
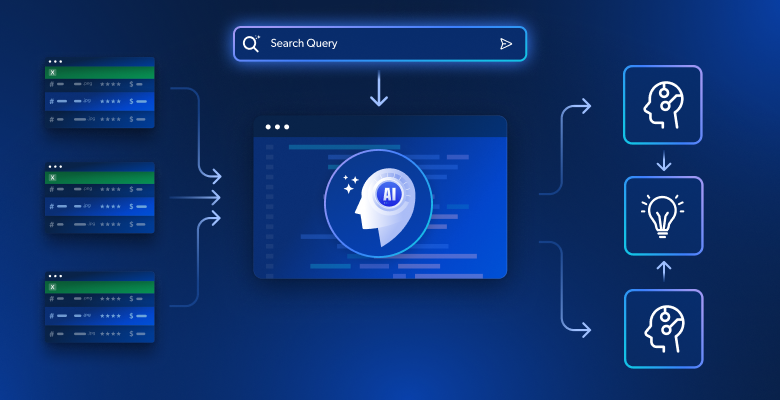
En esta guía aprenderás:
- Qué es la Generación Agenética de Recuperación-Aumentada (RAG) y por qué es importante añadir capacidades agenticas
- Cómo Bright Data permite la recuperación autónoma y en directo de datos web para sistemas RAG
- Cómo procesar y limpiar los datos de web-scraping para la generación de incrustaciones
- Implementación de un controlador de agentes para orquestar entre la búsqueda vectorial y la generación de texto LLM.
- Diseñar un bucle de retroalimentación para captar las aportaciones del usuario y optimizar la recuperación y la generación de forma dinámica.
Sumerjámonos.
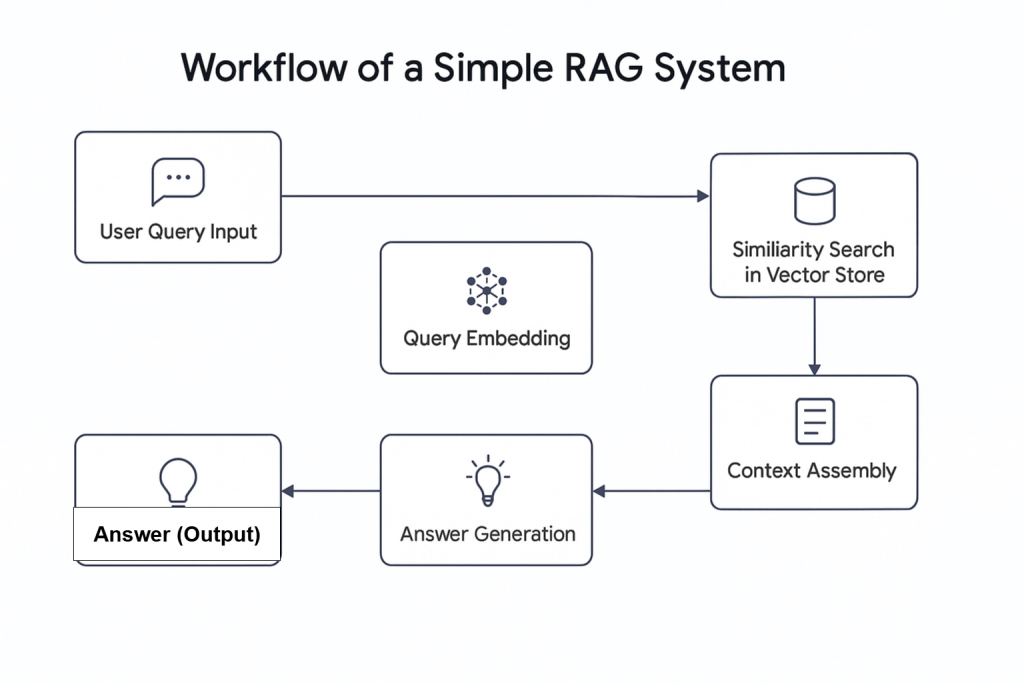
El auge de la Inteligencia Artificial (IA) ha introducido nuevos conceptos, entre ellos la RAG Agenética. En términos sencillos, la RAG Agenética es la Generación Aumentada de Recuperación (RAG) que integra agentes de IA. Como su nombre indica, la RAG es un sistema de recuperación de información que sigue un proceso lineal: recibe una consulta, recupera la información pertinente y genera una respuesta.
