
En este tutorial aprenderás:
- Qué es Gemini CLI y por qué es tan popular en la comunidad de programadores.
- Cómo añadir capacidades de interacción web y extracción de datos puede llevarlo al siguiente nivel.
- Cómo conectar Gemini CLI con el servidor Bright Data Web MCP para crear un agente de codificación de IA mejorado.
Sumerjámonos.
¿Qué es la CLI Gemini?
Gemini CLI es un agente de IA desarrollado por Google que lleva la potencia del gran modelo de lenguaje Gemini directamente a tu terminal. Está diseñado para mejorar la productividad de los desarrolladores y simplificar diversas tareas, especialmente las relacionadas con la codificación.
La biblioteca es de código abierto y está disponible a través de un paquete Node.js. En el momento de escribir este artículo, ya ha obtenido más de 67.000 estrellas en GitHub. A pesar de haber sido lanzada hace solo unos meses, el entusiasmo de la comunidad y su rápida adopción han sido notables.
En concreto, los principales aspectos que hacen especial a Gemini CLI son:
- Interacción directa con el terminal: Interactúa con los modelos Gemini directamente desde la línea de comandos.
- Enfoque de codificación: Le ayuda a depurar, generar nuevas funciones, mejorar la cobertura de las pruebas e incluso crear nuevas aplicaciones a partir de indicaciones o bocetos.
- Integración de herramientas y extensibilidad: Aprovecha un bucle ReAct (“razonar y actuar”) y puede integrarse con herramientas incorporadas (como
grep,terminal,lectura/escritura de archivos) y servidores MCP externos. - Uso gratuito: Google también ofrece un generoso nivel de uso gratuito, lo que hace que la herramienta sea ampliamente accesible.
- Capacidades multimodales: Admite tareas como generar código a partir de imágenes o bocetos.
¿Por qué ampliar Gemini CLI con funciones de interacción web y extracción de datos?
Por muy potentes que sean los modelos Gemini integrados en la CLI Gemini, siguen enfrentándose a limitaciones comunes a todos los LLM.
Los modelos Géminis sólo pueden responder basándose en el conjunto de datos estáticos en el que fueron entrenados. Pero eso es una instantánea del pasado. Además, los LLM no pueden renderizar ni interactuar con páginas web en vivo como un usuario humano. En consecuencia, su precisión y su radio de acción son intrínsecamente limitados.
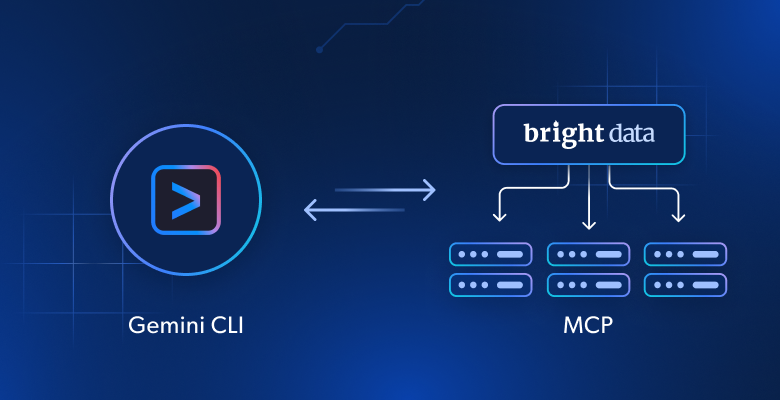
Ahora, imagina que le das a tu asistente de programación Gemini CLI la capacidad de buscar tutoriales, páginas de documentación y guías en tiempo real, y aprender de ellos. Imagíneselo interactuando con cualquier sitio web activo, del mismo modo que ya navega por su sistema de archivos. Esto supone un salto significativo en su funcionalidad, y es posible gracias a la integración con el servidor Bright Data Web MCP.
