

Desde asistentes de investigación autónomos hasta agentes que gestionan flujos de trabajo completos, los agentes de IA se están convirtiendo rápidamente en algo más que una simple tendencia; están dando forma al futuro del trabajo, el desarrollo y la toma de decisiones. Pero detrás de cada agente capaz hay una pila tecnológica cuidadosamente construida, un sistema de herramientas en capas que permite a estos agentes razonar, actuar y adaptarse.
¿Qué impulsa la próxima generación de automatización?
Para los desarrolladores, es esencial comprender esta pila. No se trata solo de qué herramientas están de moda, sino de cómo funcionan juntas, dónde reside el valor real y qué elementos fundamentales deben estar presentes para que los agentes funcionen de forma fiable.
En Bright Data, trabajamos con equipos de IA de todos los sectores, y una cosa está clara: todos los agentes comienzan con datos. En este artículo, repasaremos las capas fundamentales de la pila tecnológica de los agentes de IA, comenzando por la más importante: la recopilación e integración de datos.
Recopilación e integración de datos
El primer paso para crear agentes más inteligentes
Antes de que un agente de IA pueda razonar, planificar o actuar, necesita comprender el mundo en el que opera. Esa comprensión comienza con datos del mundo real, en tiempo real y, a menudo, no estructurados. Ya sea para entrenar un modelo, impulsar un sistema de generación aumentada por recuperación (RAG) o permitir que un agente responda a los cambios del mercado en tiempo real, los datos son el combustible.
Aquí es donde entra en juego Bright Data.
Proporcionamos la infraestructura que permite a los equipos de IA acceder a la web pública a gran escala, con precisión y de forma conforme. Nuestras herramientas están diseñadas para que la recopilación de datos no solo sea posible, sino también fluida.
El papel de Bright Data en la pila
- API de búsqueda: muestra contenido web relevante en tiempo real, ideal para búsquedas mejoradas con RAG y LLM.
- API Unlocker: elude las protecciones antibots para garantizar un acceso fiable a las fuentes de datos públicas.
- API Web Scraper: extrae datos estructurados de más de 120 000 sitios web, listos para su uso inmediato.
- Scraper personalizado: soluciones a medida para nichos verticales y necesidades específicas de los agentes.
- Mercado de conjuntos de datos: conjuntos de datos recopilados previamente para la creación rápida de prototipos o el ajuste de modelos.
- Anotaciones de IA: servicios con intervención humana para etiquetar y refinar los datos de entrenamiento.
«Si los agentes de IA son el cerebro, Bright Data es los ojos».
Caso de uso: agente de inteligencia de comercio electrónico
Una empresa minorista crea un agente de IA para supervisar los precios y la disponibilidad de productos de la competencia. Mediante la API Web Scraper y la API Unlocker de Bright Data, el agente recopila datos en tiempo real de los sitios web de la competencia y los introduce en un motor de precios que ajusta las ofertas de forma dinámica.
IA Agent Full Techstack
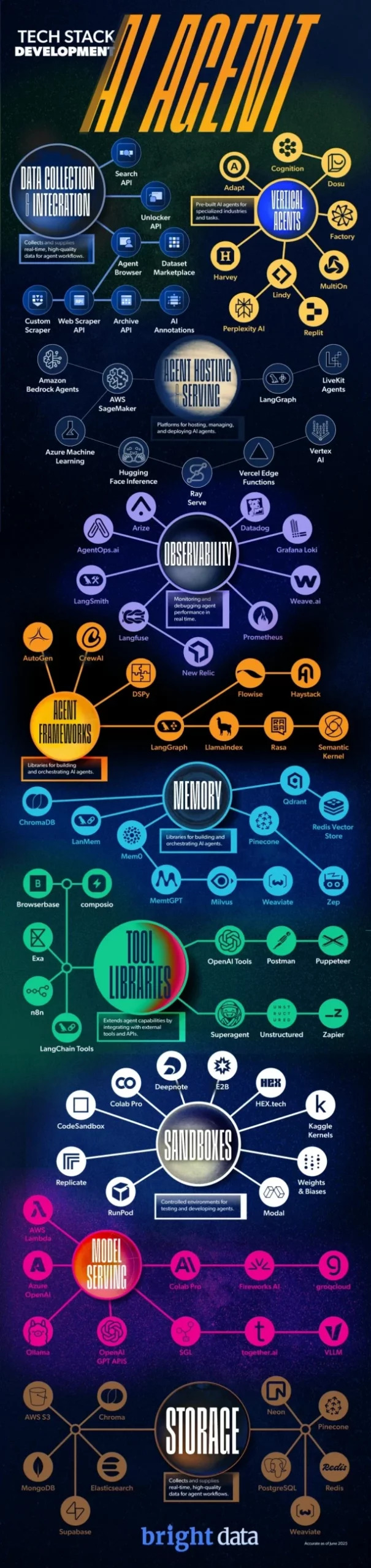
Servicios de alojamiento de agentes
Donde los agentes de IA cobran vida
Una vez que un agente tiene acceso a los datos, necesita un lugar donde operar en un entorno digital en el que pueda razonar, tomar decisiones y actuar. Esa es la función de los servicios de alojamiento de agentes: proporcionan la infraestructura que convierte los modelos estáticos en sistemas dinámicos y autónomos.
