

La guía definitiva para el Scraping web con Rust
En esta guía aprenderás:
- Si Rust es un buen lenguaje para el Scraping web.
- Cuáles son las mejores bibliotecas de Rust para el Scraping web.
- Cómo crear un Scraper web en Rust
- Cómo mantener tu operación de scraping ética y respetuosa.
¡Empecemos!
¿Es Rust un buen lenguaje para el Scraping web?
Rust es un lenguaje de programación de tipado estático conocido por su enfoque en la seguridad, el rendimiento y la concurrencia. En los últimos años, ha ganado popularidad por su alta eficiencia. Eso lo convierte en una excelente opción para una variedad de aplicaciones, incluido el Scraping web.
Rust ofrece valiosas funciones para las tareas de scraping web. En particular, su robusto modelo de concurrencia facilita la ejecución simultánea de múltiples solicitudes web. Esta característica lo posiciona como un lenguaje versátil, apto para extraer de manera eficiente cantidades sustanciales de datos de diversos sitios web.
Además, el ecosistema de Rust incluye bibliotecas de parseo de HTML y clientes HTTP para optimizar los procesos de recuperación de páginas web y extracción de datos. Veamos algunas de las más importantes.
Las mejores bibliotecas de Scraping web de Rust
Las bibliotecas de Scraping web de Rust más populares y ampliamente adoptadas incluyen:
- reqwest: un potente cliente HTTP para Rust que permite solicitudes e interacciones web fluidas.
- Scraper: una biblioteca flexible de parseo HTML en Rust, que facilita la extracción eficiente de datos de documentos HTML.
- rust-headless-chrome: ofrece automatización del navegador Chrome sin interfaz gráfica utilizando Rust, lo que proporciona una solución robusta para el Scraping web dinámico.
- thirtyfour: enlaces Rust para Selenium, que permiten realizar pruebas automatizadas y Scraping web mediante la interacción con navegadores web.
Requisitos previos
Siga las instrucciones que se indican a continuación y prepárese para escribir código Rust.
Configurar el entorno
Antes de empezar, debe tener Rust instalado en su ordenador. Para comprobar si ya lo tiene, abra el terminal y escriba el siguiente comando:
rustc --versionSi el resultado es similar al siguiente, ya estás listo para empezar:
rustc 1.75.0 (82e1608df 2023-12-21)Actualice Rust a la última versión con:
rustup updateSi ese comando devuelve un error, debes instalar Rust. Descarga el instalador desde el sitio web oficial, ejecútalo y sigue las instrucciones del asistente. Esto configurará:
- rustup: Un instalador y gestor de versiones para el lenguaje de programación Rust, que permite instalar y gestionar fácilmente diferentes cadenas de herramientas.
- cargo: El gestor de paquetes y la herramienta de compilación oficiales para Rust. Agiliza el proceso de gestión de dependencias y compilación de proyectos Rust.
Cierre todas las ventanas de terminal abiertas y repita el comando del principio de esta sección. Esta vez obtendrá el resultado deseado.
¡Genial! ¡Ya tienes Rust instalado!
Crear un proyecto Rust
Supongamos que quieres crear un nuevo proyecto Rust llamado simple_rust_web_scraper. Abre el terminal y ejecuta el siguiente comando cargo new:
cargo new simple_rust_web_scraperSi todo sale según lo previsto, recibirás el siguiente mensaje:
Se ha creado el paquete binario (aplicación) `simple_rust_web_scraper`En concreto, ese comando creará una carpeta simple_rust_web_scraper. Ábrala y observe que incluye:
- Cargo.toml: el archivo de manifiesto para especificar las dependencias del proyecto.
- src/: la carpeta donde colocar sus archivos Rust. De forma predeterminada, inicializa un archivo main.rs de muestra para usted.
Abre simple_rust_web_scraper en tu IDE de Rust. Por ejemplo, Visual Studio Code con la extensión Rust será perfecto:
Navega dentro de la carpeta src/, abre el archivo main.rs y verás estas líneas:
fn main() {
println!("Hello, world!");
}No es más que un sencillo script Rust que imprime «¡Hola, mundo!» en la terminal. En concreto, la función main() representa el punto de entrada de cualquier aplicación Rust y es donde escribirás la lógica de scraping.
¡Increíble! ¡Solo queda verificar que tu nuevo proyecto Rust funciona!
Abre la terminal de tu IDE y ejecuta este comando para compilar tu aplicación Rust:
cargo buildAparecerá una carpeta target/ que almacena algunos archivos binarios en la carpeta raíz de tu proyecto.
