
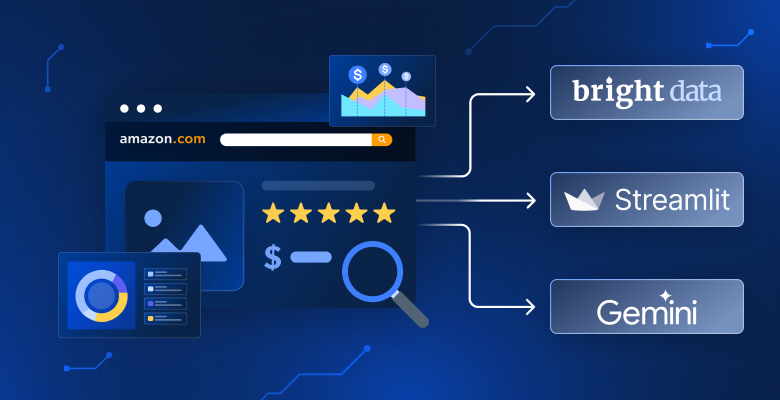
¿Cansado de comparar manualmente productos en Amazon? ¿Quieres hacer preguntas a la IA sobre tus resultados de búsqueda? ¿Necesitas información más detallada que la que te ofrece la clasificación por precio o valoración? En este tutorial, crearás un analizador de productos de Amazon que busca en cualquiera de los 23 mercados de Amazon, analiza los resultados con IA y presenta la información a través de paneles interactivos.
Lo que crearás
Al final de esta guía, tendrás una aplicación web funcional que recopila datos de productos de Amazon y los organiza en un panel fácil de navegar con información basada en IA.
Características principales y flujo de trabajo del usuario
Así es como funciona:
- Búsqueda y recopilación de datos. Seleccione uno de los 23 mercados de Amazon (Estados Unidos, Alemania, Japón, etc.) e introduzca una palabra clave del producto, como «auriculares inalámbricos». La aplicación utiliza la API Web Scraper de Bright Data para recopilar información sobre el producto.
- Visualización de resultados organizados. Los datos se presentan a través de una interfaz limpia basada en pestañas:
- Recomendaciones. Vea los productos clasificados según un algoritmo de puntuación personalizado (que combina la valoración, el número de reseñas y los descuentos) con tres categorías: «Mejor relación calidad-precio», «Mejor valorado» y «Mejores ofertas».
- Análisis de mercado. Explore gráficos interactivos que muestran la distribución de precios y los patrones de valoración para comprender el panorama de los productos.
- Asistente de IA. Haga preguntas en inglés sencillo, como «¿Qué productos tienen las valoraciones más altas por debajo de 100 dólares?». La IA analiza los resultados de búsqueda actuales y proporciona respuestas con citas de productos.
- Resultados de productos. Explore, ordene y exporte el conjunto de datos completo a CSV para su posterior análisis.
Ahora que hemos visto lo que hace la aplicación, veamos las tecnologías que lo hacen posible.
La pila tecnológica y la arquitectura del proyecto
Nuestra aplicación utiliza una pila moderna basada en Python, en la que cada componente se ha elegido por sus puntos fuertes específicos en el manejo de datos, la IA y el desarrollo web.
| Componente | Tecnología | Finalidad |
|---|---|---|
| Fuente de datos | Bright Data API de Amazon Scraper | Recopilación de datos de Amazon fiable y a escala empresarial sin la molestia de gestionar proxies o la resolución de CAPTCHAs. |
| Frontend | Streamlit | Cree rápidamente un panel web interactivo y atractivo utilizando solo Python. |
| Integración de IA | Google Gemini | Información en lenguaje natural, resumen de datos y funcionalidad de asistente de IA. |
| Procesamiento de datos | Pandas | La piedra angular para toda la limpieza, transformación y análisis de datos. |
| Operaciones matemáticas | NumPy | Algoritmos de puntuación de valores y cálculos estadísticos. |
| Visualizaciones | Plotly | Gráficos y diagramas interactivos y completos que los usuarios pueden explorar. |
| HTTP(S) y reintentos | Solicitudes + Tenacidad | Comunicación robusta y resistente con API externas. |
Arquitectura del proyecto
El proyecto está organizado en una estructura modular para garantizar una separación clara de las funciones, lo que facilita el mantenimiento y la ampliación del código.
