
En esta guía, repasaremos el uso y la arquitectura de un Scraper LLM universal para el seguimiento de menciones LLM. Este proyecto combinará los siguientes Scrapers en una única interfaz unificada:
Cuando hayas terminado con esta guía, podrás realizar lo siguiente.
- Activar scrapers utilizando la API de Scraping web de Bright Data.
- Comprobar la disponibilidad y descargar los resultados del Scraper.
- Utilizar el formato de salida de Bright Data para una normalización sin esfuerzo.
- Comparar indicaciones en múltiples LLM simultáneamente para investigación y validación.
¿Quieres lanzarte directamente al proyecto? Échale un vistazo en GitHub.
¿Por qué crear un Scraper LLM universal?
El comportamiento de búsqueda ha cambiado. Ahora los usuarios hacen preguntas a los chatbots de IA y confían en las respuestas generadas, rara vez vuelven atrás para continuar la búsqueda. Esto cambia drásticamente las operaciones de SEO y de inteligencia de mercado: si su marca no se menciona en los resultados del chatbot, es posible que los clientes potenciales nunca la descubran.
Las empresas ahora necesitan aparecer no solo en los resultados de búsqueda, sino también en los resultados de los modelos. Los Scrapers LLM preconstruidos de Bright Data proporcionan resultados normalizados de los modelos más populares del mercado. Al unificar estas API en una única interfaz, los equipos pueden comparar los resultados de las recomendaciones de todos los principales LLM.
Considere la siguiente pregunta: ¿Quiénes son los mejores proveedores de Proxy residenciales?
Consultar manualmente cada LLM y leer los resultados puede llevar una hora o más. Con los resultados unificados, puede reenviar la pregunta a varios LLM simultáneamente y utilizar expresiones regulares para determinar inmediatamente si su empresa aparece en las respuestas.
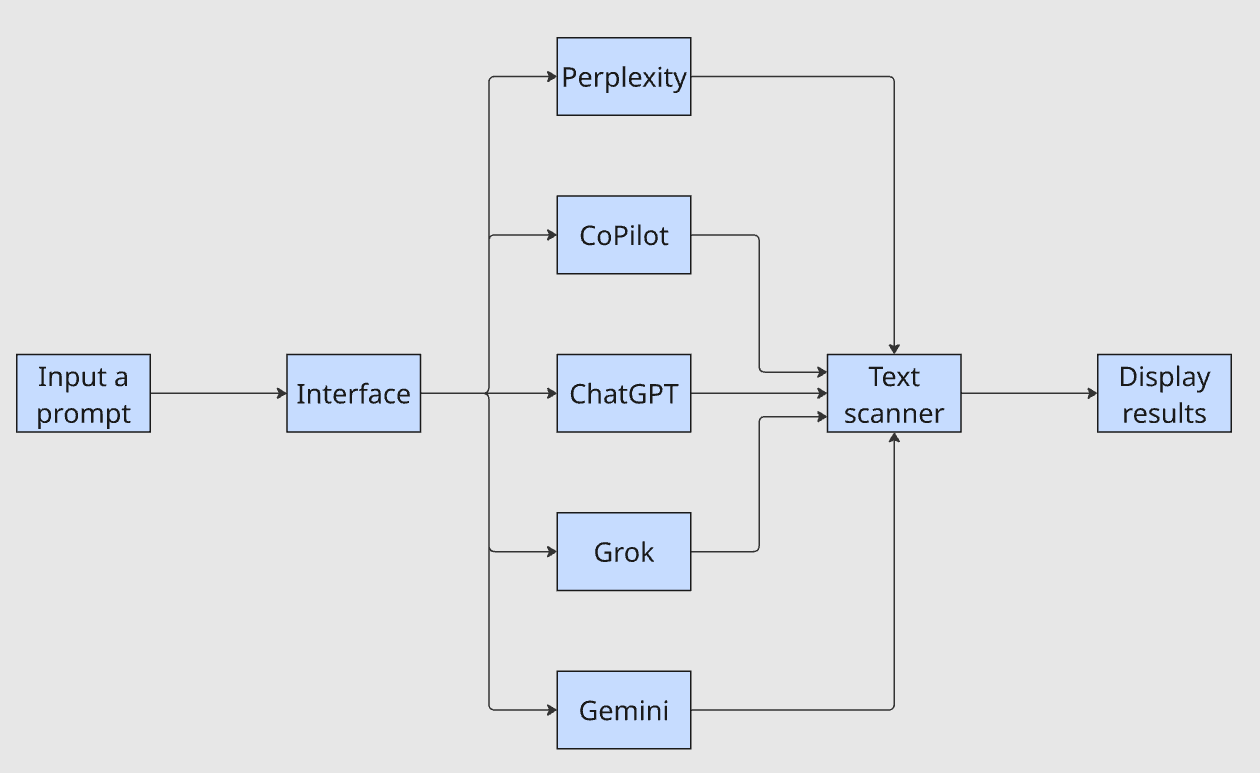
La interfaz toma una sola pregunta, la reenvía a cada LLM, canaliza los resultados a través de un escáner de texto y muestra los resultados. La pregunta «¿Aparece mi empresa en los resultados?», que antes llevaba una hora, ahora se responde en cuestión de minutos.
Creación del software real
Ahora, tenemos que crear el software real. Crearemos el esqueleto básico de nuestro proyecto. A continuación, iremos completando el código sobre la marcha. Esta sección no contiene el código completo. Se trata de un desglose conceptual, no de una explicación línea por línea.
Para empezar
Podemos empezar creando una nueva carpeta de proyecto.
mkdir universal-llm-scraper
cd universal-llm-scraperA continuación, creamos un entorno virtual para evitar conflictos de dependencias.
python -m venv .venvA continuación, debe activar el entorno virtual. El primero se puede activar en Linux o macOS. Si utiliza Windows, utilice el segundo comando.
Linux/macOS
source .venv/bin/activateWindows
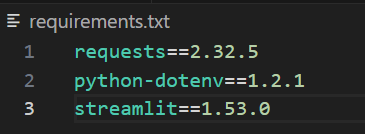
..venvScriptsActivate.ps1Por último, cree un archivo llamado requirements.txt y añada las dependencias que se indican a continuación. Puede ajustar los números de versión. Sin embargo, estos funcionaron bien durante la compilación, por lo que los hemos fijado para obtener un comportamiento reproducible.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0Cuando haya terminado, el archivo tendrá el aspecto que se muestra en la imagen siguiente.
