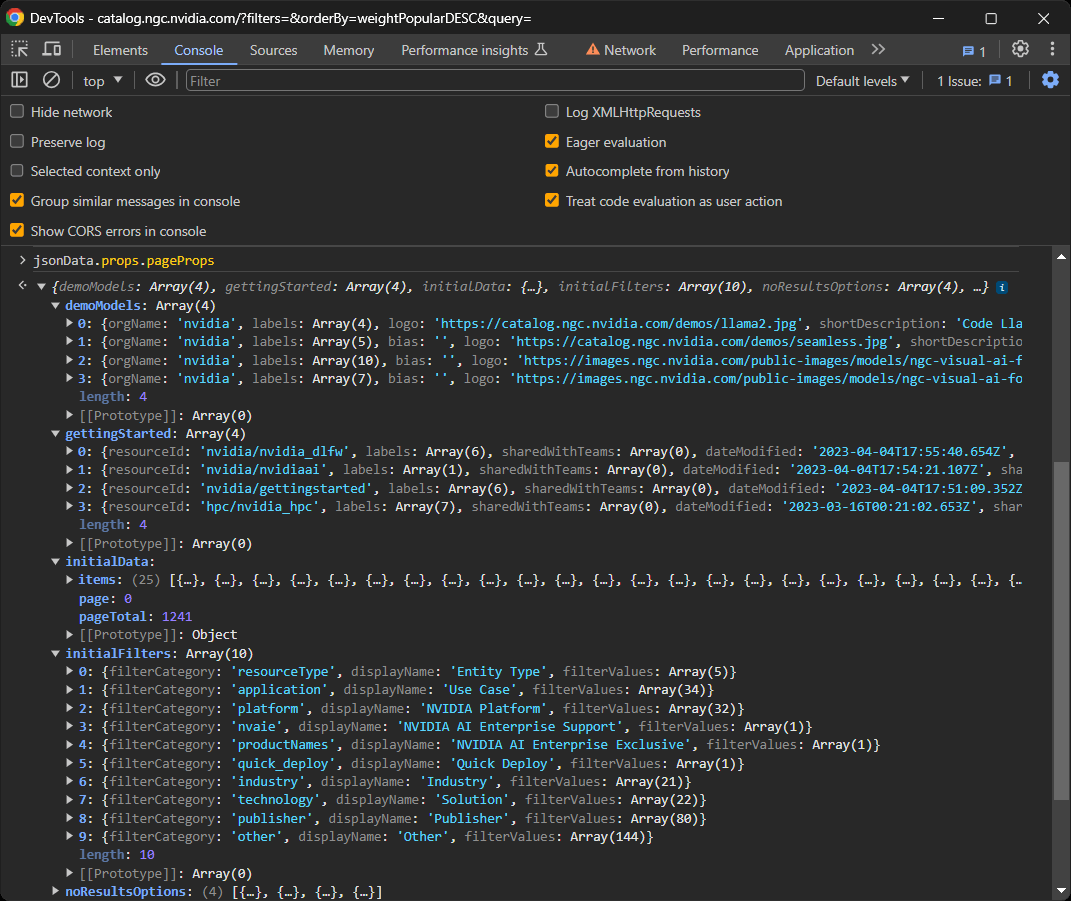
A continuación, haz clic con el botón derecho del ratón en el objeto y selecciona la opción «Copiar objeto»:
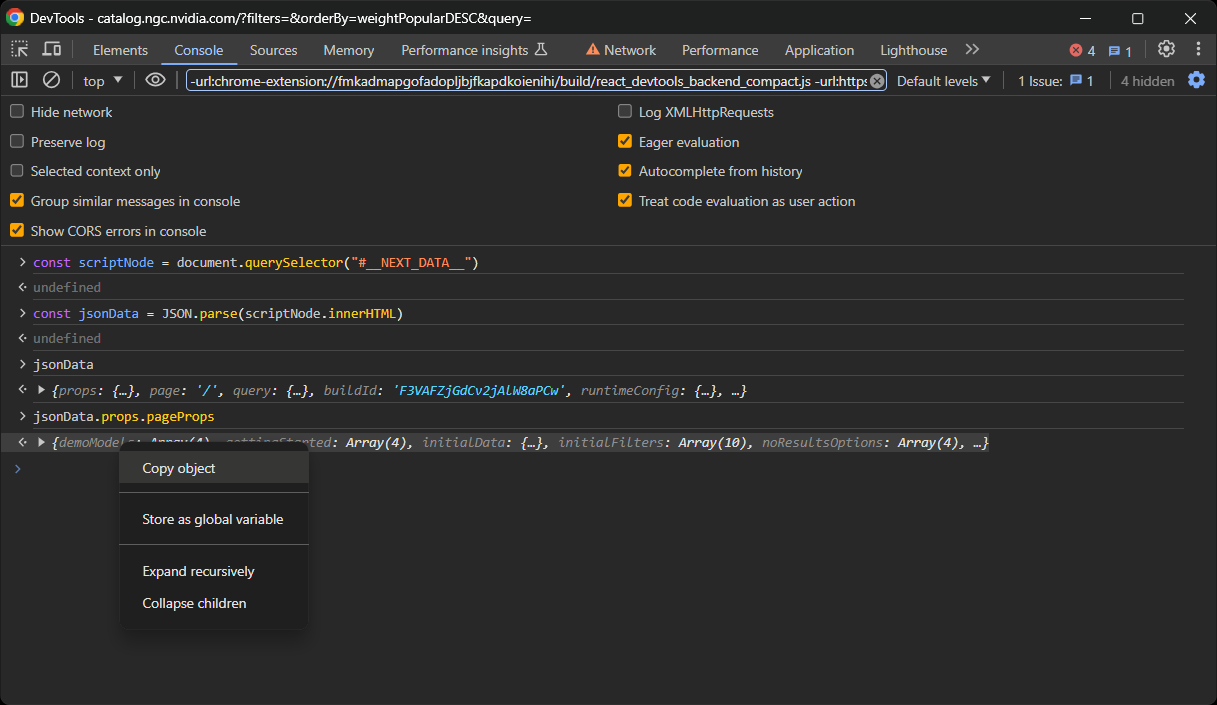
Por último, crea un archivo data.json y pega en él el contenido deseado.
¡Genial! Acabas de realizar Scraping web en un sitio Next.js en menos de un minuto.
Si lo juntas todo, obtendrás este script de scraping de Next.js:
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pagePropsRecuperación de datos de las funciones self.__next_f.push
Next.js 13 introdujo el App Router. Esto cambia la forma en que Next.js entrega los datos a React para la hidratación. En este caso, debes seleccionar todos los nodos <script> que contengan la cadena self.__next_f.push.