El servidor Bright Data Web MCP proporciona acceso a más de 60 herramientas preparadas para la IA para la recopilación de datos web en tiempo real y la interacción web. Todas ellas se alimentan de la rica infraestructura de datos de IA de Bright Data.
Para obtener la lista completa de herramientas expuestas por el servidor MCP de Bright Data Web, consulte la documentación.
Éstas son sólo algunas de las cosas que puede conseguir combinando Gemini CLI con Web MCP:
- Recuperar SERPs para insertar automáticamente enlaces contextuales en informes o artículos.
- Pida a Gemini que busque tutoriales o documentación actualizados, aprenda de ellos y, a continuación, genere código o plantillas de proyecto en consecuencia.
- Extraiga datos de sitios web reales y guárdelos localmente para simularlos, probarlos o analizarlos.
Veamos un ejemplo práctico de esta integración.
Cómo integrar el servidor Web MCP en la CLI Gemini
Aprenda a instalar y configurar Gemini CLI localmente y a integrarlo con el servidor Bright Data Web MCP. La configuración resultante se utilizará para:
- Rastrea una página de producto de Amazon.
- Almacena los datos localmente.
- Crear un script Node.js para cargar y procesar los datos.
Siga los pasos que se indican a continuación.
Requisitos previos
Para reproducir los pasos de esta sección del tutorial, asegúrate de tener lo siguiente:
- Node.js 20+ instalado localmente (recomendamos utilizar la última versión LTS).
- Una clave API Gemini o una clave API Vertex AI (en este caso, vamos a utilizar una clave API Gemini).
- Una cuenta de Bright Data.
No es necesario que configure las claves API todavía. Los pasos siguientes le guiarán en la configuración de las claves API de Gemini y Bright Data cuando llegue el momento.
Aunque no es estrictamente necesario, los siguientes conocimientos previos le serán de ayuda:
- Comprensión general del funcionamiento de MCP.
- Cierta familiaridad con el servidor MCP de Bright Data Web y sus herramientas disponibles.
Paso 1: Instalar Gemini CLI
Para empezar a utilizar la CLI de Gemini, primero debe generar una clave de API desde Google AI Studio. Sigue las instrucciones oficiales para recuperar tu clave API Gemini.
Nota: Si ya dispone de una clave API de Vertex AI, o prefiere utilizarla, consulte la documentación oficial.
Una vez que tengas tu clave API Gemini, abre tu terminal y establécela como variable de entorno con este comando Bash:
export GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"O, alternativamente, con este comando PowerShell en Windows:
$env:GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Sustituya la con la clave generada.
A continuación, instala la CLI Gemini de forma global a través del paquete oficial @google/gemini-cli:
npm install -g @google/gemini-cliEn la misma sesión de terminal en la que configuraste la GEMINI_API_KEY (o VERTEX_API_KEY), inicia la CLI de Gemini con:
geminiEsto es lo que deberías ver:
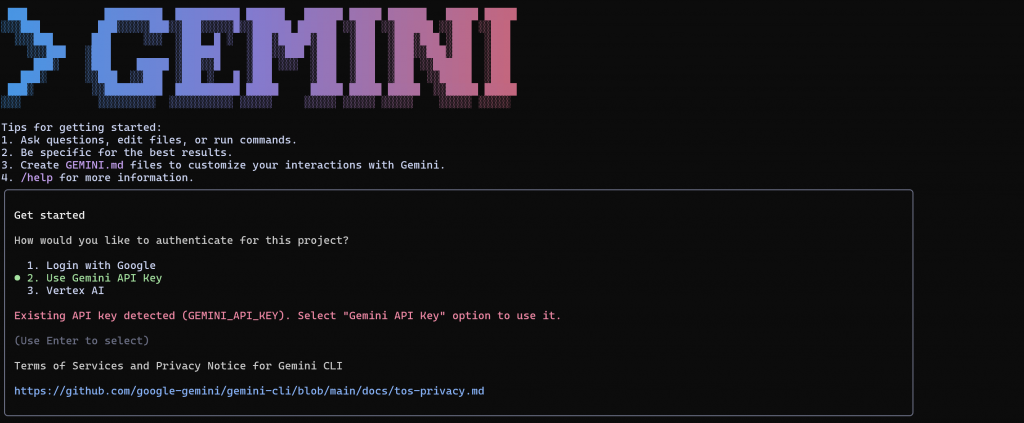
Pulse Intro para seleccionar la opción 2 (“Use Gemini API key”). La CLI debería detectar automáticamente su clave de API y pasar a la vista de solicitud:
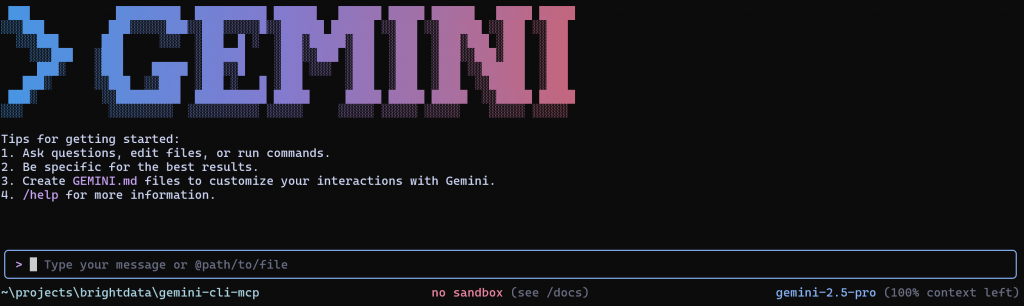
En la sección “Escriba su mensaje o @ruta/a/archivo”, puede escribir su mensaje directamente o hacer referencia a un archivo para enviarlo a Gemini CLI para su ejecución.
En la esquina inferior derecha, verá que Gemini CLI utiliza el modelo gemini-2.5-pro. Ese es el modelo configurado de fábrica. Afortunadamente, la API Gemini ofrece un nivel gratuito con hasta 100 solicitudes por día utilizando el modelo gemini-2.5-pro, por lo que puedes probarlo incluso sin un plan de pago.
Si prefiere un modelo con límites de velocidad superiores, como gemini-2.5-flash, puede configurarlo antes de iniciar la CLI definiendo la variable de entorno GEMINI_MODEL. En Linux o macOS, ejecute:
export GEMINI_MODEL="gemini-2.5-flash"O, lo que es lo mismo, en Windows:
$env:GEMINI_MODEL="gemini-2.5-flash"A continuación, inicie la CLI Gemini como de costumbre con el comando gemini.
¡Genial! El Gemini CLI está ahora configurado y listo para usar.
Paso 2: Empezar a utilizar el servidor MCP de Bright Data Web
Si aún no lo ha hecho, regístrese en Bright Data. Si ya tiene una cuenta, simplemente inicie sesión.
A continuación, siga las instrucciones oficiales para generar su clave de API de Bright Data. Para simplificar, en este paso se asume que está utilizando un token con permisos de administrador.
Instale el servidor MCP Bright Data Web de forma global mediante este comando:
npm install -g @brightdata/mcpA continuación, comprueba que todo funciona con el siguiente comando Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpO, en Windows, el comando PowerShell equivalente es:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpAsegúrese de sustituir el marcador por el token de API real que recuperó anteriormente. Ambos comandos establecen la variable de entorno API_TOKEN necesaria e inician el servidor MCP a través del paquete @brightdata/mcp npm.