Ejecuta el ejecutable binario compilado asociado a tu código con:
cargo runEsto debería mostrar lo siguiente en la terminal:
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `targetdebugsimple_rust_web_scraper.exe`
¡Hola, mundo!Las dos primeras líneas son solo información de registro, por lo que puede ignorarlas. Concéntrese en la última línea y compruebe que el proyecto ha generado el mensaje «¡Hola, mundo!» como se esperaba.
¡Perfecto! Ahora tienes un proyecto Rust. ¡Es hora de escribir algo de lógica de Scraping web en Rust!
Cómo crear un Scraper en Rust
En esta sección del tutorial paso a paso, aprenderás a realizar Scraping web con Rust. En concreto, crearás un Scraper en Rust que recopila automáticamente datos del sandbox Scrape This Site Country. Así es como se ve la página de destino:
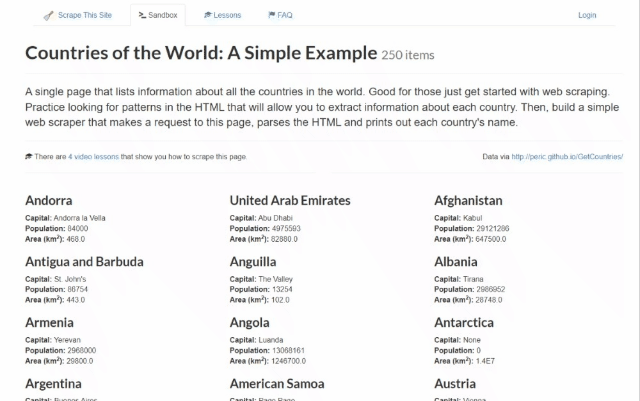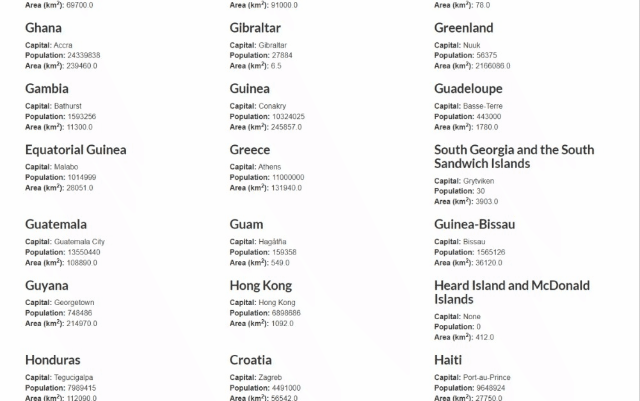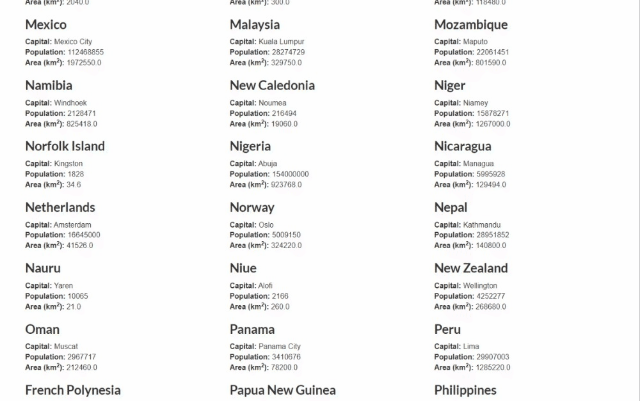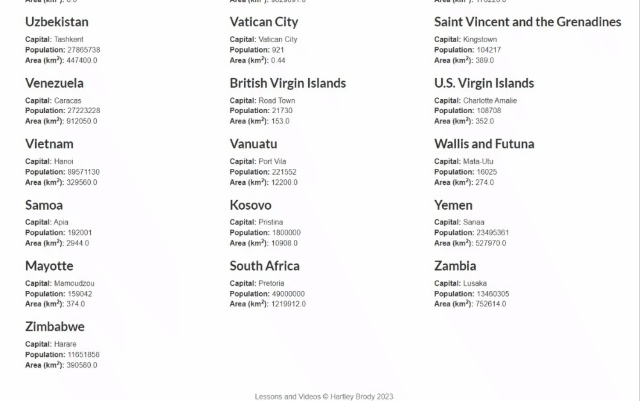
Como puedes ver, contiene una lista de todos los países del mundo y alguna información interesante sobre ellos.
Lo que hará el script de Scraping web en Rust es:
- Conectarse a la página de destino y realizar el parseo de su HTML.
- Seleccionar los elementos HTML de los países de la página.
- Extraer datos de ellos y almacenarlos en una estructura de datos Rust.
- Transformar los datos recopilados en un formato legible para los humanos, como CSV.
Sigue los pasos que se indican a continuación y alcanza tu objetivo de scraping.
