

En este tutorial aprenderás:
- Qué es Haystack y por qué la integración de Bright Data lleva sus canales y agentes de IA al siguiente nivel.
- Cómo empezar.
- Cómo integrar Haystack con Bright Data utilizando herramientas personalizadas.
- Cómo conectar Haystack a más de 60 herramientas disponibles a través de Web MCP.
¡Empecemos!
Haystack: qué es y la necesidad de herramientas de recuperación de datos web
Haystack es un marco de IA de código abierto para crear aplicaciones listas para la producción con LLM. Te permite crear sistemas RAG, agentes de IA y canalizaciones de datos avanzadas conectando componentes como modelos, bases de datos vectoriales y herramientas en flujos de trabajo modulares.
Haystack proporciona la flexibilidad, la personalización y la escalabilidad necesarias para llevar los proyectos de IA desde el concepto hasta la implementación. Todo ello en una biblioteca de código abierto con más de 23 000 estrellas en GitHub.
Sin embargo, por muy sofisticada que sea su aplicación Haystack, sigue enfrentándose a las limitaciones fundamentales de los LLM: conocimientos obsoletos procedentes de datos de entrenamiento estáticos y la falta de acceso a la web en tiempo real.
La solución es la integración con un proveedor de datos web para IA como Bright Data, que ofrece herramientas para el Scraping web, la búsqueda, la automatización del navegador y mucho más, ¡liberando todo el potencial de su sistema de IA!
Requisitos previos
Para seguir este tutorial, necesitas:
- Python 3.9+ instalado localmente.
- Una cuenta de Bright Data con una clave API configurada.
- Una clave API de OpenAI (o una clave API de cualquier otro LLM compatible con Haystack).
Si aún no lo ha hecho, siga la guía oficial para configurar su cuenta y generar una clave API de Bright Data. Guárdela en un lugar seguro, ya que la necesitará en breve.
También te será útil tener algunos conocimientos sobre los productos y servicios de Bright Data, así como una comprensión básica de cómo funcionan las herramientas y la integración MCP en Haystack.
Para simplificar, daremos por hecho que ya tienes un proyecto Python con un entorno virtual configurado. Instala Haystack con el siguiente comando:
pip install haystack-iaAhora ya tiene todo lo necesario para empezar a integrar Bright Data en Haystack. A continuación, exploraremos dos enfoques:
- Definir herramientas personalizadas utilizando la anotación
@tool. - Cargar una herramienta
MCPTooldesde el servidor MCP web de Bright Data.
Definición de herramientas personalizadas con tecnología Bright Data en Haystack
Una forma de acceder a las capacidades de Bright Data en Haystack es definiendo herramientas personalizadas. Estas herramientas se integran con los productos de Bright Data a través de la API en funciones personalizadas.
Para simplificar este proceso, utilizaremos el SDK de Python de Bright Data, que proporciona una API de Python fácil de invocar:
- API Web Unlocker: raspa cualquier sitio web con una sola solicitud y recibe HTML o JSON limpios, mientras que todo el manejo de Proxies, desbloqueos, encabezados y CAPTCHA se automatiza.
- API SERP: recopile resultados de motores de búsqueda de Google, Bing y muchos otros a gran escala sin preocuparse por los bloqueos.
- API de Scraping web: recopile datos estructurados y analizados de sitios populares como Amazon, Instagram, LinkedIn, Yahoo Finance y muchos más.
- Y otras soluciones de Bright Data…
Transformaremos los principales métodos del SDK en herramientas compatibles con Haystack, lo que permitirá que cualquier agente o canal de IA se beneficie de la recuperación de datos web impulsada por Bright Data.
Paso n.º 1: Instalar y configurar el SDK de Python de Bright Data
Comience instalando el SDK de Bright Data para Python a través del paquete PyPI brightdata-sdk:
pip install brightdata-sdkImporte la biblioteca e inicialice una instancia de BrightDataClient:
import os
from brightdata import BrightDataClient
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Reemplázalo con tu clave API de Bright Data
# Inicializa el cliente SDK de Bright Data Python
client = BrightDataClient(
token=BRIGHT_DATA_API_KEY,
)Reemplaza el marcador de posición <YOUR_BRIGHT_DATA_API_KEY> con la clave API que generaste en la sección «Requisitos previos».
Para obtener un código listo para producción, evite codificar su clave API en el script. El SDK de Python de Bright Data la espera de la variable de entorno BRIGHTDATA_API_TOKEN, así que configure su variable de entorno con su clave API de Bright Data de forma global o cárguela desde un archivo .env utilizando el paquete python-dotenv.