├── streamlit_app.py # Punto de entrada principal de la aplicación Streamlit
├── requirements.txt # Dependencias del proyecto
├── .env # Claves API y variables de entorno (privadas)
└── amazon_analytics/ # Módulo de lógica de aplicación central
├── __init__.py # Inicialización del paquete
├── api.py # Integración de la API de Bright Data
├── data_processor.py # Limpieza de datos, normalización e ingeniería de características
├── shopping_intelligence.py # Motor de recomendación y puntuación de productos
├── gemini_ai_engine.py # Análisis de IA e ingeniería de prompts con Gemini
├── ai_engine_interface.py # Interfaz abstracta del motor de IA
├── ai_response.py # Objetos de respuesta de IA estandarizados
└── config.py # Gestión de la configuraciónUna vez aclarada la arquitectura, preparemos el entorno de desarrollo.
Requisitos previos
Antes de empezar a programar, asegúrate de tener lo siguiente preparado:
- Python 3.8+. Si no lo tiene instalado, descárguelo desde el sitio web oficial de Python.
- Una cuenta de Bright Data. Necesitarás una clave API para acceder a la API de Amazon Scraper. Regístrate para obtener una prueba gratuita y generar tu clave API.
- Una clave API de Google. Es necesaria para utilizar el modelo Gemini IA. Puedes generar una desde Google AI Studio.
- Conocimientos básicos. Te será útil estar familiarizado con Python, Pandas y el concepto de API web.
Una vez que tengas todo esto, podemos continuar con la configuración del proyecto.
Paso 1: configuración del entorno de desarrollo
En primer lugar, clonemos el repositorio del proyecto, creemos un entorno virtual para aislar nuestras dependencias e instalemos los paquetes necesarios.
Instalación
Abre tu terminal y ejecuta los siguientes comandos:
# Clonar el repositorio
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# Crear y activar un entorno virtual
python -m venv venv
source venv/bin/activate # En Windows, utilice: venvScriptsactivate
# Instalar las bibliotecas necesarias
pip install -r requirements.txtConfiguración de la clave API
A continuación, cree un archivo .env en el directorio raíz del proyecto para almacenar de forma segura sus claves API.
# Crear el archivo .env
touch .envAhora, abra el archivo .env en un editor de texto y añada sus claves:
BRIGHT_DATA_TOKEN=tu_token_de_bright_data_aquí
GOOGLE_API_KEY=tu_clave_de_google_api_aquíSu entorno ya está completamente configurado. Profundicemos en la lógica central, comenzando por la recopilación de datos.
Paso 2: recopilar datos de productos de Amazon con Bright Data
La base de nuestra aplicación son los datos de alta calidad. Extraer manualmente datos de un sitio como Amazon es complejo: hay que gestionar Proxies, manejar diferentes diseños de página y encontrar formas de eludir los CAPTCHA y los mecanismos de bloqueo de Amazon.
La API Amazon Web Scraper de Bright Data elimina toda esta complejidad. Ofrece:
- Fiabilidad de nivel empresarial. Se basa en una red de más de 150 millones de Proxies residenciales de origen ético en 195 países, lo que garantiza un acceso constante e ininterrumpido.
- Sin complicaciones de infraestructura. La rotación automática de IP, la Resolución de CAPTCHA y la gestión de Proxy se gestionan por ti entre bastidores.