Paso n.º 1: inspecciona el sitio de destino
Necesitará instalar algunas bibliotecas para realizar el Scraping web en Rust, pero ¿cuáles son las más adecuadas para su caso concreto? Para responder a esta pregunta, debe averiguar si el sitio de destino tiene páginas de contenido estático o dinámico. Para ello, visite el sitio en su navegador.
Navega hasta la página de destino, haz clic con el botón derecho del ratón en una sección en blanco y selecciona la opción «Inspeccionar» para abrir DevTools. Ve a la pestaña «Red» y vuelve a cargar la página. Céntrate en lo que ves en la sección «Fetch/XHR»:
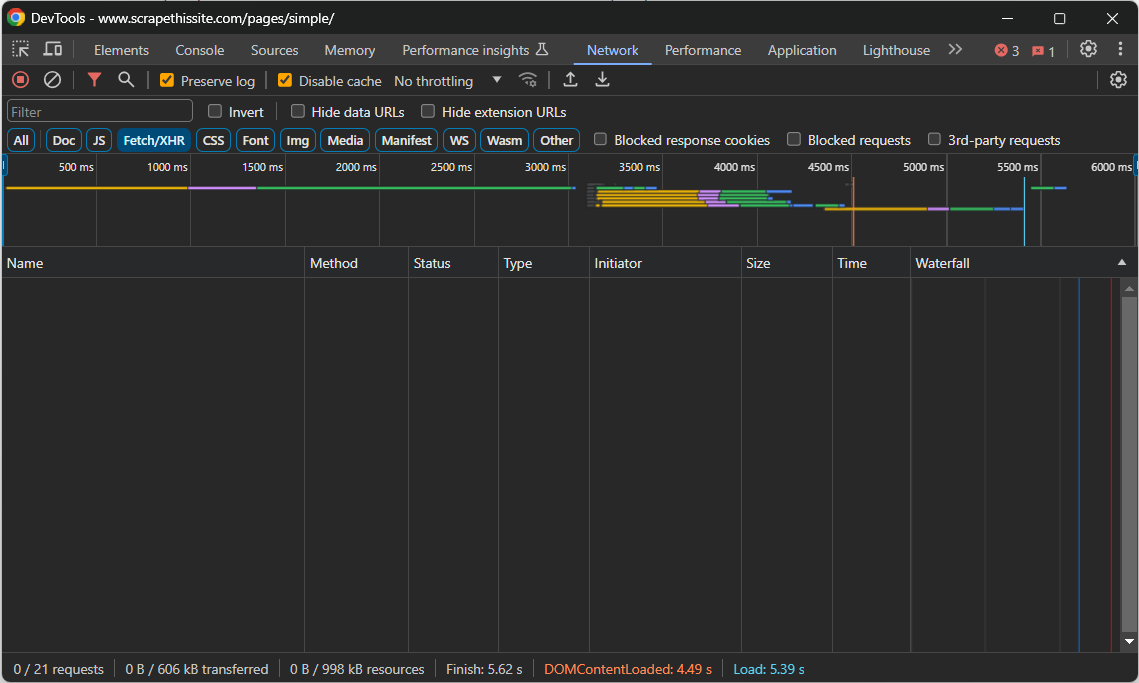
Mientras la página se carga y se renderiza, esa sección permanecerá vacía. Esto significa que la página web no realiza ninguna solicitud AJAX. En otras palabras, no recupera datos dinámicamente en el cliente a través de JavaScript. Por lo tanto, se trata de una página de contenido estático, cuyo documento HTML ya contiene todos los datos de interés.