Para instalar estas dependencias, simplemente ejecute el comando pip que se muestra a continuación.
pip install -r requirements.txtModelos de IA como objetos
A continuación, debemos comprender que todos nuestros modelos de IA funcionan como objetos. Cada uno tiene los siguientes atributos.
nombre: una etiqueta legible para el modelo.dataset_id: es un identificador único para el Scraper.url: la URL real que utilizamos para acceder al modelo de IA.
En la clase siguiente, creamos este mismo objeto de modelo. Esta clase no necesita métodos ni lógica. Si estás familiarizado con la informática, es similar a una estructura antigua.
class AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url Escribir un recuperador de modelos
A continuación, debemos escribir un recuperador de modelos. Esta clase realiza un trabajo más pesado. El recuperador de modelos proporciona una capa de coordinación unificadora entre Bright Data y el resto de nuestro código. Utiliza su clave API de Bright Data para autenticarse con la API. También tenemos varios métodos: get_model_response(), trigger_prompt_collection(), collect_snapshot() y write_model_output(). A medida que avancemos, iremos completando estos métodos.
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passget_model_response()
Este método se utilizará principalmente para la orquestación. Utiliza trigger_prompt_collection() para iniciar un Scraper y devolver su snapshot_id. A continuación, se utiliza collect_snapshot() para sondear la API y devolver la respuesta cuando esté lista. Por último, escribimos la respuesta en un archivo utilizando write_model_output().
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: failed to trigger snapshot. Por favor, espere y vuelva a intentarlo.")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"No se ha podido recopilar la instantánea {snapshot_id} para {model.name}. Por favor, espere y vuelva a intentarlo")
self.write_model_output(model, llm_response)trigger_prompt_collection()
Para activar una recopilación, pasamos nuestro token API a los encabezados HTTP. A continuación, intentamos enviar una solicitud POST a la API. Permitimos hasta tres reintentos, ya que los fallos en HTTP pueden ser a veces impredecibles y los reintentos tienen esto en cuenta. Si la respuesta es buena, devolvemos el snapshot_id. Si se producen errores, seguimos intentándolo hasta que se agotan los reintentos. Si superamos los reintentos, salimos de la función.
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
respuesta = Ninguna
intentar:
respuesta = solicitudes.post(
f"https://api.brightdata.com/conjuntos_de_datos/v3/scrape?dataset_id={model.dataset_id}¬ify=false&include_errors=true",
encabezados=encabezados,
datos=datos,
tiempo de espera=POST_TIMEOUT
)
respuesta.raise_for_status()
carga = respuesta.json()
id_instantánea = carga["id_instantánea"]
devolver id_instantánea
excepto (ValueError, KeyError, TypeError, requests.RequestException) como e:
imprimir(f"falló al activar la instantánea {model.name}: {e}")
intentos -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
Una vez que tenemos nuestro snapshot_id, comprobamos cada minuto si está listo. La API devuelve el código de estado 202 si la recopilación está en curso. Cuando la instantánea está lista, devuelve un 200. Cuando recibimos cualquier otro código de estado, lanzamos un error y entramos en la lógica de reintento. Si se superan los reintentos, salimos del método.
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"Esperando {model.name} instantánea {snapshot_id}")
max_errors = 3
while not ready and max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
try:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
except requests.RequestException as e:
max_errors -= 1
print(f"{model.name}: error de sondeo ({e})")
continue
if response.status_code == 200:
print(f"¡La instantánea {snapshot_id} de {model.name} está lista!")
ready = True
llm_response = response.json()
return llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
print("Error al comunicarse con el servidor")
print(f"Se ha superado el número máximo de errores, no se ha podido recopilar la instantánea {snapshot_id}")
returnwrite_model_output()
Esta es muy sencilla. Solo la usamos para almacenar los resultados de nuestro modelo. os.makedirs(OUTPUT_FOLDER, exist_ok=True) se utiliza para asegurarnos de que tenemos una carpeta de resultados. A continuación, escribimos el archivo en la carpeta de resultados y utilizamos model.name para nombrar el archivo.
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"Finished generating report from {model.name} → {path}") Escribir un archivo principal
Ahora, escribiremos un archivo principal. Podemos utilizarlo para ejecutar los procesos de backend sin cargar la interfaz de usuario. run_one() nos permite ejecutar el proceso en un único modelo. Dentro de main(), utilizamos ThreadPoolExecutor() para ejecutar esta función en varios subprocesos simultáneamente. En lugar de realizar una recopilación cada vez, podemos realizar una recopilación por subproceso para acelerar drásticamente nuestros resultados.
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "¿Por qué el cielo es azul?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
fallos = 0
con ThreadPoolExecutor(máximo_trabajadores=min(MÁXIMO_TRABAJADORES, longitud(modelos))) como grupo:
futuros = {grupo.enviar(ejecutar_uno, m, recuperador, prompt): m para m en modelos}
para fut en as_completed(futuros):
modelo = futuros[fut]
intentar:
name = fut.result()
print(f"{name}: done")
except Exception as e:
failures += 1
print(f"{model.name}: failed ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()Puede ejecutar el archivo principal utilizando el siguiente comando.
python main.pyLa interfaz de usuario de Streamlit
La interfaz de usuario de Streamlit es muy similar a nuestro archivo principal en cuanto a concepto. Seguimos utilizando múltiples subprocesos para ejecutar cada colección. Nuestras funciones write_output() y sanitize_filename() se utilizan solo para limpiar los nombres de los archivos. En lugar de imprimir en la terminal, creamos variables con Streamlit para iniciar y mostrar la aplicación en su navegador local.