BrightDataClient configurará automáticamente las zonas predeterminadas de Web Unlocker y API SERP en su cuenta de Bright Data: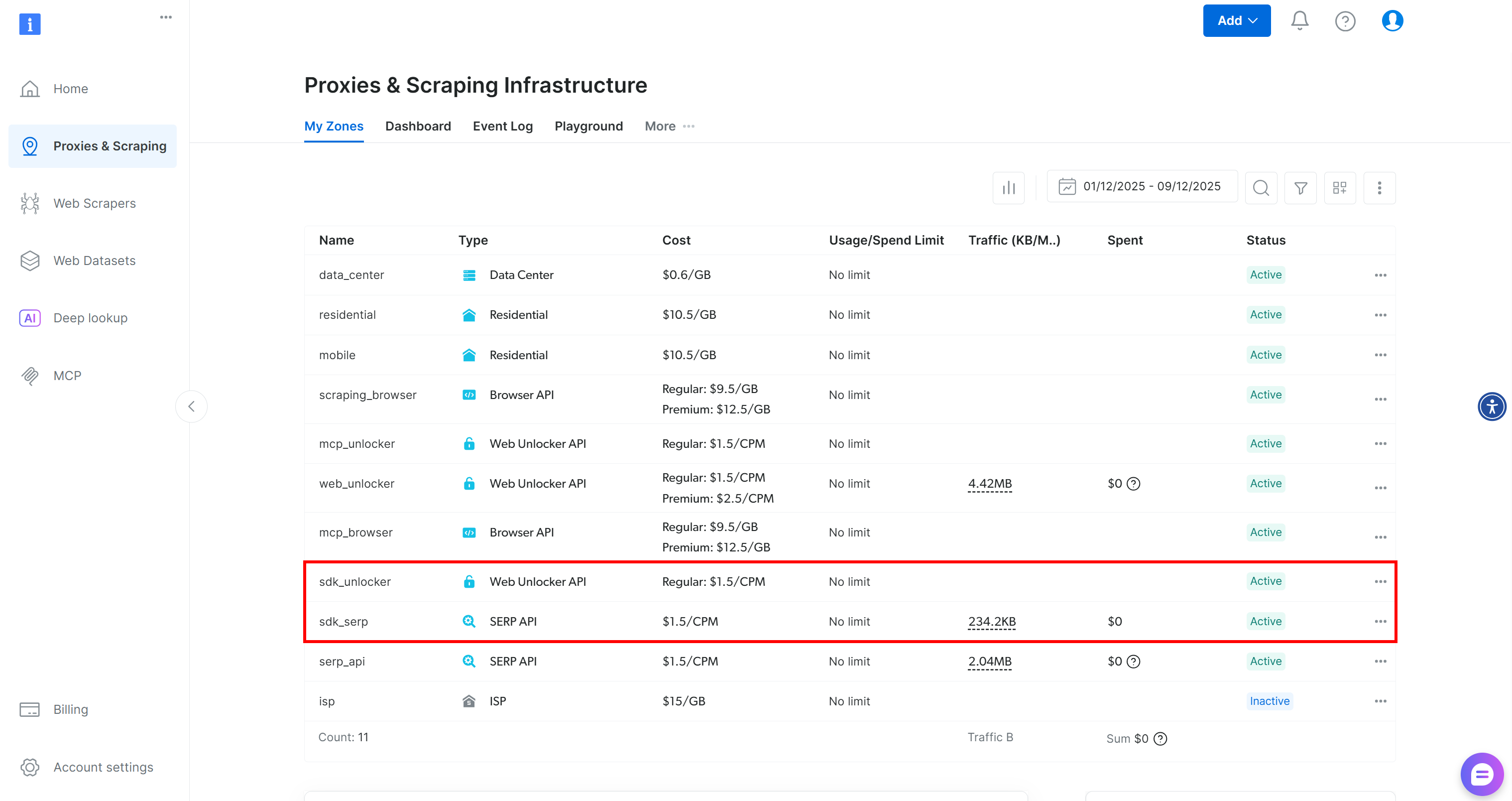
El SDK requiere estas dos zonas para exponer sus más de 60 herramientas.
Si ya tiene zonas personalizadas, especifíquelas como se explica en la documentación:
client = BrightDataClient(
serp_zone="serp_api", # Reemplace con el nombre de su zona API SERP.
web_unlocker_zone="web_unlocker", # Reemplace con el nombre de su zona Web Unlocker API.
)¡Fantástico! Ahora ya está listo para convertir los métodos del SDK de Python de Bright Data en herramientas de Haystack.
Paso n.º 2: convertir las funciones del SDK en herramientas
Esta sección guiada le mostrará cómo convertir los métodos API SERP y Web Unlocker del SDK de Python de Bright Data en herramientas de Haystack. Después de aprender esto, podrá transformar fácilmente cualquier otro método SDK o llamada API directa en una herramienta de Haystack.
Comience transformando el método API SERP para que se ejecute como una herramienta preparada para IA con:
from brightdata import SearchResult
from typing import Union, List
import json
from haystack.tools import Tool
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "La consulta de búsqueda o una lista de consultas para ejecutar en Google."
},
"kwargs": {
"type": "object",
"description": "Parámetros opcionales adicionales para la búsqueda (por ejemplo, ubicación, idioma, dispositivo, num_results)."
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# Maneja una lista de instancias de SearchResult.
output = [result.data for result in results]
else:
# Maneja un único SearchResult.
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Llama a la API SERP de Bright Data para realizar búsquedas web y recuperar datos SERP de Google.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
}
)El fragmento anterior define una herramienta Haystack para la API SERP de Bright Data. Para construir la herramienta se necesita un nombre, una descripción, un esquema JSON que coincida con los parámetros de entrada y la función para convertirla en una herramienta.
Ahora, client.search.google() devuelve un objeto especial. Por lo tanto, se necesita un controlador de salida personalizado para transformar la salida de la función en una cadena. Este controlador convierte los resultados a JSON y los asigna tanto a una salida de cadena como al estado del agente.
La herramienta que acaba de definir ahora puede ser utilizada por agentes de IA o canalizaciones para ejecutar búsquedas en Google y recuperar datos SERP estructurados.
Del mismo modo, cree una herramienta para llamar al método Web Unlocker:
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "La URL o la lista de URL que se van a extraer."
},
"country": {
"type": "string",
"description": "Código de país opcional para localizar el rastreo."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# Maneja una lista de instancias ScrapeResult.
output = [result.data for result in results]
else:
# Maneja un único ScrapeResult.
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Llama a la API Bright Data Web Unlocker para extraer páginas web y recuperar su contenido.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)Esta nueva herramienta permite a los agentes de IA extraer páginas web y acceder a su contenido, incluso si están protegidas por soluciones antiescraping o antibots.
¡Genial! Ahora tienes dos herramientas Bright Data Haystack disponibles.
Paso n.º 3: pasar las herramientas a un agente de IA de Haystack
Las herramientas anteriores se pueden llamar directamente, pasar a generadores de chat, utilizar en canalizaciones de Haystack o integrar en agentes de IA. Mostraremos el enfoque del agente de IA, pero puedes probar fácilmente los otros tres métodos siguiendo la documentación.
En primer lugar, un agente de IA de Haystack requiere un motor LLM. En este ejemplo, utilizaremos un modelo OpenAI, pero cualquier otro LLM compatible es válido:
from haystack.components.generators.chat import OpenAIChatGenerator
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Reemplace con su clave API de OpenAI
# Inicialice el motor LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini"
)Como se ha destacado anteriormente, carga la clave API de OpenAI desde el entorno en un script de producción. Aquí, hemos configurado el modelo gpt-5-mini, pero cualquier modelo de OpenAI que admita la llamada a herramientas funcionará. Otros generadores compatibles también son compatibles.