- Datos estructurados completos. Proporciona datos JSON limpios y estructurados con más de 20 puntos de datos por producto, incluyendo ASIN, precios, valoraciones, reseñas, información del vendedor, descripciones del producto, imágenes, disponibilidad y mucho más.
- Precios rentables. Modelo de pago por uso a partir de 0,001 $ por registro, lo que lo hace escalable para proyectos de cualquier tamaño.
Integración de API (api.py)
Nuestra clase BrightDataAPI en api.py gestiona todas las interacciones con la API. Utiliza un flujo de trabajo de activación-sondeo-descarga, ideal para gestionar trabajos de scraping que pueden ser de larga duración.
El método trigger_search inicia el trabajo de scraping. Observe el uso del decorador @retry de la biblioteca tenacity, que añade resiliencia al reintentar automáticamente la solicitud con un retroceso exponencial si falla.
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/conjuntos_de_datos/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""Activa una nueva tarea de scraping y devuelve el ID de la instantánea."""
payload = [{
"keyword": keyword,
"url": amazon_url,
"pages_to_search": pages_to_search
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]Después de iniciar una búsqueda, el método wait_for_results sondea la API hasta que se completa el trabajo y, a continuación, descarga los datos. Esto evita que la aplicación se cuelgue mientras espera e incluye un tiempo de espera para evitar bucles infinitos.
Una vez que se dispone de una recopilación de datos fiable, el siguiente paso es limpiar y enriquecer estos datos sin procesar.
Paso 3: creación del canal de procesamiento de datos
Los datos sin procesar de cualquier fuente rara vez tienen el formato perfecto para su análisis. Nuestra clase DataProcessor en data_processor.py se encarga de limpiar, normalizar y diseñar nuevas características a partir de los datos extraídos de Amazon, dejándolos listos para nuestras capas de IA y visualización. Para obtener una visión más amplia del procesamiento de datos, consulte nuestra guía sobre análisis de datos con Python.
Análisis inteligente de precios
Un reto importante en los datos de comercio electrónico es el manejo de formatos internacionales. Por ejemplo, un precio en Alemania puede ser «1,234,56», mientras que en Estados Unidos es «1,234.56». La función parse_float_locale maneja de forma inteligente estas variaciones.
# amazon_analytics/data_processor.py (simplificado para facilitar la lectura)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""Analizador flotante robusto que maneja formatos numéricos internacionales."""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# Determinar el separador decimal por la última posición
si s.rfind(',') > s.rfind('.'):
s = s.replace('.', '').replace(',', '.') # Formato europeo
else:
s = s.replace(',', '') # Formato estadounidense
elif has_comma:
# Comprueba si la coma es un separador de miles o un separador decimal
if re.search(r",d{3}$", s):
s = s.replace(',', '') # Separador de miles
else:
s = s.replace(',', '.') # Separador decimal
return float(s)
return NoneAlgoritmo de puntuación de valor personalizado
Para ayudar a los usuarios a identificar rápidamente los mejores productos, hemos creado una puntuación de valor personalizada. Esta métrica compuesta combina múltiples factores en una única puntuación fácil de entender.
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10)
-> float:
"""Calcula una puntuación compuesta basada en la calidad, la prueba social y el valor de la oferta."""
score = 0.0
# 40 % de peso para la calidad del producto (calificación)
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# 30 % de peso para la prueba social (número de valoraciones)
if num_ratings and num_ratings >= min_reviews:
# Escala logarítmica para evitar que los artículos muy populares dominen
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# 30 % de peso para el valor de la oferta (porcentaje de descuento)
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # Límite máximo del 50 % de descuento
score += discount_score * 0.3
return round(score, 2)Este algoritmo equilibra la calidad (calificación), la prueba social (volumen de reseñas) y el valor de la oferta (descuento) para proporcionar una medida holística del atractivo de un producto.
Ahora que nuestros datos están limpios y enriquecidos, podemos introducirlos en nuestro motor de IA para obtener información más detallada.