Una vez más, visite la página de destino en el navegador y acceda a la consola. Ejecute el siguiente comando para seleccionar los nodos <script>:
const scriptNodes = document.querySelectorAll("script")querySelectorAll() devuelve un objeto NodeList. Conviértalo en una matriz con Array.from() para aplicar el método filter() y obtener solo los nodos de interés:
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))Ahora, hydrationScriptNodes contendrá todos los elementos <script> de hidratación de la página:
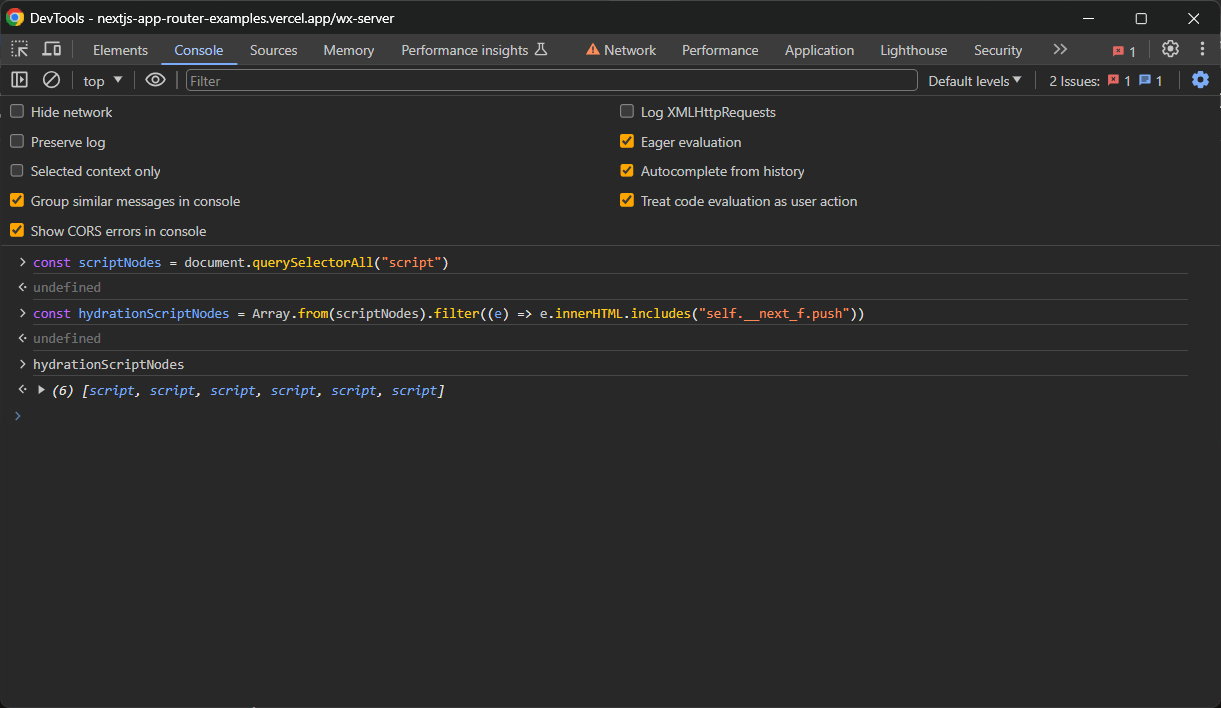
Sin embargo, por lo general solo se desea el nodo que tiene el atributo initialTree. Aquí es donde se almacenan todos los datos de hidratación de interés:
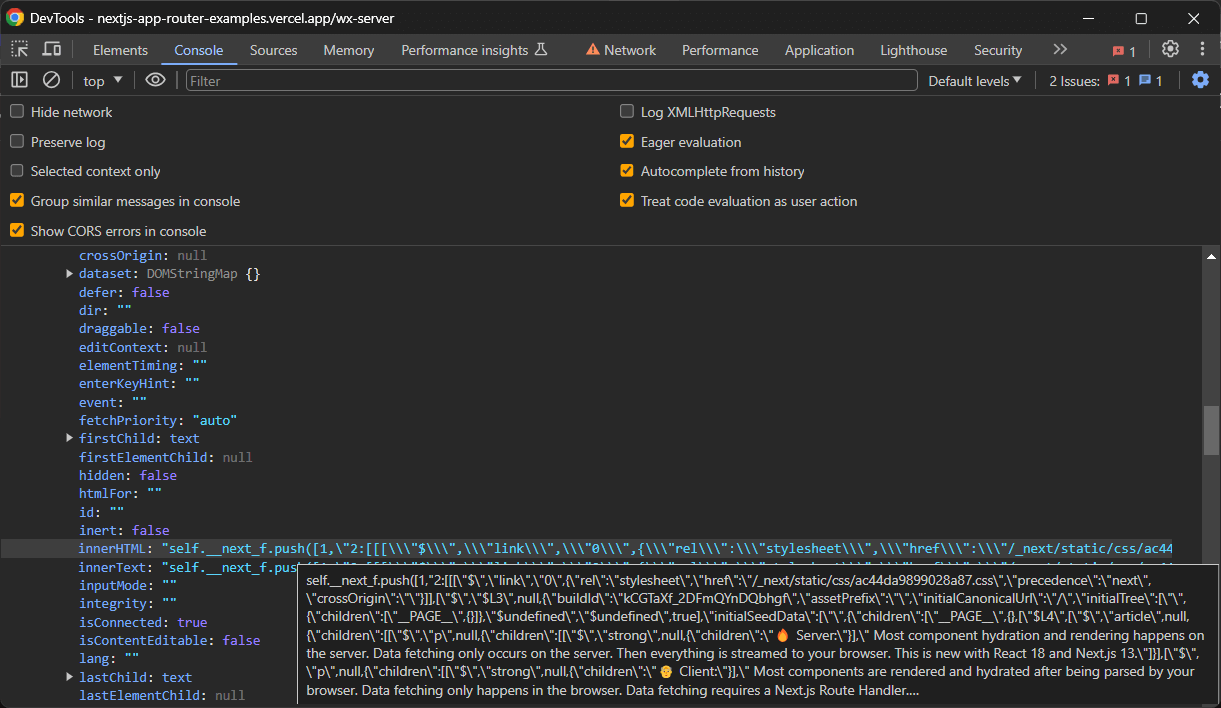
Selecciónelo con:
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))A continuación, extraiga los datos de interés con:
scriptNode.innerHTMLTenga en cuenta que los datos recuperados contienen la información de interés, pero requieren un parseo adicional. Puede convertirlos a un formato más legible con unas pocas líneas adicionales.
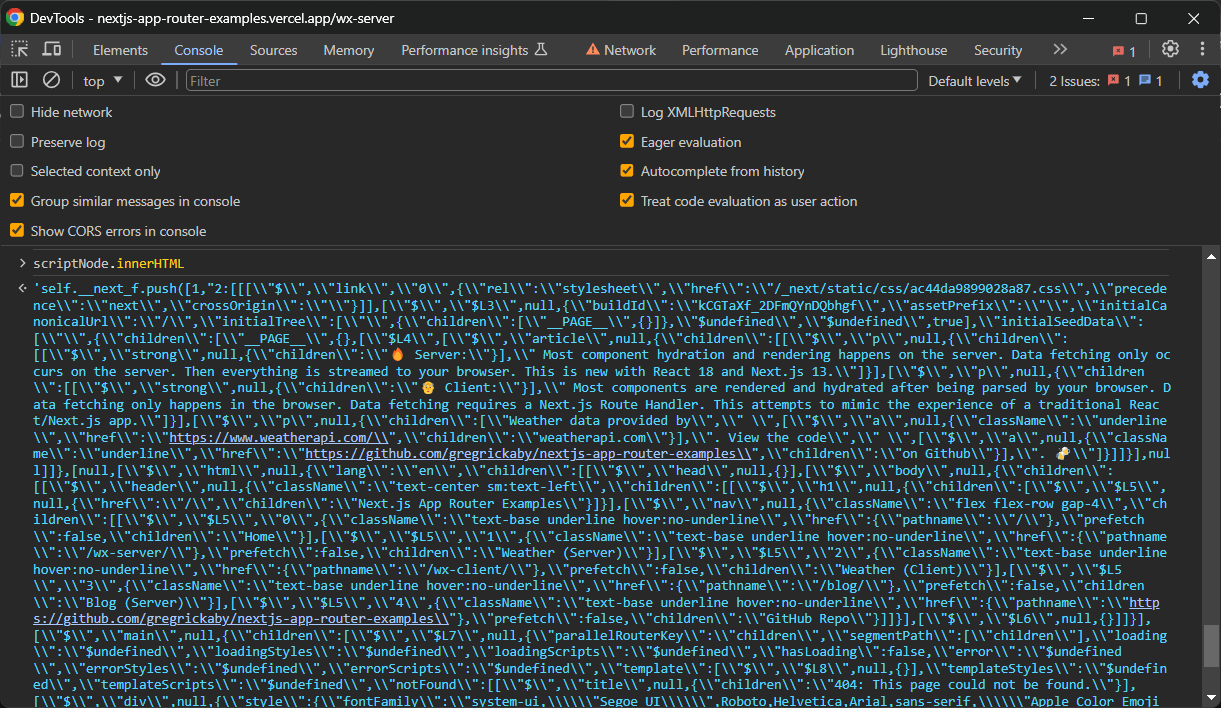
En este caso, el script de scraping de Next.js es:
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTML¡Enhorabuena! ¡Rastrear sitios Next.js nunca ha sido tan fácil!