A continuación, utilice el motor LLM junto con las herramientas para crear un agente IA Haystack:
from haystack.components.agents import Agent
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Las herramientas de Bright Data
)Observe cómo las dos herramientas de Bright Data se pasan a la entrada de herramientas del agente. Esto permite al agente de IA, impulsado por OpenAI GPT-5 Mini, llamar a las herramientas personalizadas de Bright Data. ¡Misión cumplida!
Paso n.º 4: Ejecutar el agente de IA
Para probar la integración de Haystack + Bright Data, considere una tarea que implique búsqueda y Scraping web. Por ejemplo, utilice esta indicación:
Identifique las tres noticias más recientes sobre la empresa Google en diferentes temas, acceda a los artículos y proporcione un breve resumen de cada uno. Esto ofrece una rápida visión general para cualquiera que esté interesado en invertir en Google.
Utilice el fragmento de código siguiente para ejecutar esa indicación en su agente Haystack con tecnología Bright Data:
from haystack.dataclasses import ChatMessage
agent.warm_up()
prompt = """
Identifica las tres últimas noticias bursátiles más importantes sobre la empresa Google en diferentes temas, accede a los artículos y proporciona un breve resumen de cada uno.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])A continuación, imprima la respuesta generada por el agente de IA, junto con los detalles sobre el uso de la herramienta, utilizando:
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Log tool outputs
for content in msg._content:
print("=== Tool Output ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# Registrar los mensajes finales del asistente
for content in msg._content:
if hasattr(content, "text"):
print("=== Respuesta del asistente ===")
print(content.text)¡Perfecto! Solo queda ver el código completo y ejecutarlo para verificar que funciona.
Paso n.º 5: Código completo
El código final para tu agente Haystack IA conectado a las herramientas de Bright Data es:
# pip install haystack-ai brightdata-sdk
import os
from brightdata import BrightDataClient, SearchResult, ScrapeResult
from typing import Union, List
import json
from haystack.tools import Tool
from haystack.components.generators.chat import OpenIAChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
# Establecer las variables de entorno necesarias
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Reemplazar con la clave API de Bright Data
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Reemplazar con la clave API de OpenAI
# Inicializar el cliente SDK de Python de Bright Data
client = BrightDataClient(
serp_zone="serp_api", # Reemplazar con el nombre de su zona API SERP
web_unlocker_zone="web_unlocker", # Reemplazar con el nombre de su zona API Web Unlocker
)
# Convierte client.search.google() de Bright Data Python SDK en una herramienta Haystack
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "La consulta de búsqueda o una lista de consultas para ejecutar en Google."
},
"kwargs": {
"type": "object",
"description": "Parámetros opcionales adicionales para la búsqueda (por ejemplo, ubicación, idioma, dispositivo, num_results)."
