

En esta guía, vamos a cubrir:
- Introducción al raspado web en R
Introducción al Raspado web en R
El primer paso sería entender qué herramientas vamos a utilizar en este tutorial de R.
Entendiendo las Herramientas: R y rvest
R es una biblioteca rica y fácil de usar para el análisis estadístico y la visualización de datos que proporciona herramientas útiles para la manipulación de datos y la tipografía dinámica.
rvest一de “harvest “一 es el más popular o uno de los paquetes de R más populares, ofrece funciones de raspado web, también gracias a su interfaz extremadamente fácil de usar. Vanilla rvest permite extraer datos de una sola página web, lo que es perfecto para una exploración inicial. Posteriormente, se puede ampliar con la biblioteca polite para extraer datos de varias páginas.
Configuración del entorno de desarrollo
Si aún no está utilizando R dentro de RStudio, siga las instrucciones a continuación para su instalación.
Una vez hecho esto, abra la consola e instale rvest:
install.packages("rvest")
Como parte de la colección tidyverse, se recomienda oficialmente ampliar las funcionalidades incorporadas de rvest con otros paquetes de la colección como magrittr para la legibilidad del código o xml2 para trabajar con HTML y XML. Puede hacerlo instalando directamente tidyverse:
install.packages("tidyverse")Comprender la página web
El raspado web es una técnica para recuperar datos de páginas web dentro de procesos automatizados que están en completa conformidad con las normas.
De esta definición se desprenden tres consideraciones importantes:
- Los datos se presentan en varios formatos.
- Los sitios web presentan la información de maneras muy diferentes.
- Es necesario que se tenga acceso legal a los datos raspados.
Para entender cómo raspar una URL, primero hay que entender cómo se muestra el contenido de la página web a través del lenguaje de marcado HTML y el lenguaje de estilo de hoja CSS.
HTML proporciona el contenido y la estructura de la página web, que se carga en el navegador para crear un Modelo de Objetos del Documento (DOM) en forma de árbol, organizando el contenido con “tags.“. Las etiquetas (tags) tienen una estructura jerárquica, y cada una de ellas tiene una funcionalidad específica que se aplica a todo el contenido incluido en sus declaraciones de apertura () y cierre ():
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html>La etiqueta es el componente mínimo de cualquier página web, con las etiquetas <head> y <body> anidadas en su interior. <head> y <body> son a su vez “padres” de otras etiquetas dentro de ellas, siendo <div> (para sección de documento) y (para párrafo) algunos de sus “hijos” más comunes.
En el fragmento anterior, se puede ver los “atributos” asociados a cada “element” HTML: lang, class y style están preconfigurados; los atributos que empiezan con data- son personalizados para Amazon.
class es de interés particular para el raspado web, junto con el atributo id ya que nos permite dirigirnos a un grupo de elementos y a elementos específicos, respectivamente. Originalmente, esto se ocupaba para establecer estilos en CSS.
CSS establece el estilo de la página web. Se puede seleccionar cualquier elemento HTML y asignar nuevos valores a sus propiedades de estilo. También se puede aplicar estilos CSS en línea dentro del elemento HTML con el atributo style, como se mostró en la sección anterior:
<body .. style="padding-bottom: 0px;">En CSS puro, esto se escribiría como:
body {padding-bottom: 0px;}
Aquí, body es el “selector”, padding-bottom es la “property” (propiedad), y 0px es el “value” (valor).
Cualqiuer tag, class, o id puede usarse como un selector CSS.
Los usuarios pueden interactuar dinámicamente con el contenido mostrado en la página web mediante las funcionalidades que proporciona el lenguaje de programación JavaScript a través de la etiqueta script. Tras una interacción del usuario, el contenido mostrado puede cambiar y puede aparecer contenido nuevo; los raspadores web avanzados pueden imitar las interacciones del usuario, como veremos más adelante.
Herramientas de desarrollo
Los principales navegadores web ofrecen herramientas integradas para desarrolladores que permiten recopilar y actualizar en tiempo real la información técnica de una página web con fines de registro, depuración, pruebas y análisis del rendimiento. En este tutorial, utilizaremos las DevTools de Chrome.
Se puede acceder a las Herramientas para desarrolladores desde la esquina superior derecha del navegador, en Más herramientas:
En DevTools, es posible desplazarse por el HTML no procesado en la pestaña Elementos. Al desplazarse por cualquier línea HTML, el elemento correspondiente renderizado en la página web se resaltará en azul:
A la inversa, se puede hacer clic en el icono de la esquina superior izquierda y seleccionar cualquier elemento renderizado de la página web para redirigirse a su homólogo HTML sin procesar, de nuevo resaltado en azul.
Estos dos procesos son todo lo necesario para extraer los descriptores CSS para nuestro tutorial práctico.