¿Por qué combinar agentes de IA con GAR?
Una encuesta reciente muestra que casi dos tercios de los flujos de trabajo que utilizan agentes de IA informan de un aumento de la productividad. Además, cerca del 60 por ciento afirma haber ahorrado costes. Esto hace que la combinación de agentes de IA con RAG pueda cambiar las reglas del juego de los flujos de trabajo de recuperación modernos.
Agentic RAG ofrece capacidades avanzadas. A diferencia de los sistemas RAG tradicionales, no sólo puede recuperar datos, sino que también puede decidir obtener información de fuentes externas, como datos web en directo incrustados en una base de datos.
Este artículo demuestra cómo construir un sistema RAG Agentic que recupera información de noticias utilizando Bright Data para la recopilación de datos web, Pinecone como base de datos vectorial, OpenAI para la generación de texto y Agno como controlador del agente.
Visión general de Bright Data
Tanto si se abastece de un flujo de datos en directo como si utiliza datos preparados de su base de datos, la calidad de los resultados de su sistema Agentic RAG depende de la calidad de los datos que recibe. Aquí es donde Bright Data resulta esencial.
Bright Data proporciona datos web fiables, estructurados y actualizados para una amplia gama de casos de uso. Con la API Web Scraper de Bright Data, que tiene acceso a más de 120 dominios, el raspado web es más eficiente que nunca. Gestiona los retos comunes del scraping, como las prohibiciones de IP, CAPTCHA, cookies y otras formas de detección de bots.
Para empezar, regístrate en la versión de prueba gratuita y, a continuación, obtén la clave de API y el identificador de conjunto de datos del dominio que deseas rastrear. Una vez que los tengas, podrás empezar.
A continuación se indican los pasos para recuperar datos recientes de un dominio popular como BBC News:
- Cree una cuenta de Bright Data si aún no lo ha hecho. Dispone de una versión de prueba gratuita.
- Vaya a la página Web Scrapers. En Biblioteca de raspadores web, explore las plantillas de raspadores disponibles.
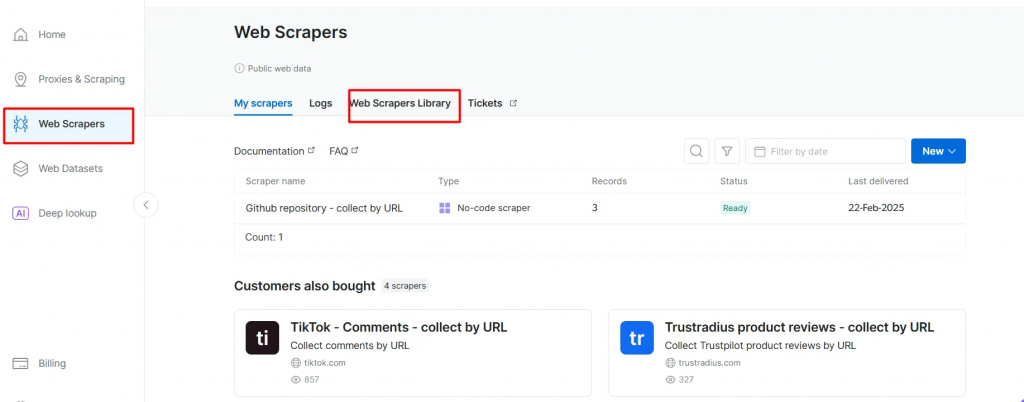
- Busque su dominio de destino, como BBC News, y selecciónelo.
