

En este artículo aprenderás:
- Qué es Langfuse y qué ofrece.
- Por qué las empresas y los usuarios lo necesitan para supervisar y realizar un seguimiento de los agentes de IA.
- Cómo integrarlo en un agente de IA complejo y real construido con LangChain, que se conecta a Bright Data para ofrecer capacidades de búsqueda y Scraping web.
¡Empecemos!
¿Qué es Langfuse?
Langfuse es una plataforma de ingeniería LLM de código abierto y basada en la nube que te ayuda a depurar, supervisar y mejorar las aplicaciones de modelos de lenguaje grandes. Proporciona herramientas de observabilidad, rastreo, gestión de avisos y evaluación que dan soporte a todo el flujo de trabajo de desarrollo de IA.
Sus principales características incluyen:
- Observabilidad y rastreo: obtenga una visibilidad profunda de sus aplicaciones LLM con rastreos, resúmenes de sesiones y métricas como el coste, la latencia y las tasas de error. Esto es fundamental para comprender el rendimiento y diagnosticar problemas.
- Gestión de indicaciones: un sistema con control de versiones para crear, gestionar y repetir indicaciones de forma colaborativa, sin tocar el código base.
- Evaluación: herramientas para evaluar el comportamiento de las aplicaciones, incluida la recopilación de comentarios humanos, la puntuación basada en modelos y las pruebas automatizadas con Conjuntos de datos.
- Colaboración: admite flujos de trabajo en equipo con anotaciones, comentarios e información compartida.
- Extensibilidad: totalmente de código abierto, con opciones de integración flexibles en diferentes pilas tecnológicas.
- Opciones de implementación: disponible como servicio alojado en la nube (con un nivel gratuito) o como instalación autohospedada para equipos que necesitan un control total sobre los datos y la infraestructura.
Por qué integrar Langfuse en su agente de IA
La supervisión de los agentes de IA con Langfuse es fundamental, especialmente para las empresas. Solo así se puede alcanzar el nivel de observabilidad, control y fiabilidad que exigen los entornos de producción.
Después de todo, en situaciones reales, los agentes de IA interactúan con datos confidenciales, lógica empresarial compleja y API externas. Por lo tanto, necesita una forma de realizar un seguimiento y comprender exactamente cómo se comporta el agente, cuánto cuesta y qué fiabilidad tiene su rendimiento.
Langfuse proporciona un seguimiento integral, métricas detalladas y herramientas de depuración que permiten a los equipos (incluso a los que no son técnicos) supervisar cada paso de un flujo de trabajo de IA, desde las entradas rápidas hasta las decisiones del modelo y las llamadas a herramientas.
Para las empresas, esto se traduce en menos puntos ciegos, una resolución más rápida de los incidentes y un mayor cumplimiento de la gobernanza interna y las normativas externas. Además, Langfuse también admite la gestión y evaluación de indicaciones, lo que permite a los equipos versionar, probar y optimizar las indicaciones a gran escala.
Cómo utilizar Langfuse para rastrear un agente de IA de seguimiento del cumplimiento construido con LangChain y Bright Data
Para mostrar las capacidades de seguimiento y supervisión de Langfuse, primero se necesita un agente de IA que instrumentar. Por este motivo, crearemos un agente de IA real utilizando LangChain, impulsado por las soluciones de Bright Data para la búsqueda y el Scraping web.
Nota: Langfuse y Bright Data son compatibles con una amplia gama de marcos de agentes de IA. LangChain se ha elegido aquí solo por simplicidad y con fines de demostración.
Este agente de IA listo para su uso en empresas se encargará de las tareas relacionadas con el cumplimiento normativo mediante:
- Cargar un documento PDF interno que describa un proceso empresarial (por ejemplo, flujos de trabajo de procesamiento de datos).
- Analizar el documento con un LLM para identificar aspectos clave de privacidad y normativos.
- Realizar búsquedas web de temas relacionados utilizando la API SERP de Bright Data.
- Acceso a las páginas principales (dando prioridad a los sitios web gubernamentales) en formato Markdown a través de la API Bright Data Web Unlocker.
- Procesar la información recopilada y proporcionar información actualizada para ayudar a evitar problemas normativos.
A continuación, este agente se conectará a Langfuse para rastrear información de tiempo de ejecución, métricas y otros datos relevantes.
Para obtener una arquitectura de alto nivel de este proyecto, consulte el siguiente diseño esquemático: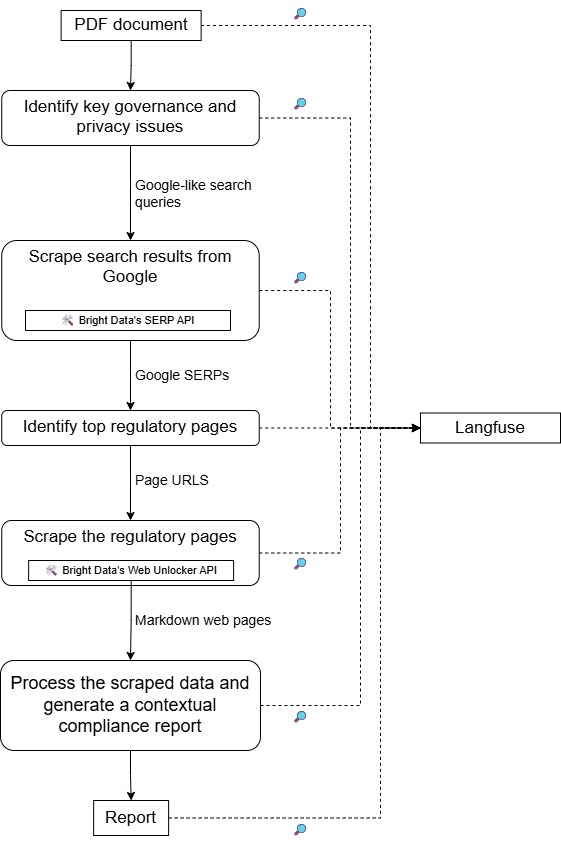
¡Siga las instrucciones que se indican a continuación!
Requisitos previos
Antes de empezar, asegúrese de que dispone de lo siguiente:
- Python 3.10 o superior instalado en su equipo.
- Una clave API de OpenAI.
- Una cuenta de Bright Data con las zonas API SERP y Web Unlocker configuradas, junto con una clave API.
- Una cuenta de Langfuse con claves API públicas y secretas configuradas.
No se preocupe por configurar las cuentas de Bright Data y Langfuse ahora mismo, ya que se le guiará a través de los pasos que se indican a continuación. También es útil tener un conocimiento básico de la instrumentación de agentes de IA para ver cómo Langfuse rastrea y gestiona los datos de tiempo de ejecución.
Paso n.º 1: Configure su proyecto de agente de IA LangChain
Ejecute el siguiente comando en su terminal para crear una nueva carpeta para su proyecto de agente de IA LangChain:
mkdir compliance-tracking-IA-agentEste directorio compliance-tracking-ai-agent/ representa la carpeta del proyecto para su agente de IA, que más adelante instrumentará a través de Langfuse.
Navegue hasta la carpeta y cree un entorno virtual Python dentro de ella:
cd compliance-tracking-IA-agent
python -m venv .venvAbra la carpeta del proyecto en su IDE de Python preferido. Tanto Visual Studio Code con la extensión Python como PyCharm son opciones válidas.
Dentro de la carpeta del proyecto, cree un script Python llamado agent.py:
compliance-tracking-IA-agent/
├─── .venv/
└─── agent.py # <------------Actualmente, agent.py está vacío. Aquí es donde más adelante definirás tu agente de IA a través de LangChain.
A continuación, activa el entorno virtual. En Linux o macOS, ejecuta en tu terminal:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activateUna vez activado, instale las dependencias del proyecto con este comando:
pip install langchain langchain-openai langgraph langchain-brightdata langchain-community pypdf python-dotenv langfuseEstas bibliotecas cubren el siguiente ámbito:
langchain,langchain-openaiylanggraph: para crear y gestionar un agente de IA basado en un modelo OpenAI.langchain-brightdata: para integrar LangChain con los servicios de Bright Data utilizando herramientas oficiales.langchain-communityypypdf: proporcionan API para leer y procesar archivos PDF a través de la bibliotecapypdfsubyacente.python-dotenv: para cargar secretos de la aplicación, como claves API de proveedores externos, desde un archivo.env.langfuse: para instrumentar su agente de IA con el fin de recopilar trazas y telemetría útiles, ya sea en la nube o localmente.
¡Listo! Ahora tienes un entorno de desarrollo Python completamente configurado para crear tu agente de IA.