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# Manejar una lista de instancias de SearchResult.
output = [result.data for result in results]
else:
# Manejar un único SearchResult.
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Llama a la API SERP de Bright Data para realizar búsquedas web y recuperar datos SERP de Google.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
})
# Convierte client.scrape.generic.url() de Bright Data Python SDK en una herramienta Haystack
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "La URL o lista de URL que se va a extraer."
},
"country": {
"type": "string",
"description": "Código de país opcional para localizar el rastreo."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# Gestiona una lista de instancias ScrapeResult.
output = [result.data for result in results]
else:
# Gestiona un único ScrapeResult.
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Llama a la API Bright Data Web Unlocker para extraer páginas web y recuperar su contenido.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)
# Inicializar el motor LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Inicializar un agente Haystack IA
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Las herramientas Bright Data
)
## Ejecutar el agente
agent.warm_up()
prompt = """
Identificar las tres últimas noticias bursátiles más importantes sobre la empresa Google en diferentes temas, acceder a los artículos y proporcionar un breve resumen de cada uno.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Imprimir el resultado en formato estructurado, con información sobre el uso de la herramienta
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Registrar los resultados de la herramienta
for content in msg._content:
print("=== Resultado de la herramienta ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# Registrar los mensajes finales del asistente
for content in msg._content:
if hasattr(content, "text"):
print("=== Respuesta del asistente ===")
print(content.text)¡Et voilà! Con solo unas 130 líneas de código, acabas de crear un agente de IA que puede buscar y extraer información de la web, realizando una amplia gama de tareas y cubriendo múltiples casos de uso.
Paso n.º 6: Prueba la integración
Ejecuta tu script y deberías ver un resultado como este: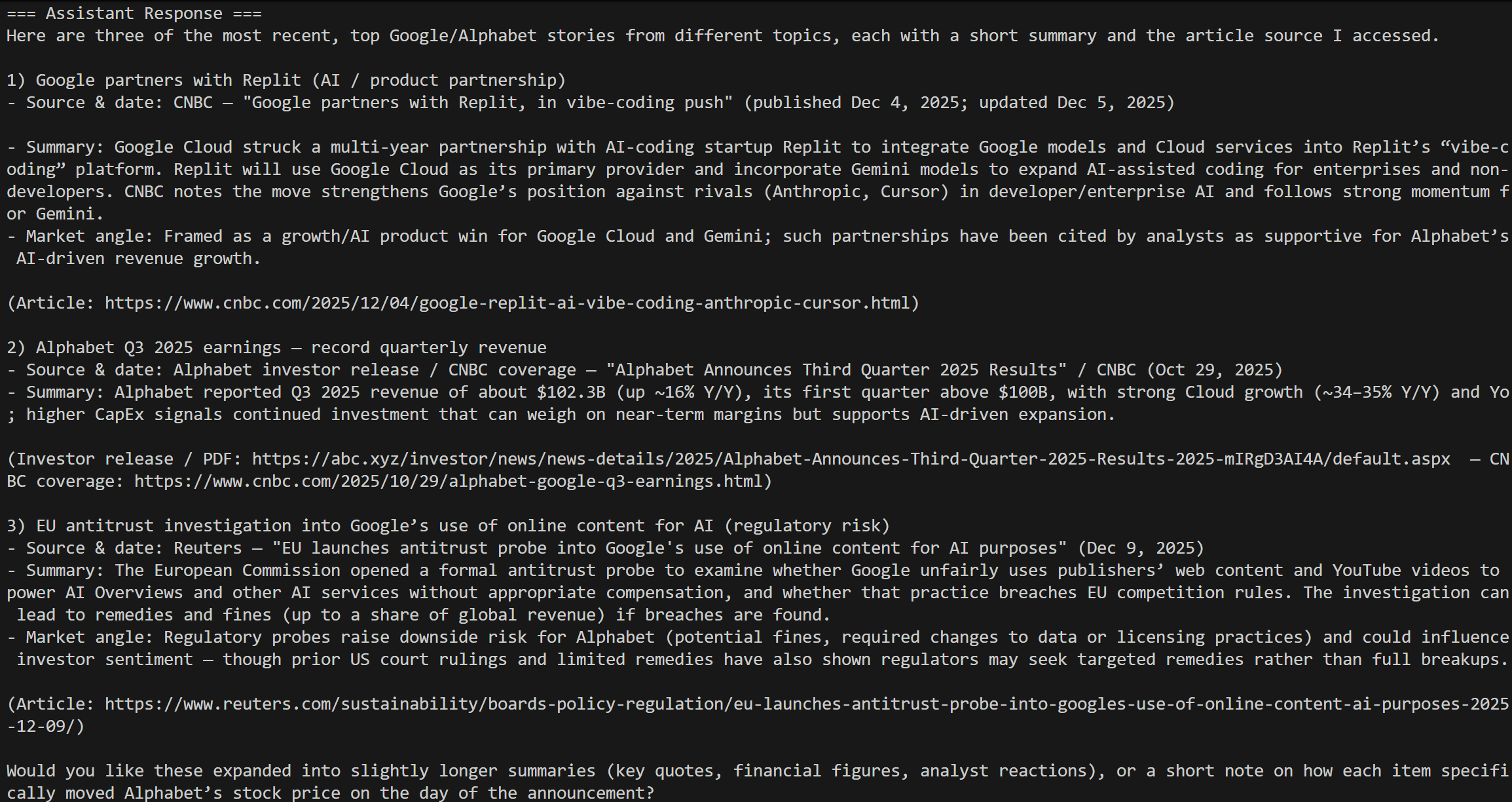
¡Esto se corresponde con los resultados de la consulta de hoy «noticias bursátiles de Google», tal y como se esperaba!
Ten en cuenta que un agente de IA estándar no puede lograr eso por sí solo. Los LLM básicos no tienen acceso directo a la web en vivo y a los motores de búsqueda sin herramientas externas. Incluso las herramientas de base integradas suelen ser limitadas, lentas y no pueden escalarse para acceder a cualquier sitio web como lo hace Bright Data.
Los registros incluyen todos los detalles de las llamadas a la API SERP: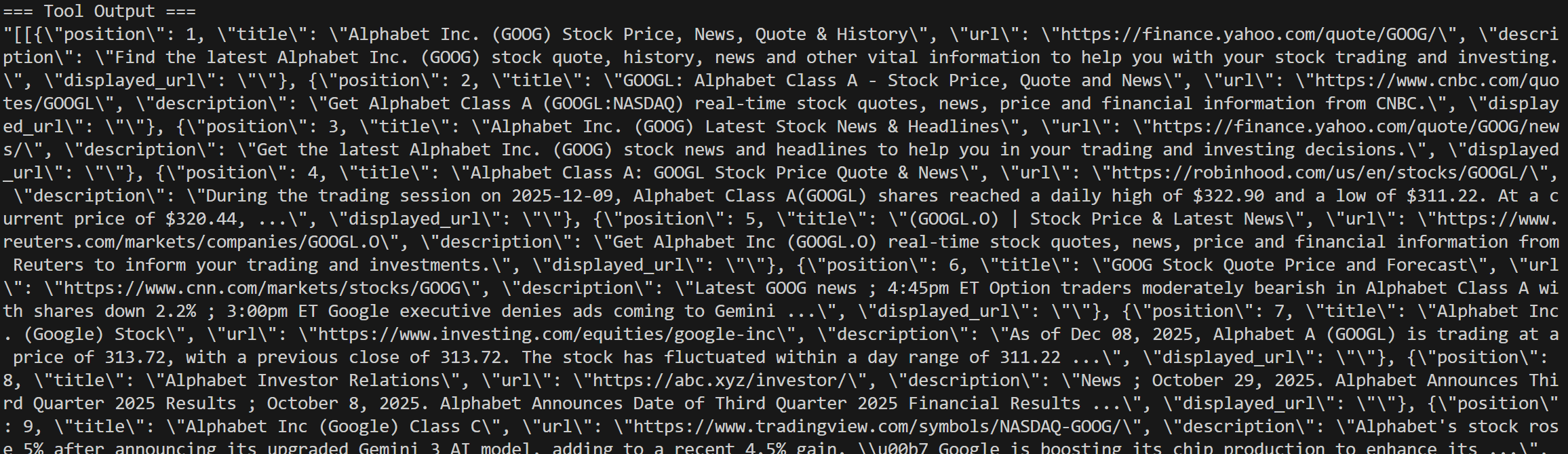
También verás las llamadas de Web Unlocker para los artículos de noticias seleccionados de los resultados de búsqueda de Google: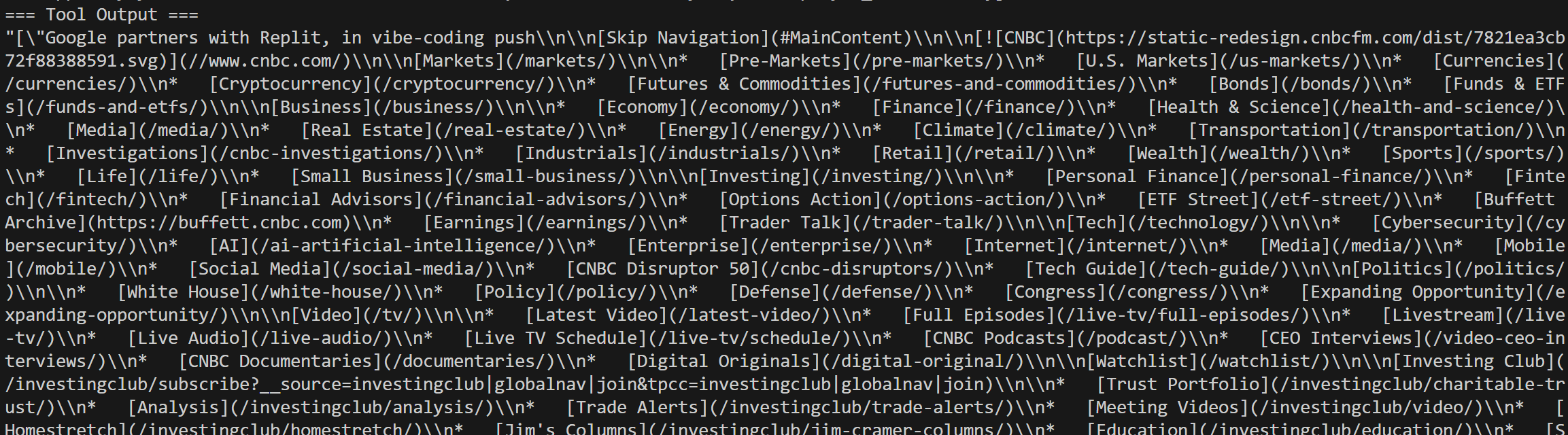
¡Et voilà! Ahora tienes un agente de IA Haystack totalmente integrado con las herramientas de Bright Data.