Escribir la interfaz de usuario
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
return path
def main():
st.set_page_config(page_title="Universal LLM Scraper", layout="wide")
st.title("Universal LLM Scraper")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("Falta BRIGHTDATA_API_TOKEN. Añádalo a un archivo .env en la raíz del proyecto.")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("Configuración de ejecución")
prompt = st.text_area("Prompt", value="¿Quiénes son los mejores proveedores de Proxies residenciales?", height=120)
target_phrase = st.text_input("Frase objetivo a rastrear", value="Bright Data")
selected = st.multiselect("Modelos", options=model_names, default=model_names)
country = st.text_input("País (opcional)", value="")
save_to_disk = st.checkbox("Guardar resultados en salida/", value=True)
redact_terms = st.text_area("Términos de marca que se deben ocultar (uno por línea)", value="")
redact_mode = st.selectbox("Modo de ocultación", ["Mascarar", "Eliminar"], index=0)
run_clicked = st.button("Ejecutar rastreos", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # nombre_modelo -> error str
if "paths" not in st.session_state:
st.session_state.paths = {} # nombre_modelo -> ruta guardada
def apply_redaction(text: str) -> str:
terms = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not terms:
return text
pattern = re.compile(r"(" + "|".join(map(re.escape, terms)) + r")", flags=re.IGNORECASE)
if redact_mode == "Mask":
return pattern.sub("███", text)
return pattern.sub("", text)
def extract_answer_text(payload: dict) -> str | None:
if not isinstance(payload, dict):
return None
if isinstance(payload.get("answer_text"), str):
return payload["answer_text"]
if "data" in payload and isinstance(payload["data"], list) and payload["data"]:
first = payload["data"][0]
if isinstance(first, dict) and isinstance(first.get("answer_text"), str):
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# Fallback: si no podemos encontrar answer_text, simplemente buscamos la carga útil serializada.
try:
blob = json.dumps(payload, ensure_ascii=False)
return target_phrase.lower() in blob.lower()
except Exception:
return False
# Diseño: estado + resultados
status_col, results_col = st.columns([1, 2], gap="large")
with status_col:
st.subheader("Status")
if run_clicked:
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
if not selected:
st.warning("Selecciona al menos un modelo.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
payload = retriever.run(model, prompt, country=country)
return model_name, payload
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, total)) as pool:
futures = [pool.submit(run_one, name) for name in selected]
for fut in as_completed(futures):
try:
model_name, payload = fut.result()
st.session_state.results[model_name] = payload
status_boxes[model_name].success(f"{model_name}: done")
if save_to_disk:
path = write_output(model_name, payload)
st.session_state.paths[nombre_modelo] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("Ejecución completada.")
# Mostrar archivos guardados (si los hay)
if st.session_state.paths:
st.caption("Archivos guardados")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("Errores")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("Resultados")
if not st.session_state.results:
st.info("Haga clic en 'Ejecutar rastreos' para recopilar los resultados.")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
for tab, model_name in zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
with tab:
answer_text = extract_answer_text(payload)
mentioned = mentions_target(payload)
st.markdown(f"**Frase objetivo mencionada:** {'✅' si se menciona, si no '❌'}")
if answer_text and isinstance(answer_text, str):
st.markdown("### Respuesta")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### JSON sin procesar")
st.json(payload)
if __name__ == "__main__":
main()Sí, app.py es más largo que nuestro archivo principal. Sin embargo, solo hay unas pocas diferencias clave con respecto a main.py.
- Gestión del estado: con Streamlit, almacenamos nuestros resultados, errores y rutas de archivos en
st.session_state. Esto nos permite recuperarlos y mostrarlos en la interfaz de usuario. - Orquestación: en lugar de codificar nuestras indicaciones y colecciones de modelos, estas se recopilan y activan desde la interfaz de usuario.
- Inspección de texto: inspeccionamos el texto de nuestra respuesta para ver si contiene la frase objetivo. Si la frase objetivo está presente, mostramos un ✅. Si no lo está, mostramos un ❌.
Uso de la interfaz de usuario
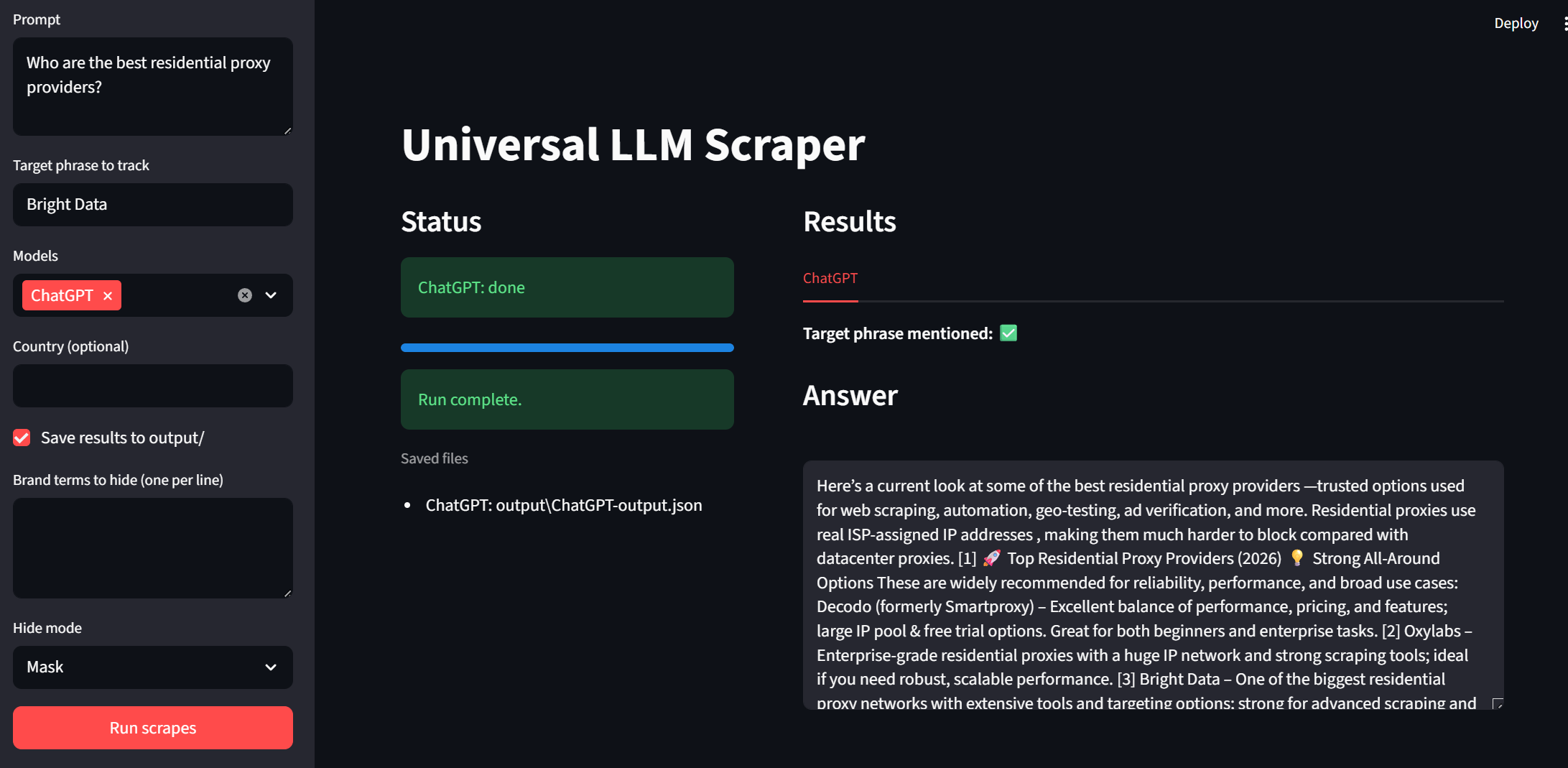
Ahora es el momento de probar nuestra interfaz de usuario. Puede ejecutar la aplicación con el fragmento de código siguiente.