Como confirmación adicional, haz clic con el botón derecho y selecciona la opción «Ver código fuente de la página»:
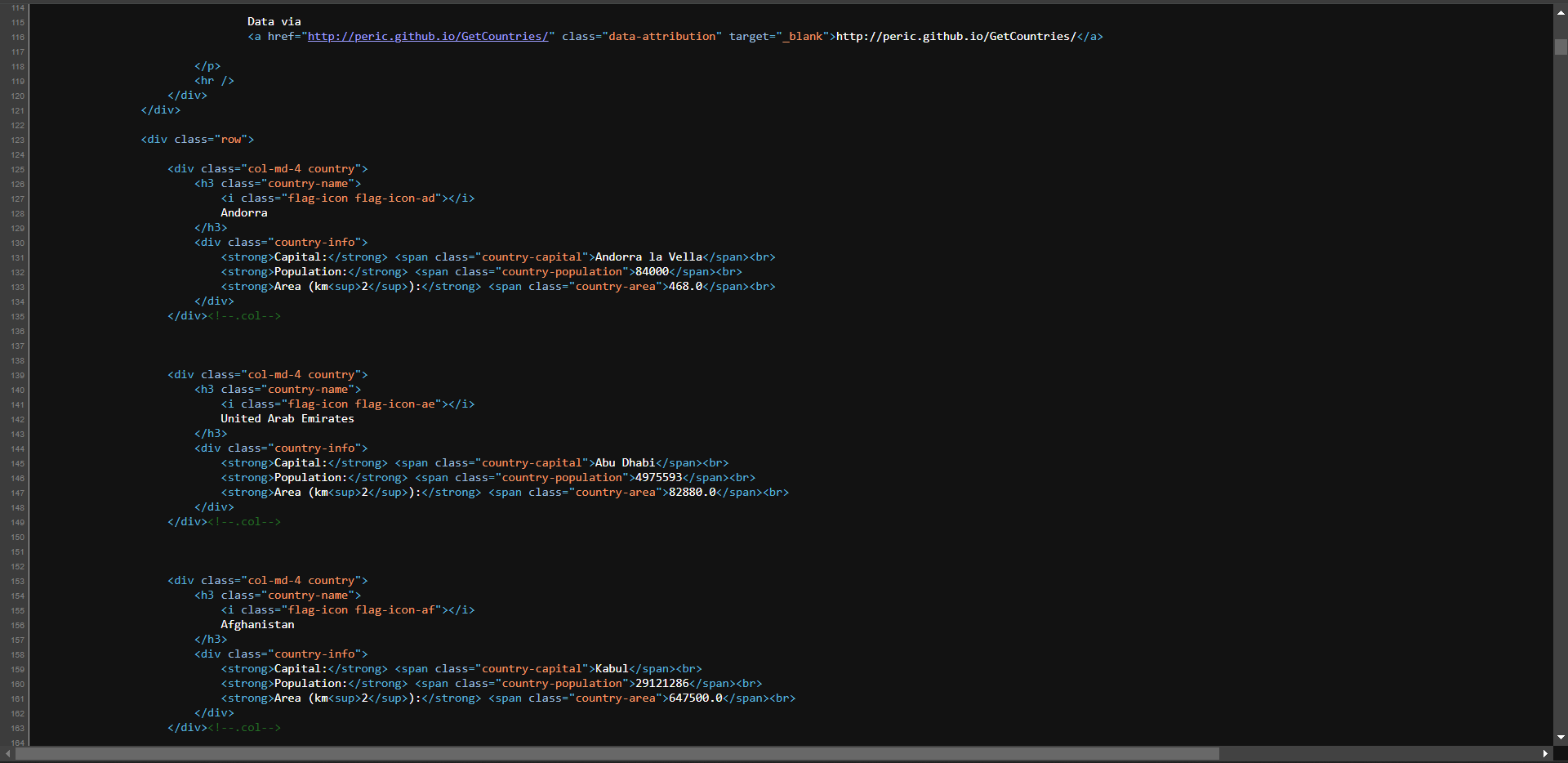
Explora el código y verás que todos los datos de la página están incrustados en el HTML devuelto por el servidor.
En un sitio con varias páginas, repita este procedimiento en todas las páginas de interés.
Dado que las páginas de destino no utilizan JavaScript, no necesitas una biblioteca de automatización del navegador como rust-headless-chrome. Podrías seguir utilizándola, pero ejecutar Chrome requiere tiempo y recursos, por lo que solo supondría una sobrecarga de rendimiento y ningún beneficio real.
En su lugar, debe emplear una biblioteca de clientes HTTP para recuperar el documento HTML asociado a una página y una biblioteca de análisis HTML para extraer datos de ella. Por lo tanto, reqwest y scraper son las dos bibliotecas de Scraping web de Rust que necesita.
Paso n.º 2: Instalar las bibliotecas de scraping
Es hora de instalar reqwest y Scraper.
Abre un terminal en la carpeta raíz de tu proyecto o utiliza el terminal de tu IDE. Ejecuta el siguiente comando para añadir reqwest y Scraper a las dependencias de tu proyecto:
cargo add Scraper reqwest --features "reqwest/blocking"Nota: La función reqwest/blocking permite a reqwest realizar llamadas HTTP sincrónicas que bloquean el hilo actual. Obtén más información en la documentación.
El comando cargo add actualizará el archivo Cargo.toml en consecuencia, asegurándose de que contenga:
[dependencias]
reqwest = { versión = "0.11.23", características = ["bloqueo"] }
Scraper = "0.18.1"
Además, instalará las dos bibliotecas y todas sus dependencias.
¡Perfecto! ¡Ahora tienes todo lo que necesitas para realizar Scraping web con Rust!
