En este artículo, trataremos:
- Qué es el servidor MCP de Playwright y cómo puede utilizarse para el web scraping.
- Las diferentes herramientas disponibles en el servidor MCP de Playwright
- Cómo el servidor MCP de Bright Data Web puede proporcionar una alternativa más sencilla para el web scraping.
Entremos en materia
El servidor MCP Playwright
Playwright es ampliamente conocido como herramienta de automatización de navegadores, a menudo utilizada para probar y automatizar tareas de navegación. El servidor MCP de Playwright se basa en esta funcionalidad, sólo que esta vez no está diseñado para uso humano directo, sino para agentes de IA.
Al ejecutar el servidor, puede conectar cualquier host MCP y conceder a los agentes de IA acceso a todo el conjunto de herramientas de automatización de Playwright.
Esto significa que su agente de IA puede interactuar con un navegador web igual que lo haría un humano, realizando acciones como realizar compras en línea, buscar las últimas noticias, responder a correos electrónicos y mucho más.
En este artículo, nos centraremos principalmente en el web scraping. Con Playwright MCP Server, obtendrá las herramientas de bajo nivel necesarias no sólo para la automatización del navegador, sino también para permitir a un LLM raspar y extraer datos directamente de la web.
El servidor Playwright MCP
Como todo servidor MCP, el servidor Playwright MCP viene con un conjunto de herramientas que pueden ser expuestas a un agente AI. Estas herramientas se corresponden directamente con las API de Playwright que los desarrolladores ya conocen y utilizan. Veamos algunas de las más importantes:
- Browser_click: Permite al agente de IA hacer clic en elementos, igual que un humano con un ratón.
- Browser_drag: Permite interacciones de arrastrar y soltar.
- Browser_close: Cierra la instancia del navegador.
- Browser_evaluate: Permite al agente de IA ejecutar código JavaScript directamente en la página.
- Browser_file_upload: Maneja la carga de archivos a través del navegador.
- Browser_fill_form: Rellena formularios en una página web.
- Browser_hover: Desplaza el puntero del ratón sobre los elementos.
- Browser_navigate: Navega a cualquier URL.
- Browser_press_key: Simula la pulsación de teclas, dando al agente acceso completo a la entrada del teclado.
Con todas estas herramientas a disposición del agente de IA, puede maniobrar fácilmente a través de la web y raspar datos. Veamos cómo hacerlo.
Web Scraping con el servidor Playwright MCP
En esta sección, realizaremos una tarea de web scraping utilizando el servidor MCP de Playwright. Nuestro agente de IA recopilará la información más reciente sobre los precios de los modelos de iPhone 16. Para simplificar las cosas, limitaremos la tarea a una única fuente: Best Buy.
Configuración del servidor
Para ejecutar el servidor MCP de Playwright, necesitamos un host MCP. Puede utilizar cualquier host de su elección, como Claude Desktop, Cursor o Gemini CLI. Para este artículo, utilizaremos VS Code.
El servidor MCP de Playwright es un servidor MCP local implementado en Node.js, así que antes de continuar, asegúrate de que tienes Node instalado.
Para configurar el servidor, necesitamos añadir la siguiente configuración a nuestro host MCP:
{
"servers": {
"playwright": {
"comando": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Esta configuración se aplica a cómo se configuran los servidores MCP en VS Code, aunque puede diferir ligeramente en otros hosts MCP. Una vez completada la configuración, nuestro agente de IA tendrá acceso a las herramientas proporcionadas por el servidor. Con eso en su lugar, podemos empezar a raspar.
Scraping con el servidor MCP
El primer paso es navegar al sitio web de BestBuy. Para ello, simplemente instruiremos al agente de IA para que abra el sitio, y utilizará la herramienta Browser_navigate para llegar allí.