streamlit run app.pyEcha un vistazo a la barra lateral. Podemos introducir indicaciones y frases objetivo. Ahora se pueden seleccionar los modelos mediante un menú desplegable. «País» y «Guardar salida» son ajustes opcionales por parte del usuario. Para ejecutar el programa, simplemente haz clic en el botón «Ejecutar rastreos» en la parte inferior.
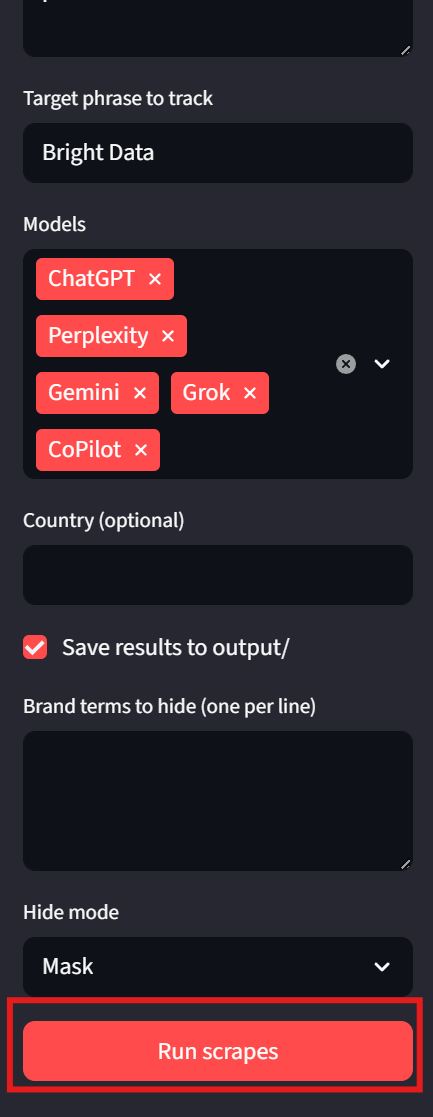
Los resultados
Cada modelo aparece como una pestaña independiente dentro de los resultados. De esta forma, podemos revisar rápidamente los resultados. En las imágenes siguientes, Bright Data recibió una marca de verificación verde por cada resultado del modelo. Ejemplo:
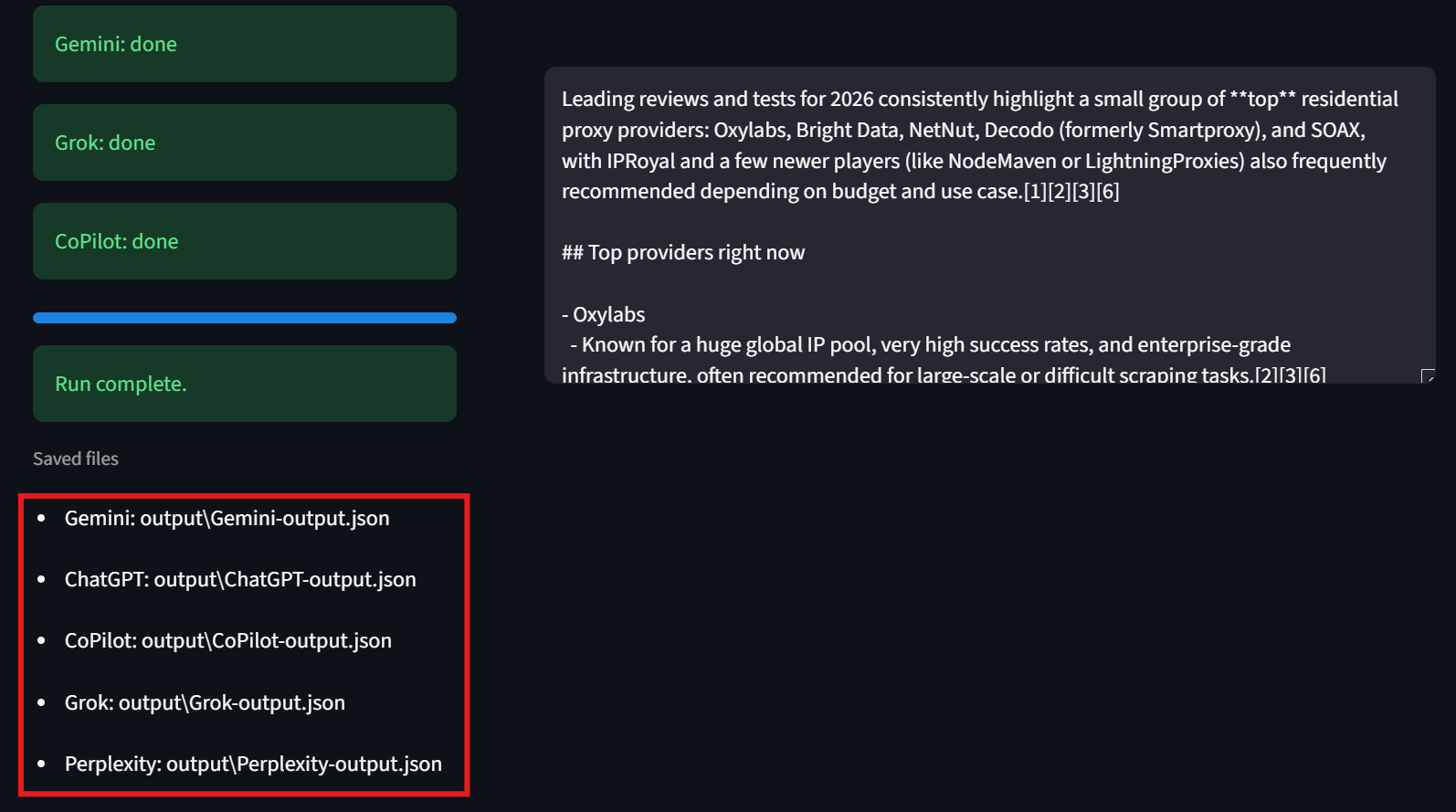
Los usuarios también deben fijarse en la esquina inferior izquierda de la interfaz. Aquí, la interfaz de usuario muestra la ruta de cada uno de los archivos de resultados. Esto facilita la inspección de los resultados sin procesar.
