

En esta guía aprenderás:
- Qué es y cómo funciona la clasificación de tiro por cero
- Ventajas e inconvenientes de su uso
- Relevancia de esta práctica en el web scraping
- Tutorial paso a paso para aplicar la clasificación de disparo cero en un escenario de web scraping
Sumerjámonos.
¿Qué es la clasificación Zero-Shot?
La clasificación sin disparos (ZSC ) es la capacidad de predecir una clase que un modelo de aprendizaje automático nunca ha visto durante su fase de entrenamiento. Una clase es una categoría o etiqueta específica que el modelo asigna a un dato. Por ejemplo, podría asignar la clase “spam” al texto de un correo electrónico, o “gato” a una imagen.
ZSC puede clasificarse como un ejemplo de aprendizaje por transferencia. El aprendizaje por transferencia es una técnica de aprendizaje automático en la que se aplican los conocimientos adquiridos al resolver un problema para ayudar a resolver otro distinto pero relacionado.
La idea central de la ZSC lleva tiempo explorándose y aplicándose en varios tipos de redes neuronales y modelos de aprendizaje automático. Puede aplicarse a distintas modalidades, entre ellas:
- Texto: Imagina que tienes un modelo entrenado para entender el lenguaje en sentido amplio, pero nunca le has enseñado un ejemplo de “reseña de producto para envases sostenibles”. Con ZSC, puede pedirle que identifique tales reseñas a partir de un montón de texto. Para ello, entiende el significado de las categorías (etiquetas) deseadas y las relaciona con el texto de entrada, en lugar de basarse en ejemplos preaprendidos para cada etiqueta específica.
- Imágenes: Un modelo entrenado en un conjunto de imágenes de animales (por ejemplo, gatos, perros, caballos) podría ser capaz de clasificar una imagen de una cebra como “animal” o incluso como “animal rayado parecido a un caballo” sin haber visto nunca una cebra durante el entrenamiento.
- Sonido: Un modelo puede estar entrenado para reconocer sonidos urbanos comunes como “claxon de coche”, “sirena” y “ladrido de perro”. Gracias a ZSC, un modelo puede identificar un sonido para el que nunca ha sido entrenado explícitamente, como “martillo neumático”, comprendiendo sus propiedades acústicas y relacionándolas con sonidos conocidos.
- Datos multimodales: ZSC puede trabajar con distintos tipos de datos, como clasificar una imagen basándose en una descripción textual de una clase que nunca ha visto, o viceversa.
¿Cómo funciona ZSC?
La clasificación sin disparos está ganando interés gracias a la popularidad de los LLM preentrenados. Estos modelos se entrenan con cantidades masivas de datos orientados a la IA, lo que les permite desarrollar un profundo conocimiento del lenguaje, la semántica y el contexto.
En el caso de las ZSC, los modelos preentrenados suelen afinarse en una tarea denominada NLI(Natural Language Inference). La NLI consiste en determinar la relación entre dos fragmentos de texto: una “premisa” y una “hipótesis”. El modelo decide si la hipótesis es una vinculación (verdadera dada la premisa), una contradicción (falsa dada la premisa) o neutra (sin relación).
En una configuración de clasificación sin disparos, el texto de entrada actúa como premisa. Las etiquetas de categoría candidatas se tratan como hipótesis. El modelo calcula qué “hipótesis” (etiqueta) es más probable que implique la “premisa” (texto de entrada). La etiqueta con la mayor puntuación de implicación se elige para la clasificación.
Ventajas y limitaciones de la clasificación de tiro por cero
Es hora de explorar las ventajas e inconvenientes de la ZSC.
Ventajas
La ZSC presenta varias ventajas operativas, entre ellas
- Adaptabilidad a nuevas clases: La ZSC abre la puerta a la clasificación de datos en categorías inéditas. Para ello, define nuevas etiquetas sin necesidad de reentrenar el modelo ni de recopilar ejemplos de entrenamiento específicos para las nuevas clases.
- Menor necesidad de datos etiquetados: El método reduce la dependencia de extensos conjuntos de datos etiquetados para las clases objetivo. Esto reduce el etiquetado de datos, uncuello de botella habitual en los plazos y costes de los proyectos de aprendizaje automático.
- Aplicación eficaz de los clasificadores: Los nuevos esquemas de clasificación pueden configurarse y evaluarse rápidamente. Eso facilita ciclos de iteración más rápidos en respuesta a la evolución de los requisitos.