Estas plataformas gestionan todo, desde la coordinación hasta la ejecución, y garantizan que los agentes puedan escalar, interactuar con las API y operar de forma continua.
Lo que utilizan los desarrolladores
- LangGraph: un tiempo de ejecución basado en grafos para crear flujos de trabajo de agentes con estado y de varios pasos.
- Hugging Face Inference Endpoints: aloja y sirve modelos y agentes, con herramientas como Transformers Agents para interacciones en tiempo real.
- AWS (Bedrock, Lambda, SageMaker): ofrece una infraestructura flexible y escalable para implementar y gestionar agentes a gran escala.
Las plataformas de alojamiento son los sistemas operativos del mundo de los agentes, pero incluso el agente mejor alojado solo es tan bueno como los datos en los que se basa.
Observabilidad
Hacer que los agentes de IA sean transparentes, trazables y fiables
A medida que los agentes se vuelven más autónomos, la necesidad de comprender lo que hacen y por qué lo hacen se vuelve esencial. Las herramientas de observabilidad ayudan a los desarrolladores a supervisar el rendimiento, rastrear las decisiones y depurar problemas en tiempo real.
Lo que utilizan los desarrolladores
- LangSmith (LangChain): rastrea, depura y evalúa flujos de trabajo impulsados por LLM.
- Weights & Biases: realiza un seguimiento del rendimiento de los modelos, los experimentos y el comportamiento de los agentes a lo largo del tiempo.
- WhyLabs: supervisa la deriva de datos y las anomalías de los modelos en entornos de producción.
La observabilidad convierte a los agentes de cajas negras en cajas de cristal, lo que proporciona a los desarrolladores la visibilidad que necesitan para generar confianza y repetir de forma segura.
Marcos de agentes
Los planos para crear agentes más inteligentes y capaces
Los marcos definen cómo se estructuran los agentes, cómo razonan, interactúan con las herramientas y colaboran con otros agentes. A medida que aumenta la complejidad de los agentes, los marcos evolucionan para dar soporte a sistemas multiagente, descomposición de tareas y planificación dinámica.
Lo que utilizan los desarrolladores
- Crew IA: permite que equipos de agentes colaboren, cada uno con funciones y responsabilidades definidas.
- LangGraph: admite la lógica de ramificación y los flujos de trabajo con estado para el comportamiento complejo de los agentes.
- DSPy: un marco declarativo para optimizar y ajustar los procesos de LLM.
Los marcos proporcionan a los agentes su estructura y lógica, pero dependen de datos precisos y en tiempo real para funcionar de manera eficaz.
Memoria
Cómo los agentes recuerdan, aprenden y se mantienen al tanto del contexto
Los sistemas de memoria permiten a los agentes retener el contexto, recordar interacciones pasadas y desarrollar una comprensión a largo plazo. Normalmente alimentada por bases de datos vectoriales, la memoria es esencial para la personalización, la continuidad y el razonamiento complejo.
Lo que utilizan los desarrolladores
- ChromaDB: ligero e ideal para el desarrollo local.
- Qdrant: búsqueda vectorial escalable y lista para la producción con filtrado híbrido.
- Weaviate: modular y compatible con el aprendizaje automático, se utiliza a menudo en implementaciones de nivel empresarial.
La memoria permite a los agentes aprender y adaptarse, pero solo es tan útil como los datos que almacena, lo que refuerza la necesidad de contar con datos de alta calidad desde el principio.
Bibliotecas de herramientas
Cómo actúan los agentes en el mundo real
Las bibliotecas de herramientas proporcionan a los agentes la capacidad de interactuar con API de sistemas externos, bases de datos, motores de búsqueda y mucho más. Esto es lo que convierte los modelos de lenguaje en agentes capaces de actuar.
Lo que utilizan los desarrolladores
- LangChain: un ecosistema robusto para encadenar LLM con herramientas, memoria y flujos de trabajo.
- OpenAI Functions: permite a los agentes llamar a herramientas externas directamente desde los modelos GPT.