Pasando al siguiente nivel
En primer lugar, necesitamos una cuenta de Supabase. Puede dirigirse a supabase.com y seguir las instrucciones. Supabase ofrece una variedad de planes de precios para satisfacer sus necesidades. Para este proyecto, su nivel gratuito será suficiente. Sin embargo, a medida que su base de datos crezca, es posible que necesite actualizarla.
Necesitarás una clave API. Una vez que hayas terminado de configurar tu cuenta y tu proyecto, haz clic en Configuración del proyecto en la barra lateral. Ve a la pestaña Claves API para recuperar tu clave API.
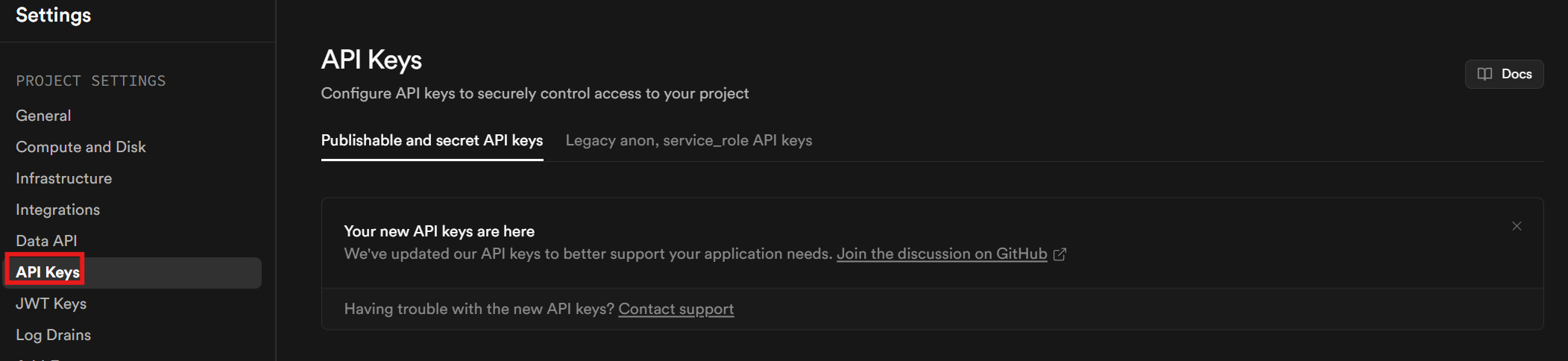
Desplázate hasta la parte inferior de la página. Tu clave se encuentra en la sección denominada «Claves secretas».
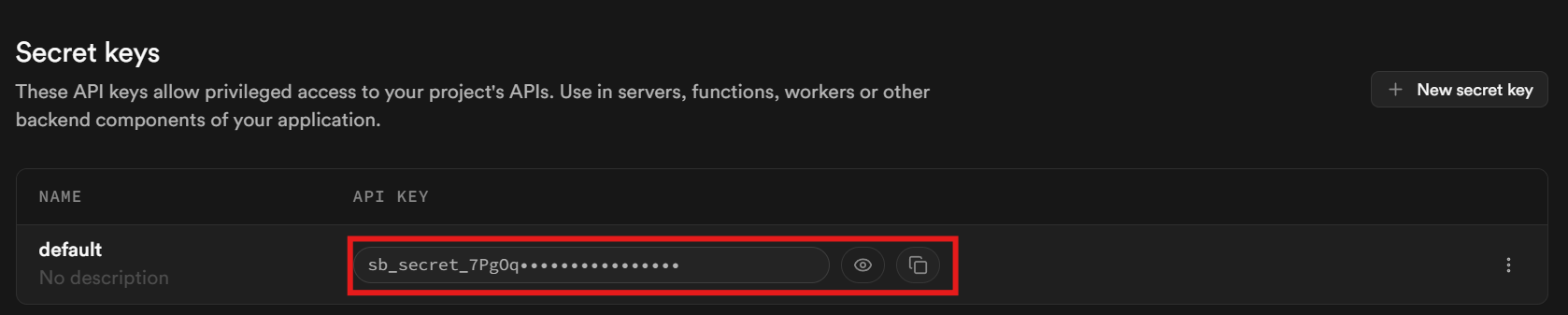
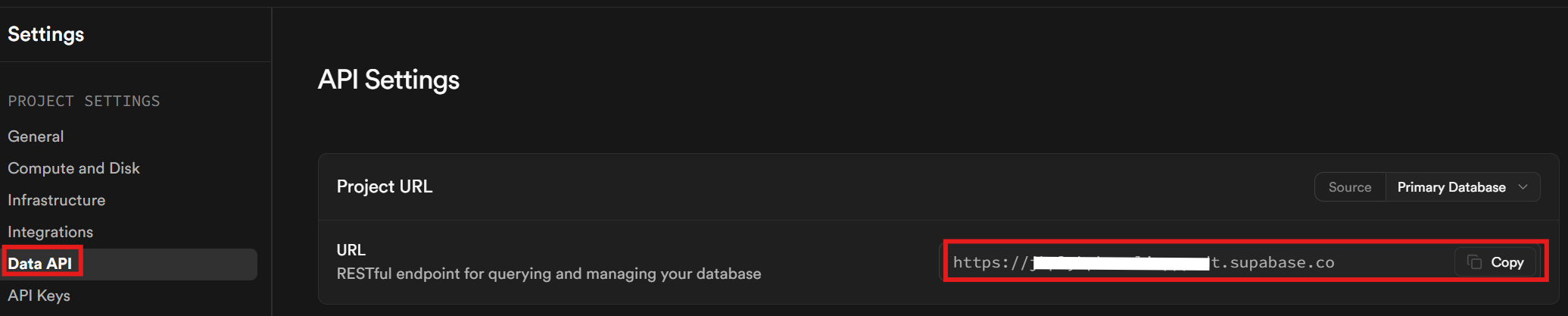
Por último, en la pestaña API de datos, recupera tu URL de Supabase. Esta es la URL que utilizas para comunicarte con tu base de datos.