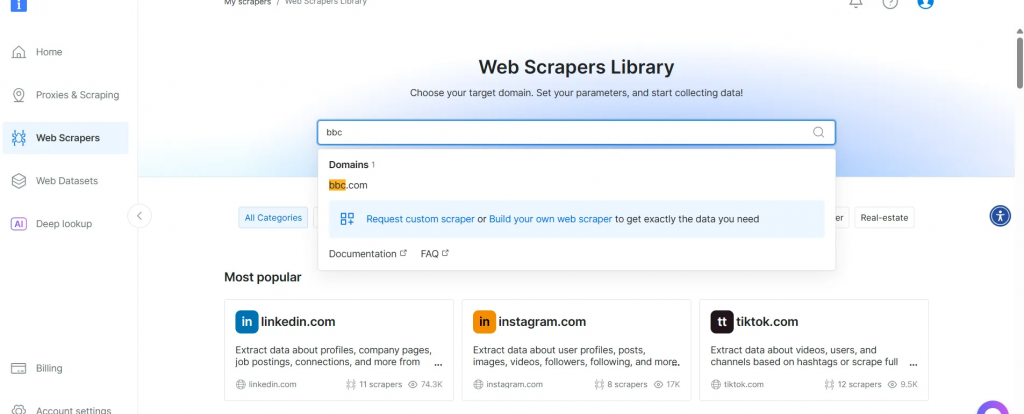
- En la lista de raspadores de BBC News, seleccione BBC News – recopilar por URL. Este rascador le permite recuperar datos sin iniciar sesión en el dominio.
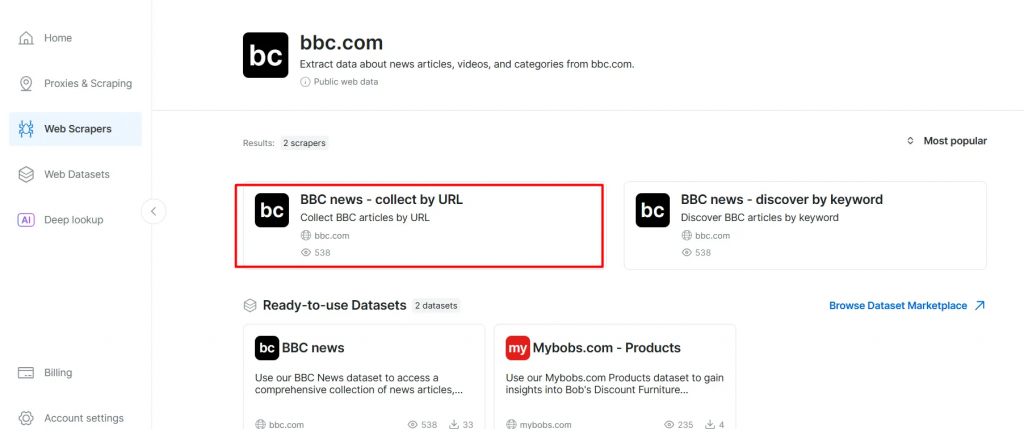
- Elija la opción API Scraper. No-Code Scraper ayuda a recuperar conjuntos de datos sin código.

- Haga clic en API Request Builder y copie su
API-key,BBC Dataset URLydataset_id. Los utilizará en la siguiente sección cuando cree el flujo de trabajo de Agentic RAG.