Paso n.º 2: Configurar la lectura de variables de entorno
Su agente de IA se conectará a servicios de terceros, incluidos OpenAI, Bright Data y Langfuse. Para evitar codificar las credenciales en su script y prepararlo para su uso empresarial, configure el script para que las lea desde un archivo .env. ¡Por eso hemos instalado python-dotenv!
En agent.py, comience añadiendo la siguiente importación:
from dotenv import load_dotenvA continuación, cree un archivo .env en la carpeta de su proyecto:
compliance-tracking-IA-agent/
├─── .venv/
├─── agent.py
└─── .env # <------------Este archivo almacenará todas tus credenciales, claves API y secretos.
En agent.py, carga las variables de entorno desde .env con esta línea de código:
load_dotenv()¡Genial! Ahora tu script puede leer de forma segura los valores del archivo .env.
Paso n.º 3: prepara tu cuenta de Bright Data
Las herramientas LangChain Bright Data funcionan conectándose a los servicios Bright Data configurados en tu cuenta. En concreto, las dos herramientas necesarias para este proyecto son:
BrightDataSERP: recupera los resultados del motor de búsqueda para encontrar páginas web normativas relevantes. Se conecta a la API SERP de Bright Data.BrightDataUnblocker: accede a cualquier sitio web público, incluso si está restringido geográficamente o protegido por bots. Esto permite al agente extraer contenido de páginas web individuales y aprender de ellas. Se conecta a la API Web Unblocker de Bright Data.
En otras palabras, para utilizar estas dos herramientas, necesita una cuenta de Bright Data con una zona API SERP y una zona Web Unblocker API configuradas. ¡Vamos a configurarlas!
Si aún no tiene una cuenta de Bright Data, comience por crear una. De lo contrario, inicie sesión. Vaya a su panel de control y navegue hasta la página «Proxies y scraping». Allí, compruebe la tabla «Mis zonas»: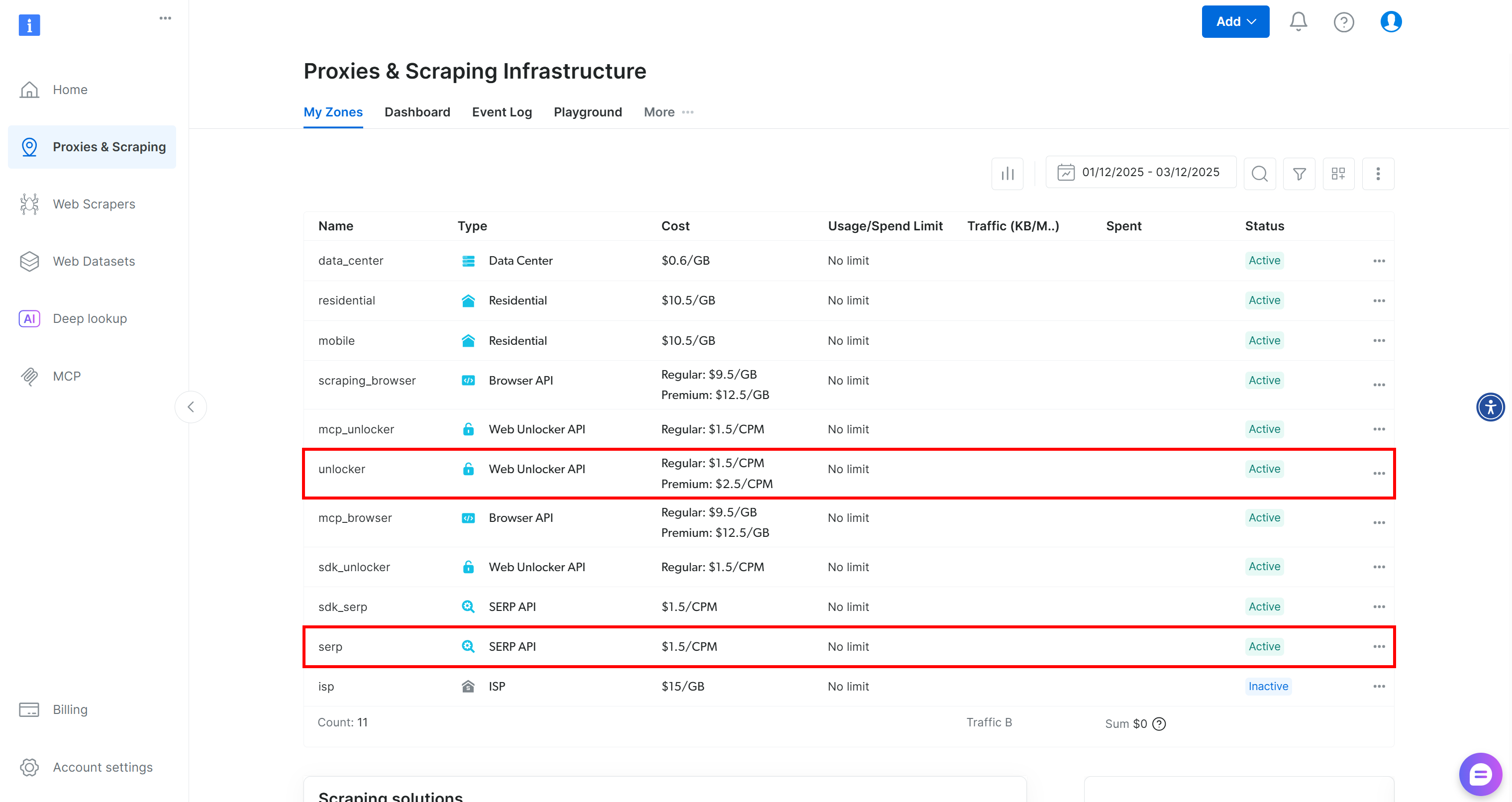
Si la tabla ya contiene una zona API Web Unlocker llamada unlocker y una zona API SERP llamada serp, ya está listo. Esto se debe a que:
- La herramienta
BrightDataSERPLangChain se conecta automáticamente a una zona API SERP llamadaserp. - La herramienta
BrightDataUnblockerLangChain se conecta automáticamente a una zona API de Web Unblocker llamadaweb_unlocker.
Para obtener más detalles, consulte la documentación de Bright Data x LangChain.
Si no dispone de esas dos zonas necesarias, puede crearlas fácilmente. Desplácese hacia abajo en las tarjetas «Unblocker API» y «API SERP», pulse el botón «Crear zona» y siga el asistente para añadir las dos zonas con los nombres necesarios: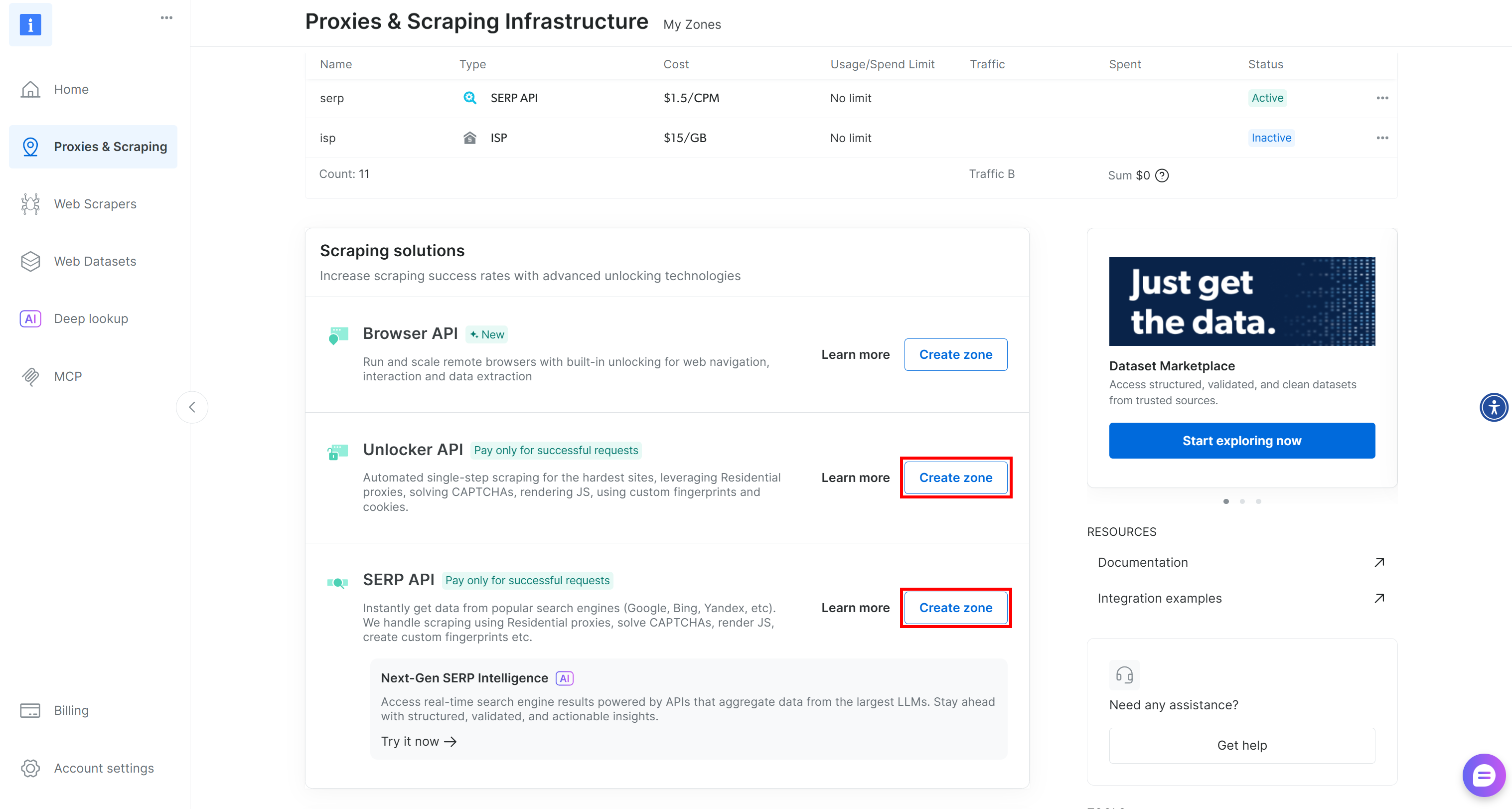
Para obtener instrucciones paso a paso, consulte estas dos páginas de documentación:
Por último, debe indicar a las herramientas LangChain Bright Data cómo conectarse a su cuenta. Esto se hace utilizando su clave API de Bright Data, que se utiliza para la autenticación.