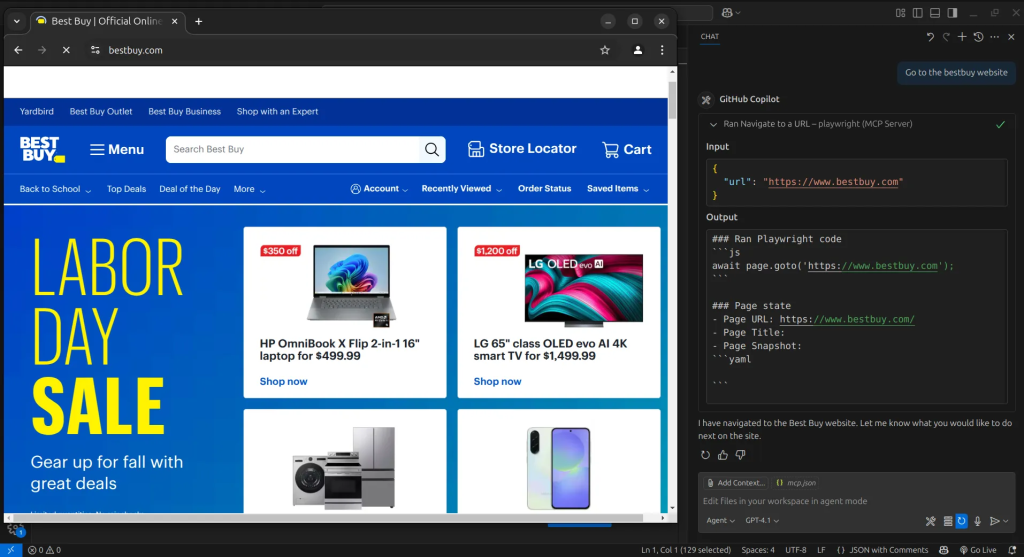
A continuación, le pediremos que busque el iPhone 16. Para ello, utilizará la herramienta Browser_navigate. Para ello, utilizará la herramienta Browser_press_key para introducir la consulta de búsqueda.

A continuación, el agente utilizará la herramienta Browser_click para pulsar el botón de búsqueda.
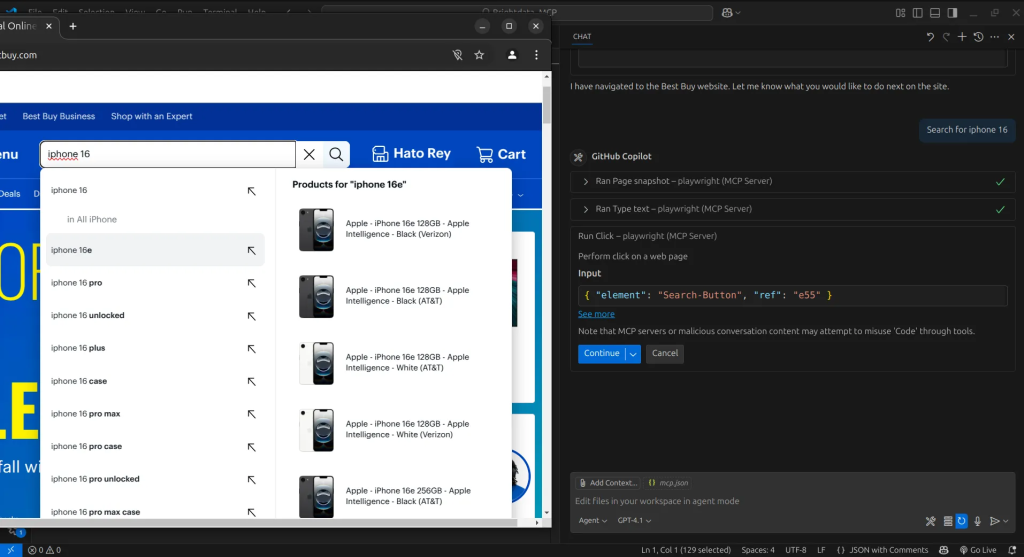
Con esto, obtenemos nuestros resultados. A cada paso, mientras el agente navega por la página, captura una instantánea del estado actual. A continuación, podemos utilizar estas instantáneas para ordenar al agente que extraiga la información que necesitamos y la organice en un formato estructurado.