Una vez que tengamos nuestras claves, debemos actualizar nuestro archivo de entorno y nuestro archivo de requisitos. Tu nuevo archivo de entorno debería tener ahora este aspecto.
BRIGHTDATA_API_TOKEN=<TU-clave-API-bright-data>
SUPABASE_URL=<TU-url-proyecto-supabase>
SUPABASE_API_TOKEN=<TU-clave-API-supabase>Nuestro archivo de requisitos ahora tiene este aspecto.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2Creación de las tablas
Ahora, tenemos que crear nuestras tablas dentro de la base de datos. Utilizando la barra lateral, abre el editor SQL.
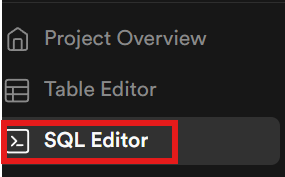
Ejecuciones de LLM
Pega el siguiente código SQL en un script y ejecútalo. Esto crea una tabla llamada llm_runs. Cada vez que ejecutemos una colección, depositaremos los resultados aquí.
create table public.llm_runs (
id bigint generated by default as identity primary key,
created_at_ts bigint not null, -- unix seconds
model_name text not null,
prompt text not null,
country text null,
target_phrase text null,
mentioned boolean not null default false,
payload jsonb not null
);
create index if not exists llm_runs_created_at_ts_idx
on public.llm_runs (created_at_ts);
crear índice si no existe llm_runs_model_idx
en public.llm_runs (model_name);
crear índice si no existe llm_runs_target_idx
en public.llm_runs (target_phrase);Indicaciones
También necesitamos la capacidad de guardar indicaciones. El código siguiente crea una tabla de indicaciones.
create table public.prompts (
id bigint generated by default as identity primary key,
created_at_ts bigint not null,
prompt text not null,
is_active boolean not null default true
);
create index if not exists prompts_created_at_ts_idx
on public.prompts (created_at_ts desc);
create index if not exists prompts_active_idx
on public.prompts (is_active);Programaciones
Por último, necesitamos una tabla para almacenar los trabajos programados.
create table public.schedules (
id bigint generated by default as identity primary key,
name text not null,
is_enabled boolean not null default true,
next_run_ts bigint not null,
last_run_ts bigint null,
models jsonb not null default '[]'::jsonb,
país texto nulo,
frase_objetivo texto nulo,
solo_indicaciones_activas booleano no nulo por defecto verdadero,
bloqueado_hasta_ts bigint nulo,
propietario_bloqueo texto nulo,
repetir_cada_segundos bigint no nulo por defecto 86400
);
crear índice si no existe schedules_due_idx
en public.schedules (is_enabled, next_run_ts);
crear índice si no existe schedules_lock_idx
en public.schedules (locked_until_ts);Arquitectura actualizada
El código base final es ahora tan grande que ya no cabe en un tutorial. En lugar de volcar todos los archivos aquí, repasaremos algunos de los puntos fundamentales que hay detrás de la conexión a la base de datos, el ejecutor sin interfaz y la interfaz de usuario Streamlit.
Interacciones con la base de datos
Tenemos una variedad de ayudantes de base de datos, pero todo se basa principalmente en la lectura y la creación dentro de la base de datos. El código siguiente nos permite conectarnos a toda la base de datos.
def get_db() -> Client:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # mantén la coherencia con tu .env
if not url or not key:
raise RuntimeError("Falta SUPABASE_URL o SUPABASE_API_TOKEN en el entorno.")
return create_client(url, key)Para interactuar realmente con la base de datos, llamamos a métodos adicionales además de get_db(). En el siguiente fragmento, get_db() recupera la base de datos. A continuación, utilizamos db.table("llm_runs").insert(row).execute() para insertar nuevas filas en nuestra tabla llm_runs. Las indicaciones y los ayudantes de programación siguen esta misma lógica básica.
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,)
-> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
"mentioned": bool(mentioned),
"payload": payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "FAILED RUN"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"Insert failed: {res}")
return res.data[0]Ejecutor sin interfaz gráfica
Después de crear la interfaz de usuario Streamlit, renombramos main.py a headless_runner.py a medida que el proyecto se ampliaba. Ya no hay un programa principal, sino dos scripts que se ejecutan simultáneamente.
persist_run() comprueba si hay una carga útil vacía en la API. Si la carga útil está vacía, devolvemos False e imprimimos un mensaje en la terminal sobre la inserción fallida. Si la carga útil contiene información, utilizamos save_run() para insertar los resultados en la base de datos.
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: skipping DB insert (payload is None).")
return False
# Si desea tratar la lista/diccionario vacío como «no guardar», mantenga esto:
if payload == {} or payload == []:
print(f"{model_name}: omitiendo inserción en la base de datos (carga útil vacía). type={type(payload).__name__}")
return False
try:
json.dumps(payload, ensure_ascii=False)
except TypeError as e:
print(f"{model_name}: payload no serializable en JSON ({e}). Stringifying.")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
try:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
except Exception as db_err:
print(f"{model_name}: DB insert failed: {db_err}")
return mentionedAntes de continuar, hay otra parte importante de nuestro ejecutor sin interfaz que debes tener en cuenta. Tenemos una variedad de variables de entorno opcionales que puedes utilizar para ajustar la configuración. El tiempo de ejecución real de nuestro programa se mantiene dentro de un simple bucle while. Dentro del bucle de tiempo de ejecución, comprobamos continuamente si hay nuevos trabajos en la programación. Cada vez que vence un trabajo programado, se llama a run_schedule_once() para iniciar la ejecución.