Genere su clave API de Bright Data y guárdela en su archivo .env de la siguiente manera:
BRIGHT_DATA_API_KEY="<SU_CLAVE_API_DE_BRIGHT_DATA>"¡Eso es todo! Ahora ya tiene todos los requisitos previos para conectar su script LangChain a las soluciones de Bright Data a través de las herramientas oficiales.
Paso n.º 4: Configurar las herramientas LangChain Bright Data
En su archivo agent.py, prepare las herramientas LangChain Bright Data de la siguiente manera:
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker() Nota: No es necesario especificar manualmente su clave API de Bright Data. Ambas herramientas intentan leerla automáticamente desde la variable de entorno BRIGHT_DATA_API_KEY, que ha configurado anteriormente en su archivo .env.
Paso n.º 5: integrar el LLM
Su agente de IA para el seguimiento del cumplimiento necesita un cerebro, que está representado por un modelo LLM. En este ejemplo, el proveedor de LLM elegido es OpenAI. Por lo tanto, comience añadiendo su clave API de OpenAI al archivo .env:
OPENAI_API_KEY="<SU_CLAVE_API_OPENAI>"A continuación, en el archivo agent.py, inicialice la integración LLM de la siguiente manera:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-5-mini",
) Nota: El modelo configurado aquí es GPT-5 Mini, pero puede utilizar cualquier otro modelo de OpenAI.
Si no desea utilizar OpenAI, siga las guías oficiales de LangChain para conectarse a cualquier otro proveedor de LLM.
¡Genial! Ahora tiene todo lo necesario para definir un agente de IA de LangChain.
Paso n.º 6: definir el agente de IA
Un agente LangChain requiere un LLM, algunas herramientas opcionales y un sistema de indicaciones para definir el comportamiento del agente.
Combine todos esos componentes en un agente LangChain de esta manera:
from langchain.agents import create_agent
# Defina el indicador del sistema que instruye al agente sobre su tarea centrada en el cumplimiento y la privacidad
system_prompt = """
Usted es un experto en seguimiento del cumplimiento. Su función es analizar documentos en busca de posibles problemas normativos y de privacidad.
Su análisis se basa en la investigación de normas actualizadas y fuentes autorizadas en línea utilizando las herramientas de Bright Data, incluidas la API SERP y Web Unlocker.
Proporcione información precisa y lista para su uso en la empresa, asegurándose de que todos los resultados estén respaldados por citas tanto del documento original como de fuentes externas autorizadas.
"""
# Lista de herramientas disponibles para el agente
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Definir el agente de IA
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)La función create_agent() crea un tiempo de ejecución del agente basado en grafos utilizando LangGraph. Un grafo se compone de nodos (pasos) y aristas (conexiones) que definen cómo procesa la información el agente. El agente se mueve a través de este grafo, ejecutando diferentes tipos de nodos. Para obtener más detalles, consulte la documentación oficial.
Básicamente, la variable agent ahora representa su agente de IA con la integración de Bright Data para el seguimiento y análisis del cumplimiento. ¡Fantástico!
Paso n.º 7: Iniciar el agente
Antes de iniciar el agente, necesita una indicación que describa la tarea de seguimiento del cumplimiento y el documento que se va a analizar.
Comience leyendo el documento PDF de entrada:
from langchain_community.document_loaders import PyPDFDirectoryLoader
# Cargar todos los documentos PDF de la carpeta de entrada
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Cargar todas las páginas de todos los PDF de la carpeta de entrada
docs = loader.load()
# Combinar todas las páginas de los PDF en una sola cadena para su análisis
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])Esto utiliza el cargador de documentos de la comunidad pypdf de LangChain para leer todas las páginas de los PDF de la carpeta input/ y agregar su texto en una única variable de cadena.
Añade una carpeta input/ dentro del directorio de tu proyecto:
compliance-tracking-IA-agent/
├─── .venv/
├─── input/ # <------------
├─── agent.py
└─── .envEsa carpeta contendrá los archivos PDF que el agente analizará en busca de problemas relacionados con la privacidad, la normativa o el cumplimiento.
Suponiendo que la carpeta input/ contiene un único documento, la variable internal_document_to_analyze contendrá su texto completo. Ahora se puede incrustar en un mensaje que indique claramente al agente que realice la tarea de análisis:
from langchain_core.prompts import PromptTemplate
# Defina una plantilla de solicitud para guiar al agente a través del flujo de trabajo.
prompt_template = PromptTemplate.from_template("""
Dado el siguiente contenido PDF:
1. Haga que el LLM lo analice para identificar los aspectos clave principales que vale la pena explorar en términos de privacidad.
2. Traduce esos aspectos en hasta 3 consultas de búsqueda muy breves (no más de 5 palabras), concisas y específicas, adecuadas para Google.
3. Realiza búsquedas web para esas consultas utilizando la herramienta API SERP de Bright Data (buscando páginas en inglés, limitadas a Estados Unidos).
4. Acceder a las 5 páginas web principales, que no sean PDF (dando prioridad a los sitios web gubernamentales) en formato de datos Markdown utilizando la herramienta Web Unlocker de Bright Data.
5. Procesar la información recopilada y crear un informe final conciso que incluya citas del documento original y conocimientos de las páginas recopiladas para evitar problemas normativos.
CONTENIDO DEL PDF:
{pdf}
""")
# Rellene la plantilla con el contenido de los PDF
prompt = prompt_template.format(pdf=internal_document_to_analyze)Por último, pasar la indicación al agente y ejecutarla:
# Transmite la respuesta del agente mientras sigues cada paso con Langfuse
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()¡Misión cumplida! Su agente de IA LangChain, impulsado por Bright Data, ya está listo para gestionar tareas de análisis de documentos y de investigación normativa de nivel empresarial.
Paso n.º 8: Empieza a utilizar Langfuse
Ahora ha llegado a un punto en el que su agente de IA está implementado. Este es normalmente el momento en el que se desea añadir Langfuse para el seguimiento y la supervisión de la producción. Al fin y al cabo, lo habitual es instrumentar los agentes que ya están en funcionamiento.