Limitaciones
Aunque potente, la clasificación sin disparos presenta limitaciones como:
- Variabilidad del rendimiento: Los modelos impulsados por ZSC pueden mostrar una precisión inferior en comparación con los modelos supervisados entrenados ampliamente en conjuntos de clases fijas. Esto se debe a que ZSC se basa en la inferencia semántica en lugar del entrenamiento directo con ejemplos de clases objetivo.
- Dependencia de la calidad del modelo: El rendimiento de ZSC depende de la calidad y las capacidades del modelo lingüístico subyacente preentrenado. Un modelo de base potente suele dar mejores resultados de ZSC.
- Ambigüedad y redacción de las etiquetas: La claridad y el carácter distintivo de las etiquetas candidatas influyen en la precisión. Las etiquetas ambiguas o mal definidas pueden dar lugar a un rendimiento inferior al óptimo.
Relevancia de la clasificación de cero en el raspado web
La continua aparición de nueva información, productos y temas en la Web exige métodos de tratamiento de datos adaptables. Todo empieza con el web scraping, elproceso automatizado de recuperación de datos de páginas web.
Los métodos tradicionales de aprendizaje automático requieren una categorización manual o un reentrenamiento frecuente para manejar nuevas clases en datos raspados, lo que resulta ineficaz a escala. En cambio, la clasificación de cero disparos aborda los desafíos planteados por la naturaleza dinámica de los contenidos web al permitir:
- Categorización dinámica de datos heterogéneos: Los datos extraídos de diversas fuentes pueden clasificarse en tiempo real utilizando un conjunto de etiquetas definidas por el usuario y pertinentes para los objetivos analíticos actuales.
- Adaptación a la evolución de la información: Las nuevas categorías o temas pueden incorporarse inmediatamente al esquema de clasificación, sin necesidad de largos ciclos de reelaboración del modelo.
Así, los casos de uso típicos de ZSC en el raspado web son:
- Categorización dinámica de contenidos: Cuando se raspan contenidos como artículos de noticias o listados de productos de múltiples dominios, ZSC puede asignar automáticamente elementos a categorías predefinidas o nuevas.
- Análisis de sentimientos para temas novedosos: En el caso de las reseñas de clientes de productos nuevos o los datos de redes sociales relacionados con marcas emergentes, ZSC puede realizar análisis de sentimiento sin necesidad de datos de entrenamiento de sentimiento específicos de ese producto o marca. Esto facilita la supervisión puntual de la percepción de la marca y la evaluación de las opiniones de los clientes.
- Identificación de tendencias y temas emergentes: Al definir etiquetas de hipótesis que representan nuevas tendencias potenciales, ZSC puede utilizarse para analizar texto raspado de foros, blogs o medios sociales para identificar la creciente prevalencia de estos temas.
Aplicación práctica de la clasificación de tiro por cero
Esta sección del tutorial le guiará a través del proceso de aplicación de la clasificación de tiro cero a los datos recuperados de la Web. El sitio objetivo será “Equipos de Hockey: Formularios, búsqueda y paginación“:

En primer lugar, un raspador web extraerá los datos de la tabla anterior. A continuación, un LLM los clasificará utilizando ZSC. Para este tutorial, se utilizará el DistilBart-MNLI de Hugging Face: un LLM ligero de la familia BART.
Siga los pasos que se indican a continuación y vea cómo conseguir el objetivo de ZSC deseado.
Requisitos previos y dependencias
Para replicar este tutorial, debes tener Python 3.10.1 o superior instalado en tu máquina.
Supongamos que llamas a la carpeta principal de tu proyecto zsc_project/. Al final de este paso, la carpeta tendrá la siguiente estructura:
zsc_project/
├── zsc_scraper.py
└── venv/Dónde:
zsc_scraper.pyes el archivo Python que contiene la lógica de codificación.venv/contiene el entorno virtual.
Puede crear el directorio del entorno virtual venv/ de la siguiente manera:
python -m venv venvPara activarlo, en Windows, ejecute
venvScriptsactivateDe forma equivalente, en macOS y Linux, ejecute:
source venv/bin/activateEn el entorno virtual activado, instale las dependencias con:
pip install requests beautifulsoup4 transformers torchEstas dependencias son:
peticiones: Una biblioteca para realizar peticiones web HTTP.beautifulssoup4: Una biblioteca para analizar documentos HTML y XML y extraer datos de ellos. Más información en nuestra guía sobre raspado web BeautifulSoup.transformadores: Una biblioteca de Hugging Face que proporciona miles de modelos preentrenados.torch: PyTorch, un marco de aprendizaje automático de código abierto.
¡Maravilloso! Ya tiene lo que necesita para extraer los datos del sitio web de destino y realizar el ZSC.