Paso 4: integración de la IA para un análisis inteligente con Gemini
Aquí es donde nuestra aplicación se vuelve verdaderamente inteligente. Utilizamos la IA Gemini de Google para analizar los datos procesados y responder a las preguntas de los usuarios. Uno de los principales retos de los LLM es la alucinación, es decir, inventar hechos que no están presentes en los datos de origen. Nuestro GeminiAIEngine está diseñado para evitarlo.
# amazon_analytics/gemini_ai_engine.py (simplificado significativamente para mayor claridad del tutorial)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""Crea un mensaje a prueba de alucinaciones incluyendo todo el contexto de los datos."""
# Nota: La implementación real incluye una asignación detallada de campos,
# conversión de tipos y manejo de NaN para más de 20 atributos de productos.
products_data = []
for _, row in df.iterrows():
product = {
'name': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'final_price': float(row.get('final_price', 0)) if pd.notna(row.get('final_price')) else 0,
'rating': float(row.get('rating', 0)) if pd.notna(row.get('rating')) else 0,
'num_ratings': int(row.get('num_ratings', 0)) if pd.notna(row.get('num_ratings')) else 0,
# ... campos adicionales con el manejo adecuado de tipos
}
products_data.append(product)
return f"""Eres un experto analista de productos de Amazon con capacidades avanzadas de razonamiento.
REGLAS DE CERO ALUCINACIONES:
1. NUNCA inventes ni te inventes NINGUNA información sobre los productos.
2. Utiliza ÚNICAMENTE los datos que se proporcionan explícitamente a continuación.
3. Si falta información, indica claramente «Esta información no está disponible».
4. Cita siempre los ASIN específicos de los productos para su verificación.
5. Utiliza tu razonamiento para proporcionar información valiosa basada en los datos reales.
CAPACIDADES DE RAZONAMIENTO:
- Compara productos analizando el precio, las valoraciones, las reseñas y las características.
- Identifica los productos con la mejor relación calidad-precio teniendo en cuenta la relación entre el precio y la valoración.
- Evalúa la confianza en el producto evaluando la calidad de la valoración y el volumen de reseñas.
- Detecta ofertas comparando el precio inicial con el precio final.
CONSULTA DEL USUARIO: {user_query}
DATOS DE PRODUCTOS DISPONIBLES ({len(df)} productos):
{json.dumps(products_data, indent=2)}
Utilice su razonamiento para analizar estos datos y proporcionar información útil y precisa. Incluya ASIN y números específicos para su verificación.Técnicas clave contra las alucinaciones:
- Inclusión completa de datos. Toda la información del producto se proporciona a la IA, sin dejar lugar a especulaciones.
- Límites explícitos. Reglas claras sobre lo que la IA puede y no puede hacer.
- Citas ASIN. Obliga a la IA a hacer referencia a productos específicos para su verificación.
- Formato de datos estructurado. El formato JSON hace que el parseo de datos sea fiable para la IA.
Este enfoque de ingeniería de prompts transforma la IA en un analista de datos fiable, lo que hace que sus resultados sean confiables y verificables.
Con el motor de IA listo, podemos construir el sistema de recomendaciones.
Paso 5: creación del motor de inteligencia de compras
El ShoppingIntelligenceEngine en shopping_intelligence.py utiliza los datos procesados para generar tres recomendaciones principales: «Mejor valor general», «Mejor valorado» y «Mejor oferta». El motor aplica sofisticados criterios de filtrado para garantizar recomendaciones de calidad.
El sistema funciona con una lista de diccionarios de productos y utiliza métodos auxiliares independientes para cada categoría de recomendación, cada uno con umbrales de calidad específicos.