Comience por crear una cuenta de Langfuse. Se le redirigirá a la página «Organizaciones», donde deberá crear una nueva organización. Para ello, haga clic en el botón «Nueva organización»: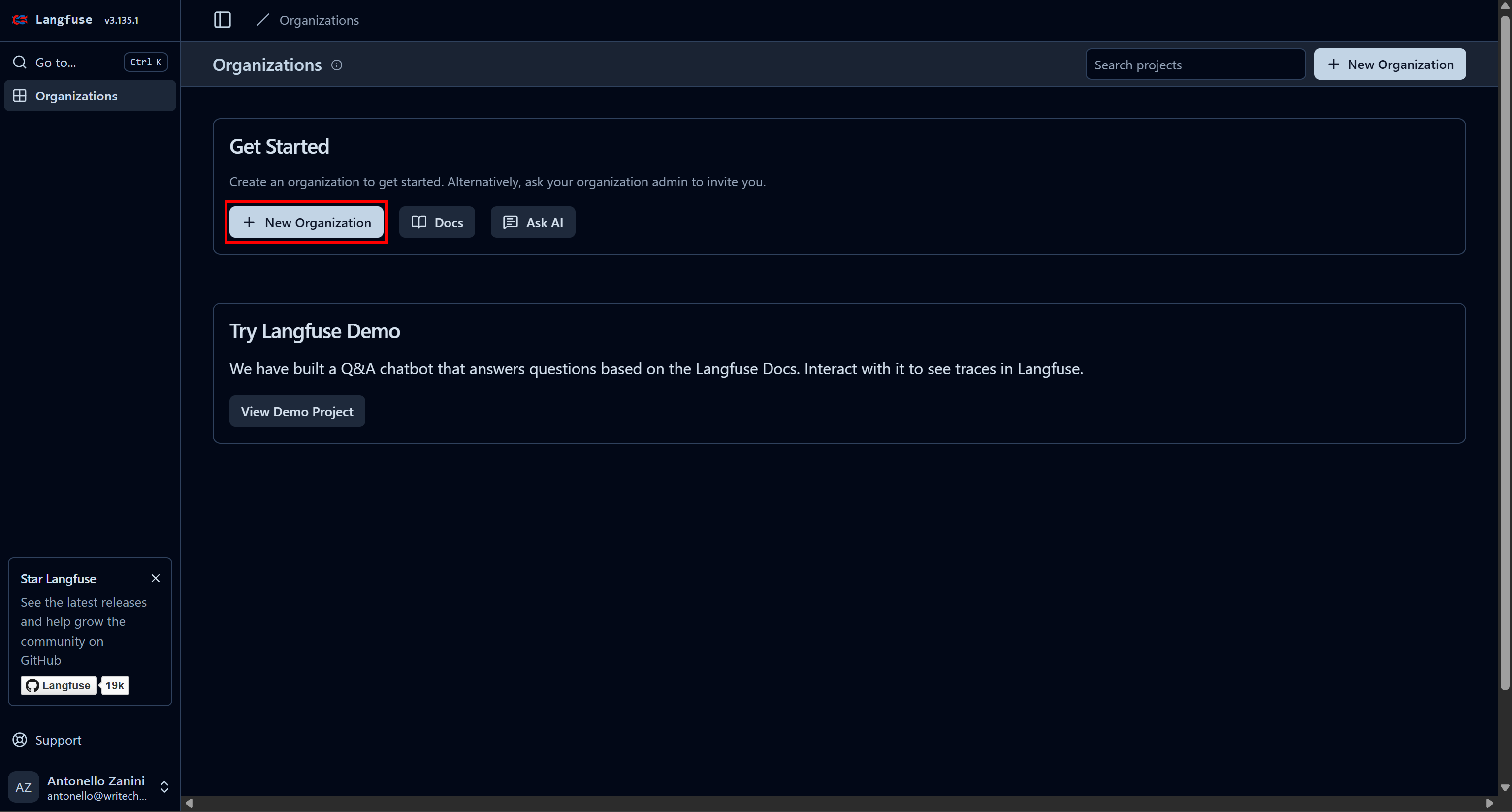
Asigne un nombre a su organización y continúe con el asistente hasta el paso final «Crear proyecto»:
En el último paso, asigne un nombre a su proyecto, como «compliance-tracking-IA-agent», y pulse el botón «Crear». A continuación, se le redirigirá a la vista «Configuración del proyecto». Desde allí, navegue hasta la página «Claves API»:
En la sección «Claves API del proyecto», haga clic en «Crear nuevas claves API»:
En la ventana modal que aparece, asigne un nombre a su clave API y haga clic en «Crear claves API»:
Recibirá una clave API pública y otra secreta. Para una integración rápida, haga clic en el botón «Copiar al portapapeles» en la sección «.env»: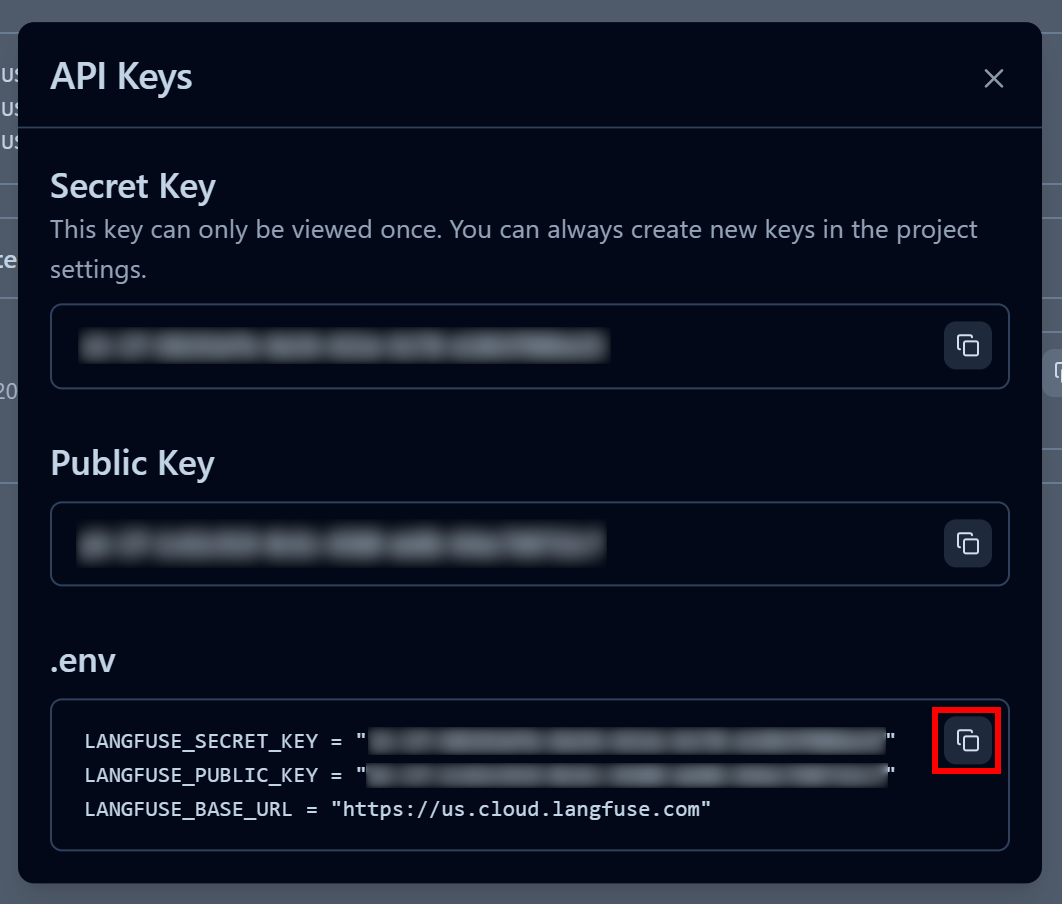
A continuación, pegue las variables de entorno copiadas en el archivo .env de su proyecto:
LANGFUSE_SECRET_KEY = "<TU_LANGFUSE_SECRET_KEY>"
LANGFUSE_PUBLIC_KEY = "<TU_LANGFUSE_PUBLIC_KEY>"
LANGFUSE_BASE_URL = "<TU_LANGFUSE_BASE_URL>"¡Genial! Ahora tu script puede conectarse a tu cuenta de Langfuse Cloud y enviar información de rastreo útil para la supervisión y la observabilidad.
Paso n.º 9: Integrar el seguimiento de Langfuse
Langfuse es totalmente compatible con LangChain (así como con muchos otros marcos de creación de agentes de IA), por lo que no se requiere ningún código personalizado.
Para conectar su agente de IA LangChain a Langfuse, solo tiene que inicializar el cliente Langfuse y crear un controlador de devolución de llamada:
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Cargar variables de entorno desde el archivo .env
load_dotenv()
# Inicializar el cliente Langfuse para el seguimiento y la observabilidad
langfuse = get_client()
# Crear un controlador de devolución de llamada Langfuse para capturar las interacciones del agente Langchain
langfuse_handler = CallbackHandler()
A continuación, pasar el controlador de devolución de llamada Langfuse al invocar al agente:
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Integración de Langfuse
):
step["messages"][-1].pretty_print()¡Ya está! Tu agente IA LangChain ya está completamente instrumentado. Toda la información de tiempo de ejecución se enviará a Langfuse y se podrá ver en la aplicación web.