Paso n.º 3: Conéctese a la página de destino
Utiliza el método get() de reqwest::blocking para realizar una solicitud GET a la URL dada y descargar el documento HTML asociado:
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;Ten en cuenta que esta instrucción es sincrónica, por lo que la ejecución del script se interrumpirá hasta que el servidor responda.
Una vez que obtenga una respuesta, puede acceder al código HTML de la página de destino con:
let html = response.text()?;Escriba estas dos líneas en la función main() de min.rs.:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conectarse a la página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrae el html sin procesar y lo imprime
let html = response.text()?;
println!("{html}");
Ok(())
}Si te preguntas qué es Result<(), Box<dyn std::error::Error>>, es porque vamos a utilizar Residuals. Echa también un vistazo a la función println() al final, que registra el HTML recuperado.
Ejecuta el script y se imprimirá en la terminal:
<!doctype html>
<HTML lang="en">
<HEAD>
<META charset="utf-8">
<TITLE>Países del mundo: un ejemplo sencillo | Scrape This Site | Un entorno público para aprender a realizar Scraping web</TITLE>
<!-- omitido por brevedad... -->¡Bien hecho! ¡Ese es exactamente el HTML de la página de destino!
Paso n.º 4: Parseo del documento HTML
Ahora tienes el HTML fuente de la página deseada almacenado en una variable de cadena. Introdúcelo en la función parse_document() de Scraper para analizarlo:
let document = Scraper::Html::parse_document(&html);El objeto de documento devuelto expone la API de exploración DOM que necesitas para realizar el Scraping web con Rust.
Así es como debería verse tu archivo main.rs hasta ahora:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conectarse a la página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrae el html sin procesar y lo imprime
let html = response.text()?;
// analiza el documento HTML
let document = Scraper::Html::parse_document(&html);
Ok(())
}Ya estás listo para escribir la lógica de parseo de datos. Pero primero, ¡tienes que estudiar la estructura de la página de destino!
Paso n.º 5: inspeccionar la página
El scraping web implica seleccionar nodos HTML en una página y extraer datos de ellos. Los selectores CSS se encuentran entre los métodos más populares para seleccionar nodos HTML. Si eres desarrollador web, probablemente ya estés familiarizado con ellos. Si no es así, explora la documentación.
La única forma de definir selectores CSS eficaces es inspeccionar el HTML de la página de destino. Por lo tanto, abre el entorno de pruebas Scrape This Site Country en el navegador, haz clic con el botón derecho del ratón en un elemento de país y selecciona «Inspeccionar:».
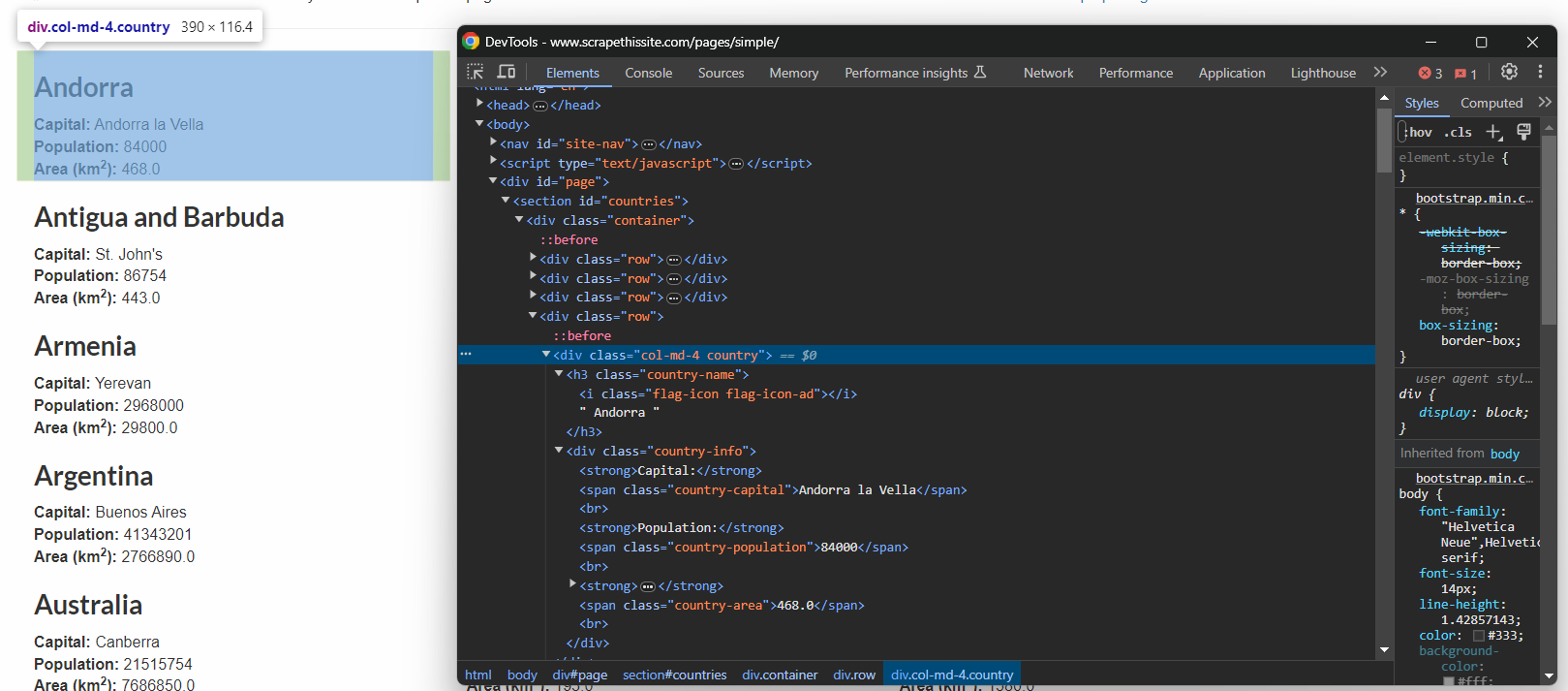
Allí, puedes ver que cada cuadro de información de país es un nodo HTML .country que contiene:
- El nombre del país en un elemento .country-name.
- El nombre de la capital en un elemento .country-capital.
- La información sobre la población en un elemento .country-population.
- El área en km² ocupada por el país en el elemento .country-area.
En el párrafo anterior, se encuentran todos los selectores CSS necesarios para seleccionar los nodos HTML deseados. Pruebe los selectores en un cuadro de información del país antes de aplicarlos a todos los elementos de la página.