- Exa: permite la búsqueda web en tiempo real, a menudo utilizada en agentes de investigación y sistemas RAG.
Las bibliotecas de herramientas son las que hacen que los agentes sean útiles, pero su eficacia depende de la calidad de los datos con los que interactúan.
Sandboxes
Donde los agentes ejecutan código y prueban ideas de forma segura
Los agentes necesitan cada vez más escribir y ejecutar código, ya sea para el análisis de datos, simulaciones o la toma de decisiones dinámicas. Los entornos aislados proporcionan entornos seguros y aislados para hacer precisamente eso.
Lo que utilizan los desarrolladores
- OpenAI Code Interpreter: ejecuta Python de forma segura dentro de GPT-4 para tareas con gran volumen de datos.
- Replit: un entorno de codificación basado en la nube con integración de IA.
- Modal: infraestructura sin servidor que también funciona como capa de ejecución de código segura.
Los entornos aislados permiten a los agentes razonar sobre los problemas y generar resultados procesables, pero, una vez más, la calidad de esos resultados depende de la calidad de los datos introducidos.
Servicio de modelos
El segundo cerebro: donde se toman las decisiones
Si los datos son el primer cerebro del agente de IA, lo que los agentes saben entonces es la segunda forma en que piensan.
Aquí es donde se alojan y se accede a los LLM, que proporcionan el razonamiento y la generación de lenguaje que impulsa cada decisión del agente. El rendimiento, la latencia y la precisión de esta capa afectan directamente a la eficacia del agente.
Lo que utilizan los desarrolladores
- OpenAI (GPT-4, GPT-4o): estándar del sector para el razonamiento de uso general y las capacidades multimodales.
- Anthropic (Claude): conocido por sus ventanas de contexto largas y su diseño centrado en la alineación.
- Mistral: modelos de peso abierto que ofrecen un alto rendimiento a un coste menor.
- Groq: inferencia de latencia ultrabaja para respuestas de agentes en tiempo real.
- AWS ( SageMaker, Bedrock): infraestructura escalable para servir tanto modelos propietarios como abiertos.
El servicio de modelos es donde la información se convierte en acción, pero incluso los mejores modelos necesitan datos de alta calidad y en tiempo real para razonar de forma eficaz.
Almacenamiento
Donde los agentes guardan su historial, sus conocimientos y su estado
Los sistemas de almacenamiento admiten el registro de interacciones a largo plazo, el almacenamiento de resultados y el mantenimiento del estado entre sesiones. Son esenciales para la reproducibilidad, el cumplimiento normativo y la mejora continua.
Lo que utilizan los desarrolladores
- Amazon S3: la opción ideal para el almacenamiento de objetos escalable.
- Google Cloud Storage (GCS): seguro e integrado con las herramientas de IA de Google.
- Bases de datos vectoriales (por ejemplo, Qdrant, Weaviate): almacenan incrustaciones y contexto semántico para su recuperación.
El almacenamiento garantiza que los agentes puedan aprender del pasado y escalar con el tiempo, pero el valor de lo que se almacena comienza con la calidad de lo que se recopila.
Sus agentes son tan inteligentes como sus datos
Los agentes de IA solo son tan capaces como la información en la que se basan. Pueden razonar, planificar y actuar, pero solo si tienen acceso a los datos adecuados en el momento adecuado. Sin eso, incluso la pila tecnológica más sofisticada se convierte en un bucle cerrado: potente, pero desconectado del mundo real.
Por eso los datos no son solo una parte del conjunto, sino la base. Y en el ecosistema actual de IA, la fuente de datos más valiosa es la web pública.
En Bright Data, hacemos que esos datos sean accesibles.
Nuestras herramientas impulsan el primer y más crítico paso en el flujo de trabajo de los agentes de IA: la recopilación e integración de datos. Conectamos a los agentes a la web pública en tiempo real, proporcionándoles los datos estructurados, fiables y escalables que necesitan para comprender el mundo, tomar decisiones informadas y emprender acciones significativas.
Todas las capas de la pila tecnológica (marcos de agentes, sistemas de memoria, bibliotecas de herramientas, modelos de servicio) dependen de esa base. Porque sin información precisa y actualizada, los agentes no pueden adaptarse, personalizarse ni funcionar.
En cierto sentido, sus agentes tienen dos cerebros:
- Los datos: lo que saben.
- El modelo: cómo piensan.
Antes de que sus agentes puedan actuar, necesitan comprender.
Antes de poder comprender, necesitan ver.
Bright Data es cómo ven el mundo.
Siguiente paso
Descubra cómo Bright Data puede potenciar su pila de agentes de IA: https://brightdata.com/ai/products-for-ai