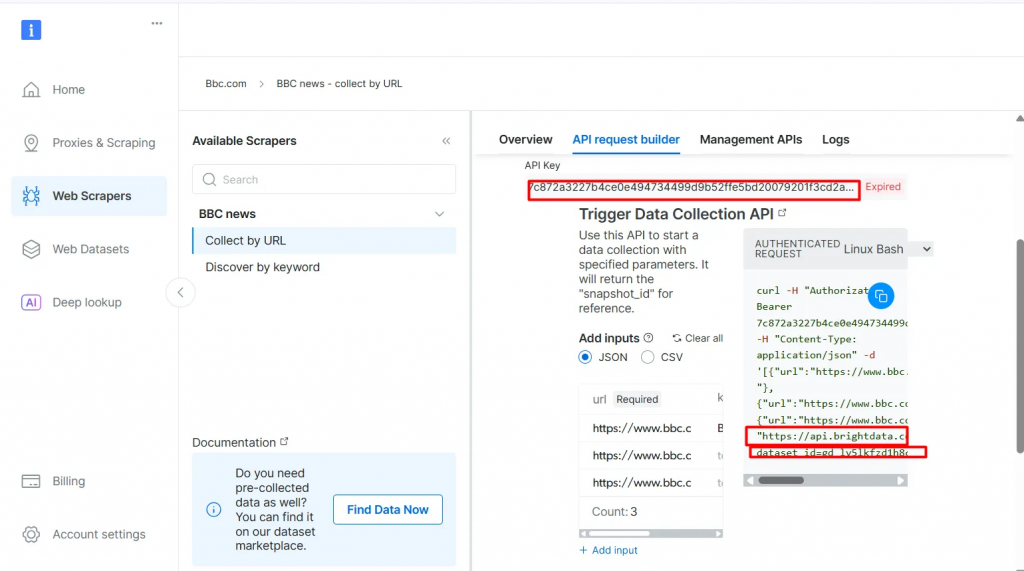
La API-key y el dataset_id son necesarios para habilitar las capacidades agentic en su flujo de trabajo. Permiten incrustar datos en tiempo real en la base de datos vectorial y realizar consultas en tiempo real, incluso cuando la consulta de búsqueda no coincide directamente con el contenido preindexado.
Requisitos previos
Antes de empezar, asegúrate de tener lo siguiente:
- Una cuenta de Bright Data
- Una clave API de OpenAI Regístrate en OpenAI para obtener tu clave API:
- Una clave API de Pinecone Consulte la documentación de Pinecone y siga las instrucciones de la sección Obtener una clave API.
- Conocimientos básicos de Python Puede instalar Python desde el sitio web oficial
- Comprensión básica de los conceptos de GAR y agente
Estructura del GAR agéntico
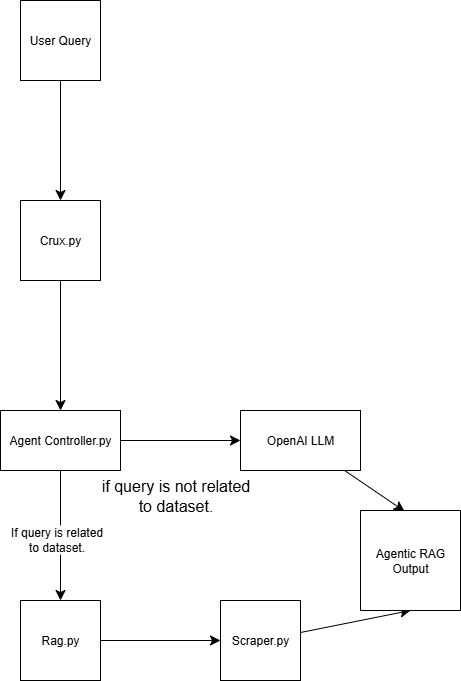
Este sistema Agentic RAG se construye utilizando cuatro scripts:
scraper.py Recupera datos web a través de Bright Data
rag.py Incrusta datos en la base de datos vectorial (Pinecone) Nota: Se utiliza una base de datos vectorial (incrustación numérica) porque almacena datos no estructurados generados típicamente por un modelo de aprendizaje automático. Este formato es ideal para la búsqueda de similitudes en tareas de recuperación.
agent_controller.py Contiene la lógica de control. Determina si utilizar datos preprocesados de la base de datos de vectores o confiar en el conocimiento general de GPT, dependiendo de la naturaleza de la consulta
crux.py Actúa como núcleo del sistema Agentic RAG. Almacena las claves API e inicializa el flujo de trabajo.