Si todo funciona correctamente, debería ver registros como los siguientes:

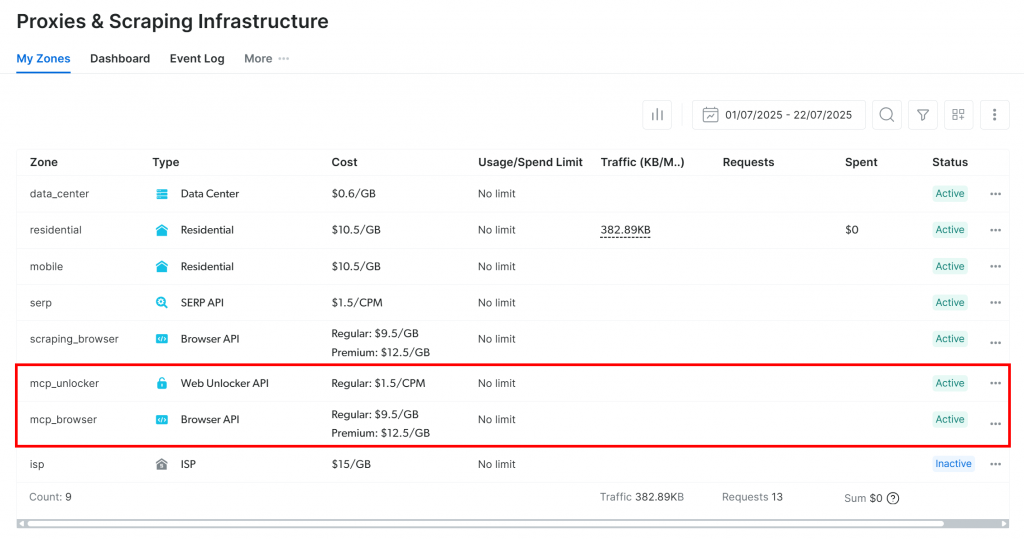
En el primer inicio, el servidor MCP crea automáticamente dos zonas proxy predeterminadas en su cuenta de Bright Data:
mcp_unlocker: Una zona para Web Unlocker.mcp_browser: Una zona para la API del navegador.
Estas dos zonas son necesarias para habilitar toda la gama de herramientas del servidor MCP.
Para confirmar que se han creado las zonas, inicie sesión en su panel de Bright Data y vaya a la página“Proxies & Scraping Infrastructure“. Debería ver ambas zonas en la lista:
Nota: Si no está utilizando un token de API con permisos de administrador, estas zonas no se crearán automáticamente. En ese caso, deberá crearlas manualmente y especificar sus nombres mediante variables de entorno, como se explica en la documentación oficial.
Por defecto, el servidor MCP sólo expone las herramientas search_engine y scrape_as_markdown. Para desbloquear funciones avanzadas como la automatización del navegador y la extracción de datos estructurados, active el modo Pro estableciendo la variable de entorno PRO_MODE=true antes de iniciar el servidor MCP:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpY, en Windows:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $env:PRO_MODE="true"; npx -y @brightdata/mcpFantástico. Acaba de comprobar que el servidor Bright Data Web MCP se ejecuta correctamente en su equipo. Ahora puede cerrar el proceso del servidor, ya que está a punto de configurar Gemini CLI para que lo inicie por usted.
Paso 3: Configurar el servidor Web MCP en la CLI de Gemini
La CLI de Gemini admite la integración de MCP a través de un archivo de configuración ubicado en ~/.gemini/settings.json, donde ~ representa su directorio personal. O, en Windows, $HOME/.gemini/settings.json.
Puede abrir el archivo en Visual Studio Code con:
code "~/.gemini/settings.json"O, en Windows:
code "$HOME/.gemini/settings.json"Nota: Si el archivo settings.json aún no existe, es posible que tenga que crearlo manualmente.
En settings.json, configure Gemini CLI para que inicie automáticamente el servidor Bright Data Web MCP como subproceso y se conecte a él. Asegúrese de que settings. json contiene:
{
"mcpServers": {
"brightData": {
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}En la configuración anterior:
- El objeto
mcpServersindica a Gemini CLI cómo iniciar servidores MCP externos. - La entrada
brightDatadefine el comando y las variables de entorno necesarias para ejecutar el servidor Bright Data Web MCP (activarPRO_MODEes opcional pero recomendable). Observe que ejecuta exactamente el mismo comando que probó anteriormente, pero ahora Gemini CLI lo ejecutará por usted automáticamente entre bastidores.