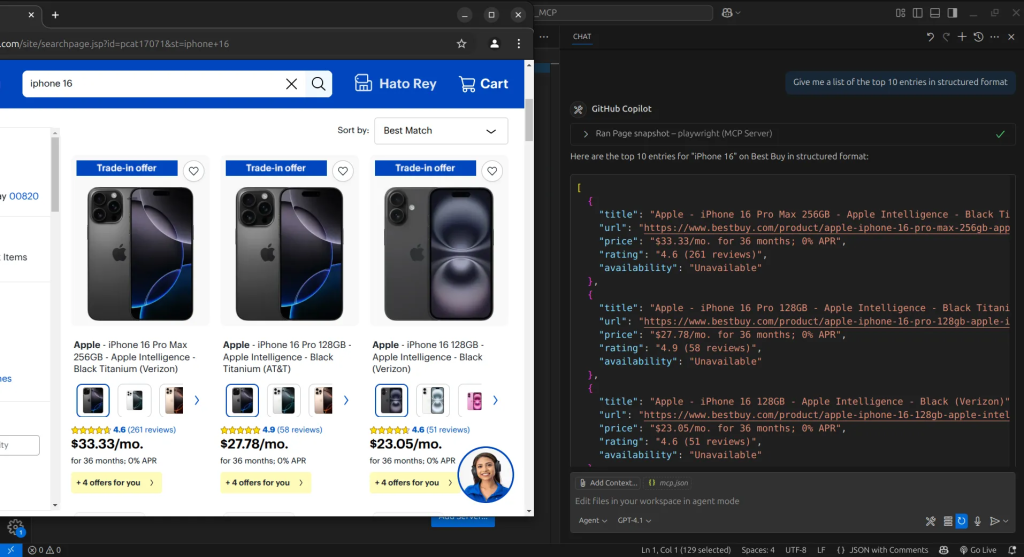
Con este enfoque, hemos conseguido raspar el sitio. Sin embargo, aunque nos da el control total para hacer casi cualquier cosa que queramos, sigue siendo de muy bajo nivel. Esto puede parecer excesivo si nuestro único objetivo es raspar datos, ya que puede que no necesitemos las capacidades de automatización web más amplias.
A continuación, vamos a explorar cómo el servidor Bright Data Web M CP puede lograr la misma tarea desde una perspectiva de mucho más alto nivel.
Servidor MCP Web de Bright Data: Un servidor MCP de Web Scraping de alto nivel
El servidor MCP de Bright Data Web incluye una serie de herramientas de alto nivel creadas específicamente para el web scraping. Entre ellas se incluyen herramientas para extraer datos de plataformas como Amazon, recuperar perfiles individuales y de empresas, e incluso recopilar perfiles, publicaciones y carretes de Instagram.
A diferencia de Playwright MCP, que opera a un nivel inferior, el servidor Bright Data Web MCP simplifica el proceso de scraping para su agente de IA. Incluso gestiona páginas web protegidas por detección de bots o CAPTCHA, proporcionando a su agente un acceso fiable allí donde los métodos tradicionales podrían fallar.
En este tutorial, utilizaremos el servidor Bright Data Web MCP para realizar la misma tarea que abordamos anteriormente con Playwright MCP. De fábrica, proporciona dos herramientas básicas:
- Herramienta de motor de búsqueda
- Herramienta de raspado de datos como markdown
Se pueden desbloquear herramientas adicionales activando el modo Pro, pero por ahora nos quedaremos con estas dos. Puedes encontrar más detalles en este artículo.