Paso 1: Instalación y configuración iniciales
Inicializa el archivo zsc_scraper.py importando las librerías necesarias y configurando algunas variables:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process El código anterior hace lo siguiente:
- Define el sitio web de destino para raspar con
BASE_URL. CANDIDATES_LABELSalmacena una lista de cadenas que definen las categorías que el modelo de clasificación zero-shot utilizará para clasificar los datos raspados. El modelo intentará determinar cuál de estas etiquetas describe mejor cada dato del equipo.- Define el número máximo de páginas a raspar y el número máximo de datos de equipos a recuperar.
Perfecto. Ya tienes lo necesario para empezar con la clasificación de tiro cero en Python.
Paso 2: Obtener las URL de las páginas
Empiece por inspeccionar el elemento de paginación de la página de destino:

Aquí puede observar que las URL de paginación están contenidas en un nodo HTML .pagination.
Defina una función para encontrar todas las URL de páginas únicas de la sección de paginación del sitio web:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urlsEsta función:
- Envía una petición HTTP al sitio web de destino con el método
get(). - Gestiona la paginación con el método
select()de BeautifulSoup. - Itera a través de cada página, asegurando un orden consistente, con un bucle
for. - Devuelve la lista de todas las URL únicas de página completa.
Genial. Has creado una función para obtener las URL de las páginas web de las que extraer datos.
Paso 3: Recopilar los datos
Empiece por inspeccionar el elemento de paginación de la página de destino:

Aquí, puede ver que los datos de los equipos a raspar están contenidos en un nodo HTML .table.
Cree una función que tome una URL de una sola página, obtenga su contenido y extraiga las estadísticas del equipo:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_dataEsta función:
- Recupera los datos de las filas de la tabla con el método
select(). - Procesa cada fila del equipo con el bucle
for row in table_rows:. - Devuelve los datos obtenidos en una lista.
Bien hecho. Has creado una función para recuperar los datos del sitio web de destino.
Paso 4: Organizar el proceso
Coordine todo el flujo de trabajo en los siguientes pasos:
- Cargar el modelo de clasificación
- Obtener las URL de las páginas que se van a raspar
- Extraer datos de cada página
- Clasificar el texto raspado con ZSC
Consíguelo con el siguiente código:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Este código:
- Carga el modelo preentrenado con el método
pipeline()y especifica su tarea con"zero-shot-classification". - Llama a las funciones anteriores y realiza la ZSC propiamente dicha.
Perfecto. Has creado una función que orquesta todos los pasos anteriores y realiza la clasificación real de tiro cero.
Paso 5: Junte todo y ejecute el código
A continuación se muestra lo que el archivo zsc_scraper.py debe contener ahora:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Muy bien. Has completado tu primer proyecto ZSC.
Ejecute el código con el siguiente comando:
python zsc_scraper.pyEste es el resultado esperado:
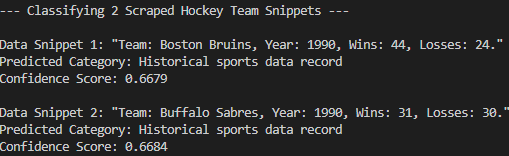
Como puede ver, el modelo ha clasificado correctamente los datos raspados en el “Registro histórico de datos deportivos”. Eso no habría sido posible sin la clasificación por cero. ¡Misión cumplida!
Conclusión
En este artículo, ha aprendido qué es la clasificación de disparo cero y cómo aplicarla en un contexto de web scraping. Los datos web cambian constantemente, y no se puede esperar que un LLM preentrenado lo sepa todo de antemano. ZSC ayuda a cerrar esa brecha clasificando dinámicamente la nueva información sin necesidad de reentrenamiento.
Sin embargo, el verdadero reto consiste en obtener datos frescos, ya queno todos los sitios web son fáciles de raspar. Ahí es donde entra Bright Data, que ofrece un conjunto de potentes herramientas y servicios diseñados para superar los obstáculos del scraping. Entre ellos se incluyen.
- Web Unlocker: Una API que elude las protecciones anti-scraping y entrega HTML limpio de cualquier página web con el mínimo esfuerzo.
- Navegador de raspado: Un navegador controlable basado en la nube con renderizado JavaScript. Maneja automáticamente CAPTCHAs, huellas digitales del navegador, reintentos, y más para usted. Se integra perfectamente con Panther o Selenium PHP.
- API de Web Scraper: Puntos finales para el acceso programático a datos web estructurados de docenas de dominios populares.
Para el escenario del aprendizaje automático, explore también nuestro centro de IA.
Regístrese ahora en Bright Data y comience su prueba gratuita para probar nuestras soluciones de scraping.