Paso n.º 10: Código final
Tu archivo agent.py ahora debería contener:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_core.prompts import PromptTemplate
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Cargar variables de entorno desde el archivo .env
load_dotenv()
# Inicializar el cliente Langfuse para el seguimiento y la observabilidad
langfuse = get_client()
# Crear un controlador de devolución de llamada Langfuse para capturar las interacciones del agente Langchain
langfuse_handler = CallbackHandler()
# Inicializar las herramientas Bright Data
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()
# Inicializar el modelo de lenguaje grande.
llm = ChatOpenAI(
model="gpt-5-mini",)
# Definir el mensaje del sistema que instruye al agente sobre su tarea centrada en el cumplimiento y la privacidad.
system_prompt = """
Eres un experto en seguimiento del cumplimiento. Tu función es analizar documentos en busca de posibles problemas normativos y de privacidad.
Tu análisis se basa en la investigación de normas actualizadas y fuentes autorizadas en línea utilizando las herramientas de Bright Data, incluidas la API SERP y Web Unlocker.
Proporciona información precisa y lista para su uso en la empresa, asegurándote de que todos los resultados estén respaldados por citas tanto del documento original como de fuentes externas autorizadas.
"""
# Lista de herramientas disponibles para el agente
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Definir el agente de IA
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)
# Cargar todos los documentos PDF de la carpeta de entrada
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Cargar todas las páginas de todos los PDF de la carpeta de entrada
docs = loader.load()
# Combinar todas las páginas de los PDF en una sola cadena para su análisis
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])
# Definir una plantilla de solicitud para guiar al agente a través del flujo de trabajo
prompt_template = PromptTemplate.from_template("""
Dado el siguiente contenido PDF:
1. Hacer que el LLM lo analice para identificar los aspectos clave principales que vale la pena explorar en términos de privacidad.
2. Traducir esos aspectos en hasta 3 consultas de búsqueda muy breves (no más de 5 palabras), concisas y específicas, adecuadas para Google.
3. Realizar búsquedas web para esas consultas utilizando la herramienta API SERP de Bright Data (buscando páginas en inglés, limitadas a los Estados Unidos).
4. Acceder a las 5 páginas web principales, que no sean PDF (dando prioridad a los sitios web gubernamentales) en formato de datos Markdown utilizando la herramienta Web Unlocker de Bright Data.
5. Procesar la información recopilada y crear un informe final conciso que incluya citas del documento original y conocimientos extraídos de las páginas rastreadas para evitar problemas normativos.
CONTENIDO DEL PDF:
{pdf}
""")
# Rellene la plantilla con el contenido de los PDF.
prompt = prompt_template.format(pdf=internal_document_to_analyze)
# Transmita la respuesta del agente mientras realiza un seguimiento de cada paso con Langfuse.
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Integración con Langfuse
):
step["messages"][-1].pretty_print()¡Vaya! Con solo unas 75 líneas de código Python, acabas de crear un agente de IA listo para su uso en empresas para el análisis normativo y de cumplimiento, gracias a LangChain, Bright Data y Langfuse.
Paso n.º 11: ejecutar el agente
Recuerda que tu agente de IA necesita un archivo PDF para funcionar. Para este ejemplo, supongamos que quieres ejecutar el análisis normativo en el siguiente documento:
Este es un documento de muestra, de estilo empresarial, que describe, a alto nivel, las prácticas de procesamiento de datos de usuarios aplicadas por una empresa.
Guárdelo como user-data-processing-workflow.pdf y colóquelo dentro de la carpeta input/ en el directorio de su proyecto:
De esta manera, el script podrá acceder a él e integrarlo en el prompt del agente.
Ejecute el agente de IA LagnChain con:
python agent.py En la terminal, verá rastros de las llamadas a las herramientas de Bright Data, como este: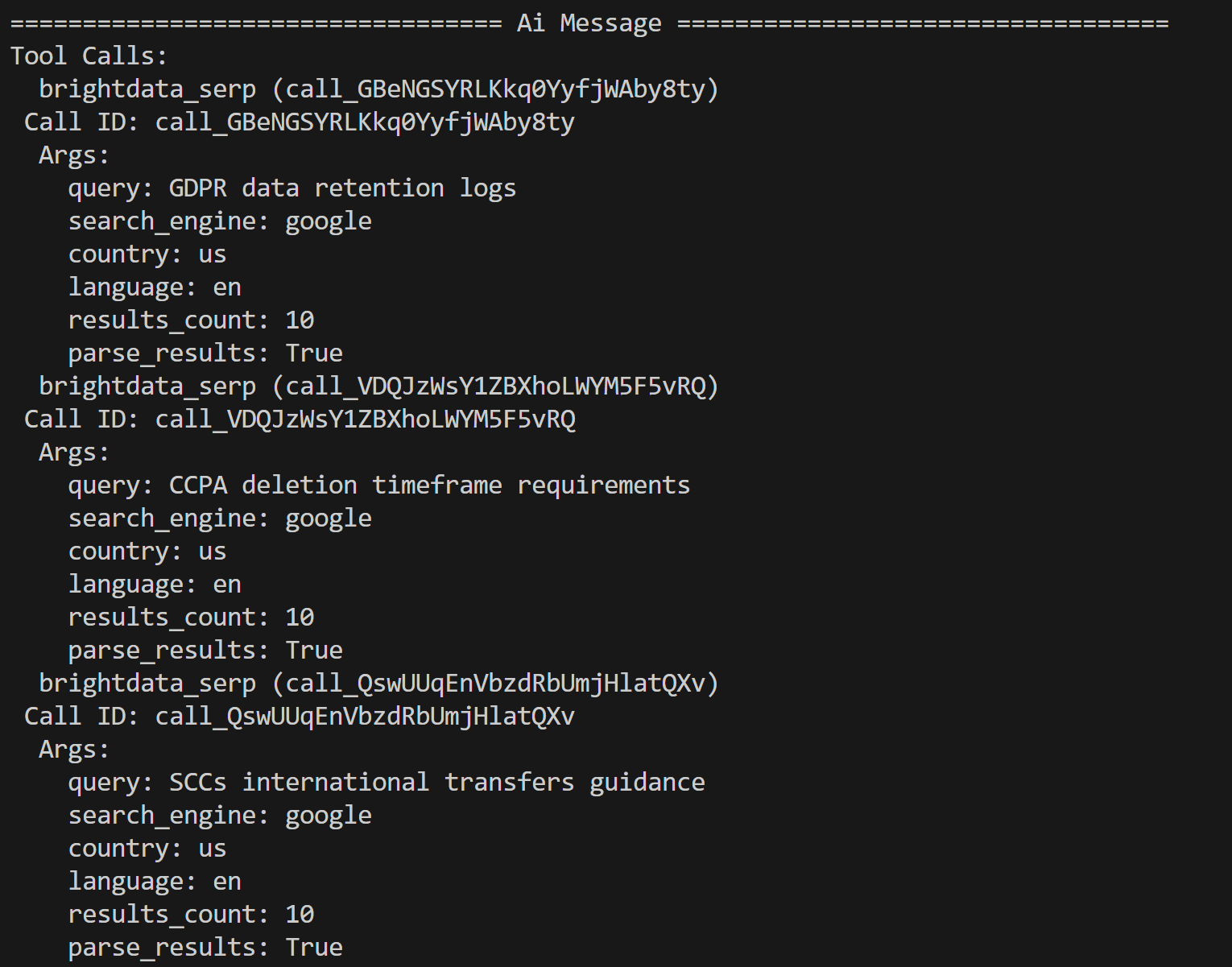
El agente de IA identificó las siguientes tres consultas de búsqueda para investigar más a fondo basándose en el contenido del PDF:
- «Registros de retención de datos del RGPD»
- «Requisitos de plazo de eliminación de la CCPA»
- «Guía de SCC para transferencias internacionales»
Estas consultas están relacionadas con posibles cuestiones normativas y de privacidad destacadas por el LLM en el documento de entrada.