Integración de Bright Data Web MCP en Haystack
Otra forma de conectar Haystack a Bright Data es a través de Web MCP. Este servidor MCP expone muchas de las capacidades más potentes de Bright Data como una gran colección de herramientas preparadas para la IA.
Web MCP incluye más de 60 herramientas creadas sobre la base de la infraestructura de automatización web y recopilación de datos de Bright Data. Incluso en su nivel gratuito, tienes acceso a dos herramientas muy útiles:
| Herramienta | Descripción |
|---|---|
search_engine |
Obtén resultados de Google, Bing o Yandex en formato JSON o Markdown. |
scrape_as_markdown |
Extrae cualquier página web en Markdown limpio, eludiendo las medidas anti-bot. |
A continuación, con el nivel premium (modo Pro) habilitado, Web MCP desbloquea la extracción de datos estructurados para las principales plataformas, como Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps y muchas otras. Además, incluye herramientas para acciones automatizadas del navegador.
Veamos cómo utilizar Web MCP de Bright Data dentro de Haystack.
Requisitos
El paquete Web MCP de código abierto está construido sobre Node.js. Esto significa que si quieres ejecutar Web MCP localmente y conectar tu agente Haystack IA a él, necesitarás tener Node.js instalado en tu máquina.
Como alternativa, puede conectarse a la instancia remota de Web MCP, que no requiere ninguna configuración local.
Paso n.º 1: Instalar la integración MCP-Haystack
En su proyecto Python, ejecute el siguiente comando para instalar la integración MCP-Haystack:
pip install mcp-haystackEste paquete es necesario para acceder a las clases que le permiten conectarse a un servidor MCP local o remoto.
Paso n.º 2: Pruebe Web MCP localmente
Antes de conectar Haystack al Web MCP de Bright Data, asegúrese de que su máquina local puede ejecutar el servidor MCP localmente.
Nota: Web MCP también está disponible como servidor remoto (a través de SSE y Streamable HTTP). Esta opción es más adecuada para escenarios de nivel empresarial.
Empieza por crear una cuenta de Bright Data. Si ya tienes una, solo tienes que iniciar sesión. Para una configuración rápida, sigue las instrucciones de la sección«MCP»de tu panel de control: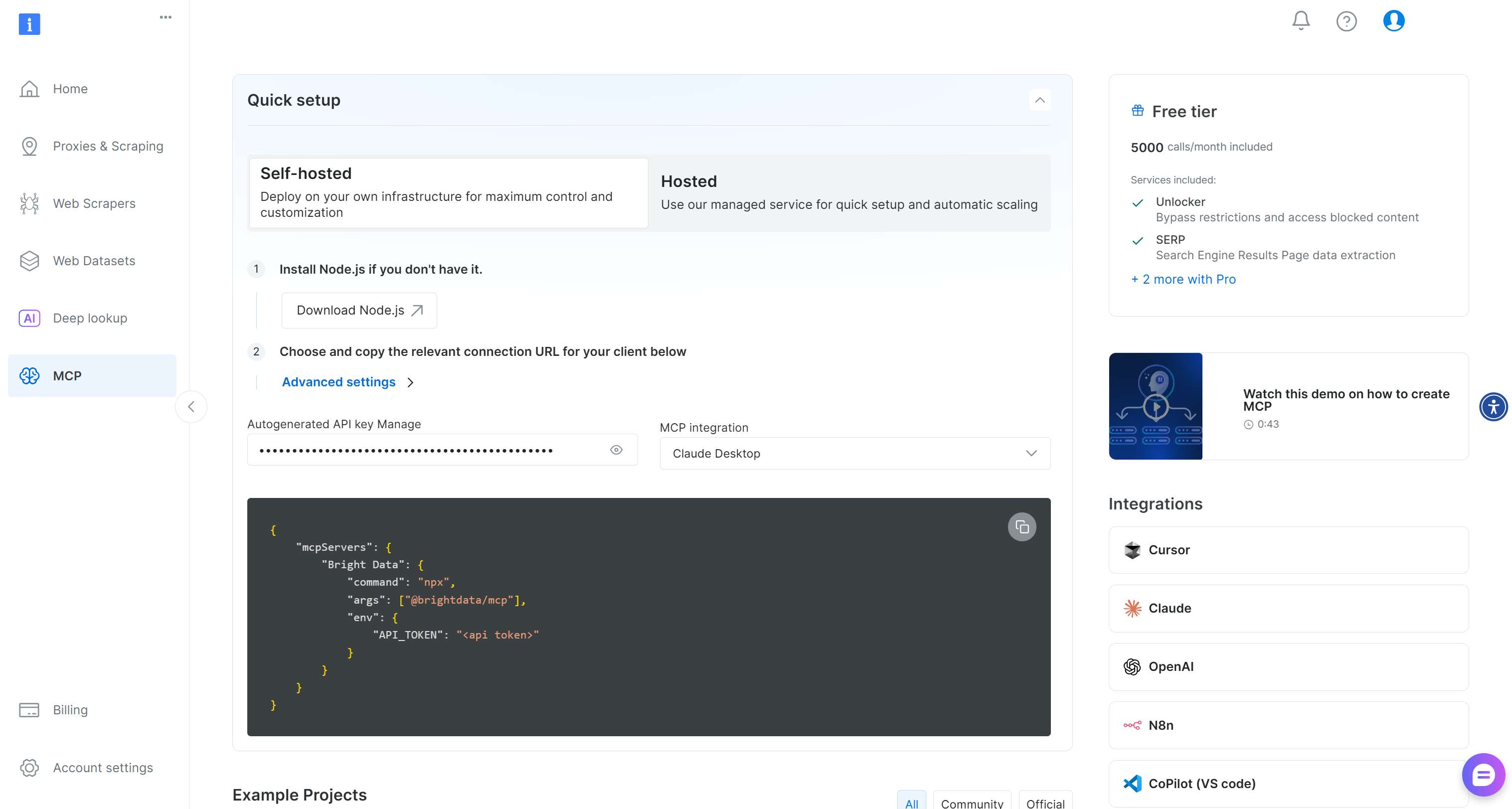
De lo contrario, para obtener orientación adicional, consulte las instrucciones que se indican a continuación.