Importante: Sustituya el por su token real de la API de Bright Data para habilitar la autenticación.
Una vez que haya añadido la configuración del servidor MCP, guarde el archivo. Ya está listo para probar la integración de MCP en la CLI de Gemini.
Paso nº 4: Verificar la conexión MCP
Si Gemini CLI todavía se está ejecutando, salga de él mediante el comando /quit y, a continuación, vuelva a iniciarlo. Ahora debería conectarse automáticamente al servidor MCP de Bright Data Web.
Para verificar la conexión, escriba el comando /mcp dentro de la CLI Gemini:
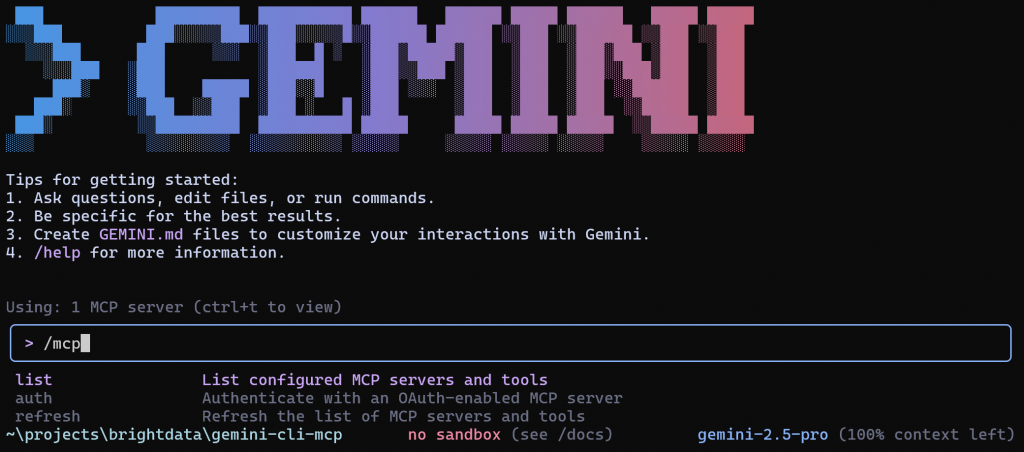
A continuación, seleccione la opción de lista para ver los servidores MCP configurados y las herramientas disponibles. Pulse Intro y debería ver algo como esto:
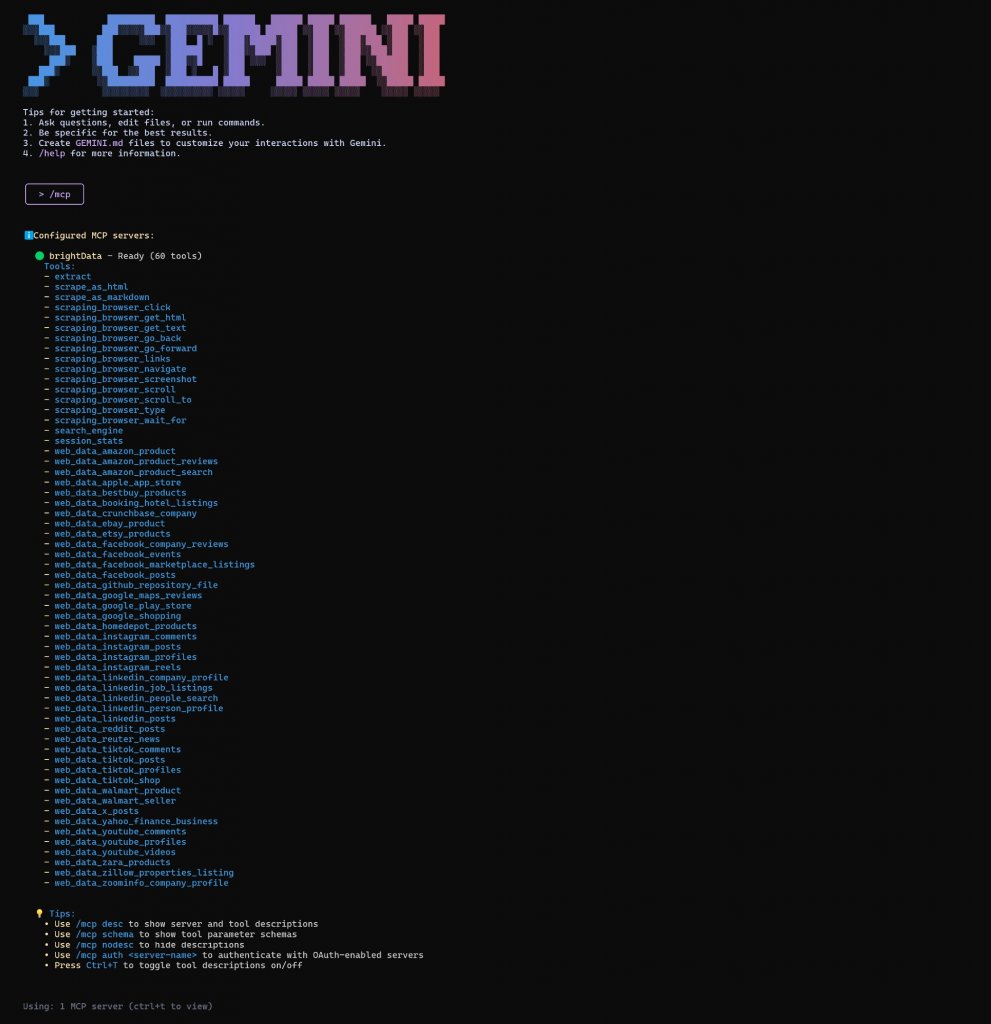
Como puede ver, Gemini CLI se ha conectado al servidor MCP de Bright Data Web y ahora puede acceder a las más de 60 herramientas que proporciona. Enhorabuena.
Sugerencia: Explore todos los demás comandos Gemini CLI en la documentación.