Paso n.º 6: recuperar datos de un solo elemento
La función parse() de scraper::Selector acepta una cadena que representa un selector CSS y devuelve un objeto selector. Úsela como se indica a continuación:
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;A continuación, puede pasar el selector al método select() expuesto por document:
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("¡No se ha encontrado el elemento del cuadro de información del país!")?;Esto aplicará el selector CSS en la página y devolverá el elemento HTML seleccionado. Dado que select() siempre devuelve un iterador, es necesario llamar a .next() para obtener el primer nodo del cuadro de información del país.
Ten en cuenta que el objeto devuelto por select() también expone la función select(). En este caso, buscará nodos solo en los hijos del nodo actual. Por lo tanto, puedes implementar toda la lógica de Scraping web de Rust de la siguiente manera:
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capital del país no encontrada")?;
let selector_población_país = Scraper::Selector::parse(".country-population")?;
let población = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;El método text() te permite acceder al texto contenido en el nodo HTML seleccionado. Para otros métodos de extracción de datos, consulta la documentación. Dado que el texto extraído podría contener espacios no deseados, elimínalos con trim().
Imprima los datos extraídos para verificar que la lógica de extracción funciona según lo esperado:
println!("Nombre del país: {name}");
println!("Capital del país: {capital}");
println!("Nombre del país: {population}");
println!("Superficie del país: {area}");
Esto produciría:
Nombre del país: Andorra
Capital del país: Andorra la Vella
Población del país: 84 000
Superficie del país: 468,0¡Sí! ¡Acabas de realizar Scraping web en Rust!
Paso n.º 7: extraer todos los elementos de la página
Esta vez, ampliarás el código anterior para recorrer todos los nodos del cuadro de información del país en la página.
En primer lugar, debes definir una estructura de datos personalizada en la que almacenar los datos recopilados. Para especificar una nueva estructura adaptada a ello, añade las siguientes líneas al principio de tu archivo main.rs:
struct Country {
name: String,
capital: String,
population: String,
area: String,
}En segundo lugar, instancie un Vec de objetos Country en main():
let mut countries: Vec<Country> = Vec::new();Este vector contendrá todos los datos recopilados.
A continuación, elimina la llamada .next() para obtener todos los cuadros de información de los países, itera sobre ellos y rellena los países:
// dónde almacenar los datos extraídos
let mut países: Vec<PAÍS> = Vec::new();
// seleccionar los elementos HTML del cuadro de información del país
let html_cuadro_información_país_selector = Scraper::Selector::parse(".country")?;
let html_cuadro_información_país_elementos = document.select(&html_cuadro_información_país_selector);
// iterar sobre los elementos HTML del país
// y extraerlos todos
for html_country_info_box_element in html_country_info_box_elements {
// lógica de extracción para un único elemento HTML del cuadro de información del país...