Limitaciones de este enfoque de scraping de Next.js
Aunque este enfoque de rastreo basado en los datos de hidratación de React es rápido y eficaz, tiene algunas limitaciones. Estas son:
- Datos parciales: los nodos especiales
<SCRIPT>añadidos por Next.js solo contienen los datos recuperados por el servidor y pasados a los componentes React durante la hidratación. Es posible que no sean todos los datos que contiene la página. Esto se debe a que los componentes React pueden tener valores codificados o recuperar otros datos de forma dinámica a través de AJAX. En este caso, es necesario realizar el Scraping web con una herramienta de automatización del navegador. - Se requiere un parseo adicional:
self.__next_f.pushimplica datos en un formato propietario, y parsearlos correctamente no siempre es fácil. - Requiere operaciones manuales: a menos que traduzca los scripts escritos anteriormente a scripts de scraping en JavaScript, Python o un lenguaje similar e integre la lógica para la exportación de datos, deberá exportar los datos manualmente a un archivo de texto. Obtenga más información en nuestra guía de Scraping web con JavaScript y Node.js.
Conclusión
En este artículo, ha aprendido qué es Next.js, por qué es una de las tecnologías más utilizadas en el mundo para crear sitios web y cómo extraer datos de ella. En particular, se ha dado cuenta de que se basa en la hidratación de React y lo que eso implica. Debido a ello, las páginas HTML devueltas por el servidor ya contienen todos los datos que necesita (¡e incluso en formato JSON!). Esto hace que el Scraping web de sitios Next.js sea muy fácil.
El verdadero problema es otro: ser bloqueado por las tecnologías antibots. Estos sistemas pueden detectar y bloquear tu script de scraping automatizado. Afortunadamente, Bright Data tiene varias soluciones eficaces para ti:
- Web Scraper IDE: un IDE en la nube para crear rastreadores web que pueden eludir y evitar automáticamente cualquier bloqueo.
- Web Scraper API: acceda fácilmente a datos web estructurados mediante programación, con un tiempo de actividad del 99,99 % y una escalabilidad ilimitada.
- Navegador de scraping: un navegador controlable basado en la nube que ofrece capacidades de renderización de JavaScript mientras gestiona CAPTCHAs, huellas digitales del navegador, reintentos automatizados y mucho más por ti. Se integra con las bibliotecas de navegadores de automatización más populares, como Playwright y Puppeteer.
- Web Unlocker: una API de desbloqueo que puede devolver sin problemas el HTML sin procesar de cualquier página, eludiendo cualquier medida antirrastreo.
¿No quiere ocuparse del Scraping web, pero sigue interesado en los datos en línea? ¡Explore los Conjuntos de datos listos para usar de Bright Data!
Preguntas frecuentes
¿Es posible ocultar o eliminar __NEXT_DATA__ del DOM en Next.js?
No, no se puede eliminar ni ocultar. Si decidieras eliminar el elemento _NEXT_DATA_ <script> del DOM, React no podría hidratarse. Dado que React necesita los datos de ese script para funcionar correctamente, no puedes eliminarlo sin esperar algún mal funcionamiento o degradación de la funcionalidad. Lee el debate de GitHub dedicado a este tema.
¿Es posible eliminar las llamadasself.__next_f.push del DOM?