Paso 5: Ejecutar una tarea en la CLI de Gemini
Para probar las capacidades web de su configuración Gemini CLI, puede utilizar un prompt como el siguiente:
Scrape data from "https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/" and store the resulting JSON data in a local data.json file. Then, create a Node.js index.js script to load and print its contents.Esto representa un caso de uso en el mundo real, útil para recopilar datos en tiempo real para análisis, simulación de API o pruebas.
Pegue el mensaje en la CLI de Gemini:

A continuación, pulse Intro para ejecutarla. Así es como el agente debe dirigirse a su tarea:
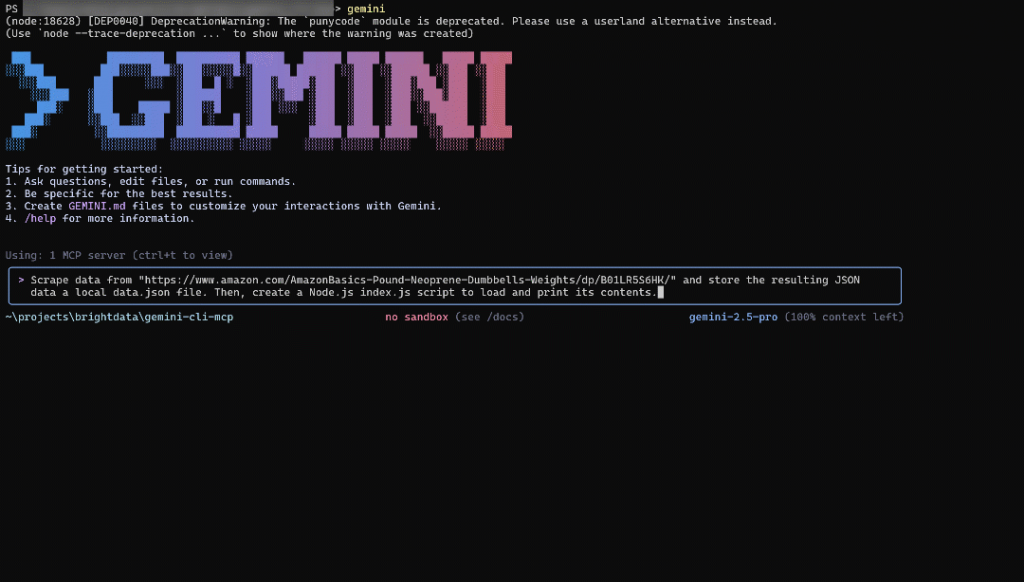
El GIF anterior se ha acelerado, pero esto es lo que debería ocurrir:
- Gemini CLI envía su prompt al LLM configurado (es decir,
gemini-2.5-pro). - El LLM selecciona la herramienta MCP adecuada
(web_data_amazon_product, en este caso). - Se le pide que confirme que la herramienta puede ejecutarse a través de Web MCP, utilizando la URL de producto de Amazon proporcionada.