Profundización en raspado web en R: Tutorial
En esta sección, exploraremos cómo hacer raspado web de la URL de Amazon para extraer reseñas de productos.
Requisitos previos
Asegurarse de tener instalado lo siguiente en el entorno Rstudio:
- R = 4.2.2
- rvest = 1.0.3
- tidyverse = 1.3.2
Exploración interactiva de la página web
Se puede utilizar las DevTools de Chrome para explorar el HTML de su URL y crear una lista de todas las clases e IDs de los elementos HTML que contienen la información que nos interesa extraer, es decir, las reseñas de los productos:

Cada reseña de cliente pertenece a un div con un id en el formato:
customer_review_$INTERNAL_ID.
El contenido HTML del div correspondiente a la reseña del cliente en la captura de pantalla anterior es el siguiente:
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
Cada parte del contenido de interés para las reseñas de clientes tiene su clase única: review-title-content para el título, review-text-content para el cuerpo y review-rating para la valoración.
Se podría comprobar que la clase es única en el documento y utilizar directamente el “selector simple”. Un enfoque más infalible es utilizar en su lugar el Descriptor CSS, que seguirá siendo único incluso si la clase se asigna a nuevos elementos en el futuro.
Basta con recuperar el Descriptor CSS haciendo clic con el botón derecho del ratón sobre el elemento en las Herramientas para desarrolladores y seleccionando Copiar selector:
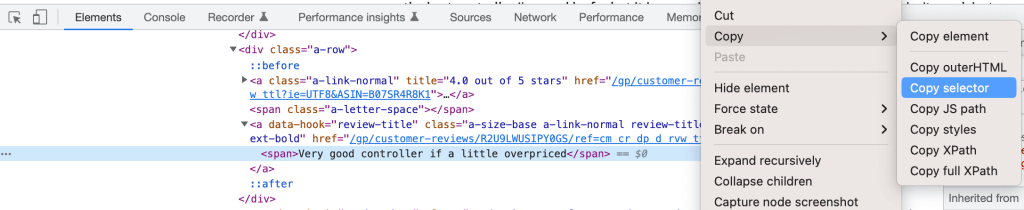
Se pueden definir los tres selectores como:
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > spanfor the titlecustomer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > spanfor the bodycustomer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > spanfor the rating *.review-ratingse ha añadido manualmente para mejorar la coherencia.
Selector CSS vs. XPath para raspado web
Para este tutorial, hemos decidido utilizar un selector CSS para identificar elementos para el raspado web. El otro enfoque común es utilizar XPath, es decir, la ruta XML, que identifica un elemento a través de su ruta completa en el DOM.
Puede extraer el XPath completo siguiendo el mismo procedimiento del selector CSS. Por ejemplo, el título de la revisión es:
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
Un selector CSS es ligeramente más rápido, mientras que XPath tiene una compatibilidad con versiones anteriores ligeramente mejor. Aparte de estas pequeñas diferencias, la selección de uno en vez del otro depende más de las preferencias personales que de las implicaciones técnicas.
Extracción programática de información de la página web
Aunque podríamos utilizar la Consola directamente para empezar a explorar cómo hacer raspado web de la URL, en su lugar crearemos un script para trazabilidad y reproducibilidad, y lo ejecutaremos a través de la Consola utilizando el comando source ().
Después de crear el script, el primer paso es cargar las librerías instaladas:
library(”rvest”)
library(”tidyverse”)A continuación, se puede extraer el contenido de interés mediante programación de la siguiente manera. Primero, se crea una variable donde se almacenará la URL a buscar:
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
A continuación, se extrae el número de identificación estándar de Amazon (ASIN) de la URL para utilizarlo como ID de producto único:
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
El uso de RegEx para limpiar el texto extraído mediante raspado web es habitual y recomendable para garantizar la calidad de los datos.
Ahora, se descarga el contenido HTML de la página web:
HTMLContent <- read_html(HtmlLink)
La función read_html() forma parte del paquete xml2.
Si se imprime() el contenido, veremos que coincide con la estructura HTML sin procesar analizada anteriormente:
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
Ahora se puede extraer los tres nodos de interés para todas las reseñas de productos de la página. Utilice los descriptores CSS proporcionados por DevTools de Chrome, modificados para eliminar el identificador específico de la revisión del cliente #customer_review-R2U9LWUSIPY0GS y el conector ” > ” de la cadena; también puede aprovechar las funcionalidades html_nodes() y html_text() de rvest para guardar el contenido HTML en objetos separados.
Los siguientes comandos extraerán los títulos de las reseñas:
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
Un ejemplo de entrada en review_title es “Muy buen controlador aunque un poco caro”.
El código siguiente extraerá el cuerpo de la reseña:
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
Un ejemplo de entrada en review_body comienza con “Sinceramente, no estoy seguro de por qué el precio…”.