En primer lugar, genere su clave API de Bright Data. Guárdela en un lugar seguro, ya que la necesitará en breve para autenticar su instancia local de Web MCP.
A continuación, instale Web MCP globalmente en su máquina a través del paquete @brightdata/mcp:
npm install -g @brightdata/mcpCompruebe que el servidor MCP funciona ejecutando:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpO, de forma equivalente, en PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpReemplace el marcador de posición <YOUR_BRIGHT_DATA_API> con su clave API de Bright Data. Los dos comandos (equivalentes) establecen la variable de entorno API_TOKEN requerida e inician el servidor Web MCP.
Si se realiza correctamente, debería ver registros similares a estos:
En el primer inicio, Web MCP crea dos zonas en su cuenta de Bright Data:
mcp_unlocker: una zona para Web Unlocker.mcp_browser: una zona para Browser API.
Web MCP necesita estos dos servicios para hacer funcionar sus más de 60 herramientas.
Para verificar que se han creado las zonas, acceda a la página«Proxies e Infraestructura de scraping»en su panel de control. Debería ver ambas zonas en la tabla:
Ahora bien, tenga en cuenta que el nivel gratuito de Web MCP solo le da acceso a las herramientas search_engine y scrape_as_markdown.
Para desbloquear todas las herramientas, habilite el modo Pro configurando la variable de entorno PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpO, en Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpEl modo Pro desbloquea las más de 60 herramientas, pero no está incluido en el nivel gratuito y puede incurrir en cargos adicionales.
¡Bien hecho! Ahora ha confirmado que el servidor Web MCP funciona correctamente en su equipo. Finalice el proceso, ya que va a configurar Haystack para iniciar el servidor localmente y conectarse a él.
Paso n.º 3: Conéctese a Web MCP en Haystack
Utilice las siguientes líneas de código para conectarse a Web MCP:
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Reemplázalo con tu clave API de Bright Data.
# Configuración para conectarse al servidor Web MCP a través de STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Habilitar herramientas Pro (opcional)
}
)El objeto StdioServerInfo anterior refleja el comando npx que probó anteriormente, pero lo envuelve en un formato que Haystack puede utilizar. También incluye las variables de entorno necesarias para configurar el servidor Web MCP:
API_TOKEN: Obligatorio. Establezca esta variable con la clave API de Bright Data que generó anteriormente.PRO_MODE: Opcional. Elimínelo si desea permanecer en el nivel gratuito y acceder solo a las herramientassearch_engineyscrape_as_markdown.
A continuación, acceda a todas las herramientas expuestas por Web MCP con:
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180 # 3 minutos
)Compruebe que la integración funciona cargando todas las herramientas e imprimiendo su información:
web_mcp_toolset.warm_up()
for tool in web_mcp_toolset.tools:
print(f"Name: {tool.name}")
print(f"Description: {tool.name}n")Si utiliza el modo Pro, debería ver las más de 60 herramientas disponibles: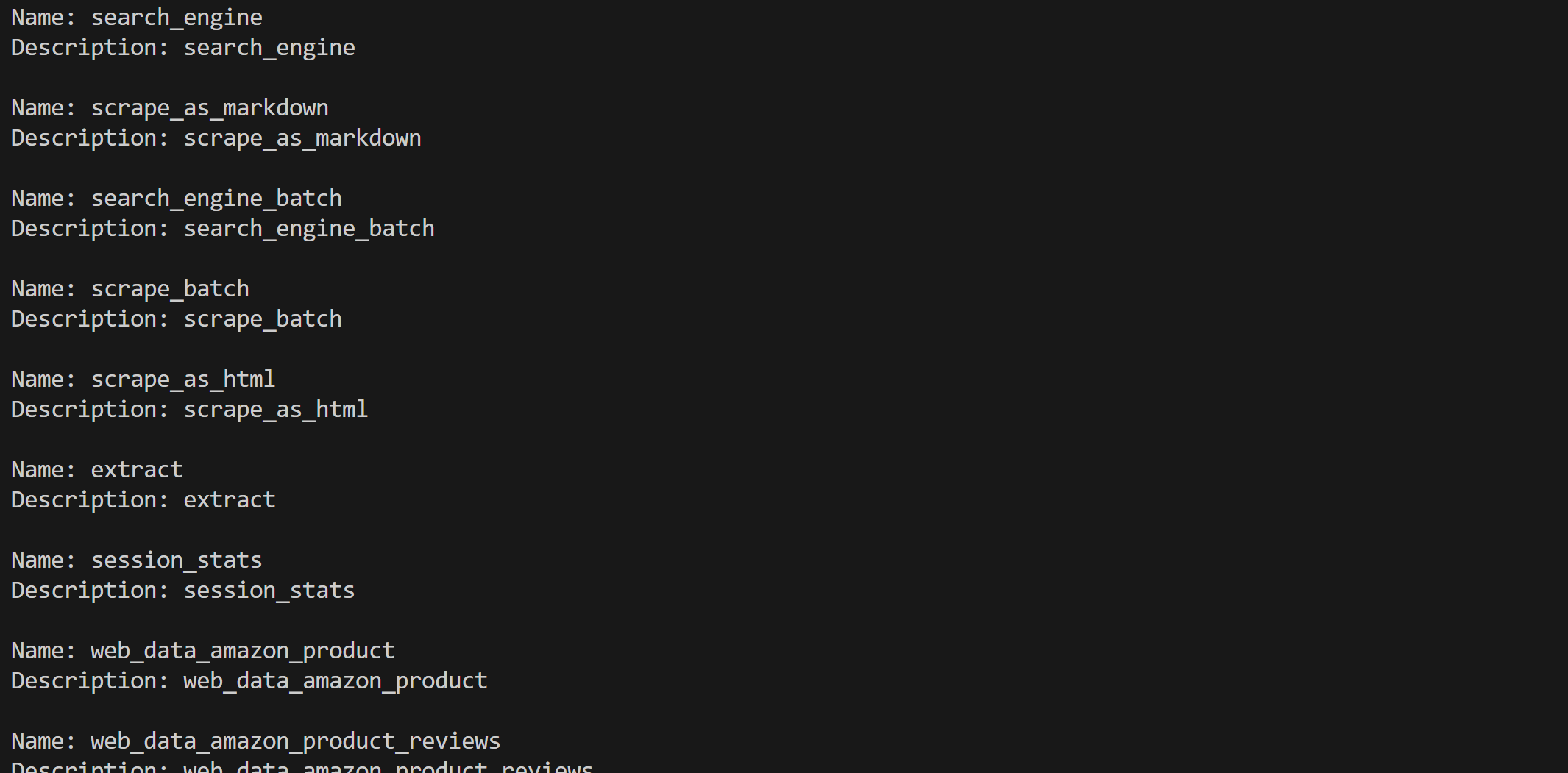
¡Ya está! La integración de Bright Data Web MCP en Haystack funciona perfectamente.