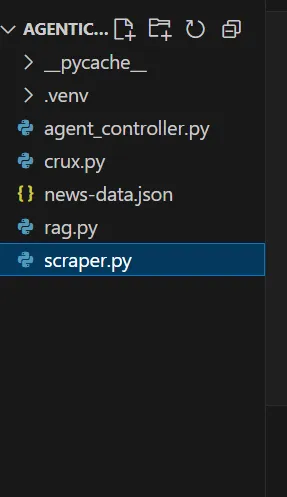
Al final de la demostración, tu estructura de trapo agéntico tendrá este aspecto:
Creación de RAG Agentic con Bright Data
Paso 1: Configurar el proyecto
1.1 Crear un nuevo directorio de proyecto
Crea una carpeta para tu proyecto y navega hasta ella:
mkdir agentic-rag
cd agentic-rag
1.2 Abrir el proyecto en Visual Studio Code
Inicie Visual Studio Code y abra el directorio recién creado:
.../Desktop/agentic-rag> code .
1.3 Configurar y activar un entorno virtual
Para configurar un entorno virtual, ejecute
python -m venv venv
Alternativamente, en Visual Studio Code, siga las instrucciones de la guía de entornos Python para crear un entorno virtual.
Para activar el entorno:
- En Windows:
.venv\Scripts\\activar - En macOS o Linux:
fuente venv/bin/activate
Paso 2: Implantar el recuperador de datos de Bright
2.1 Instala la librería requests en tu fichero scraper.py
pip install requests
2.2 Importe los siguientes módulos
import requests
import json
import time
2.3 Configure sus credenciales
Utilice la clave de API de Bright Data, la URL del conjunto de datos y dataset_id que copió anteriormente.
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 Configurar la lógica de respuesta
Rellene su solicitud con las URL de las páginas que desea raspar. En este caso, céntrate en artículos relacionados con el deporte.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 Ejecutar el código
Tras ejecutar el script, aparecerá un archivo llamado news-data.json en la carpeta del proyecto. Contiene los datos del artículo en formato JSON estructurado.
He aquí un ejemplo del contenido del archivo JSON:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
Ahora que ya tienes los datos, el siguiente paso es incrustarlos.
Paso 3: Configurar las incrustaciones y el almacén de vectores
3.1 Instale las bibliotecas necesarias en su archivo rag.py
pip install openai pinecone pandas
3.2 Importar las bibliotecas necesarias
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 Configure su clave OpenAI
Utiliza OpenAI para generar incrustaciones a partir del campo text_for_embedding.
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Configure su clave API Pinecone y los ajustes de índice
Configure el entorno Pinecone y defina su configuración de índices.
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Inicializar el cliente Pinecone y el índice
Asegúrese de que el cliente y el índice están correctamente inicializados para el almacenamiento y la recuperación de datos.
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 Limpiar, cargar y preprocesar datos
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
Nota: Puedes volver a ejecutar
scraper.pypara asegurarte de que tus datos están actualizados.
3.7 Generar incrustaciones con OpenAI
Cree incrustaciones a partir de su texto preprocesado utilizando el modelo de incrustación de OpenAI.
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Actualizar Pinecone con incrustaciones
Envía las incrustaciones generadas a Pinecone para mantener actualizada la base de datos de vectores.
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
Nota: Sólo necesita ejecutar este paso una vez para rellenar la base de datos. Después, puede comentar esta parte del código.
3.9 Inicializar la función de búsqueda Pinecone
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
Nota:
El umbral de puntuación define la puntuación mínima de similitud para que un resultado se considere relevante. Puede ajustar este valor en función de sus necesidades. Cuanto mayor sea la puntuación, más preciso será el resultado.