// crear un nuevo objeto País y añadirlo al vector
let país = País {
nombre,
capital,
población,
superficie,
};
países.push(país);
}A continuación, puede imprimir todos los países extraídos con:
// registrar los resultados
for country in countries {
println!("Nombre del país: {}", país.nombre);
println!("Capital del país: {}", país.capital);
println!("Nombre del país: {}", país.población);
println!("Superficie del país: {}", país.superficie);
println!();
}
El nuevo archivo main.rs de Rust para el Scraping web contendrá:
// estructura personalizada para almacenar los datos extraídos
struct País {
nombre: String,
capital: String,
población: String,
superficie: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conectarse a la página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extraer el html sin procesar e imprimirlo
let html = response.text()?;
// analizar el documento HTML
let document = scraper::Html::parse_document(&html);
// dónde almacenar los datos extraídos
let mut países: Vec<PAÍS> = Vec::new();
// seleccionar los elementos HTML del cuadro de información del país
let html_cuadro_información_país_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterar sobre los elementos HTML del país
// y extraerlos todos
for html_country_info_box_element in html_country_info_box_elements {
// lógica de extracción para un único elemento HTML del cuadro de información del país
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capital del país no encontrada")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;
// crear un nuevo objeto Country y añadirlo al vector
let país = País {
nombre,
capital,
población,
área,
};
países.push(país);
}
// registra los resultados
para país en países {
println!("Nombre del país: {}", país.nombre);
println!("Capital del país: {}", país.capital);
println!("Nombre del país: {}", país.población);
println!("Superficie del país: {}", país.superficie);
println!();
}
Ok(())
}
Ejecútalo y generará este resultado:
Nombre del país: Andorra
Capital del país: Andorra la Vella
Población del país: 84 000
Superficie del país: 468,0
# omitido por brevedad...
Nombre del país: Zimbabue
Capital del país: Harare
Nombre del país: 11 651 858
Superficie del país: 390 580,0¡Misión cumplida! ¡Acabas de extraer todos los países de la página de destino!
Paso n.º 8: Exportar los datos extraídos a CSV
Los datos recopilados ahora se almacenan en Rust vector, que no es el mejor formato si quieres compartirlos con otras personas. Por eso debes exportarlos a formatos fáciles de explorar, como CSV.
Para exportar datos a un archivo CSV, debes utilizar la biblioteca csv. Instálala con este comando:
cargo add csvA continuación, puedes utilizarla para generar un archivo CSV de exportación con:
// inicializar el archivo CSV de salida
let mut writer = csv::Writer::from_path("countries.csv")?;
// escribir el encabezado CSV
writer.write_record(&["name", "capital", "population", "area"])?;
// rellenar el archivo con cada país
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}Este fragmento de código crea un archivo CSV, lo inicializa con la fila de encabezado y, finalmente, lo rellena iterando sobre el vector de países.
Paso n.º 9: Ponlo todo junto
Aquí está el código completo de tu script Rust para el Scraping web:
// estructura personalizada para almacenar los datos extraídos
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// conectarse a la página de destino
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extraer el html sin procesar e imprimirlo
let html = response.text()?;
// analizar el documento HTML
let document = Scraper::Html::parse_document(&html);
// dónde almacenar los datos extraídos
let mut countries: Vec<COUNTRY> = Vec::new();
// seleccionar los elementos HTML del cuadro de información del país
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterar sobre los elementos HTML del país
// y extraerlos todos
for html_country_info_box_element in html_country_info_box_elements {
// lógica de extracción para un único elemento HTML del cuadro de información del país
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capital del país no encontrada")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Área del país no encontrada")?;
// crear un nuevo objeto País y añadirlo al vector
let país = País {
nombre,
capital,
población,
área,
};
países.push(país);
}
// inicializar el archivo CSV de salida
let mut writer = csv::Writer::from_path("countries.csv")?;
// escribir el encabezado CSV
writer.write_record(&["name", "capital", "population", "area"])?;
// rellenar el archivo con cada país
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}
Ok(())
}¿Puedes creerlo? Puedes crear un Scraper de datos Rust en menos de 100 líneas de código.