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Generar inteligencia de compras a partir de los datos de los productos."""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Generar recomendaciones de productos más vendidos con razonamiento."""
try:
# Primero, filtrar solo los productos válidos.
valid_products = []
for product in products:
rating = product.get('rating')
price = product.get('final_price')
if rating is not None and price is not None and rating > 0 and price > 0:
valid_products.append(product)
if not valid_products:
return []
picks = []
used_asins = set()
# Buscar cada categoría utilizando métodos especializados.
best_value = self._find_best_value(valid_products)
si mejor_valor y mejor_valor.get('asin') no están en asins_utilizados:
selecciones.append({
'producto': mejor_valor,
'razón': 'Mejor valor general',
'explicación': 'Excelente equilibrio entre calidad, precio y opiniones de los clientes'
})
asins_utilizados.add(mejor_valor['asin'])
highest_rated = self._find_highest_rated(valid_products)
if highest_rated and highest_rated.get('asin') not in used_asins:
picks.append({
'product': highest_rated,
'reason': 'Highest Rated',
'explanation': 'Top customer satisfaction with proven track record'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': 'Mejor oferta',
'explanation': 'Excelente relación calidad-precio con un ahorro significativo y buena calidad'
})
used_asins.add(best_deal['asin'])
# Rellenar las plazas restantes con productos de calidad si es necesario.
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
for product in remaining_products[:3-len(picks)]:
picks.append({
'product': product,
'reason': 'Quality Choice',
'explanation': 'Good balance of quality and value'
})
return picks[:3]
except Exception:
return []Métodos de filtrado por calidad
Cada categoría de recomendación tiene umbrales de calidad específicos para garantizar recomendaciones fiables:
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Busca el producto con la mejor puntuación de valor; requiere más de 10 reseñas."""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Busca el producto mejor valorado: requiere una valoración superior a 4,0 y más de 50 reseñas."""
candidates = [p for p in products if
p.get('rating', 0) >= 4.0 and
p.get('num_ratings', 0) >= 50]
if not candidates:
return None
return max(candidates, key=lambda p: (p.get('rating', 0), p.get('num_ratings', 0)))
def _find_best_deal(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Encuentra el mejor descuento: requiere un descuento del 10 % o más y una valoración de 3,5 o más."""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))Decisiones clave de diseño:
- Umbrales de calidad. Cada categoría tiene unos estándares mínimos para evitar recomendar productos de mala calidad.
- Sin duplicados. El conjunto
used_asinsgarantiza que cada producto aparezca solo una vez. - Lógica de reserva. Si se encuentran menos de 3 recomendaciones, se rellena con las puntuaciones de los siguientes mejores valores.
- Gestión de errores. Try/catch evita fallos en datos mal formados.
Este enfoque garantiza que los usuarios obtengan recomendaciones fiables y de alta calidad, en lugar de simplemente los primeros productos encontrados.
Ahora tenemos todos los componentes del backend. Creemos la interfaz de usuario para unir todo.
Paso 6: diseño del panel interactivo con Streamlit
La pieza final es la interfaz de usuario, gestionada por streamlit_app.py. Streamlit permite crear un panel reactivo basado en web con un código mínimo. La aplicación utiliza un sofisticado diseño basado en pestañas con seguimiento del progreso en tiempo real y múltiples tipos de gráficos.
Estado de la sesión y almacenamiento en caché de componentes
La aplicación utiliza variables de estado de sesión específicas para gestionar el flujo de datos y almacena en caché los componentes del backend para mejorar el rendimiento:
# streamlit_app.py - Inicialización del estado de la sesión
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""Inicializar y almacenar en caché los componentes del backend."""
api = BrightDataAPI()
processor = DataProcessor()
intelligence = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processor, intelligence, ai_engineProcesamiento de búsqueda en línea con seguimiento del progreso
La lógica de búsqueda está integrada directamente en el flujo principal de la aplicación con seguimiento detallado del progreso y persistencia de datos:
# streamlit_app.py - Procesamiento de búsqueda (simplificado)
# Ejecución de búsqueda con seguimiento del progreso
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# Activar búsqueda
status_text.text("Iniciando búsqueda en Amazon...")