A partir de los resultados devueltos por la API SERP de Bright Data, que contiene los resultados de búsqueda de Google para estas consultas, el agente selecciona las páginas principales y las extrae mediante la herramienta API Web Unblocker: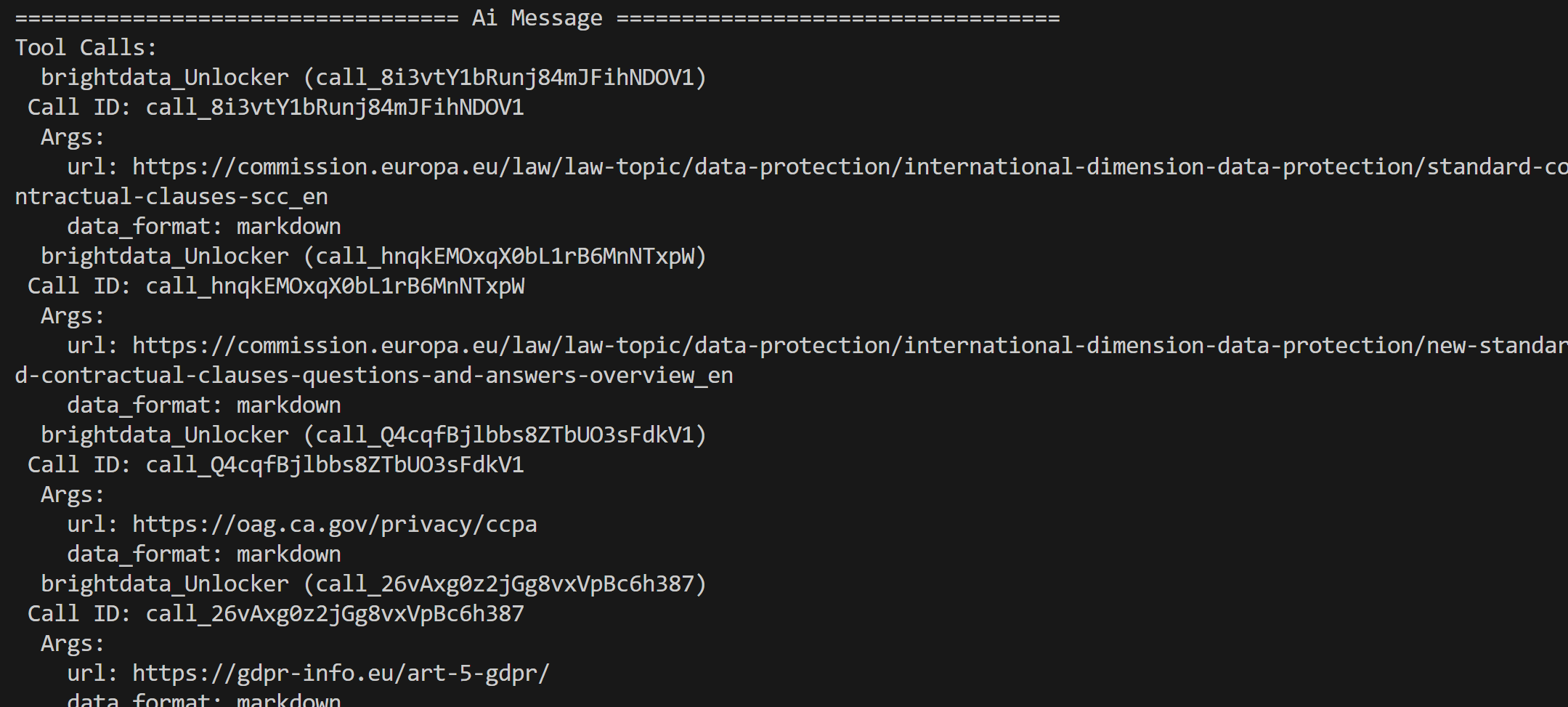
A continuación, el contenido de estas páginas se procesa y se condensa en un informe final de análisis normativo.
¡Et voilà! Su agente de IA funciona a las mil maravillas. Es hora de comprobar el efecto de la integración de Langfuse en cuanto a observabilidad y seguimiento.
Paso n.º 12: Inspeccionar los rastros del agente en Langfuse
Tan pronto como su agente de IA comience a realizar su tarea, verá aparecer los datos en su panel de control de Langfuse. En particular, observe cómo el recuento de «rastros» pasa de 0 a 1 y cómo aumentan los costes del modelo: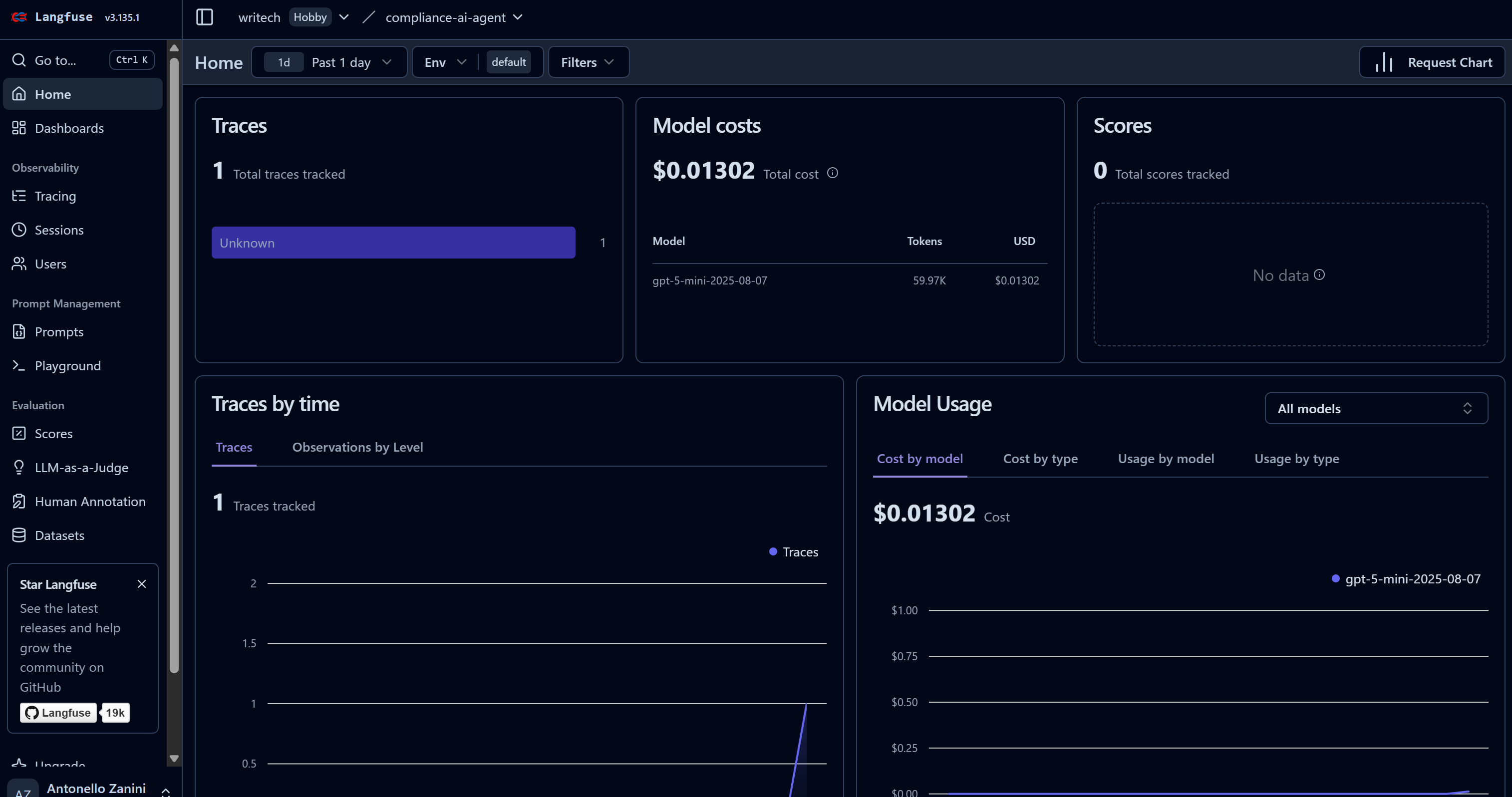
Este panel le ayuda a supervisar los costes, así como muchas otras métricas útiles.