No, no se pueden eliminar las llamadas self.__next_f.push en los nodos <script> añadidos por Next.js. Esos elementos DOM son añadidos por el servidor para que la aplicación React del lado del cliente pueda hidratarse y funcionar como se espera. Para obtener más detalles, consulta el debate de GitHub dedicado a ese tema.
¿Cómo saber si un sitio está creado con Next.js?
Hay varias formas de saber si un sitio está creado con Next.js. En primer lugar, busca el encabezado X-Powered-By establecido por defecto por algunas versiones de Next.js:
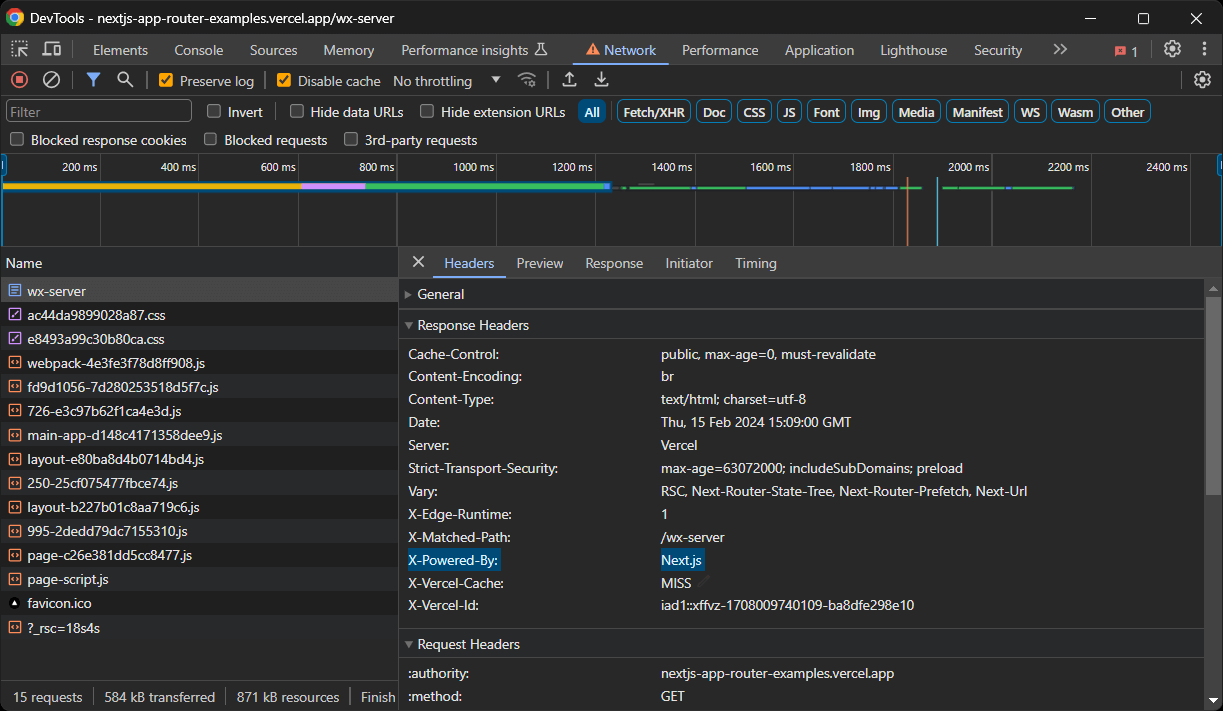
De lo contrario, compruebe si el DOM contiene un nodo <script id="__NEXT_DATA__" ... > o algunos nodos <script>self.__next_f.push(...)</script>.
¿Es Next.js la única tecnología que se basa en la hidratación de React?
No, Next.js no es la única tecnología que se basa en la hidratación de React. Otros generadores de renderizado del lado del servidor (SSR), como Gatsby, también utilizan la hidratación de React para convertir el HTML renderizado por el servidor en aplicaciones React interactivas en el lado del cliente. Este proceso es un enfoque común en SSR con React y no se limita a Next.js.