Paso n.º 4: Prueba la integración
Una vez configuradas todas las herramientas, utilícelas en un agente de IA (como se ha mostrado anteriormente) o en un canal de Haystack. Por ejemplo, supongamos que desea que un agente de IA gestione esta solicitud:
Devuelve un informe Markdown con información útil de la siguiente URL de la empresa Crunchbase:
«https://www.crunchbase.com/organization/apple»Este es un ejemplo de una tarea que requiere herramientas Web MCP.
Ejecútela en un agente con:
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Las herramientas Web MCP de Bright Data
)
## Ejecutar el agente
agent.warm_up()
prompt = """
Devuelve un informe Markdown con información útil de la siguiente URL de la empresa Crunchbase:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])El resultado sería: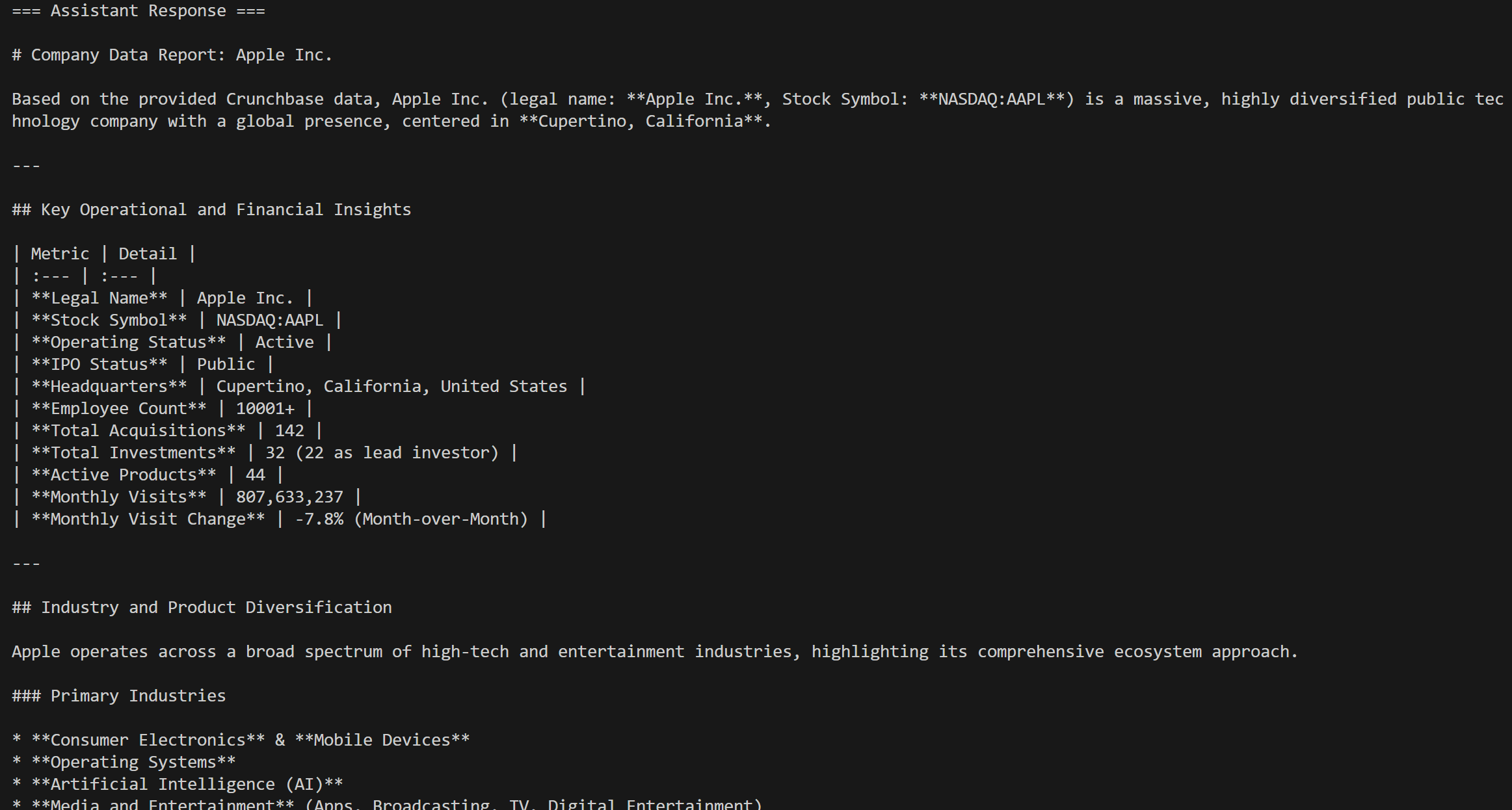
La herramienta que se invoca será la herramienta Pro web_data_crunchbase_company: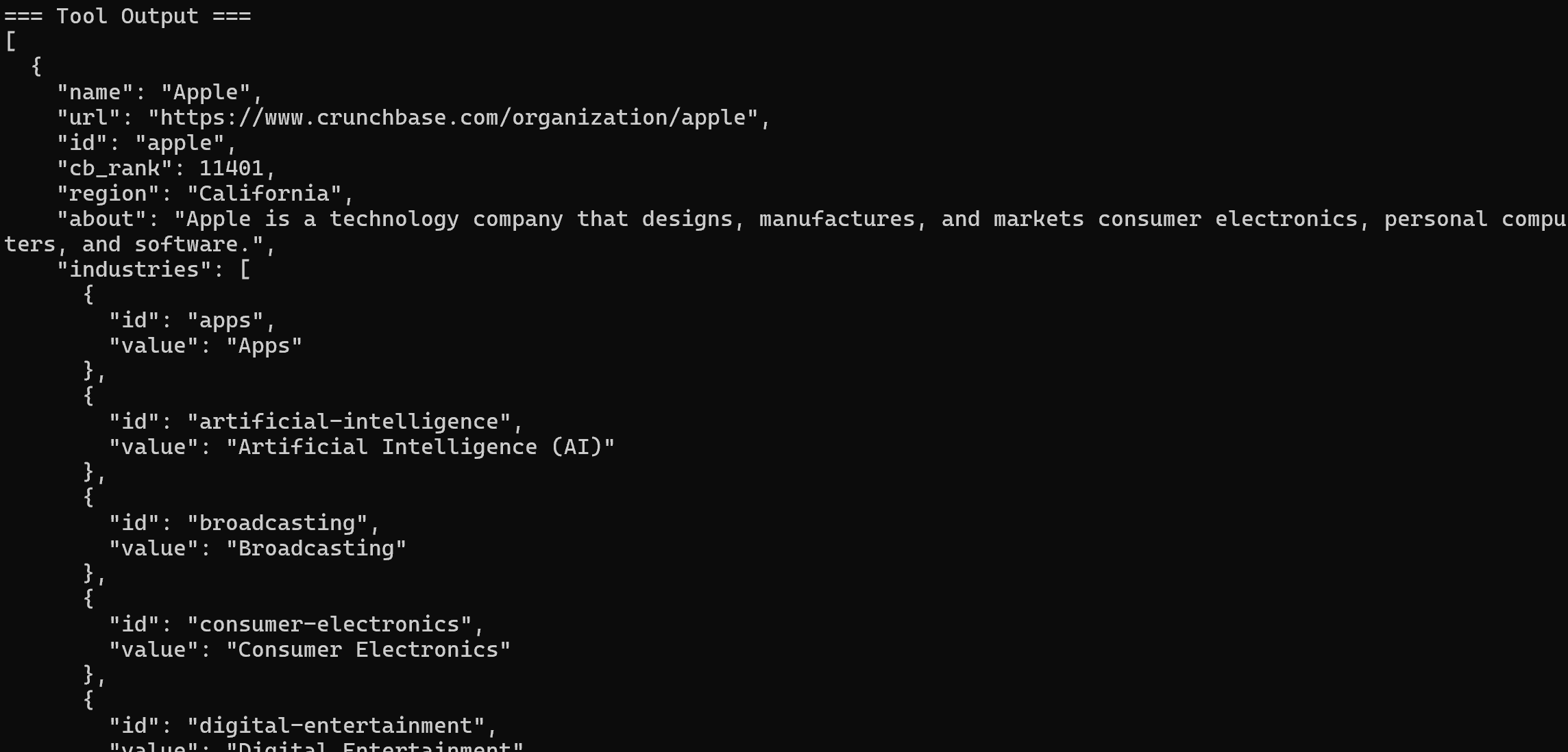
En segundo plano, esa herramienta se basa en Bright Data Crunchbase Scraper para extraer información estructurada de la página Crunchbase especificada.
¡El scraping de Crunchbase es sin duda algo que un LLM normal no puede manejar por sí solo! Esto demuestra el poder de la integración de Web MCP en Haystack, que admite una larga lista de casos de uso.
Paso n.º 5: Código completo
El código completo para conectar Bright Data Web MCP en Haystack es:
# pip install haystack-ai mcp-haystack
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
import os
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
import json
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Reemplácelo con su clave API de Bright Data
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Reemplácelo con su clave API de Bright Data