Para ver toda la información sobre la ejecución de un agente específico, vaya a la página «Tracing» y haga clic en la fila de rastreo correspondiente a su agente: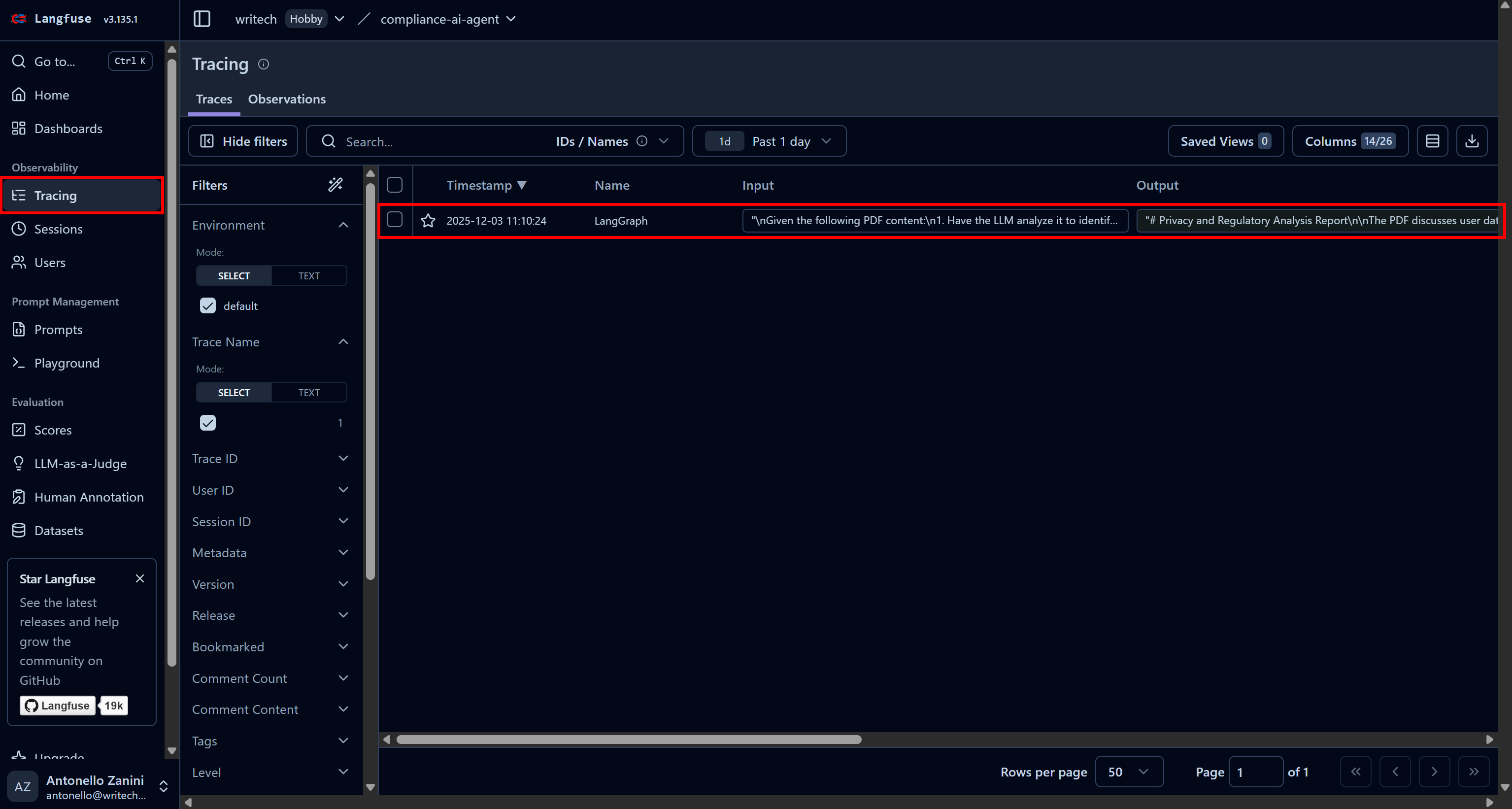
Se abrirá un panel en la parte izquierda de la página web, que muestra información detallada de cada paso realizado por su agente.
Céntrese en el primer nodo «ChatOpenAI». Esto destaca que el agente ya ha llamado tres veces a la API SERP de Bright Data, mientras que la API Web Unlocker aún no se ha llamado: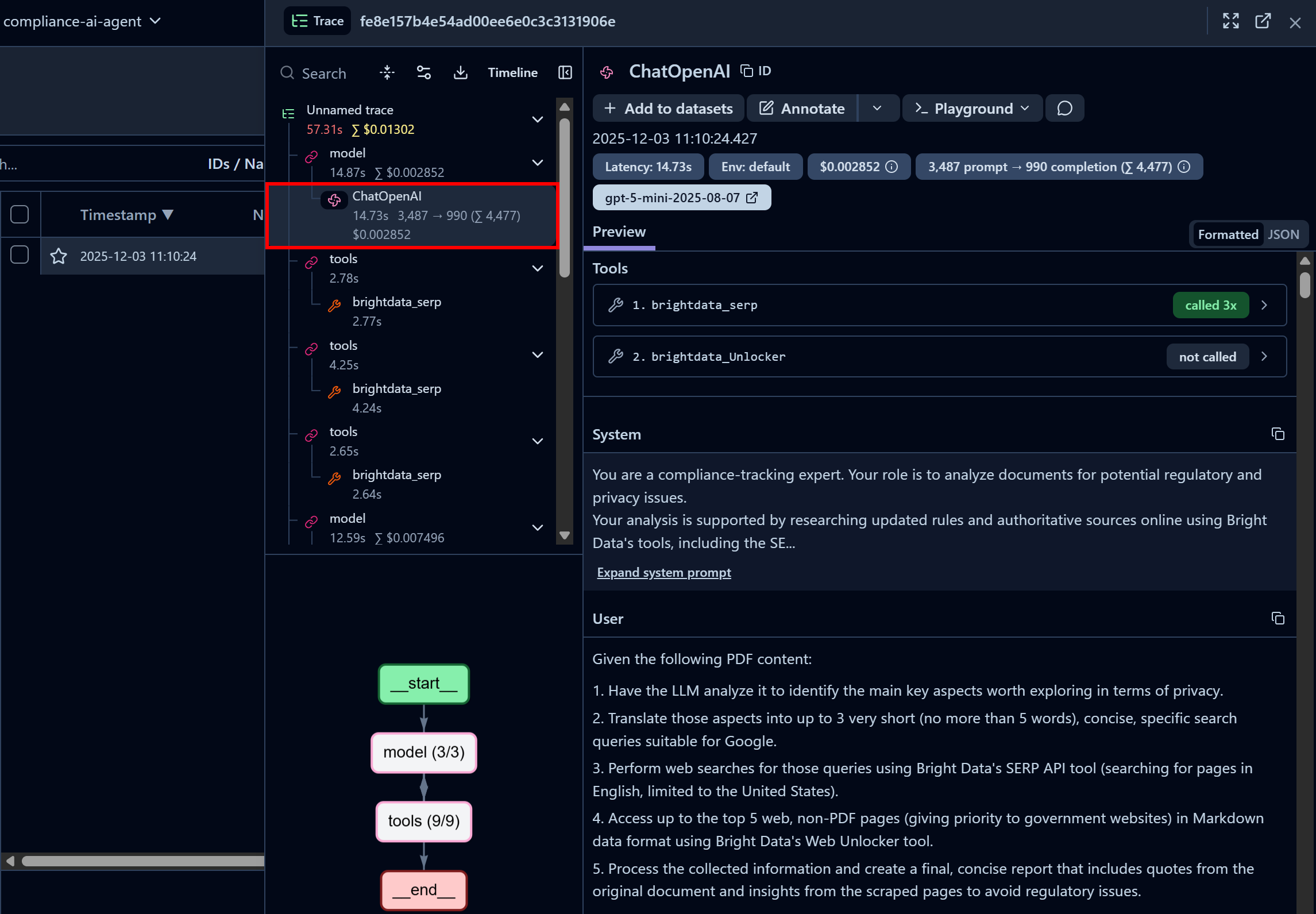
Aquí también puede inspeccionar el mensaje del sistema configurado en su código y los mensajes del usuario enviados al agente. Además, puede acceder a información como la latencia, el coste, las marcas de tiempo y mucho más. Además, un diagrama de flujo interactivo en la esquina inferior izquierda le ayuda a visualizar y explorar la ejecución del agente paso a paso.