3.10 Generar respuestas con OpenAI
Utilizar OpenAI para generar respuestas a partir del contexto recuperado a través de Pinecone.
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (Opcional) Ejecutar una prueba sencilla para consultar e imprimir los resultados
Incluya código CLI amigable que le permita ejecutar una prueba básica. La prueba ayudará a verificar que tu implementación funciona y mostrará una vista previa de los datos almacenados en la base de datos.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
Consejo: Puede controlar la cantidad de texto que se muestra cortando el resultado, por ejemplo:
[:250].
Ahora sus datos están almacenados en la base de datos vectorial. Esto significa que tienes dos opciones de consulta:
- Recuperar de la base de datos
- Utilizar una respuesta genérica generada por OpenAI
Paso 4: Construir el controlador de agentes
4.1 En agent_controller.py
Importa la funcionalidad necesaria de rag.py.
from rag import openai_generate_answer, pinecone_search
4.2 Recuperación de piñas
Añade lógica para recuperar datos relevantes del almacén vectorial de Pinecone.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 Implementar una respuesta OpenAI alternativa
Cree una lógica para generar una respuesta utilizando OpenAI cuando no se recupere ningún contexto relevante.
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
Paso 5: Póngalo todo junto
5.1 En crux.py
Importa todas las funciones necesarias de agent_controller.py.
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 Proporcione sus claves API
Asegúrese de que sus claves API de OpenAI y Pinecone están correctamente configuradas.
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 Introduce tu prompt en la función main()
Define la entrada prompt dentro de la función main().
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 Llamar al GAR Agentic
Ejecute la lógica RAG de Agentic. Verá cómo procesa una consulta comprobando primero su relevancia antes de consultar la base de datos de vectores.

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
Intente probarlo con una consulta que no coincida con su base de datos, como por ejemplo:
def main():
query = "Why Sleep?"
El agente determina que no se encuentran buenas coincidencias en Pinecone y vuelve a generar una respuesta genérica utilizando OpenAI.

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
Consejo: Puede imprimir la puntuación de relevancia (score_threshold) de cada consulta para conocer el nivel de confianza del agente.
Ya está. Ha construido con éxito su Agentic RAG.
Paso 6 (opcional): Bucle de realimentación y optimización
Puede mejorar su sistema aplicando un circuito de retroalimentación para mejorar la formación y la indexación con el tiempo.
6.1 Añadir una función de retroalimentación
En agent_controller.py, crea una función que pida feedback al usuario después de mostrar una respuesta. Puedes llamar a esta función al final de la ejecución principal en crux.py.
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 Aplicar la lógica de retroalimentación
Crear una nueva función en agent_controller.py que reinvoca el proceso de recuperación si la retroalimentación es negativa. A continuación, llama a esta función en crux.py:
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
Conclusión y próximos pasos
En este artículo, has construido un sistema autónomo Agentic RAG que combina Bright Data para el web scraping, Pinecone como base de datos vectorial, y OpenAI para la generación de texto. Este sistema proporciona una base que puede ampliarse para soportar una variedad de características adicionales, tales como:
- Integración de bases de datos vectoriales con bases de datos relacionales o no relacionales
- Creación de una interfaz de usuario con Streamlit
- Automatización de la recuperación de datos web para mantener actualizados los datos de formación
- Mejorar la lógica de recuperación y el razonamiento de los agentes
Como se ha demostrado, la calidad de los resultados del sistema Agentic RAG depende en gran medida de la calidad de los datos de entrada. Bright Data ha desempeñado un papel fundamental a la hora de facilitar datos web fiables y actualizados, esenciales para una recuperación y generación eficaces.
Considere la posibilidad de explorar nuevas mejoras de este flujo de trabajo y de utilizar Bright Data en sus futuros proyectos para mantener unos datos de entrada coherentes y de alta calidad.