Y puede utilizar los siguientes comandos para extraer la valoración de la reseña:
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
Un ejemplo de entrada en review_rating es “4,0 de 5 estrellas”.
Para mejorar la calidad de esta variable, extraiga sólo la calificación “4.0” y conviértala a int:
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
La funcionalidad de conducto %>% es proporcionada por el conjunto de herramientas magrittr.
Ahora es el momento de exportar el contenido raspado dentro de un tibble para el análisis de datos. tibble es un paquete de R que también pertenece a la colección tidyverse y se utiliza para manipular e imprimir marcos de datos.
df <- tibble(review_title, review_body, review_rating)
El marco de datos de salida es el siguiente:

Finalmente, es una buena idea refactorizar el código en la función scrape_amazon <- function(HtmlLink) para cumplir con las mejores prácticas y preparar mejor el código para escalar a múltiples URLs.
Escalado a múltiples URLs
Una vez creada la plantilla de raspado web, puede crear una lista de URL para todos los productos de los principales competidores en Amazon mediante el rastreo y el raspado web .
A la hora de escalar a múltiples URLs para producir la solución, es necesario definir los requisitos técnicos de la aplicación.
Contar con unos requisitos técnicos bien definidos garantizará el correcto cumplimiento de los requisitos empresariales y la perfecta integración con los sistemas existentes.
Es necesario actualizar la función de raspado web para que admita una combinación de lo siguiente en función de los requisitos técnicos específicos:
- Proceso en tiempo real o por lotes
- Formatos de salida, como JSON, NDJSON, CSV o XLSX.
- Destinos de salida como correo electrónico, API, webhook o almacenamiento en nube.
Ya hemos mencionado que se puede expandir rvest usando polite para raspar datos en múltiples páginas web. polite crea y gestiona una sesión de recolección web mediante el uso de tres funcionalidades principales, en total conformidad con el archivo robots.txt del proveedor de alojamiento web y con limitación de velocidad y caché de respuesta incorporadas:
bow()crea la sesión de raspado para una URL específica, es decir, le presenta al anfitrión web y le pide permiso para raspar.scrape()accede al HTML de la URL; puede canalizar la función ahtml_nodes()yhtml_text()desde rvest para recuperar contenido específico.nod()actualiza la URL de la sesión a la página siguiente, sin necesidad de volver a crear una sesión.
Citando directamente de su página web, “Los tres pilares de una sesión polite son pedir permiso, tomárselo con calma y nunca preguntar dos veces“.
Siguiente paso: ¿Preconstruido vs. Autoconstruido?
Para desarrollar un raspador web de última generación que pueda extraer buenos datos para una empresa, es necesario disponer de algunas capacidades:
- Un equipo de especialistas en datos con experiencia en extracción de datos web.
- Un equipo de ingenieros de DevOps con experiencia en gestión de proxy y elusión anti-bot para permitir superar CAPTCHAs y desbloquear sitios web menos accesibles al público.
- Un equipo de ingenieros de datos con experiencia en la creación de infraestructuras para la extracción de datos en tiempo real y por lotes.
- Un equipo de expertos en derecho para entender los requisitos legales de protección de datos para la privacidad (como GDPR y CCPA).
Los contenidos para la web se presentan en formatos variados, y es difícil encontrar dos sitios web con exactamente la misma estructura. Cuanto más complejo sea un sitio web y más funciones y datos haya que raspar, más avanzados serán los conocimientos de programación necesarios, por no mencionar el tiempo y los recursos adicionales que requerirá la solución.
Lo normal es que se desee implementar al menos las siguientes funcionalidades avanzadas:
- Minimizar las posibilidades de CAPTCHAs y detección de bots: Un enfoque sencillo en este caso es añadir un sleep() aleatorio para evitar la sobrecarga de los servidores web y los patrones de solicitud habituales. Un enfoque más eficaz es utilizar un user_agent o un servidor proxy para repartir las peticiones entre diferentes IPs.
- Raspado de sitios web con Javascript: En nuestro ejemplo de Amazon, la URL no cambia al seleccionar una variante específica del producto. Esto es aceptable para el raspado de reseñas, ya que son compartidas, pero no para el raspado de especificaciones de producto. Para imitar las interacciones del usuario en páginas web dinámicas, podría utilizar una herramienta como RSelenium para automatizar la navegación del navegador web.
Un raspador web preconstruido puede ser la elección correcta cuando se desea acceder a datos web con recursos limitados, garantizar la calidad de los datos o desbloquear casos de uso más avanzados.
Web Scraper de Bright Data proporciona plantillas para muchos sitios web impulsados por funcionalidades de vanguardia, incluida una implementación mucho más avanzada del Amazon Scraper que se demostró.