Configuración del servidor
A diferencia del servidor MCP de Playwright, que se ejecuta localmente, el servidor MCP de Bright Data Web es un servidor MCP remoto. Esto significa que el proceso de configuración es ligeramente diferente. A continuación se muestra cómo configurarlo en VS Code:
"BrightData": {
"url": "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}Para conectarse, necesitará su clave API de Bright Data. Una vez configurado, su agente estará listo para comenzar a realizar el scraping.
Scraping con el servidor MCP
En primer lugar, instruiremos al agente para que realice una búsqueda web del precio del iPhone 16.

A continuación, el agente utilizará la herramienta de búsqueda del servidor para realizar la solicitud.

Tras obtener los resultados, ordenamos al agente que extraiga información de un sitio de nuestra elección, en este caso el Apple Store. A continuación, el agente utiliza la herramienta scrape data as markdown para extraer el contenido, devolviéndolo en formato Markdown, que el agente puede procesar y comprender fácilmente.
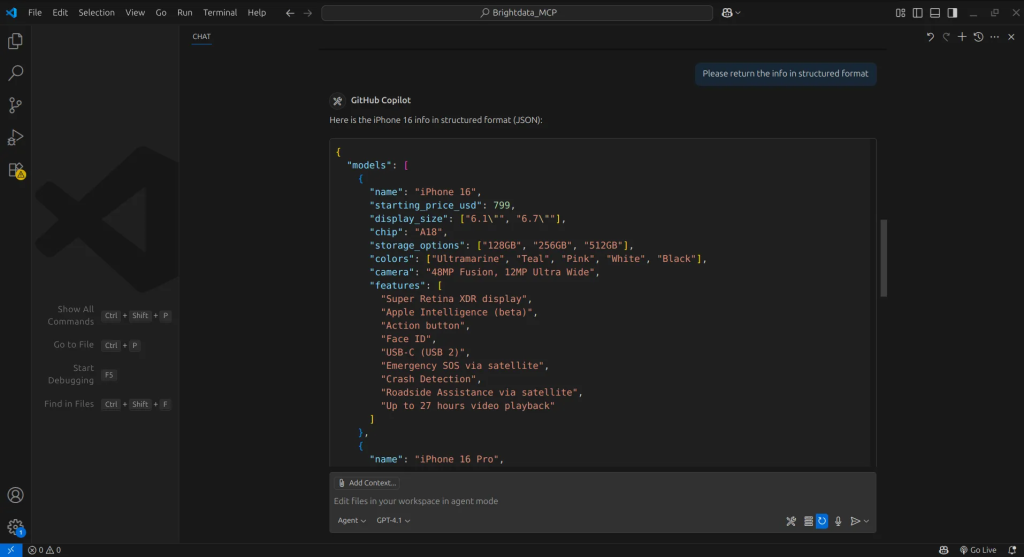
Con la información extraída, podemos instruir al agente para que la organice en un formato estructurado, y así de sencillo, tenemos nuestros datos.
En este ejemplo, sólo hemos utilizado dos herramientas para completar la tarea de scraping. Sin embargo, el servidor MCP de Bright Data Web también ofrece herramientas adicionales en Modo Pro que puede explorar para casos de uso más avanzados. Puede encontrar más ejemplos en este artículo detallado.
Conclusión
En este artículo, hemos explorado cómo se pueden utilizar los servidores MCP para hacer scraping de la web con la ayuda de agentes de IA. Primero vimos el servidor MCP Playwright, que proporciona acceso de bajo nivel a la automatización del navegador, dando a su agente control total sobre cada interacción. A continuación, exploramos el servidor Web MCP de Bright Data, que opera a un nivel superior y equipa a su agente con herramientas especializadas diseñadas específicamente para el web scraping, incluso en sitios protegidos por la detección de bots.
Ambos enfoques tienen sus puntos fuertes, Playwright es ideal cuando se necesita un control detallado del navegador, mientras que Bright Data simplifica el proceso, permitiéndole centrarse únicamente en extraer la información que necesita.
Ahora le toca a usted experimentar con ambos servidores MCP y decidir cuál se adapta mejor a su próximo proyecto.