Compila la aplicación con el siguiente comando:
cargo buildA continuación, ejecútala con:
cargo runCuando finalice el script, aparecerá un archivo countries.csv en la carpeta raíz de tu proyecto. Ábrelo y deberías ver los siguientes datos:
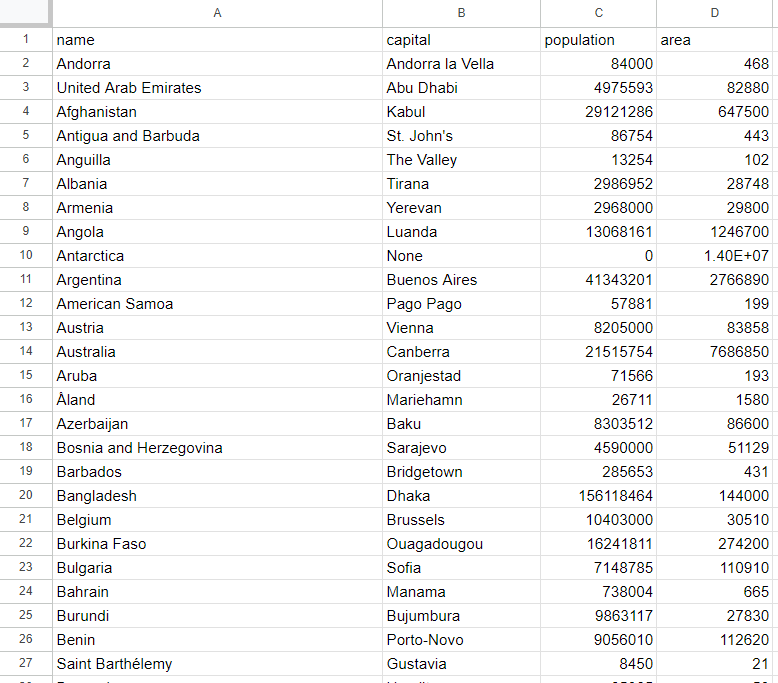
¡Et voilà! ¡Ahora ya conoce los fundamentos del Scraping web con Rust!
Mantén tus operaciones de Scraping web éticas y respetuosas
La recuperación automática de datos de Internet es una forma eficaz de obtener información útil. Sin embargo, no querrás dañar el sitio de destino mientras lo haces. Por lo tanto, debes abordar esa operación con las precauciones adecuadas.
Para realizar un Scraping web responsable, tenga en cuenta estos consejos:
- Cumpla con el archivo robots.txt: cada sitio tiene un archivo robots.txt que especifica las reglas sobre cómo los rastreadores automatizados deben acceder a sus páginas. Para mantener prácticas de scraping éticas, debe cumplir con esas directrices. Obtenga más información en nuestra guía robots.txt para Scraping web.
- Limite la frecuencia de sus solicitudes: realizar demasiadas solicitudes en un breve periodo de tiempo provocará una sobrecarga del servidor, lo que afectará al rendimiento del sitio para todos los usuarios. Esto también podría desencadenar medidas de limitación de velocidad y provocar que se le bloquee. Por lo tanto, añada retrasos aleatorios a sus solicitudes para evitar saturar el servidor de destino.
- Compruebe y respete los términos de servicio del sitio: antes de extraer datos de un sitio web, revise y respete sus términos de servicio. Estos pueden contener información sobre derechos de autor, derechos de propiedad intelectual y directrices sobre cómo y cuándo utilizar sus datos.
- Extraiga solo información disponible públicamente: concéntrese en extraer datos que sean de acceso público en el sitio y que no estén protegidos por credenciales de inicio de sesión u otras formas de autorización. Extraer datos privados o confidenciales sin el permiso adecuado es poco ético y puede acarrear consecuencias legales.
- Confíe en herramientas de extracción fiables y actualizadas: seleccione proveedores de confianza y opte por bibliotecas y herramientas que estén bien mantenidas y se actualicen periódicamente. Solo así podrá asegurarse de que se ajustan a los últimos principios éticos y mejores prácticas en materia de Scraping web. Si tiene alguna duda, lea nuestro artículo sobre cómo elegir el mejor servicio de Scraping web.
Conclusión
En este tutorial, ha visto por qué Rust es una buena opción para el Scraping web y qué bibliotecas debe utilizar para llevarlo a cabo. Aquí ha aprendido a utilizar reqwest y Scraper para crear un rastreador web Rust que puede extraer datos de un sitio web real. ¡Solo se necesitan unas pocas líneas de código!
Sin embargo, ten en cuenta que el Scraping web no siempre es tan fácil. La razón es que las soluciones anti-scraping y anti-bot son cada vez más comunes. Estas tecnologías pueden detectar la naturaleza autónoma de tu script y bloquearlo, lo que supone un serio desafío para tu operación de scraping.
Evita ese dolor de cabeza con la herramienta de Scraping web avanzada y de última generación que ofrece Bright Data. Si quieres saber más sobre cómo evitar ser bloqueado, adopta un Proxy web de uno de los varios servicios de Proxy disponibles o empieza a utilizar el avanzado Web Unlocker.
¿No quiere lidiar con el Scraping web? Explore nuestros Conjuntos de datos.
¿No está seguro de qué producto elegir? Regístrese ahora y encuentre la solución adecuada para su negocio.