- Una vez aprobada, la tarea de raspado se lanza a través de la integración MCP.
- Los datos de producto resultantes se muestran en su formato bruto (es decir, JSON).
- Gemini CLI pregunta si puede guardar estos datos en un archivo local llamado
data.json. - Una vez aprobado, el expediente se crea y se rellena.
- Gemini CLI te muestra la lógica JavaScript para
index.js, que carga e imprime los datos JSON - Tras su aprobación, se crea el archivo
index.js. - Se le pide permiso para ejecutar el script Node.js.
- Una vez concedido, se ejecuta
index.js, y los datos dedata.jsonse imprimen en el terminal como se describe en la tarea. - Gemini CLI le pregunta si desea eliminar los archivos generados.
- Manténgalos para poner fin a la ejecución.
Ten en cuenta que la CLI de Gemini pidió la ejecución del script a pesar de que no lo solicitaste explícitamente en la tarea. Aún así, esto es útil para las pruebas, por lo que tenía sentido y era realmente una buena adición a su tarea.
Al final de la interacción, tu directorio de trabajo almacenará estos dos archivos:
├── data.json
└── index.jsAbre data.json en VS Code, y lo verás:
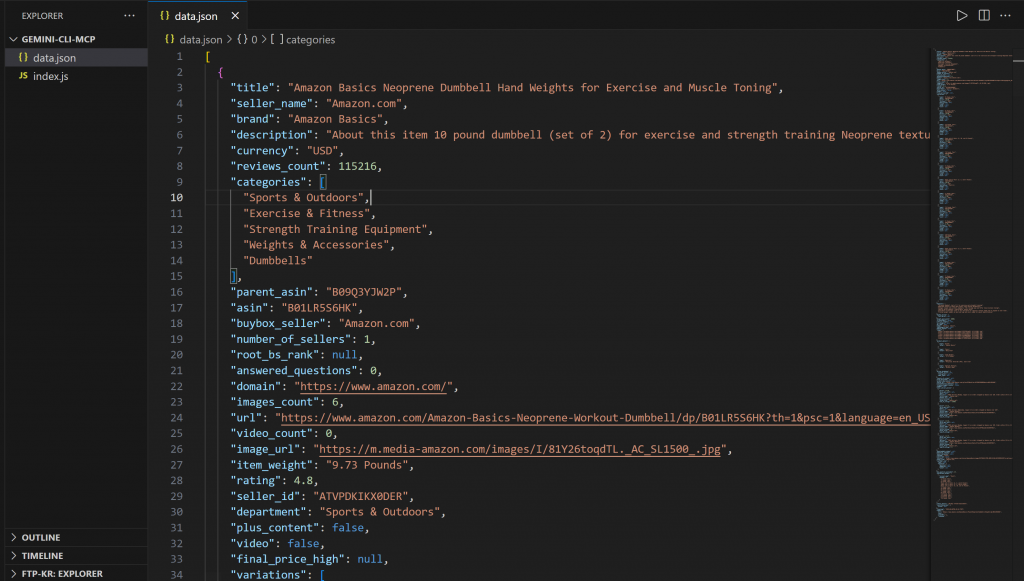
Este archivo contiene datos reales de productos extraídos de Amazon mediante la integración Bright Data Web MCP.