Ahora, inspeccione un nodo de llamada a la herramienta API SERP de Bright Data: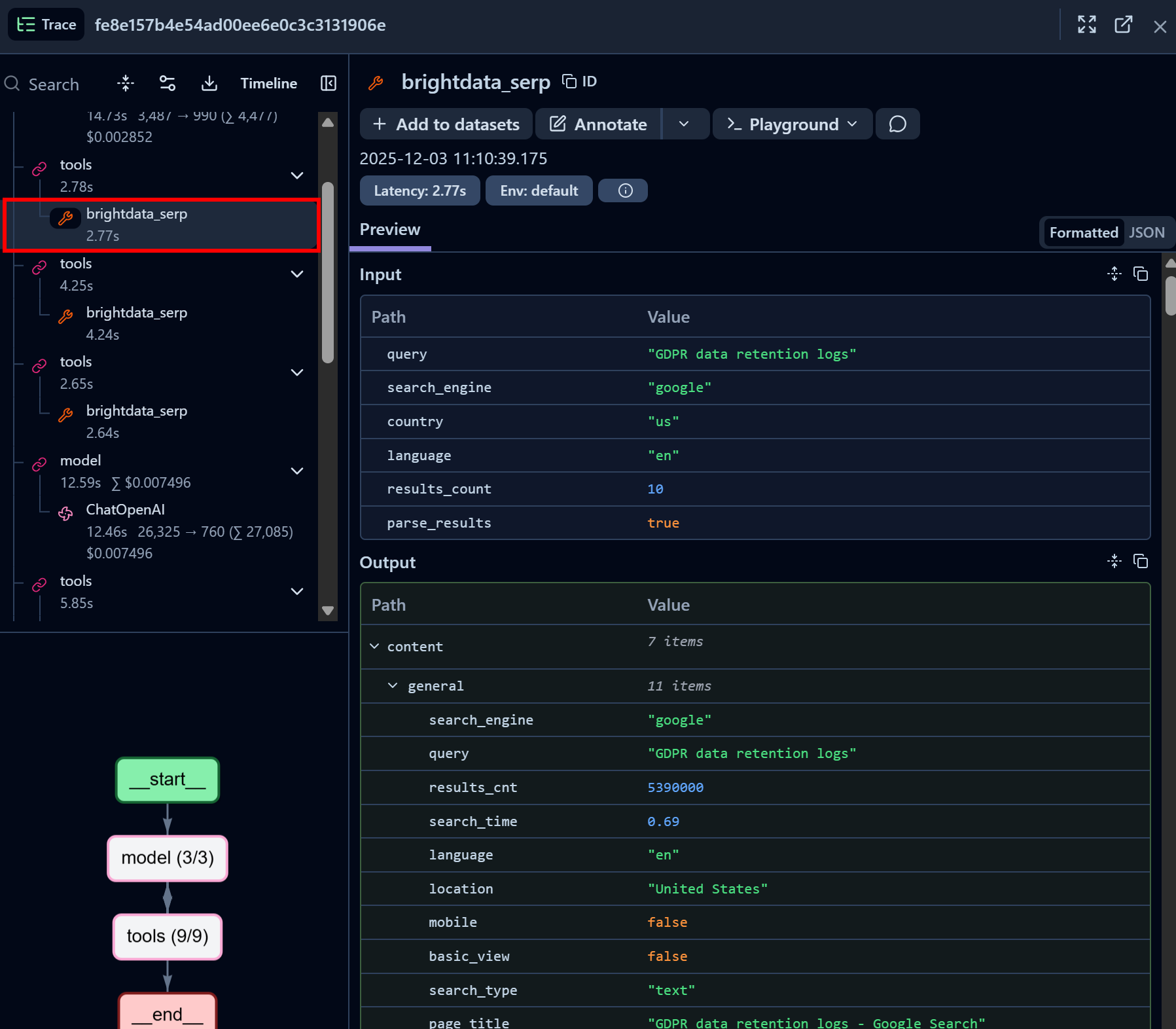
Observe cómo la herramienta LangChain de la API SERP de Bright Data ha devuelto correctamente los datos SERP para la consulta de búsqueda dada en formato JSON (lo cual es ideal para la ingestión de LLM en agentes de IA). Esto demuestra que la integración con la API SERP de Bright Data funciona perfectamente.
Si alguna vez ha intentado extraer resultados de búsqueda de Google en Python, sabrá lo difícil que puede resultar. Gracias a la API SERP de Bright Data, este proceso es inmediato, rápido y totalmente compatible con la IA.
Del mismo modo, centrémonos en un nodo de llamada a la herramienta API Web Unlocker de Bright Data: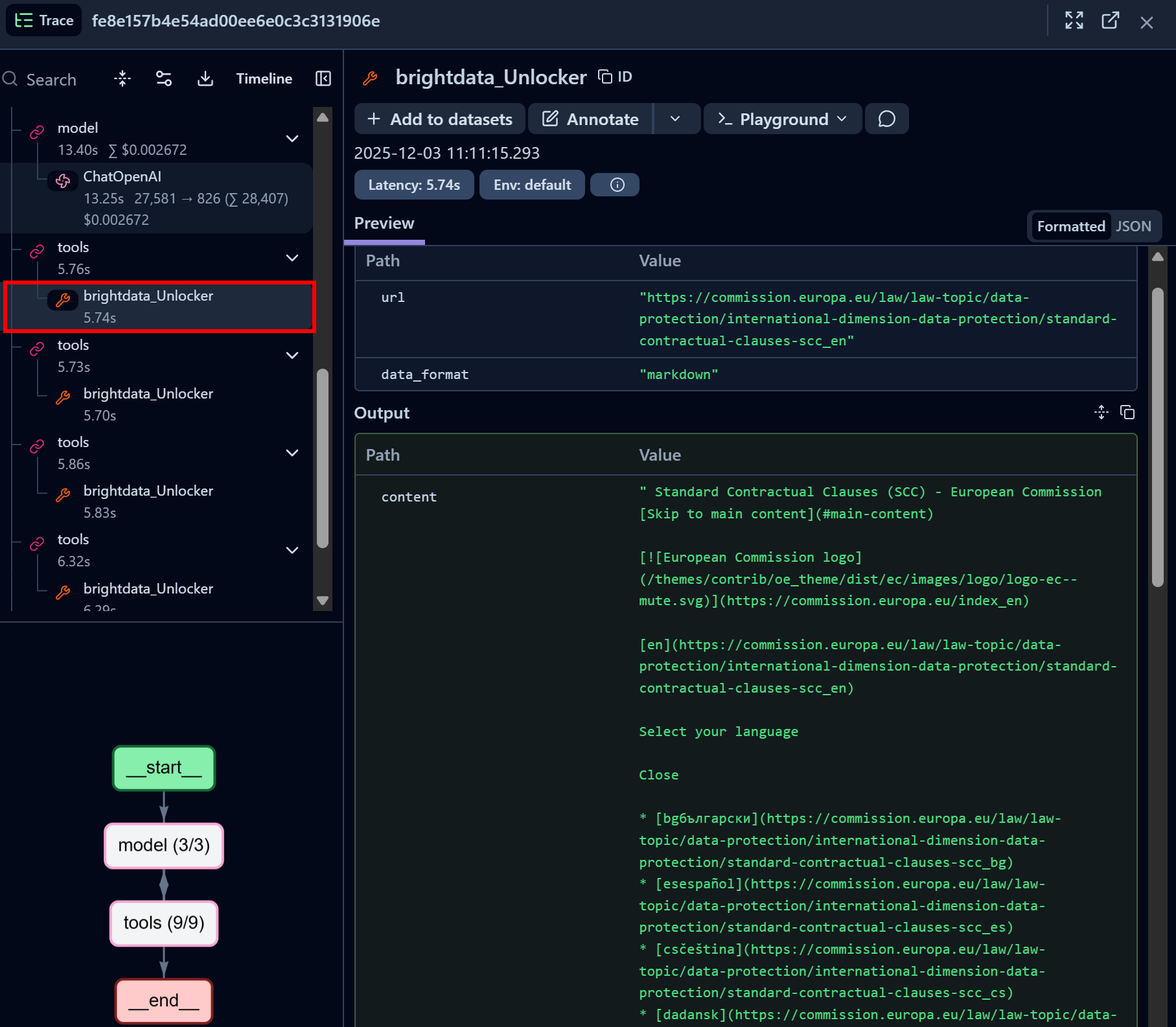
La herramienta Bright Data Web Unlocker LangChain accedió con éxito a la página identificada y la devolvió en formato Markdown.
La API Web Unlocker ofrece a su agente de IA la capacidad de acceder mediante programación a cualquier sitio web de gobernanza (u otras páginas web) sin preocuparse por los bloqueos, obteniendo como resultado una versión de la página optimizada para IA y adecuada para la ingestión de LLM.
¡Genial! La integración de Langfuse + LangChain + Bright Data ya está completa. Langfuse se puede integrar con muchas otras soluciones de creación de agentes de IA, todas ellas compatibles también con Bright Data.
Próximos pasos
Para que este agente de IA con integración de Langfuse sea aún más adecuado para empresas, tenga en cuenta las siguientes ideas:
- Añada la gestión de indicaciones: utilice las funciones de gestión de indicaciones de Langfuse para almacenar, versionar y recuperar indicaciones para sus aplicaciones LLM.
- Exportar informes: genere un informe final y guárdelo en el disco, almacénelo en una carpeta compartida o envíelo por correo electrónico a las partes interesadas pertinentes.
- Defina un panel de control personalizado: personalice el panel de control de Langfuse para que solo muestre las métricas relevantes para su equipo o las partes interesadas.
Conclusión
En este tutorial, ha aprendido a supervisar y realizar un seguimiento de su agente de IA utilizando Langfuse. En concreto, ha visto cómo instrumentar un agente de IA LangChain impulsado por las soluciones de acceso web preparadas para IA de Bright Data.
Como se ha comentado, al igual que Langfuse, Bright Data se integra con una amplia gama de soluciones de IA, desde herramientas de código abierto hasta plataformas preparadas para empresas. Esto le permite mejorar su agente con potentes capacidades de recuperación y navegación de datos web, al tiempo que supervisa su rendimiento y comportamiento a través de Langfuse.
¡Regístrese gratis en Bright Data y comience a experimentar con nuestras soluciones de datos web preparadas para IA hoy mismo!