snapshot_id = API.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# Esperar los resultados con actualizaciones de progreso inteligentes
status_text.text("Amazon está procesando tu búsqueda...")
results = smart_wait_for_results(API, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# Procesar resultados
status_text.text("Analizando productos...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# Almacenar resultados completos en el estado de la sesión
st.session_state.search_results = processed_results
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = results
st.session_state.search_metadata = {
'keyword': keyword,
'country': countries[selected_country],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"¡Se han encontrado {len(processed_results)} productos en {elapsed_time:.1f}s!")
progress_bar.progress(100)
except Exception as e:
st.error(f"Error en la búsqueda: {str(e)}")Varias visualizaciones interactivas
La pestaña Análisis de mercado crea varios tipos de gráficos en línea, cada uno con un estilo y anotaciones específicos:
# streamlit_app.py - Distribución de precios con línea mediana
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="Rango de precios",
labels={'x': f'Precio ({currencies.get(current_country_code, "USD")})', 'y': 'Número de productos'},
color_discrete_sequence=['#667eea']
)
# Añadir línea mediana para contextualizar
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="Mediana")
st.plotly_chart(fig_price, use_container_width=True)
# Dispersión de valoración frente a precio con codificación de tamaño y color
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="Calidad frente a precio",
labels={'final_price': f'Precio ({currencies.get(current_country_code, "USD")})', 'rating': 'Calificación (Estrellas)'},
color='rating',
color_continuous_scale='Viridis')
st.plotly_chart(fig_scatter, use_container_width=True)
# Distribución de la puntuación de valor con marcadores de percentiles
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="Productos con mejor relación calidad-precio",
labels={'x': 'Puntuación de valor (0,0-1,0)', 'y': 'Número de productos'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="Mediana")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75.º percentil")
st.plotly_chart(fig_value, use_container_width=True)Funciones avanzadas de gráficos
El panel de control incluye visualizaciones sofisticadas con inteligencia empresarial:
- Histogramas de precios. Con marcadores de mediana y cuartiles para el posicionamiento en el mercado.
- Gráficos de dispersión de valoraciones. El tamaño representa el volumen de reseñas, el color muestra la calidad de la valoración.
- Gráficos circulares de posición. Muestran la distribución del ranking de búsqueda (1-5, 6-10, 11-20, 21+).
- Gráficos de barras de categorías de precios. Segmenta los productos en niveles de presupuesto/valor/premium/lujo.
- Análisis de descuentos. Identifica las ofertas genuinas frente a los precios inflados.
Este enfoque integral crea un panel de análisis profesional que proporciona información útil sobre el mercado.
Conclusión
Ha creado con éxito un analizador de productos de Amazon que aprovecha la recopilación de datos de nivel empresarial, la IA avanzada y la visualización interactiva de datos. El código fuente completo de este proyecto está disponible para que lo explore y adapte en GitHub.
Ha visto cómo:
- Utilizar la API Web Scraper de Bright Data para extraer datos de Amazon de forma fiable y a gran escala.
- Implementar un sólido proceso de procesamiento de datos para manejar retos complejos con datos del mundo real.
- Diseñar un asistente de IA a prueba de alucinaciones con Google Gemini para obtener análisis fiables.
- Crear una interfaz de usuario intuitiva e interactiva con Streamlit y Plotly.
Este proyecto sirve como una potente plantilla para cualquier aplicación que requiera convertir grandes cantidades de datos web en inteligencia empresarial útil. A partir de aquí, podrías ampliarlo para crear un rastreador de precios de Amazon dedicado o integrar otras fuentes de datos.
El mundo de los datos del comercio electrónico es vasto. Si necesita conjuntos de datos prerecopilados y listos para usar, explore el mercado de Bright Data para encontrar una amplia gama de opciones.