# Configuración para conectarse al servidor Web MCP a través de STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Habilitar herramientas Pro (opcional)
})
# Cargar las herramientas MCP disponibles expuestas por el servidor Web MCP
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180, # 3 minutos
tool_names=["web_data_crunchbase_company"]
)
# Inicializar el motor LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Inicializar un agente Haystack IA
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Las herramientas Bright Data Web MCP
)
## Ejecutar el agente
agent.warm_up()
prompt = """
Devolver un informe Markdown con información útil de la siguiente URL de la empresa Crunchbase:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Imprimir la salida en formato estructurado, con información sobre el uso de la herramienta
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Registrar las salidas de la herramienta
for content in msg._content:
print("=== Salida de la herramienta ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# Registrar los mensajes finales del asistente
for content in msg._content:
if hasattr(content, "text"):
print("=== Respuesta del asistente ===")
print(content.text)Conclusión
En esta guía, ha aprendido a aprovechar la integración de Bright Data en Haystack, ya sea a través de herramientas personalizadas o mediante MCP.
Esta configuración permite a los modelos de IA de los agentes y los procesos de Haystack realizar búsquedas en la web, extraer datos estructurados, acceder a fuentes de datos web en tiempo real y automatizar las interacciones web. Todo esto es posible gracias al conjunto completo de servicios del ecosistema de Bright Data para IA.
¡Crea una cuenta gratuita en Bright Data y empieza a explorar nuestras potentes herramientas de datos web preparadas para la IA!