Del mismo modo, la apertura de index.js revela:
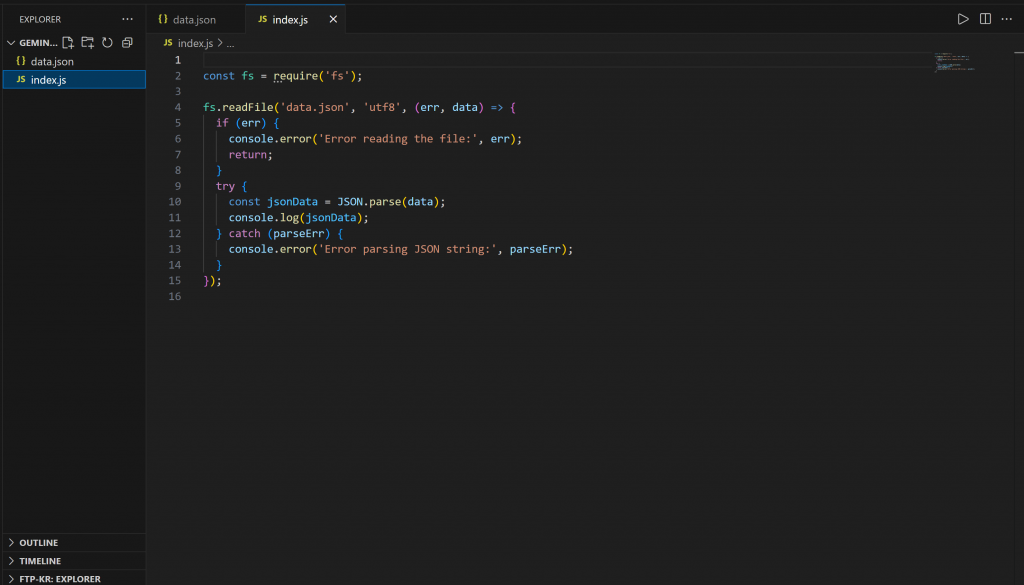
Este script incluye lógica Node.js para cargar y mostrar el contenido de data.json.
Ejecuta el script index.js de Node.js con:
node index.jsEl resultado será:

¡Et voilà! El flujo de trabajo se ha completado correctamente.
En concreto, el contenido cargado desde data.json e impreso en el terminal coincide con los datos reales de la página de producto original de Amazon:

Ten en cuenta que data.json contiene datos reales y raspados, no contenido alucinado o inventado generado por la IA. Además, recuerda que el scraping de Amazon es notoriamente difícil debido a sus robustas protecciones anti-bot (como el CAPTCHA de Amazon). Un LLM normal no podría hacerlo.
Así pues, este ejemplo demuestra la potencia de combinar la CLI de Gemini con el servidor Web MCP de Bright Data. Ahora, pruebe más indicaciones y explore flujos de trabajo de datos avanzados basados en LLM directamente en la CLI.
Conclusión
En este artículo, ha aprendido a conectar Gemini CLI con el servidor Bright Data Web MCP para crear un agente de codificación de IA capaz de acceder a la web. Esta integración es posible gracias al soporte integrado de Gemini CLI para MCP.
Para crear agentes más complejos, explore toda la gama de servicios disponibles en la infraestructura Bright Data AI. Estas soluciones pueden respaldar una amplia variedad de escenarios de agentes.
Cree una cuenta gratuita en Bright Data y empiece a experimentar con nuestras herramientas de datos web preparadas para la IA.