# ajústelas sin cambios en la base de datos
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # frecuencia de activación
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # duración del bloqueo mientras se ejecuta un trabajo
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # ejecutar todos los trabajos vencidos en cada tick
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# reclamar y ejecutar una programación, o vaciar todas las programaciones pendientes
while True:
try:
due = claim_due_schedule(now_ts=now_ts, lock_owner=lock_owner, lock_seconds=lock_seconds)
except Exception as e:
print(f"Failed to claim due schedule: {e}")
due = None
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
except Exception as e:
# Si algo explota durante la ejecución, NO avanzamos en la programación.
# El bloqueo caducará y la programación se retomará más tarde.
print(f"La ejecución de la programación se ha bloqueado: {e}")
if not drain_all_due:
break
# actualizar la hora para la próxima reclamación
now_ts = int(time.time())
if not ran_any:
# opcional: registros más silenciosos
print(f"[{int(time.time())}] No hay programaciones pendientes.")
time.sleep(tick_every_seconds)Para iniciar el ejecutor sin interfaz gráfica, simplemente abra un nuevo terminal y ejecute python headless_runner.py.
La aplicación Streamlit
Nuestra aplicación Streamlit ha crecido enormemente. Todavía puede invocarla utilizando streamlit run app.py Ahora tiene cinco pestañas separadas. La página original «Run Scrapes» sigue apareciendo inmediatamente en nuestro panel de control.
En nuestra pestaña «Prompts», los usuarios pueden crear nuevas indicaciones y, opcionalmente, guardarlas para su uso posterior. En la parte inferior de esta página, los usuarios pueden configurar y realizar ejecuciones masivas.
En la pestaña «History», los usuarios pueden consultar el historial detallado de ejecuciones. En la parte inferior de esta página, los usuarios también tienen la opción de inspeccionar las cargas JSON sin procesar si lo desean.
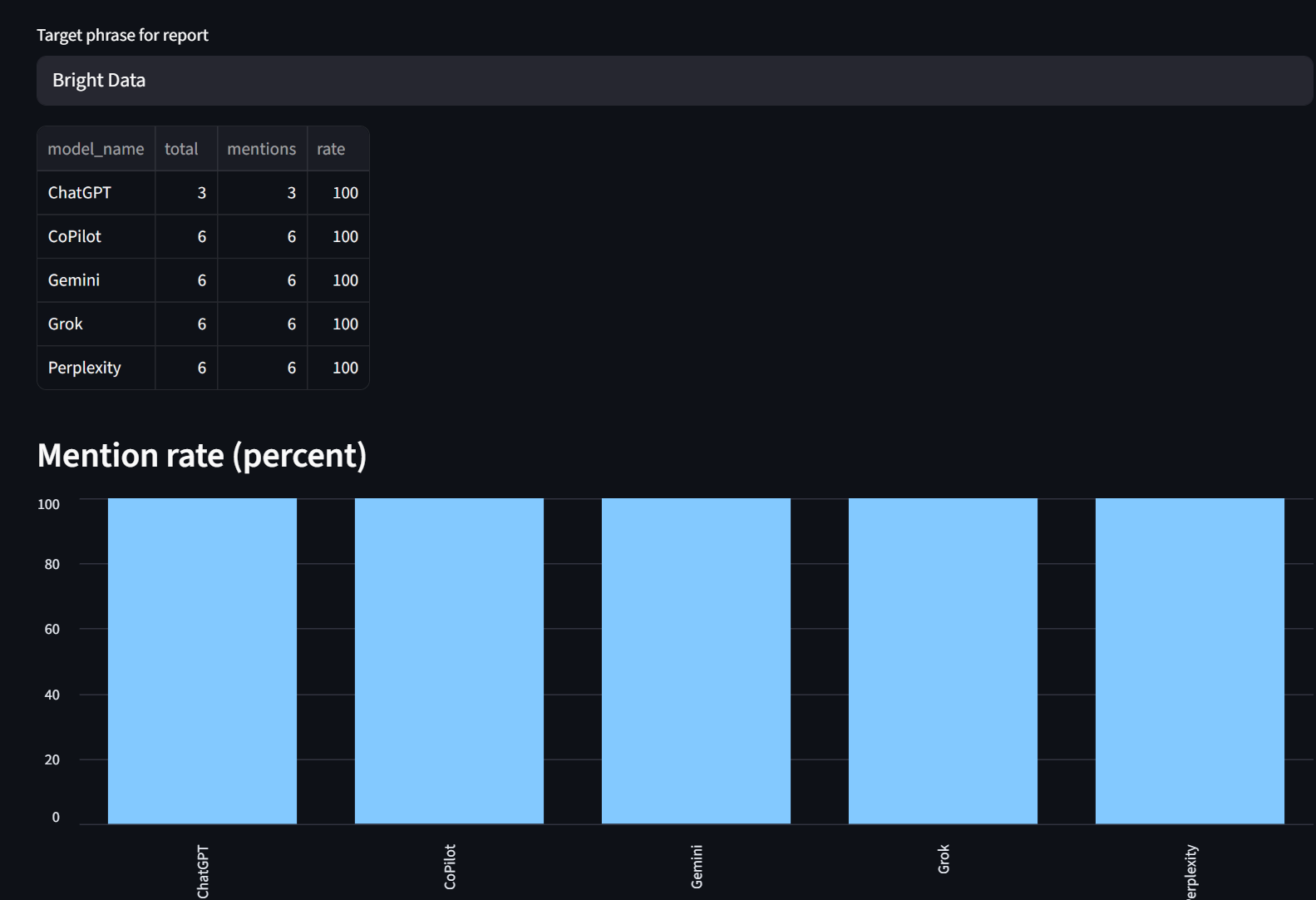
Nuestra pestaña de informes le permite ver las tasas de mención desglosadas por modelo. Como puede ver, Bright Data fue mencionado el 100 % de las veces por cada modelo aquí.
Por último, tenemos nuestra pestaña Programador. Los usuarios pueden crear y eliminar programaciones. Si no quieren esperar, también pueden utilizar el botón «Ejecutar ahora» y el ejecutor sin interfaz lo recogerá en el siguiente tick.
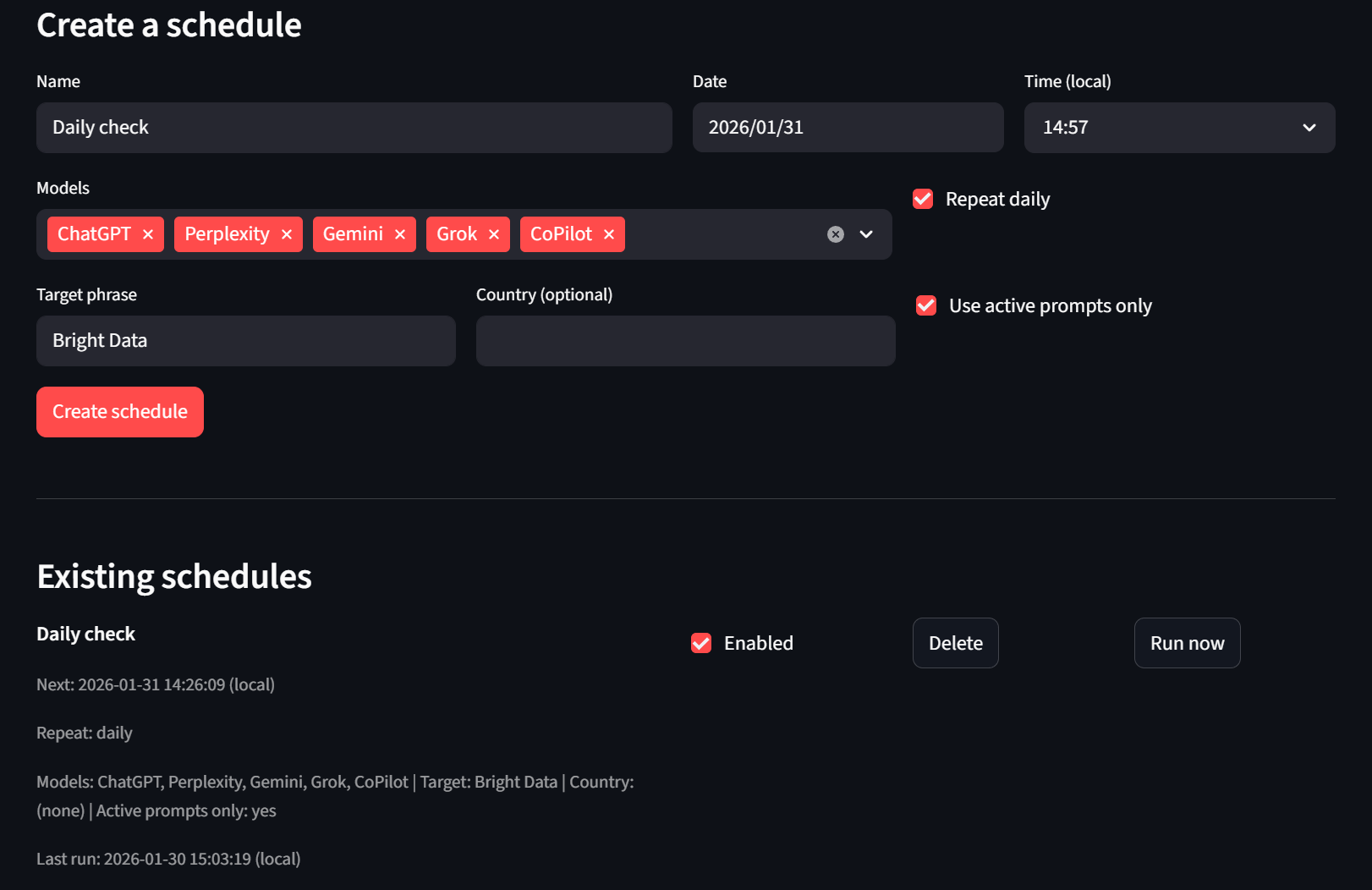
Conclusión
Si ha creado el prototipo al principio de este artículo, ya comprende los conceptos necesarios para llevar herramientas como esta a la siguiente fase.
La arquitectura que se muestra en esta guía puede admitir:
- Memoria persistente y seguimiento histórico: almacena los resultados a lo largo del tiempo para detectar tendencias en cómo los modelos de IA mencionan tu marca, realiza un seguimiento de los cambios en la clasificación e identifica a los competidores emergentes.
- Cientos de indicaciones supervisadas diariamente: automatice las recopilaciones programadas entre miles de variaciones de palabras clave, categorías de productos y comparaciones con la competencia.
- Informes y análisis automatizados: genere informes que muestren las tasas de mención de la marca, el análisis de opiniones, la frecuencia de citas y el posicionamiento competitivo en todos los principales LLM.
- Sistemas de alerta: active notificaciones cuando su marca deje de aparecer en las recomendaciones o cuando los competidores ganen visibilidad.
- Supervisión multirregional: realice un seguimiento de cómo varían las respuestas de la IA según la geografía para informar las estrategias de marketing localizadas.
Para los equipos empresariales que gestionan la reputación de la marca a gran escala, la capacidad de responder a la pregunta «¿Mi empresa es recomendada por la IA?» en todos los modelos principales, para cada consulta relevante, todos los días, ya no es opcional. Es una infraestructura esencial.
Las API de Web Scraper de Bright Data proporcionan fuentes de datos normalizadas y fiables que hacen posible este nivel de supervisión. Tanto si realiza un seguimiento de ChatGPT, Perplexity, Gemini, Grok o Microsoft Copilot, el esquema unificado elimina las fricciones de la integración y permite a su equipo centrarse en la información útil en lugar de en la gestión de datos.
¿Está listo para crear su propio sistema de supervisión de la visibilidad de la IA? Comience una prueba gratuita y compruebe cómo Bright Data puede impulsar su estrategia de SEO de última generación.





